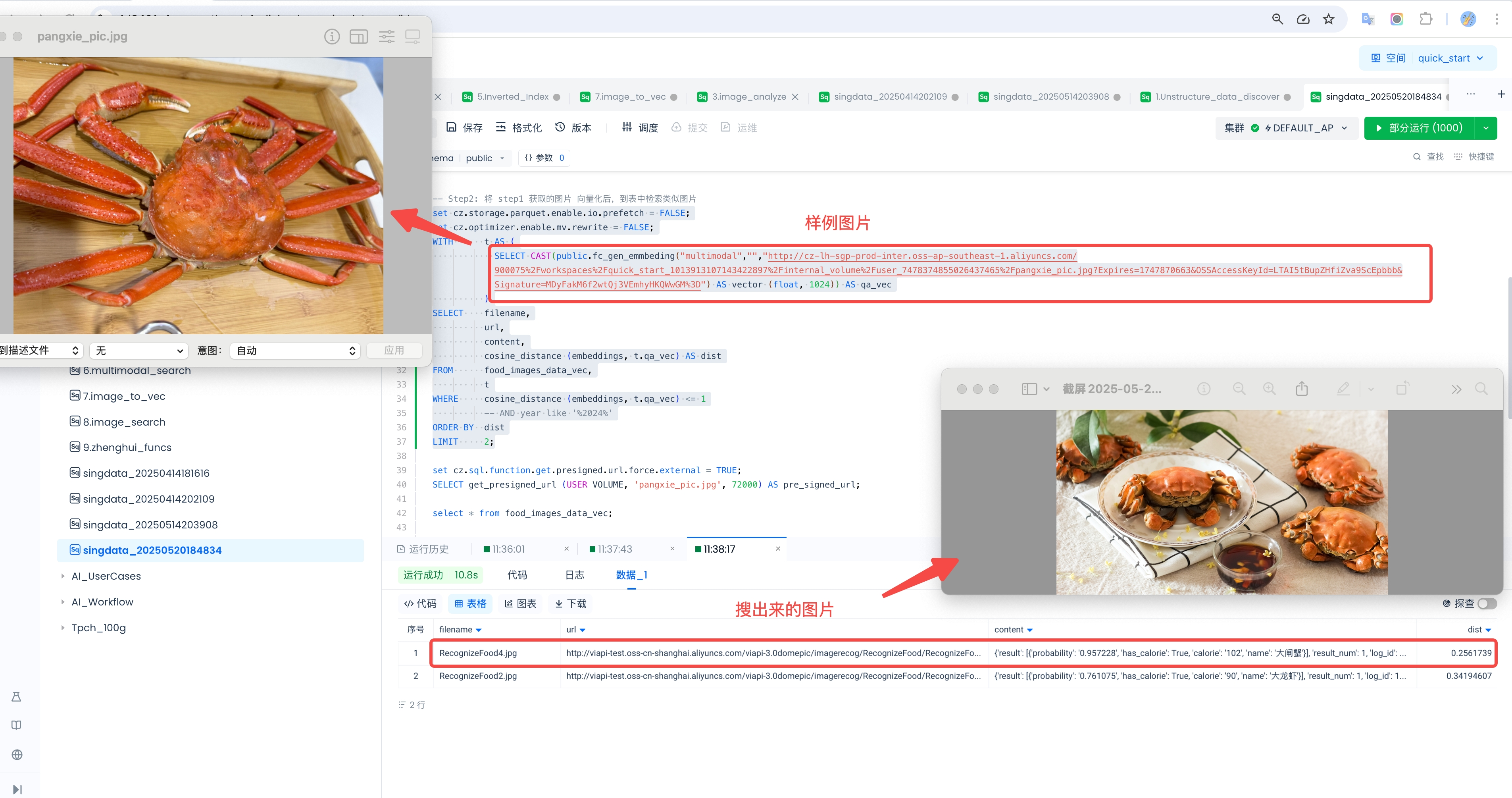
外部 AI 函数 :创建 Embedding 函数目标:利用阿里云百炼平台的 Embedding 函数,将文本和图片文件数据向量化,并实现以图搜图的场景。效果如下:
注意:完成本示例,需要您:
已安装 Docker(主要是为了保证开发环境与云上运行函数的环境一致)
拥有阿里云账号,并开通百炼平台的 API-KEY。参考 阿里云百炼
已经创建好 API 连接。参考:创建 API 连接
Step 1:准备开发环境
安装 Docker :确保您的本地已安装 Docker:https://www.docker.com/
拉取 Docker 镜像 。在本地命令行终端(如 macOS 的 Terminal)执行:
[Local]# docker pull quay.io/pypa/manylinux2014_x86_64:2022-10-25-fbea779
启动 Docker 容器 :该容器基于 manylinux2014_x86_64 镜像,并配置为使用 Python 3.10 环境。
[Local]# docker run -it --name cz_func --env PATH="/opt/python/cp310-cp310/bin:$PATH" quay.io/pypa/manylinux2014_x86_64:2022-10-25-fbea779 bash
如果容器已经停止,可以用以下命令启动并进入:
启动容器 :
进入容器 :
# docker exec -it cz_func bash
在 /root 目录下创建文件夹 embeddings
[root@docker root]# cd /root ; mkdir embeddings
[root@docker embeddings]# cd embeddings
[root@docker embeddings]# touch gen_embeddings.py
cz_llm.py 中的程序代码如下:
import os
from cz.udf import annotate
from openai import OpenAI
import json
@annotate("*->string")
class get_embeddings(object):
def evaluate(self, model_type, input_string, api_key, model_name, dim=None):
if model_type == "text":
# 初始化OpenAI客户端,使用用户提供的API密钥
client = OpenAI(
api_key=api_key,
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
input_data = input_string
completion = client.embeddings.create(
model=model_name, # 使用用户提供的文本模型名称
input=input_data,
dimensions=int(dim), # 指定向量维度
encoding_format="float"
)
result_json = json.loads(completion.model_dump_json())
embedding_vector = result_json['data'][0]['embedding']
elif model_type == "multimodal":
import dashscope
image = input_string
dashscope.api_key = api_key # 使用用户提供的API密钥
input = [{'image': image}]
resp = dashscope.MultiModalEmbedding.call(
model=model_name, # 使用用户提供的多模态模型名称
input=input
)
result_json = json.loads(json.dumps(resp.output, ensure_ascii=False, indent=4))
embedding_vector = result_json['embeddings'][0]['embedding']
else:
return "Not Valid Model Type"
if len(embedding_vector) >= 1:
return str(embedding_vector)
else:
return "Not Valid"
# 添加命令行调用入口
if __name__ == "__main__":
import argparse
parser = argparse.ArgumentParser(description="Get Embeddings using OpenAI or DashScope")
parser.add_argument('--model_type', required=True, help='Model type: text or multimodal')
parser.add_argument('--input_string', required=True, help='The input string or image path')
parser.add_argument('--api_key', required=True, help='Your API key')
parser.add_argument('--model_name', required=True, help='Model name')
parser.add_argument('--dim', default=1536, help='Vector dimensions (only for text models)')
args = parser.parse_args()
embedder = get_embeddings()
result = embedder.evaluate(
model_type=args.model_type,
input_string=args.input_string,
api_key=args.api_key,
model_name=args.model_name,
dim=args.dim
)
print(result)Step 2:下载第三方库
程序依赖第三方包:openai 需要进行下载(其余为 Python 内置库,os、json 为 Python 内置库,无需下载。cz.udf 在创建函数时系统会默认添加)。
在开发环境的命令行终端执行:
[root@docker embeddings]# pwd
/root/embeddings
[root@docker embeddings]# pip install openai -t .此时目录结构类似于:
Step 3:本地调试
需要对以下 3 行代码进行修改,因为当前环境还没有加载 cz.udf 库:
...
2 #from cz.udf import annotate # 注释掉
...
6 #@annotate("*->string") # 注释掉
...其中 API_KEY 是阿里云百炼平台的 API-KEY,需要您注册阿里云账号,登录后在这里获取:阿里云百炼
注释掉上面两行之后,保存并退出编辑脚本。请将下面的 image_url 和 api_key 替换为真实的参数并执行:
[root@docker embeddings]# export PYTHONPATH="${_PWD}:${_PWD}/lib"
[root@docker embeddings]# python gen_embeddings.py \
--model_type multimodal \
--input_string ${image_url} \
--api_key ${api_key} \
--model_name multimodal-embedding-v1Step 4:打包上传
打包之前,请将上面注释掉的两行代码取消注释。
...
2 from cz.udf import annotate # 去掉注释
...
8 @annotate("*->string") # 去掉注释执行打包命令前,请确保当前目录为程序目录(本示例为 /root/cz_llm)。
[root@docker embeddings]# pwd
/root/embeddings
[root@docker embeddings]# zip -rq ../embeddings.zip ./
[root@docker embeddings]# ls ../
提示:如果您的环境没有 zip 命令,请使用 yum install zip 尝试安装。安装过程中遇到问题,请参考附录“安装工具时报错 ”。
您会发现在 /root 目录下有一个 cz_llm.zip 文件,将这个文件拷贝到 Lakehouse USER VOLUME 中:
在 Docker 宿主机中执行:
[Local]# docker cp cz_func:/root/embeddings.zip ~/Downloads现在 cz_llm.zip 在宿主机的用户 Downloads 目录下
我们使用 Lakehouse JDBC 客户端(请参考 Lakehouse JDBC 客户端 ),将文件上传(put)到 Lakehouse USER VOLUME 中:
PUT '/Users/derekmeng/Downloads/embeddings.zip' to USER VOLUME;
Step 5:创建并使用函数:
本步骤依赖您提前创建好 API Connection,创建过程请参考:API Connection
CREATE EXTERNAL FUNCTION public.fc_embeddings
AS 'gen_embeddings.get_embeddings'
USING ARCHIVE 'volume:user://~/embeddings.zip'
connection sg_fc_api_conn
WITH PROPERTIES (
'remote.udf.api' = 'python3.mc.v0'
)
COMMENT 'Examples:
For text: text <input_string> <api_key> <model_name> <dim>
For multimodal:multimodal <input_string> <api_key> <model_name>';
# Verify
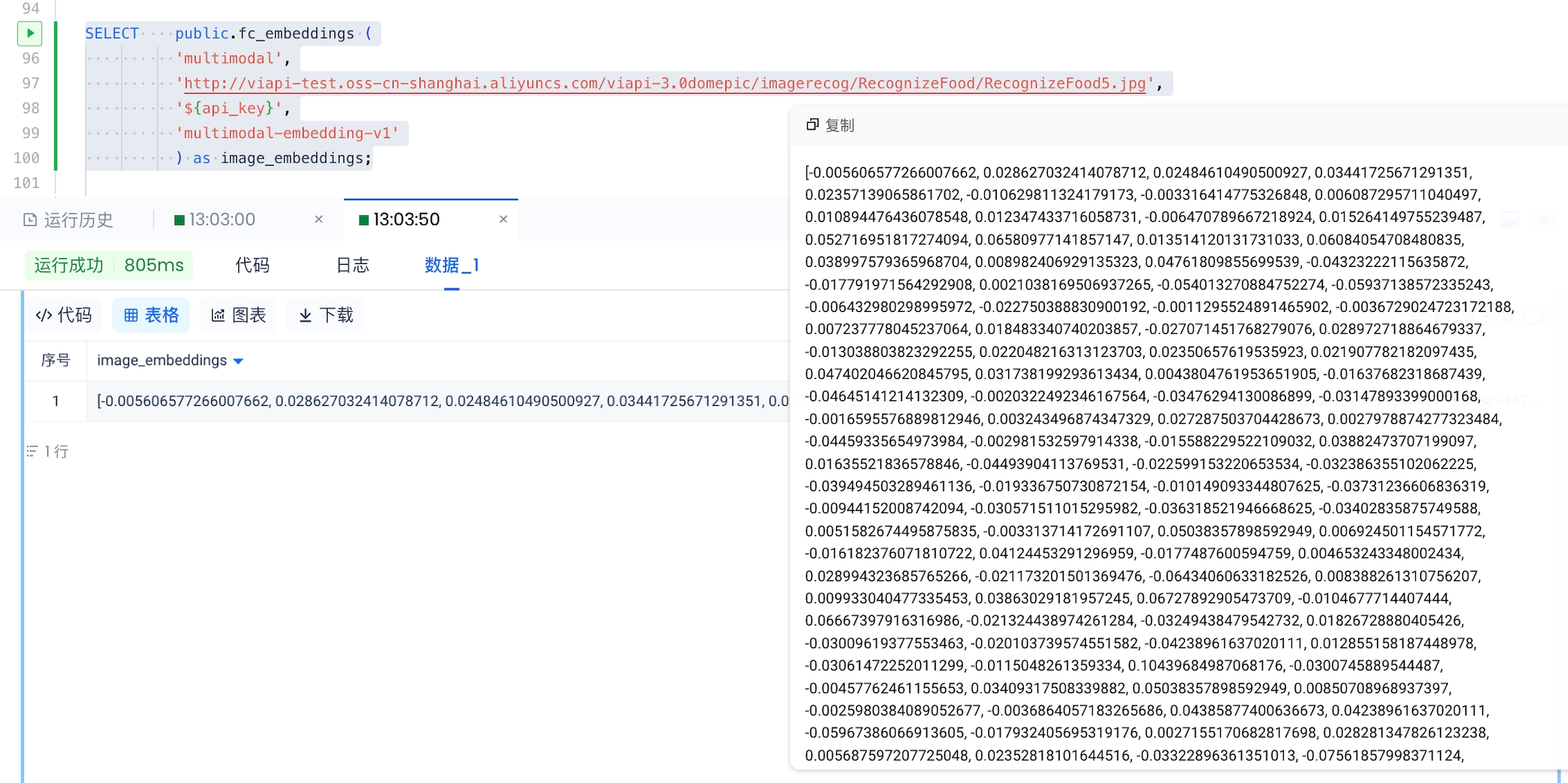
select public.fc_embeddings('multimodal', 'http://viapi-test.oss-cn-shanghai.aliyuncs.com/viapi-3.0domepic/imagerecog/RecognizeFood/RecognizeFood5.jpg', '${api_key}', 'multimodal-embedding-v1');执行效果:
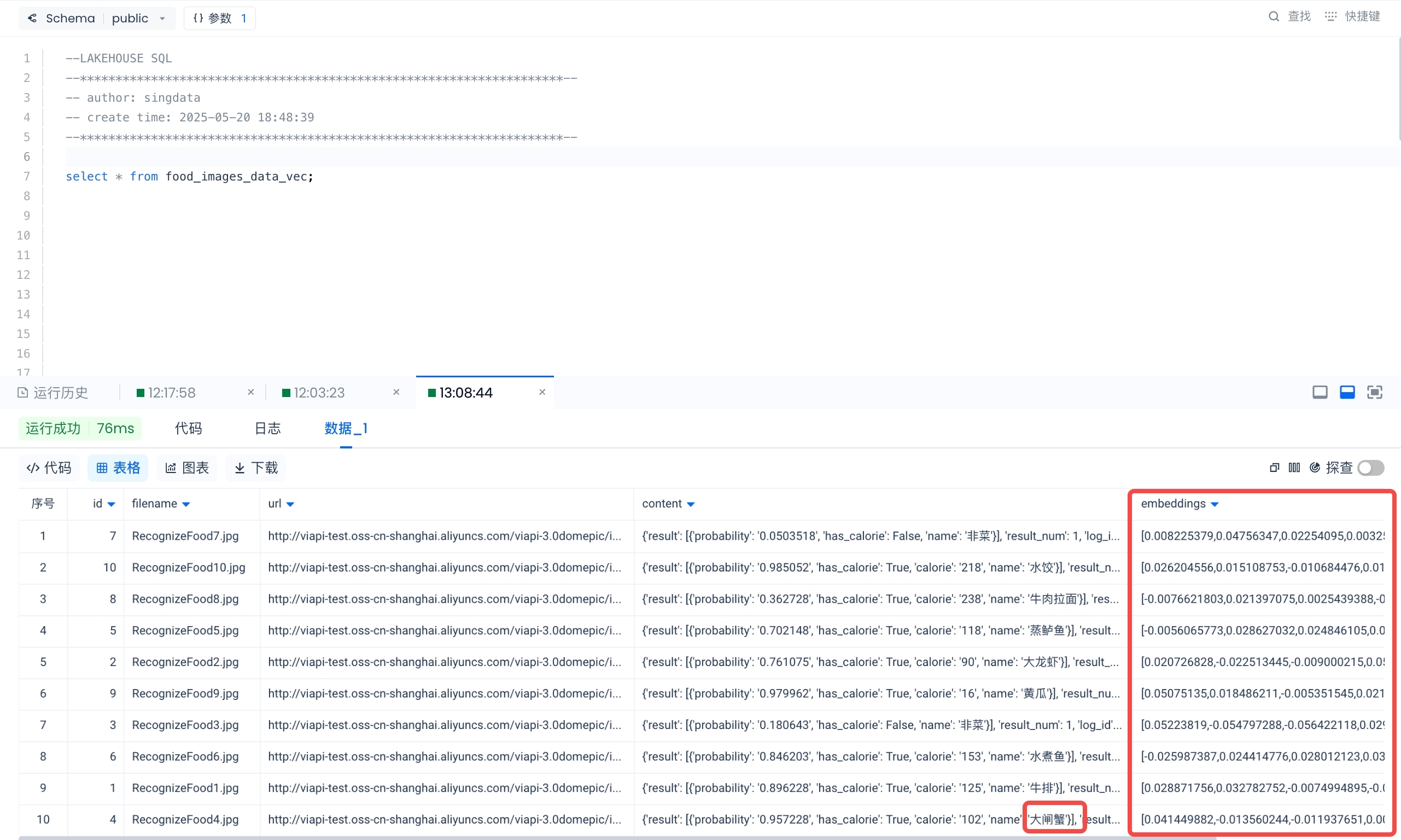
接下来的步骤是实现以图搜图功能的核心步骤。该查询接收一个图片 URL,将其向量化,然后与数据表(food_images_data_vec)中的所有图片向量进行比较。表 food_images_data_vec 的内容如下:
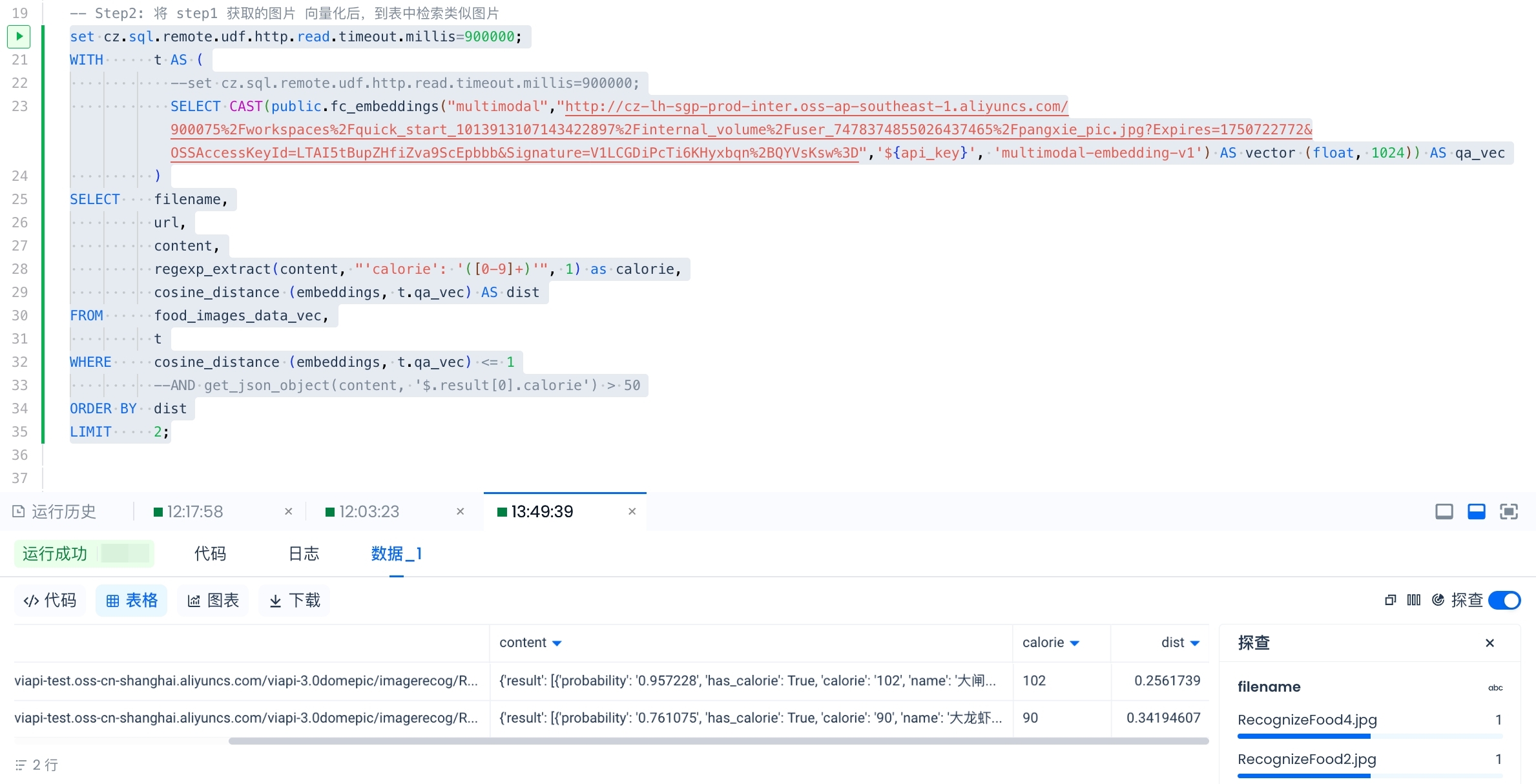
向量搜图的效果: