
将数据导入云器 Lakehouse 的完整指南
数据入仓:使用Lakehouse Studio实时同步导入Kafka数据
概述
使用场景
已有 Kafka 数据源,对数据同步的实时性要求高,期望能实时同步到 Lakehouse 的表中,实现端到端秒级延迟。
实现步骤
导航到 开发 -> 任务,点击“+”,选择“实时同步”,新建一个“实时同步”作业。
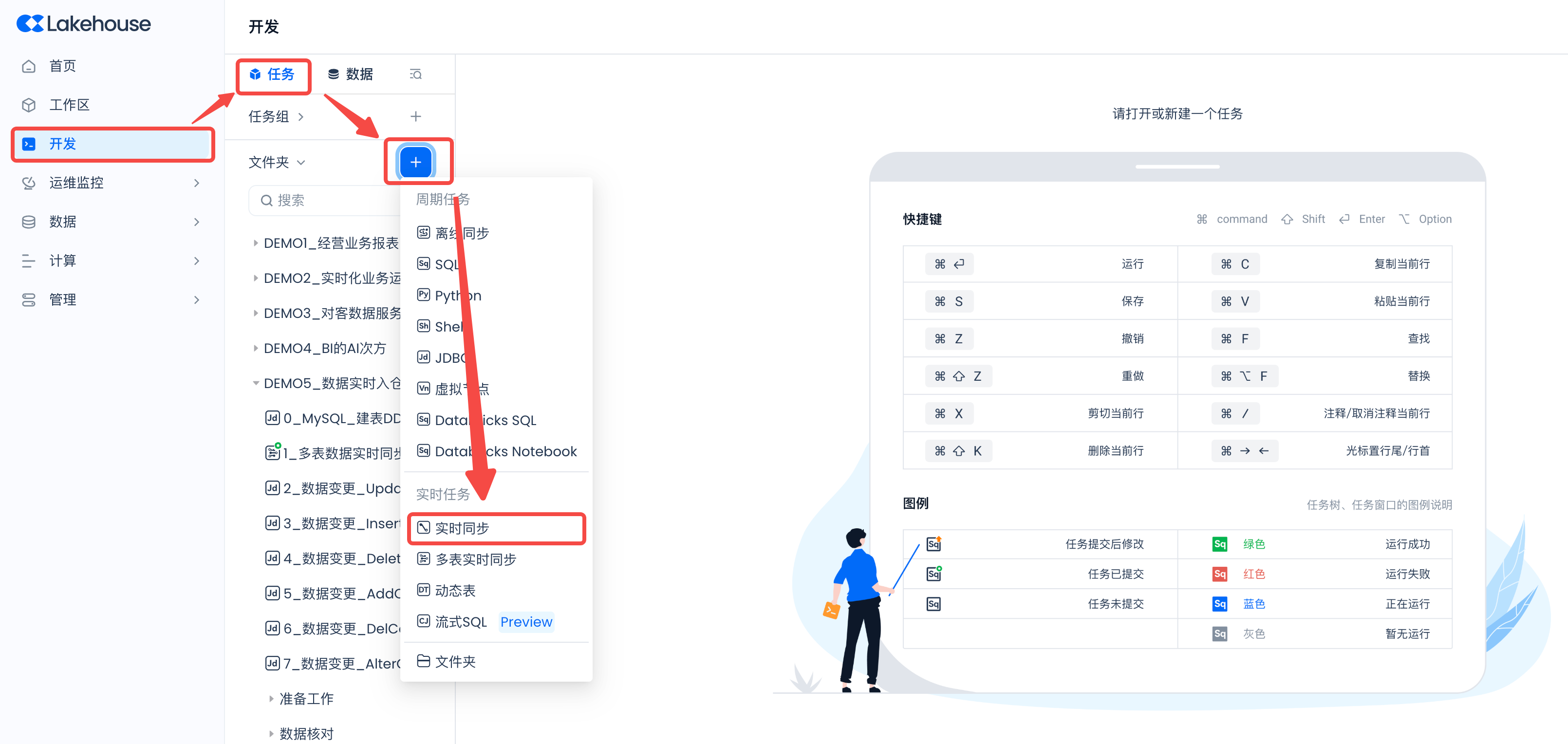
主要配置如下:
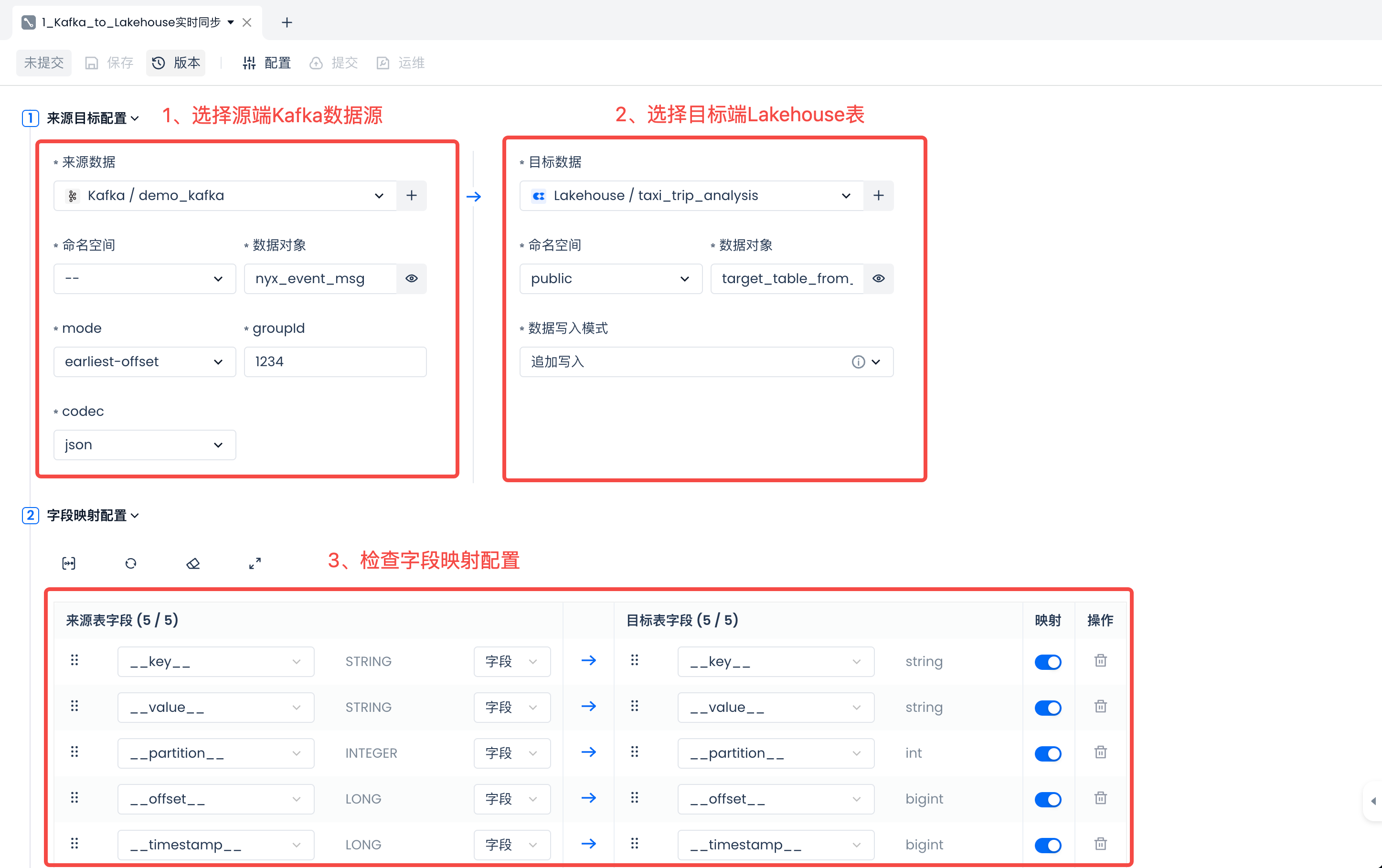
在左侧选择源端 Kafka 数据源时,请配置正确的
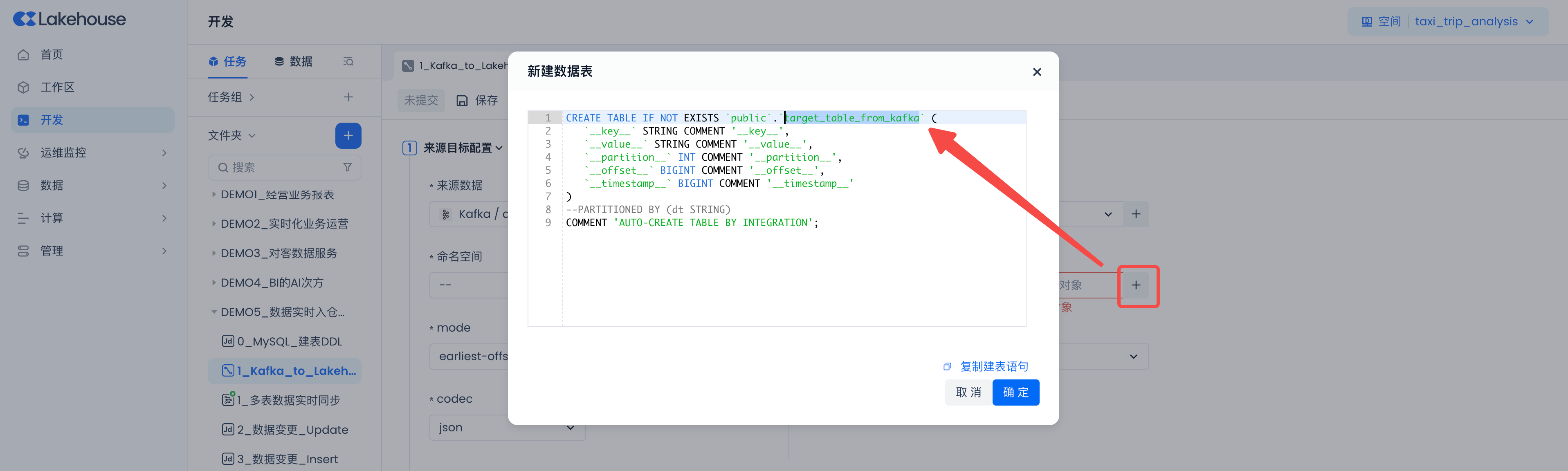
modegroupIdcodecgroupId然后在右侧选择Lakehouse目标端,选择已有的数据表,或者新建数据表(推荐使用):target_table_from_kafka。
在“新建数据表”SQL代码里,将表名改为“target_table_from_kafka”。
在“字段映射配置”区域,系统会默认使用 Kafka Topic 的内置字段进行数据字段映射。如果 Topic 内的消息格式为 JSON,你还可以通过新增计算列的方式,使用 JSONPath 规则解析
value[__value__].[accountId]__value__accountId__value__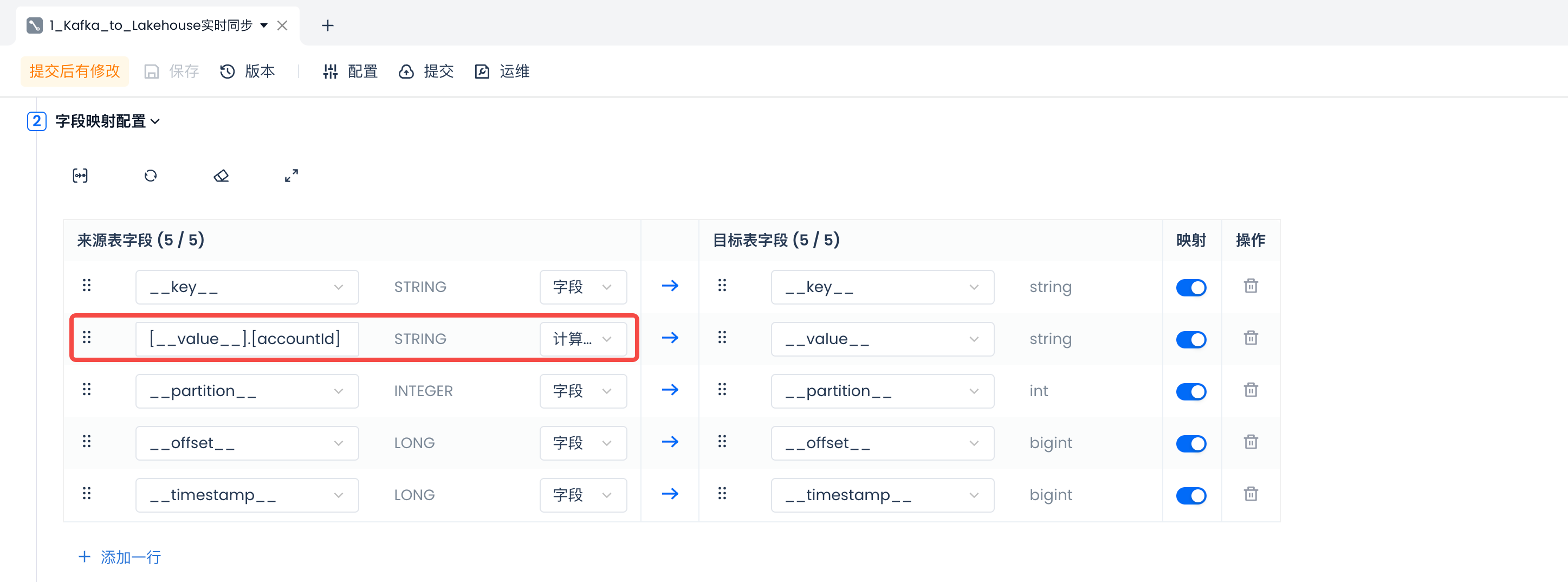
在“同步规则配置”中,设定同步的最大并发数。增大并发数可以提升数据消费速度。
检查字段映射符合预期后,在配置中设定“集群”等必填信息,点击“确定”,然后点击“保存”以保存任务配置。
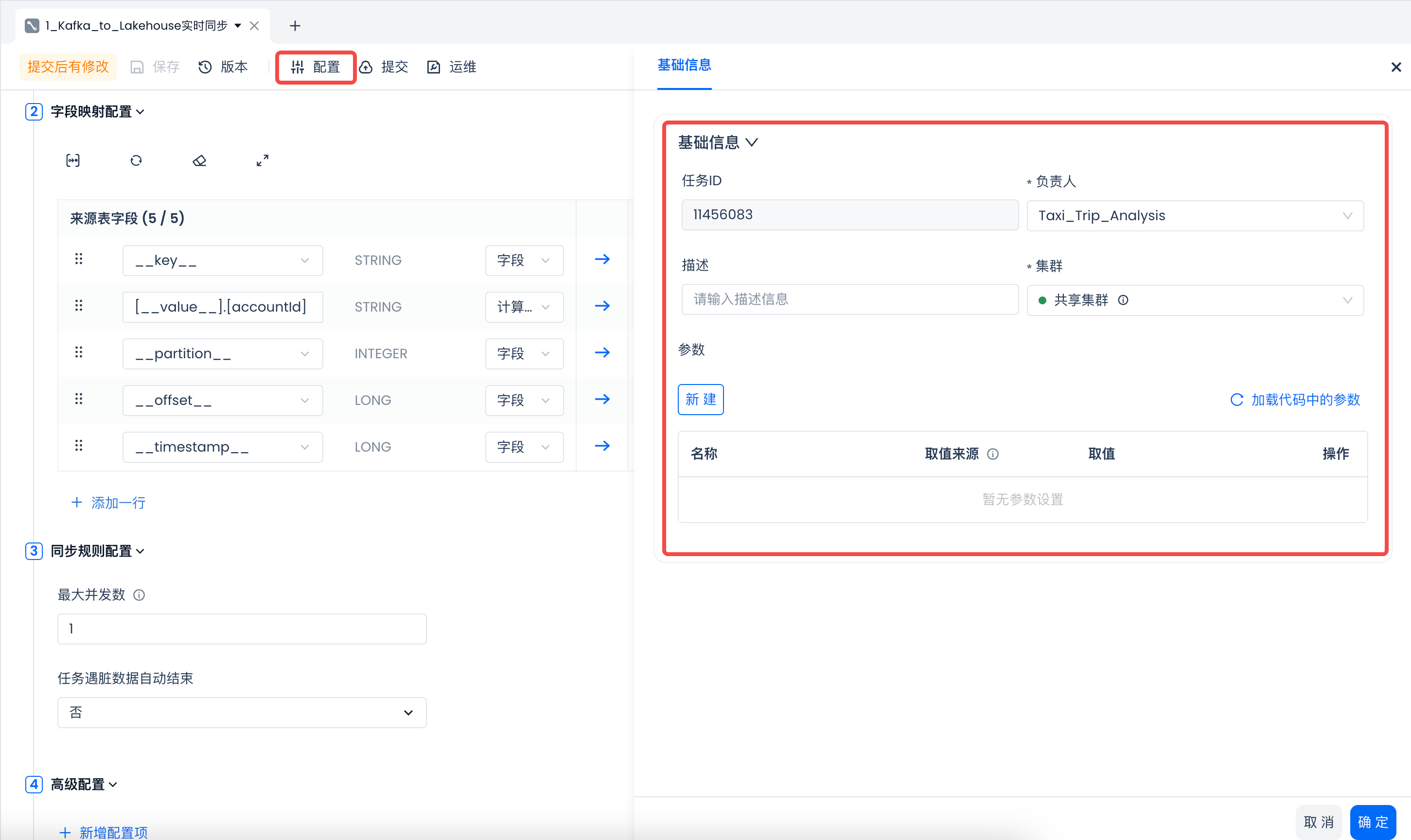
实时同步任务当前不支持直接运行测试,需要提交发布后,检查运行结果是否正常。
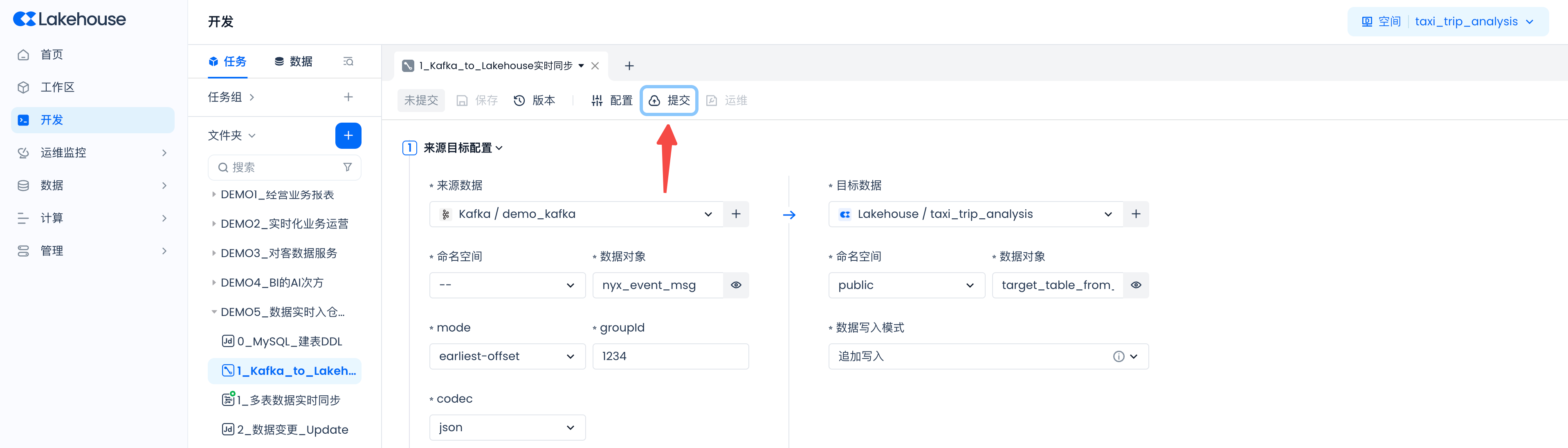
下一步建议
-
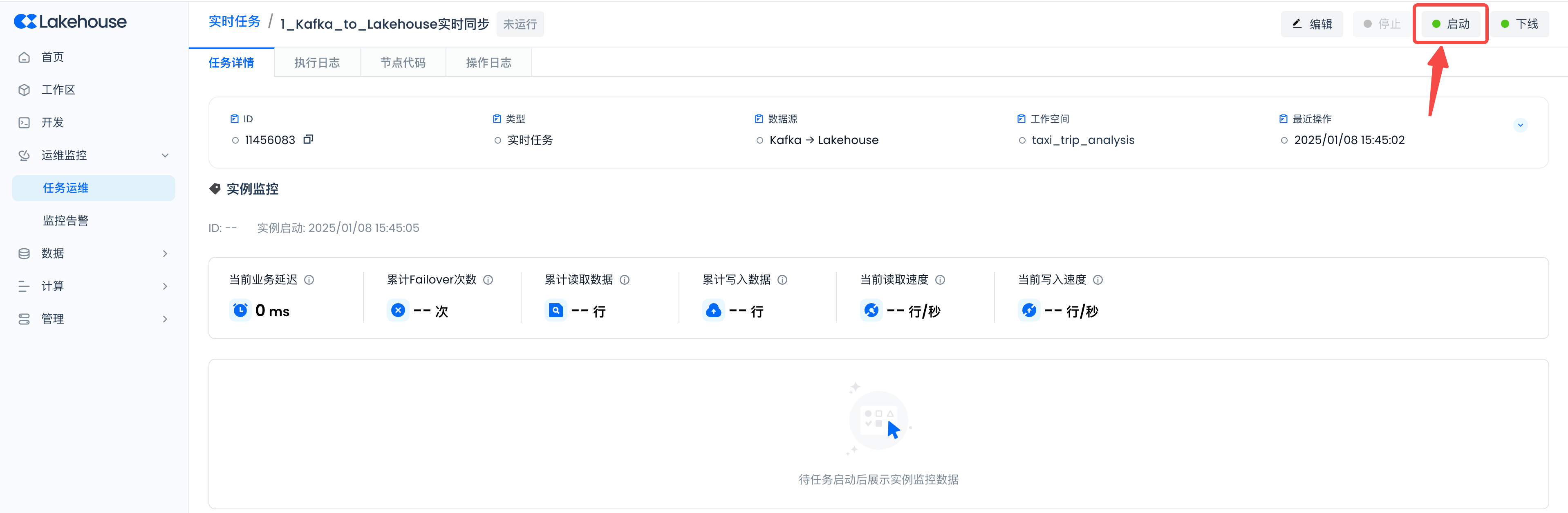
在运维中心启动实时同步任务,观察任务运行指标并验证数据同步结果是否正常。
-
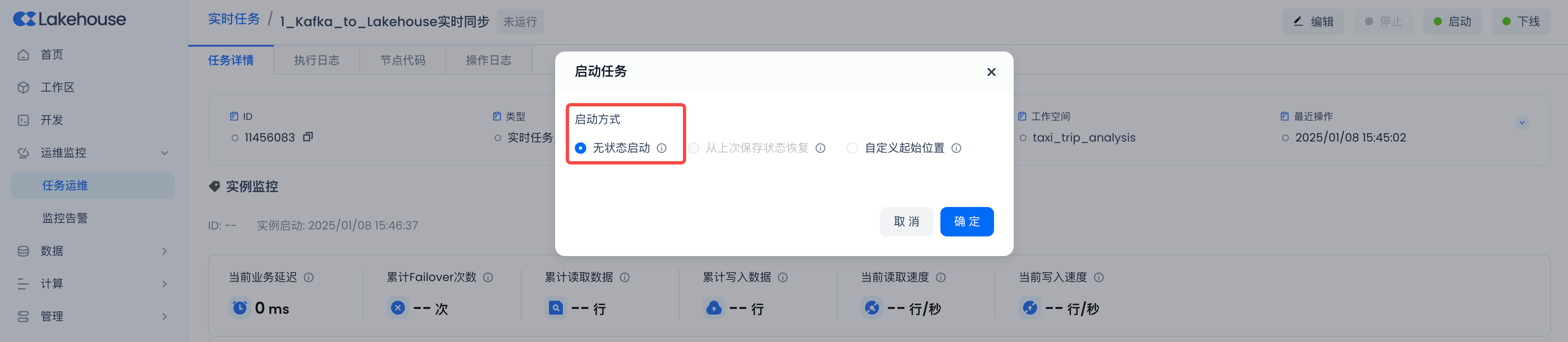
第一次启动时选择“无状态启动”的方式即可。
-
正常启动后,可以看到以下监控指标,表示同步任务运行正常。
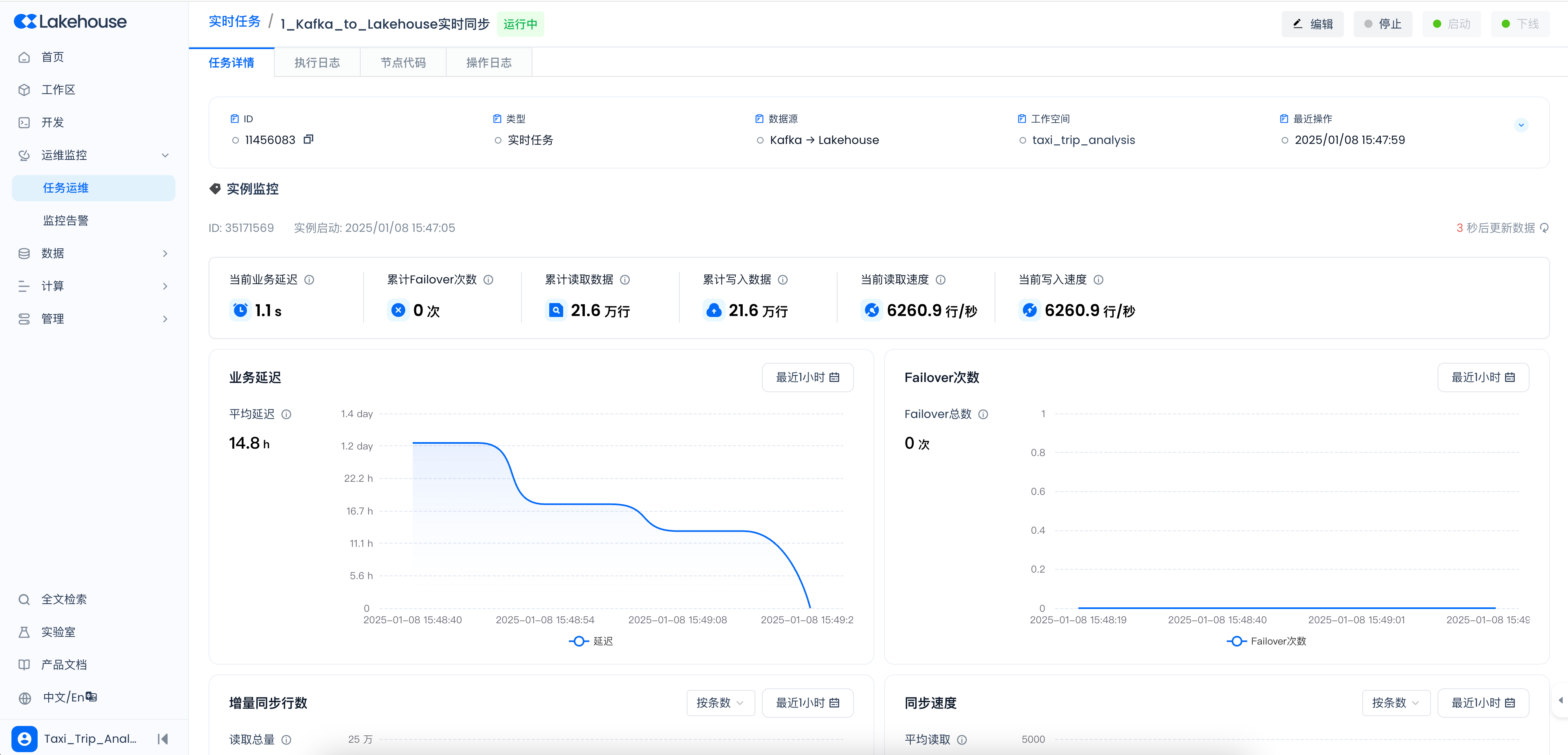
-
抽查目标表中的数据,与源端数据进行校验核对,确认是否符合预期。
资料
联系我们