
数据导入概览(Data Ingestion / Data Import)
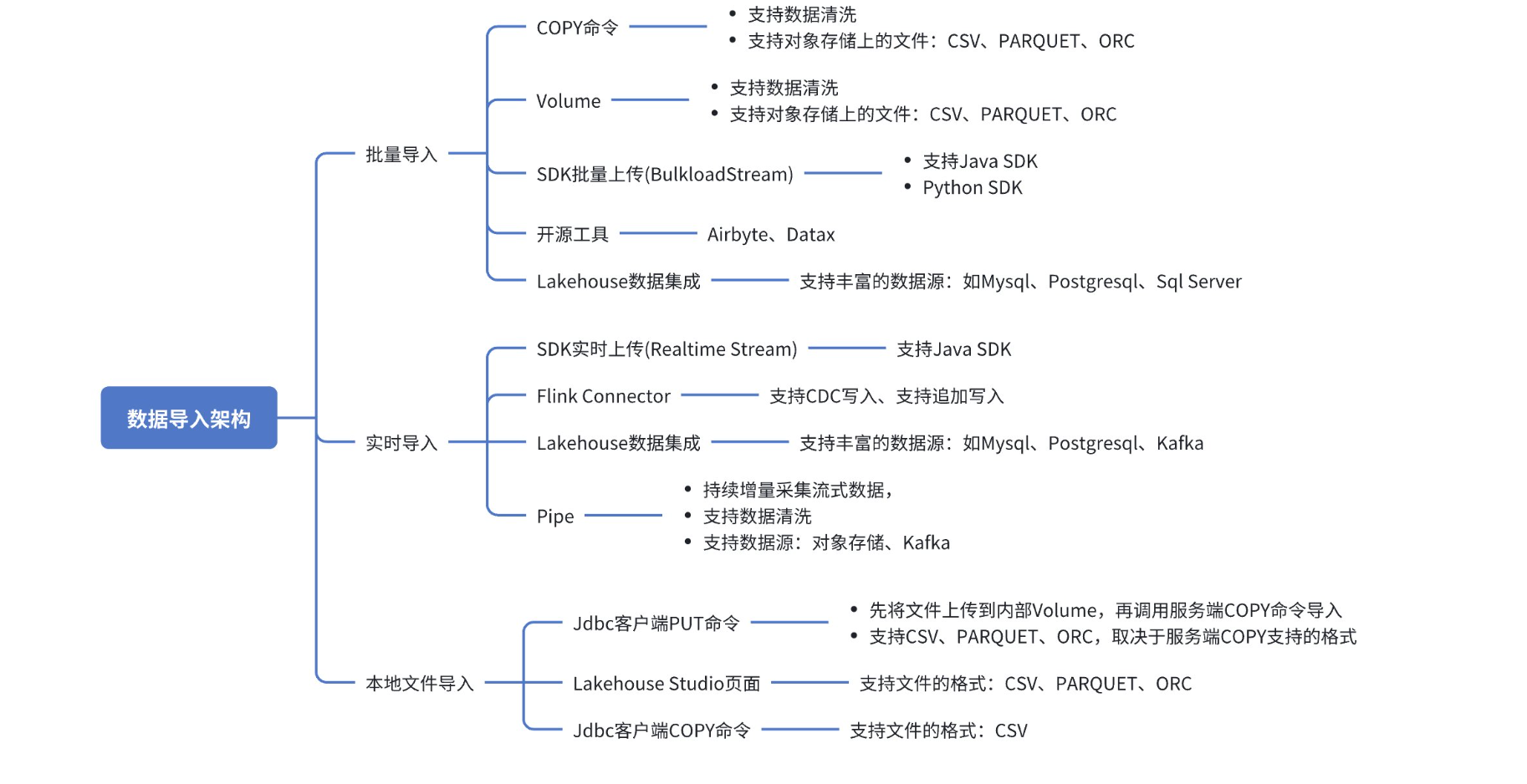
将数据加载到 Lakehouse 的方法有多种,具体取决于数据源、数据格式、加载方式(如批量、流式或数据传输)等因素。Lakehouse 提供了多种导入方式,按导入方式划分包括:支持用户 SDK 导入、支持使用 SQL 命令导入、支持使用客户端上传数据、支持第三方开源工具导入、支持通过 Lakehouse Studio 可视化界面导入。
导入方式概览
按场景划分
| 数据源 | 具体案例 | 适用场景 |
|---|---|---|
| 本地文件快速上传 | 使用put命令上传到内部Volume,再使用COPY命令导入 | 适用于源文件上传,并且需要使用 SQL 进行转换的场景。推荐在上传过程中使用 SQL 来转换或处理异常数据。 |
| 使用Lakehouse Studio的可视化上传界面 | 1. 适用于需要上传小数据量文件的用户,尤其是当文件存储在本地时。 2. 用户界面友好,简化上传流程。 3. 支持多种文件格式,包括 CSV、Parquet、Avro,满足不同数据格式需求。 | |
| 使用Jdbc客户端 在 JDBC 2.0.0 之后的版本中,本地 COPY 命令已被弃用。我们建议你使用 PUT 方法将数据上传到 volume 中,然后使用服务器端的 COPY 命令进行导入。 | 1. 在没有可视化界面的情况下处理小数据量,适合技术用户,尤其是那些熟悉命令行操作且需要批量处理小数据量的用户。2. 快速处理 CSV 文件,适合脚本化和自动化操作。 | |
| 批量从对象存储导入数据 | 使用Volume批量从对象存储加载数据 | 1. 适用于存储在对象存储上的数据,需要利用 SQL 性能优势快速读取大量数据的场景。 2. 高效处理大规模数据集。 3. 支持在导入时进行 SQL 数据转换,简化数据导入流程。 4. 支持多种文件格式,包括 CSV、Parquet、ORC。 |
| 使用Copy命令导入 | 1. 具备 Volume 的优势。区别在于,COPY 命令提供更多容错参数和数据导出支持,同时也支持导出到对象存储。 | |
| 使用JavaSDK读取Kafka实时写入到Lakehouse中 | 使用Java SDK导入数据 | 1. 适合需要实时数据流处理的业务场景,尤其是熟悉 Java 的开发人员。 2. 实现实时数据读取和写入,确保数据的即时可用性。 3. 适合自定义数据导入流程,提供高度灵活性。 |
| 自定义SDK读取文件写入到Lakehouse中 | 使用Java SDK导入数据 | 1. 适合一次性大量数据导入,且数据更新频率不高(时间间隔大于五分钟)的场景。 2. 支持自定义数据源,提供数据导入的灵活性。 |
| 使用Python SDK导入数据 | 1. 适合熟悉 Python 的开发人员,需要自定义数据导入流程,尤其是当数据源不在对象存储或现有集成不支持时。 | |
| 需要全托管服务和可视化操作的用户,尤其是需要同步第三方数据源的用户 | 使用 Lakehouse Studio 数据集成 | 1. 支持丰富的数据源和多种导入方式。 2. 提供实时同步、CDC镜像同步和离线周期调度同步。 3. 可视化监控,提高数据管理的透明度。 |
按导入方式
| 导入方式名称 | 使用方式 | 使用注意事项 |
|---|---|---|
| COPY 命令 | COPY INTO 命令 | 1. 目前支持的对象存储位置为腾讯云 COS 和阿里云 OSS。 2. 不支持跨云厂商导入(后续会支持)。例如,你的 Lakehouse 实例部署在阿里云而对象存储是腾讯云 COS。 |
| Volume | 使用ISNERT INTO... SELECT FORM VOLUEM导入 | 1. 目前支持的对象存储位置为腾讯云 COS 和阿里云 OSS。 2. 不支持跨云厂商导入(后续会支持)。例如,你的 Lakehouse 实例部署在阿里云而对象存储是腾讯云 COS。 |
| 数据集成 | 使用数据集成导入 | 1. 支持丰富的数据源,但性能可能比 COPY 命令和 Volume 略差。 |
| SDK实时数据流(RealtimeStream) | 实时上传数据 | 1. 实时写入的数据可以秒级查询。 2. 进行表结构更改时,需要先停止实时写入任务,然后在表结构变更后一段时间(大约 90 分钟)后,重新启动任务。 3. Table stream、materialized view 和 dynamic table 只能显示已经提交的数据。实时任务写入的数据需要等待约 1 分钟才能确认,因此 table stream 也需要等待约 1 分钟才能看到。 |
| SDK批量上传(BulkloadStream) | 批量上传数据Java SDK、批量上传数据Python SDK | |
| 使用开源工具导入数据 | AIRBYTE、DATAX、 FLINK CONNECTOR |
导入说明
Lakehouse 从原理上提供了两种主要的数据写入方法,以适应不同的数据处理需求和性能考量。
SQL 引擎直接拉取
Lakehouse 的 SQL 引擎能够直接从对象存储中拉取数据,这一方法特别适合于数据源已经位于对象存储的场景。未来,Lakehouse 计划扩展支持更多类型的数据源,以进一步提升数据接入的灵活性。
- 优势:SQL 引擎直接拉取数据,利用其性能优势,可以高效地处理存储在对象存储中的数据。使用 COPY 命令、Volume 可在导入过程中进行数据转换。
- 计算资源:执行 SQL 查询时会消耗计算资源(Virtual Cluster),但这种消耗是值得的,因为它提供了强大的数据处理能力。
- 文件格式:目前支持的文件格式包括 CSV、PARQUET 和 ORC,这些格式都是数据分析和处理中常用的格式。
- 导入方式:支持多种数据导入方式,如 COPY 命令、Volume、数据集成离线导入以及 SDK 批量上传(BulkloadStream)。
向Ingestion Service推送数据
Lakehouse 的 Ingestion Service 为需要实时数据写入的场景提供了解决方案。客户端将数据推送到服务端,由 Ingestion Service 接收并提交到表中,包括 SDK 实时数据流(RealtimeStream)和 CDC 实时写入。
- 优势:提高了数据写入的时效性,实现了实时写入和实时可读。
- 资源消耗:目前 Ingestion Service 处于预览版,使用该服务暂不计费。但请注意,未来将开始计费。
- 适用场景:适用于需要实时数据流处理的业务场景,如实时分析和即时数据更新。
批量加载建议
批量摄取涉及加载不需要实时处理的大型有界数据集。这些数据通常以特定的频率被摄取,并非所有数据都立即到达。对于批量加载,建议使用对象存储来存储传入数据。Lakehouse 支持多种文件格式,包括 CSV、Parquet、ORC。
联系我们