分析型集群规划配置及使用实践
分析场景需求
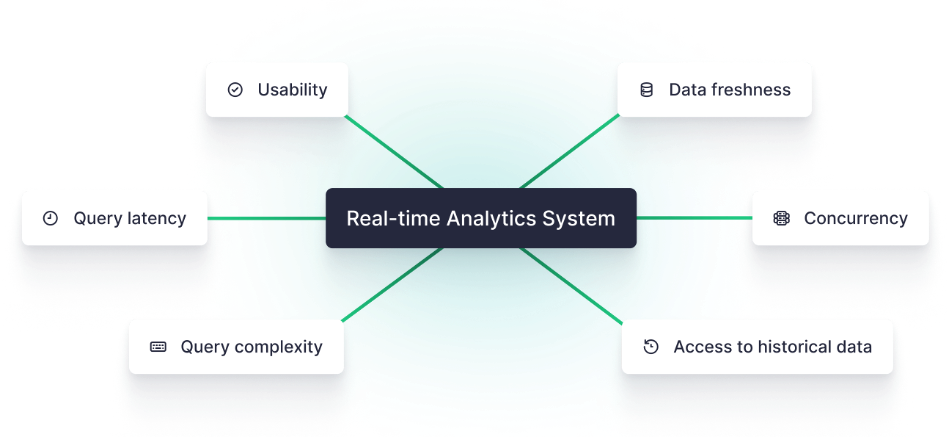
• 数据新鲜度:实时采集和处理快速变化的数据
• 低延迟查询:提供秒级、亚秒级查询延迟,保障 SLA
• 支持复杂查询:满足不同业务逻辑、数据规模的分析要求
• 高并发:面向最终用户的多并发
• 历史明细查询:支持明细级别实时历史对比、历史检索及探查分析
云器Lakehouse在分析场景方面的产品能力
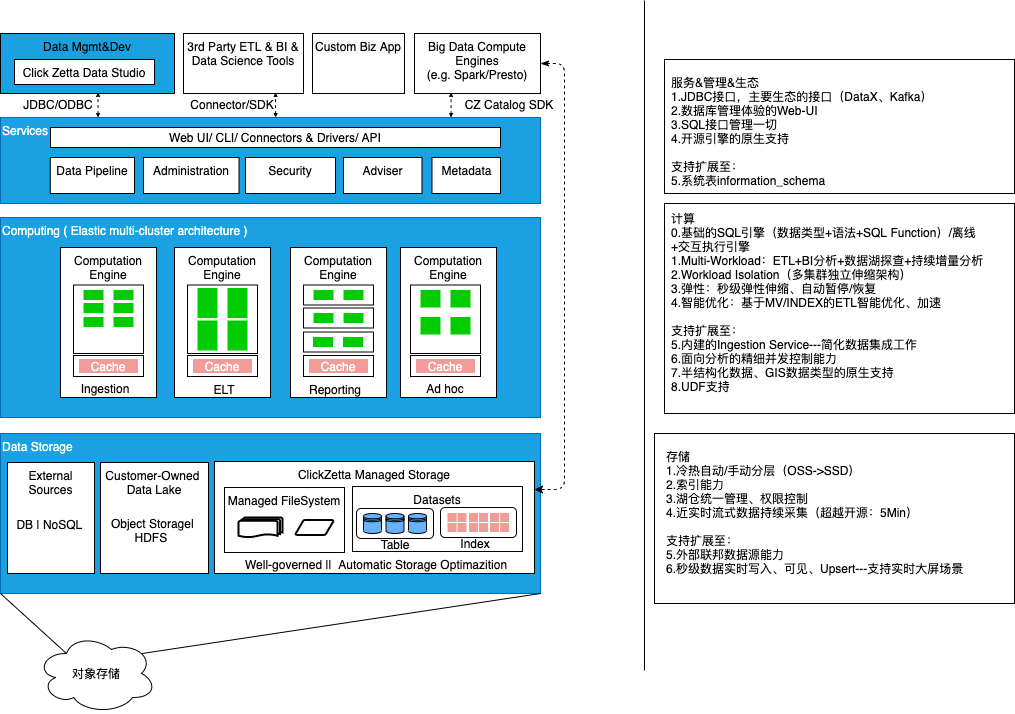
| 分类 | 产品能力 | 适应场景 |
|---|---|---|
| 存储 | 列式存储 | 绝大部分ETL、OLAP分析场景 |
| Local Cache | Local Cache由计算资源Virtual Cluster本地SSD提供,数据I/O加速 | |
| Cache策略:LRU、Preload Cache | LRU:根据Query识别热数据自动cache;Preload Cache:根据分析人员设定固定范围的数据对象,无需Query触发、系统主动对新数据进行增量Cache,保障SLA | |
| 数据Layout | 分区 | 存在按时间连续写入的大规模表 |
| 分桶+系统Compaction服务自动re-clustering保持新数据的分桶聚集 | 根据cluster key条件过滤,ETL+BI场景下常用 | |
| SORT | 提高sort key的条件过滤效率,在BI分析场景下常用 | |
| 轻量Index:bloomfilter index | 指定Key的点查过滤,可以和Cluster key组合使用,在BI分析场景下常用 | |
| 导入/导出 | COPY命令 | 基于文件方式批量导出、导入 |
| 实时摄取服务Ingestion Service | 提供实时写入API,支持Append/Upsert实时写入,面向要求数据新鲜度场景 | |
| 计算 | CZ SQL Engine提供2种不同负载优化的执行模式:ETL DAG执行优化、MPP+Pipeline分析执行优化模式 | 通过Virtual Cluster的不同类型区别使用:通用型(General Purpose)、分析型(Anaytics) |
| 用户接口 | Studio Web-UI | Ad-hoc分析、数据加工任务 |
| JDBC | 对接广泛的BI/客户端工具生态 | |
| SQL Alchemy/Java SDK/Go SDK | Python、Java、Go编程接口 |
合理规划和使用Virtual Cluster
本章节将介绍ClickZetta Lakehouse弹性计算资源的产品特性及规划使用的方法。
Virtual Cluster特性介绍
计算集群(Virtual Cluster,简称:VC)是ClickZetta Lakehouse提供的计算资源集群服务。计算集群提供在Lakehouse中执行查询分析所需的CPU、内存、本地临时存储(SSD介质)等资源。这三种资源被捆绑到称为Lakehouse计算单元的计算规模单元中。 CRU 作为计算资源大小和性能的抽象、规范化的度量单位。
ClickZetta Lakehouse根据不同规格计算资源的实际使用时长(秒粒度计算时长)进行计量,不同规格的CUR以及计量单价如下:
| Lakehouse Virtual Cluster规格 | CRU*时 | MAX_CONCURRENCY默认值 |
|---|---|---|
| 1 | 1 | 8 |
| 2 | 2 | 8 |
| 4 | 4 | 8 |
| 8 | 8 | 8 |
| 16 | 16 | 8 |
| 32 | 32 | 8 |
| 64 | 64 | 8 |
| 128 | 128 | 8 |
| 256 | 256 | 8 |
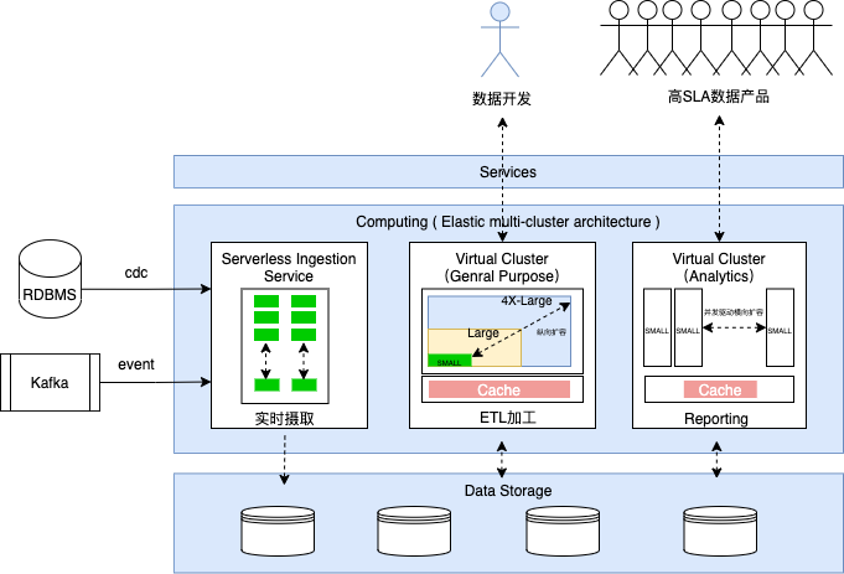
ClickZetta Lakehouse支持纵向和横向2个维度的计算资源弹性伸缩:
- 纵向:通过修改Virtual Cluster的规格大小调整CRU数量,提升或降低指定集群的算力和性能
- 横向:通过修改集群的Replica数量,扩大或减少Cluster副本数调整并发查询能力。
根据负载规划计算资源数量和大小
计算资源使用最佳实践原则
-
通过多计算资源实现负载隔离
- 使用多个独立的Virtual Cluster支撑不同业务(Workload)。可根据周期性ETL、线上业务报表、分析师数据分析等不同需求,创建不同的计算资源并分配给不同的用户或应用使用,避免不同业务或人员资源争抢导致的SLA下降。
-
合理设置自动暂停时长
-
Lakehouse的计算资源具备IDLE闲置时自动暂停、作业发起时自动拉起、按实际资源使用时长计费(暂停阶段不计费)的特性,通过AUTO_SUSPEND_IN_SECOND参数可以设置,默认为600秒无查询时自动暂停。
-
不同场景的建议(考虑数据Cache和资源Resume时间2个维度)
- 低频使用Ad-hoc查询或ETL作业,AUTO_SUSPEND_IN_SECOND为1Min左右。
- 高频分析场景,AUTO_SUSPEND_IN_SECOND=10Min以上,保持分析依赖的数据始终在Cache当中,同时避免频繁VC启停带来的Latency下降。
-
-
根据负载类型选择Virtual Cluster的资源类型
- 通用型集群(VCLUSTER_TYPE=GENERAL) 可对于分析场景的并发和作业时效性保障要求不强情况下,可以完成分析引擎所做的所有事情。为批处理Workload优化,吞吐优先、支持资源争抢&共享,适用于ELT、数据导入(如外表读取及写入)、Ad-hoc查询等场景。
- 分析型集群(VCLUSTER_TYPE=ANALYTICS) 支持指定作业并发数的分析引擎。适用于对查询Latency和并发能力有强保障的场景,如Reporting、Dashboard、关键业务的数据产品。
- 同步型集群(VCLUSTER_TYPE=INTEGRATION)适用于处理离线集成和实时集成任务。多个集成任务可共用一个同步型计算集群实例。超出集群计算能力的集成任务将进入队列排队。
-
使用弹性并发能力支持关键数据应用
{kind=link}
Lakehouse Virtual Cluster不同场景的容量设计建议
当前ClickZetta Lakehouse支持的主要业务场景的业务特点如下:
| 场景/工作负载 | 场景需求 | 资源需求需求 | 数据规模及查询时延需求 | Query特点 | 并发特点 |
|---|---|---|---|---|---|
| 固定报表 | 多并发,稳定的低时延 | 小+弹性扩缩 | •小,查询GB规模 •如 TP95 <3秒 | 针对加工好的数据,逻辑简单、模式固定 | 面向广泛的一线人员,10~100或更大 |
| Ad-hc | 明细数据支持交互式探查、分析 | 中 | •中,100GB~10TB •大部分查询期望10秒内,对复杂查询的时延有容忍度 | 逻辑较复杂 | 面向专业分析人员,较少 (与组织规模相关) |
| ETL | 按计划稳定产出 成本敏感,控制成本 突发状况下有弹性需求(如补数、临时出数) | 大 | •大,TB~PB+级别 •小时级,产出完成时间有SLA需求 | 逻辑复杂 加工型:进多出多 | 低,单用户的多任务 接受作业常态化挤压排队 |
Virtual Cluster资源规格设计参考
本文计划从业务负载类型、执行频率、作业并发、处理数据规模、SLA要求几个维度提供样例的资源规格设计,供参考使用。
- 负载类型:包括ETL、Ad-hoc、Reporting、实时分析(Operational Analytics等不同特点的数仓工作负载
- 执行频率: 相关负载执行周期
- 并发:需要在同时间执行的作业数量
- 数据处理规模: 单作业平均扫描的数据量大小
- 作业时延SLA: 业务上预期的任务交付时间
示例:
| 业务场景 | 负载类型 | 执行频率 | 作业并发 | 处理数据规模 | VCluster类型 | 作业时延SLA | VCluster Name | VCluster Size(CRU) |
|---|---|---|---|---|---|---|---|---|
| ETL调度作业 | 近实时离线处理 | 小时 | 1 | 1 TB | 通用型 | 15 Min | etl_vc_hourly | 4 |
| T+1离线处理 | 天 | 1 | 10 TB | 通用型 | 4 Hours | etl_vc_daily | 16 | |
| Tableau/FineBI | Ad-Hoc Analytics | Ad hoc | 8 | 1 TB | 通用型 | <1 MinTP90:<5s | analytics_vc | 16 |
| 数据应用产品 | Applications | On demand | 8 | 100 GB | 分析型 | <3秒 | application_vc | 4 |
| On demand | 96 | 100 MB | 分析型 | <3秒 | application_vc | 4 | ||
| ClickZetta Web-UI<数据开发测试> | Ad-Hoc Analytics | Ad hoc | 8 | 3 TB | 通用型 | < 1 MinTP90:<15 s | analytics_vc(可与分析师BI探查共用) | 16 |
注:以上示例仅做参考示意。实际业务环境下,受Query的复杂度、数据模型(分区、分桶)、Cache命中情况等多种因素影响,应以实际业务的运行结果作为基准进行资源规划。
依据并发需求配置虚拟计算资源实践
云器Lakehouse分析型虚拟计算集群(Virtual Cluster)适用于Ad-hoc、多并发固定报表、实时分析等对于查询时延有较高要求的场景。分析型虚拟计算集群提供以下配置选项:
| 配置选项 | 说明 |
|---|---|
| 规格 | 虚拟集群内计算资源实例大小。规格范围从XS~5XLarge,规格增加一级,算力资源增加一倍。 |
| 类型 | 通用型或分析型,此处我们使用分析型。 |
| 最大并发数 | 单个计算资源实例支持的并发查询,超过单实例最大并发数时,新的查询将排队或分配到虚拟集群内的其他计算资源实例。 |
| 实例最小值 | 虚拟集群初始启动时集群实例数量,默认为1。 |
| 实例最大值 | 虚拟集群可以使用的最大实例数量。当实例最大值>实例最小值时,意味着根据虚拟集群接收到的并发数量是否超过所有计算实例的总最大并发数决定是否自动横向扩展新的计算实例,直到当前实例数量=实例最大值。 |
| 当前实例数量 | 虚拟集群当前使用的实例数量。 |
下图描述了分析型虚拟集群相关参数间的关系:
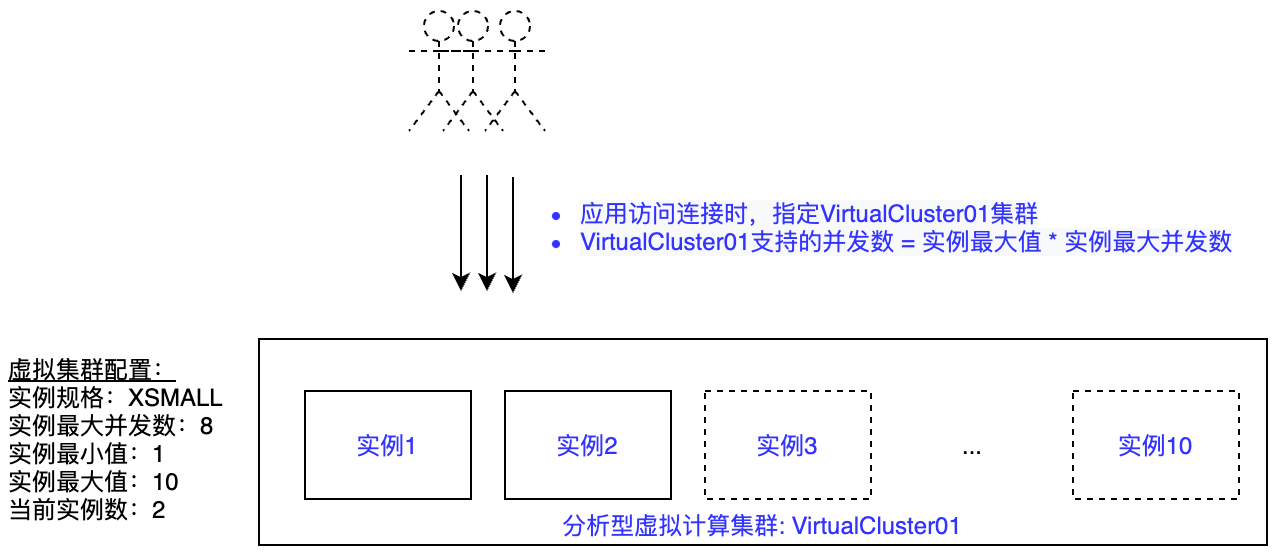
垂直伸缩:其中实例规格是对虚拟集群进行垂直伸缩的选项,调整实例规格可以让单个作业获得更大的算力以提升作业性能。
横向伸缩:以提高集群并发能力为目标的弹性能力。分析型集群面向横向伸缩场景,提供了单集群内多实例的架构设计。每个分析型集群通过设置实例最小值、实例最大值定义集群初始实例数量以及横向扩容的上限。
在实际的业务场景中,对于面向用户的数据产品往往有SLA的要求,如100并发下P99的查询延迟小于2秒。同时,也希望计算资源得到充分的利用,在满足业务需求的前提下尽可能降低资源成本。如下图所示:
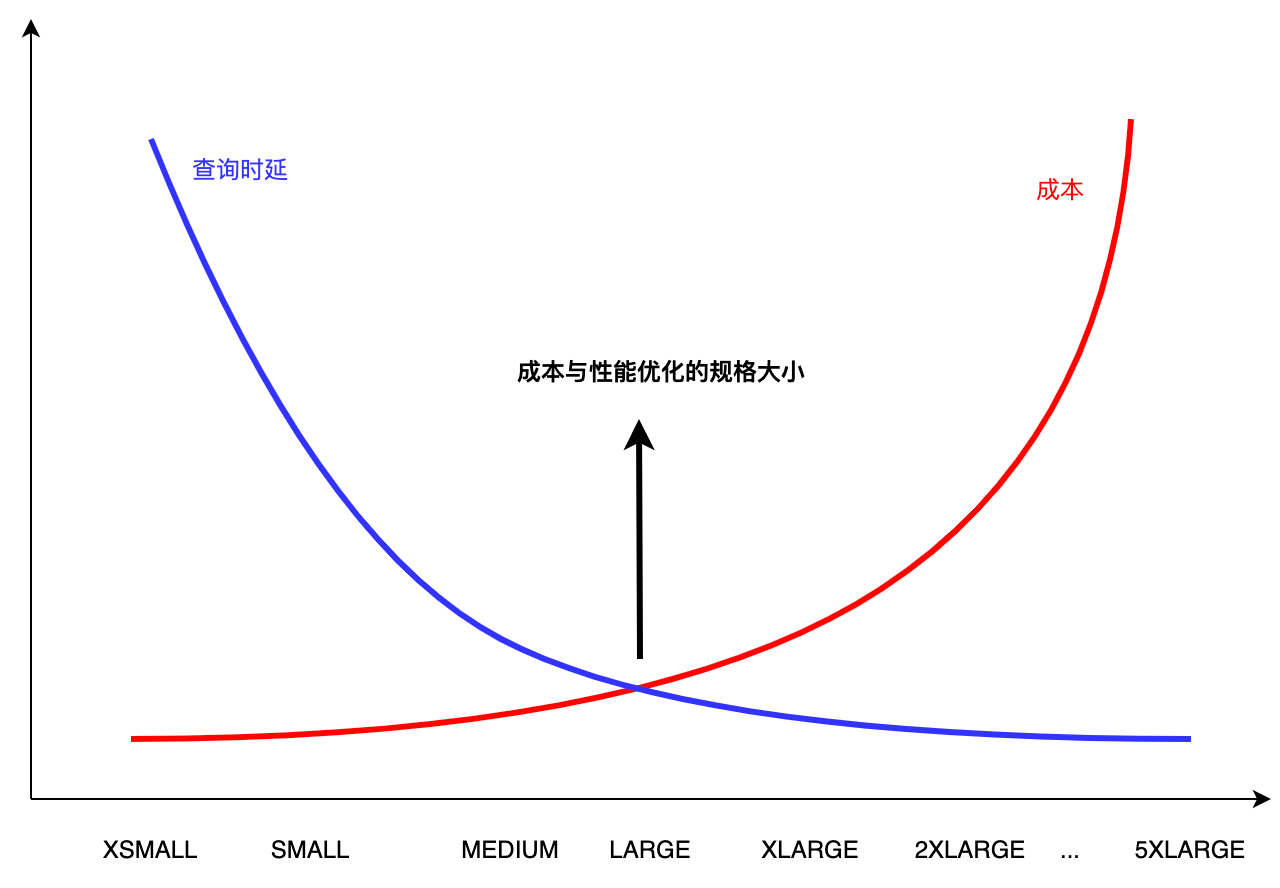
在特定的业务场景下,我们希望能够找到性能满足SLA要求的最小资源需求。本文从实践角度,结合示例场景通过以下几个步骤工作来确定合理的资源规格配置。
场景示例
数据平台加工后的数据包装称为数据产品(如Dashboard),对外支撑最大20用户并发查询,其中单个用户每次数据产品请求平均产生8个数据平台查询(平均每个Dashboard 8个指标),相当于对数据平台有160个并发查询。要求P99查询延迟小于1.5秒。
数据查询具备以下特点:
- Dashboard查询使用数据集大小:1GB左右。
- Dashboard查询的特点:以点查、过滤、聚合为主,无JOIN。
本文使用SSB FLAG 1G的数据集和查询语句来模拟上述场景,用于验证并发查询下的集群配置及效果。
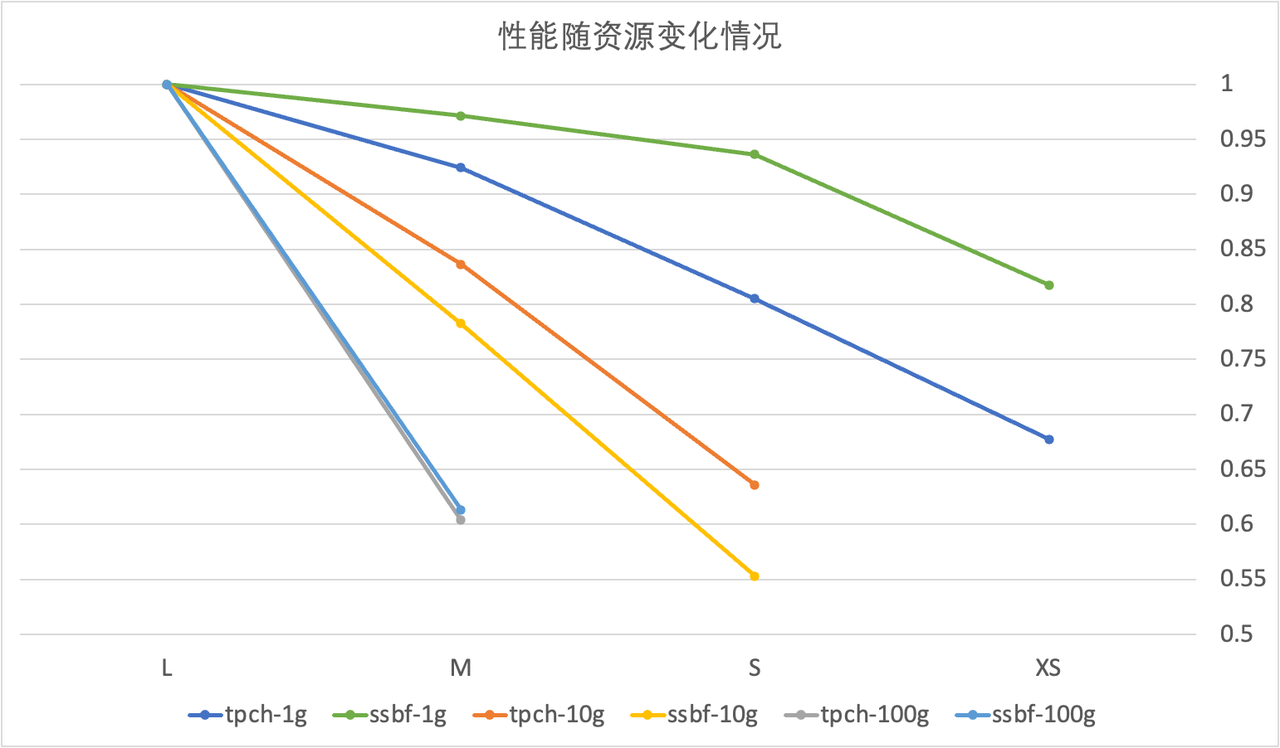
第1步:找到性能、成本平衡的单实例规格大小
- 使用不同SIZE的集群规格运行查询(如本文使用从Large->XSMALL几种规格分别进行了测试),找到资源规格尽可能小、同时性能下降不明显的资源规格。
根据下图所示,SSBF-1G的benchmark在XSMALL规格时仍然保持了Large的80%以上性能表现。这里选择XSMALL规格来支持数据产品。
注:根据测试结果,建议 100G数据规模默认使用 Large大小,10G 使用 Medium,1G 对应 Small或XSmall。
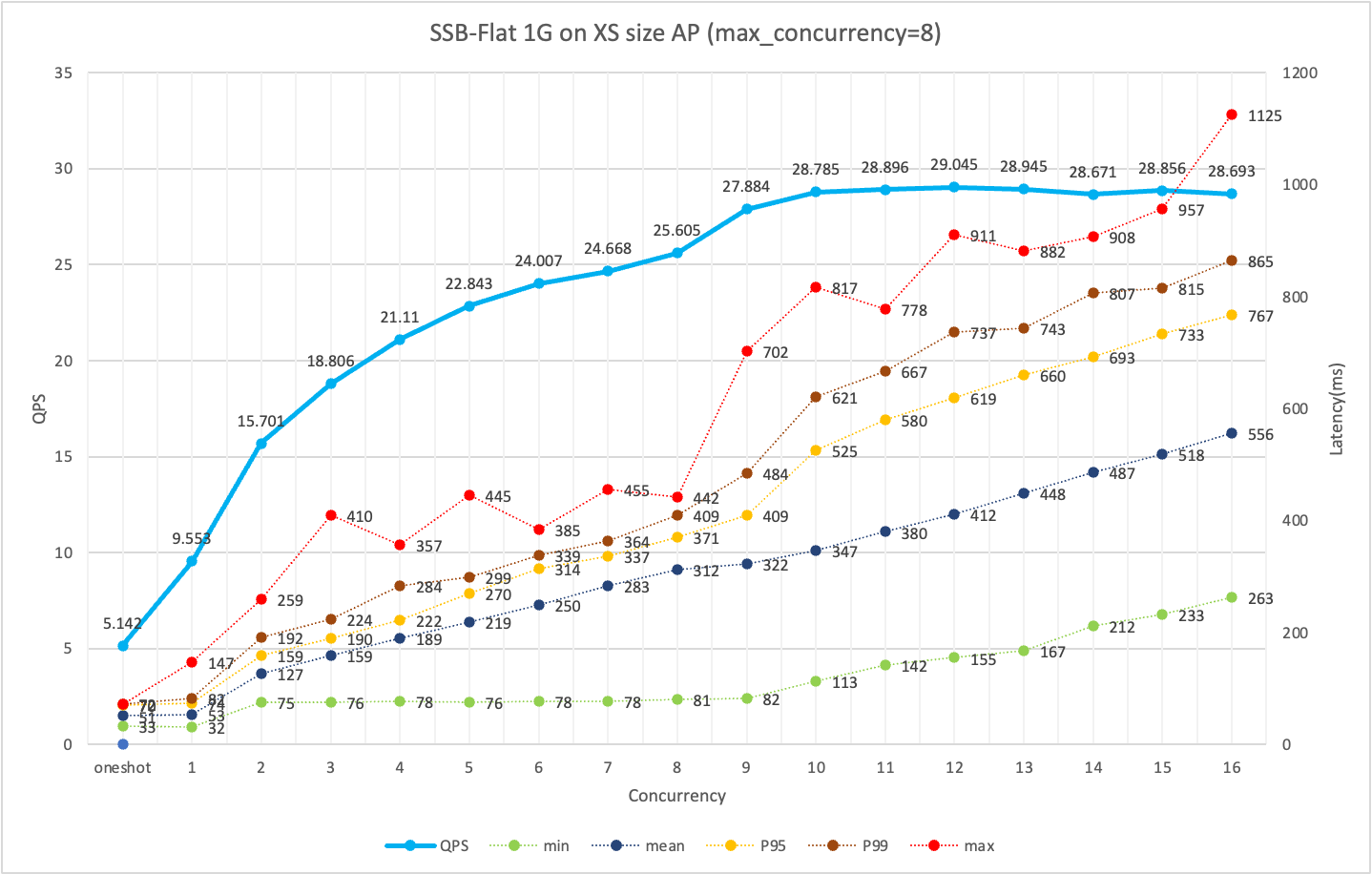
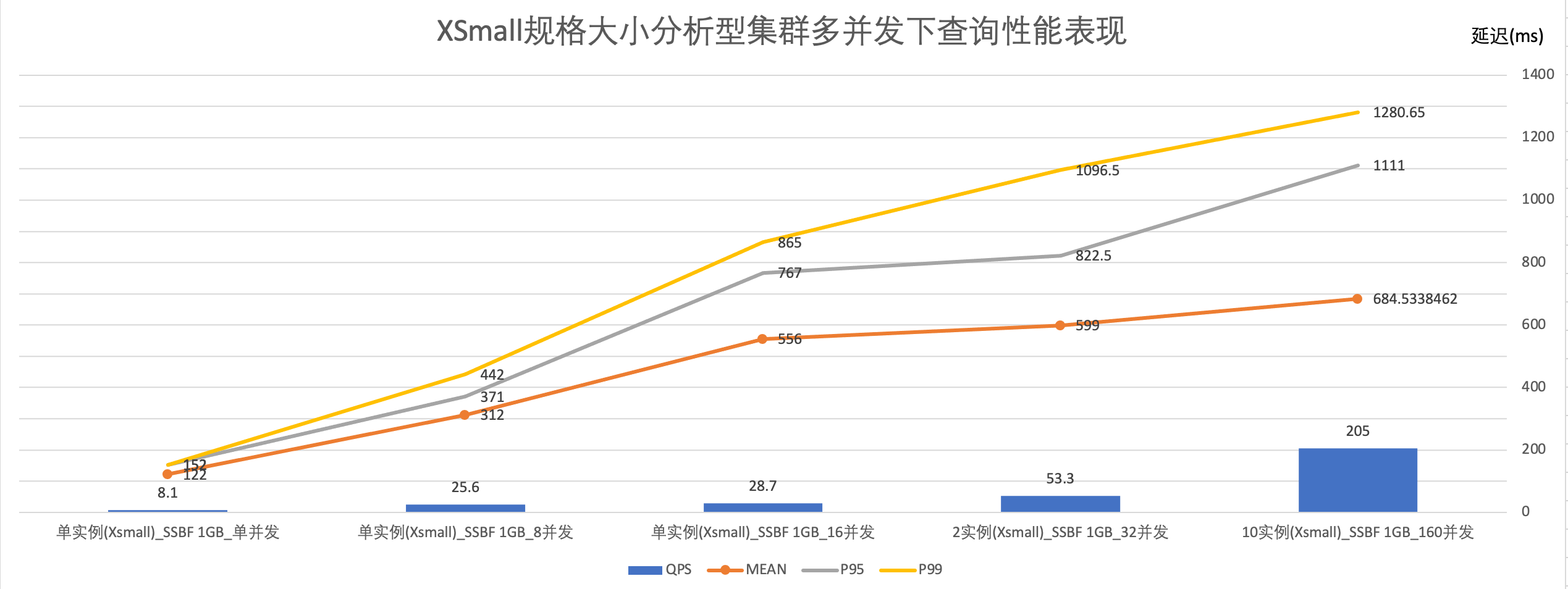
第2步:测试单实例下在多大并发下,有较好的查询SLA、QPS
如下图所示,使用XSMALL规格集群,在8并发请求下,QPS较高、P95/P99查询表现好。
第3步:通过横向扩容,找到同时满足SLA和业务实际并发需求的最大实例数
根据前文介绍,一个集群能够支持的并发数= 实例最大值 * 实例最大并发数。原则上,单实例规格大小确定后,横向扩展的实例具备同样的查询SLA和QPS。
结合测试数据,本文将使用XSMALL规格,最大实例数=10的虚拟集群,可以满足160并发的查询需要。查询响应时长P95=1111毫秒,P99=1280.65毫秒。
小结
本节以小规模数据集上的多并发简单查询场景为例,介绍了如何合理设置云器Lakehouse的虚拟计算集群规格大小及相关参数以满足SLA需求。
为简化这个参考过程,以下根据测试信息给出一些经验值供参考。
| 负载类型 | 数据规模 | VC实例SIZE(CRU) | 单实例QPS参考 | 场景举例 |
|---|---|---|---|---|
| 固定报表/Serving查询(简单过滤或聚合为主) | 1GB | 1 | 25 | 需求示例:1.结果数据在10GB规模2.查询分析为简单的过滤或聚合3.SLA要求支持200 Query并发能力4.平均响应时长:1秒集群配置方案示例:1.分析型VC,SIZE选择Medium规格大小2.按照单Medium在10GB数据简单查询有20的QPS,推算10个实例可以提供200QPS,因此最大实例数设置为10。 |
| 10GB | 4 | 20 | ||
| 100GB | 8 | <10 | ||
| Ad-hoc/BI动态生成报表(有关联分析、复杂计算) | 1GB | 2 | 15 | |
| 1GB | 4 | 25 | ||
| 100GB | 16 | <10 |
使用Preload Cache机制提升关键业务查询稳定性
Preload工作机制及适用场景
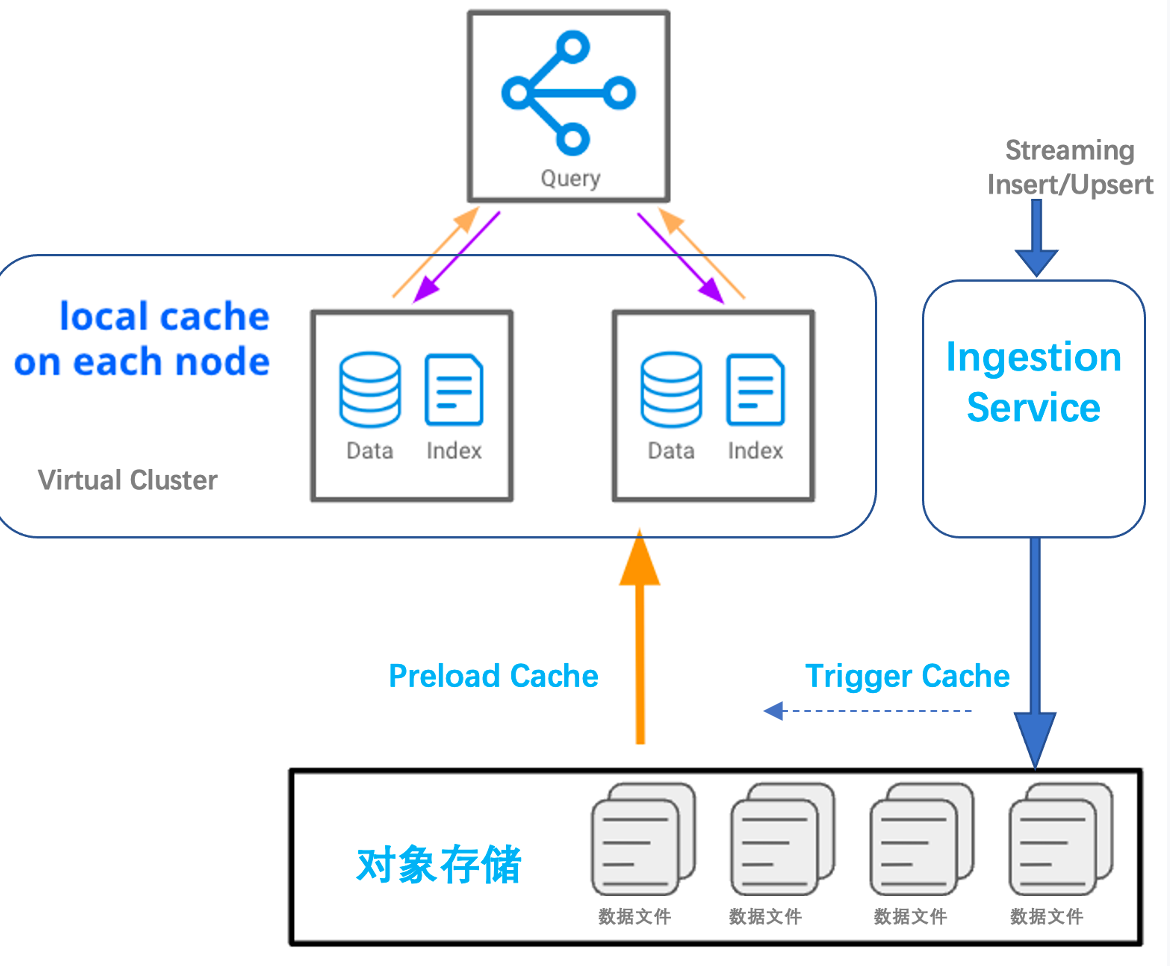
适合的使用场景
• 存量数据随计算资源主动Cache,避免历史数据首次访问的Latency
• 实时数据写入触发Cache,减少新数据写入落盘后,查询Latency抖动
使用方法
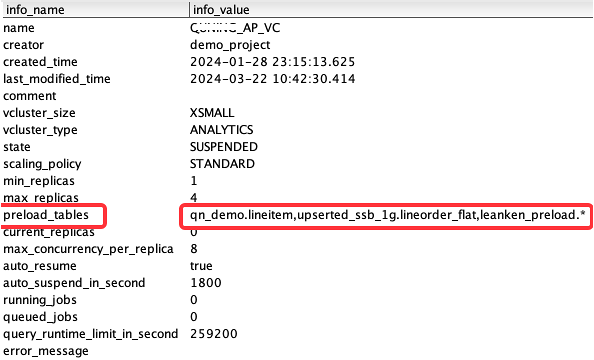
面向指定计算资源设置PRELOAD的数据对象范围,支持枚举和通配方式。
查看当前计算资源的Preload配置:
Preload在实时分析场景消除新数据的查询抖动
| 未Cache文件数占比 | TPCH 100G (0%) | TPCH 100G (1%) | TPCH 100G (5%) | TPCH 100G (10%) | TPCH 100G (20%) | TPCH 100G (30%) |
|---|---|---|---|---|---|---|
| 查询延迟 | 9300 ms | 15418ms | 20311ms | 19027ms | 18815ms | 20841ms |
计算资源及作业运行监控
计算资源运行状态
通过Web-UI监控
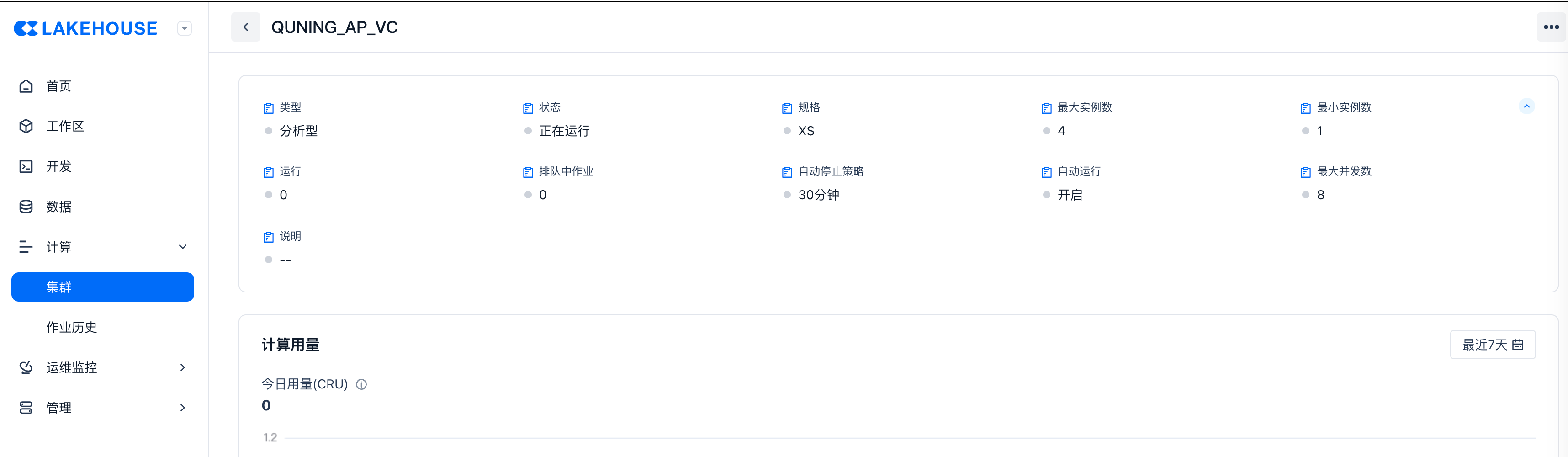
通过SQL API监控
| name | QUNING_AP_VC |
|---|---|
| creator | demo_project |
| created_time | 2024-01-28 23:15:13.625 |
| last_modified_time | 2024-03-27 09:59:48.212 |
| comment | |
| vcluster_size | 1 |
| vcluster_type | ANALYTICS |
| state | RUNNING |
| scaling_policy | STANDARD |
| min_replicas | 1 |
| max_replicas | 4 |
| preload_tables | qn_demo.lineitem,upserted_ssb_1g.lineorder_flat,leanken_preload.* |
| current_replicas | 1 |
| max_concurrency_per_replica | 8 |
| auto_resume | true |
| auto_suspend_in_second | 1800 |
| running_jobs | 0 |
| queued_jobs | 0 |
| query_runtime_limit_in_second | 259200 |
| error_message |
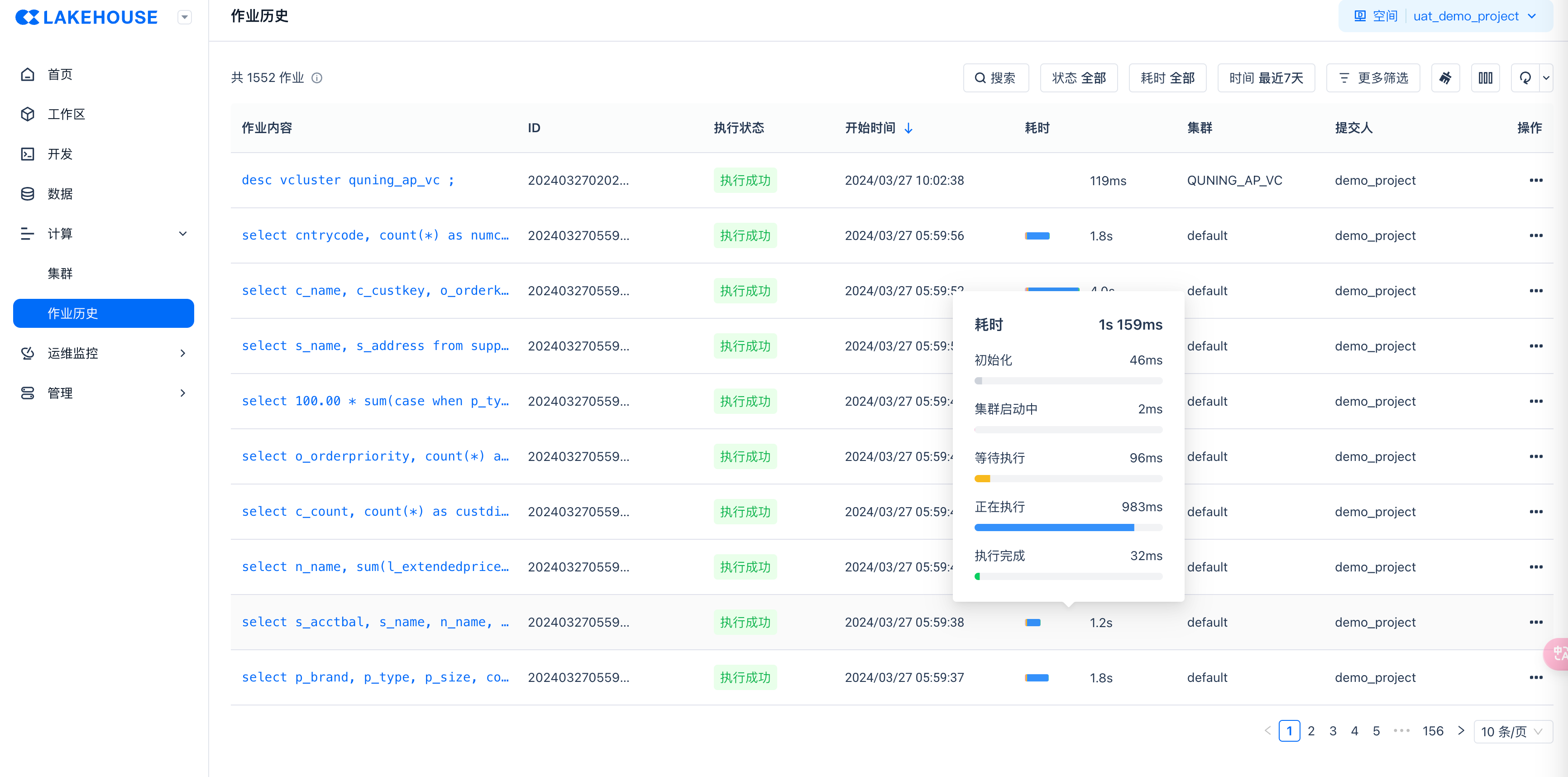
作业监控
场景:作业失败、超长运行、指定用户/VC作业监控、作业运行时长及成本统计、指定TAG监控。
通过Web-UI监控
增加过滤条件:如通过TAG方式过滤特定作业/作业组
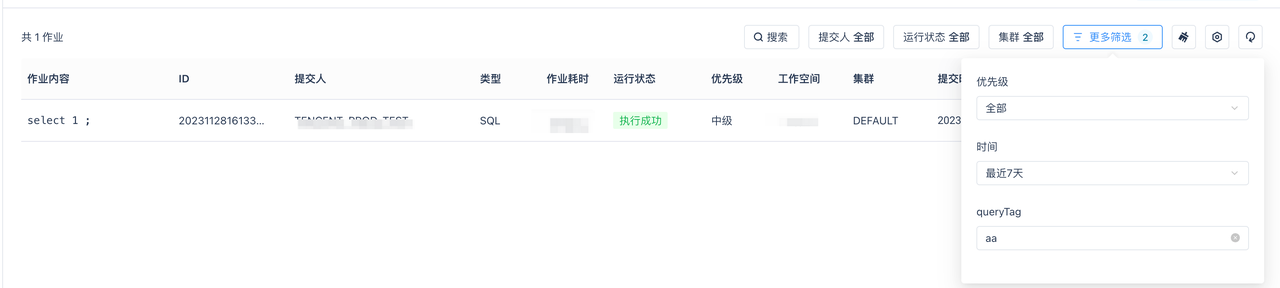
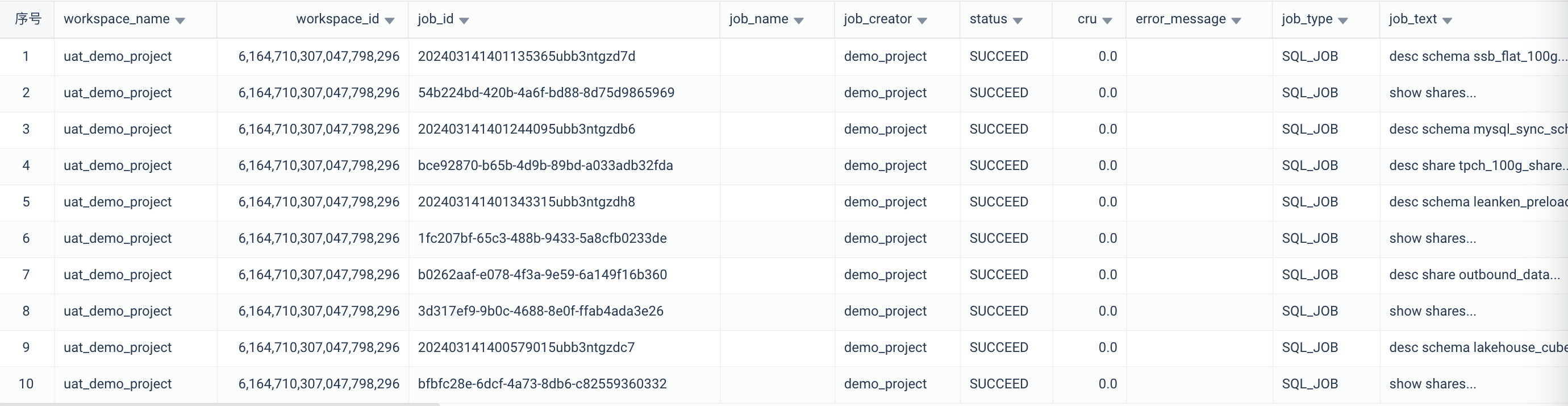
通过SHOW JOBS命令监控近期执行作业成功/排队/超长运行状态
SHOW JOBS命令获取工作空间内计算资源内正在进行中、已经完成的近期作业。
注:
列出最近执行的作业,包括已经结束和运行中的作业。用户可以使用此命令列出拥有权限的作业,默认显示最近7天提交的任务,最多可查询10000条。
| name | QUNING_AP_VC |
|---|---|
| creator | demo_project |
| created_time | 2024-01-28 23:15:13.625 |
| last_modified_time | 2024-03-27 09:59:48.212 |
| comment | |
| vcluster_size | 1 |
| vcluster_type | ANALYTICS |
| state | RUNNING |
| scaling_policy | STANDARD |
| min_replicas | 1 |
| max_replicas | 4 |
| preload_tables | qn_demo.lineitem,upserted_ssb_1g.lineorder_flat,leanken_preload.* |
| current_replicas | 1 |
| max_concurrency_per_replica | 8 |
| auto_resume | true |
| auto_suspend_in_second | 1800 |
| running_jobs | 0 |
| queued_jobs | 0 |
| query_runtime_limit_in_second | 259200 |
| error_message |
通过INFORMATION_SCHEMA查看历史执行作业
INFORMATION_SCHEMA的数据字典视图存在10min左右的延迟,适合对长期历史作业数据进行分析。在线实时的作业分析需要使用SHOW JOBS命令获取。