如何将飞书上的表格导入到lakehouse中
1. 前期准备说明
飞书应用的创建:获取应用凭证信息
云器Lakehouse的账号信息:登录云器web页面创建脚本任务导入数据
目标表格类型确认:此部分很重要!需要基于目标表格的类型明确需要开通的系列权限。
2. 飞书应用创建与配置
创建飞书应用
步骤1:登录飞书开放平台
访问:https://open.feishu.cn/
使用飞书账号登录
点击右上角"进入开发者后台"
步骤2:创建应用
点击"创建应用"
选择"企业自建应用"
填写应用信息:
应用名称 :云器数据同步应用
应用描述 :将飞书表格数据同步到云器lakehouse中
应用图标 :上传应用图标(可选)
步骤3:获取应用凭证
创建完成后,在左侧菜单"凭证与基础信息"页面记录:
App ID :cli_xxxxxxxxxx
App Secret :xxxxxxxxxxxxxxxx
配置应用权限
在配置权限前,请先确认需要导入的文件类型,并基于飞书文档的权限要求开通相应的权限。本文以电子表格(sheets)为例进行操作说明。具体类型可参考飞书API文档
步骤1:申请权限范围
进入"权限管理"页面
搜索并添加以下权限:
表格相关权限 :
sheets:spreadsheet - 查看、评论、编辑和管理工作表
sheets:spreadsheet:readonly - 查看工作表
drive:drive - 查看云文档文件夹
具体操作 :
权限范围 → 搜索"sheets" → 勾选以下权限:
1、查看、评论、编辑和管理工作表
2、查看和编辑电子表格
3、查看云文档文件夹
步骤2:申请权限审批
点击"创建版本"
填写版本说明:数据同步功能上线
提交审核(如果是企业内部应用,通常自动通过)
步骤3:应用发布
审核通过后,点击"申请线上发布"
选择发布范围:
全员可见 :推荐选择
指定部门 :根据需要选择
获取表格访问权限
注意:若是企业用户,除了在应用开发中配置权限,还需要在文档中开通应用访问权限。
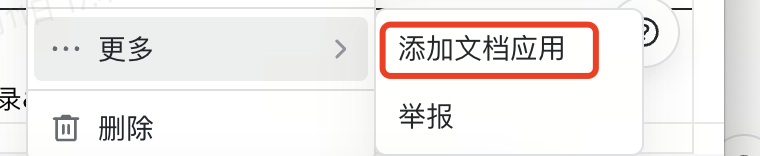
打开目标飞书表格
点击页面右上角...-->选择更多-->添加文档应用
配置文档应用权限
搜索应用名称:云器数据同步应用
设置权限:可编辑 (确保能读取数据)
记录关键信息
应用凭证 :是飞书开放平台应用的身份标识和安全凭据
App ID :cli_xxxxxxxxxxApp Secret :xxxxxxxxxxxxxxxx
tenant_access_token :是飞书开放平台中自建应用用于访问租户资源的凭证。最长访问时效是2小时。
数据资源URL中要求相关信息 :例如针对电子表格URL 中:https://open.feishu.cn/open-apis/sheets/v2/spreadsheets/:spreadsheetToken/values/:range
spreadsheetToken:电子表格的 token
Range:格式为!<开始位置>:<结束位置>。
3. 云器lakehouse中导入飞书数据
方式一:使用python脚本导入飞书数据
步骤1:在云器Studio中创建Python任务
登录云器Lakehouse控制台
进入"开发" → "Python任务"
点击"新建任务"
配置任务信息:任务名称 :飞书数据同步,任务描述 :从飞书表格导入数据到Lakehouse
步骤2:配置代码参数
import requests
from sqlalchemy import text
from clickzetta_dbutils import get_active_lakehouse_engine
def get_feishu_token():
url = "https://open.feishu.cn/open-apis/auth/v3/tenant_access_token/internal"
data = {"app_id": "您自己的app_id", "app_secret": "xxxxxxxxxxxxx"}
response = requests.post(url, json=data, timeout=5)
return response.json()['tenant_access_token']
def get_sheet_data(token):
url = "https://open.feishu.cn/open-apis/sheets/v2/spreadsheets/DuUHsqS6qh97i9tpNkYcoC84nHb/values/2729cf!A1:B2"
headers = {"Authorization": f"Bearer {token}"}
response = requests.get(url, headers=headers, timeout=5)
return response.json()['data']['valueRange']['values']
def get_lakehouse_connection():
"""
使用get_active_lakehouse_engine连接Lakehouse,无需用户在python中填写云器关联的账户信息
注意:vcluster参数是必填的
"""
engine = get_active_lakehouse_engine(
vcluster="DEFAULT", # 必填:虚拟集群名称
workspace="对应的工作空间名称", # 可选:工作空间名称
schema="public" # 可选:schema名称,默认为public
)
return engine
def create_table():
"""创建表:这里需要要求自己根据飞书表中的数据信息创建规范的table"""
engine = get_lakehouse_connection()
create_sql = text("""
CREATE TABLE IF NOT EXISTS feishu_data (
name VARCHAR(255),
id BIGINT,
created_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP
)
""")
with engine.connect() as conn:
conn.execute(create_sql)
print("✅ 表创建成功")
def insert_data(data):
"""插入数据 """
engine = get_lakehouse_connection()
headers = data[0]
rows = data[1:]
# 批量生成SQL
for i, row in enumerate(rows):
name = str(row[0]).replace("'", "''") # 转义单引号
id_value = int(row[1])
with engine.connect() as conn:
insert_sql = f"INSERT INTO feishu_data (name, id) VALUES ('{name}', {id_value})"
conn.execute(text(insert_sql))
print(f"✅ 插入第{i+1}行: {name}, {id_value}")
print(f"✅ 数据插入完成,共{len(rows)}条记录")
def verify_data():
"""验证数据"""
engine = get_lakehouse_connection()
with engine.connect() as conn:
result = conn.execute(text("SELECT * FROM feishu_data ORDER BY created_time DESC"))
rows = result.fetchall()
print(f"\n📊 验证结果 (共{len(rows)}条记录):")
for row in rows:
print(f" name: {row.name}, ID: {row.id}, 时间: {row.created_time}")
if __name__ == "__main__":
print("🚀 飞书数据导入云器Lakehouse")
print("=" * 50)
# 1. 获取飞书数据
print("\n📥 获取飞书数据...")
token = get_feishu_token()
print(f"Token获取成功: {token[:10]}...")
data = get_sheet_data(token)
print("飞书数据获取成功:")
for i, row in enumerate(data):
print(f" 行{i+1}: {row}")
# 2. 创建表
print(f"\n🔧 创建Lakehouse表...")
create_table()
# 3. 插入数据
print(f"\n📝 插入数据...")
insert_data(data)
# 4. 验证数据
print(f"\n🔍 验证结果...")
verify_data()
print(f"\n🎉 任务完成!")步骤3:配置调度信息进行周期调度(可选)
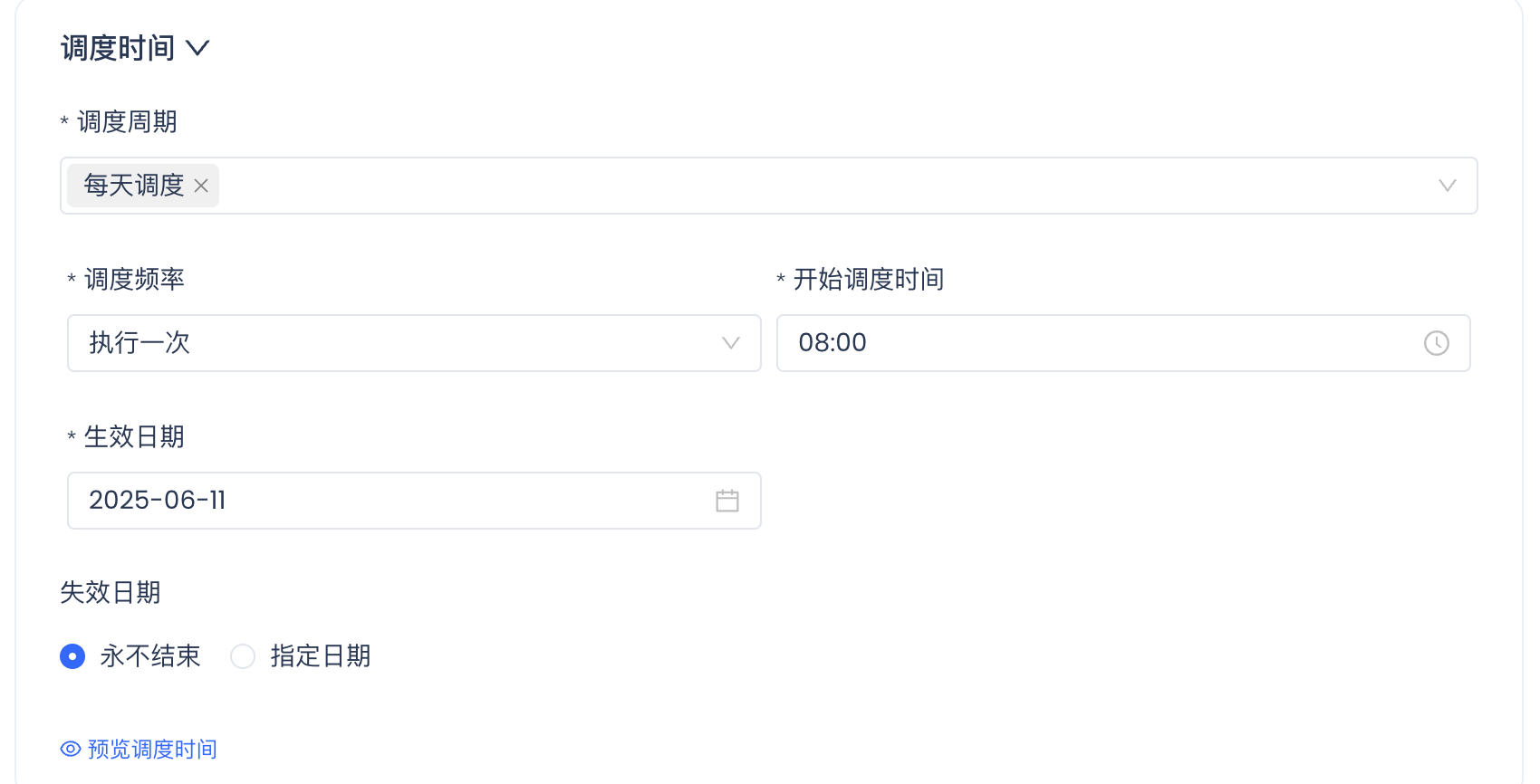
若需要定期从表中拉取数据,可直接配置该python任务的调度信息。
例如:若需要每天早上8点定时拉取最新数据,则可进行如下配置
调度周期:每天调度
调度频率:执行一次、开始调度时间:08:00
生效日期:2025-06-11(希望任务开始运行的时间)
方式二:使用离线任务的方式导入飞书数据
当前离线任务的方式暂时不支持周期性抽取数据,只支持手动触发执行。
步骤1:获取tenant_access_token
可使用python脚本获取tenant_access_token
登录云器Lakehouse控制台
进入"开发" → "Python任务"
点击"新建任务"
配置任务信息:
任务名称 :获取飞书tenant_access_token
import requests # 添加导入语句
def get_feishu_token():
url = "https://open.feishu.cn/open-apis/auth/v3/tenant_access_token/internal"
data = {
"app_id": "cli_xxxxxxx",
"app_secret": "xxxxxxxxxxxxxx"
}
response = requests.post(url, json=data)
# 添加错误处理(重要!)
if response.status_code != 200:
raise Exception(f"HTTP请求失败,状态码: {response.status_code}")
json_data = response.json()
# 检查飞书API返回的错误
if json_data.get("code") != 0:
raise Exception(f"飞书API错误: [{json_data.get('code')}] {json_data.get('msg')}")
return json_data['tenant_access_token']
# 调用函数并打印结果
try:
result = get_feishu_token()
print(f"获取的租户访问令牌: {result}")
except Exception as e:
print(f"获取token失败: {str(e)}")步骤2:使用RestApi的方式创建飞书数据源
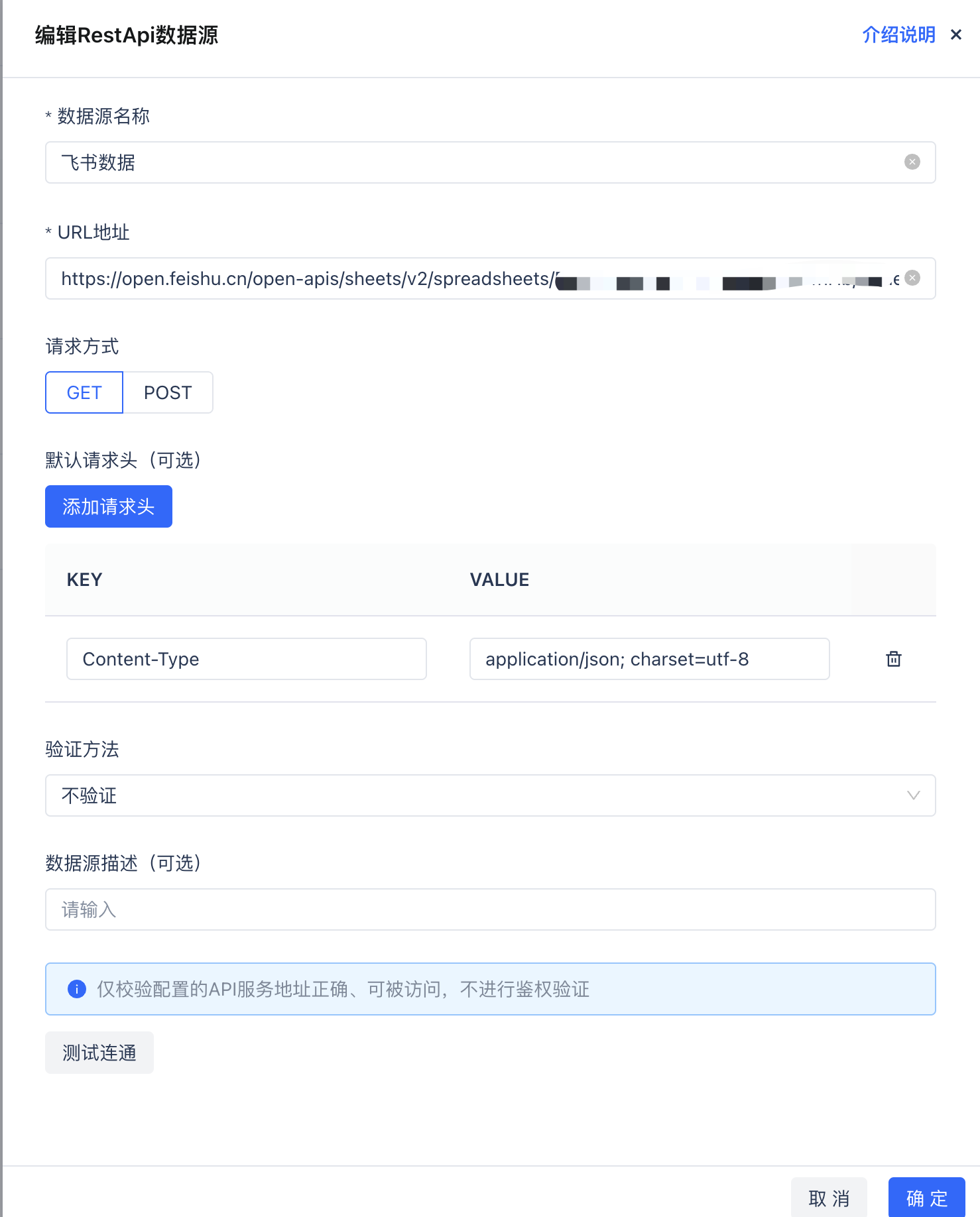
登录云器Lakehouse控制台
进入"管理-数据源"
新建数据源,选择RestApi
步骤3:创建离线同步任务同步数据
登录云器Lakehouse控制台
进入"开发" → "离线同步"
点击"新建任务"
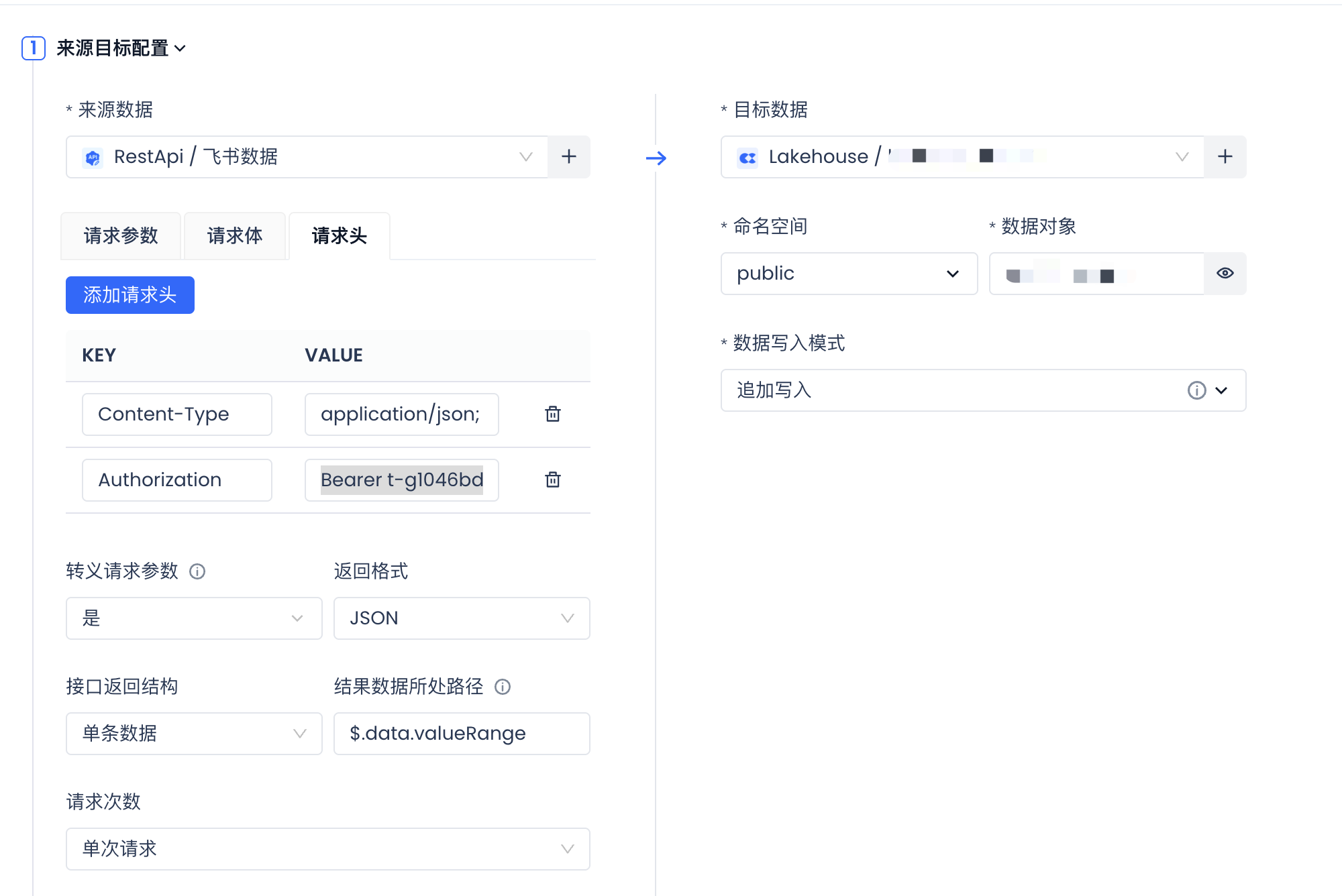
来源目标配置:
来源数据:选择同步的数据源:飞书数据。 数据源配置参考步骤2
请求参数:空
请求体:填写应用凭证 { "app_id": "cli_xxxx", "app_secret": "xxxxxxxxxxxxxx" }
请求头:key :value Content-Type:application/json; charset=utf-8 Authorization :Bearer tenant_access_token
结果数据所处路径:你需要导入的数据的具体位置。可先不配置,通过点击预览数据确定数据位置后填写。
-----------------------------------------------------------------------------------
目标数据:导入的数据地址。若是导入至云器lakehouse中,需先创建相应的table。(当前方式暂不支持快速建表)
图例:数据对象表名为:test02_feishu
字段映射配置:暂不支持嵌套数组格式的JSON解析,因此针对飞书API返回的数据,仅支持将value值以string类型导入至目标表中。
步骤4:数据处理,将导入string字段处理成标准化表
前提:需要用户提前明确表结构。
登录云器Lakehouse控制台
进入"开发" → "SQL任务"
点击"新建任务"
-- 1. 创建目标表
CREATE TABLE if not EXISTS test02_feishu_parsed (
name STRING,
id BIGINT
);
-- 2. 转换并插入数据
INSERT INTO test02_feishu_parsed
WITH parsed AS (
SELECT from_json(content, 'array<array<string>>') as arr
FROM test02_feishu
WHERE content IS NOT NULL
),
flattened AS (
SELECT explode(slice(arr, 2, size(arr))) as row_data
FROM parsed
WHERE size(arr) > 1
)
SELECT
row_data[0] as name,
CAST(row_data[1] AS BIGINT) as id
FROM flattened;
-- 3. 查看结果
SELECT * FROM test02_feishu_parsed;4. 常见问题
问题1:使用python脚本和离线任务导入飞书数据的区别
Python脚本导入:可支持定期调度飞书表格中的数据,但是需要用户熟悉Python语法。
离线任务导入:提供无代码页面配置,操作门槛较低。但是当前暂不支持周期调度,后续版本会支持。
问题2:开发过程中总是提示没有权限
检查相关权限是否配置正确
飞书应用中:是否是基于文件类型配置相应的权限。注意,url中sheet和wiki对应的权限都是有区别的,一定要选择正确的权限点。
配置后是否发布审批:用户在配置权限后,还需点击发布,待管理员审批通过后才能获取权限点
是否在飞书文档中为该应用配置了访问权限。此步骤非常重要!企业用户必须完成此配置才能通过API进行访问。