
如何使用Zeppelin操作云器Lakehouse
简介
Zeppelin 是一款基于 Web 的 Notebook 工具,它支持多种数据处理后端和语言,可以让你轻松地进行交互式数据分析。通过使用 Zeppelin,你可以连接到云器 Lakehouse,执行 SQL 查询并创建数据驱动的交互式文档。
准备工作
-
安装 Zeppelin: 请访问 Zeppelin 官网 并按照指引完成安装。
-
配置 Zeppelin 以连接云器 Lakehouse: 你需要完成以下步骤来配置 Zeppelin 的 JDBC 解释器,以便连接到云器 Lakehouse。
2.1 首先,下载云器 Lakehouse 的 JDBC 驱动程序。
2.2 接下来,在 Zeppelin 页面上点击右上角的“anonymous”,在弹出的下拉列表中选择“Interpreter”。
2.3 点击右上角的“+Create”按钮,创建一个新的解释器。在 Interpreter Name 字段中输入“clickzetta”,并在 Interpreter 类型下拉菜单中选择“jdbc”。
2.4 在配置页面中,填写以下信息:
- default.url:填写云器 Lakehouse JDBC 连接串,格式如下:
jdbc:clickzetta://<instanceid>.api.clickzetta.com/<workspace_name>?virtualCluster=<vcluster>&schema=<schema> - default.driver:填写云器 Lakehouse JDBC 驱动程序的类名:
com.clickzetta.client.jdbc.ClickZettaDriver - 在 Artifact 部分,点击“Add”按钮并上传先前下载的 JDBC 驱动程序 JAR 文件。
2.5 完成配置后,点击“Save”按钮保存设置,并重启名为“clickzetta”的解释器。
- default.url:填写云器 Lakehouse JDBC 连接串,格式如下:
创建 Notebook 并访问云器 Lakehouse
-
新建一个名为“数据探查”的 Notebook,将 Default Interpreter 设置为“clickzetta”。
-
保存 Notebook 后,你可以在单元格中输入云器 Lakehouse 的 SQL 命令,然后点击“Run”按钮执行操作。
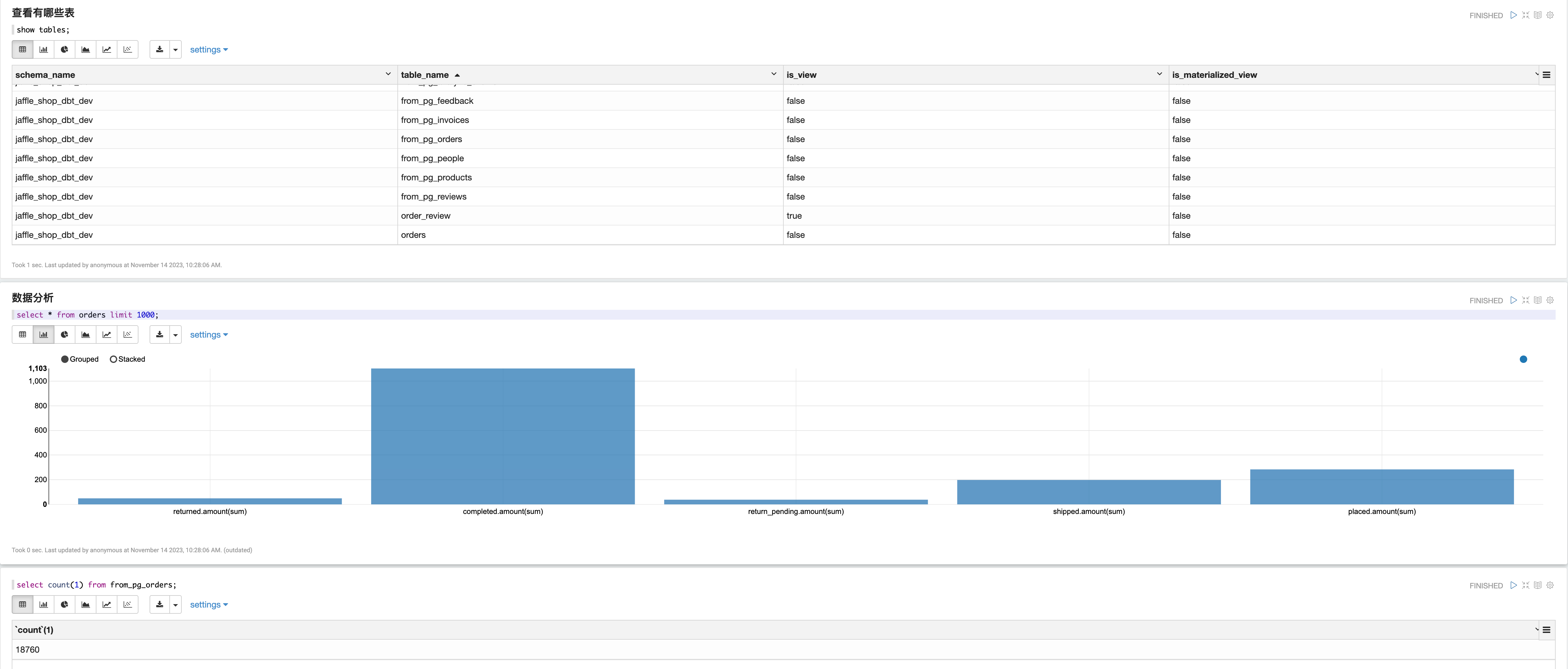
你可以参考以下命令进行操作:
- show tables:列出当前数据库中的所有表。
- select:查询表中的数据。
查看当前 workspace 中的计算资源(vCluster)和数据库 schema
-
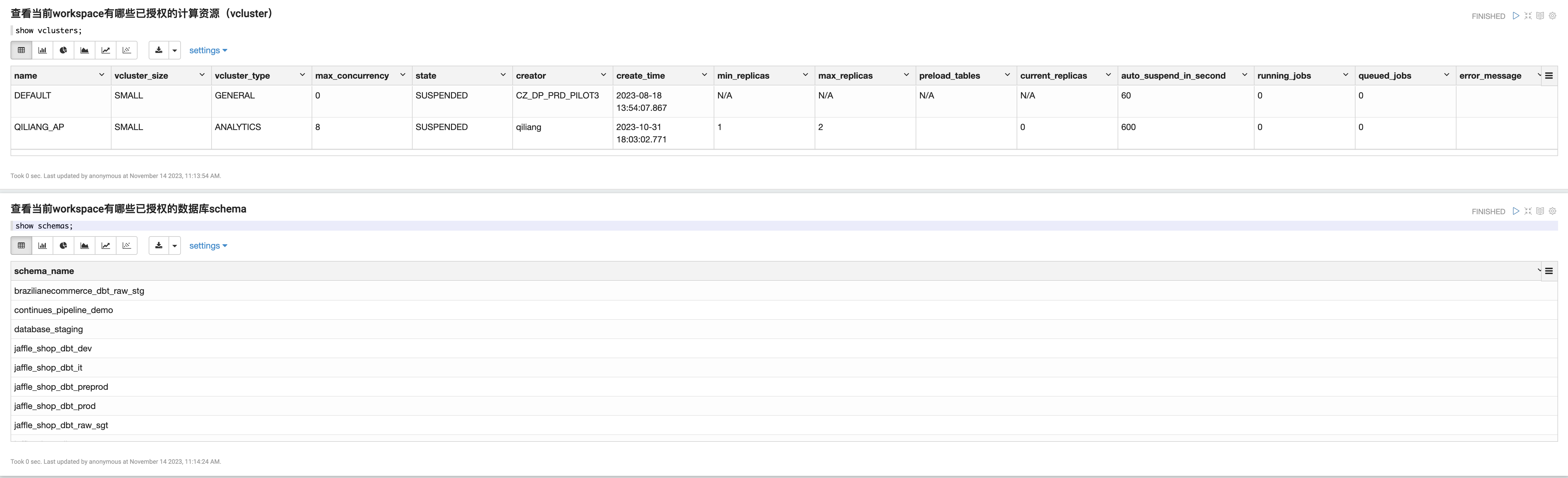
使用以下命令查看当前 workspace 中的计算资源(vCluster)列表:
-
使用以下命令查看当前 workspace 中的数据库 schema 列表:
切换作业执行的计算资源(vCluster)和数据 schema
-
使用以下命令切换作业执行的计算资源(vCluster):
例如:
-
使用以下命令切换要访问的数据 schema:
例如:
现在,你已经成功配置了 Zeppelin 并开始使用它来操作云器 Lakehouse。你可以继续探索更多 SQL 命令和数据可视化功能,以便更有效地分析和呈现数据。