
指标与答案构建器
当 AI 回答涉及计算逻辑的问题时,如果没有预定义的公式,模型每次都可能生成不同的 SQL,导致同一指标出现口径不一致的情况。指标和答案构建器解决的就是这个问题——把计算逻辑固化下来,让模型直接引用,而不是临时推断。
什么时候用指标,什么时候用答案构建器?
| 场景 | 推荐 | 原因 |
|---|---|---|
| 单表聚合,如 SUM、AVG、COUNT | 指标 | 配置简单,支持别名和同环比 |
| 需要多表 JOIN | 答案构建器 | 指标不支持多表,需要写完整 SQL 模板 |
| 有复杂过滤条件(如只统计有效订单) | 答案构建器 | 过滤逻辑写在 SQL 模板的 WHERE 中 |
| 明细查询(非聚合,返回行级数据) | 答案构建器 | 指标只支持聚合计算 |
它们对问答准确性的作用
指标和答案构建器不是“展示配置”,而是影响 AI 如何理解问题、选择 SQL 和稳定复用口径的关键配置。
实际配置分析域时,健康度扫描会检查“域内是否存在指标”。如果域内没有指标,系统会给出异常项,提示这可能影响问答正确性。这说明指标不是可选的装饰项,而是推荐上线前至少配置核心指标。
| 配置 | 对问答的作用 | 不配置时的常见问题 |
|---|---|---|
| 指标 | 固化常用聚合口径,减少模型临时生成 SQL 的不确定性。 | 同一个“销售额”“账户数”等问题可能每次生成不同 SQL。 |
| 指标别名 | 让模型理解同一指标的不同叫法。 | 用户说“客单价”“人均消费”“ARPU”等业务词时,可能匹配不到正确指标。 |
| 答案构建器 | 固化复杂 SQL、JOIN、过滤、明细查询或多指标组合。 | 复杂问题依赖模型临时推理,容易漏 JOIN、漏过滤条件或分组错误。 |
| Filters / Dims | 约束用户提问时哪些字段可作为筛选条件和维度。 | 用户要求“按地区”“按时间”“只看有效订单”时,系统可能不知道哪些列可以使用。 |
一个实用判断是:如果问题可以用单表、单个聚合函数稳定表达,优先做成指标;如果需要完整 SQL 逻辑、多个字段、多表 JOIN 或明细返回,使用答案构建器。
创建指标
在左侧导航栏 数据 -> 指标 中,点击 + 新建指标。支持聚合与自定义代码两种方式。
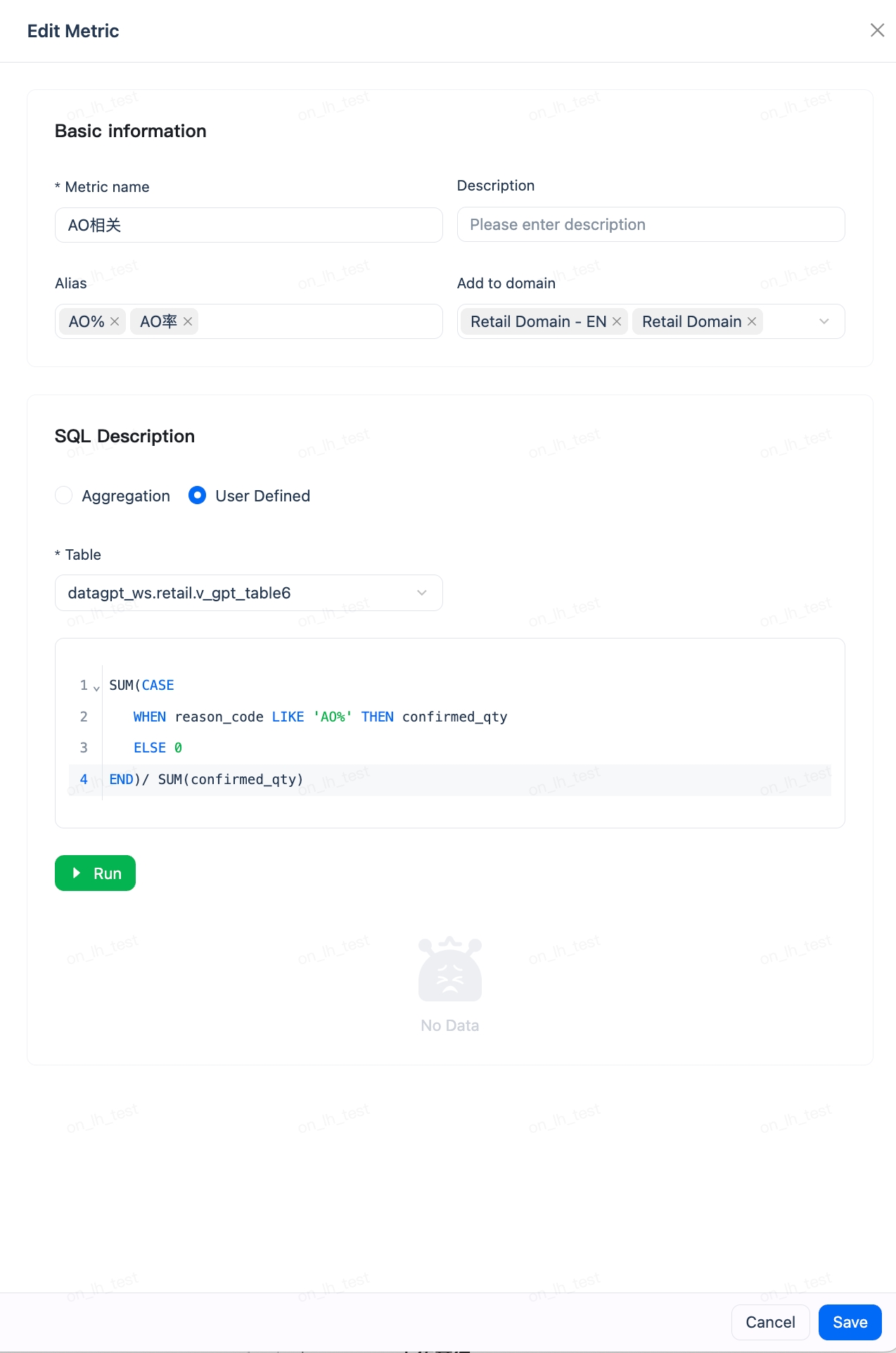
一个指标模板中可以定义多个指标,每个指标可以添加多个别名,让模型理解同一概念的不同叫法(如"客单价"和"人均消费")。
在分析域中添加指标
除了从左侧导航 数据 -> 指标 创建全局指标,也可以在分析域管理页中配置指标:
- 进入 分析域管理。
- 打开 数据 页签。
- 点击顶部卡片中的 指标。
- 点击 添加指标。
实际页面提供三种入口:
| 入口 | 说明 |
|---|---|
| 自动生成指标 | 选择表后由系统生成简单指标建议。 |
| 新建指标 | 手动创建指标。 |
| 选择已有指标 | 将已经创建好的指标加入当前分析域。 |
“自动生成指标”适合快速启动。页面会先要求选择表,然后点击 生成指标。系统会基于字段类型和字段用途生成候选指标,例如计数、求和、平均值、最大值、最小值。
需要注意:自动生成的是候选建议,不是最终业务口径。你应逐个检查指标名称、聚合函数、字段选择和过滤条件,再决定是否采纳。
实际测试中,账户表曾生成过类似指标:
| 指标含义 | 可能的 SQL 口径 |
|---|---|
| 账户总数 | |
| 总座位数 | |
| 平均座位数 | |
| 最晚创建时间 | |
| 最早试用结束时间 | |
这些指标能帮助系统稳定回答“账户总数是多少”“平均座位数是多少”这类问题。但如果业务上需要“只统计有效账户”“排除测试数据”“按付费账户统计”,就不能直接采纳默认建议,需要补充过滤逻辑或改用答案构建器。
分析方法
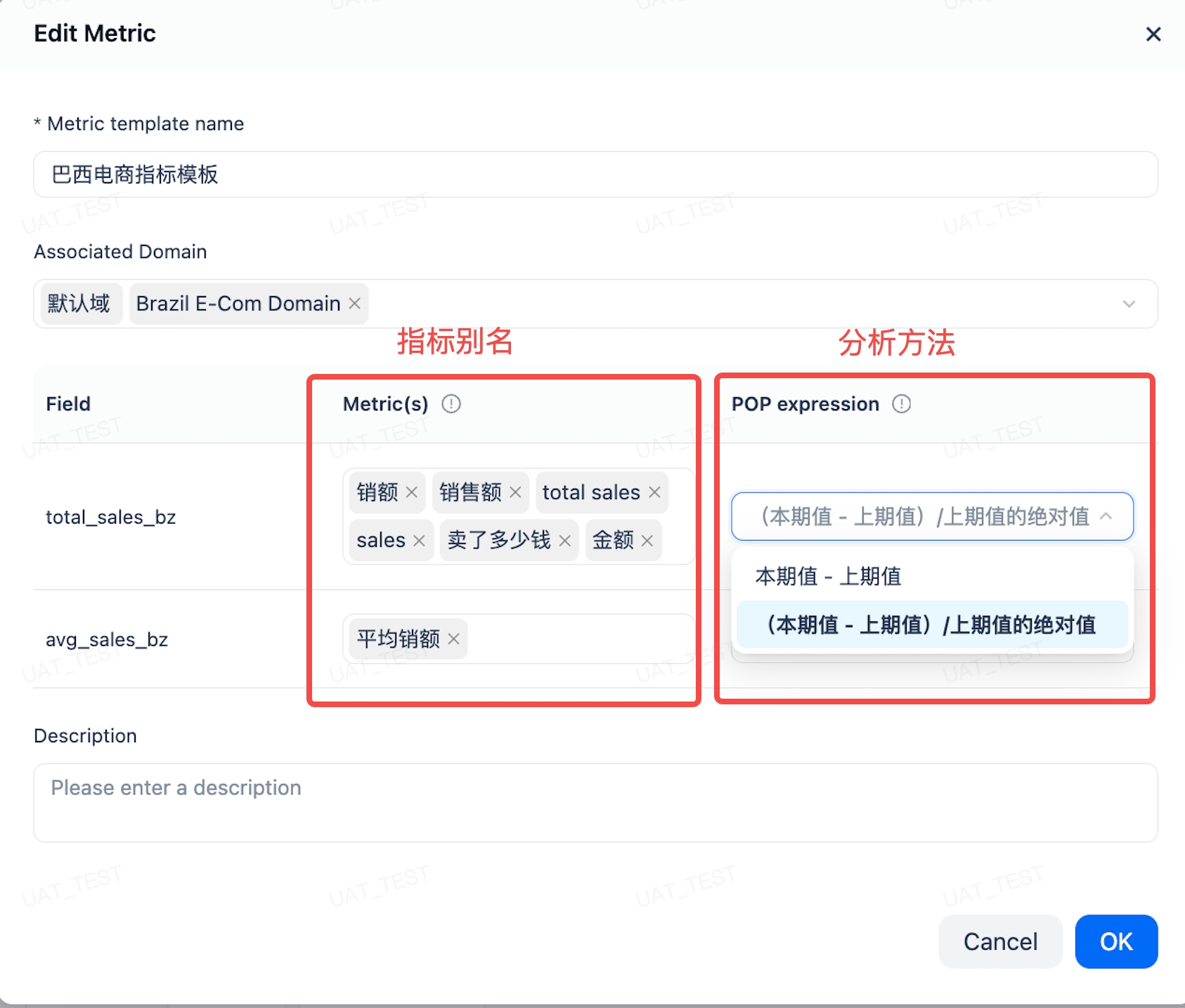
指标需要指定分析方法,影响同环比的计算逻辑:
| 分析方法 | 同环比算法 | 适用场景 |
|---|---|---|
| 可加型指标 | (本期值 - 上期值)/ |上期值| | 绝对数值类指标,如销售额、订单数 |
| 比例型指标 | 本期值 - 上期值 | 百分比类指标,如市场占有率、转化率 |
例:市场占有率今年 30%、去年 20%,比例型算法的同比结果是 +10%(不是 +50%)。
创建答案构建器
在左侧导航栏 数据 -> 答案构建器 中,点击 + 新建答案构建器。
答案构建器的核心是一段 SQL 模板,其中
${dims}${filters}在分析域管理页中,也可以通过 数据 -> 答案构建器 -> 添加答案构建器 配置。实际页面提供:
| 入口 | 说明 |
|---|---|
| 新建答案构建器 | 直接编写新的 SQL 模板。 |
| 选择已有答案构建器 | 复用已有答案构建器。 |
新建答案构建器时,页面包含 代码 和 数据 区域,并提供 格式化 和 运行校验 按钮。代码区会提示:
这意味着答案构建器不是自然语言说明,而是一段可校验的 SQL 模板。写完后应先点击 运行校验,确认 SQL 语法、表名、字段名、JOIN 和变量使用都能通过,再保存。
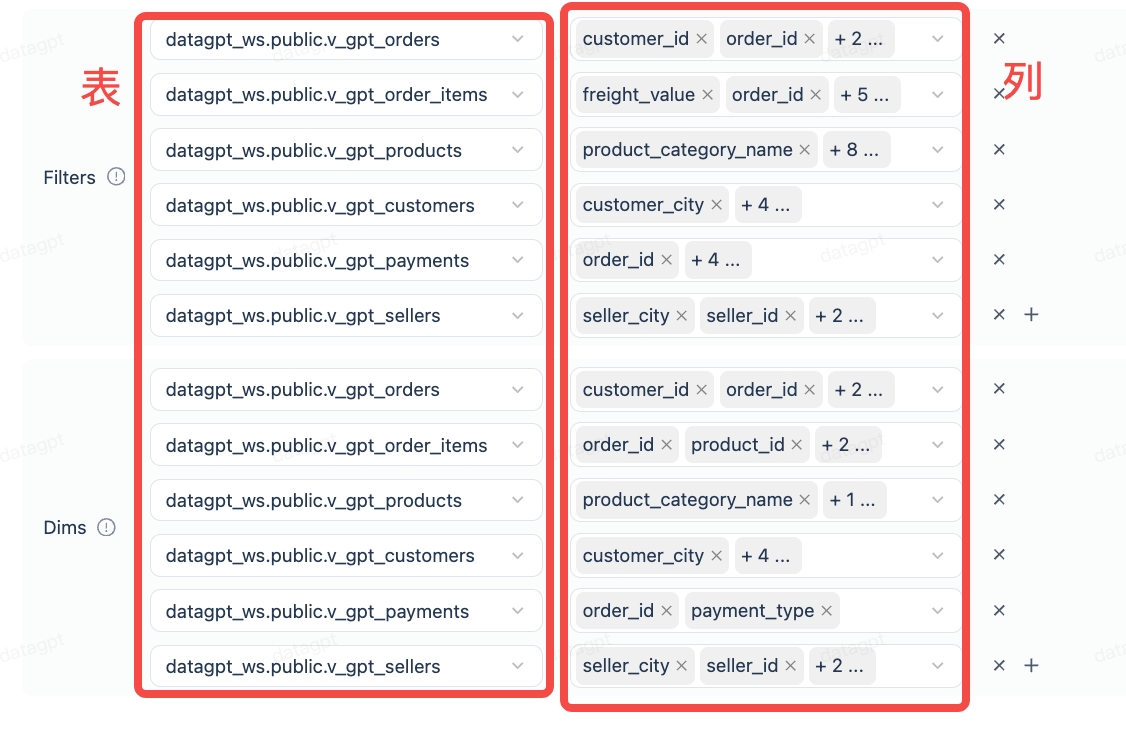
配置 Filters 和 Dims
SQL 模板下方需要定义哪些列可以作为过滤条件(Filters)和维度(Dims)。未在此处选中的列,不会作为问题的过滤条件和维度。
答案构建器适合解决的问题
答案构建器适合把复杂逻辑固定下来,避免模型每次临时推断。
典型场景包括:
- 多表 JOIN:订单、客户、商品、支付等多张表需要组合。
- 复杂过滤:只统计有效订单、排除测试数据、只看某类状态。
- 明细查询:返回订单明细、用户列表、异常记录,而不是一个聚合数字。
- 多指标组合:同一 SQL 中同时返回销售额、订单数、平均值、转化率等。
- 固定业务口径:例如“带看转换率”“玩家活跃度”“交易明细”等已经有明确口径的问题。
如果一个问题经常被问、SQL 又比较复杂,就应该优先考虑答案构建器,而不是依赖 AI 每次重新生成 SQL。
配置检查清单
保存指标或答案构建器前,建议检查:
| 检查项 | 指标 | 答案构建器 |
|---|---|---|
| 名称是否业务可读 | 必查 | 必查 |
| 是否配置别名 | 建议 | 建议 |
| 是否绑定正确表 | 必查 | 必查 |
| 聚合函数是否符合口径 | 必查 | 视 SQL 而定 |
| 是否需要过滤条件 | 视场景 | 必查 |
| 是否涉及多表 JOIN | 不适用 | 必查 |
| 是否完成运行校验 | 建议 | 必查 |
| 是否加入目标分析域 | 必查 | 必查 |
配置完成后,应回到分析域点击 开始分析,用典型问题验证:
- 系统是否优先引用已配置指标或答案构建器。
- 返回 SQL 是否符合预期。
- 按维度拆分、按条件筛选是否能正确生效。
- 结果是否与人工 SQL 或业务口径一致。
相关文档
- 配置分析域 — 指标和答案构建器运行的业务上下文
- 答案构建器最佳实践 — 答案构建器的设计与验证方法
- 分析域配置原则与常见问题 — 配置过程中的踩坑经验与 FAQ
- 问答准确率提升 — 指标和答案构建器在整体准确率提升方案中的定位
- 数据源管理 — 配置指标所依赖的数据表来源
- 对话式数据分析(Analytics Agent) — 功能概览