
Lakehouse 快速入门体验
概要介绍
欢迎使用Lakehouse!本指南设计了一系列精心编排的体验项目,引导你循序渐进地了解Lakehouse的核心功能和优势。
本指南包含以下体验内容:

-
快速运行第一个SQL查询 (2-3分钟) 体验Lakehouse简单易用的SQL分析环境。
-
快速创建第二个计算集群 (3-6分钟) 了解如何创建和管理不同类型的计算资源。
-
存算分离架构体验 (5-8分钟) 体验计算资源和存储资源独立扩展,实现资源高效利用。
-
湖仓一体架构体验 (7-10分钟) 学习如何统一处理结构化和非结构化数据。
-
离线实时一体化体验 (5-7分钟) 体验在统一平台上同时处理批处理和流处理数据。
-
向量检索与倒排索引融合检索体验 (7-10分钟) 了解如何结合语义检索与关键词检索实现高效混合查询。
-
数据转换和分析 (5-8分钟) 体验灵活的数据处理和分析能力。
-
清理资源 (3分钟) 学习如何清理创建的资源,避免不必要的资源占用。
每个实践路径都有明确的操作步骤和预期结果,帮助你快速掌握Lakehouse的核心功能,体验其在数据处理和分析方面的强大能力。
准备工作
登录Lakehouse Studio并新建一个工作空间:
lakehouse_quick_experience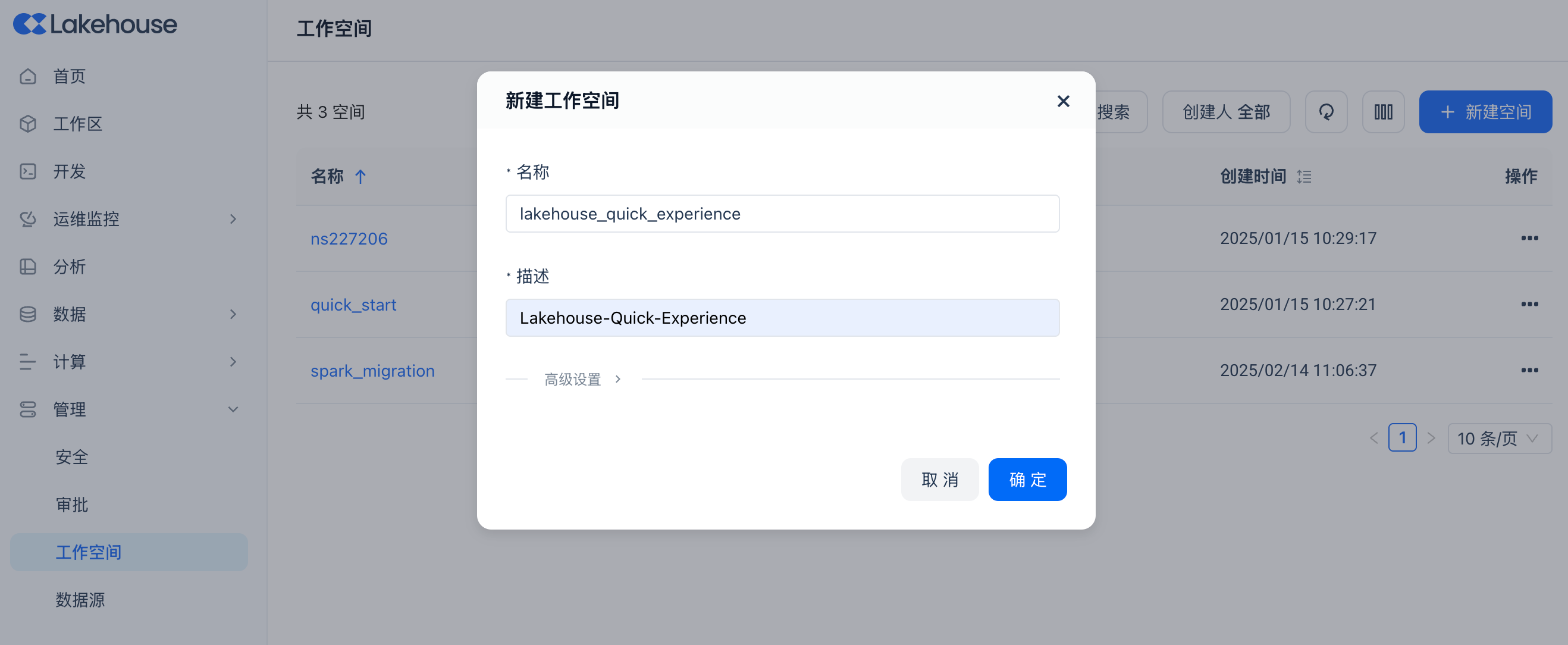
进入“开发”页面,并在右上角将工作空间切换为新建的工作空间。
创建新的SQL工作表入口:
创建一个新的SQL工作表,命名为“00_环境准备”。
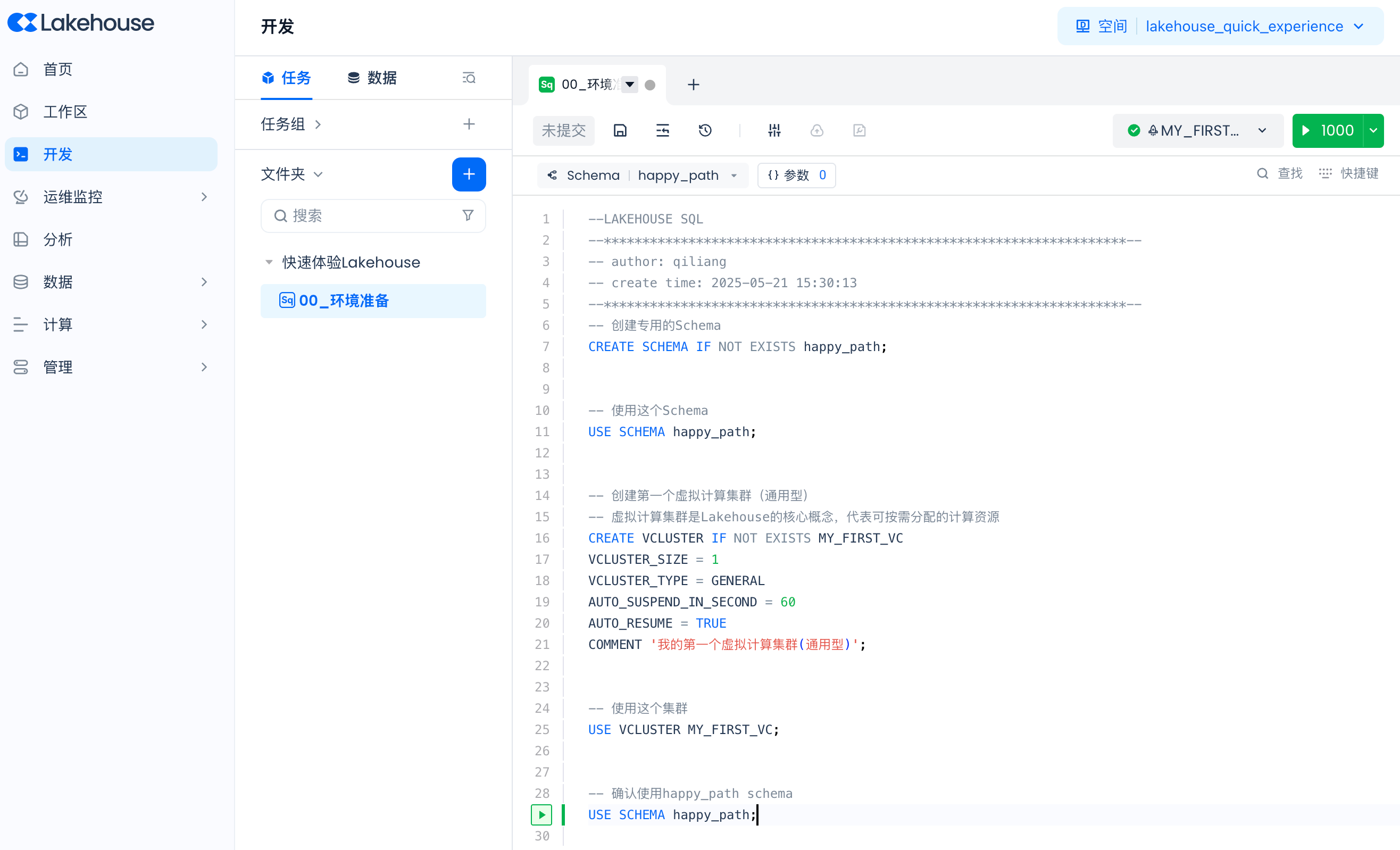
在开始体验前,我们需要创建一个专用的 Schema 和第一个虚拟计算集群。
-- 创建专用的Schema CREATE SCHEMA IF NOT EXISTS happy_path; -- 使用这个Schema USE SCHEMA happy_path; -- 创建第一个虚拟计算集群(通用型) -- 虚拟计算集群是Lakehouse的核心概念,代表可按需分配的计算资源 CREATE VCLUSTER IF NOT EXISTS MY_FIRST_VC VCLUSTER_SIZE = 1 VCLUSTER_TYPE = GENERAL AUTO_SUSPEND_IN_SECOND = 60 AUTO_RESUME = TRUE COMMENT '我的第一个虚拟计算集群(通用型)'; -- 使用这个集群 USE VCLUSTER MY_FIRST_VC; -- 确认使用happy_path schema USE SCHEMA happy_path;
💡 提示:虚拟计算集群 (Virtual Cluster) 虚拟计算集群是Lakehouse提供数据处理、分析的计算资源对象,提供执行SQL作业所需的CPU、内存、本地临时存储等资源。集群具备快速创建/销毁、扩容/缩容、暂停/恢复等特点,按照资源规格大小以及使用时长计费,暂停或删除后不产生费用。Lakehouse提供两种类型的集群:通用型(适合ETL数据加工)和分析型(适合查询分析)。
基础操作
1. 运行你的第一个SQL查询
在这个练习中,你将执行简单的SQL查询、创建表并进行基本分析。预计用时:2-3分钟。
-
登录 Lakehouse Studio
-
创建一个新的 SQL 工作表,命名为“01_我的第一个SQL”
-
执行以下SQL命令:
-- 使用已创建的虚拟集群和Schema USE VCLUSTER MY_FIRST_VC; USE SCHEMA happy_path; -- 简单查询 SELECT 1 as id, '你好,Lakehouse!' as greeting;
-
创建一个简单的表并插入数据:
-- 创建一个简单的产品表 CREATE TABLE IF NOT EXISTS happy_path.my_first_table ( product_id INT, product_name STRING, price DECIMAL(10,2), category STRING ); -- 插入一些示例数据 INSERT INTO happy_path.my_first_table VALUES (101, '高清智能电视', 3999.99, '电子产品'), (102, '无线蓝牙耳机', 799.00, '电子产品'), (103, '智能手表', 1299.50, '可穿戴设备'), (104, '便携式充电宝', 159.90, '配件'), (105, '机械键盘', 349.00, '电脑配件'); -- 查询刚插入的数据 SELECT * FROM happy_path.my_first_table;
-
运行一个聚合查询:
-- 按类别统计产品数量和平均价格 SELECT category, COUNT(*) as product_count, AVG(price) as avg_price, MIN(price) as min_price, MAX(price) as max_price FROM happy_path.my_first_table GROUP BY category ORDER BY avg_price DESC;
提示:你可以看到,无需任何复杂配置,就可以立即执行 SQL 查询、创建表、插入数据和进行分析,这体现了 Lakehouse 简单易用的特性。
2. 创建第二个计算集群
接下来,我们来创建一个不同类型的计算集群,了解如何根据不同场景选择合适的计算资源。预计用时:3-6分钟。
-
创建一个新的 SQL 工作表,命名为“02_创建分析型计算集群”
-
检查当前环境:
-- 确认当前使用的集群和Schema SELECT CURRENT_VCLUSTER(); USE SCHEMA happy_path;
-
创建分析型虚拟计算集群:
-- 创建分析型虚拟计算集群 -- 分析型集群优化了查询性能,适合低延时、高并发的分析场景 CREATE VCLUSTER IF NOT EXISTS MY_SECOND_VC VCLUSTER_SIZE = 1 VCLUSTER_TYPE = ANALYTICS AUTO_SUSPEND_IN_SECOND = 60 AUTO_RESUME = TRUE COMMENT '我的第二个虚拟计算集群(分析型)';
-
切换到新创建的集群并测试:
-- 使用分析型集群 USE VCLUSTER MY_SECOND_VC; USE SCHEMA happy_path; -- 创建一个简单的测试表 CREATE TABLE IF NOT EXISTS happy_path.simple_test ( id INT, name STRING, value DOUBLE ); -- 插入几行示例数据 INSERT INTO happy_path.simple_test VALUES (1, '产品A', 99.5), (2, '产品B', 150.75), (3, '产品C', 25.99); -- 查询刚插入的数据 SELECT * FROM happy_path.simple_test;
-
查看集群信息:
-- 查看当前使用的集群 SELECT CURRENT_VCLUSTER(); -- 查看所有集群 SHOW VCLUSTERS;
💡 提示:集群类型选择 通用型集群(GENERAL)支持纵向伸缩,满足ETL Pipeline类型的任务需求;分析型集群(ANALYTICS)支持集群内多副本(Replica)的横向伸缩,满足面向并发查询的弹性能力。建议使用通用型集群进行ETL数据加工,使用分析型集群进行查询分析或支持数据产品应用。
核心架构体验
3. 存算分离架构体验
存算分离是 Lakehouse 的核心架构特性,让你可以灵活调整计算资源而不影响数据存储。预计用时:5-8分钟。
-
创建一个新的 SQL 工作表,命名为“03_存算分离体验”
-
准备环境:
-- 使用第一个集群(通用型) USE VCLUSTER MY_FIRST_VC; USE SCHEMA happy_path;
-
创建测试数据集:
-- 创建一个用于测试的数据集 CREATE TABLE IF NOT EXISTS happy_path.demo_dataset ( id INT, value DOUBLE, text_data STRING, created_at TIMESTAMP ); -- 插入一些示例数据 INSERT INTO happy_path.demo_dataset VALUES (1, 123.45, 'Text-1', CURRENT_TIMESTAMP()), (2, 678.90, 'Text-2', CURRENT_TIMESTAMP()), (3, 246.80, 'Text-3', CURRENT_TIMESTAMP()), (4, 135.79, 'Text-4', CURRENT_TIMESTAMP()), (5, 975.31, 'Text-5', CURRENT_TIMESTAMP());
-
在第一个集群上查询数据:
-- 确认当前使用的集群 SELECT CURRENT_VCLUSTER(); -- 查询数据集 SELECT * FROM happy_path.demo_dataset ORDER BY id;
-
切换到第二个集群查询相同数据:
-- 切换到第二个集群(分析型) USE VCLUSTER MY_SECOND_VC; USE SCHEMA happy_path; -- 查询相同的数据集 SELECT * FROM happy_path.demo_dataset ORDER BY id;
-
在第二个集群上添加新数据:
-- 在第二个集群上添加新数据 INSERT INTO happy_path.demo_dataset VALUES (6, 432.10, 'Text-6', CURRENT_TIMESTAMP()), (7, 789.65, 'Text-7', CURRENT_TIMESTAMP()); -- 查询更新后的数据集 SELECT * FROM happy_path.demo_dataset ORDER BY id;
-
切换回第一个集群,查看数据变化:
-- 切换回第一个集群 USE VCLUSTER MY_FIRST_VC; USE SCHEMA happy_path; -- 查询数据,验证在另一个集群上添加的数据是否可见 SELECT * FROM happy_path.demo_dataset ORDER BY id;
💡 提示:存算分离架构 Lakehouse采用Single Engine All Data架构,将计算和存储分开,使系统能够更快地处理查询任务。这种架构使计算资源可以根据需求弹性调整,而数据存储在云对象存储中实现"无限扩展"。当不使用集群时,它会自动暂停以节省资源,需要时会自动恢复,有效降低总体拥有成本(TCO)。
4. 湖仓一体架构体验
湖仓一体架构允许你用统一的 SQL 直接查询多种格式的文件,无需复杂的 ETL 转换。预计用时:7-10分钟。
-
创建一个新的 SQL 工作表,命名为“04_湖仓一体体验”
-
准备环境:
-- 使用第一个集群(通用型),更适合大批量数据导入导出处理 USE VCLUSTER MY_FIRST_VC; USE SCHEMA happy_path;
-
创建并准备数据:
-- 创建一个产品信息表作为数据源 CREATE TABLE IF NOT EXISTS happy_path.products_for_lake ( product_id INT, product_name STRING, category STRING, price DECIMAL(10,2), stock_quantity INT, last_update_date DATE ); -- 插入示例数据 INSERT INTO happy_path.products_for_lake VALUES (201, '超薄笔记本电脑', '电脑', 6999.00, 45, DATE '2023-01-15'), (202, '游戏主机', '游戏设备', 3799.00, 30, DATE '2023-01-16'), (203, '无线鼠标', '电脑配件', 129.90, 100, DATE '2023-01-17'), (204, '智能音箱', '智能家居', 599.00, 60, DATE '2023-01-18'), (205, '蓝牙耳机', '音频设备', 899.00, 75, DATE '2023-01-19');
-
导出多种格式的文件到User Volume:
-- User Volume是Lakehouse提供的内部存储空间 -- 可以将表数据导出为不同格式,也可以直接查询这些文件 -- 1. 导出为CSV格式 COPY INTO USER VOLUME SUBDIRECTORY 'lake_demo/products_csv' FROM happy_path.products_for_lake FILE_FORMAT = (TYPE = CSV HEADER = TRUE) OVERWRITE = TRUE; -- 2. 导出为JSON格式 COPY INTO USER VOLUME SUBDIRECTORY 'lake_demo/products_json' FROM happy_path.products_for_lake FILE_FORMAT = (TYPE = JSON) OVERWRITE = TRUE; -- 3. 导出为Parquet格式 COPY INTO USER VOLUME SUBDIRECTORY 'lake_demo/products_parquet' FROM happy_path.products_for_lake FILE_FORMAT = (TYPE = PARQUET) OVERWRITE = TRUE; -- 查看User Volume中的文件 LIST USER VOLUME SUBDIRECTORY 'lake_demo';
-
创建销售记录表并导出为CSV格式:
-- 创建销售记录表 CREATE TABLE IF NOT EXISTS happy_path.sales_for_lake ( sale_id INT, product_id INT, sale_date DATE, quantity INT, total_amount DECIMAL(10,2), customer_id STRING ); -- 插入销售数据 INSERT INTO happy_path.sales_for_lake VALUES (1001, 201, DATE '2023-02-01', 1, 6999.00, 'C5001'), (1002, 203, DATE '2023-02-01', 2, 259.80, 'C5002'), (1003, 205, DATE '2023-02-02', 1, 899.00, 'C5003'), (1004, 204, DATE '2023-02-03', 1, 599.00, 'C5001'), (1005, 202, DATE '2023-02-03', 1, 3799.00, 'C5004'); -- 导出销售数据到User Volume (CSV格式) COPY INTO USER VOLUME SUBDIRECTORY 'lake_demo/sales_csv' FROM happy_path.sales_for_lake FILE_FORMAT = (TYPE = CSV HEADER = TRUE) OVERWRITE = TRUE; -- 查看所有导出的文件 LIST USER VOLUME SUBDIRECTORY 'lake_demo';
-
使用分析型集群直接查询不同格式文件:
-- 切换到分析型集群进行交互式查询 USE VCLUSTER MY_SECOND_VC; USE SCHEMA happy_path; -- 注意:根据实际导出文件名调整FILES参数 -- 1. 查询CSV格式文件 SELECT * FROM USER VOLUME USING csv OPTIONS('header'='true') FILES('lake_demo/products_csv/part00001.csv') LIMIT 5; -- 2. 查询JSON格式文件 SELECT * FROM USER VOLUME USING json FILES('lake_demo/products_json/part00001.json') LIMIT 5; -- 3. 查询Parquet格式文件 SELECT * FROM USER VOLUME USING parquet FILES('lake_demo/products_parquet/part00001.parquet') LIMIT 5;
-
联合查询不同格式的文件:
-- 联合查询Parquet格式的产品数据和CSV格式的销售数据 SELECT p.product_id, p.product_name, p.category, p.price, s.quantity as quantity_sold, s.total_amount as sales_amount FROM ( SELECT * FROM USER VOLUME USING parquet FILES('lake_demo/products_parquet/part00001.parquet') ) p JOIN ( SELECT * FROM USER VOLUME USING csv OPTIONS('header'='true') FILES('lake_demo/sales_csv/part00001.csv') ) s ON p.product_id = s.product_id ORDER BY sales_amount DESC;
⚠️ 注意:执行上述语句时,请确保文件路径和文件名与实际导出的文件一致。如果文件名不同,请根据
LIST USER VOLUME💡 提示:湖仓一体架构 Lakehouse作为湖仓一体化的数据平台,可以无缝连接云上对象存储,并利用一体化的数据处理引擎高效处理数据湖中的半结构化和非结构化数据。通过Volume对象,用户可以轻松将图片、文本等非结构化数据导入数据平台,并进行分析处理。湖仓一体架构将结构化和非结构化数据整合于统一的Catalog-Schema视图,解决统一的湖仓元数据管理和权限管理问题。
5. 离线实时一体化体验
Lakehouse 支持在同一平台上同时处理批处理数据和流处理数据,预计用时:5-7分钟。
-
创建一个新的 SQL 工作表,命名为“05_离线实时一体体验”
-
准备环境:
-- 使用第二个集群(分析型),更适合低延时的实时数据查询 USE VCLUSTER MY_SECOND_VC; USE SCHEMA happy_path;
-
创建历史订单表和实时订单表:
-- 创建历史订单表(代表离线批处理数据) CREATE TABLE IF NOT EXISTS happy_path.historical_orders ( order_id STRING, customer_id STRING, product_id STRING, order_amount DECIMAL(10,2), order_time TIMESTAMP, status STRING ); -- 插入几条历史订单数据 INSERT INTO happy_path.historical_orders VALUES ('ORD001', 'CUST001', 'PROD-A', 199.99, TIMESTAMP '2023-01-01 08:30:00', 'COMPLETED'), ('ORD002', 'CUST002', 'PROD-B', 59.95, TIMESTAMP '2023-01-01 09:15:00', 'COMPLETED'), ('ORD003', 'CUST001', 'PROD-C', 149.50, TIMESTAMP '2023-01-02 14:20:00', 'COMPLETED'); -- 创建实时订单表(代表实时流数据) CREATE TABLE IF NOT EXISTS happy_path.realtime_orders ( order_id STRING, customer_id STRING, product_id STRING, order_amount DECIMAL(10,2), order_time TIMESTAMP, status STRING );
-
创建统一视图:
-- 创建统一视图查看所有订单 CREATE OR REPLACE VIEW happy_path.all_orders AS SELECT order_id, customer_id, product_id, order_amount, order_time, status, 'historical' as data_source FROM happy_path.historical_orders UNION ALL SELECT order_id, customer_id, product_id, order_amount, order_time, status, 'realtime' as data_source FROM happy_path.realtime_orders;
-
查询统一视图:
-- 查询所有订单 SELECT * FROM happy_path.all_orders ORDER BY order_time DESC; -- 查看订单统计 SELECT data_source, COUNT(*) as order_count, SUM(order_amount) as total_amount FROM happy_path.all_orders GROUP BY data_source;
-
模拟实时数据写入:
-- 插入新的实时订单 INSERT INTO happy_path.realtime_orders VALUES ('ORD004', 'CUST003', 'PROD-B', 59.95, CURRENT_TIMESTAMP(), 'PENDING');
-
再次查询统计结果,查看变化:
-- 再次查询订单统计 SELECT data_source, COUNT(*) as order_count, SUM(order_amount) as total_amount FROM happy_path.all_orders GROUP BY data_source;
💡 提示:离线实时一体架构 Lakehouse支持在同一平台上同时处理批处理数据和流处理数据。通过统一视图,你可以同时查询历史数据和实时数据,当新数据插入后,它立即在统一视图中可见,无需等待批处理窗口或数据同步。这种架构大大简化了需要同时分析历史趋势和实时数据的应用场景。你也可以申请开通“动态表”功能,通过增量计算的实现方式来替代当前视图的方式。
6. 向量检索与倒排索引融合检索体验
Lakehouse 支持高效的向量检索和倒排索引检索,可用于实现语义搜索和关键词搜索的混合查询。预计用时:7-10分钟。
-
创建一个新的 SQL 工作表,命名为“06_融合检索体验”
-
准备环境:
-- 使用第二个集群(分析型),更适合低延时、高性能的向量检索场景 USE VCLUSTER MY_SECOND_VC; USE SCHEMA happy_path; -- 启用倒排索引预过滤功能 SET cz.sql.index.prewhere.enabled=true;
-
创建向量索引表:
-- 创建商品信息表,同时包含向量字段和文本字段 CREATE TABLE IF NOT EXISTS happy_path.product_search_demo ( product_id INT, product_name STRING, category STRING, description STRING, price DECIMAL(10,2), vec VECTOR(FLOAT, 16), -- 16维向量表示产品特征 -- 创建向量索引 INDEX product_vec_idx (vec) USING VECTOR PROPERTIES ( "scalar.type" = "f32", "distance.function" = "l2_distance" ), -- 创建倒排索引,用于全文检索 INDEX product_description_idx (description) INVERTED PROPERTIES ( 'analyzer' = 'chinese' ) );
-
插入示例数据:
-- 插入带有向量的示例数据 INSERT INTO happy_path.product_search_demo VALUES (1001, '超薄笔记本电脑', '电脑', '轻薄便携的高性能商务笔记本,搭载最新处理器和高清显示屏', 6999.00, vector(0.1, 0.2, 0.3, 0.4, 0.5, 0.1, 0.2, 0.3, 0.4, 0.5, 0.1, 0.2, 0.3, 0.4, 0.5, 0.1)), (1002, '专业游戏笔记本', '电脑', '高性能游戏本,搭载独立显卡,适合玩大型游戏和专业设计', 9999.00, vector(0.2, 0.3, 0.4, 0.5, 0.6, 0.2, 0.3, 0.4, 0.5, 0.6, 0.2, 0.3, 0.4, 0.5, 0.6, 0.2)), (1003, '商务办公台式机', '电脑', '稳定高效的办公台式电脑,适合企业和家庭办公环境使用', 4599.00, vector(0.3, 0.4, 0.5, 0.6, 0.7, 0.3, 0.4, 0.5, 0.6, 0.7, 0.3, 0.4, 0.5, 0.6, 0.7, 0.3)); -- 继续插入更多数据 INSERT INTO happy_path.product_search_demo VALUES (1004, '专业摄影相机', '数码设备', '高像素专业级单反相机,适合风景和人像摄影,画质清晰细腻', 12999.00, vector(0.4, 0.5, 0.6, 0.7, 0.8, 0.4, 0.5, 0.6, 0.7, 0.8, 0.4, 0.5, 0.6, 0.7, 0.8, 0.4)), (1005, '便携蓝牙音箱', '音频设备', '小巧便携的蓝牙音箱,音质清晰,续航时间长,适合户外使用', 299.00, vector(0.5, 0.6, 0.7, 0.8, 0.9, 0.5, 0.6, 0.7, 0.8, 0.9, 0.5, 0.6, 0.7, 0.8, 0.9, 0.5)), (1006, '无线降噪耳机', '音频设备', '主动降噪技术,无线连接,舒适佩戴,长时间使用不压耳', 1299.00, vector(0.6, 0.7, 0.8, 0.9, 1.0, 0.6, 0.7, 0.8, 0.9, 1.0, 0.6, 0.7, 0.8, 0.9, 1.0, 0.6)), (1007, '智能手表', '可穿戴设备', '支持心率监测、运动追踪和消息提醒的智能手表,兼容多种智能手机', 1599.00, vector(0.7, 0.8, 0.9, 1.0, 0.1, 0.7, 0.8, 0.9, 1.0, 0.1, 0.7, 0.8, 0.9, 1.0, 0.1, 0.7)); -- 继续插入其余数据 INSERT INTO happy_path.product_search_demo VALUES (1008, '健身追踪器', '可穿戴设备', '专业健身追踪手环,记录日常活动、睡眠质量和运动数据,防水设计', 399.00, vector(0.8, 0.9, 1.0, 0.1, 0.2, 0.8, 0.9, 1.0, 0.1, 0.2, 0.8, 0.9, 1.0, 0.1, 0.2, 0.8)), (1009, '超高清智能电视', '家用电器', '65英寸4K超高清智能电视,支持语音控制和各种流媒体应用', 5999.00, vector(0.9, 1.0, 0.1, 0.2, 0.3, 0.9, 1.0, 0.1, 0.2, 0.3, 0.9, 1.0, 0.1, 0.2, 0.3, 0.9)), (1010, '智能空气净化器', '家用电器', '高效过滤PM2.5和有害气体,智能监测空气质量,自动调节工作模式', 1899.00, vector(1.0, 0.1, 0.2, 0.3, 0.4, 1.0, 0.1, 0.2, 0.3, 0.4, 1.0, 0.1, 0.2, 0.3, 0.4, 1.0));
-
测试分词功能:
-- 测试中文分词效果 SELECT tokenize('专业高性能游戏笔记本电脑', MAP('analyzer', 'chinese', 'mode', 'smart'));
-
单独使用向量检索:
SELECT product_id, product_name, category, description, price, l2_distance(vec, vector(0.2, 0.3, 0.4, 0.5, 0.6, 0.2, 0.3, 0.4, 0.5, 0.6, 0.2, 0.3, 0.4, 0.5, 0.6, 0.2)) AS distance FROM happy_path.product_search_demo WHERE l2_distance(vec, vector(0.2, 0.3, 0.4, 0.5, 0.6, 0.2, 0.3, 0.4, 0.5, 0.6, 0.2, 0.3, 0.4, 0.5, 0.6, 0.2)) < 10 ORDER BY distance LIMIT 5;
-
单独使用倒排索引:
-- 使用倒排索引进行关键词搜索 - 查找描述中包含"高性能"的产品 SELECT product_id, product_name, category, description, price FROM happy_path.product_search_demo WHERE match_phrase(description, '高性能', MAP('analyzer', 'chinese')) ORDER BY price DESC;
-
向量和倒排索引融合检索:
-- 融合查询:找到类似于参考向量且描述中包含"游戏"的产品 SELECT product_id, product_name, category, description, price, l2_distance(vec, vector(0.2, 0.3, 0.4, 0.5, 0.6, 0.2, 0.3, 0.4, 0.5, 0.6, 0.2, 0.3, 0.4, 0.5, 0.6, 0.2)) AS distance FROM happy_path.product_search_demo WHERE match_phrase(description, '游戏', MAP('analyzer', 'chinese')) AND l2_distance(vec, vector(0.2, 0.3, 0.4, 0.5, 0.6, 0.2, 0.3, 0.4, 0.5, 0.6, 0.2, 0.3, 0.4, 0.5, 0.6, 0.2)) < 10 ORDER BY distance LIMIT 5;
-
复杂的混合查询场景:
-- 查找价格在500-10000元之间,描述中包含"高性能"或"专业",并且向量相似度高的产品 SELECT product_id, product_name, category, description, price, l2_distance(vec, vector(0.2, 0.3, 0.4, 0.5, 0.6, 0.2, 0.3, 0.4, 0.5, 0.6, 0.2, 0.3, 0.4, 0.5, 0.6, 0.2)) AS distance FROM happy_path.product_search_demo WHERE price BETWEEN 500 AND 10000 AND (match_phrase(description, '高性能', MAP('analyzer', 'chinese')) OR match_phrase(description, '专业', MAP('analyzer', 'chinese'))) AND l2_distance(vec, vector(0.2, 0.3, 0.4, 0.5, 0.6, 0.2, 0.3, 0.4, 0.5, 0.6, 0.2, 0.3, 0.4, 0.5, 0.6, 0.2)) < 10 ORDER BY distance LIMIT 5;
7. 离线批量体验
Lakehouse 支持离线批量处理和转换。预计用时:7-10分钟。
- 创建一个新的 SQL 工作表,命名为“07_批量处理和转换体验”
- 准备环境:
-- 使用第一个集群(通用型),更适合批量数据处理和转换 USE VCLUSTER MY_FIRST_VC; USE SCHEMA happy_path;
-
创建并填充销售数据表:
-- 创建并填充销售数据表 CREATE TABLE IF NOT EXISTS happy_path.sales_data ( sale_id INT, customer_id STRING, product_id STRING, category STRING, amount DECIMAL(10,2), date_time TIMESTAMP ); -- 插入模拟销售数据 INSERT INTO happy_path.sales_data VALUES (1, 'CUST-10', 'PROD-23', '电子产品', 399.99, DATEADD(DAY, -29, CURRENT_TIMESTAMP())), (2, 'CUST-15', 'PROD-41', '服装', 129.50, DATEADD(DAY, -27, CURRENT_TIMESTAMP())), (3, 'CUST-10', 'PROD-11', '食品', 79.99, DATEADD(DAY, -25, CURRENT_TIMESTAMP())), (4, 'CUST-22', 'PROD-35', '家居用品', 249.00, DATEADD(DAY, -23, CURRENT_TIMESTAMP())), (5, 'CUST-31', 'PROD-18', '图书', 45.95, DATEADD(DAY, -20, CURRENT_TIMESTAMP())), (6, 'CUST-10', 'PROD-24', '电子产品', 599.00, DATEADD(DAY, -18, CURRENT_TIMESTAMP())), (7, 'CUST-18', 'PROD-42', '服装', 89.95, DATEADD(DAY, -15, CURRENT_TIMESTAMP())), (8, 'CUST-27', 'PROD-12', '食品', 105.50, DATEADD(DAY, -12, CURRENT_TIMESTAMP())), (9, 'CUST-22', 'PROD-36', '家居用品', 179.99, DATEADD(DAY, -9, CURRENT_TIMESTAMP())), (10, 'CUST-15', 'PROD-19', '图书', 38.50, DATEADD(DAY, -6, CURRENT_TIMESTAMP())), (11, 'CUST-31', 'PROD-25', '电子产品', 1299.00, DATEADD(DAY, -3, CURRENT_TIMESTAMP())), (12, 'CUST-10', 'PROD-43', '服装', 159.95, DATEADD(DAY, -1, CURRENT_TIMESTAMP()));
-
创建日期维度表:
-- 创建日期维度表 CREATE TABLE IF NOT EXISTS happy_path.date_dim AS SELECT DISTINCT date_time::DATE as date_id, YEAR(date_time) as year, MONTH(date_time) as month, DAY(date_time) as day, DAYOFWEEK(date_time) as day_of_week, CASE WHEN DAYOFWEEK(date_time) IN (6, 7) THEN true ELSE false END as is_weekend FROM happy_path.sales_data; -- 查看日期维度 SELECT * FROM happy_path.date_dim ORDER BY date_id;
-
创建销售汇总表:
-- 创建销售汇总表 CREATE TABLE IF NOT EXISTS happy_path.sales_summary AS SELECT d.date_id, d.year, d.month, s.category, COUNT(*) as transaction_count, COUNT(DISTINCT s.customer_id) as customer_count, SUM(s.amount) as total_sales, AVG(s.amount) as avg_transaction_value FROM happy_path.sales_data s JOIN happy_path.date_dim d ON DATE(s.date_time) = d.date_id GROUP BY d.date_id, d.year, d.month, s.category; -- 查看汇总数据 SELECT * FROM happy_path.sales_summary ORDER BY date_id DESC, total_sales DESC;
-
切换到分析型集群进行交互式分析:
-- 切换到分析型集群进行交互式分析 USE VCLUSTER MY_SECOND_VC; USE SCHEMA happy_path;
-
使用窗口函数进行高级分析:
-- 使用窗口函数分析销售趋势 SELECT date_id, category, total_sales, LAG(total_sales) OVER (PARTITION BY category ORDER BY date_id) as prev_day_sales, total_sales - LAG(total_sales) OVER (PARTITION BY category ORDER BY date_id) as daily_change, SUM(total_sales) OVER (PARTITION BY category ORDER BY date_id ROWS BETWEEN 6 PRECEDING AND CURRENT ROW) as rolling_7day_sales FROM happy_path.sales_summary ORDER BY category, date_id DESC;
-
创建业务洞察视图:
-- 创建业务洞察视图 CREATE OR REPLACE VIEW happy_path.business_insights AS SELECT category, year, month, SUM(total_sales) as monthly_sales, COUNT(DISTINCT date_id) as active_days, SUM(total_sales) / COUNT(DISTINCT date_id) as avg_daily_sales, SUM(customer_count) as total_customers, SUM(total_sales) / NULLIF(SUM(customer_count), 0) as sales_per_customer FROM happy_path.sales_summary GROUP BY category, year, month; -- 查询业务洞察 SELECT * FROM happy_path.business_insights ORDER BY year DESC, month DESC, monthly_sales DESC;
-
销售排名与占比分析:
-- 分析各品类的销售排名与占比 SELECT category, SUM(total_sales) as category_sales, RANK() OVER (ORDER BY SUM(total_sales) DESC) as sales_rank, SUM(total_sales) / SUM(SUM(total_sales)) OVER () * 100 as sales_percentage, SUM(customer_count) as category_customers, RANK() OVER (ORDER BY SUM(customer_count) DESC) as customer_rank, SUM(customer_count) / SUM(SUM(customer_count)) OVER () * 100 as customer_percentage FROM happy_path.sales_summary GROUP BY category ORDER BY category_sales DESC;
💡 提示:集群负载优化 在数据处理流程中,可以根据不同的操作类型选择合适的集群类型:通用型集群更适合批量数据处理和转换任务,如 ETL 操作、数据清洗和聚合计算;分析型集群则更适合交互式查询和分析,特别是需要快速响应的仪表盘和报表场景。通过合理分配计算负载,可以优化资源使用并提高整体性能。
清理资源
完成体验后,建议清理创建的资源,以避免不必要的资源占用。预计用时:3分钟。
-
创建一个新的 SQL 工作表,命名为“10_清理环境”
-
准备环境:
-- 使用第一个集群(通用型) USE VCLUSTER MY_FIRST_VC; USE SCHEMA happy_path;
-
清理数据表:
-- 列出所有创建的表 SHOW TABLES; -- 删除创建的表 DROP TABLE IF EXISTS happy_path.my_first_table; DROP TABLE IF EXISTS happy_path.simple_test; DROP TABLE IF EXISTS happy_path.demo_dataset; DROP TABLE IF EXISTS happy_path.products_for_lake; DROP TABLE IF EXISTS happy_path.sales_for_lake; DROP TABLE IF EXISTS happy_path.sales_data; DROP TABLE IF EXISTS happy_path.historical_orders; DROP TABLE IF EXISTS happy_path.realtime_orders; DROP TABLE IF EXISTS happy_path.date_dim; DROP TABLE IF EXISTS happy_path.sales_summary; DROP TABLE IF EXISTS happy_path.product_search_demo;
-
清理创建的视图:
-- 列出所有创建的视图 SHOW TABLES WHERE IS_VIEW=TRUE; -- 删除创建的视图 DROP VIEW IF EXISTS happy_path.all_orders; DROP VIEW IF EXISTS happy_path.business_insights;
-
清理User Volume中的文件:
-- 查看User Volume中的文件 LIST USER VOLUME SUBDIRECTORY 'lake_demo'; -- 删除User Volume中的演示文件 REMOVE USER VOLUME 'lake_demo'; -- 再次检查确认文件已删除 LIST USER VOLUME SUBDIRECTORY 'lake_demo';
-
切换到默认集群:
-- 切换到默认集群,确保不在要删除的集群上执行删除操作 USE VCLUSTER DEFAULT;
-
清理虚拟集群:
-- 删除之前创建的虚拟集群 DROP VCLUSTER IF EXISTS MY_FIRST_VC; DROP VCLUSTER IF EXISTS MY_SECOND_VC;
-
最后清理创建的schema:
-- 删除我们创建的happy_path schema DROP SCHEMA IF EXISTS happy_path;
⚠️ 注意事项:>
- 清理前请确认演示体验已全部完成
- 如果你打算继续使用某些资源,可以选择性地跳过相应的删除命令
- 虚拟集群删除前,必须先切换到另一个集群,否则无法删除当前正在使用的集群
- 如果你有重要数据,请在删除前做好备份
总结与推荐路径
恭喜你完成了Lakehouse的功能体验!通过这些练习,你已经了解了Lakehouse的核心特性,包括简单易用的SQL环境、灵活的计算资源管理、存算分离架构、湖仓一体化、离线实时一体化以及强大的检索能力。
根据你的角色和兴趣,以下是推荐的学习路径:
数据分析师:
- 运行你的第一个 SQL 查询
- 创建第二个计算集群
- 湖仓一体架构体验
- 数据转换和分析
数据工程师:
- 运行你的第一个 SQL 查询
- 创建第二个计算集群
- 湖仓一体架构体验
- 离线实时一体化体验
- 数据转换和分析
数据架构师/管理人员:
- 运行你的第一个 SQL 查询
- 创建第二个计算集群
- 存算分离架构体验
- 湖仓一体架构体验
- 离线实时一体化体验
现在你可以开始将Lakehouse应用到实际业务场景中,享受简单高效的数据处理和分析体验!