
多表实时同步任务完整指南
功能概述
多表实时同步任务,可以实现对源端库表进行全量同步和增量同步。其中增量同步,主要是基于对数据库变更消息进行处理来实现。多表实时同步任务是一个常驻任务,可达到秒级的端到端数据时效性。多表实时同步,支持两种同步类型和两种同步模式:
两种同步类型:全量同步和增量同步
- 其中全量同步为可选步骤,在启动实时同步任务时可以选择全量同步,也可以不选择。
- 如果选择了全量同步,系统会在启动增量同步时,也同时进行全量同步数据。全量同步的数据会写入到临时表,然后进行merge合并操作。全量同步完成后,会自动继续增量同步,不需要人为干预。
- 全量同步,基于JDBC协议,连接到源端抽取数据,会对数据库有较大的读取压力。
- 增量同步,基于数据库变更消息(比如MySQL的binlog),来解析其中内容,同步写入到目标端。对于数据库的压力主要是连接串的压力,相比全量同步,压力会小很多。
两种同步模式:多表镜像同步和多表合并同步
这两种模式的区别在于源端的表如何写入到目标端。
- 多表镜像同步,目标端的表和源端的表是一一对应的。
- 多表合并同步,支持把源端多张表合并写入到目标端一张表中。这种模式适合于源端是分库分表场景。多表合并同步,要求源端表的字段结构完全一致,或者基本一致。
原理介绍
流程原理
主要步骤如下:
-
启动增量同步,将源端变更数据,同步写入到目标表中。
-
进行全量同步,将数据存量数据,同步到临时表,此过程增量同步不停止。
-
全量同步完成后,将临时表的数据合并到目标表中,此过程会先停止增量同步,暂停消费源端数据库的变更。
-
合并完成后,恢复增量同步。
使用和运维指南
常规使用:在进行实时同步前,对源端数据库需要进行哪些参数设置和权限准备?
对源端数据库,需要进行必要的参数和权限配置,以确保数据库变更日志工作正常和同步任务具备足够权限能够正常获取到数据,
数据库参数配置
PostgreSQL
注意:修改以下参数需要重启Postgresql Server后生效。
| 配置 | 说明 | 默认值(单位) |
| wal_level | 预写日志(WAL)级别,决定多少信息写入到 WAL 中。 replica:会写入足够的数据以支持WAL归档和复制,包括在standby服务器上运行只读查询 minimal:会去掉除从崩溃或者立即关机中进行恢复所需的信息之外的所有记录 logical:会增加支持逻辑解码所需的信息 要支持实时同步,需要将wal_level设置为logical | replica |
| max_replication_slots | 服务端允许创建的slot数量。 | 10 |
| max_wal_senders | 服务端最多可同时运行的wal sender进程,对应我们可以同时进行实时同步的任务数。 | 10 |
| max_slot_wal_keep_size | 每个slot保存的wal大小。-1表示无限制。 | -1(MB) |
| wal_sender_timeout | 超过这个配置时间的复制连接会被终端。 | 60000(ms) |
MySQL
| 属性 | 描述 | 要求配置 | 查询方法 |
| log_bin | 是否开启binlog | ON或on | SHOW GLOBAL VARIABLES LIKE 'log_bin' |
| binlog_format | binlog日志格式。有三种取值可能: statement模式:记录的sql语句,优点是binlog保存内容少,缺点是有时候会导致同步结果不准确,因为同样的sql函数,可能在master和server上执行出不一样的结果,导致同步结果不对 row:记录的是sql执行前后的完整行数据,优点是数据准确,缺点是binlog数据量大 mixed:mysql会根据执行的sql内容自己决定用statement模式还是row模式来保存记录。 | ROW或row | SHOW GLOBAL VARIABLES LIKE 'binlog_format' |
| binlog_row_image | binlog记录前镜像和后镜像的方式 | FULL或full(前镜像和后镜像都记录全部字段) | SHOW GLOBAL VARIABLES LIKE 'binlog_row_image' |
| binlog_expire_logs_seconds | binlog自动清理时间 | 按业务要求配置,建议配置86400(秒)或以上 |
数据库权限配置
同步不同类型数据源的变更事件时,需要在相应数据源服务端配置好适当的权限才能保证数据的正常同步。尽管直接分配一个管理员或超级用户的权限足够保证任务正常运行,但通常会希望能够最小化权限需要分配给同步数据的用户的权限。各操作步骤需要的具体权限配置说明如下。
PostgreSQL
请注意,在执行赋权SQL语句时,确保执行账号自身具备可以授权的权限,建议使用管理员账号。为了确保任务顺利运行,建议将下述所有场景的授权均执行一遍。
使用场景:配置任务(获取元数据:schema列表、table列表、table字段列表)
所需权限:
授权方式
-
赋予某个角色读取information_schema的权限:
-
赋予某个角色读取某张表的权限:
使用场景:同步WAL日志
- 所需权限
- 授权语句
使用场景:同步历史全量数据(可选)
- 所需权限
-
授权语句
-
赋予某个角色读取某张表的权限:
-
赋予某个角色读取schema下所有表的权限:
-
使用场景:变更数据同步,创建publication
所需权限
授权语句
-
赋予CREATE权限
MySQL
请注意,在执行赋权SQL语句时,确保执行账号自身具备GRANT OPTION权限,建议使用超管账号比如root。为了确保任务顺利运行,建议将下述所有场景的授权均执行一遍。
使用场景:配置任务(获取元数据:database列表、table列表、table字段列表)
所需权限
授权语句
-
赋予用户查询 database 列表的权限:
-
赋予用户查询 table 列表和 table 详情的权限(SELECT包含了SHOW TABLES的权限):
使用场景:基于binlog日志同步变更数据
所需权限
授权语句
使用场景:同步历史全量数据
所需权限
授权语句
-
赋予用户查询 table 的权限:
常规使用:如何配置和运行实时同步任务同步?
通过以下步骤,按序操作:
- 在任务开发中配置同步任务,选择合适的镜像同步/多表合并同步模式,选定同步对象和正确的目标schema。
- 保存任务配置内容。
- 在调度配置中,选择合适的同步型集群,作为任务的资源,保存。
- 提交任务到运维中心。
- 在运维中心,操作启动任务。特别注意按需选择是否需要进行全量同步(此选项仅在任务提交上线后第一次启动时可以选择)。
补充说明:
- 提交任务后不会自动启动,需要在运维中心手动启动。
- 如果首次启动时选择进行全量同步,任务会先完成各表的全量同步,再进入对应表的增量同步阶段。
- 如果首次启动时不进行全量同步,任务会直接进入增量同步,不会自动补拉历史存量数据。
常规使用:配置同步任务,如何选择源端数据对象?
-
整库镜像同步模式,以数据库为粒度配置,只选择库,不逐张选择表。适用于希望把某个库整体镜像到目标端,并自动纳入库内后续新增表的场景。
-
多表镜像同步模式,源端对象的选择方式是先选库、再选表。它适用于只同步部分指定表的场景。此模式不会自动把后续新增表纳入同步范围。
-
多表合并同步模式,相对更加复杂,需要基于“虚拟表”的概念来进行操作。
- “虚拟表”核心作用是用来定义将源端哪些表同步到一张表中
- 新建“虚拟表”时,可以基于数据源、Schema、Table名称,给定筛选条件,来全选需要同步的源端表的范围,然后把这些表,定义成写入到同一张“虚拟表”。
- 系统会基于“虚拟表”的命名,在目标端Lakehouse中自动创建出目标表。
常规使用:在同步过程中,期待在目标表中额外新增字段来记录来源信息,需要如何配置?
-
可以在任务配置时,开启使用扩展字段功能。
-
扩展字段目前支持设置源端server名称、database名称、schema名称和table名称。
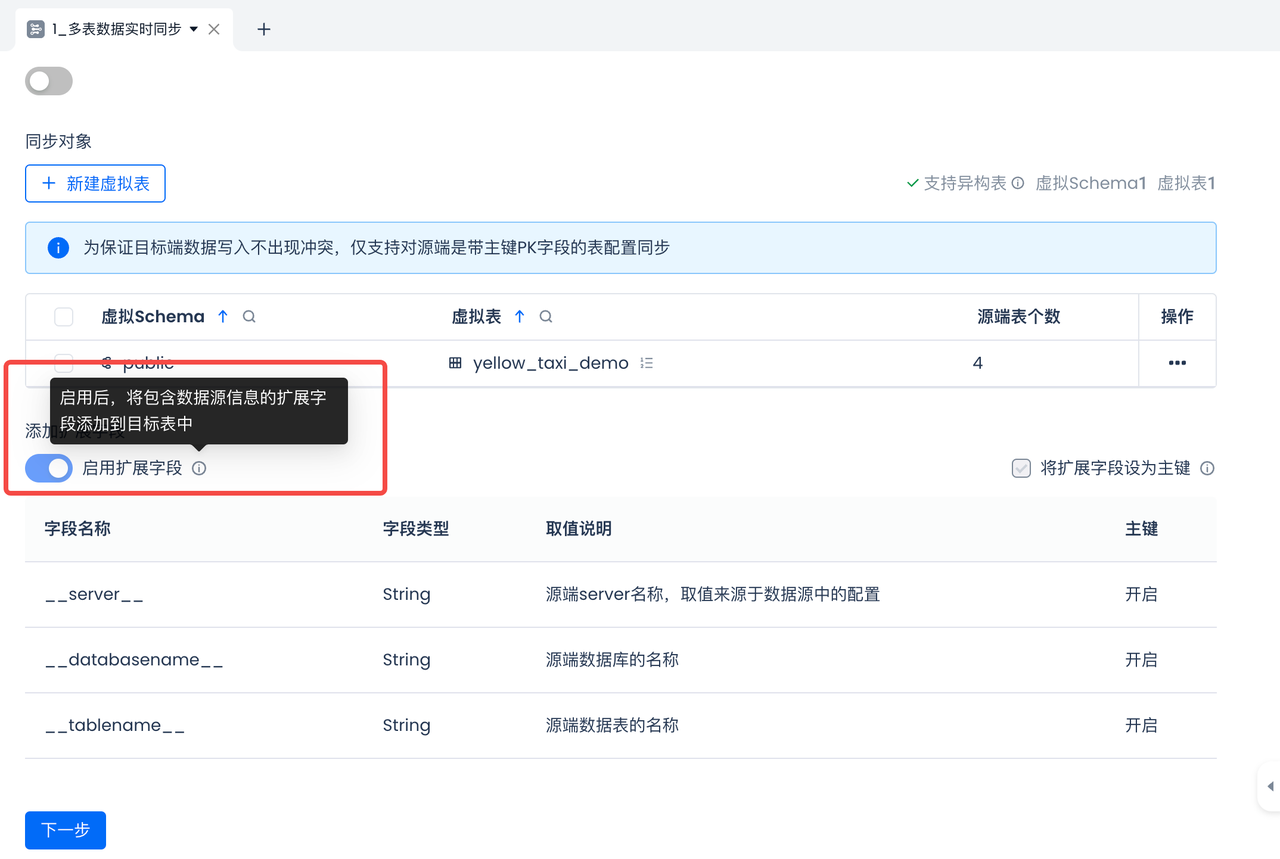
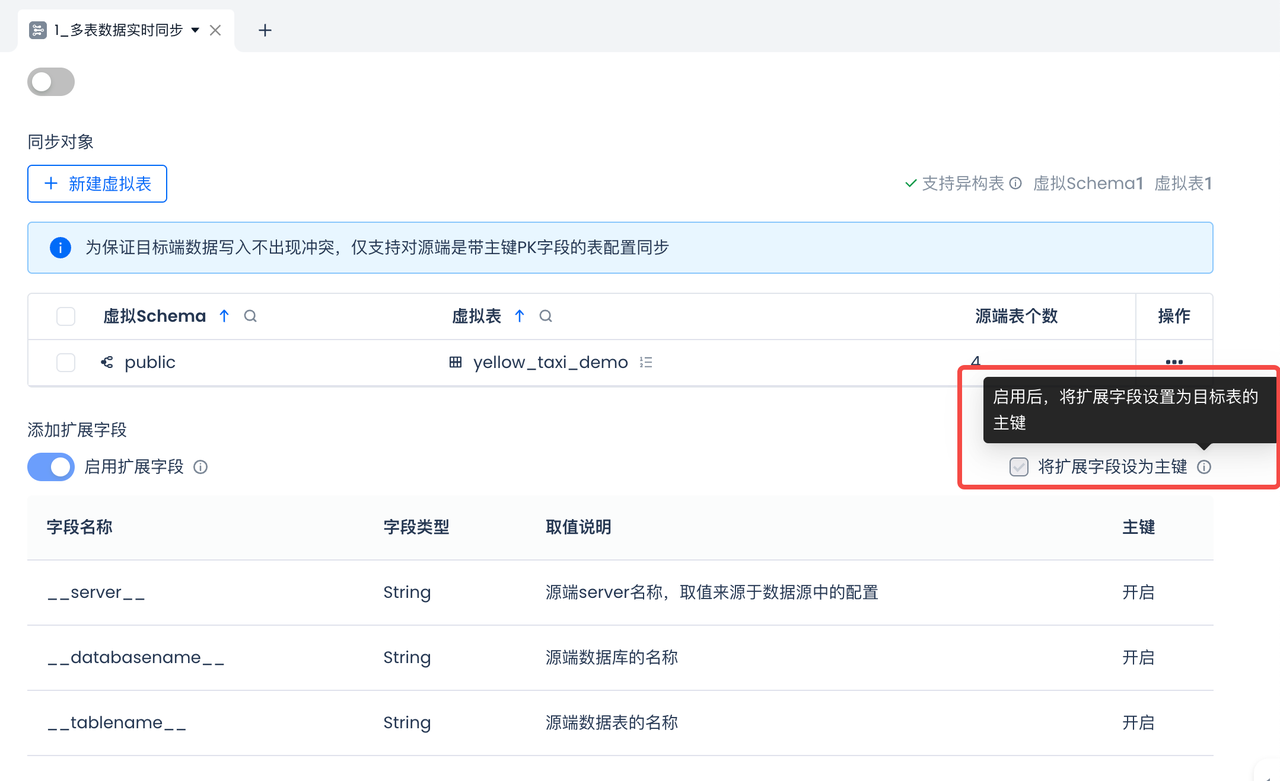
常规使用:在同步过程中,如果源端表中,不同分库分表里面,存在主键相同记录,需要如何配置同步任务来避免数据写入冲突?
-
可以在任务配置时,开启使用扩展字段功能,并把扩展字段设置为目标表的联合主键。
常规使用:如果源端的分库分表,表的字段结构基本一致,但又不是完全相同, 部分表多一些字段,如何配置同步任务?
- 使用异构字段合并功能。
- 在配置虚拟表时,系统会自动校验源端表的字段结构是否完全一致,如果不一致,系统会提示出来,依据提示,选择
常规使用:如果任务第一次启动没有选择全量同步,后续想补充进行全量同步,如何操作?
有如下几种方案可以使用:
-
方案一:操作单表进行重新同步。
- 重新同步,会先把源端表同步到临时表中,然后通过insert overwrite写入到目标表中。
- 重新同步不会影响目标表的数据查询。
-
方案二:操作单表进行补数同步,在过滤条件中,给一个能全量拉取到源端表的条件,比如 where 1=1 。
- 除了给where条件之外,也可以按需选择其它条件进行过滤,比如数据源名称、数据表名称。
-
方案三:把同步任务停止、下线、然后再上线。启动任务时,选择进行全量同步。
- 停止和下线任务不会删除目标表。
- 停止任务,会使得目标表中的数据不再更新,基于目标表查询到的数据不是最新、会有延迟。
- 下线任务会清空同步位点等中间信息,无法做到从停止的位置继续续传。重新上线任务、启动后,只能重新开始进行全量同步和增量同步。
常规使用:任务运行后,如果想新增更多表进行同步,应该如何处理?
先区分任务模式,再决定后续动作。对于多表镜像模式,新增表不会自动进入同步范围,需要回到任务开发界面把新表加入任务,随后完成保存、提交,并在运维中心停止后重新启动任务,这三个动作缺一不可;例如原来只同步
00_wky_demo确认自动适配时,可直接查看运维中心的“源端表变更记录”页签。这个页签主要用于展示源端新增表的记录情况,便于判断系统是否已经识别到新的来源对象。比如整库镜像模式下,某个库里新建了一张业务表,可以先看这里是否已经出现新增记录,再继续结合同步对象状态判断后续是否开始同步;如果这里没有记录,不一定代表任务异常,也可能只是当前任务模式本身不支持自动新增表,或者源端暂时没有发生新增表事件。
常规使用:分库分表,加减数据源、schema、table,需要如何操作,有什么影响?
- 在任务开发界面,直接编辑即可。
- 添加对象后,需要保存、提交,提交之后重启任务才能生效。
- 对于多表镜像模式,新增对象不会仅靠保存自动生效,必须完成保存、提交、重启这三个动作。
- 对于已经停止后再启动的任务,启动弹框默认选择“从上次保存状态恢复”;如需从指定位点回溯,可选择“自定义起始位置”。
- 不会影响存量表的同步进度。
常规使用:任务启动后,对所有表都进行全量同步耗时较长,如何优先同步重要的表?
- 在正在进行全量同步的重要单表上,使用“优先执行”,会在资源队列中插队、优先处理,进行全量同步。
常规使用:任务启动后,如何查看表的全量同步状态和详情?
建议把“查看全量状态”和“判断任务是否真正开始处理数据”放在同一条观察路径里理解:先在运维中心确认任务顶层状态是否已经从“已暂停”变为“运行中”,再到同步对象区域查看单表是否已经出现全量或增量状态变化,最后结合同步对象的“全量同步详情”、操作日志和执行日志补足证据。首次启动时如果选择了全量同步,常见的单表状态变化是先完成全量同步,再进入增量“正在同步”状态,因此如果某张表已经显示“同步完成”,同时增量状态是“正在同步”,通常说明这张表的历史数据已经完成装载,后续新变更也已经开始持续写入目标端;相反,如果任务顶层已经是“运行中”,但所有表都长时间停留在“暂未启动”或没有进入“正在同步”,就不应只依据任务状态判断成功,而应该继续查看执行日志。操作日志在这里的作用是帮助判断最近一次启动实际选择的是“无状态启动”“从上次保存状态恢复”还是“自定义起始位置”,例如当日志显示最近一次启动方式是“从上次保存状态恢复”时,就可以先排除“是不是又走了一次首次全量启动”的误判。
常规使用:任务启动后,如何对任务中的特定表进行重新同步,有什么影响?
-
如果需要修复特定表中的数据,选择“重新同步”:
- “重新同步”操作,会先重新同步源端表中的数据到临时表中,然后通过insert overwrite写入到目标表中,会重写掉目标表中已存在的数据。但不影响该目标表的查询。
-
如果要从源端重新拉取全量数据/部分数据,选择“补数同步”:
- “补数同步”操作,会按照给定的过滤条件,从源端拉取数据到临时表中,然后delete目标表的相关数据,最后通过merge into的方式写入到目标表。
常规使用:如果想暂时停止增量数据同步,需要如何操作?
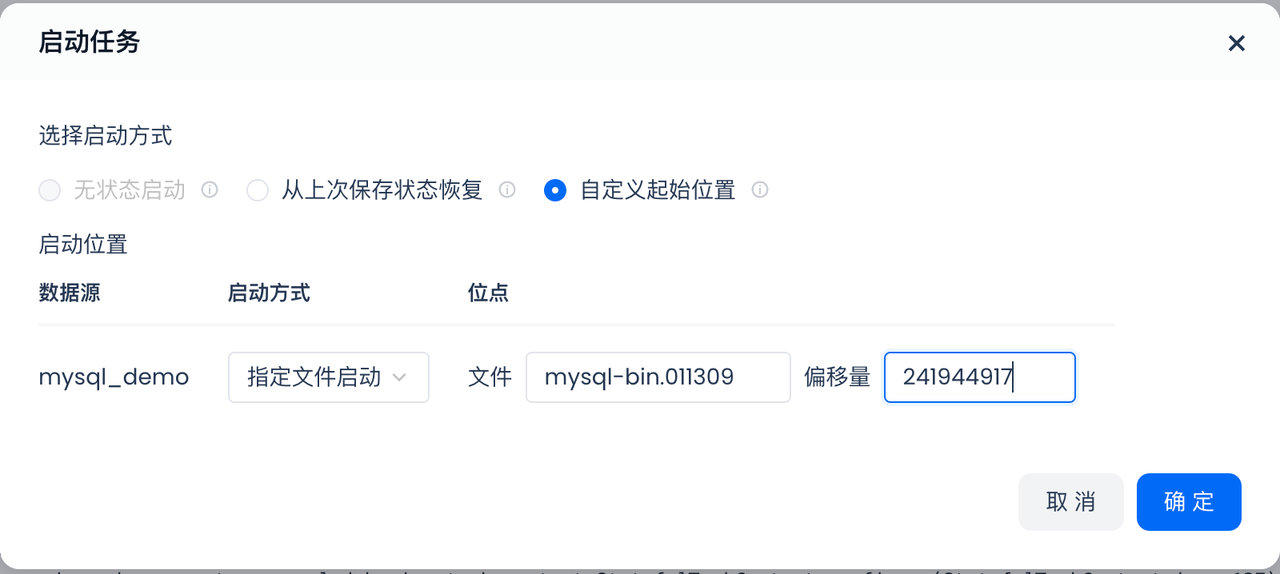
如果只是想暂时停止所有表的增量消息消费,在运维中心的实时同步详情页点击“停止”即可,不需要下线任务。后续恢复时点击“启动”,通常直接在弹框中选择“从上次保存状态恢复”即可,系统会从上次停止的位置继续续传;任务首次运行后,再次重启时“无状态启动”不再可用,如需回溯,则应选择“自定义起始位置”,并按要求填写具体位点或文件。如下图以 MySQL 为例,请确保填写的 binlog 位点没有过期失效。
常规使用:任务启动后,如何暂停和恢复单表的增量同步?
在单表维度,如果希望只暂停某张表的增量处理,可以在单边的运维操作菜单中选择“停止增量同步”,这样会暂停该表的变更数据消费而不再写入目标表;后续再通过“恢复增量同步”重新启动该表的增量同步。为了保证数据连续性,恢复增量同步时系统会从源端重新拉取一次全量数据。
常规使用:下线实时同步任务有何影响?在什么情况下需要下线任务?
- 下线任务属于相对高危的操作,建议谨慎使用,非必要不使用。
- 停止实时同步任务、下线掉, 不会清理目标表中的数据、不会删除目标表,但会清理中间过程的缓存数据和位点信息。
- 如果任务确定不再需要使用,可以下线任务。
- 如果遇到任务状态异常等偶发情况,期望对任务进行一次修复,可以尝试下线任务后再上线任务。
- 下线任务、再次上线并启动任务,会重新开始同步数据。重新同步不会重新建表,全量数据同步会对于老的表进行覆盖写入,增量同步会对目标表做merge into的更新。
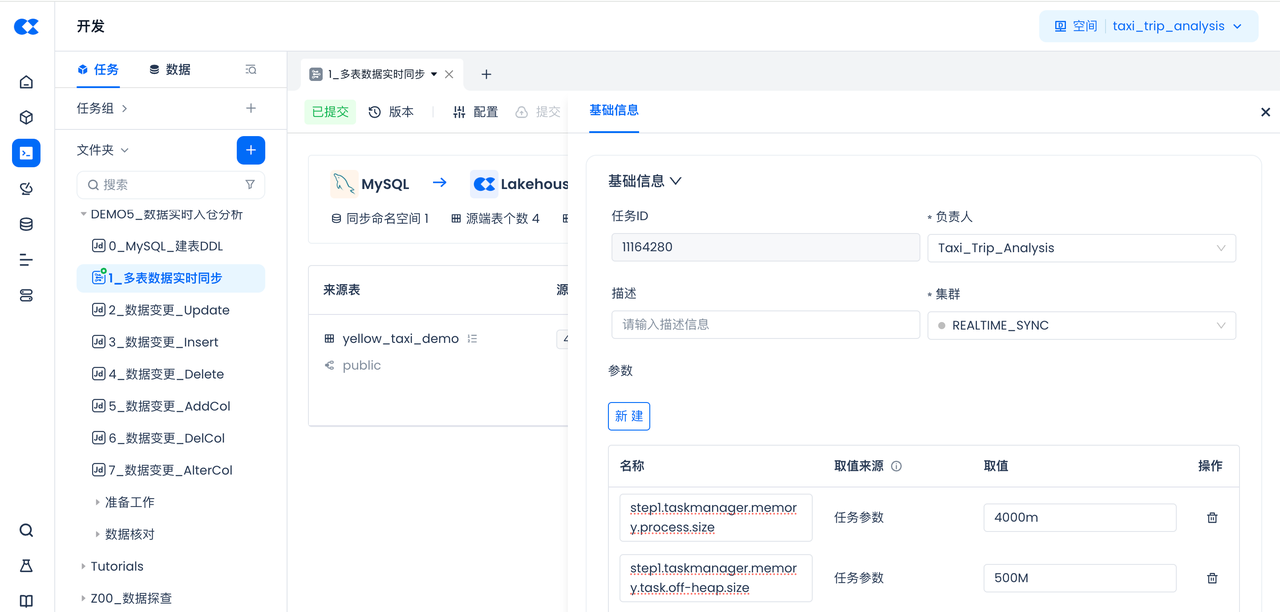
常规使用:如果同步任务中数据表和数据量特别大,做性能调优,可以通过哪些参数来设置?
-
在任务配置中的参数,通常保持默认值即可。
-
如果全量数据特别大,期待加速同步速度,在任务的“配置”中,可以适当调大以下两个参数的取值:
-
step1.taskmanager.memory.process.size,比如设定为4000m(默认:1728m)
-
step1.taskmanager.memory.task.off-heap.size,比如设定为500M(默认:256M)
-
紧急运维:任务失败后,遇到无法自行处理的问题,如何配合云器排查?
- 第一时间可通过飞书、电话等方式联系云器技术支持人员,云器方在接收到电话或者飞书信息后会快速做出响应并启动问题处置流程。
- 由于是OP部署环境,存在网络隔离等原因,需要客户配合获取任务执行日志等信息,以便快速排查解决问题。
紧急运维:如果源头突发多张表的流量很大,影响部分重要表的同步消费,如何处理?
- 可以对相对不重要的表,使用“暂停增量同步”功能,暂停该表的变更消息消费,为重要表的同步让出处理资源。
- 在重要表的变更消费完成后,再回复被暂停表的增量同步。
任务监控和告警
任务详情运维页面监控指标的含义
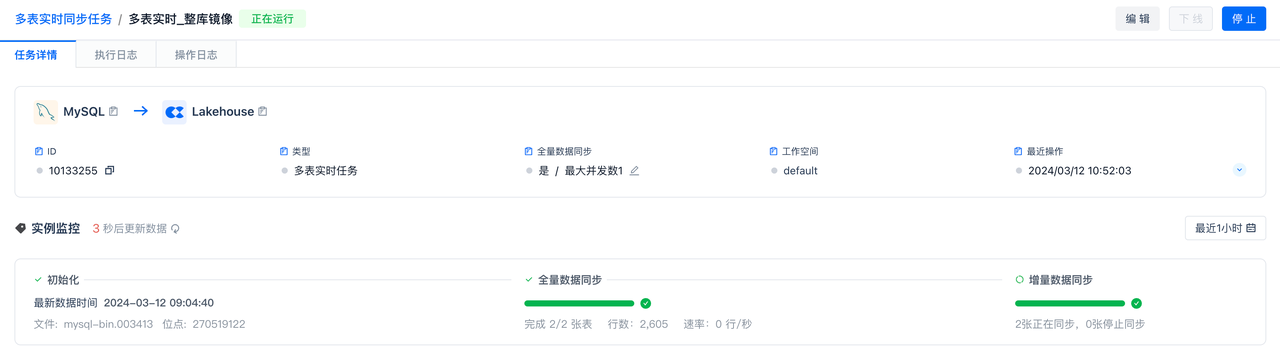
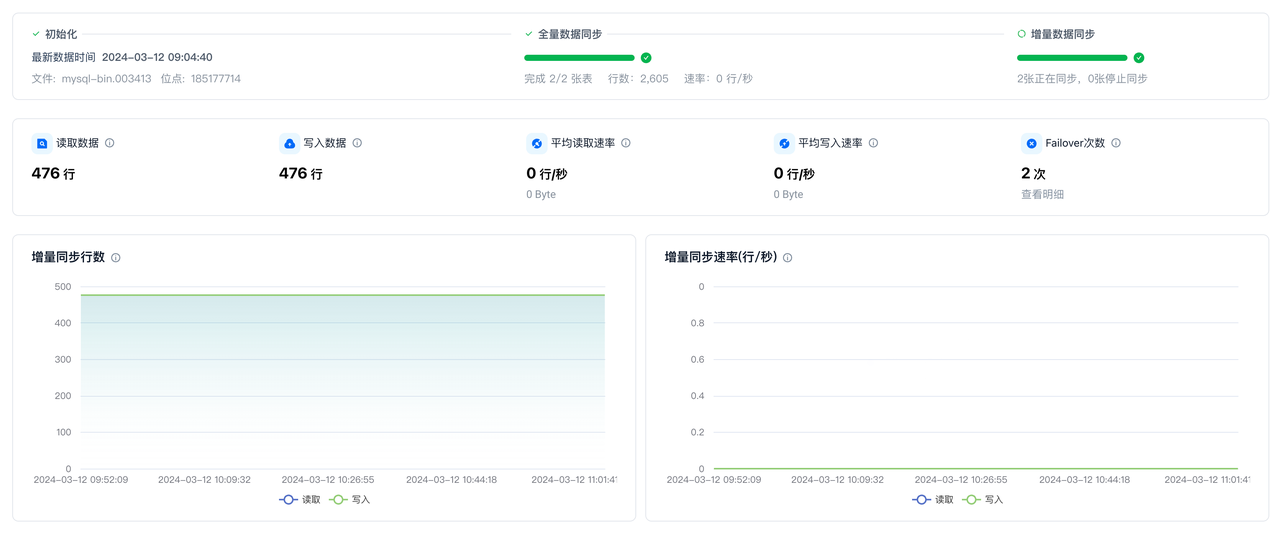
阶段监控
任务启动后,会经历初始化、全量同步、增量同步三个阶段。可在实例监控区域查看这三个阶段的运行状态。
指标监控
| 指标名称 | 口径说明 |
| 读取数据 | 数据同步任务在统计周期内从数据源读取的记录数。 |
| 写入数据 | 数据同步任务在统计周期内向目标数据源写入的记录数。 |
| 平均读取速率 | 数据同步任务在统计周期内平均读取速率。(周期内总读取记录/周期时间) |
| 平均写入速率 | 数据同步任务在统计周期内平均写入速率。(周期内总写入记录/周期时间) |
| Failover次数 | 数据同步任务在统计周期内运行发生Failover次数。Failover次数代表数据同步服务自身运行的稳定性。 |
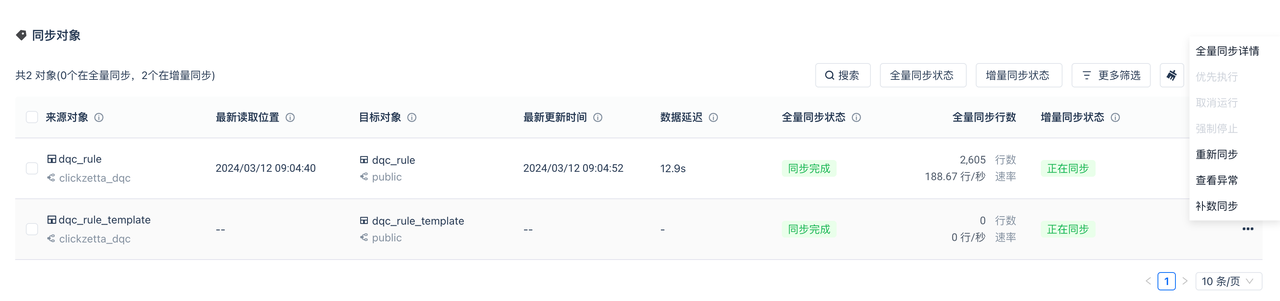
单表同步进度
| 指标 | 口径说明 |
| 最新读取位置 | 同步任务实时读取来源对象数据并写入目标表,以目标表最新一条记录的写入时间作为读取位置。 |
| 最新更新时间 | 最近一次写入目标表的时间。 |
| 数据延迟 | 数据从数据源端事务提交到同步至目标端可见的时间间隔。 |
任务监控告警的配置
在监控告警功能板块中,可以配置监控规则,来对实时同步任务的运行状态和延迟指标等,进行监控。对于实时同步任务,为了全方位监控任务运行的健康度,建议按照下文的操作指南配置上以下告警(可按需配置更多):
- 多表实时同步任务运行失败
- 多表实时同步作业failover
- 多表实时同步任务目标表变更失败
- 多表实时同步延迟
- 多表实时同步读取点位延迟
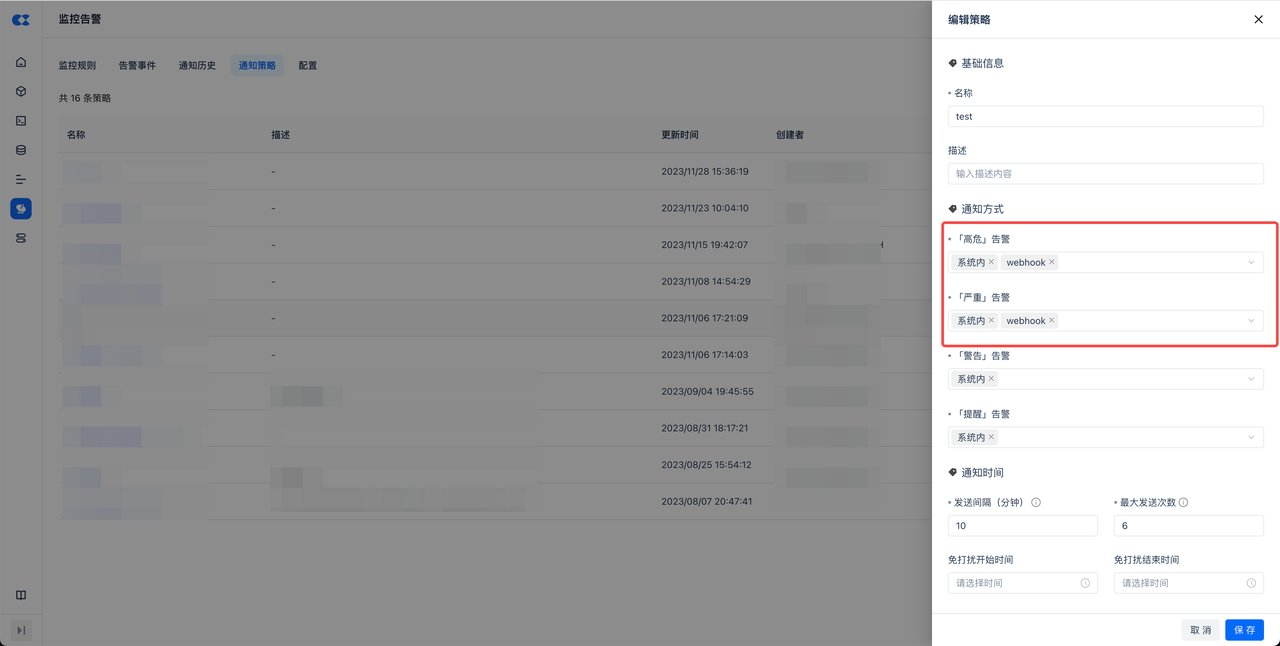
初始准备:IM告警机器人配置
-
机器人配置:
- 在飞书中配置群机器人,参考:在群组中使用机器人
- 在企业微信中配置群机器人,参考:https://open.work.weixin.qq.com/help2/pc/14931
-
获取到群机器人的webhook地址。
-
在产品中新增一个webhook配置,渠道选择飞书/企业微信、webhook地址填写机器人的地址。

-
在通知策略中启用webhook。
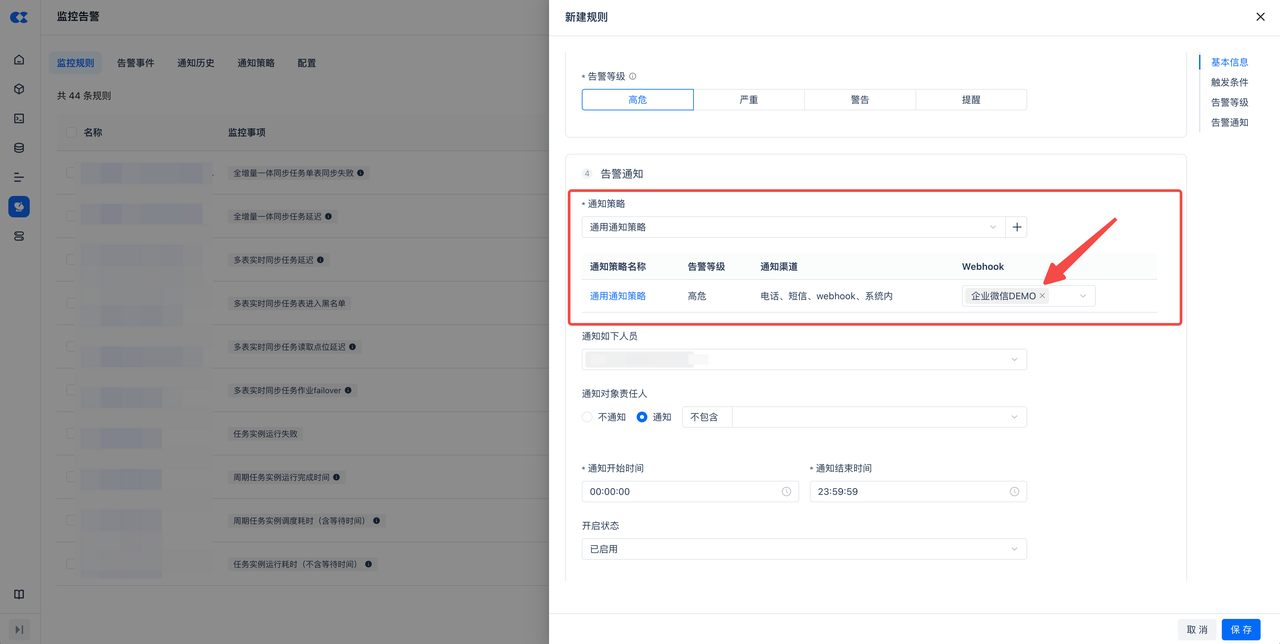
-
监控规则中,选择启用了webhook的通知策略,填写webhook中选择上面定义好的webhook配置。
实时数据集成任务异常监控配置
-
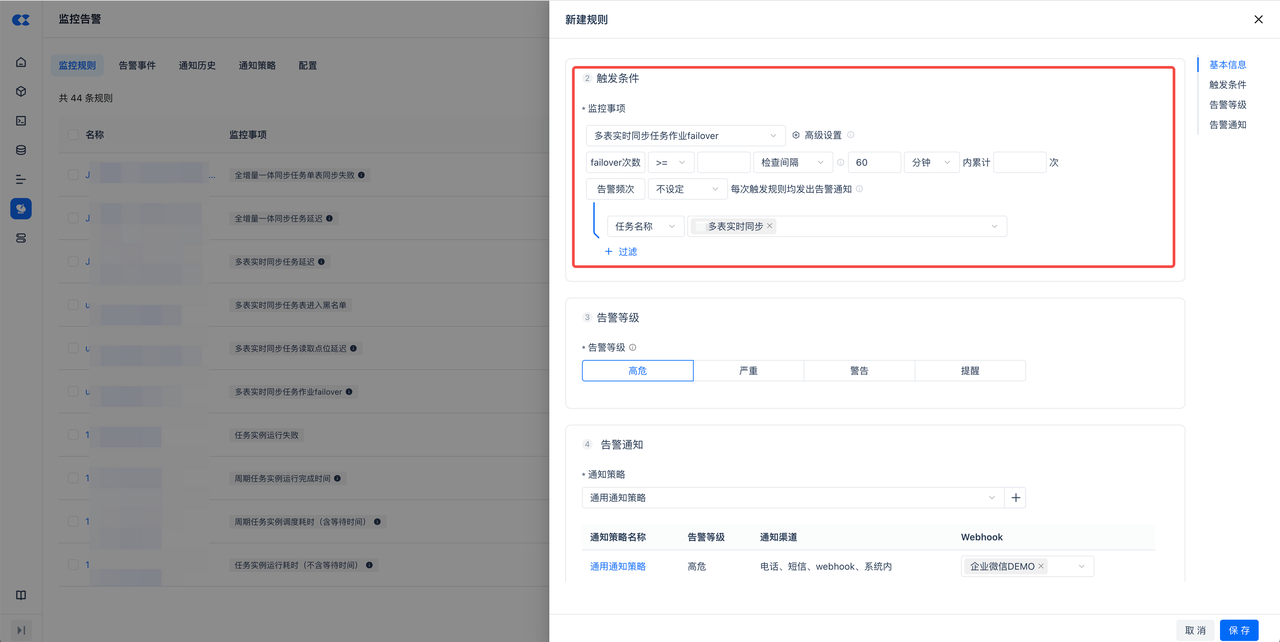
任务fairover告警:新建监控规则,在监控事项中选择“多表实时同步作业failover”。可以额外增加过滤属性,比如工作空间、任务名称等。如不增加过滤,默认对实例下所有多表实时任务全部监控。
-
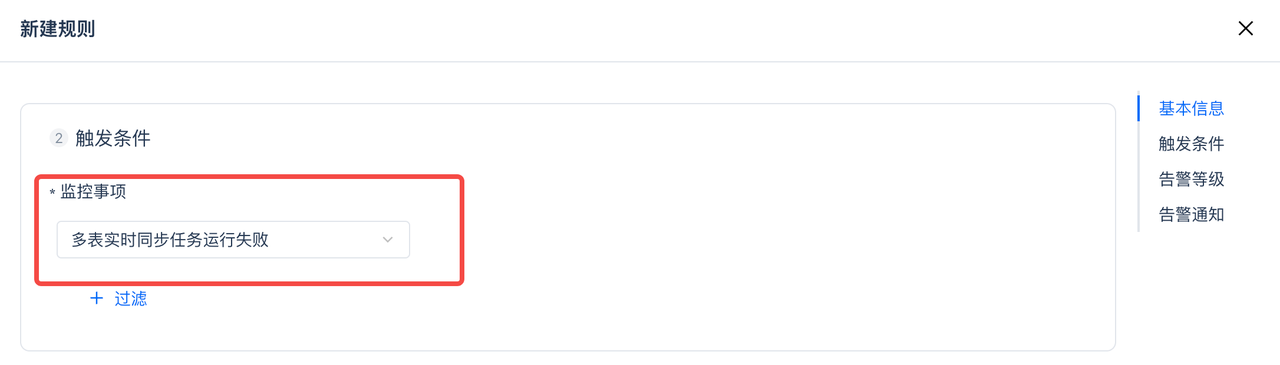
任务停止告警:新建监控规则,在监控事项中选择“多表实时同步任务运行失败”。可以额外增加过滤属性,比如工作空间、任务名称等。如不增加过滤,默认对实例下所有多表实时任务全部监控。
实时数据集成任务中出现异常监控配置
-
存量单表同步异常告警
-
增量单表异常告警
-
当前可配置出表被加入到黑名单的告警,覆盖 Schema Evelution失败、单字段大小超10M限制 这两种场景。
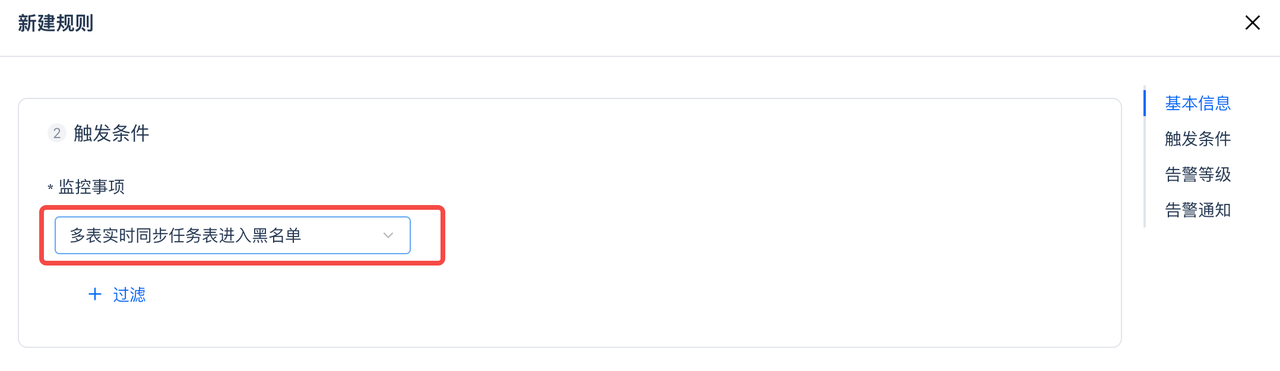
-
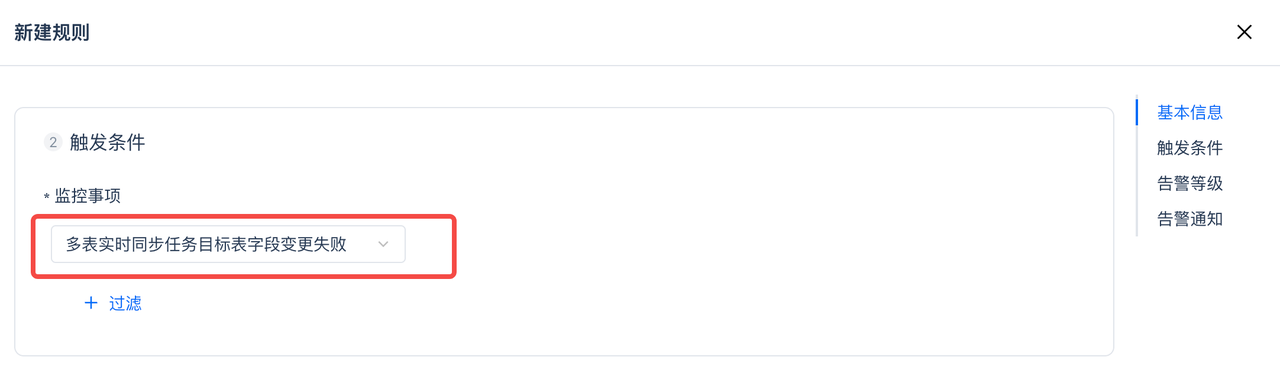
Schema Evelution失败告警:新建监控规则,在监控事项中选择“多表实时同步任务目标表变更失败”。
-
实时数据集成任务中最大延迟监控配置
-
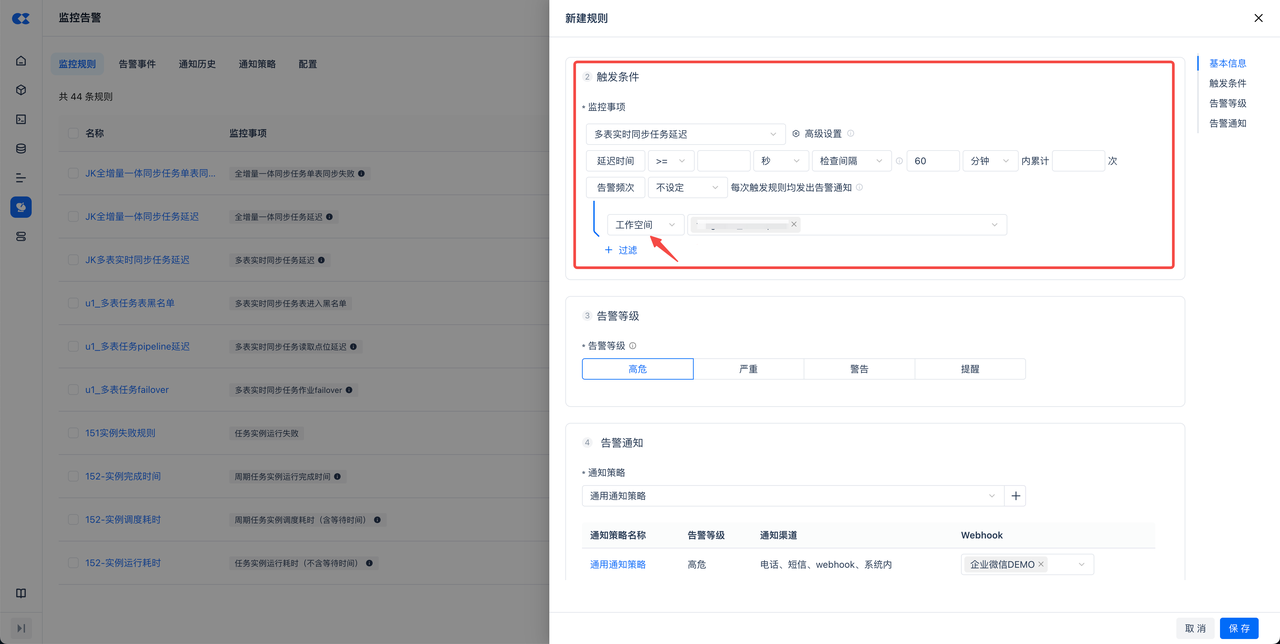
端到端同步延迟:新建监控规则,在监控事项中选择“多表实时同步延迟”。可以额外增加过滤属性,比如工作空间、任务名称等。如不增加过滤,默认对实例下所有多表实时任务全部监控。
-
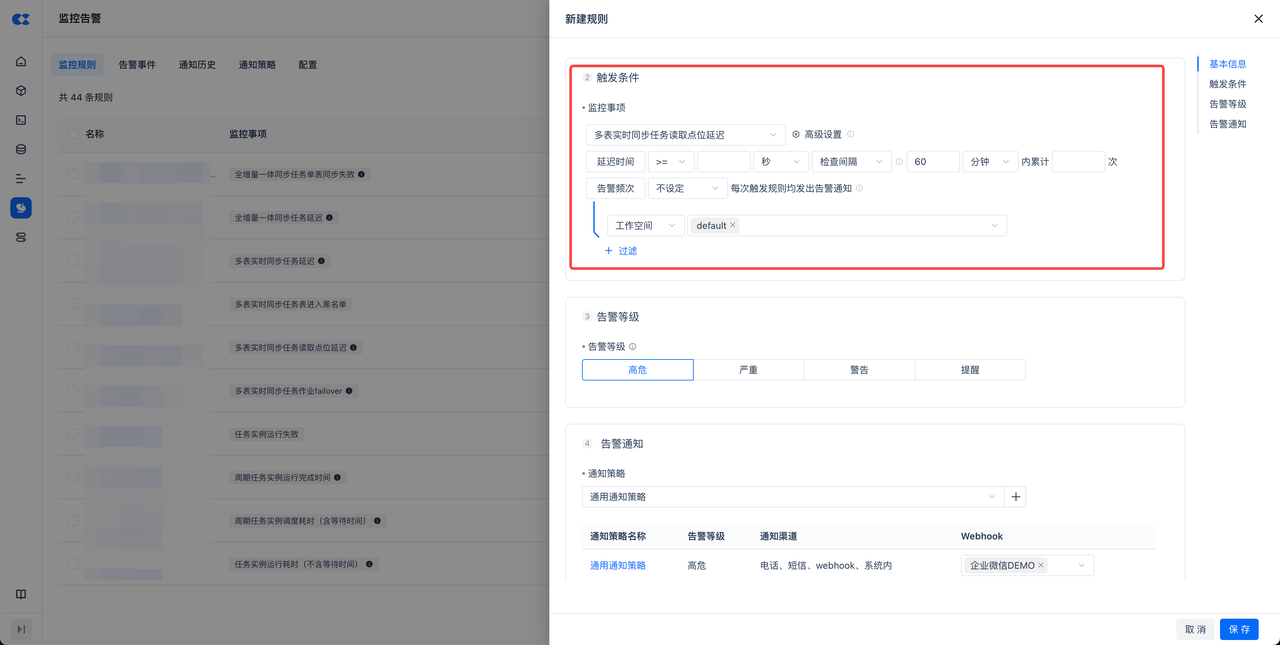
读取位点延迟:新建监控规则,在监控事项中选择“多表实时同步读取点位延迟”。可以额外增加过滤属性,比如工作空间、任务名称等。如不增加过滤,默认对实例下所有多表实时任务全部监控。
常见报错排查
增量同步失败
Binlog位点过期
-
问题现象
- 以指定文件和位点的方式启动任务,或者任务停止一段时间后选择从状态恢复启动后任务失败,执行日志中报错:Caused by: java.lang.IllegalStateException: The connector is trying to read binlog starting at Struct{version=1.9.7.Final,connector=mysql,name=mysql_binlog_source,ts_ms=1734071479878,db=,server_id=0,file=mysql-bin.010937,pos=432041283,row=0}, but this is no longer available on the server. Reconfigure the connector to use a snapshot when needed.
-
可能原因
- Mysql的binlog通常不会永久保存,会被定期回收,如果指定了一个已经被清理的binlog文件或位点,或者任务停止了很长时间,自动从状态恢复的时候会继续从上次暂停的一个被清理的位点继续消费,则会遇到上述报错,因为对应的binlog数据已经被删除。
-
解决措施
-
通过
查询当前数据库的最新binlog文件和位点:show master status
-
使用结果中的file和position重启同步任务
-
如果需要补回丢失的数据,可以选择相应的表进行重新同步
-
Server-id冲突
-
问题现象
- 任务启动失败,执行日志中报错:A slave with the same server_uuid/server_id as this slave has connected to the master; the first event '' at 4, the last event read from '/home/mysql/log/mysql/mysql-bin.011268' at 90995258, the last byte read from '/home/mysql/log/mysql/mysql-bin.011268' at 90995258. Error code: 1236; SQLSTATE: HY000. The 'server-id' in the mysql cdc connector should be globally unique, but conflicts happen now.
-
可能原因
- 实时同步任务默认在为每个mysql数据源建立一个连接并分配一个server-id用来同步binlog数据,生成的server-id的范围在5400-6400之间,如果出现上述报错导致任务失败,说明本次任务为这个数据库连接分配的server-id与数据库上的其他同步工具或同步任务发生了冲突。
-
解决措施
- 检查同一个数据库实例下是否有其他同步任务或同步工具正在同步binlog数据
- 重启同步任务
数据源时区配置错误
-
问题现象
- 任务启动失败,执行日志中报错:Caused by: org.apache.flink.table.api.ValidationException: The MySQL server has a timezone offset (28800 seconds ahead of UTC) which does not match the configured timezone Etc/GMT+12. Specify the right server-time-zone to avoid inconsistencies for time-related fields.
-
可能原因
- 数据源中配置的时区(默认东八区,Asia/Shanghai)与数据库配置的时区不一致。
-
解决措施
- 确认数据库配置的时区,然后修改数据源中配置的时区
Binlog事件size超限
-
问题现象
- 任务运行失败,执行日志中报错Caused by: io.debezium.DebeziumException: log event entry exceeded max_allowed_packet; Increase max_allowed_packet on master; the first event '' at 58722808, the last event read from '/rdsdbdata/log/binlog/mysql-bin-changelog.004054' at 109251835, the last byte read from '/rdsdbdata/log/binlog/mysql-bin-changelog.004054' at 109251854. Error code: 1236; SQLSTATE: HY000.
-
可能原因
- 数据库配置的
小于Binlog中的某个事件的sizemax_allowed_packet - 数据库binlog文件损坏
- 数据库配置的
-
解决措施
- 联系dba调整数据库的
参数大小,可调整的上限为1G,生效后重新同步max_allowed_packet - 如果调整
参数后仍然无法成功,则binlog文件可能已经损坏,可以重启任务,选择一个更新的点位,即跳过有问题的位点来继续同步增量数据;如果需要补全中间可能缺少的数据,选择需要补全数据的表重新同步全量数据max_allowed_packet
- 联系dba调整数据库的
全量同步失败
PK长度超限
-
问题现象
- 全量同步状态失败,执行日志中报错:BulkLoad stream errorcom.dtstack.flinkx.throwable.FlinkxRuntimeException: BulkLoad failed, stream id: bulkload_stream_xxx final status:COMMIT_FAILED, error msg:Task lost connection, message: container stopped by AM. Detail CZLH-71006:Encoded key size 191 exceeds max size 128
-
可能原因
- 源表中的主键字段总长度过程,超过默认配置的128字节
- 同步任务配置中选择了多个扩展字段作为联合主键,如多表合并场景中选择了server_id、database、schema、table作为联合主键来避免多个表中的主键字段有冲突,扩展后的联合主键总长度超过默认配置的128字节
-
解决措施
- 修改同步任务,增加配置:
同步任务Failover
与Lakehouse Ingestion Service断连
-
问题现象
- 任务发生failover,failover详情中有如下信息:java.util.concurrent.ExecutionException: java.lang.RuntimeException: java.lang.RuntimeException: java.io.IOException: Async commit for instance [270076] workspace [xsy_ent] failed. Error detail is:rpcProxy call hit final failed after max retry reached. at com.dtstack.flinkx.connector.lakehouse.sink.LakeHouseRedisMetaHybridIgsMultiWriter.flushInternal
-
可能原因
- 通常发生在Lakehouse服务端升级的情况下,数据同步任务与Lakehouse Ingestion Service连接中断
-
解决措施
- 一般发生在服务升级期间,通常在完成升级后任务会自动恢复
- 如果确认服务升级完成,任务还在持续failover,尝试手动重启任务
- 如果手动重启任务后任务还是无法恢复正常,需要检查Lakehouse Ingestion Service服务健康状态
Binlog事件反序列化失败
-
问题现象
- 任务发生failover,failover详情中有如下信息:com.github.shyiko.mysql.binlog.event.deserialization.EventDataDeserializationException: Failed to deserialize data of EventHeaderV4
-
可能原因
- 这个问题通常出现在来源数据库的binlog中突然产生了大量的事件,如发生大量业务数据的更新,或历史数据批量删除等场景,导致同步任务写入端无法在短时间内处理完所有数据,发生反压,同步任务的读取端停止消费binlog数据,同步任务中的binlog client与数据库服务端的连接会被任务超时而中断,或者服务端的处理线程idle过久被回收,都有可能导致同步任务接受到不完整的binlog事件消息,从而导致反序列化失败
-
解决措施
- 如果流量的增长是短时间的,通常同步任务能够在有限的failover次数内恢复正常
- 如果持续长时间出现,可尝试调整mysql配置,调大slave_net_timeout和thread_pool_idle_timeout的值,
- 临时调整(MySQL实例重启会失效):
- 永久调整,修改MySQL的配置文件
表进入黑名单
执行Schema evolution失败
-
问题现象
- 某张表的状态自动变为停止同步状态,表对象边上的tips看到有
、pk column different
、pk column type mismatch
等错误信息invalid modify column
- 某张表的状态自动变为停止同步状态,表对象边上的tips看到有
-
可能原因
- 来源表结构发生了Lakehouse不支持的变更,包括:
- PK字段列表变更,如PK字段重命名,或从原来的一个字段变成两个字段
- PK字段类型变更,如将PK字段的类型从bigint改为varchar
- 字段类型发生不兼容修改,如从int改为double等
-
解决措施
- 检查源端表结构,修改为正确的结构
- 重新全量同步停止增量同步的表,全量同步完成后相应的增量数据也会继续同步
已知局限和注意事项
- 为保证目标端数据写入不出现冲突,仅支持对源端是带主键PK字段的表配置同步,非PK表不支持同步。
- 在同步任务中会自动创建目标表,为了确保任务运行稳定和数据正确,无特别必要,不要手动去创建表、修改表和删除表。
- Schema Evolution,支持源端新增字段、删除字段,暂不支持变更字段类型。
- 自动新增表仅适用于整库镜像模式;多表镜像模式下,新增表需要编辑任务、保存提交并重启后生效。