
动态表简介
【预览发布】本功能当前处于受邀预览发布阶段。如果需要使用,请联系我们的技术支持同学协助处理。
什么是动态表
动态表(Dynamic Table)是云器Lakehouse的数据对象。创建时与表的区别是通过定义查询语句动态生成数据,刷新时自动获取Base Table的增量数据,采用增量算法进行计算,这样做的优势是大幅提升数据处理效率,尤其适用于处理大规模数据。
动态表应用场景
面向实时加工场景
在实时数据加工场景中,数据以持续且快速的方式流入系统。传统的数据处理方法,如完全重载(Full Reload)或全量刷新(Full Refresh),在性能和资源消耗方面可能不够高效,特别是在处理大规模数据流时。动态表采用增量计算方法,仅处理自上次更新以来变化的数据,从而显著减少了计算资源的消耗。
动态表的优势:
- 实时性:能够迅速将新数据变更反映到数据仓库中,保持数据的高新鲜度。
- 成本效益:通过设置合理的刷新间隔,可以平衡性能与成本,实现资源的最优利用。
- 资源弹性:Lakehouse的资源可以轻松实现弹性扩展,尤其在处理峰值数据流入时更具优势。
- 按需计算:未来Lakehouse将实现按需启动计算资源,即仅在有数据需要计算时才会启动相应资源,进一步提高效率和降低成本。
应用实例:
背景: 一家电子商务公司希望实时分析其销售数据,以便快速做出库存和定价决策。数据以高速率持续流入系统,需要一种高效的数据处理方法。
挑战:
- 传统的全量数据处理方法在性能和资源消耗方面效率低下,尤其是在高峰时段。
- 需要一种能够快速响应数据变更并保持数据新鲜的处理机制。
解决方案:
- 引入动态表,采用增量计算方法,仅处理自上次更新以来变化的数据。
动态表的优势:
-
实时性: 动态表能够迅速捕捉并反映数据变更,确保决策基于最新的销售数据。
-
成本效益:通过动态表,公司可以根据实际需求设置合理的数据刷新间隔,避免了不必要的计算资源浪费。
-
资源弹性:在促销活动或节假日等流量高峰时段,Lakehouse的资源可以按需扩展,以应对数据流入的峰值,而不必长期维持高额的资源配置。
-
按需计算:未来,Lakehouse的按需计算功能将进一步提高效率,仅在有数据需要计算时才启动资源,从而降低成本。
数据新鲜度要求较高的固定维度分析查询场景
在固定维度分析查询场景中,我们追求的是能够提供近乎实时的分析结果。传统的视图查询可以实现这一点,但如果涉及大量数据转换,则可能会导致查询速度变慢。为了解决这个问题,我们可以将转换后的结果进行物化,这样在查询时就可以直接返回这些结果,从而提高查询速度。物化结果可以采用传统的表格或者dynamic table。
使用传统的表可以提供最高的性能,因为它们在查询时只返回预先转换好的数据。但这种方法的缺点是,需要定期评估数据转换的时间,并通过调度进行全量计算,这通常会占用较长的时间。
dynamic table结合了增量计算的优势。通过仅更新自上次加载以来发生变化的记录,dynamic table不仅减少了每次构建的时间,通过缩短时间间隔还保持了数据的最新性。
注意事项
- 在处理源端大量变化数据时,计算任务可能接近全量计算的负载。尽管增量计算在效率上具有明显优势,但如果您设置的刷新间隔过短,可能会导致任务积压。这是因为每次刷新操作本身需要一定的时间来完成,如果这个时间超过了您设置的刷新间隔,将会导致后续刷新任务的排队等待。
- 建议:
- 合理设置刷新间隔:根据数据变更的频率和任务的刷新耗时,合理设置刷新间隔,以避免刷新操作的积压。
- 监控和调整:持续监控数据变更模式和系统性能,根据实际情况调整刷新间隔,以实现效率和资源的最优化利用。
- 建议:
- 在编写算子时,请参考《算子是如何增量刷新》中的注意事项来优化增量刷新任务。
动态表工作原理概述
如何获取变化的数据
- MetaService(元数据服务,Lakehouse 的一个组件服务)记录了 Lakehouse 里每张表的每一个历史数据版本
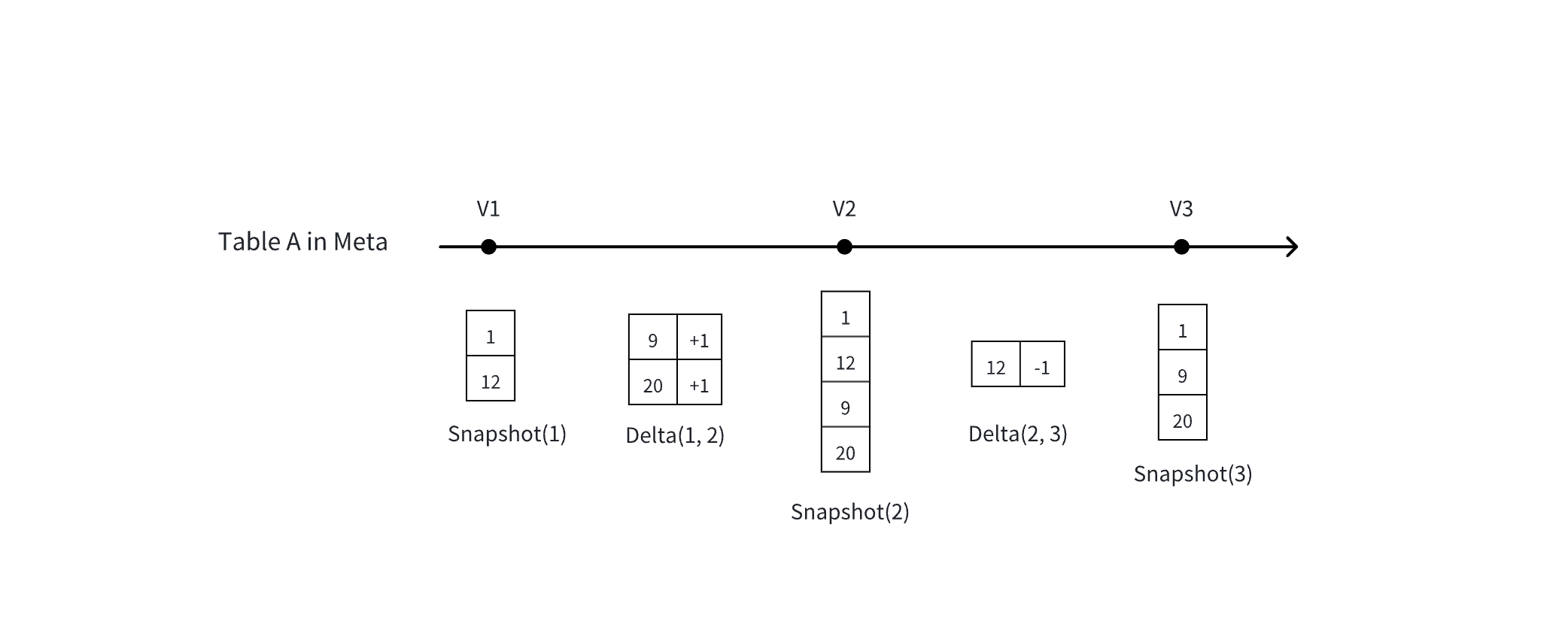
- 基本概念:一张表的 Snapshot(全量) VS Delta(变化)
Lakehouse Dynamic Table 刷新机制
Lakehouse 目前使用调度机制来更新 Dynamic Table。支持以下几种调度模式:
- 在 DDL 语句中定义调度属性
- 在 Lakehouse Studio 中定义调度
- 使用第三方调度引擎提交 Refresh 作业
| 使用方式 | 优点 | 缺点 | |
|---|---|---|---|
| DDL语句中定义调度属性 | 在refreshOption中定义刷新间隔,具体使用方式参考动态表创建文档。目前限制刷新间隔一分钟。 | 简单易用,可以快速设置刷新选项。不依赖任何第三方工具。 | 当前Lakehouse不支持在 Dynamic Table 上定义严格的上下游依赖关系。在 DDL 定义中依赖时间调度。可以通过时间间隔的方式先保证上游刷新完成再调度下游 |
| 在 Lakehouse Studio 中定义调度 | 可以在 Lakehouse Studio 中通过可视化界面配置调度,具体配置方式可以参考任务开发调度文档。目前限制刷新间隔一分钟。 | 可视化配置,用户友好。支持调度依赖配置,确保上游刷新完成后再刷新下游。支持单节点运行监控,如失败告警、超时告警等。 | |
| 使用第三方调度引擎提交 Refresh 作业 | 通过下载 Lakehouse 客户端命令,使用 cron 表达式定时提交 Refresh 任务。或者通过 Java Jdbc 接口自定义提交 Refresh 命令。 | 您可以更灵活地控制作业的提交和配置调度信息,时间间隔没有限制 | 需要依赖第三方调度。引入第三方调度系统 |
动态表和物化视图、普通视图的比较
从Lakehouse的实现机制上来看,动态表是基于传统的物化视图来演进的,虽然两者有一些共性,但是定位上存在很大区别
| 物化视图 | 动态表 | 普通视图 | |
|---|---|---|---|
| 定义 | 一种预计算并存储查询结果的特殊视图 | 专注于数据加工的高效工具 | 一种虚拟表,不存储数据,只保存查询定义 |
| 性能优化 | 显著提升查询效率,通过预存结果减少重复计算。其他 SQL可以利用该物化结果进行查询改写 | 虽然也可以提高查询效率,但是查询优化器不会进行查询改写 | 性能取决于底层数据表的查询效率,查询是计算逻辑每次重新计算 |
| 数据时效性 | 要求数据即时更新,以确保查询改写的准确性 | 注重数据加工灵活性,可调整数据滞后性 | 数据新鲜度每次都是最新的 |
| 更新机制 | 采用定时刷新机制,保持数据最新 | 根据业务定义调整,不强制实时更新 | 不存储数据无需更新 |
| 查询优化 | 优化器自动识别并使用预存结果 | 不依赖于查询优化器的自动重写 | |
| 使用场景 | 适合于预计算并复用查询结果的场景 | 适合数据加工,可能数据不是最新的 | 适合于查询复杂度不高不涉及大量加工,如果涉及大数据量和很多复杂算子,查询很慢,因为每次都是重新计算 |
| 运维 | 无复杂运维场景 | 动态表还支持了复杂的加列,版本回滚等功能 | 无复杂运维场景 |
动态表刷新监控
通过 SQL 命令查看刷新历史
您目前可以利用 SQL 命令来监控动态表的刷新历史。尽管该命令可能尚未全面上线,但您已经可以通过以下 SQL 语句来获取所有动态表的刷新情况概览:
过滤刷新历史
您可以使用 WHERE 子句来根据特定字段过滤信息,例如,要查看名为 my_dy 的动态表的刷新历史,可以使用以下命令:
| 字段名称 | 含义 |
|---|---|
| workspace_name | 工作空间名称 |
| schema_name | schema名称 |
| name | 动态表名字 |
| virtual_cluster | 使用的计算集群 |
| start_time | 刷新开始时间, |
| end_time | 刷新结束时间 |
| duration | 刷新耗时 |
| state | 作业状态,setup\resuming cluster\queued\running\success\failed |
| refresh_trigger | MANUAL(由用户调用refresh手动触发刷新,包含studio调度刷新) LH_SCHEDULED(由lakehouse调度刷新) |
| suspended_reson | 暂停调度原因 |
| refresh_mode | NO_DATA FULL INCREMENTAl |
| error_message | 刷新失败的信息,如果失败则会在这里有 |
| source_tables | 记录了dynamict table使用的表名称 |
| stats | 增量刷新条数等信息 |
| job_id | 作业ID,通过点击作业ID可以看到job profile |
通过Job Profile查看单个作业的刷新情况
除了 SQL 命令,您还可以通过 Job Profile 来查看单个作业的刷新详情
- 您也可以通过job profile的输入记录来判断是否是增量读取数据
动态表的成本
计算成本
动态表的刷新操作依赖于计算资源(Virtual Cluster)来执行,包括:
- 定时刷新:根据设定的时间间隔自动执行刷新。
- 手动刷新:用户根据需要手动触发刷新。
这些刷新操作均会消耗计算资源。
存储成本
动态表同样需要存储空间来保存其具体化结果。与常规表一样,动态表支持:
- Time Travel:允许用户访问过去7天内的任何时间点的数据。
- Time Travel 保留期限:默认设置为7天,超过此期限后,数据将无法通过Time Travel访问,并且会被物理删除。
注意:Time Travel 目前处于预览版,其默认保留周期为7天。在预览期间,用户可以免费查询7天内的数据版本,且不会对这段时间内的版本收费。预览期结束后,Lakehouse 将开始对使用 Time Travel 功能产生的存储费用进行单独计费。
刷新调度设置周期
刷新速度影响因素
增量刷新的速度主要取决于两个因素:
- 源数据的变更量:刷新操作需要处理的数据量越大,所需的时间就越长。
- 固定开销:无论数据变更量大小,每次刷新都会产生的一些基本开销。
商业价值与刷新频率
- 如果数据新鲜度对您的业务价值不是至关重要,可以考虑降低刷新频率。这种策略可以减少因频繁刷新带来的计算开销。
- 采用增量计算模式可以提高单次刷新的速度,因为它只处理自上次刷新以来发生变化的数据。
刷新成本与频率的平衡
- 刷新成本会随着刷新频率的增加而上升。因此,您需要在数据新鲜度所带来的商业价值和由此产生的计算成本之间做出权衡。
- 高频率的刷新操作虽然可以保持数据的实时更新,但累积的计算成本也会随之增加。
建议
- 评估您的业务需求,确定数据新鲜度对您业务的具体价值。
- 根据业务价值来设定合理的刷新频率,以优化成本效益。
- 利用增量计算模式来提高刷新效率,减少不必要的计算开销。
动态表限制
- 增量刷新限制:不支持非确定性函数,比如random、current_timestamp、current_date等
- 不支持直接修改动态表数据,比如执行update、delete、truncate数据
使用动态表加工案例
使用动态表加工Lakehouse提供的样例数据
Lakehouse 提供了一个名为 ecommerce_events_multicategorystore_live 的动态公共数据集,该数据集位于 clickzetta_sample_data.clickzetta_sample_data.ecommerce_events_history 路径下。这个数据集是实时更新的,并且可以被直接查询。
实时数据集可用性:目前,ecommerce_events_multicategorystore_live 实时写入的公共数据集只在阿里云的上海区域提供。如果您的账户或服务不在该区域,您将无法查询此公共数据集。
- 编写SQL脚本使用DDL定义调度加工数据
- 查看动态表刷新
使用命令查看动态表刷新
在作业历史中查看dynamic table刷新历史
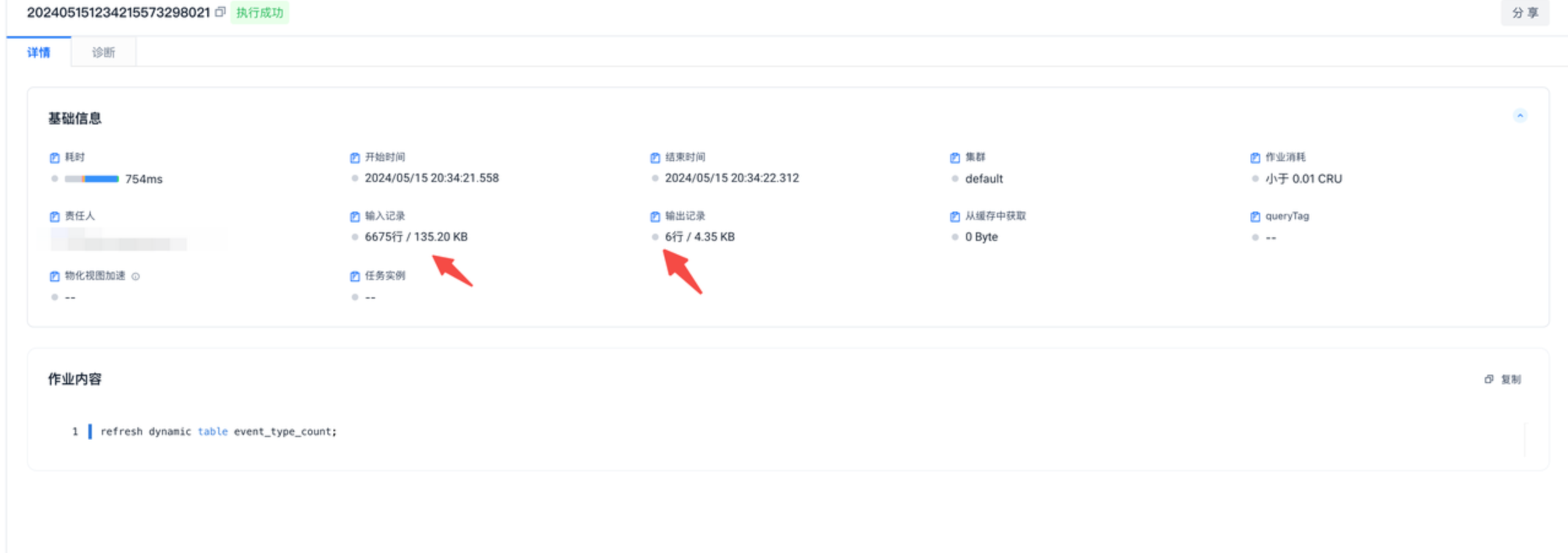
点进详情中可以查看输入记录可以看到获取了增量多少条,诊断中可以查看增量执行SQL的计划
- 在作业历史中看到增量刷新有数据后,可以查看数据变化
使用STUDIO刷新调度动态表刷新任务
在本次演示中,我们将通过以下步骤模拟增量数据的插入,并展示增量计算的效果:
- 模拟增量数据插入:使用
INSERT INTO语句将模拟数据插入到指定表中,以此来模拟实际业务场景中的增量数据更新。 - 利用 Studio 调度刷新:随后,我们将利用 Lakehouse Studio 的调度功能来触发和执行增量数据的刷新任务。
- 演示增量计算效果:通过上述步骤,我们旨在展示增量计算如何高效地处理新插入的数据,并将更新反映在最终的查询结果中。
- 数据准备
- 数据加工
-
新建SQL脚本“1.时间处理dt”,将准备的数据使用SQL创建dy进行加工
-
新建SQL脚本“2.聚合dy”,对上一步加工完的数据进行聚合操作
-
- 构建依赖和调度关系
-
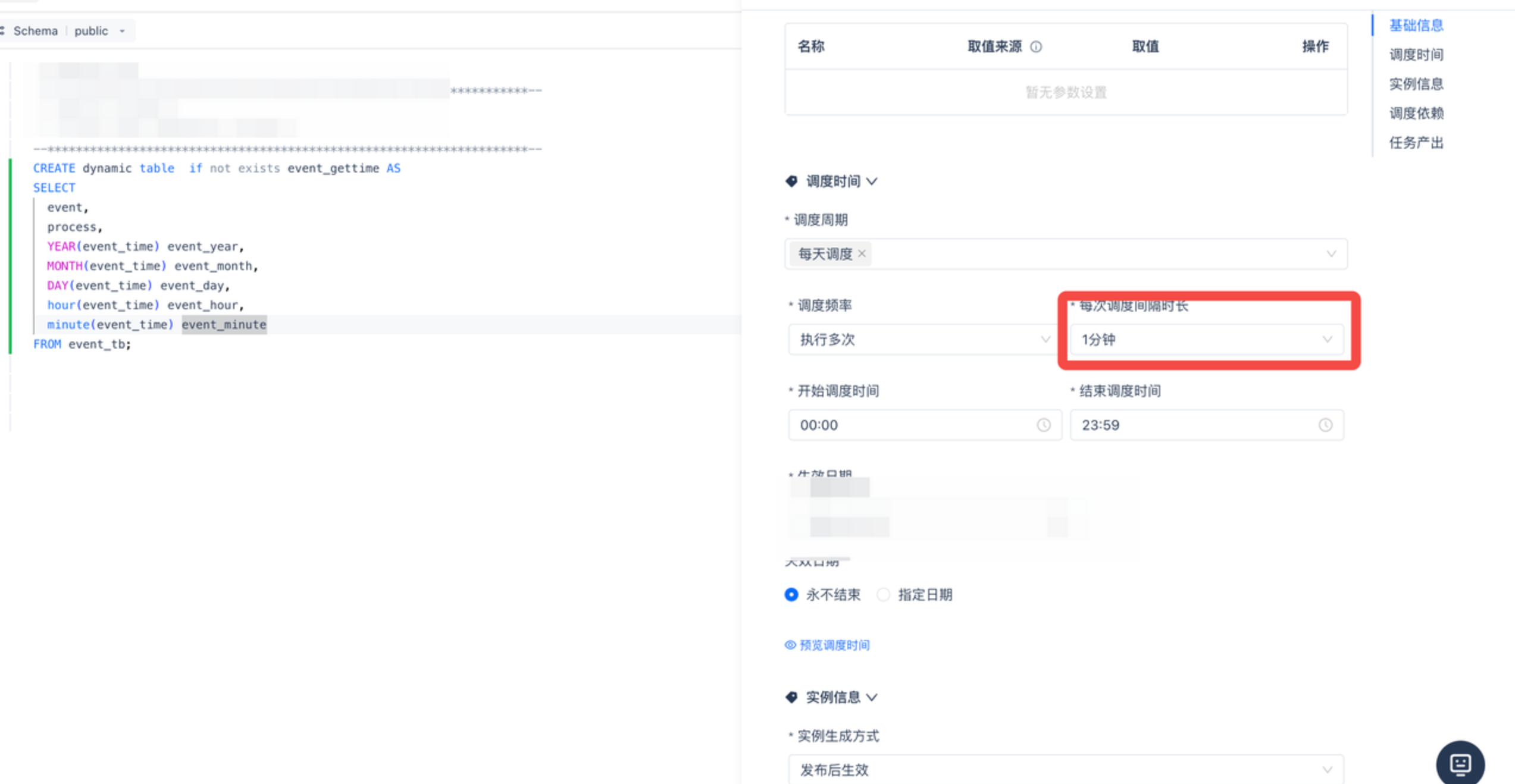
任务一“1.时间处理dt” 配置定时一分钟调度一次
-
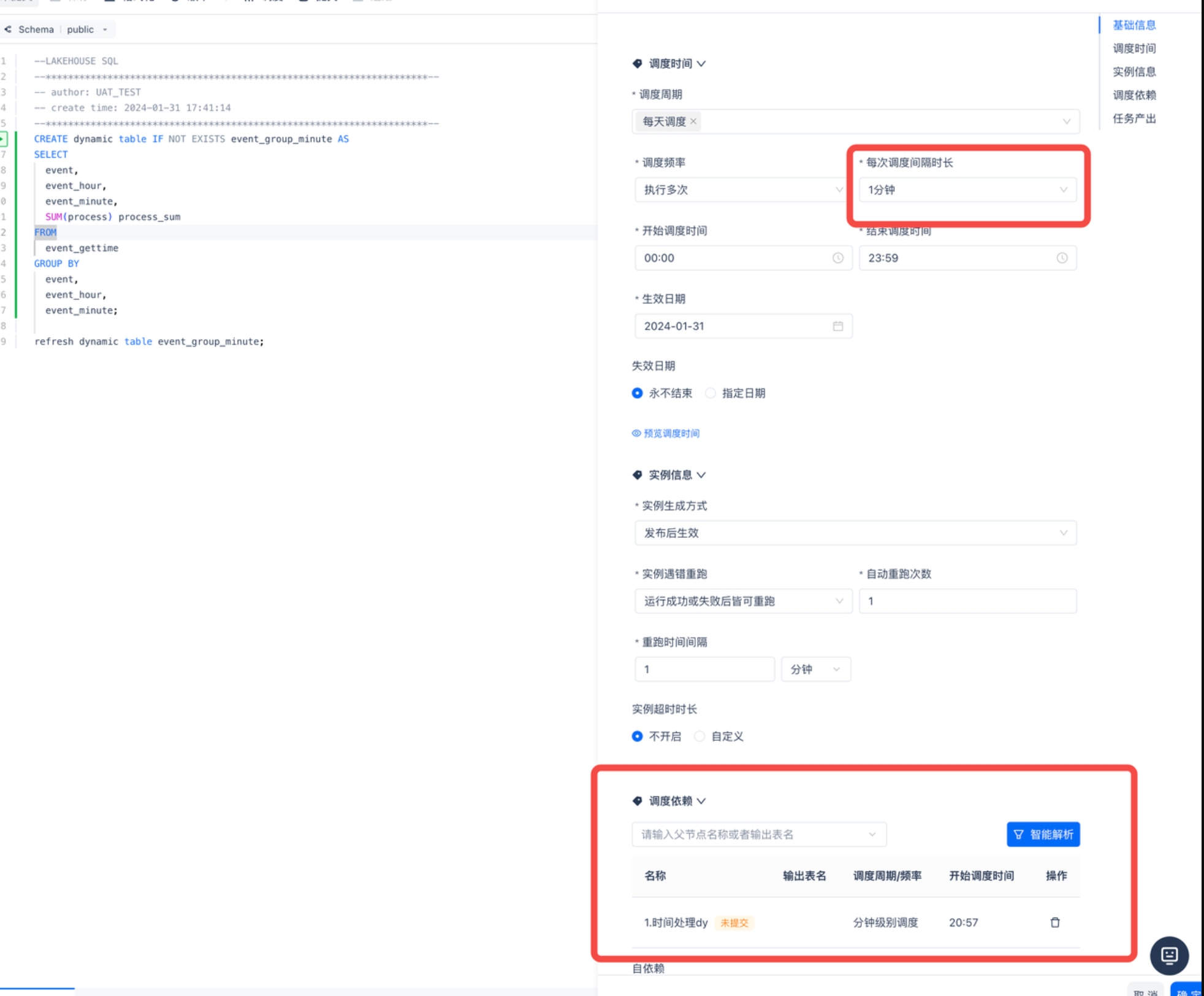
任务二“2.聚合dy” 按照任务一配置定时一分钟调度一次,并且在调度依赖中配置依赖任务一“1.时间处理dt”
-
在数据开发界面每个任务点击提交任务

- 查看是否增量刷新