-- Data_Clean virtual cluster
CREATE VCLUSTER IF NOT EXISTS Data_Clean
VCLUSTER_SIZE = XSMALL
VCLUSTER_TYPE = GENERAL
AUTO_SUSPEND_IN_SECOND = 60
AUTO_RESUME = TRUE
COMMENT 'Data_Clean VCLUSTER for test';
-- Use our VCLUSTER
USE VCLUSTER Data_Clean;
-- Create and Use SCHEMA
CREATE SCHEMA IF NOT EXISTS Data_Clean;
USE SCHEMA Data_Clean;
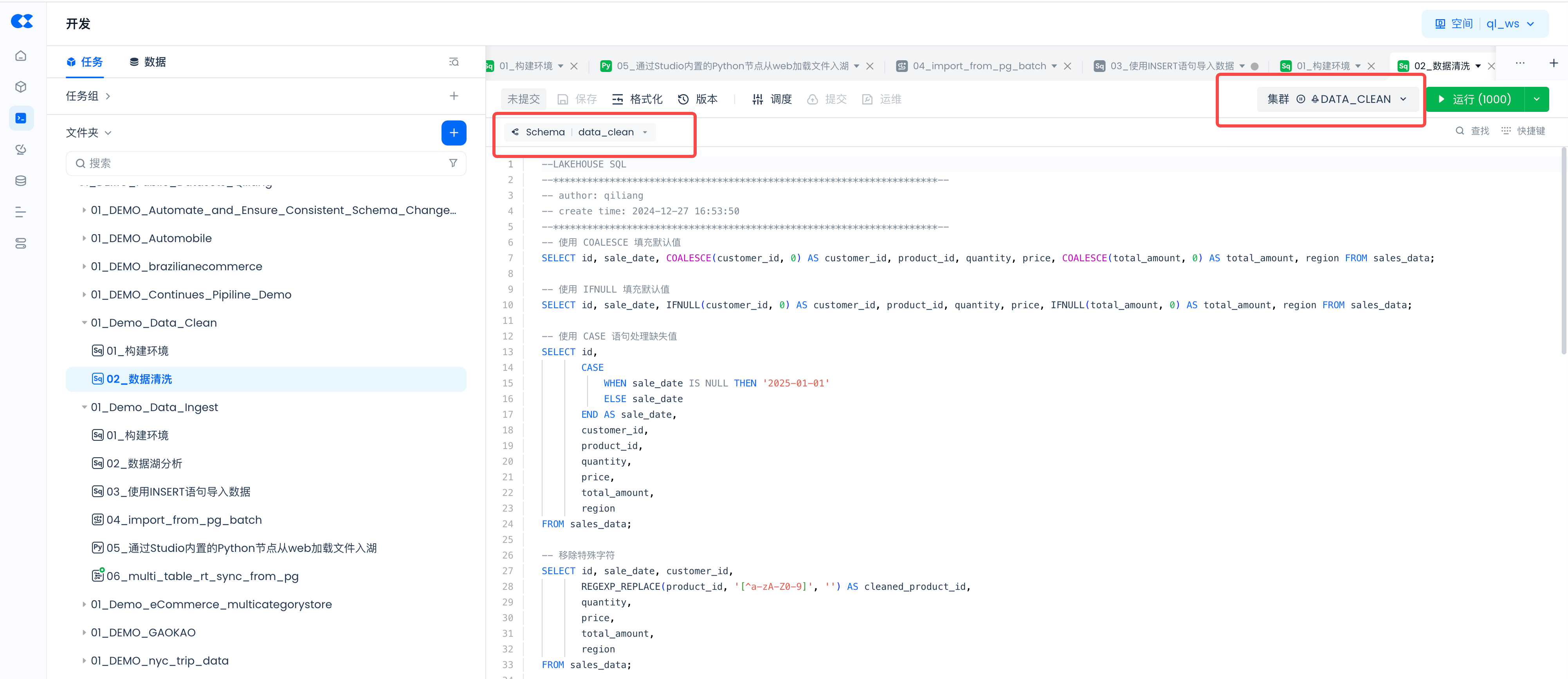
-- 使用 COALESCE 填充默认值
SELECT id, sale_date, COALESCE(customer_id, 0) AS customer_id, product_id, quantity, price, COALESCE(total_amount, 0) AS total_amount, region FROM sales_data;
-- 使用 IFNULL 填充默认值
SELECT id, sale_date, IFNULL(customer_id, 0) AS customer_id, product_id, quantity, price, IFNULL(total_amount, 0) AS total_amount, region FROM sales_data;
-- 使用 CASE 语句处理缺失值
SELECT id,
CASE
WHEN sale_date IS NULL THEN '2025-01-01'
ELSE sale_date
END AS sale_date,
customer_id,
product_id,
quantity,
price,
total_amount,
region
FROM sales_data;
-- 将字符串转换为日期
SELECT id, CAST(sale_date AS DATE) AS sale_date,
customer_id, product_id, quantity,
CAST(price AS DECIMAL(10, 2)) AS price,
CAST(total_amount AS DECIMAL(10, 2)) AS total_amount, region
FROM sales_data;
删除空格
说明
在数据清洗过程中,字符串前后的空格会导致数据分析结果不准确。我们可以使用
TRIM
TRIM
函数删除空格。在实际项目中,删除空格常用于清理包含多余空格的文本字段。
实现
-- 删除空白值
SELECT id,
TRIM(sale_date) AS sale_date,
customer_id,
product_id,
quantity,
price,
total_amount,
TRIM(region) AS region
FROM sales_data;
-- 将区域字段转换为小写
SELECT id,
sale_date,
customer_id,
product_id,
quantity,
price,
total_amount,
LOWER(region) AS region
FROM sales_data;
删除异常值
说明
异常值可能会影响数据分析的结果,使用
DELETE
DELETE
语句可以删除这些记录。在实际项目中,删除异常值常用于剔除极端或错误的数据,以保证分析结果的准确性。
实现
< -5000;
## 去重
### 说明
在数据集中,重复记录会影响数据分析的准确性。我们可以使用 `DISTINCT` 或者 `ROW_NUMBER()` 函数来去除重复记录。在实际项目中,去重操作常用于合并多个数据源或清理历史数据时。
### 实现
```sql
-- 使用 DISTINCT 去重
SELECT DISTINCT customer_id, product_id, region FROM sales_data;
-- 使用 ROW_NUMBER() 去重
WITH RowNumCTE AS (
SELECT *,
ROW_NUMBER() OVER(PARTITION BY customer_id, product_id, region ORDER BY id) AS row_num
FROM sales_data
)
SELECT id, sale_date, customer_id, product_id, quantity, price, total_amount, region
FROM RowNumCTE
WHERE row_num = 1;
-- 按区域分组计算总销售额
SELECT region, SUM(total_amount) AS total_sales FROM sales_data GROUP BY region;
-- 按产品分组计算总销售量
SELECT product_id, SUM(quantity) AS total_quantity FROM sales_data GROUP BY product_id;
-- 合并两个结果集
SELECT id, sale_date, customer_id, product_id, quantity, price, total_amount, region FROM sales_data
UNION
SELECT id, sale_date, customer_id, product_id, quantity, price, total_amount, region FROM another_sales_data;