将AWS S3的非结构化数据转换为Lakehouse中的RAG就绪数据
在Lakehouse中统一处理非结构化和结构化数据以用于RAG应用
在Lakehouse架构中开发检索增强生成(RAG)应用面临特定挑战。整合文本、图像、视频和结构化表格等不同数据类型需要强大的架构灵活性。确保不同格式和来源的数据质量和一致性需要全面的验证和转换流程。高效管理大量非结构化和结构化数据的存储,同时保持可扩展性和性能是重大挑战。这些数据类型的处理和分析需要先进的算法和大量计算能力。此外,不同数据类型和来源的健壮数据治理、安全性和合规性增加了复杂性。
尽管存在这些挑战,但在RAG应用开发中统一处理非结构化和结构化数据是至关重要的。这种方法可以整合不同数据类型,提供全面视图,揭示单独分析时可能不明显的深入见解。统一方法简化了操作,减少了对多个系统的依赖,从而简化了维护并降低了运营成本。它确保了数据一致性和准确性,提高了数据驱动决策的可靠性。统一处理允许结合不同数据类型的见解,进行高级分析。这种方法优化了资源利用,增强了可扩展性和灵活性,简化了架构,并通过减少数据重复和移动提高了数据一致性。此外,具有统一处理的简化架构减少了运营开销,提高了开发效率,并增强了数据一致性,这对于有效且高效的RAG应用至关重要。
统一数据管道解决方案概述
数据源:
- AWS S3上的非结构化文件(PDF、邮件、JPG等)
AI数据转换:
- 将非结构化数据转换为JSON格式,包括嵌入数据、文本摘要和图像摘要。
数据加载到Lakehouse:
- 将原始数据加载到
raw_table,存储与文件和元素相关的各种元数据和内容。
数据清洗和转换(Lakehouse向量/倒排索引):
- 清洗并转换原始数据到
silver_table,带有向量索引和倒排索引。
数据检索(Lakehouse SQL):
- 使用Lakehouse SQL进行向量和文本搜索,以检索和分析数据。
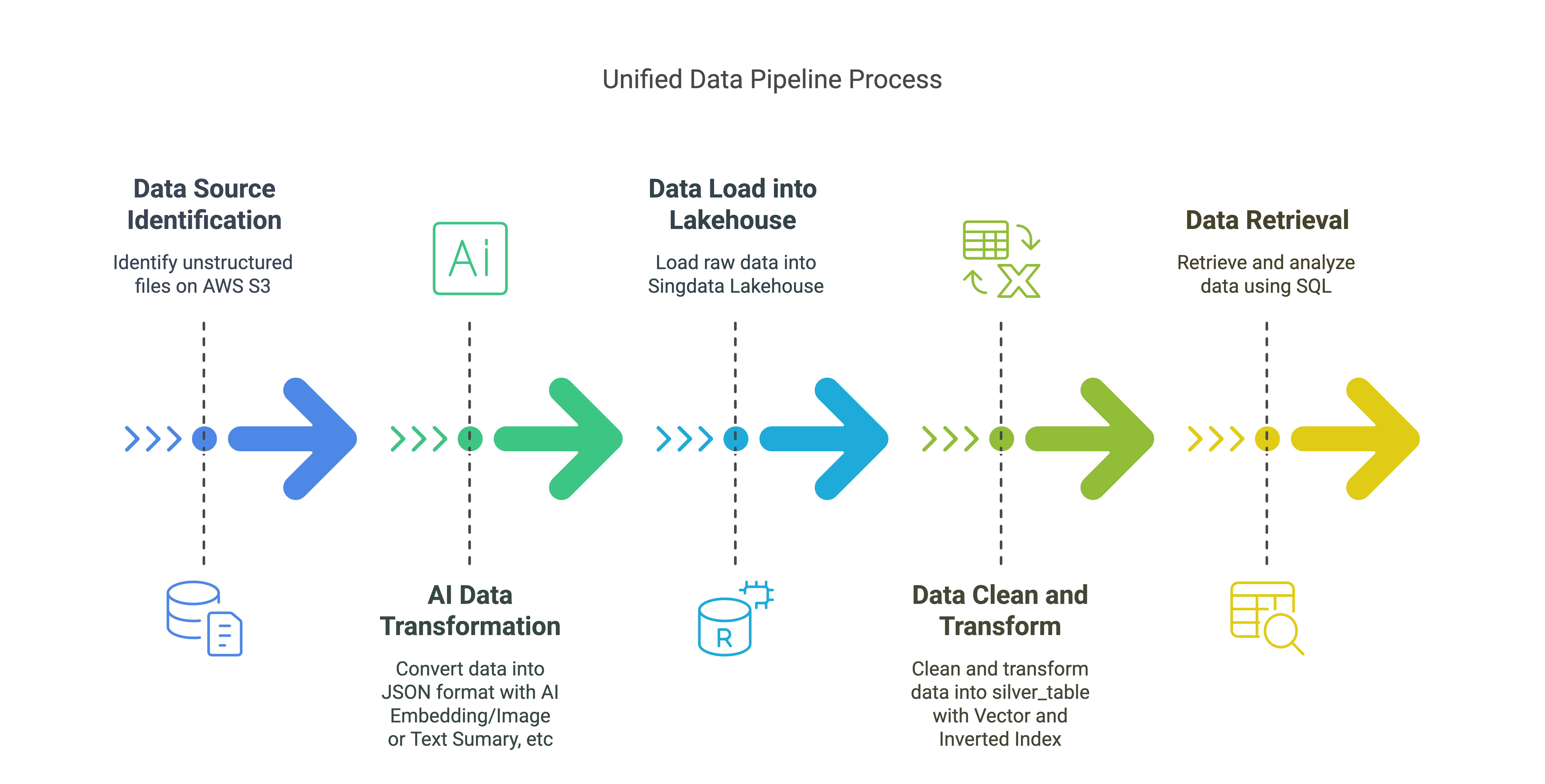
关键组件:
- AWS S3:存储非结构化数据。
- 非结构化数据:从S3摄取非结构化数据,将其转换为JSON格式。
- 非结构化Lakehouse连接器:将数据加载到Lakehouse。
- Lakehouse:存储和管理用于RAG应用的转换数据,带有向量索引和倒排索引。
在本快速教程中,我们将从S3存储桶中摄取PDF/邮件/图像,使用Unstructured将其转换为标准化的JSON,然后进行分块、嵌入并加载到Lakehouse表中。之后,RAG应用可以从Lakehouse中检索数据,并以适用于RAG应用的格式获取嵌入数据和文本/图像内容。
先决条件:
A. 获取您的Unstructured Serverless API密钥。它提供14天试用,每天最多1000页。
B. 获取您的Lakehouse账户。它提供1个月试用和200元优惠券。
C. 创建一个AWS S3存储桶,并填充您选择的PDF文件。请务必记录下您的凭证。
D. 安装必要的库:
- 打开终端并创建新的Python 3.9.21环境,命名为“非结构化”:
conda create -n unstructured python=3.9
conda activate unstructured
然后选择非结构化作为当前环境
- 您可以联系qiliang@clickzetta.com获取unstructured_ingest-0.5.5-py3-none-any.whl。
您可以从GitHub存储库获取源代码。
!pip install -U dist/unstructured_ingest-0.5.5-py3-none-any.whl --force-reinstall
!pip install -U "unstructured-ingest[s3, pdf, clickzetta, embed-huggingface]"
!pip install --force-reinstall "unstructured-ingest[clickzetta]"
!pip install python-dotenv
import json
import pandas as pd
import logging
import warnings
logging.basicConfig(level=logging.ERROR)
warnings.filterwarnings("ignore", category=UserWarning)
# 如果您想删除表,请将drop_tables设置为True
drop_tables = True
加载环境变量
在此示例中,我们从Localfile的.env文件中加载所有包含机密信息的环境变量。.env文件包含以下变量:
cz_username:连接到Lakehouse服务的用户名
cz_password:连接到Lakehouse服务的密码
cz_service:要连接的Lakehouse服务名称
cz_instance:要连接的Lakehouse服务实例名称
cz_workspace:要连接的Lakehouse服务工作区名称
cz_schema:要连接的Lakehouse服务架构名称
cz_vcluster:要连接的Lakehouse服务虚拟集群名称
AWS_KEY:连接到AWS服务的密钥
AWS_SECRET:连接到AWS服务的密钥
AWS_S3_NAME:连接到AWS S3服务的存储桶名称
UNSTRUCTURED_API_KEY:连接到UNSTRUCTURED API的API密钥
UNSTRUCTURED_URL:连接到UNSTRUCTURED API的URL
import os
import dotenv
dotenv.load_dotenv('./.env') # 替换为您.env文件的路径
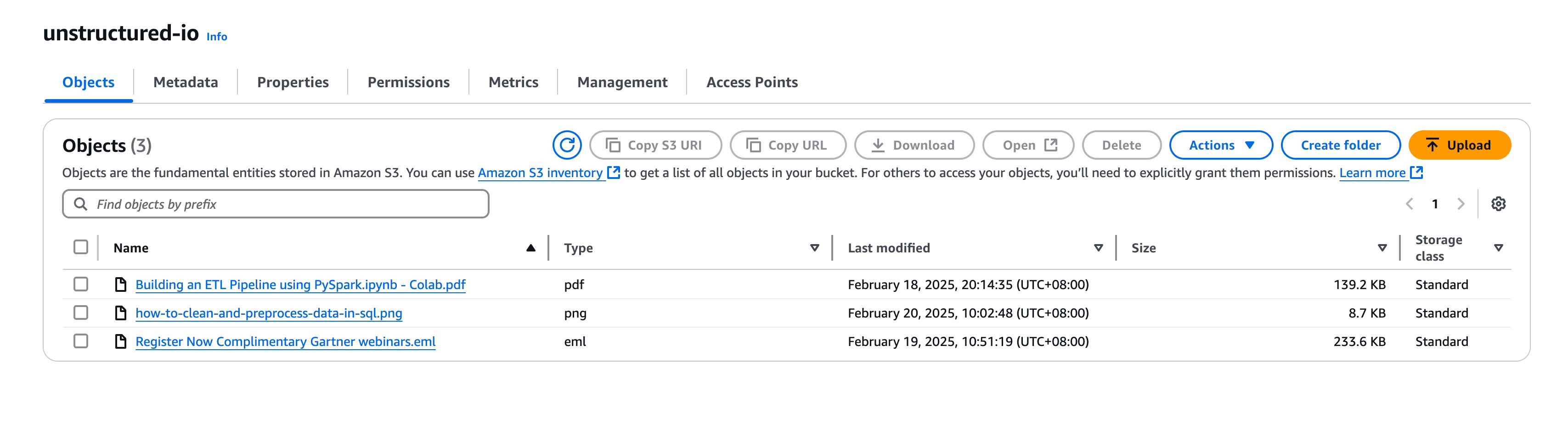
将非结构化数据放入AWS S3
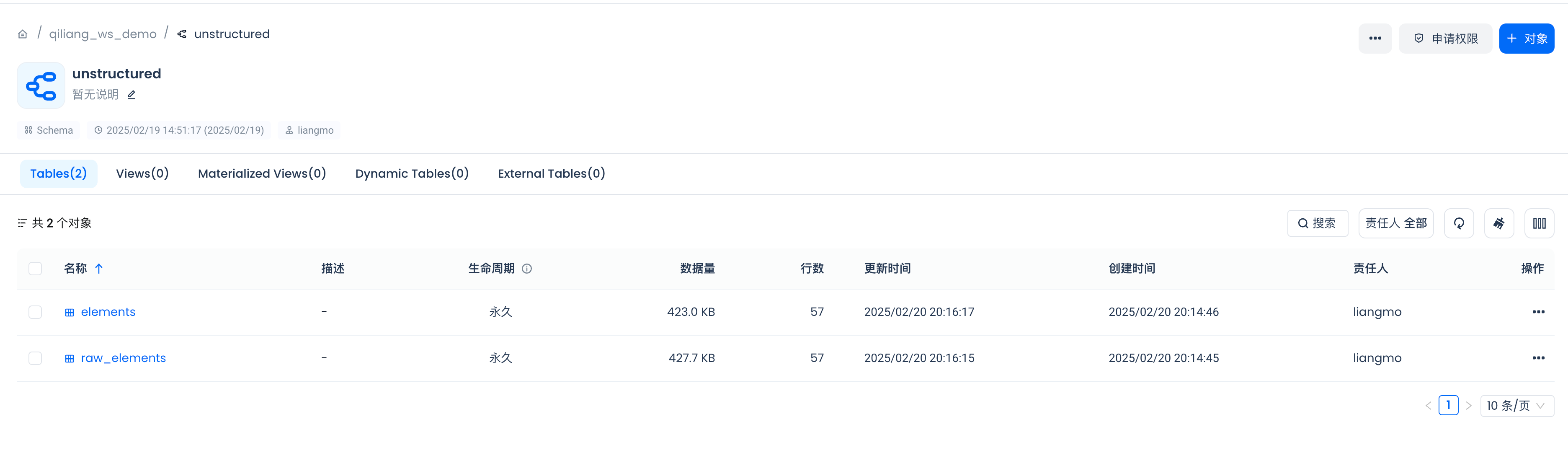
在Lakehouse中创建索引
在构建非结构化数据预处理管道之前,让我们先在Lakehouse中创建一个架构和一个表,用于存储处理后的数据。
有关架构的示例,请参阅非结构化文档。如果您将使用文档中的架构,请确保嵌入式的dims值与您选择使用的嵌入模型的维度数量相匹配。在此示例中,它设置为768,但您的嵌入模型可能会产生不同维度的向量。
# 定义用于在Lakehouse中存储数据的表名。
raw_table_name = "raw_elements"
silver_table_name = "elements"
embeddings_dimensions = 768
# 获取连接到Lakehouse的连接参数。
_username = os.getenv("cz_username")
_password = os.getenv("cz_password")
_service = os.getenv("cz_service")
_instance = os.getenv("cz_instance")
_workspace = os.getenv("cz_workspace")
_schema = os.getenv("cz_schema")
_vcluster = os.getenv("cz_vcluster")
Silver表旨在存储与文件和元素相关的各种元数据和内容。这两个索引优化了特定查询的性能:
倒排文本索引增强了全文检索功能,使得基于文本内容查找记录更加容易。
向量索引优化了向量数据的相似性搜索,这对于基于嵌入式数据比较和查找相似元素的任务非常有用。
对于RAG(检索增强生成)应用开发的好处:
增强搜索效率:通过支持倒排和向量搜索,此表允许RAG应用基于文本内容和语义相似性高效检索相关信息。这增强了模型查找和生成上下文相关响应的能力。
提高准确性:全文和相似性搜索的结合确保了RAG应用可以访问更广泛的相关数据,从而提高了生成内容的准确性和相关性。
可扩展性:借助优化的索引,该表可以处理大量数据并快速执行搜索,支持RAG应用的可扩展性需求。
简化架构:将倒排文本和向量搜索功能结合到一个表中,消除了对单独的文本和向量搜索数据库的需求。这简化了维护,减少了运营开销,并提高了开发效率。
数据一致性:将数据副本数量从三个减少到一个,提高了数据一致性,最小化了数据重复,并减少了数据同步和移动的需求。
总体而言,这些索引确保了对文本和嵌入式字段的搜索和检索高效进行,支持快速准确的查询结果,这对于开发有效且高效的RAG应用至关重要。
# 定义用于在Lakehouse中存储数据的架构。
raw_table_ddl = f"""
CREATE TABLE IF NOT EXISTS {_schema}.{raw_table_name} (
id STRING, -- 自动递增序列
record_locator STRING,
type STRING,
record_id STRING, -- 数据源的记录标识符(例如,连接器元数据中的记录定位器)
element_id STRING, -- 元素的唯一标识符(SHA-256或UUID)
filetype STRING, -- 文件类型(例如,PDF、DOCX、EML等)
file_directory STRING, -- 文件所在目录
filename STRING, -- 文件名
last_modified TIMESTAMP, -- 文件的最后修改时间
languages STRING, -- 文档语言,支持多种语言列表
page_number STRING, -- 页码(适用于PDF、DOCX等)
text STRING, -- 提取的文本内容
embeddings STRING, -- 向量数据
parent_id STRING, -- 父元素ID,用于表示元素层次结构
is_continuation BOOLEAN, -- 是否是前一个元素的延续(用于分块)
orig_elements STRING, -- JSON格式的原始元素(用于存储完整的元素结构)
element_type STRING, -- 元素类型(例如,叙述文本、标题、表格等)
coordinates STRING, -- 元素坐标(以JSONB格式存储)
link_texts STRING, -- 添加的字段:链接文本
link_urls STRING, -- 添加的字段:链接URL
email_message_id STRING, -- 添加的字段:电子邮件消息ID
sent_from STRING, -- 添加的字段:发件人
sent_to STRING, -- 添加的字段:收件人
subject STRING, -- 添加的字段:主题
url STRING, -- 添加的字段:URL
version STRING, -- 添加的字段:版本
date_created TIMESTAMP, -- 添加的字段:创建日期
date_modified TIMESTAMP, -- 添加的字段:修改日期
date_processed TIMESTAMP, -- 添加的字段:处理日期
text_as_html STRING, -- 添加的字段:HTML格式的文本
emphasized_text_contents STRING,
emphasized_text_tags STRING
);
"""
silver_table_ddl = f"""
CREATE TABLE IF NOT EXISTS {_schema}.{silver_table_name} (
id STRING, -- 自动递增序列
record_locator STRING,
type STRING,
record_id STRING, -- 数据源的记录标识符(例如,连接器元数据中的记录定位器)
element_id STRING, -- 元素的唯一标识符(SHA-256或UUID)
filetype STRING, -- 文件类型(例如,PDF、DOCX、EML等)
file_directory STRING, -- 文件所在目录
filename STRING, -- 文件名
last_modified TIMESTAMP, -- 文件的最后修改时间
languages STRING, -- 文档语言,支持多种语言列表
page_number STRING, -- 页码(适用于PDF、DOCX等)
text STRING, -- 提取的文本内容
embeddings vector({embeddings_dimensions}), -- 向量数据
parent_id STRING, -- 父元素ID,用于表示元素层次结构
is_continuation BOOLEAN, -- 是否是前一个元素的延续(用于分块)
orig_elements STRING, -- JSON格式的原始元素(用于存储完整的元素结构)
element_type STRING, -- 元素类型(例如,叙述文本、标题、表格等)
coordinates STRING, -- 元素坐标(以JSONB格式存储)
link_texts STRING, -- 添加的字段:链接文本
link_urls STRING, -- 添加的字段:链接URL
email_message_id STRING, -- 添加的字段:电子邮件消息ID
sent_from STRING, -- 添加的字段:发件人
sent_to STRING, -- 添加的字段:收件人
subject STRING, -- 添加的字段:主题
url STRING, -- 添加的字段:URL
version STRING, -- 添加的字段:版本
date_created TIMESTAMP, -- 添加的字段:创建日期
date_modified TIMESTAMP, -- 添加的字段:修改日期
date_processed TIMESTAMP, -- 添加的字段:处理日期
text_as_html STRING, -- 添加的字段:HTML格式的文本
emphasized_text_contents STRING,
emphasized_text_tags STRING,
INDEX inverted_text_index (text) INVERTED PROPERTIES('analyzer'='unicode'),
INDEX embeddings_vec_idx(embeddings) USING vector properties (
"scalar.type" = "f32",
"distance.function" = "l2_distance")
);
"""
clean_transformation_data_sql = f"""
INSERT INTO {_schema}.{silver_table_name}
SELECT
id,
record_locator,
type,
record_id,
element_id,
filetype,
file_directory,
filename,
last_modified,
languages,
page_number,
text,
CAST(embeddings AS VECTOR({embeddings_dimensions})) AS embeddings,
parent_id,
is_continuation,
orig_elements,
element_type,
coordinates,
link_texts,
link_urls,
email_message_id,
sent_from,
sent_to,
subject,
url,
version,
date_created,
date_modified,
date_processed,
text_as_html,
emphasized_text_contents,
emphasized_text_tags
FROM {_schema}.{raw_table_name};
"""
# 定义连接到Lakehouse的函数。
from clickzetta.connector import connect
import pandas as pd
def get_connection(password, username, service, instance, workspace, schema, vcluster):
connection = connect(
password=password,
username=username,
service=service,
instance=instance,
workspace=workspace,
schema=schema,
vcluster=vcluster)
return connection
# 创建连接到Lakehouse的连接。
conn = get_connection(password=_password, username=_username, service=_service, instance=_instance, workspace=_workspace, schema=_schema, vcluster=_vcluster)
# 执行SQL语句的函数
def excute_sql(conn,sql_statement: str):
with conn.cursor() as cur:
stmt = sql_statement
cur.execute(stmt)
results = cur.fetchall()
return results
if drop_tables:
excute_sql(conn,f"DROP TABLE IF EXISTS {_schema}.{raw_table_name}")
excute_sql(conn,f"DROP TABLE IF EXISTS {_schema}.{silver_table_name}")
# 在Lakehouse中创建表
excute_sql(conn, raw_table_ddl)
excute_sql(conn, silver_table_ddl)
创建数据库可能需要几秒钟。让我们检查状态。我们希望在开始写入之前确保它显示为healthy。
PDF/图像/邮件的摄取和预处理管道
非结构化摄取和转换管道由多个必要的配置编译而成。这些配置不必完全按照以下顺序。
-
ProcessorConfig:定义通用处理行为
-
S3IndexerConfig、S3DownloaderConfig、S3ConnectionConfig:控制从S3摄取数据,包括源位置和身份验证选项。
-
PartitionerConfig:描述分块行为。这里我们仅设置非结构化API的身份验证,但您也可以通过此配置控制分块参数,例如分块策略。
-
ChunkerConfig:定义分块策略和分块大小。
-
EmbedderConfig:设置连接到嵌入模型提供程序以生成数据块的嵌入。
-
ClickzettaConnectionConfig、ClickzettaUploadStagerConfig、ClickzettaUploaderConfig:控制管道的最后一步——将数据加载到Lakehouse RAW表中。
from unstructured_ingest.v2.interfaces import ProcessorConfig
from unstructured_ingest.v2.pipeline.pipeline import Pipeline
from unstructured_ingest.v2.processes.chunker import ChunkerConfig
from unstructured_ingest.v2.processes.connectors.fsspec.s3 import (
S3ConnectionConfig,
S3DownloaderConfig,
S3IndexerConfig,
S3AccessConfig,
)
from unstructured_ingest.v2.processes.embedder import EmbedderConfig
from unstructured_ingest.v2.processes.partitioner import PartitionerConfig
from unstructured_ingest.v2.processes.connectors.sql.clickzetta import (
ClickzettaConnectionConfig,
ClickzettaAccessConfig,
ClickzettaUploadStagerConfig,
ClickzettaUploaderConfig
)
pipeline = Pipeline.from_configs(
context=ProcessorConfig(
verbose=True,
tqdm=True,
num_processes=20,
),
indexer_config=S3IndexerConfig(remote_url=os.getenv("AWS_S3_NAME")),
downloader_config=S3DownloaderConfig(),
source_connection_config=S3ConnectionConfig(
access_config=S3AccessConfig(
key=os.getenv("AWS_KEY"),
secret=os.getenv("AWS_SECRET"))
),
partitioner_config=PartitionerConfig(
partition_by_api=True,
api_key=os.getenv("UNSTRUCTURED_API_KEY"),
partition_endpoint=os.getenv("UNSTRUCTURED_URL"),
),
chunker_config=ChunkerConfig(
chunking_strategy="by_title",
chunk_max_characters=512,
chunk_combine_text_under_n_chars=200,
),
embedder_config=EmbedderConfig(
embedding_provider="huggingface", # "langchain-huggingface" for ingest v<0.23
embedding_model_name="BAAI/bge-base-en-v1.5",
),
destination_connection_config=ClickzettaConnectionConfig(
access_config=ClickzettaAccessConfig(password=_password),
username=_username,
service=_service,
instance=_instance,
workspace=_workspace,
schema=_schema,
vcluster=_vcluster,
),
stager_config=ClickzettaUploadStagerConfig(),
uploader_config=ClickzettaUploaderConfig(table_name=raw_table_name),
)
pipeline.run()
清洗/转换RAW表并插入到Silver表
# 您可以在插入到Silver表之前执行更多SQL语句来清洗和转换数据。、
excute_sql(conn, clean_transformation_data_sql)
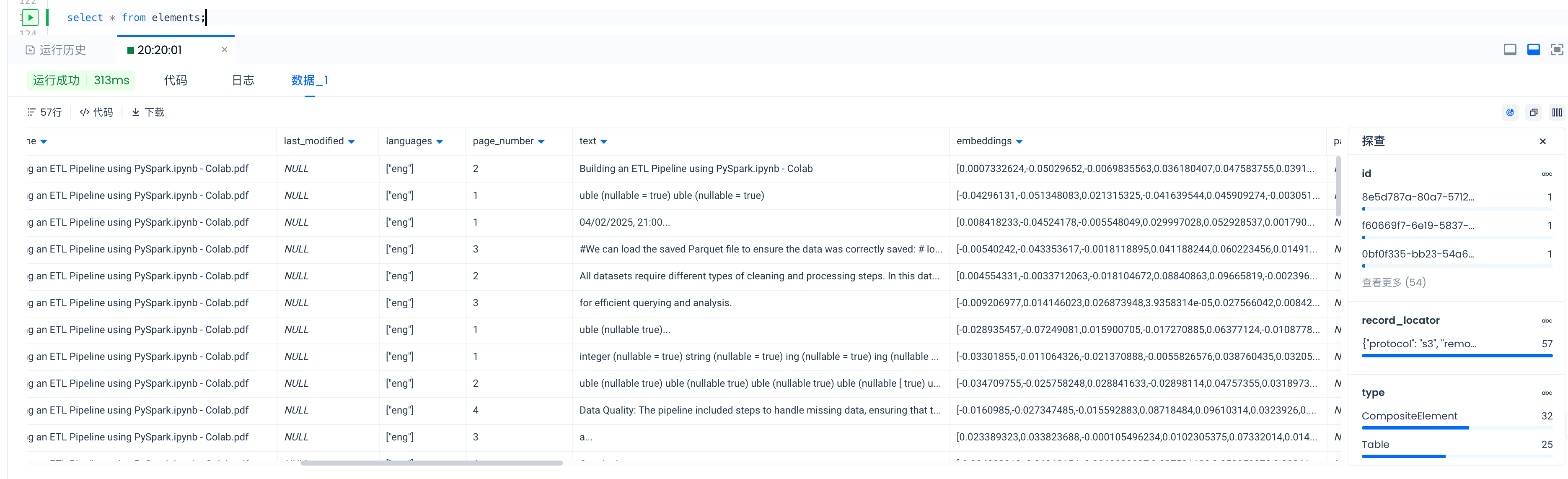
检查RAG数据就绪输出
让我们连接到Lakehouse。在上一个单元格的日志中,您可以查看在上传步骤中每个文档上传了多少个元素。
def get_rag_ready_data(conn, num_results: int = 5):
with conn.cursor() as cur:
stmt = f"""
SELECT
*
FROM {silver_table_name}
LIMIT {num_results}
"""
cur.execute(stmt)
results = cur.fetchall()
columns = [desc[0] for desc in cur.description] # 从游标描述中获取列名
rag_ready_data_df = pd.DataFrame(results, columns=columns)
return rag_ready_data_df
rag_ready_data_df = get_rag_ready_data(conn)
rag_ready_data_df

或者您可以通过Lakehouse Studio检查数据。
从Lakehouse检索相关文档
from sentence_transformers import SentenceTransformer
def get_embedding(query):
model = SentenceTransformer("BAAI/bge-base-en-v1.5")
return model.encode(query, normalize_embeddings=True)
def retrieve_documents(conn, query: str, num_results: int = 5):
embedding = get_embedding(query)
embedding_list = embedding.tolist()
embedding_json = json.dumps(embedding_list)
with conn.cursor() as cur:
stmt = f"""
WITH
vector_embedding_result AS (
SELECT
"vector_embedding" as retrieve_method,
record_locator,
type,
filename,
text,
orig_elements,
cosine_distance(embeddings, cast({embedding_list} as vector({embeddings_dimensions}))) AS score
FROM {silver_table_name}
ORDER BY score ASC
LIMIT {num_results}
)
SELECT * FROM vector_embedding_result
ORDER by score ASC;
"""
cur.execute(stmt)
results = cur.fetchall()
columns = [desc[0] for desc in cur.description] # 从游标描述中获取列名
df = pd.DataFrame(results, columns=columns)
return df
# query_text = "Harmon, Dave Scott, Bill Schmidt, Chris Teumer • Gain an action plan to hiring top IT talent • Understand how to best position yourself in the market to gain top talent • Learn why CIOs need to pay attention to hiring IT talent Register The Gartner 2025 Technology Adoption Roadmap for Infrastructure & Operations (I&O) Wednesday, February 19, 2025 EST: 10:00 a.m. | GMT: 15:00 Presented by: Ajeeta Malhotra and Amol Nadkarni • Discover why 66% of surveyed technologies are"
query_text = "What is gartner leadership vision for digital tech?"
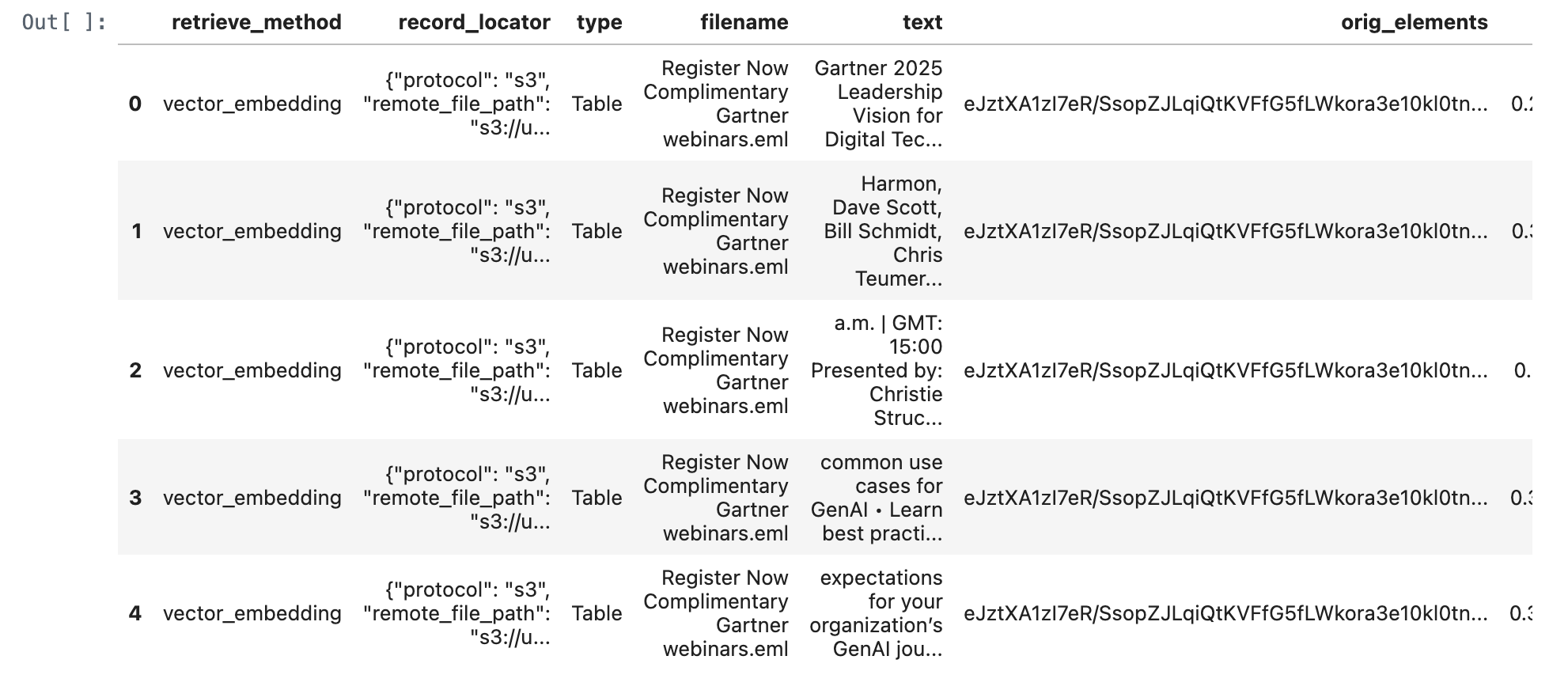
retrieve_documents_df = retrieve_documents(conn, query_text)
retrieve_documents_df
def match_all_documents(conn, query: str, num_results: int = 1):
with conn.cursor() as cur:
stmt = f"""
WITH
scalar_match_all_result AS (
SELECT
"scalar_match_all" as retrieve_method,
record_locator,
type,
filename,
text,
orig_elements,
-100 AS score
FROM {silver_table_name}
WHERE match_all(
text,
"{query}",
map("analyzer", "unicode")
)
ORDER BY score ASC
LIMIT {num_results}
)
SELECT * FROM scalar_match_all_result
ORDER by score ASC;
"""
cur.execute(stmt)
results = cur.fetchall()
columns = [desc[0] for desc in cur.description] # 从游标描述中获取列名
df = pd.DataFrame(results, columns=columns)
return df
match_all_documents_df = match_all_documents(conn,query_text)
match_all_documents_df
def match_any_documents(conn, query: str, num_results: int = 5):
with conn.cursor() as cur:
stmt = f"""
WITH
scalar_match_any_result AS (
SELECT
"scalar_match_any" as retrieve_method,
record_locator,
type,
filename,
text,
orig_elements,
0 AS score
FROM {silver_table_name}
WHERE match_any(
text,
"{query}",
map("analyzer", "unicode")
)
ORDER BY score ASC
LIMIT {num_results}
)
SELECT * FROM scalar_match_any_result
ORDER by score ASC;
"""
cur.execute(stmt)
results = cur.fetchall()
columns = [desc[0] for desc in cur.description] # 从游标描述中获取列名
df = pd.DataFrame(results, columns=columns)
return df
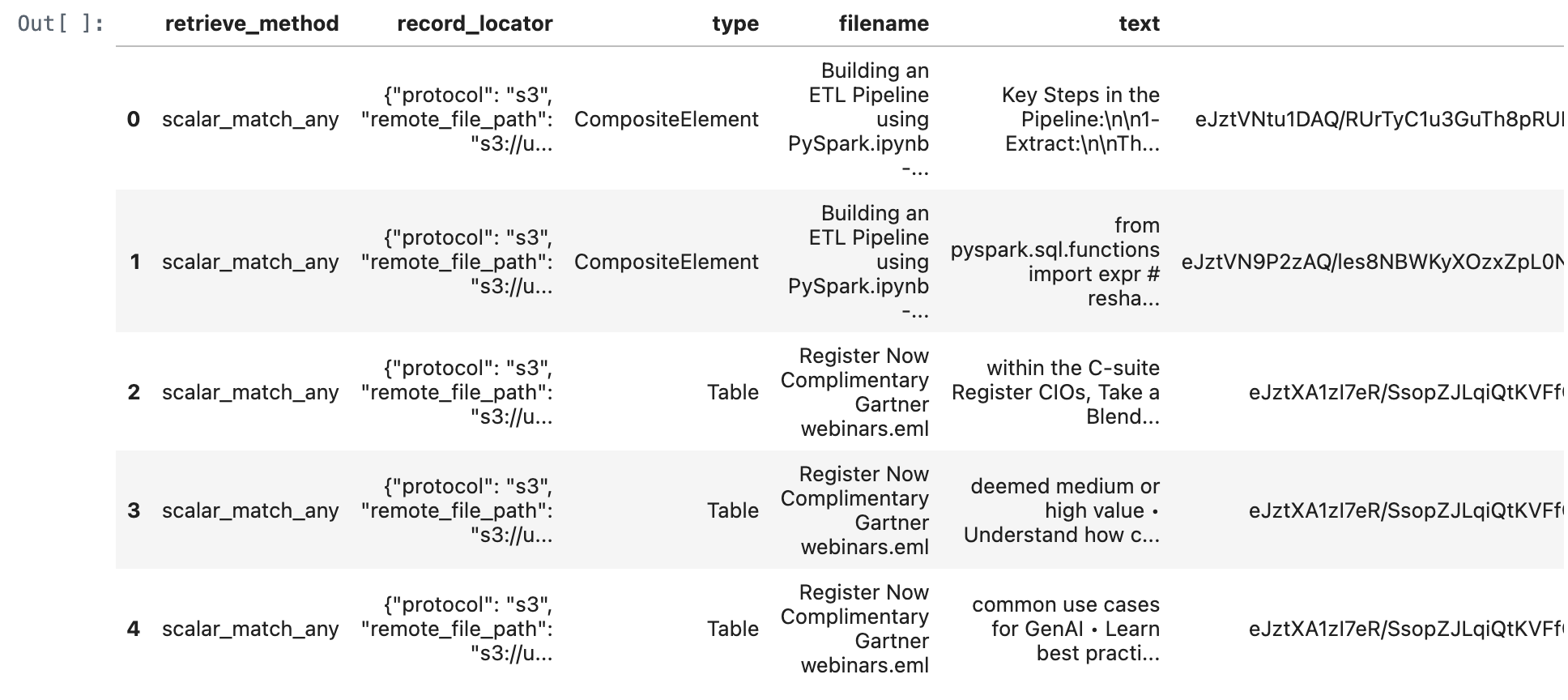
match_any_documents_df = match_any_documents(conn,query_text)
match_any_documents_df
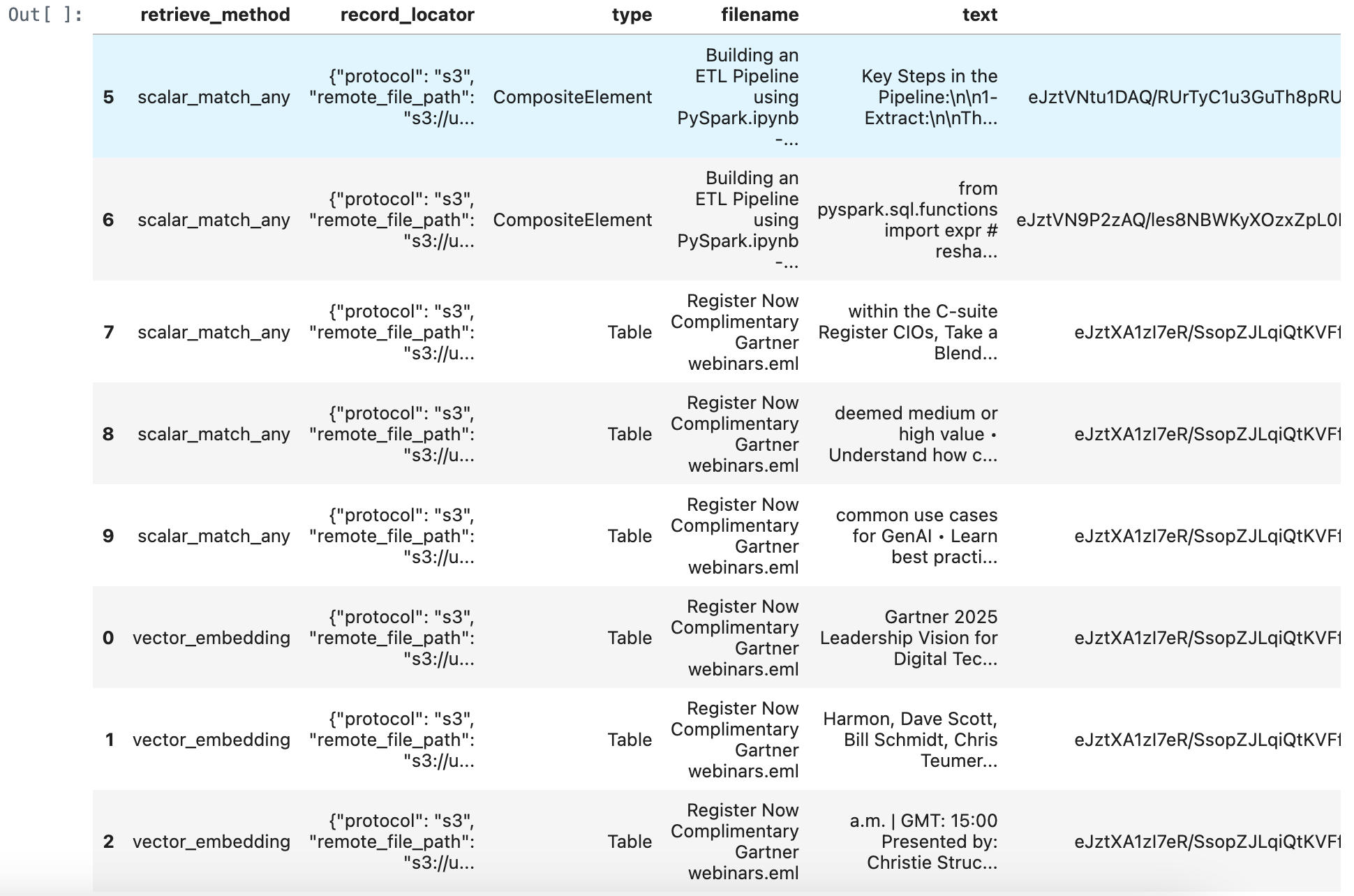
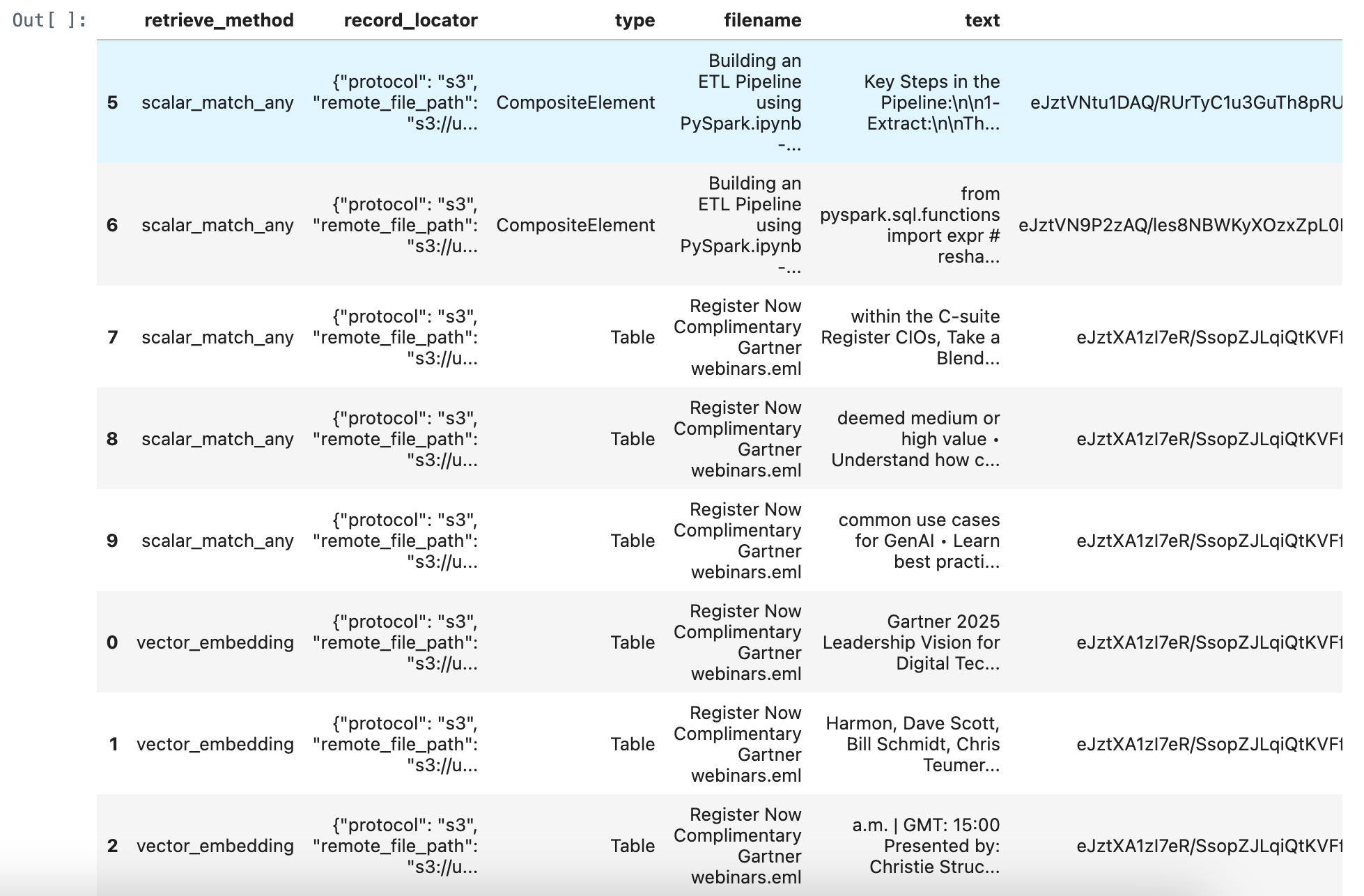
merged_df = pd.concat([retrieve_documents_df, match_all_documents_df, match_any_documents_df], ignore_index=True)
merged_df = merged_df.sort_values(by='score', ascending=True)
merged_df
import pandas as pd
import torch
import numpy as np
from transformers import AutoModelForSequenceClassification, AutoTokenizer
# 定义重新排序函数
def rerank_texts(query, texts, model_name="BAAI/bge-reranker-v2-m3", normalize=True):
"""
基于指定的重新排序模型,根据与给定查询的相关性重新排序文本列表。
参数:
- query: 查询字符串。
- texts: 要重新排序的文本列表。
- model_name: 要使用的重新排序模型名称。
- normalize: 是否使用sigmoid函数将分数归一化到[0, 1]范围。
返回:
- 重新排序的文本列表。
- 对应的分数列表。
"""
# 加载模型和分词器
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
model.eval()
# 准备输入对 [query, text]
pairs = [[query, text] for text in texts]
inputs = tokenizer(pairs, padding=True, truncation=True, return_tensors="pt", max_length=512)
inputs = {key: value.to(device) for key, value in inputs.items()}
# 获取相关性分数
with torch.no_grad():
outputs = model(**inputs)
scores = outputs.logits.view(-1).cpu().numpy()
# 如果需要,将分数归一化到 [0, 1]
if normalize:
scores = 1 / (1 + np.exp(-scores))
# 将文本与分数结合并按分数降序排序
scored_texts = list(zip(texts, scores))
scored_texts.sort(key=lambda x: x[1], reverse=True)
# 分离排序后的文本和分数
sorted_texts, sorted_scores = zip(*scored_texts)
return list(sorted_texts), list(sorted_scores)
# 示例用法
# query = "Which session is presented by Ajeeta Malhotra and Amol Nadkarni?"
query = "What is gartner leadership vision for digital tech?"
sorted_texts, sorted_scores = rerank_texts(query, merged_df["text"].tolist())
# 更新DataFrame,添加重新排序的文本和分数
merged_df["reranked_text"] = sorted_texts
merged_df["rerank_score"] = sorted_scores
# 获取DataFrame的第一行,该行具有最高的重新排序分数
first_row_reranked_text = merged_df.iloc[0]['reranked_text']
print(first_row_reranked_text)
Gartner 2025 Leadership Vision for Digital Technology and Business Services Wednesday, February 19, 2025 EST: 11:00 a.m. | GMT: 16:00 Presented by: Chrissy Healey, Scott Frederick and Jennifer Barry • Revert back to growth by defining and delivering transformative impact • Resolve the asset and AI-first dilemma in delivery • Decode demand in your top accounts Register How U.S. Government Executives Can Navigate Upcoming Workforce Changes Friday, February 21, 2025 EDT: 10:00
为RAG应用开发总结优势
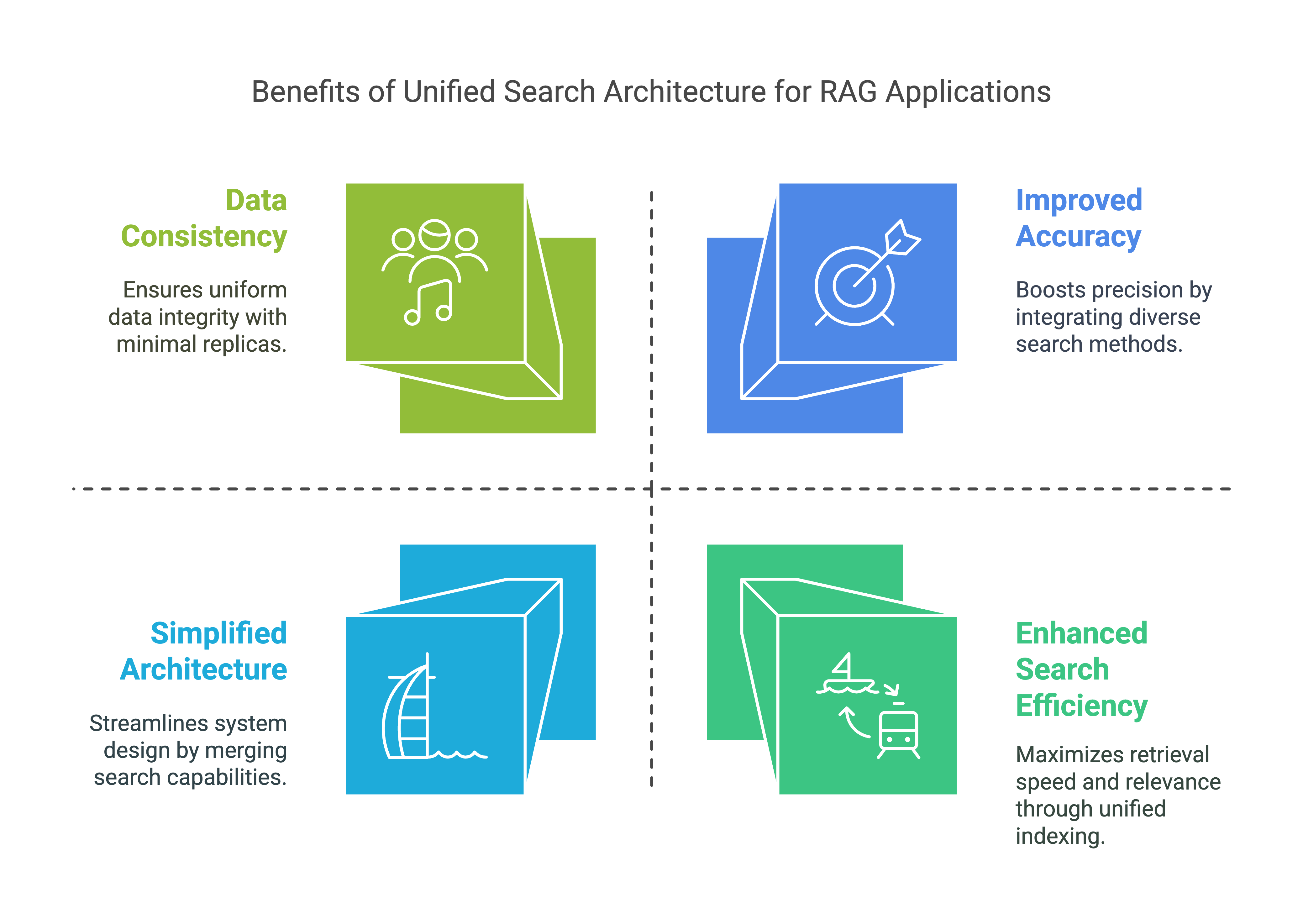
增强搜索效率:
- 通过支持倒排和向量搜索,此表允许RAG应用基于文本内容和语义相似性高效检索相关信息。这增强了模型查找和生成上下文相关响应的能力。
提高准确性:
- 全文和相似性搜索的结合确保了RAG应用可以访问更广泛的相关数据,从而提高了生成内容的准确性和相关性。
可扩展性:
- 借助优化的索引,该表可以处理大量数据并快速执行搜索,支持RAG应用的可扩展性需求。
简化架构:
- 将倒排文本和向量搜索功能结合到一个表中,消除了对单独的文本和向量搜索数据库的需求。这简化了维护,减少了运营开销,并提高了开发效率。
数据一致性:
- 将数据副本数量从三个减少到一个,提高了数据一致性,最小化了数据重复,并减少了数据同步和移动的需求。
总体而言,这种Lakehouse架构减少了运营复杂性,提高了数据一致性,并提高了开发效率,非常适合有效的RAG应用开发。
附录:
您也可以通过访问 github 查看本实践教程。
