
动态表简介
什么是动态表
动态表(Dynamic Table)是云器Lakehouse的数据对象。创建时与表的区别是通过定义查询语句动态生成数据,刷新时自动获取的Base Table的增量数据,采用增量算法来进行计算,这样做的优势是大幅提升数据处理效率,尤其适用于处理大规模数据。
Dynamic Table捕获源表变化的时效性
Dynamic Table根据源表对象的元数据修改提交时间来感知变化数据,源表发生变化并且完成元数据提交的变化可以被捕获,源表变化可能存在以下情况影响变化数据的时效性:
- DML方式修改数据:源表发生DML操作,DML任务成功结束后,源表变化数据可被Dynamic Table访问;
- 批量导入(Bulkload):源表有批量任务导入,在批量导入任务成功结束后,源表的变化数据可被Dynamic Table访问;
- 流式导入:源表通过Ingestion Service流式API写入数据,默认1Min提交变化,提交后源表的变化数据即可被Dynamic Table访问。注:对于流式写入的源表本身进行SQL查询时是实时可见,这里仅约束了基于该表的增量变化被Dynamic Table可见的时效。
动态表应用场景
不适用于增量场景
- 查询操作里存在大量数据排序需求,例如使用了 Orderby 子句。
- Window 函数需要对数据进行排序(RowNumber=1 的情况除外),并且增量数据中包含多个数据量特别大的 Partition。
- 数据缺乏良好的聚集性,无法通过 Joinkey、Aggregat key、Window partition key 等清晰地将冷数据和热数据区分开来。
- Aggregat key中目前支持的类型有CHAR、VARCHAR、STRING、TINYINT、SMALLINT、INT、BIGINT、DECIMAL、BOOLEAN、DATE如果有其他类型则不支持
面向实时加工场景
在实时数据加工场景中,数据以持续且快速的方式流入系统。传统的数据处理方法,如完全重载(Full Reload)或全量刷新(Full Refresh),在性能和资源消耗方面可能不够高效,特别是在处理大规模数据流时。动态表采用增量计算方法,仅处理自上次更新以来变化的数据,从而显著减少了计算资源的消耗。
动态表的优势:
- 实时性:能够迅速将新数据变更反映到数据仓库中,保持数据的高新鲜度。
- 成本效益:通过设置合理的刷新间隔,可以平衡性能与成本,实现资源的最优利用。
- 资源弹性:Lakehouse的资源可以轻松实现弹性扩展,尤其在处理峰值数据流入时更具优势。
- 按需计算:未来Lakehouse将实现按需启动计算资源,即仅在有数据需要计算时才会启动相应资源,进一步提高效率和降低成本。
应用实例:
背景: 一家电子商务公司希望实时分析其销售数据,以便快速做出库存和定价决策。数据以高速率持续流入系统,需要一种高效的数据处理方法。
挑战:
- 传统的全量数据处理方法在性能和资源消耗方面效率低下,尤其是在高峰时段。
- 需要一种能够快速响应数据变更并保持数据新鲜的处理机制。
解决方案:
- 引入动态表,采用增量计算方法,仅处理自上次更新以来变化的数据。
动态表的优势:
-
实时性: 动态表能够迅速捕捉并反映数据变更,确保决策基于最新的销售数据。
-
成本效益:通过动态表,公司可以根据实际需求设置合理的数据刷新间隔,避免了不必要的计算资源浪费。
-
资源弹性:在促销活动或节假日等流量高峰时段,Lakehouse的资源可以按需扩展,以应对数据流入的峰值,而不必长期维持高额的资源配置。
-
按需计算:未来,Lakehouse的按需计算功能将进一步提高效率,仅在有数据需要计算时才启动资源,从而降低成本。
数据新鲜度要求较高的固定维度分析查询场景
在固定维度分析查询场景中,我们追求的是能够提供近乎实时的分析结果。传统的视图查询可以实现这一点,但如果涉及大量数据转换,则可能会导致查询速度变慢。为了解决这个问题,我们可以将转换后的结果进行物化,这样在查询时就可以直接返回这些结果,从而提高查询速度。物化结果可以采用传统的表格或者dynamic table。
使用传统的表可以提供最高的性能,因为它们在查询时只返回预先转换好的数据。但这种方法的缺点是,需要定期评估数据转换的时间,并通过调度进行全量计算,这通常会占用较长的时间。
dynamic table结合了增量计算的优势。通过仅更新自上次加载以来发生变化的记录,dynamic table不仅减少了每次构建的时间,通过缩短时间间隔还保持了数据的最新性。
注意事项
- 在处理源端大量变化数据时,计算任务可能接近全量计算的负载。尽管增量计算在效率上具有明显优势,但如果你设置的刷新间隔过短,可能会导致任务积压。这是因为每次刷新操作本身需要一定的时间来完成,如果这个时间超过了你设置的刷新间隔,将会导致后续刷新任务的排队等待。
- 建议:
- 合理设置刷新间隔:根据数据变更的频率和任务的刷新耗时,合理设置刷新间隔,以避免刷新操作的积压。
- 监控和调整:持续监控数据变更模式和系统性能,根据实际情况调整刷新间隔,以实现效率和资源的最优化利用。
- 建议:
- 在编写算子时参考算子是如何增量刷新中的注意事项来优化增量刷新任务
不适合场景
- 涉及大量 Outer Join 操作,且 Outer Join 右表数据频繁变动。
- 是否存在大量数据排序操作(如使用 Order by)。
- Window 操作需对数据排序(RowNumber=1 情况除外),同时增量数据包含多个数据量极为庞大的 Partition。
- 数据是否具有良好的聚集特性,例如能否通过 Join key、Aggregate key 或 Window partition key 明确区分冷数据与热数据。
工作原理、刷新机制、成本与限制
以下内容在专门文档中有权威说明,本文不再重复:
- 增量计算原理(MVCC、Delta、算子级增量算法):见增量计算机制
- 与普通视图、普通表的区别、选型:见动态表(Dynamic Table)
- 刷新调度(DDL 刷新间隔 / Lakehouse Studio / 第三方调度引擎):见动态表(Dynamic Table)
- 刷新监控(
字段说明):见动态表(Dynamic Table)SHOW DYNAMIC TABLE REFRESH HISTORY - 成本与限制(计算/存储成本、非确定性函数限制、不可直接 DML):见动态表(Dynamic Table)
使用动态表加工Lakehouse提供的样例数据
Lakehouse 提供了一个名为
ecommerce_events_multicategorystore_liveclickzetta_sample_data.clickzetta_sample_data.ecommerce_events_history实时数据集可用性:目前,
ecommerce_events_multicategorystore_live- 编写SQL脚本使用DDL定义调度加工数据
- 查看动态表刷新
使用命令查看动态表刷新
在作业历史中查看dynamic table刷新历史
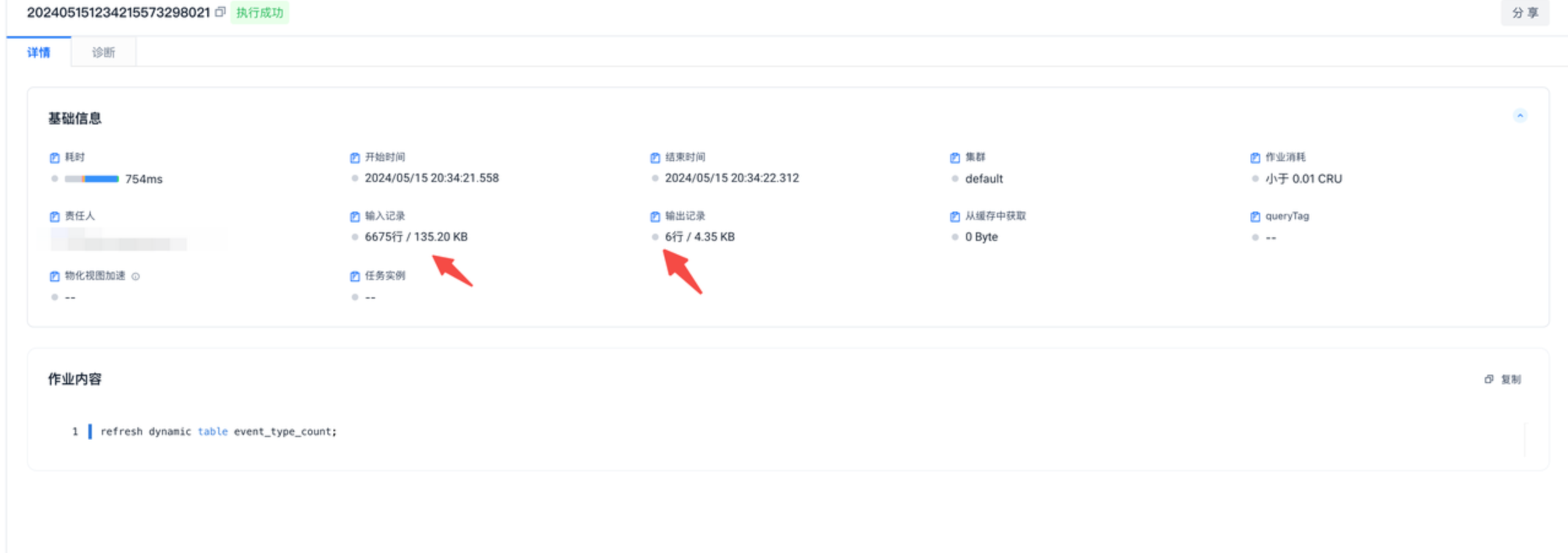
点进详情中可以查看输入记录可以看到获取了增量多少条,诊断中可以查看增量执行SQL的计划
- 在作业历史中看到增量刷新有数据后,可以查看数据变化
使用STUDIO刷新调度动态表刷新任务
在本次演示中,我们将通过以下步骤模拟增量数据的插入,并展示增量计算的效果:
- 模拟增量数据插入:使用
语句将模拟数据插入到指定表中,以此来模拟实际业务场景中的增量数据更新。INSERT INTO - 利用 Studio 调度刷新:随后,我们将利用 Lakehouse Studio 的调度功能来触发和执行增量数据的刷新任务。
- 演示增量计算效果:通过上述步骤,我们旨在展示增量计算如何高效地处理新插入的数据,并将更新反映在最终的查询结果中。
- 数据准备
- 数据加工
-
新建SQL脚本“1.时间处理dt”,将准备的数据使用SQL创建dy进行加工
-
新建SQL脚本“2.聚合dy”,对上一步加工完的数据进行聚合操作
-
- 构建依赖和调度关系
-
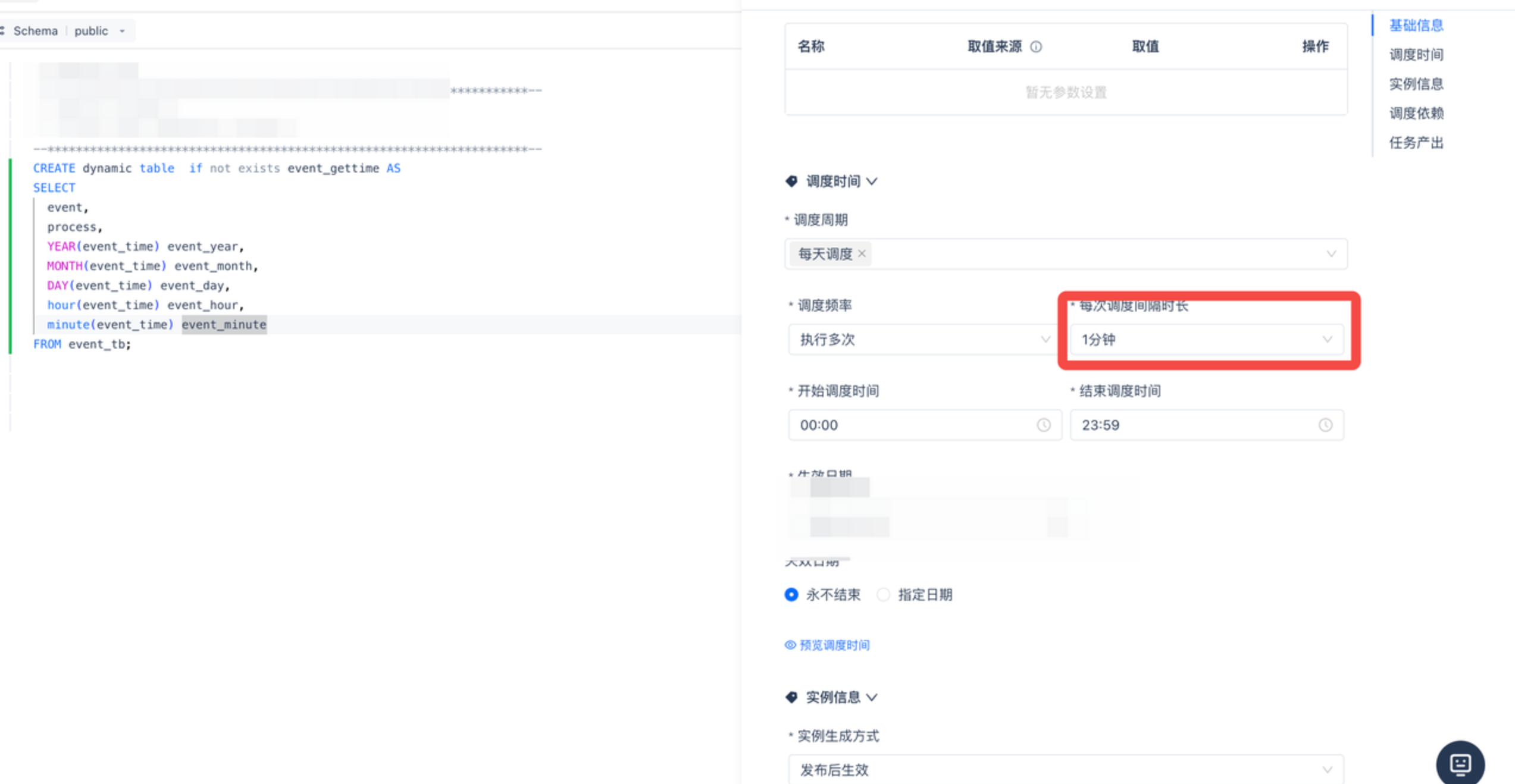
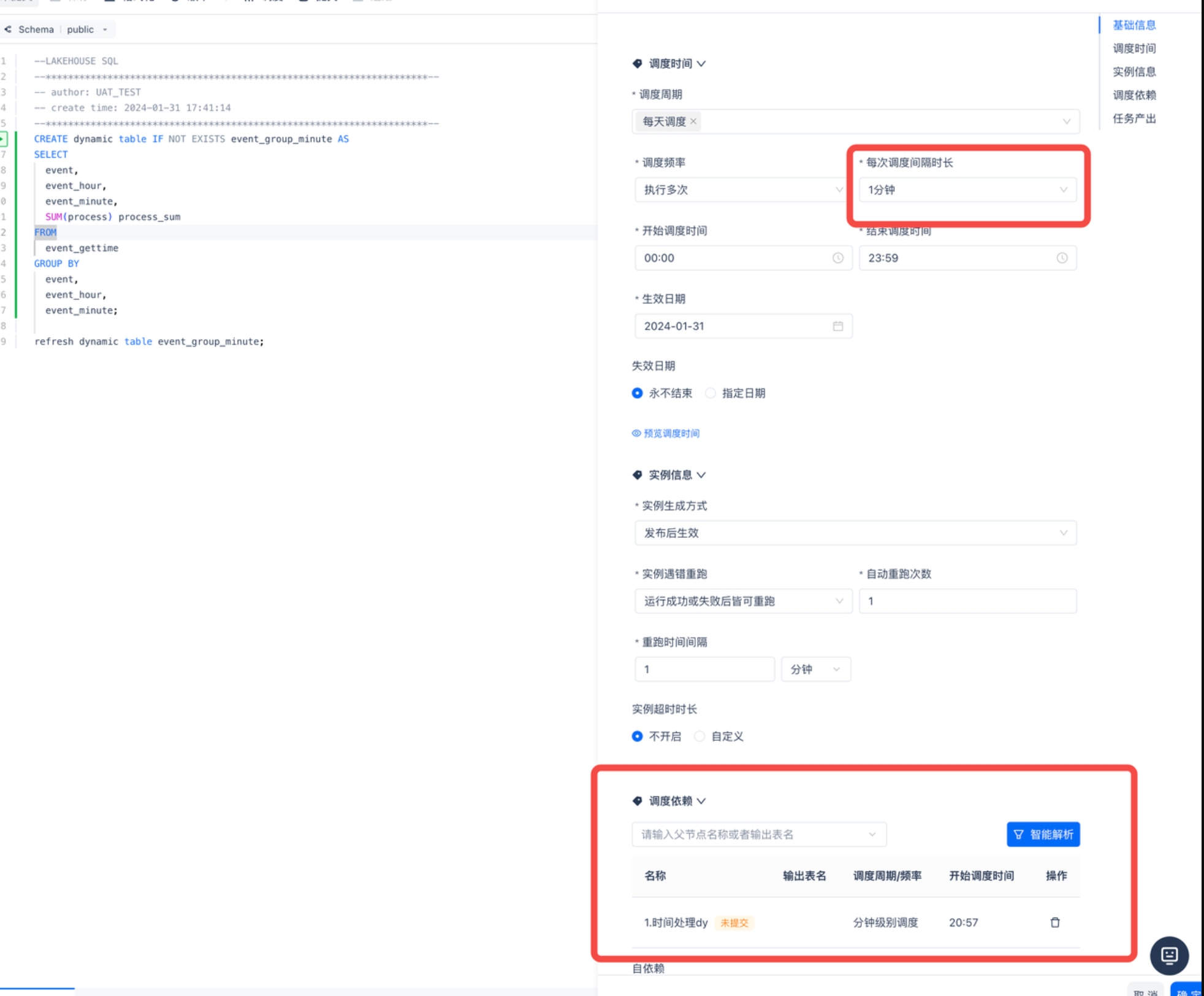
任务一“1.时间处理dy” 配置定时一分钟调度一次
-
任务二“2.聚合dy” 按照任务一配置定时一分钟调度一次并且在调度依赖中配置依赖任务一“1.时间处理dy”
-
在数据开发界面每个任务点击提交任务

- 查看是否增量刷新
使用动态表节点加工任务
使用方式参考动态表任务
约束限制
、CURRENT_TIMESTAMP()
、RAND()
、UUID()
等非确定性函数可以在动态表中使用,创建不报错,但不建议使用——会造成行间数据不一致。详细行为和替代方案见 动态表中的非确定性函数。CURRENT_DATE()- 建议使用GP型集群来刷新动态表。原因:动态表刷新过程中会根据内置策略自动执行小文件合并操作,而AP型集群不支持此功能。