
流式SQL
流式SQL是Lakehouse平台推出的一种新型SQL调度模式,它采用微批处理运行机制,支持设置秒级的数据刷新间隔,类似于Spark Streaming的微批执行方式。与传统的定时调度相比,流式SQL能够显著减少提交和编译SQL的开销,因为它将提交的SQL转化为一个常驻进程,一旦达到设定的时间间隔,就会自动触发数据的运行和处理。流式SQL目前是面向需要数据新鲜度更高的场景,目前支持dt刷新和加工数据过程中含有table stream。
为了更清晰地理解流式SQL的优势,我们可以将其与普通SQL的执行过程进行对比:
普通SQL执行过程
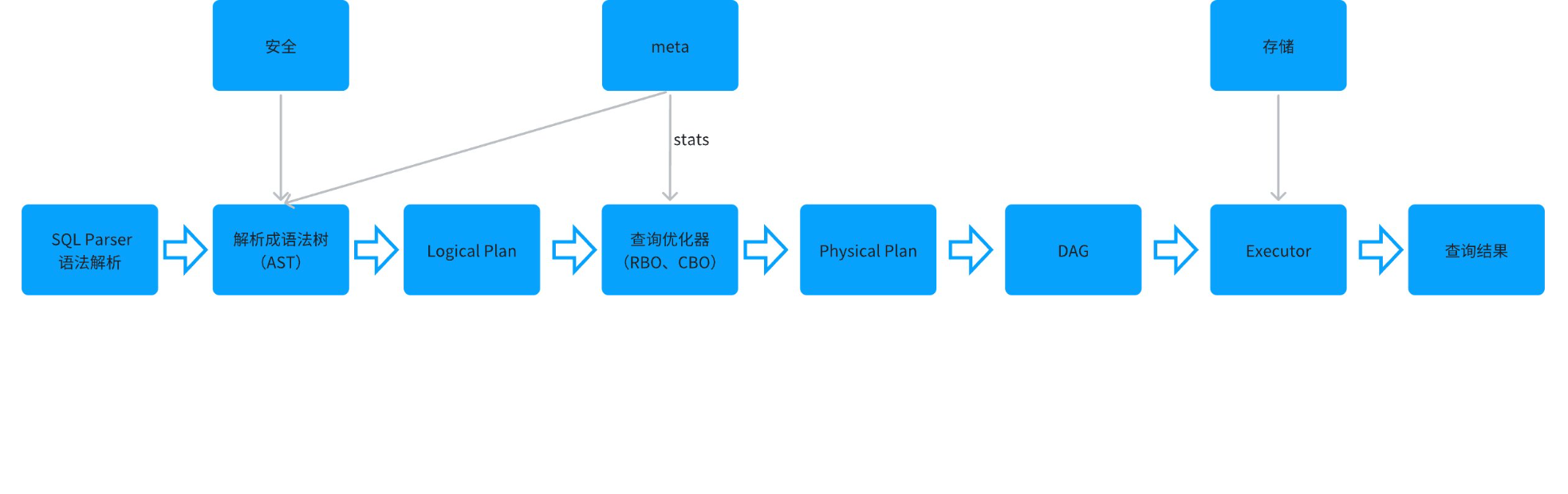
-
语法解析器(Parser),词法分析,语法分析将SQL文本解析成抽象语法树(AST),语义分析,类型推导和检查。生产Logical Plan
-
查询优化器(Optimizer):通过Rule对Plan进行变换,根据cost model找出best plan
- RBO:基于规则的优化器,通过用户下发的SQL语句进行的优化,主要通过改下SQL,比如SQL子句的前后执行顺序等。比较常见的优化包括谓语下推、字段过滤下推、常量折叠、索引选择、Join优化等等
- CBO:基于代价的优化器,根据收集的统 计信息来计算每种执行方式的代价,进而选择最优的执行方式
- HBO:History-Based Optimizer,基于历史的优化器
-
生成DAG图:DAG描述了执行计划映射到物理分布式集群的具体描述,根据执行计划,分布式执行,体现的是执行计划被物化到分布式系统上,具备的一些特性:比如并发度,数据传输方式等等,保证有序性和可靠性
-
Executor读取数据进行运算
流式SQL执行过程
-
首次提交与物理执行计划生成:
- 在流式SQL首次提交时,系统会进行完整的编译过程,包括语法解析、查询优化和物理执行计划的生成。
- 这一阶段生成的物理执行计划(DAG图)将被固化,用于后续的执行周期。
-
后续执行的优化:
- 物理执行计划生成并固化,后续的执行周期在大部分情况下将直接使用这一计划,无需再次进行编译。
- 这意味着每次数据到达时,流式SQL可以跳过耗时的解析和优化步骤,直接进入执行阶段。
- 在执行过程中,优化器也会监测每次要处理的数据量,如果数据量变化非常大使得执行计划不是最优时,优化器会重新生成物理执行计划并固化。
定时调度与流式SQL的对比
-
普通定时调度:
- 每次执行前都需要重新解析和优化SQL,这增加了额外的开销。
- 时间间隔通常需要设置得相对较大,以减少调度的频率和资源消耗。
-
流式SQL:
- 由于省去了重复的编译过程,流式SQL可以支持更小的时间间隔,实现更高频的数据更新和处理。
- 这种模式特别适合需要实时或近实时数据处理的应用场景
流式SQL适用场景
流式SQL的引入,为数据处理带来了更高的灵活性和实时性。在动态表(dynamic table)的DDL(Data Definition Language)定义中,调度的时间间隔通常有一个最小值,例如一分钟。这意味着数据的更新和处理至少会有一个一分钟的延迟。然而,流式SQL通过微批处理机制,允许将这个时间间隔缩短到秒级,从而实现更快速的数据反应和处理。
- 实时数据处理:流式SQL能够快速响应数据变化,适合需要实时数据处理和分析的应用。
- 高频数据更新:对于需要频繁更新数据的系统,流式SQL可以减少每次更新的延迟,提高数据处理的实时性。
流式SQL使用限制
- 要求流式是动态表或者SQL加工中含有table stream。普通SQL暂时不支持
- 作业必须运行在分析型(ap)集群
- 目前只支持在Lakehouse 界面开发流式SQL。一个SQL文件中只能处理一个DML SQL任务
流式SQL如何使用
开发流式SQL任务
-
数据开发中新建流式SQL节点
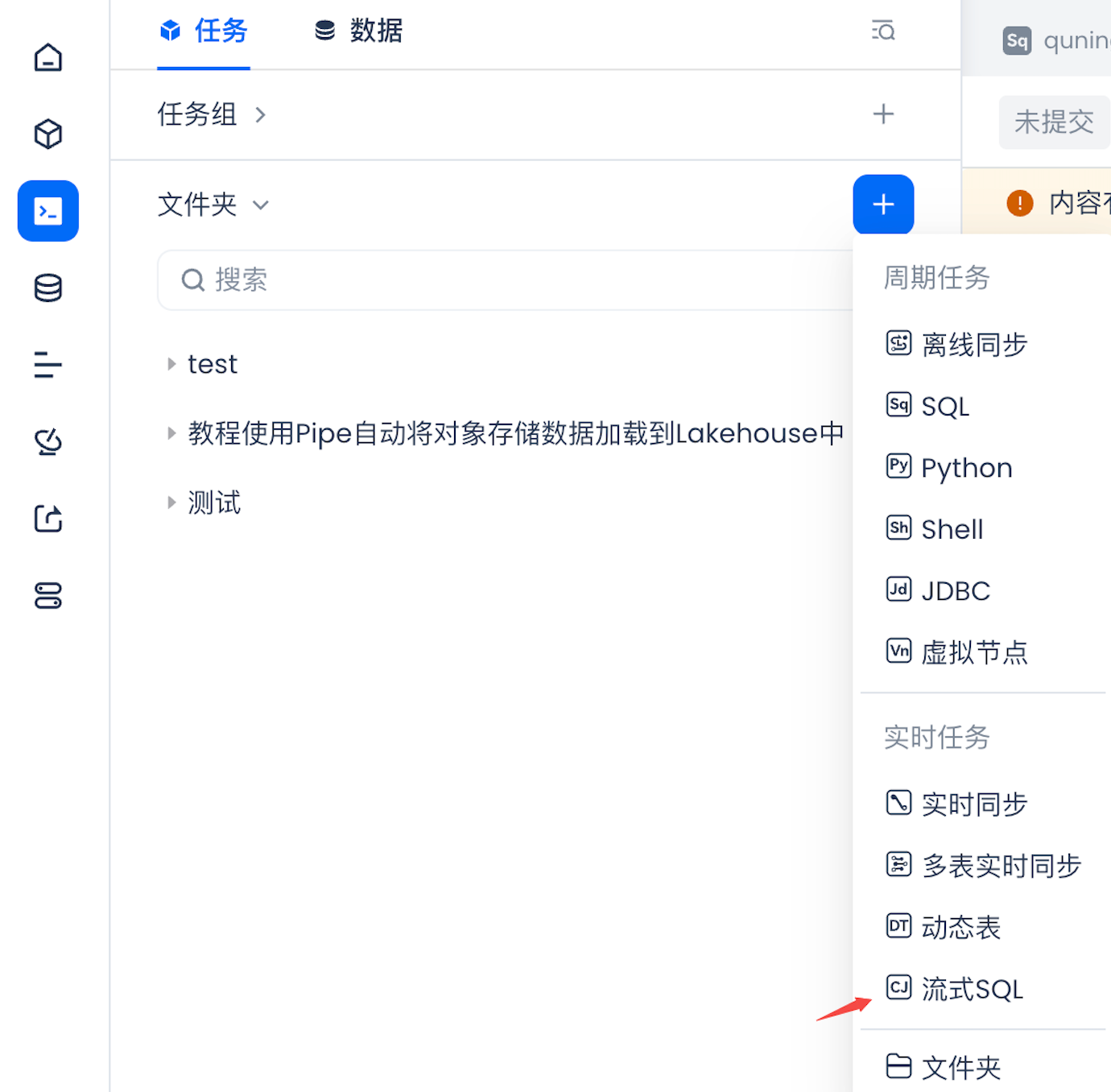
-
编写SQL任务
提交的SQL任务中只能有一条DML SQL语句。在开发阶段可以编写任何SQL,目前是没有限制。但是在启动阶段会校验SQL是不是符合流式SQL。
流式SQL要求
- 要求流式是动态表或者SQL加工中含有table stream
- 作业必须运行在分析型(ap)集群
- 一个SQL文件中只能处理一个SQL任务
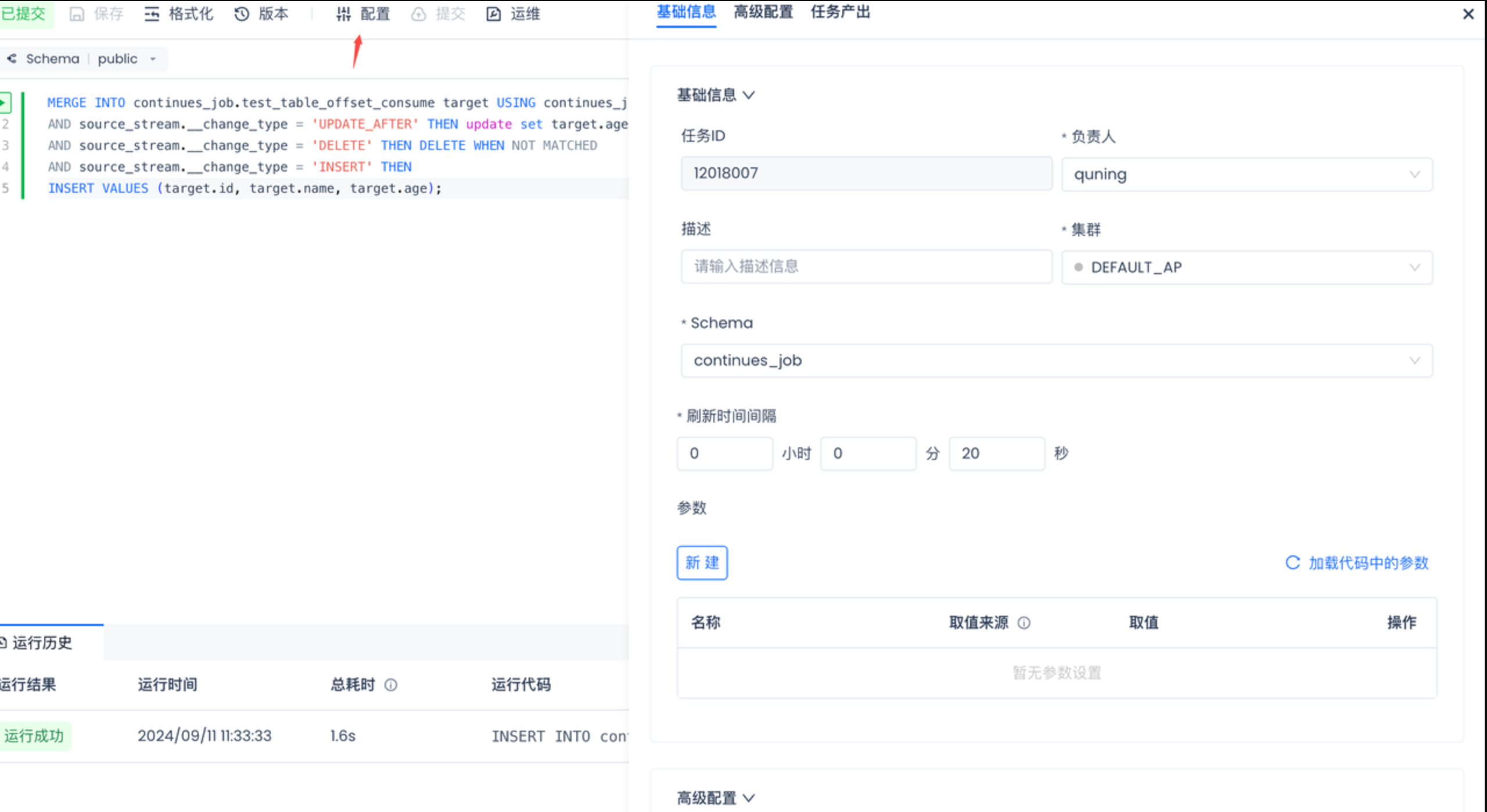
配置处理间隔
点击配置按钮,刷新间隔用来配置多长时间处理一次,目前最短时间是1s
运行流式SQL任务
- 点击提交按钮会将流式SQL提交到运维中心
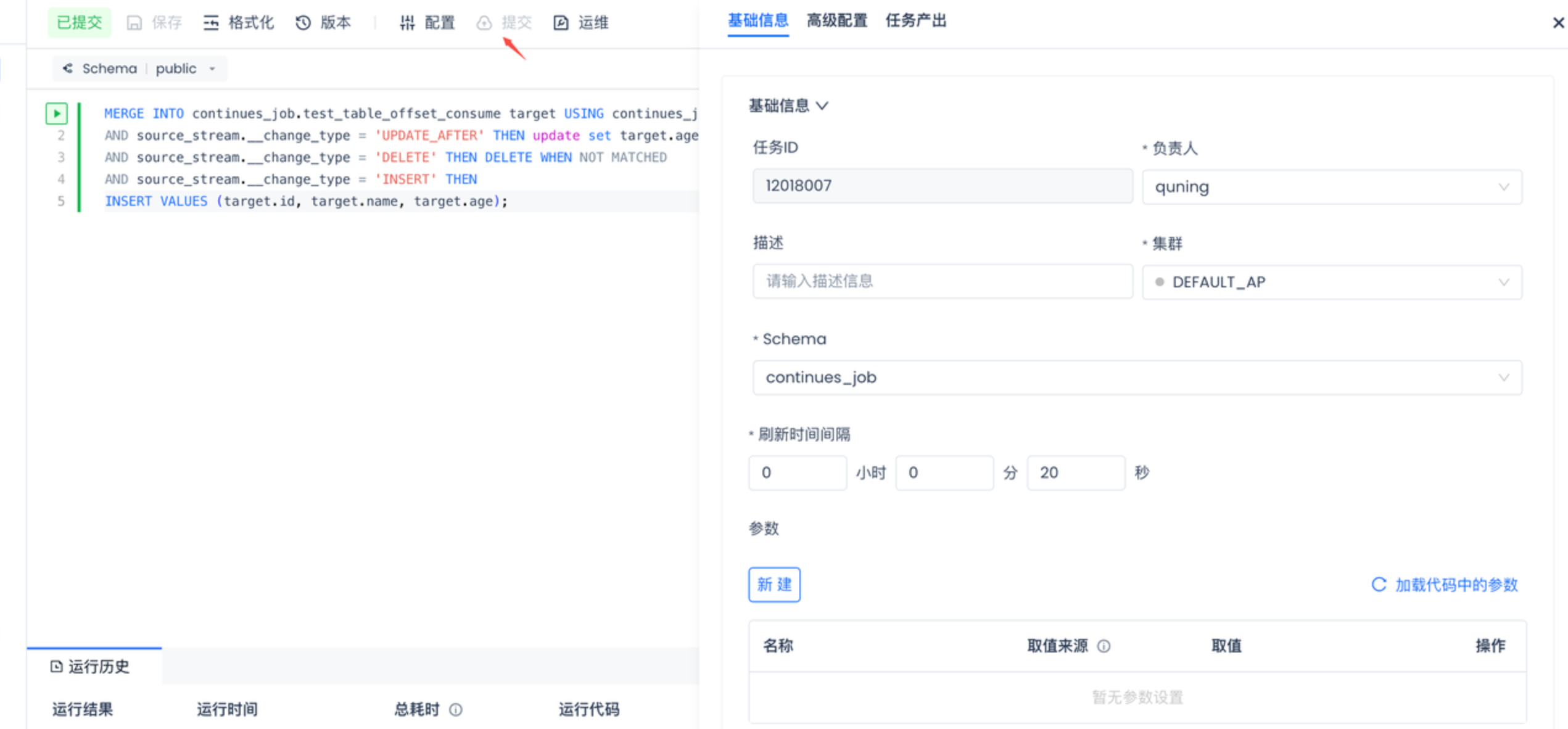
- 启动流式SQL。进入到运维中心点击启动按钮。流式SQL就会运行

流式SQL运维
-
在运维中心界面中,可以看到当前工作空间中所有的流式SQL列表。

-
流式SQL运行过程可以通过job ID查看运行情况

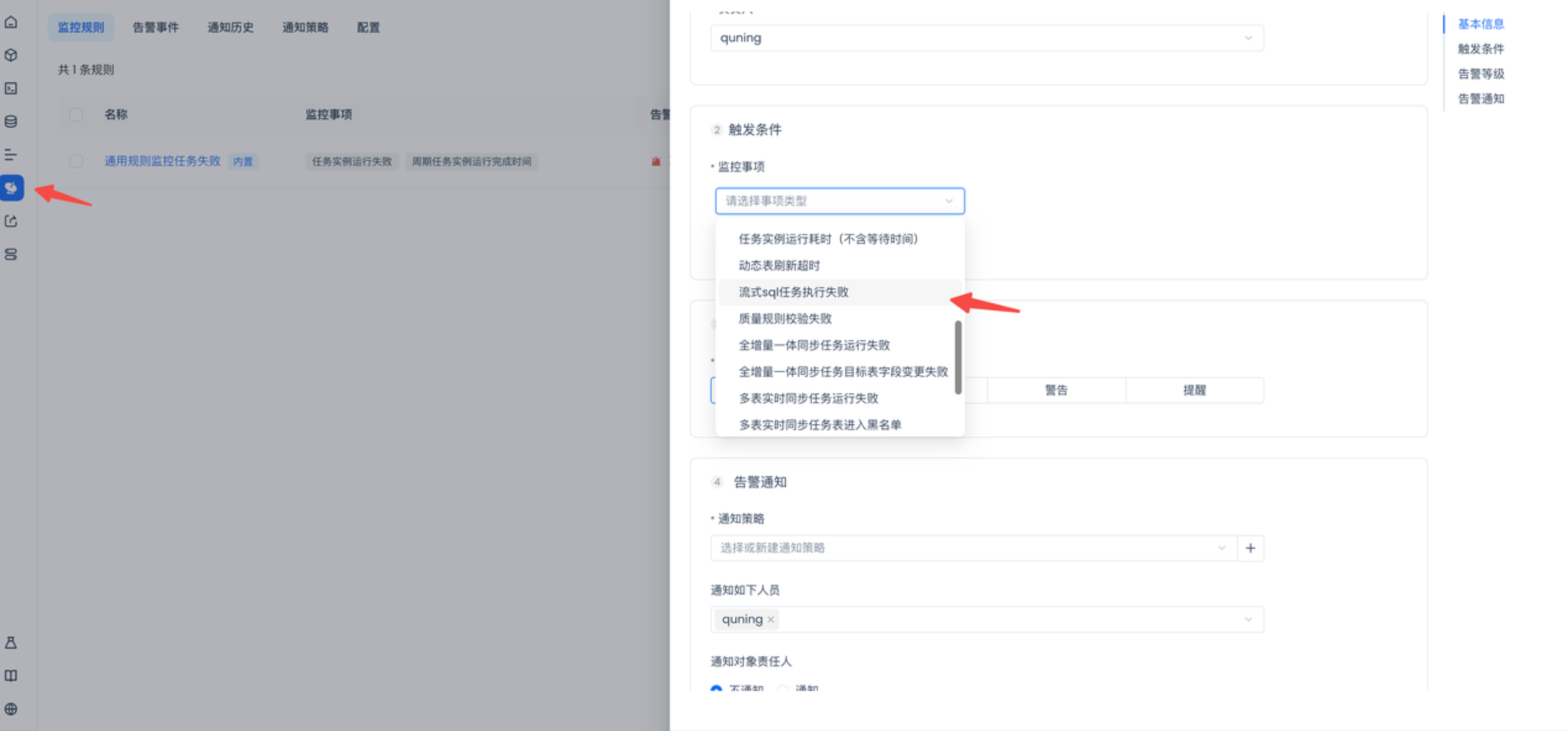
流式SQL监控告警
监控告警中支持监控流式SQL任务执行失败告警
流式SQL使用具体案例
TABLE STREAM使用流式SQL
本次案例使用TABLE STREAM实现缓慢变化维第一种覆盖更新。并使用流失SQL的微批处理保证数据的新鲜度。
缓慢变化维度(Slowly Changing Dimension,SCD)是数据仓库中处理数据变更的一种方法。在数据仓库中,数据通常是从多个数据源整合而来的。随着时间的推移,这些数据源中的数据可能会发生变化,例如更新、添加或删除。缓慢变化维度是一种用于处理和更新这些数据变化的技术。SCD有多种类型,SCD1:覆盖更新,SCD2:历史记录等
我们模拟当原表数据发生变化时,通过流失SQL加工,缓慢变化维表也会变化。
- 新建一个普通SQL节点。执行一下SQL。用于创建原表并插入一些测试数据,和开启table stream捕获原表的变化
- 创建一张缓慢变化维表,用于保持和原表一致
- 新建一个流式SQL节点,将下面SQL复制到流式SQL节点中。我们设置20秒间隔处理一次数据
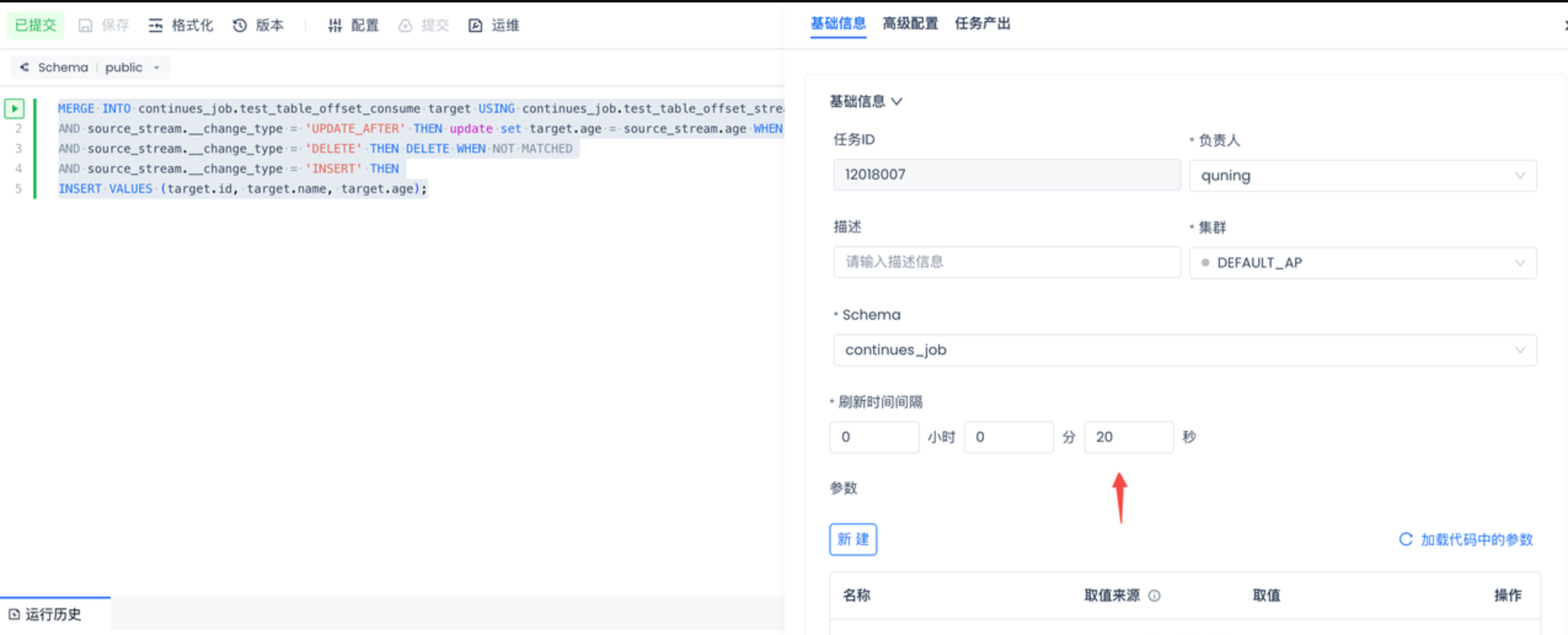
- 提交流式SQL,并且在运维中心点击启动
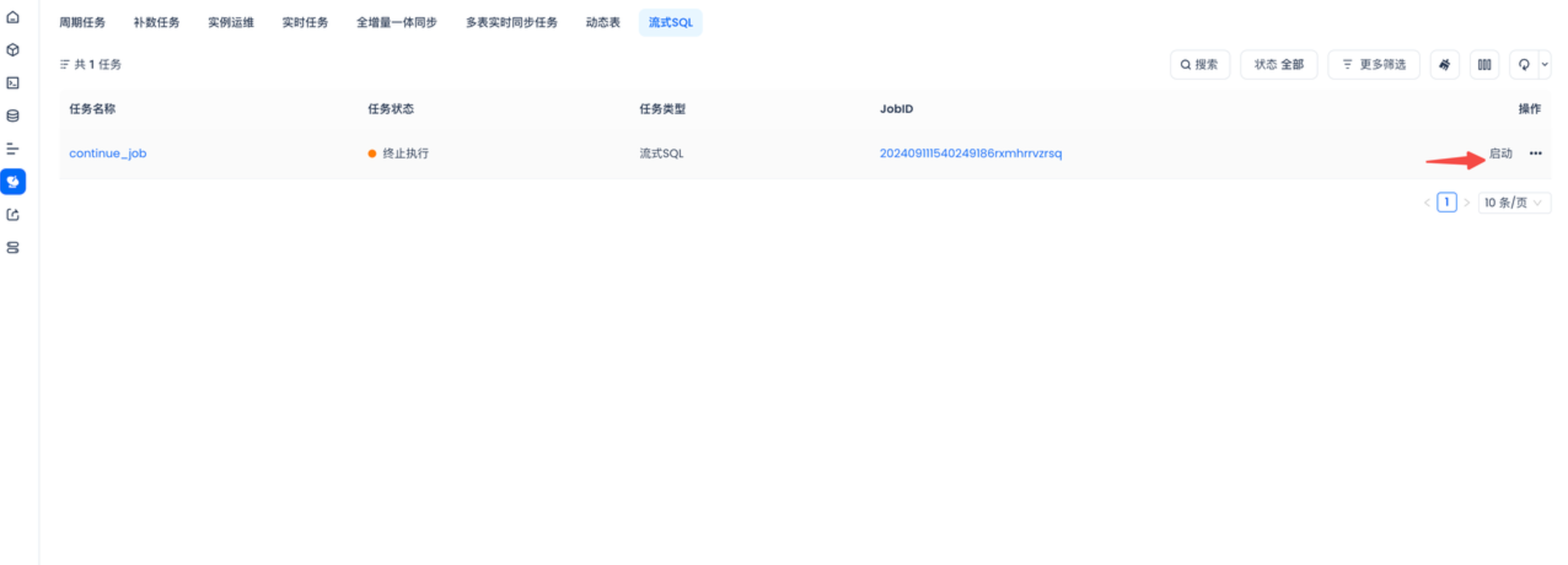
- 通过更新原表数据,流式SQL运行成功之后。SCD表也会和流式SQL保持一致
- 普通节点执行SQL
- 清理环境
-
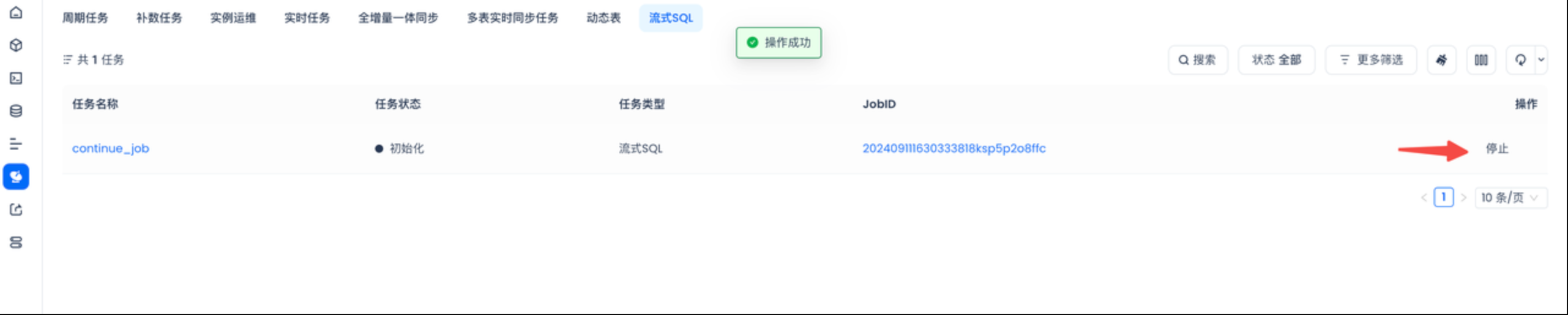
运维中心中停止流式SQL
-
删schema
Dynamic Table使用流式SQL
本次案例使用dynamic table对数据按时间进行聚合。利用流式SQL微批调度提高数据新鲜度
- 创建一ods表
- 使用动态表进行聚合。在普通SQL节点中创建动态表,注意不要在ddl中设置调度周期
- 新建流式SQL节点,将下面SQL复制到节点内容中,并配置10s运行一次
- 启动流式SQL刷新动态表

- 新建普通SQL节点,向表原表中插入一些数据,查询动态表是否刷新成功