基于BI分析场景学习产品功能使用
本章内容将通过真实的业务场景案例,帮助你快速入门云器 Lakehouse Studio 核心功能模块,并指导你完成从业务数据库到数据应用的端到端工作流搭建。通过本章节的介绍,你将会了解:
- 如何配置数据源
- 如何创建数据集成任务
- 如何创建数据开发任务
- 如何进行任务调度配置与任务发布
- 如何进行任务实例运维
- 如何通过 JDBC 连接到 BI 工具
- 如何创建和调用 UDF 函数
场景介绍
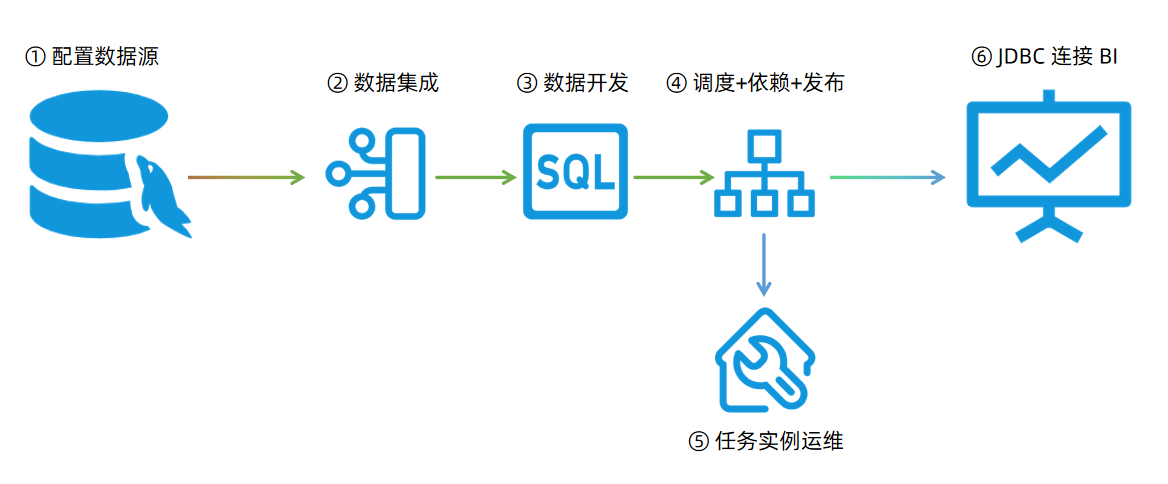
企业的商业智能 BI 一般由企业的业务系统提供原始数据,业务系统后台数据库一般选型为关系型数据库,如 MySQL、Oracle 等。本场景以 MySQL 数据库为例,通过云器 Studio 完成 ① 数据源配置、② 数据集成、③ 数据开发、④ 任务调度配置发布、⑤ 任务实例运维,以及 ⑥ 通过 JDBC 的方式连接到 BI 工具,完成 BI 数据分析的业务需求。
工作流程示意图
业务需求
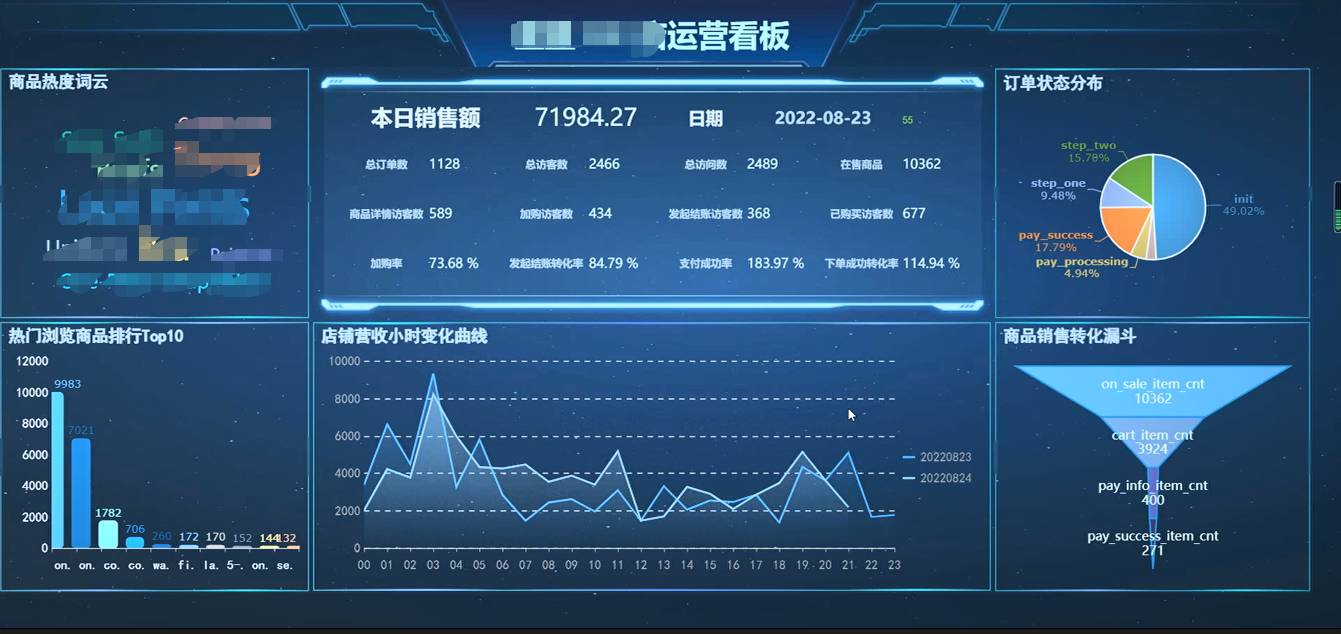
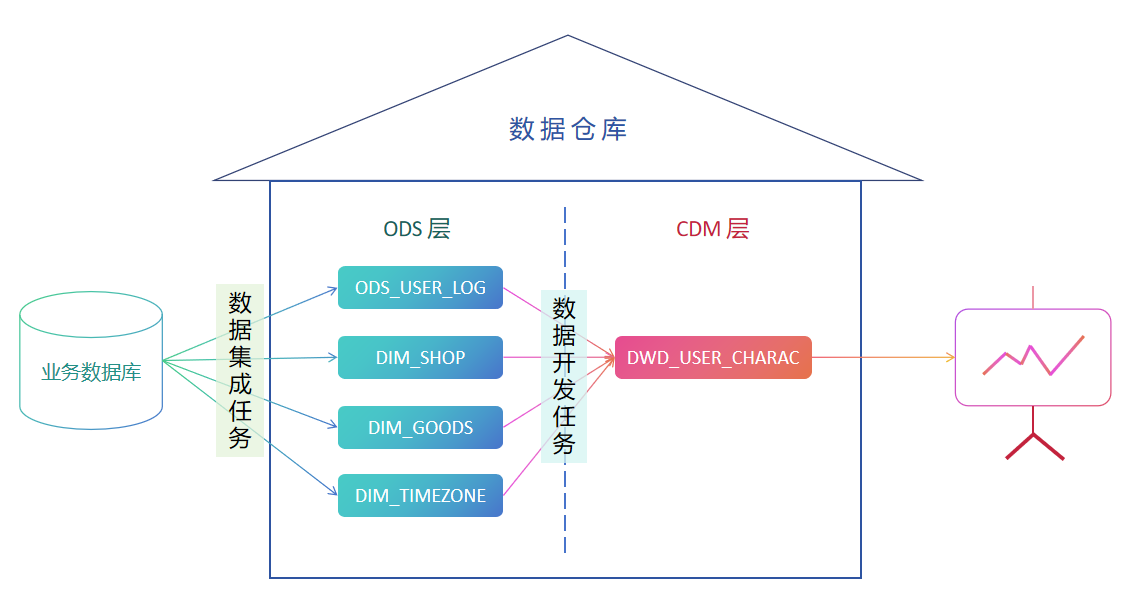
本例中的业务需求模拟电商场景中常见的 BI 分析需求场景,通过用户行为日志数据,关联商品、店铺、时区等维度表数据,生成一张数仓明细层的宽表,提供给下游数据应用层,再通过 BI 工具进行销售额、订单数统计,漏斗转化模型、热门商品展示等。

整体的工作流构建思路是:
完成这 4 张表的数据集成任务创建
>>
创建 4 张 Lakehouse 目标表,1 张业务实时表,和 3 张维度表
>>
创建数据开发任务
>>
通过 SQL 关联查询,将四张表的字段融合成一张宽表,写入一张 DWD 层的结果表
>>
按照数据集成任务在前,SQL 任务在后的顺序配置任务依赖关系
>>
将所有的任务提到到生产环境。
回顾准备工作
参考上一章节的准备工作,在“快速开始”之前,你需要确保你所在的企业已经开通了云器 Lakehouse 服务,可以登录到 Studio 产品首页。
在初始化的产品环境下,你可能已经拥有如下对象资源:
- 默认用户(User):你的用户名 —— 图1
- 默认工作空间:quickstart_ws —— 图2
- 默认 Schema:public —— 图3
- 默认的计算集群:通用型集群:DEFAULT,分析型集群:DEFAULT_AP —— 图4
图1 —— 用户(User)
图2 —— 工作空间:QuickStart_WorkSpace
图3 —— Schema:Public
图4 —— 计算集群:Default

开始工作
接下来我们一步步展开工作,从连接业务系统的数据库开始。
【配置数据源】
Studio 提供的新建数据源的方式有两种:
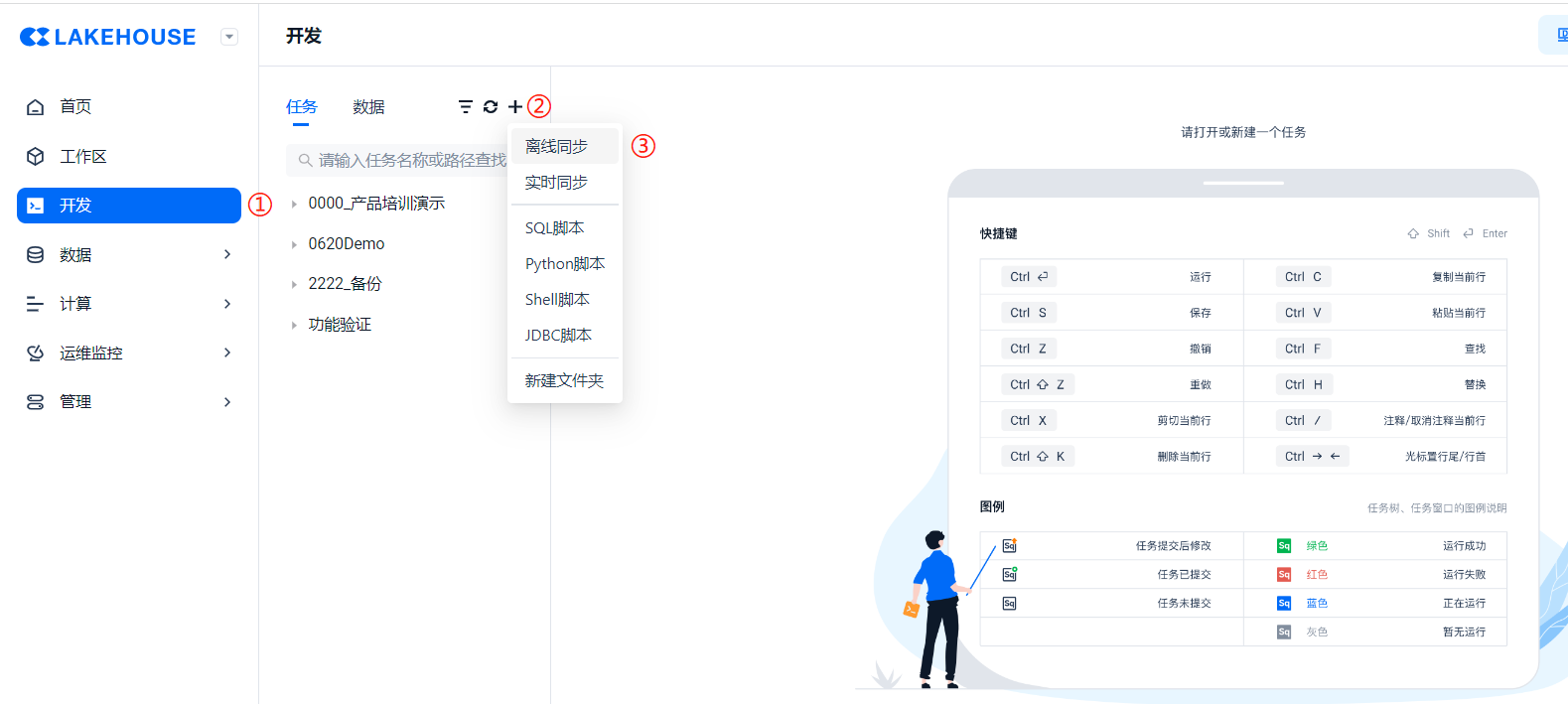
- 方法一:按照 ① [管理] → ② [数据源] → ③ [新建数据源] 的步骤可以新建数据源;
- 方法二:通过 ① [开发] → ② ["✙" 按钮] → ③ [离线同步] → ④ ["✙" 按钮] 的方式也可以新建数据源。
图1 —— 方法一
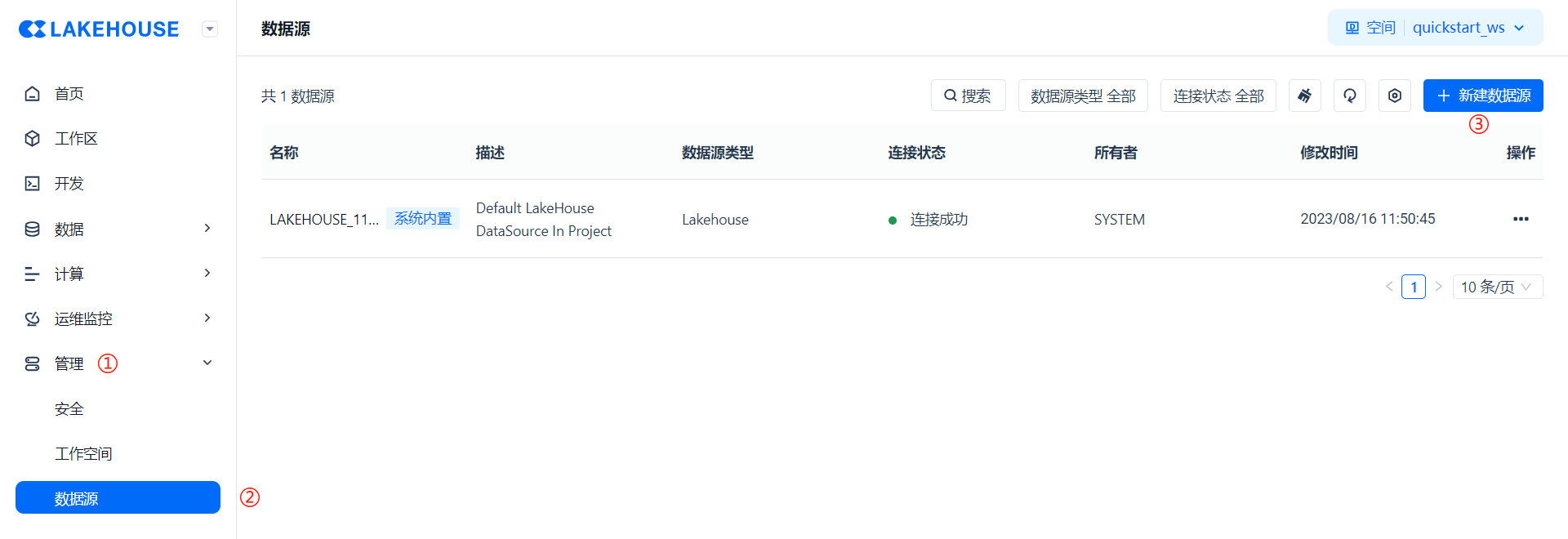
图2 —— 方法二
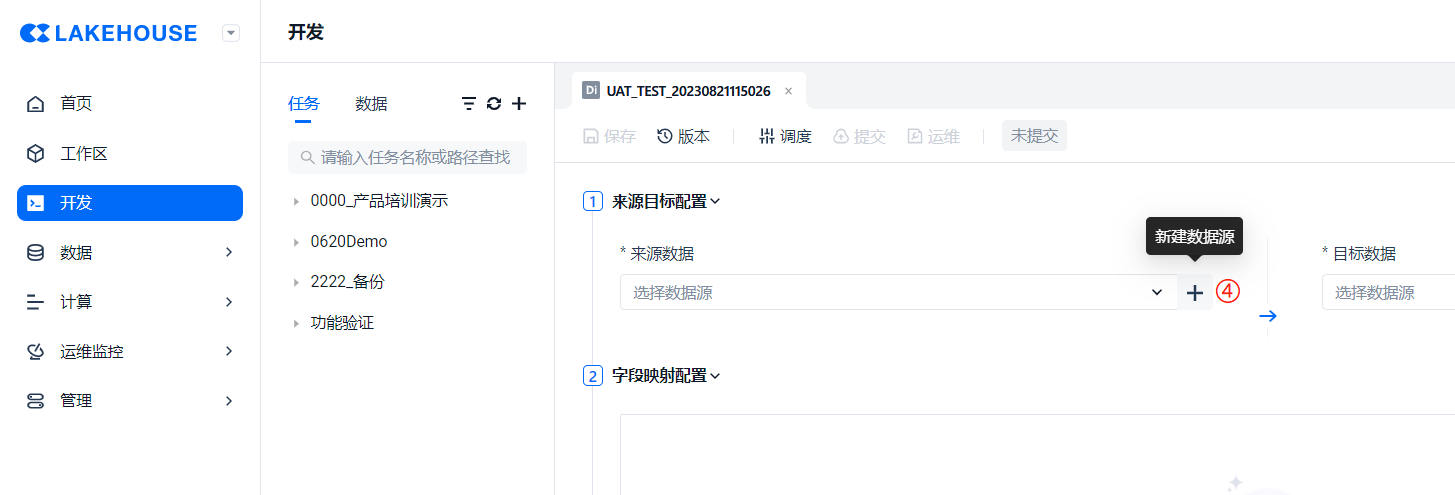
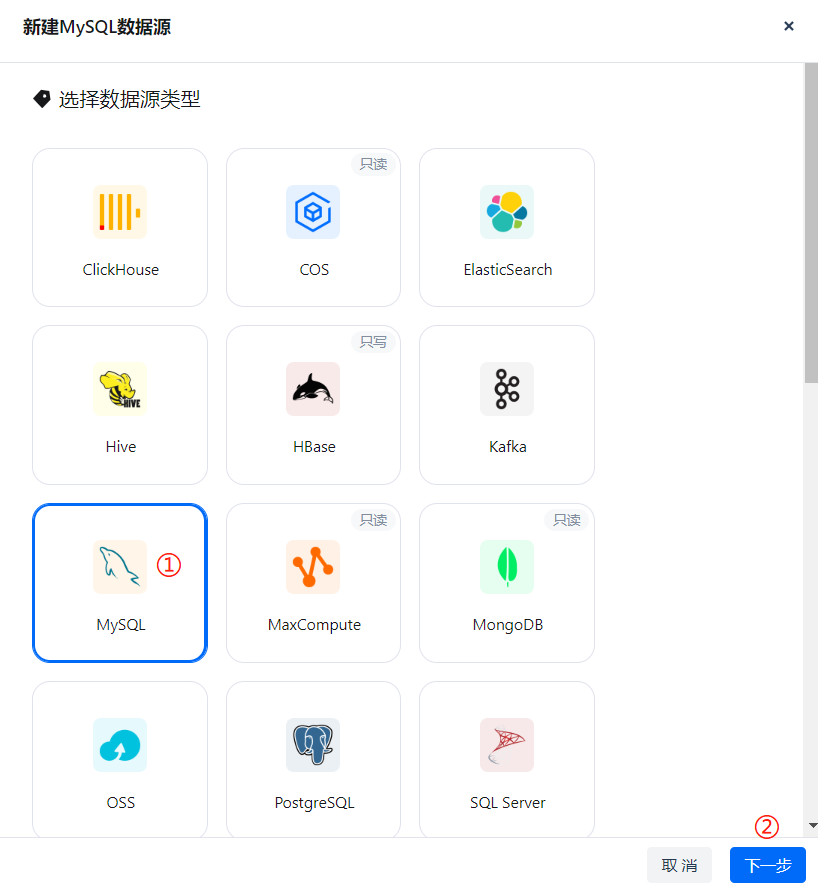
在新建数据源页面选择 MySQL 类型数据源,点击下一步。
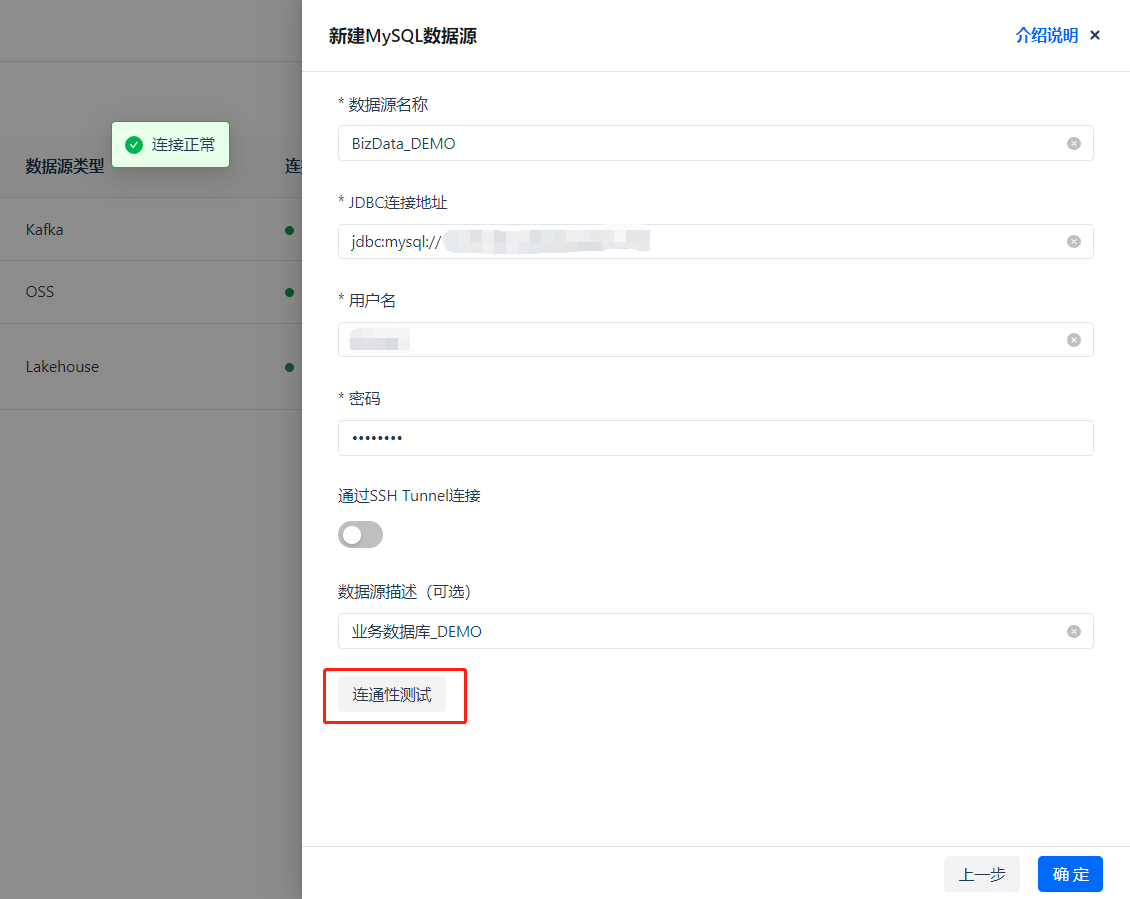
输入数据库连接信息,点击连通性测试,如果配置正确,会显示绿色的 [√连接正常],如果连接测试失败,则需要核对配置信息,或更改数据库的访问白名单策略。*如果需要定向添加 IP 白名单,请联系云器客服或客户经理。
创建成功后可在列表中看到该数据源。
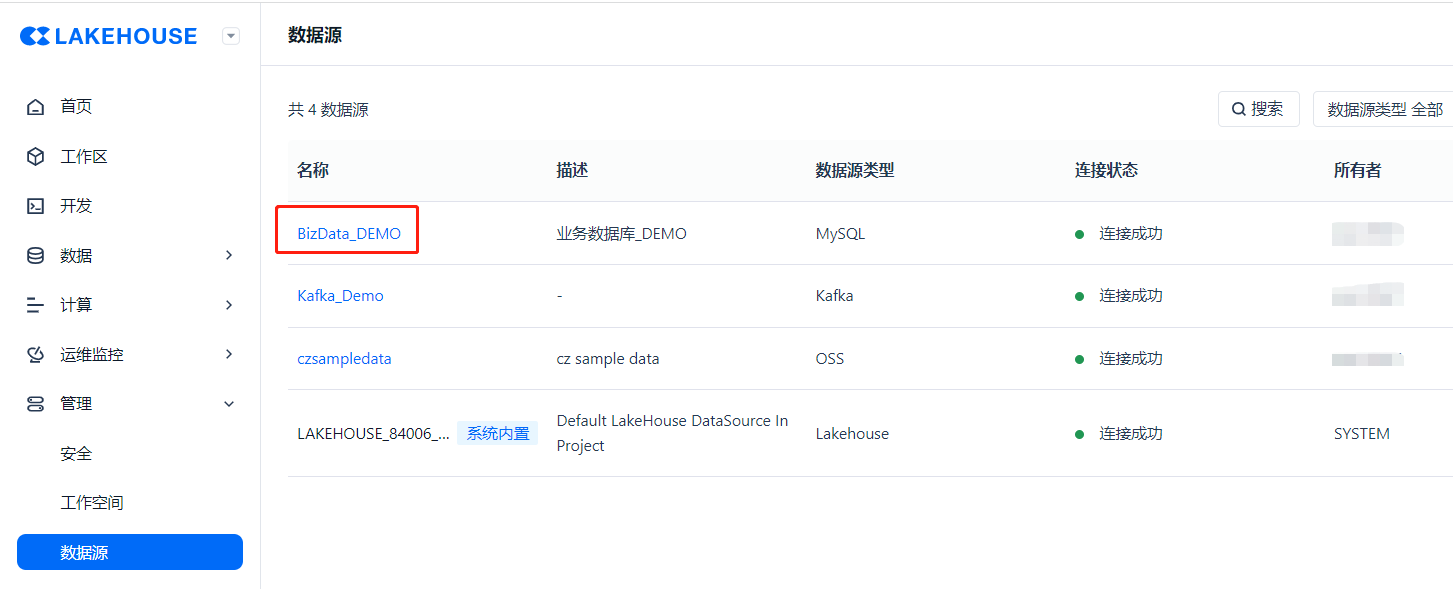
【创建数据集成任务】
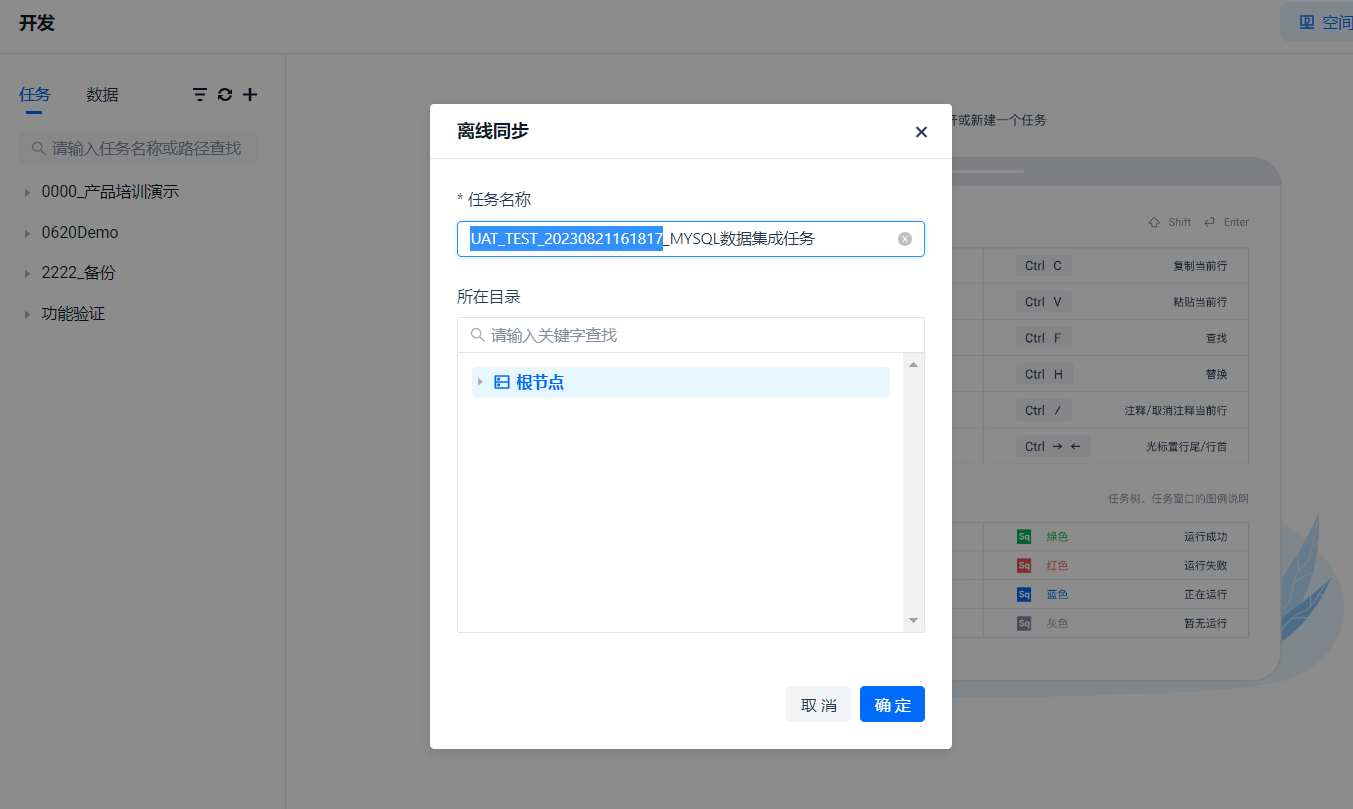
让我们回到 [开发] 菜单,创建一个 [离线同步任务]
这里的任务名称暂时命名为 “MYSQL数据集成任务”,点击确定。
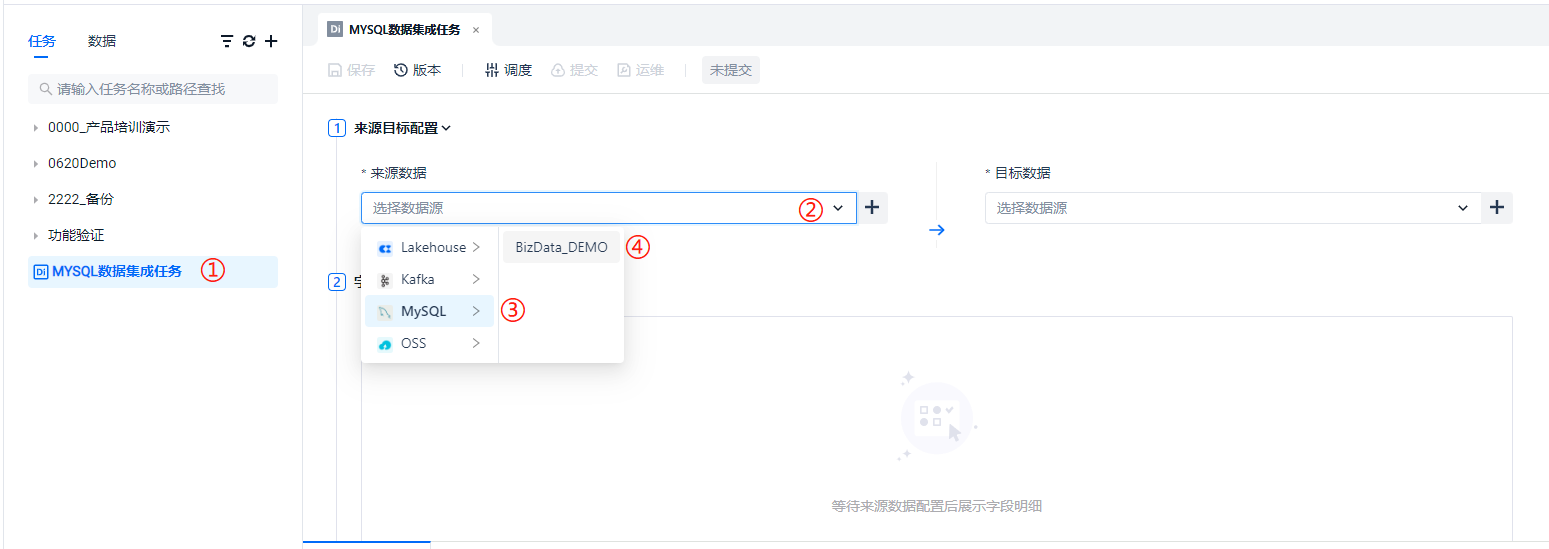
在 ① 的列表处可见刚才创建的任务,点击 ② 处选择数据源类型为 ③ 处的 MYSQL,并选择到我们刚才创建的数据源名称:BizData_Demo
在 ① 处选择库,在 ② 处选择表,在 ③ 处添加过滤条件,点击 ④ 处的按钮可以进行数据的预览。splitPk 是用于多并发抽取数据用的切分键,需要根据数据库中表 INT 类型主键进行数据分割,非必要项,此处不做深入演示。
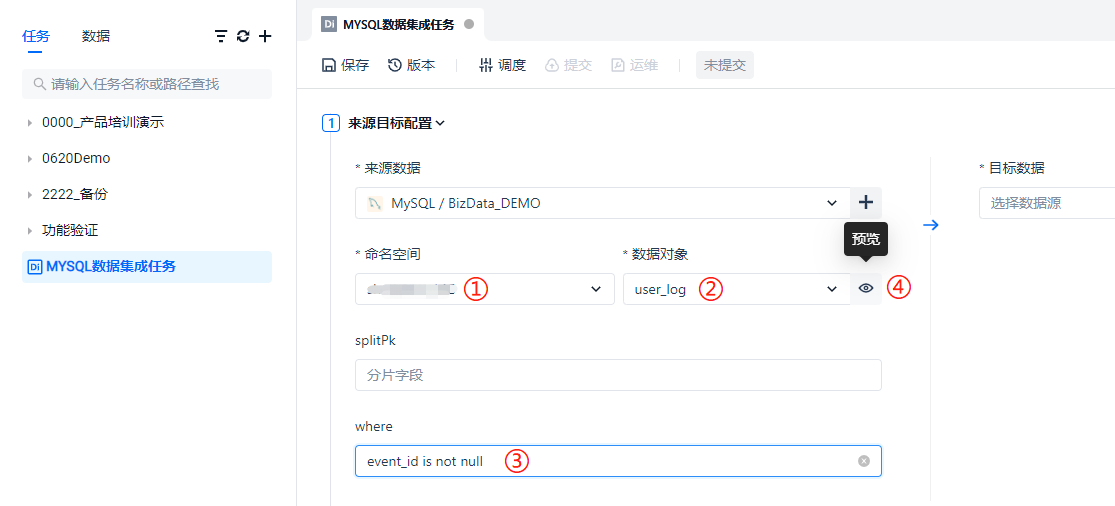
点击 [预览] 按钮后,会根据配置的过滤条件预览少量数据。
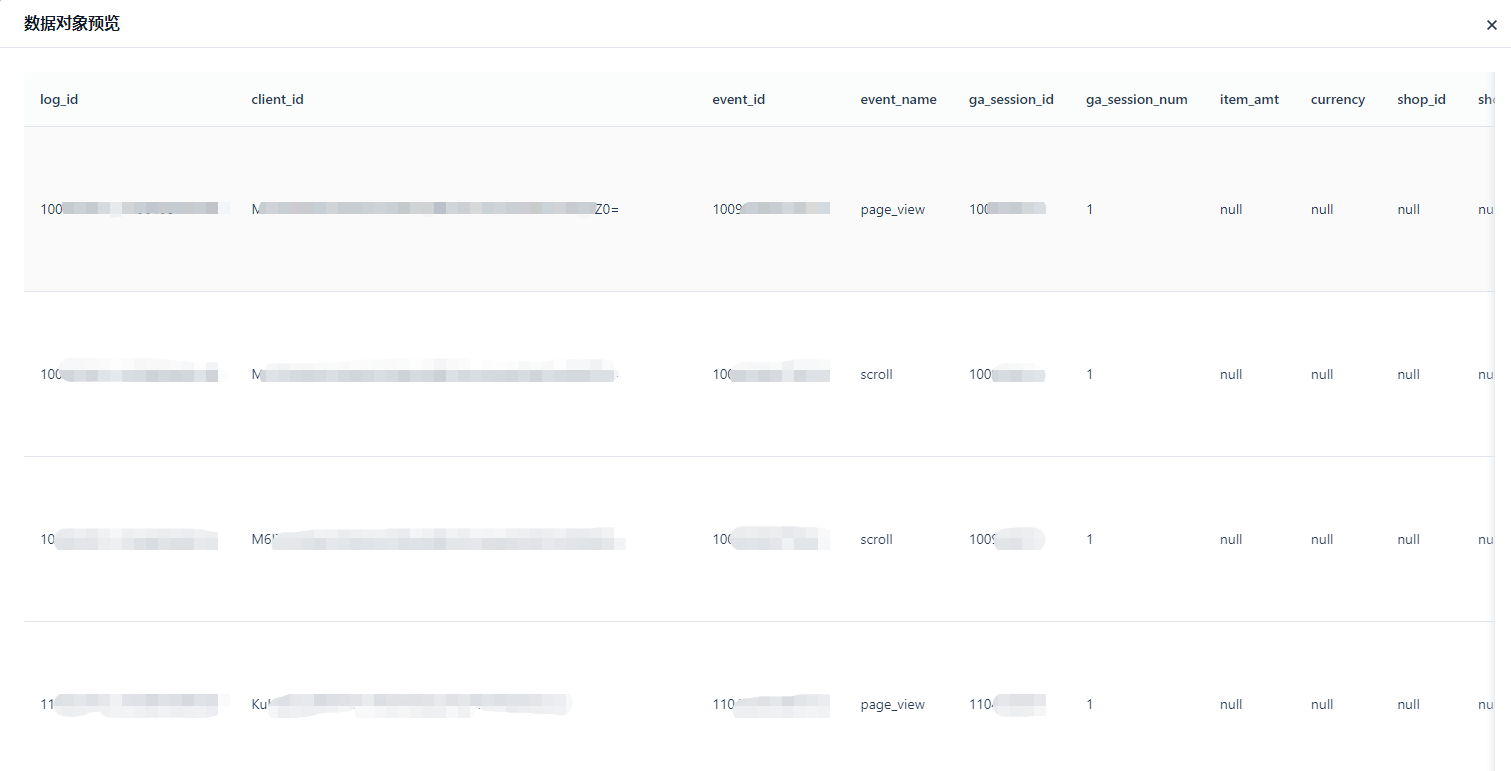
由于我们是从 MySQL 数据源向云器 Lakehouse 进行数据同步,那么目标端数据源自然是选择 Lakehouse 类型,如下图 ① → ② → ③ 步骤所示
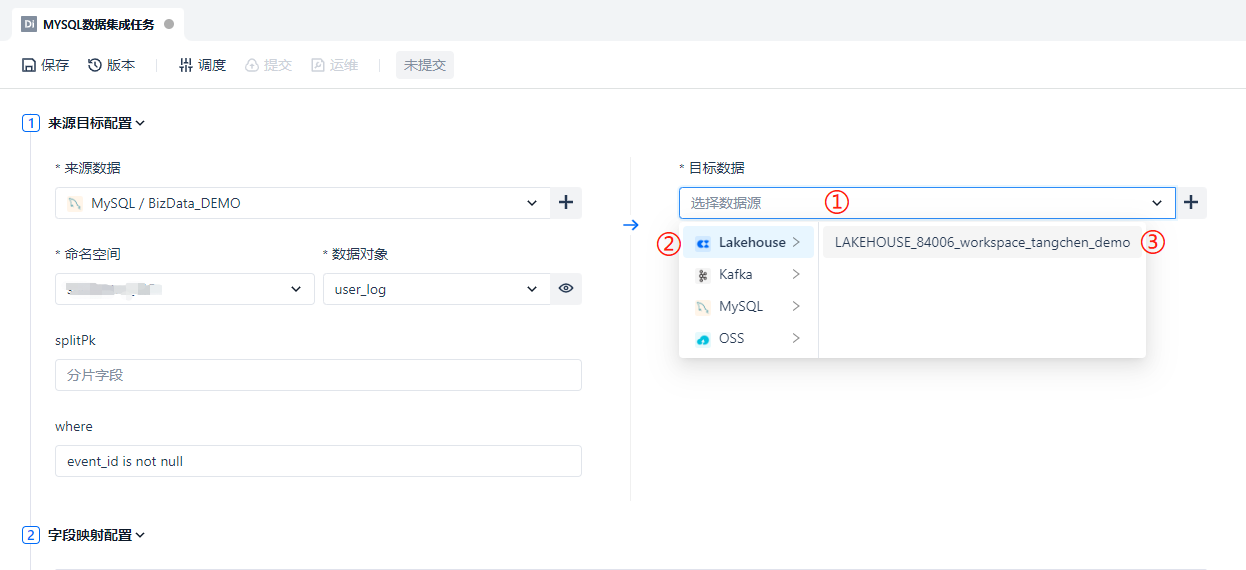
① 处的命名空间可以先选择默认的 public,数据对象由于是首次创建任务,还没有在 Lakehouse 端进行建表,所以 ② 处提供了贴心的一键建表功能。
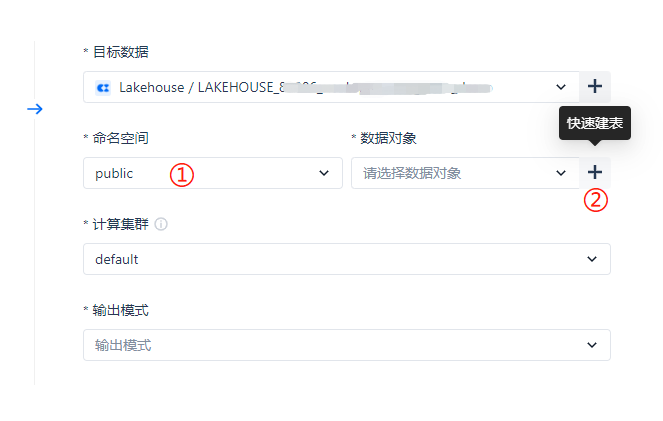
在弹出的一键建表窗口,如果点击 [确定] 按钮,会直接创建 Lakehouse 表;此外,还支持复制建表语句,方便用户进行修改后单独做创建操作。
注意:一键建表的 DDL 语句创建的不是【分区表】,不带分区字段。如果你希望在 Lakehouse 中创建分区表,请修改建表的 DDL 语句。分区表创建语法详见【SQL 参考】章节。
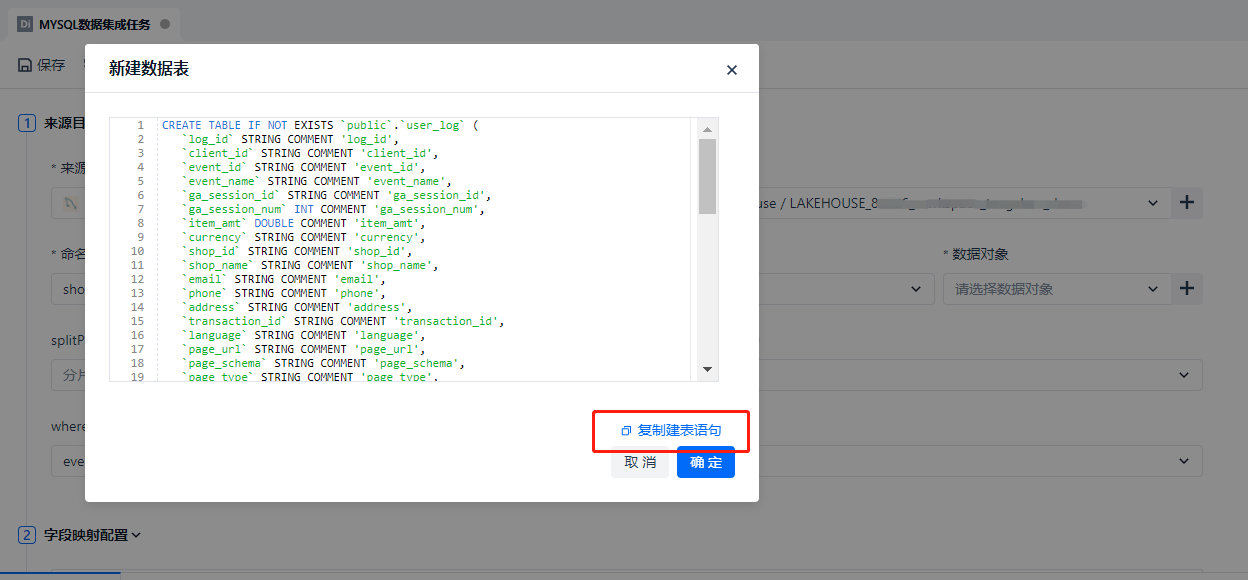
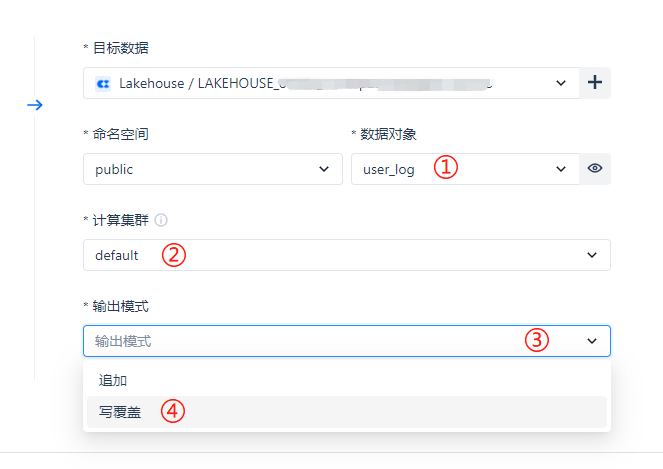
创建目标表后会在 ① 处数据对象直接选中该表,② 处的计算集群无需改动,默认选择 default 集群,③ 处输出模式选择上,由于我们做全量数据同步,因此一般会选择 ④ 处的 [写覆盖] 模式。
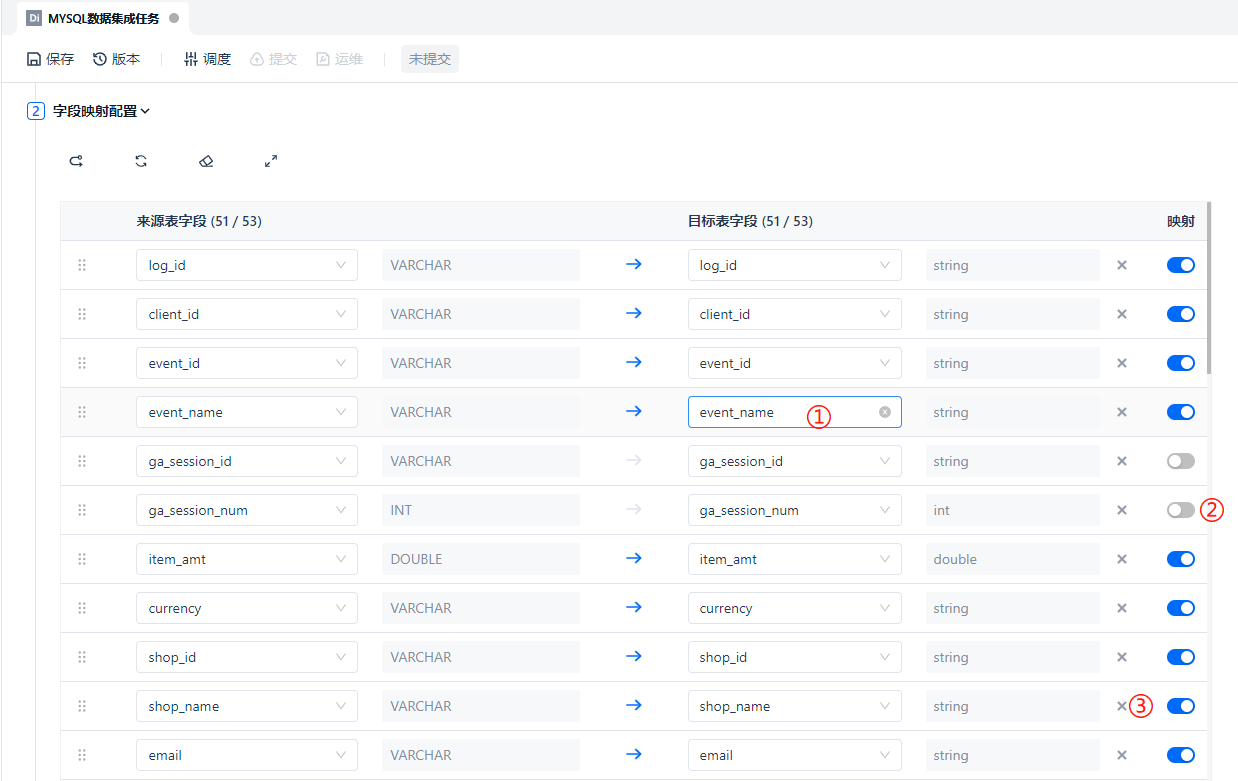
在选择完源端表和目标端表之后,下面的字段映射配置会显示出来。① 处支持直接修改目标端字段名,② 处支持开启该行字段的映射或暂时关闭(其他字段不受影响),③ 处支持删除单行的字段映射,用于减少一些明确的无用字段。
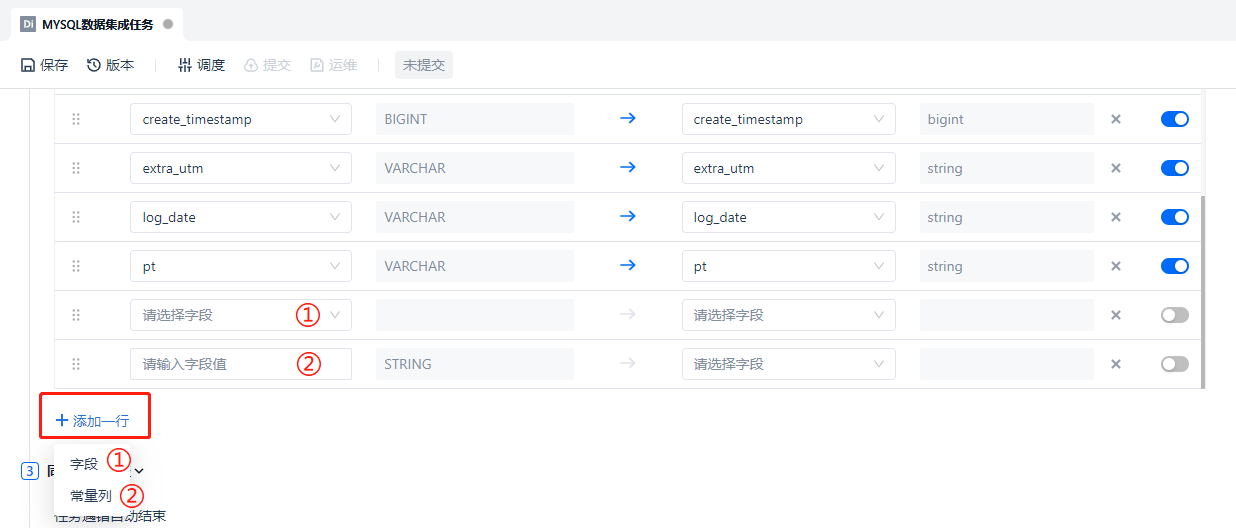
在字段映射底部,也支持手动添加字段,或常量列,手动添加的字段可以重复获取源端表中某字段的值,赋予目标端的某个其他字段,常量列支持在数据同步的同时做一些轻量的处理和转换,可以给目标端字段赋值固定值,或函数表达式。本例中不涉及此操作,因此不予以演示。
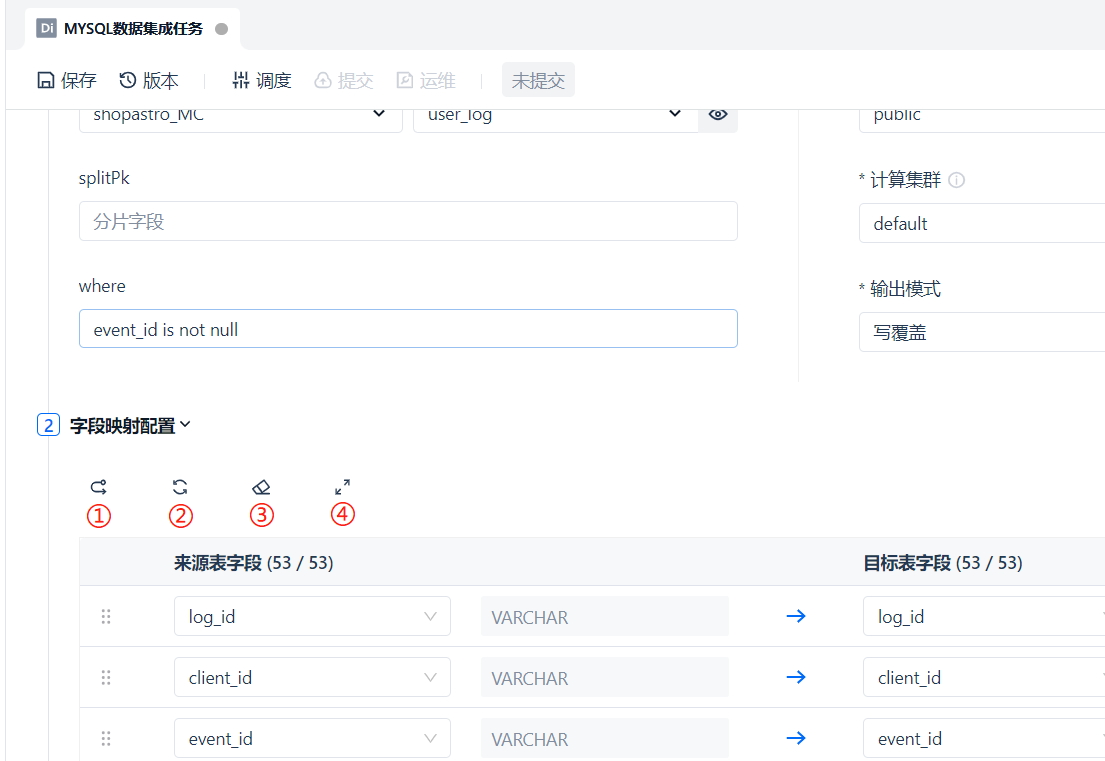
那么万一字段映射填写错乱了,想要重置字段映射关系该怎么办?在这里我们也贴心准备了重置刷新等功能,分别是 ① 同名映射 ② 重置刷新 ③ 清除映射 ④ 全屏化。
任务配置完成后,位于 ① 处的 [保存] 可对任务进行保存,位于 ② 处的 [版本] 可以查看历史版本信息,这里不再赘述。值得一提的是位于 ③ 处的 [调度] 配置完成后,可以解锁后面的 [提交] 按钮,只有任务提交到生产环境了,才会根据调度的配置进行作业的调度,因此在任务 [提交] 后会解锁 [运维] 按钮。
但在任务保存之后,我们通常会点击位于 ④ 处的 [运行] 按钮,尝试手动运行任务,完成数据的初始化集成。
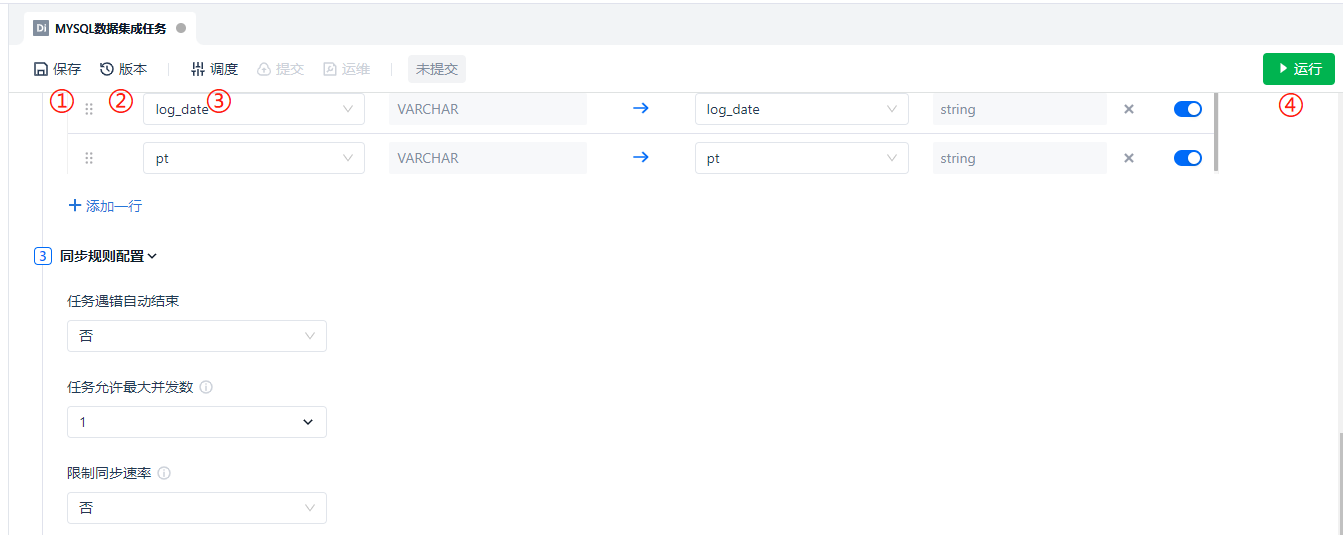
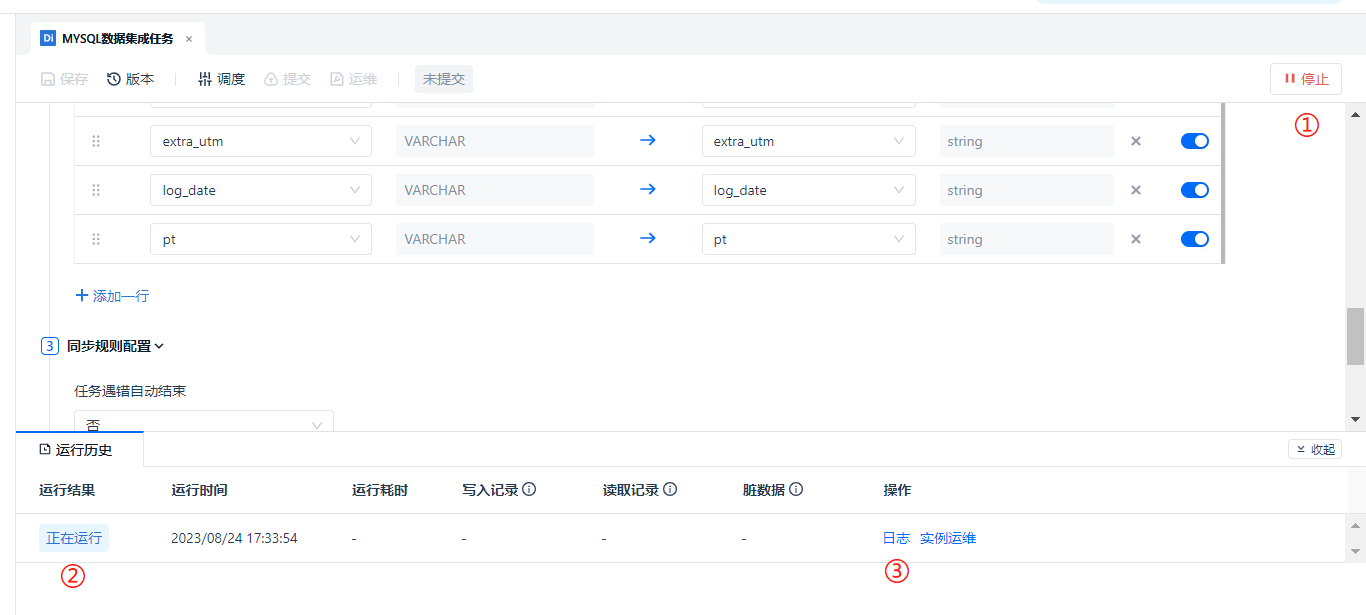
点击 [运行] 启动任务以后,① 处的 [运行] 按钮会变成 [停止] 按钮,下方的运行历史会增加一个条目,在 ② 处标记了正在运行的任务实例,右侧的操作栏下,一般查看位于 ③ 处的 [日志] 即可查看任务运行详情。
日志信息如下所示:
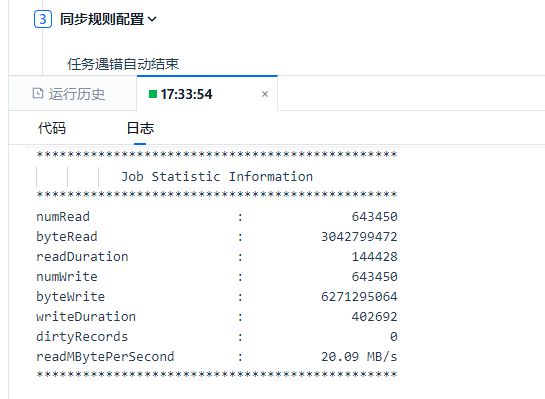
接下来等待任务完成即可。至此,数据已经写入云器 Lakehouse 了。
【配置调度依赖】
我们先别急着去查看数据条数,继续完成调度上的配置。点击上边功能菜单的 [调度] 按钮,右侧滑出调度菜单,我们下拉快进到 [调度时间] 部分:在离线 T+1 场景中,调度周期配置为 [每天调度] 、[执行一次]、[00:00 开始调度]、当天开始生效、[永不失效] 即可。
其中 ① 处还可以选择为 [每月指定天],[每周指定天] 的方式,② 处可以选择为 [执行多次] X 分钟的调度周期间隔。
在 [实例信息] 部分,由于我们刚刚已经运行过任务了,那么位于 ③ 处的实例生成方式可以选择为 [次日生效]。(注意:每日多次的任务在发布后要选择 [发布后生效],否则要等到第二天才会开始运行)
[实例遇错重跑],则是处理任务报错重跑的策略,通常我们选择 [运行成功或失败后皆可重跑] 即可,这里不作过多赘述。
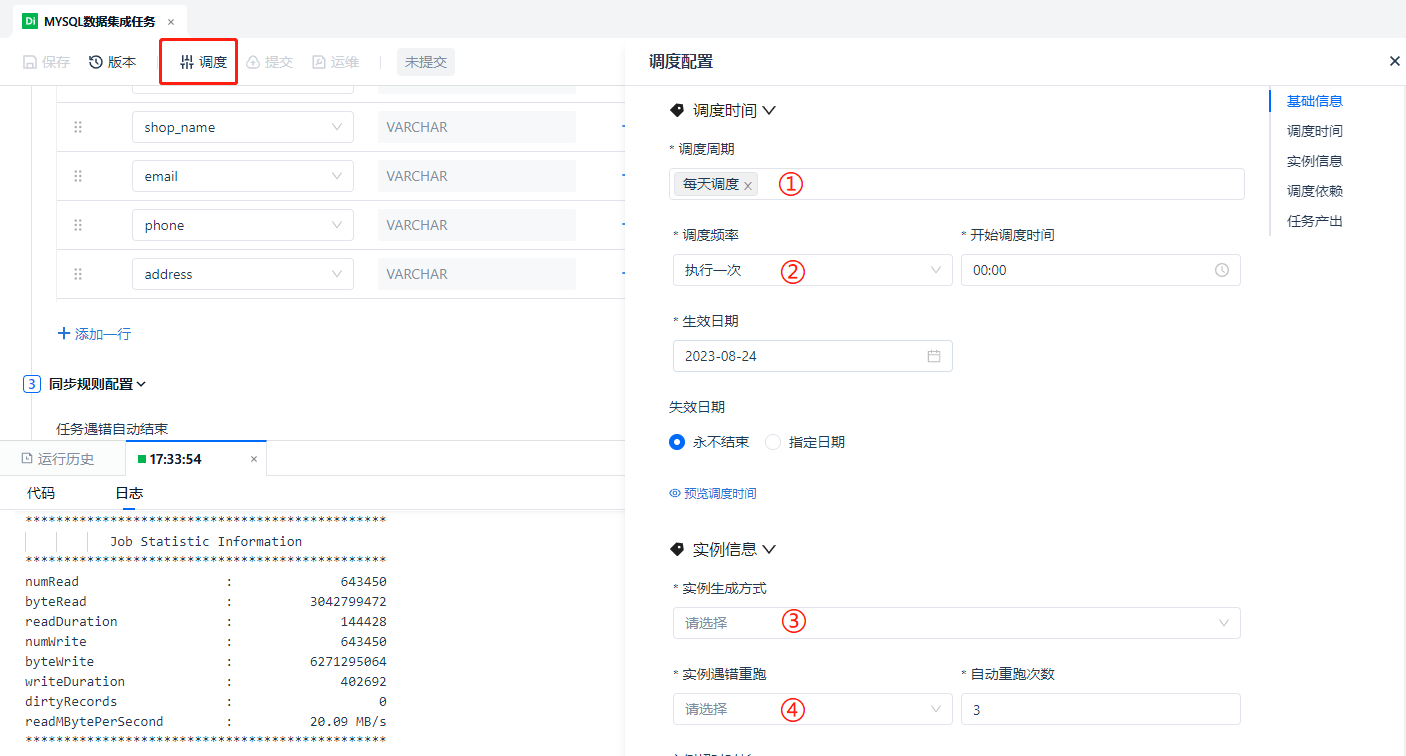
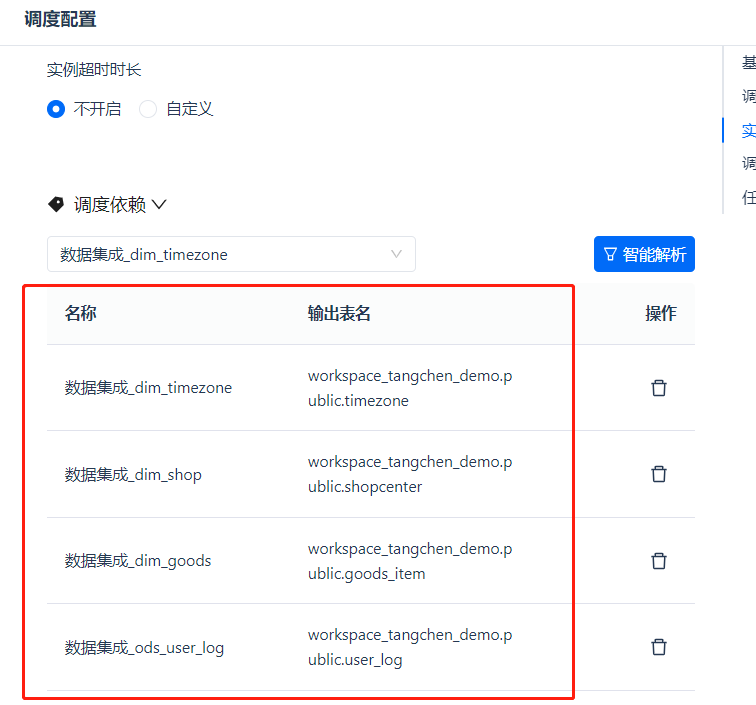
最后我们来到 ① [调度依赖] 和 ② [任务产出] 这部分,配置完成后我们点击 ③ [确定] 按钮,即可解锁 [提交] 按钮了,就具备将任务提交到生产环境进行作业调度的条件了。
关于 [调度依赖],我们都知道一个标准的数仓处理过程都是从数据的接入开始的,所以数据集成任务通常作为整个链路的起始节点,是没有上游依赖任务的,因此位于 ① 处的 [调度依赖] 此处不作任何设置。当然数据集成任务一般也不会长达一天的时间,因此下方的 [自依赖] 也无需勾选。
关于 [任务产出],首先要解释一下任务产出是做什么用的:当前完成配置的数据集成任务的作用是把源端数据库对应表的数据写入目标端的目标表,因此在整个调度系统中,需要宣称这个目标表是被这个任务所“生产出来”的,即“任务产出”。
此处所定义了的任务产出的表名,不单单必须是目标表的“物理真名”,也可以是人为更改的其他“别名”,甚至是多个不同的别名。其最主要的作用是使该任务所产出的表可以在整个调度依赖系统中被其他任务搜索到,从而形成上下游的依赖关系。其最大的应用则是在调度系统中可以被其他任务所依赖。
因此,这里提供了人工自定义添加表名,和系统 [智能解析] 功能按钮。本例中,不做别名的特殊调整,所以直接选择 [智能解析] 即可,如图所示。
完成配置后点击 [确定],解锁 [提交] 按钮。
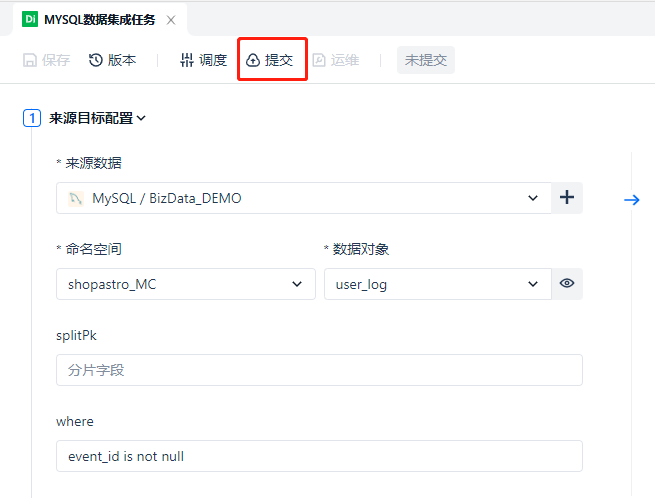
【提交发布任务】
点击 [提交] 按钮,会弹出与历史版本对比的确认窗口,本例中是首次提交,直接点击 [确定] 即可。
提交成功后会弹出提示,并且任务状态会改变:[未提交] → [已提交]
至此,一个数据集成任务就发布完成了。 接下来我们可能会有两个疑问: 1、刚才同步了数据,我是不是要查看一下数据量对不对,并进行一下预览; 2、数据集成任务发布到调度系统中去了,怎么去运维和查看这些任务。 针对以上的 2 个问题,我们分别会在接下的【数据开发】章节与【任务实例运维】章节进行讲解。
【创建数据开发任务】
按图所示创建 SQL 任务,可以进入到 SQL 的 编辑器页面,我们先进行一些基本的数据探查,比如核对一下刚刚接入表的数据量,预览一些数据等等。
任务名称暂定为 “SQL数据开发任务”,点击确定。
创建成功后进入 SQL 编辑器,功能按钮与数据集成任务大致相同,多了 [格式化] 按钮用于美化 SQL。
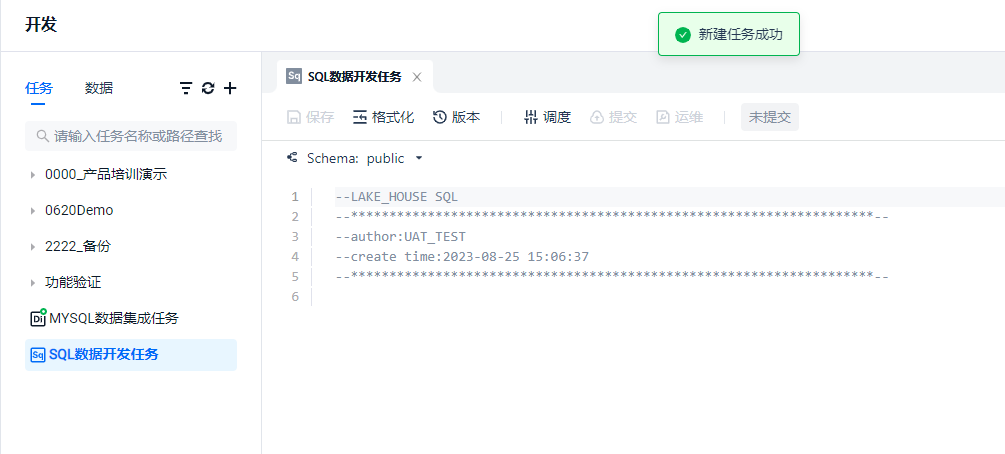
通过统计表条目数语句,查询结果。在 ① 处可以局部 / 单行执行 Query,在 ② 处会全部脚本运行任务,无论用 ① 或 ② 的方式,运行都是在 ③ 处查看结果。
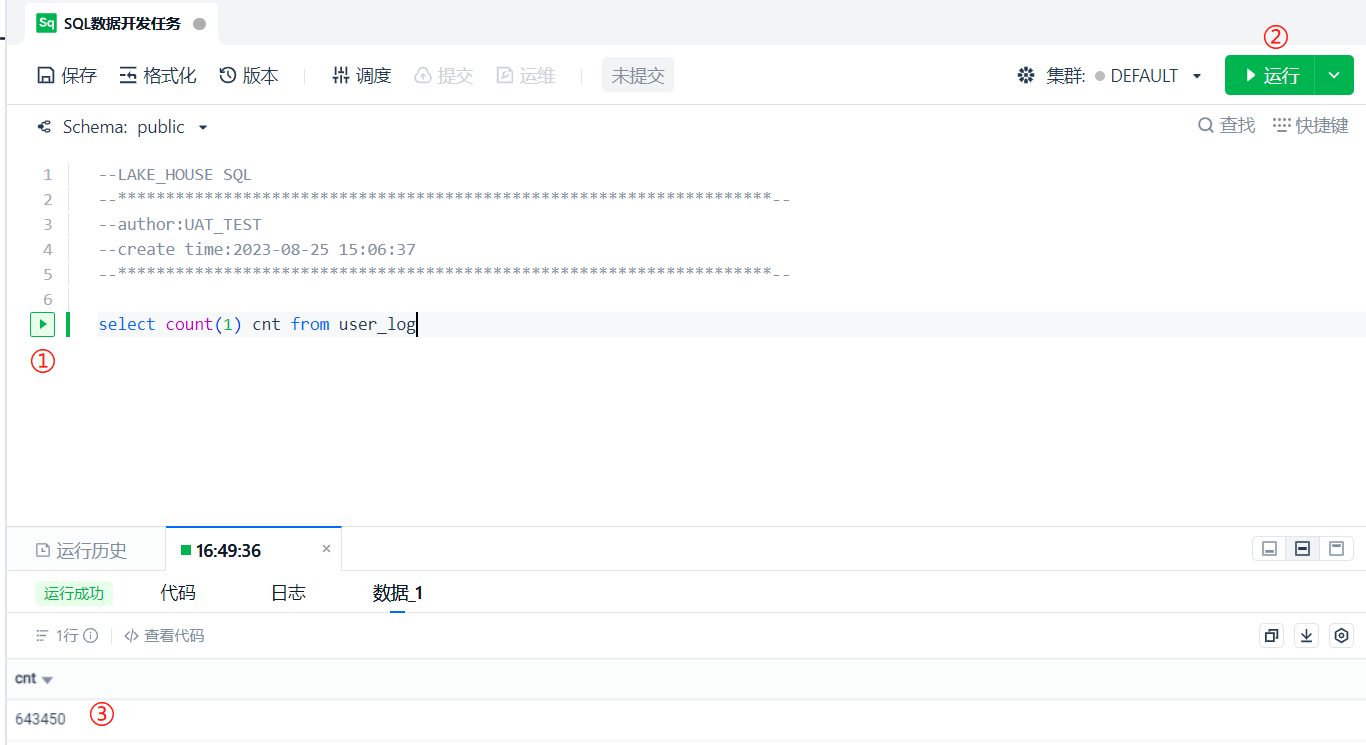
之后我们再去源端数据库中查询一下这个表的条目数,可以发现两边条目数一致。(别忘了我们再数据集成的 [筛选] 处添加了 event_id is not null,在查询源端数据库时也要加上这个条件)
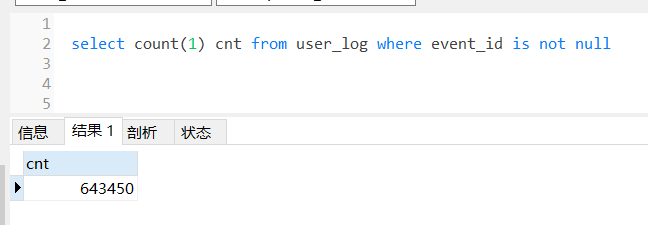
好的,两边数据量一致,再通过类似以下的脚本来预览一下数据,看看数据格式是否都正确等等。
截止到这一步,基本的数据探查已经完成,接下来我们来构建整个工作流。
让我们再来确认一下业务目标:我们按照从左到右的顺序,已经完成了数据源的配置,并且学会了如何创建数据集成任务和数据开发任务。
那么,我们只需要重复多次【创建数据集成任务】,就可以将这 4 张表创建出来,并将数据接入到云器 Lakehouse。
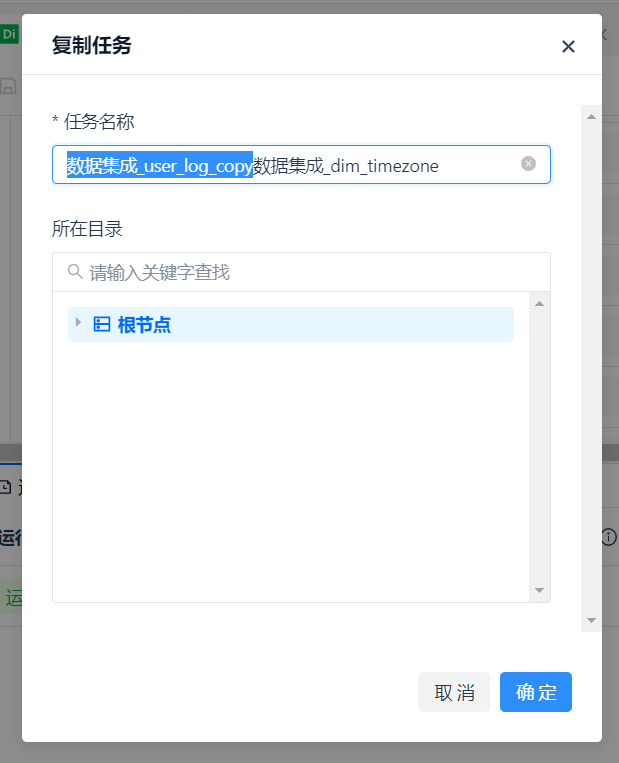
通过任务名称右侧的 [更多] 选项中的 [复制] 功能,可以快速复制出 4 个来自相同数据源的任务,再略微修改配置,一键创建目标表,可以非常方便地完成任务的创建。
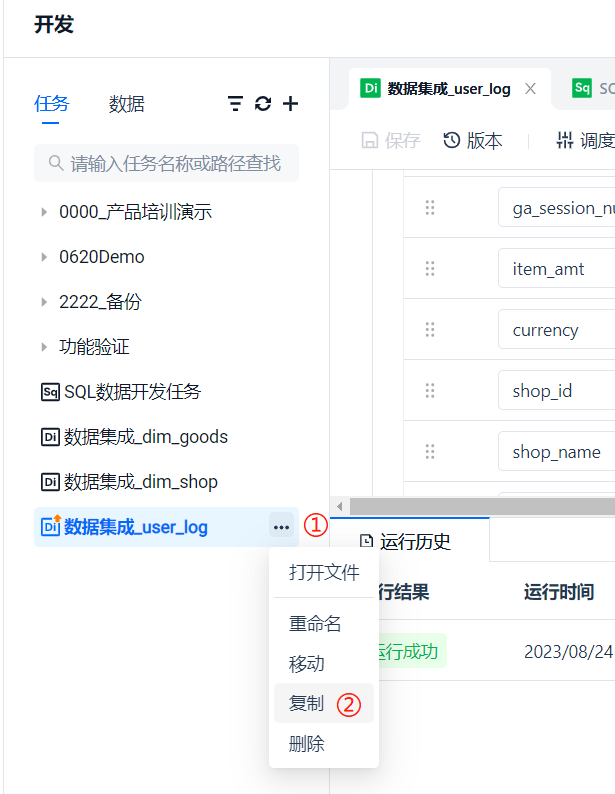
复制出来的任务名默认是在原有任务名上增加 “_copy”,这里只需要按需改成我们想要的名字即可。
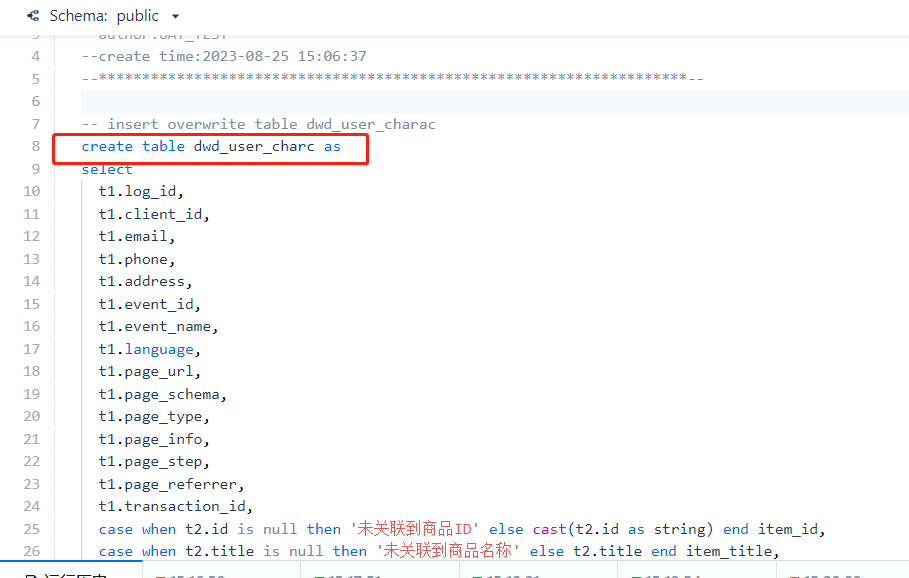
接下来,修改数据开发任务中的脚本内容,完成 user_log 表与 shop、goods、timezone 3个维度表的关联查询,并将结果写入 dwd_user_charac,如果是首次创建表,可以使用 create table xxx as select... 的语句,单独运行一次即可。当然如果需要每天进行任务调度的话,最终提交的任务中,写入方式应该是 [覆盖写入](insert overwrite)。
通过模糊检索选择上游的调度依赖。
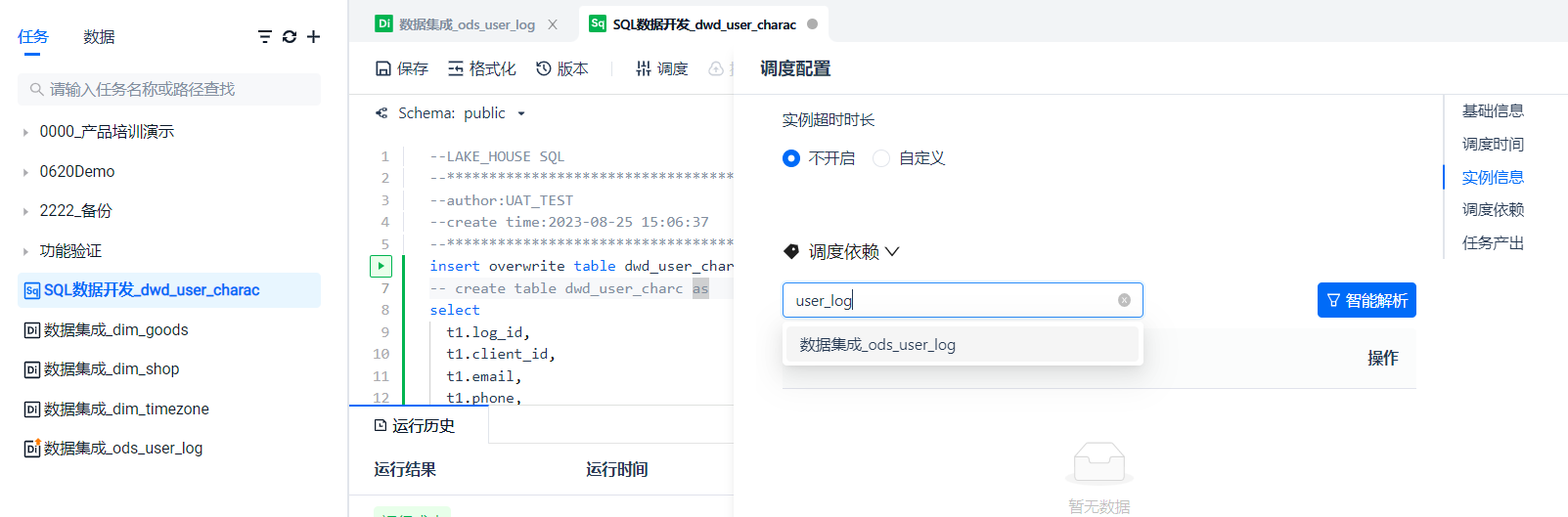
我们直到所有的数据集成任务都完成后才能执行 SQL 加工任务,因此添加四次上游任务即可。
其他的配置与上面讲过的方法一样,最后别忘了 [保存] 和 [提交],所有提交后的任务图标应该是带有绿色圆圈上角标的样式。

好的,至此,我们已经完成了所有数据集成任务和数据开发任务的创建,并且已经运行过了一轮任务。接下来,我们介绍一下如何去 [运维中心] 中查看这些任务实例及血缘关系。
【任务运维】
任务提交到生产之后,我们来介绍一下基础的运维工作。通过左边菜单栏点击 ① 处的 [任务运维] 进入到运维中心。按照上面 ②③④⑤ 的页签,分别表示了 [周期任务]、[实时任务]、[补数任务],以及 [任务实例]。
当我们点击进入【任务运维】功能模块时,页面默认跳转到的是 ④ 的 [任务实例],因为运维人员一般关心的就是任务实例每天的运行状态和运行结果如何。而任务实例分为 ⑥ [周期实例]、⑦ [临时实例] 两种,任务实例的运行状态有:⑧ [运行成功]、⑨ [运行中]、⑩ [运行失败] 3 种。
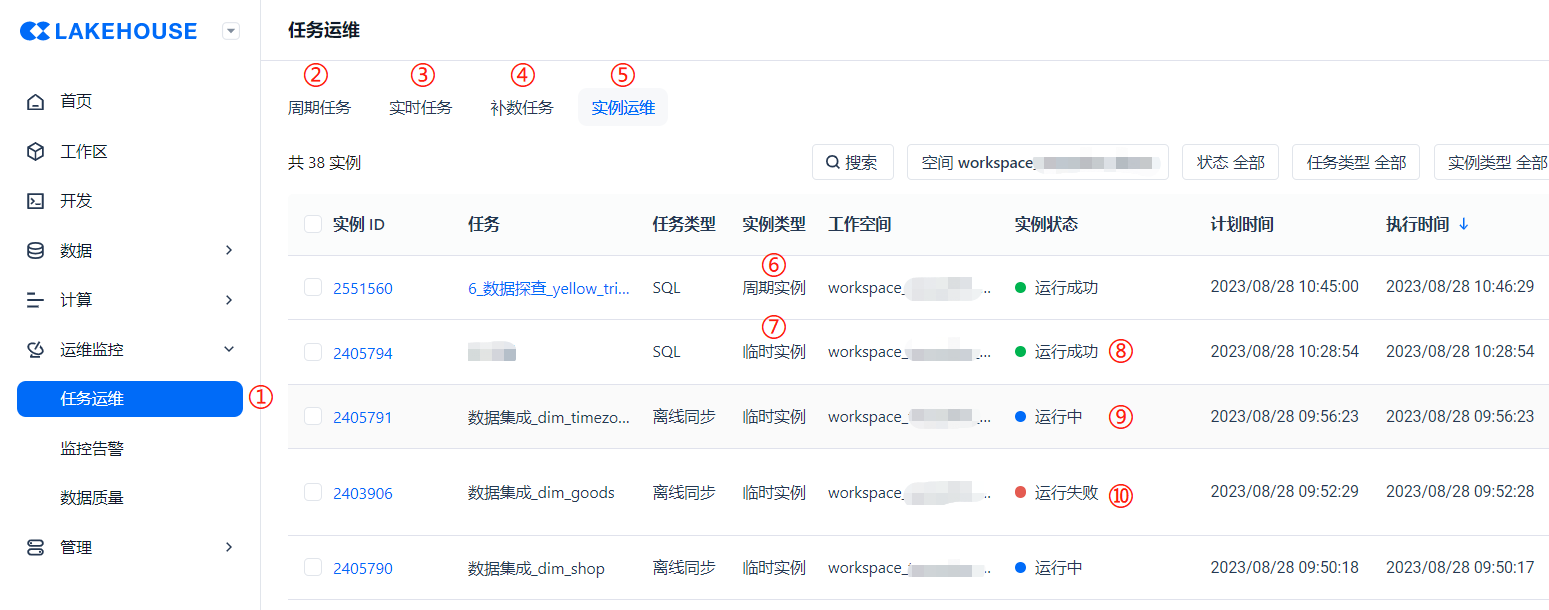
这里我们要理解【任务】和【实例】的区别:任务是指一种预设的工作流程配置,而实例则是将这些工作流程配置的实例化,也就是实际执行的事例。
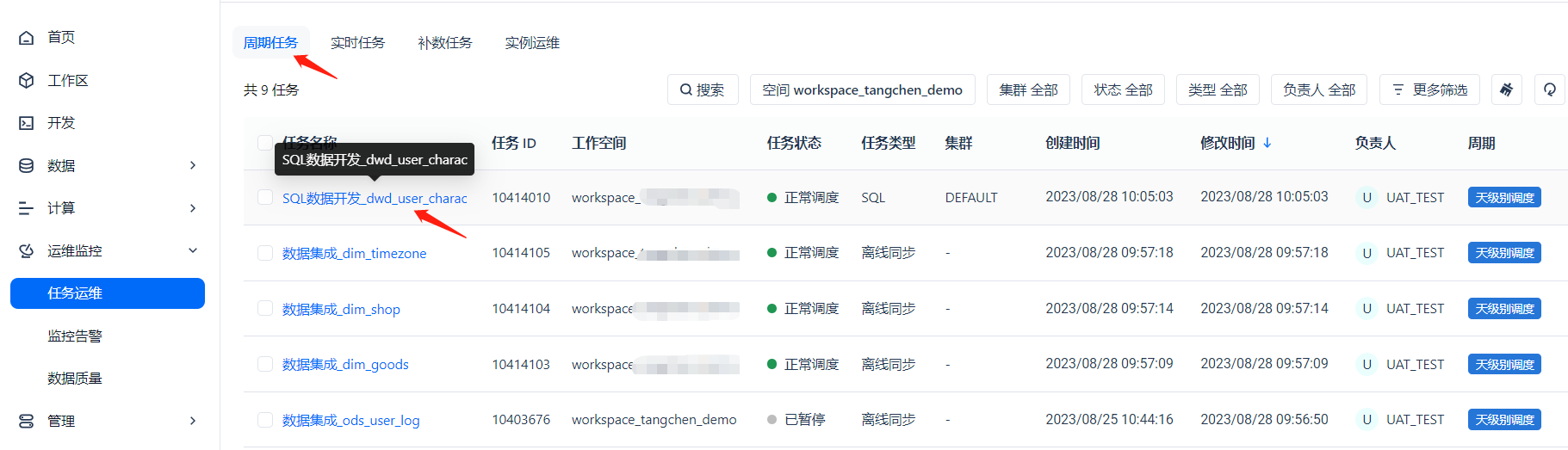
我们点击周期任务这个页签,查看我们发布的 SQL 数据开发任务,可以进入到任务详情页面。
任务详情页面除了自身的信息 ①[任务详情] 以外,还提供 ② [任务实例]、③ [节点代码]、④ [操作日志] 的查看页签,这里仅展示任务详情页签。 任务详情上半部分展示的是任务的一些元数据信息。
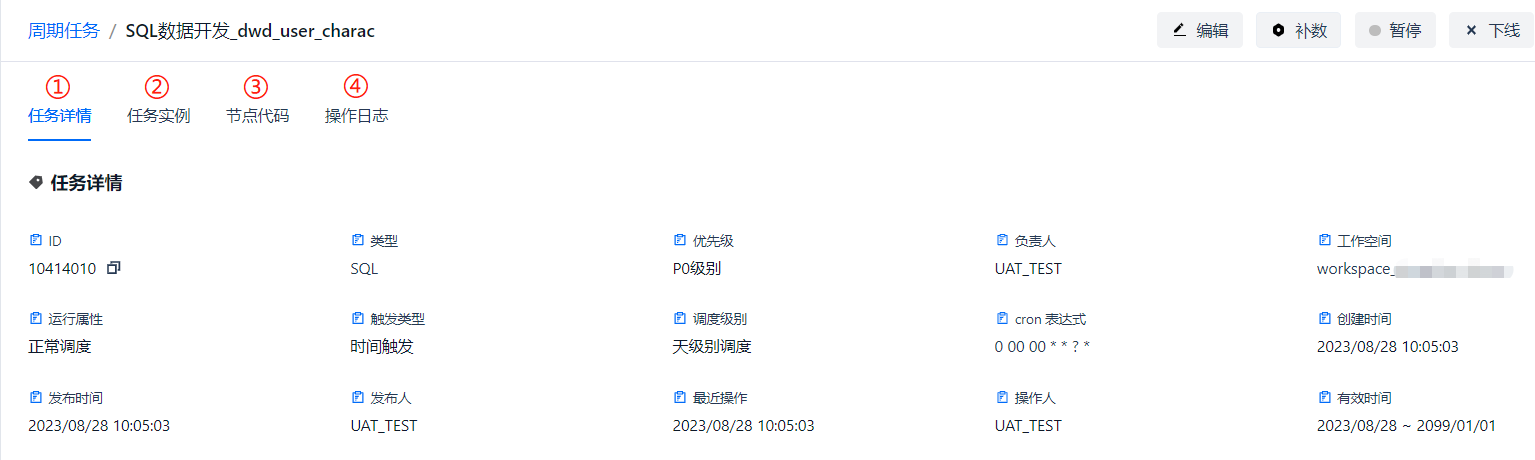
下半部分则展示的是该任务与上下游任务之间的依赖关系。
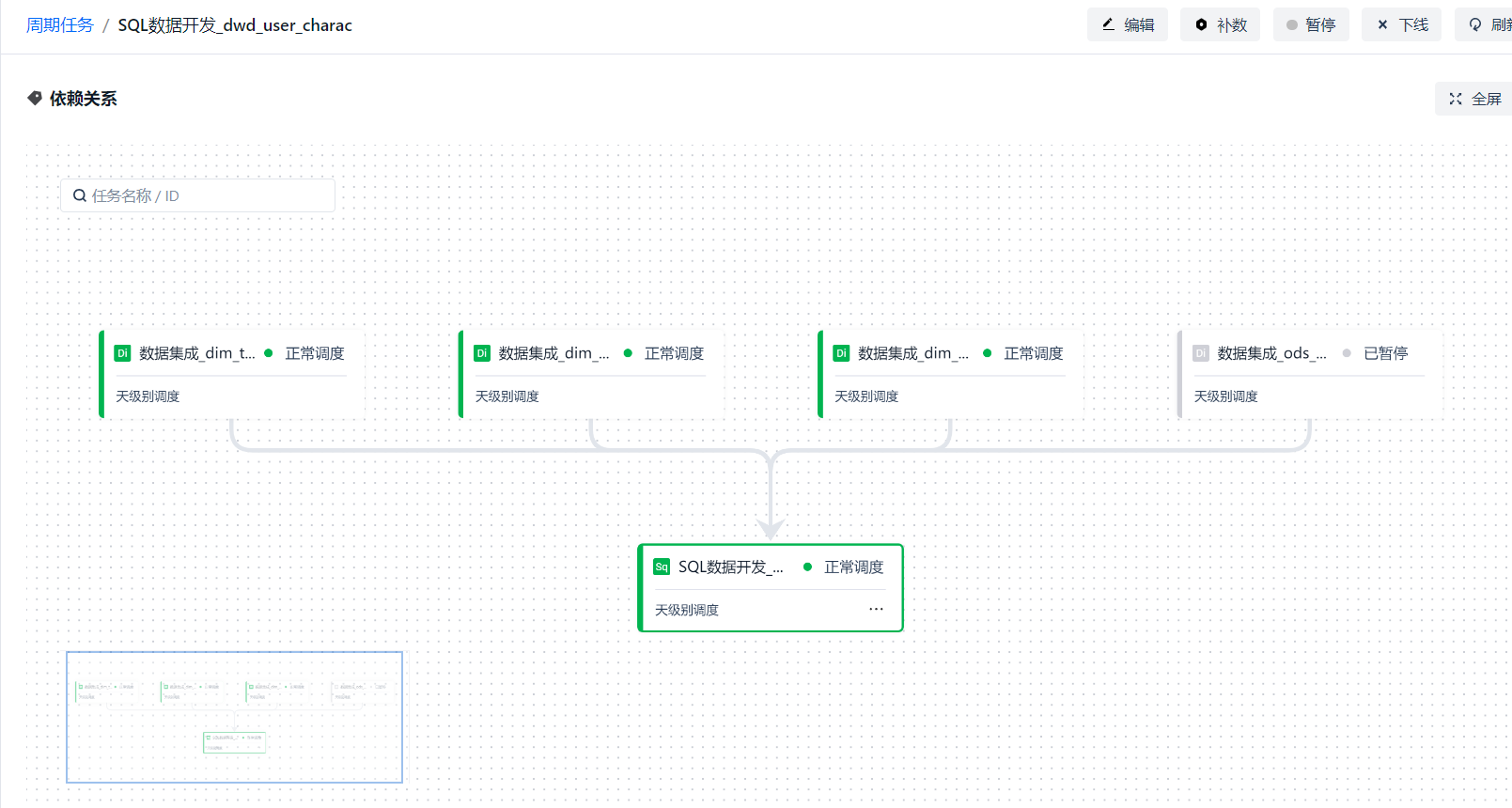
那么上面是任务的详情,在实例的详情中一样可以看到实例的运行状态,和任务详情相似,不同的是节点展示的是实例的实际运行情况,并支持对实例进行一些置成功、置失败、重跑等操作,这里一样不加以赘述了。
【连接 BI 工具】
根据上面的内容,我们假设现在所有的数据准备工作已经完成,下一步就是数据的应用了,在本例中数据仓库加工后的数据最终展示在 BI 看板上。
首先我们要了解的一点是,云器 Lakehouse 提供了丰富的 SDK,允许 BI 工具通过 JDBC 或 Python SqlAlchemy 直接连接访问 Lakehouse,因此市面上常规的 BI 工具,如:帆软 BI、SuperSet、Tableau、衡石 BI、Power BI 等大多都可以支持。
以帆软 BI 为例,首先我们可以到 < JAVA SDK 简介> 章节处获取 JDBC Driver 。

下载到 JAVA SDK 后,我们需要在帆软 BI 的系统设置中将这个 Driver 添加到第三方数据连接驱动中。 帆软 BI 稍微特殊一些,默认是不允许用户本地上传驱动的,需要打开后台的开关。操作步骤参见官网文档: https://help.fanruan.com/finebi/doc-view-1540.html
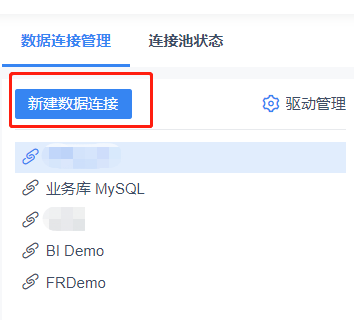
在获准管理驱动之后,我们通过系统设置进入到数据连接管理。
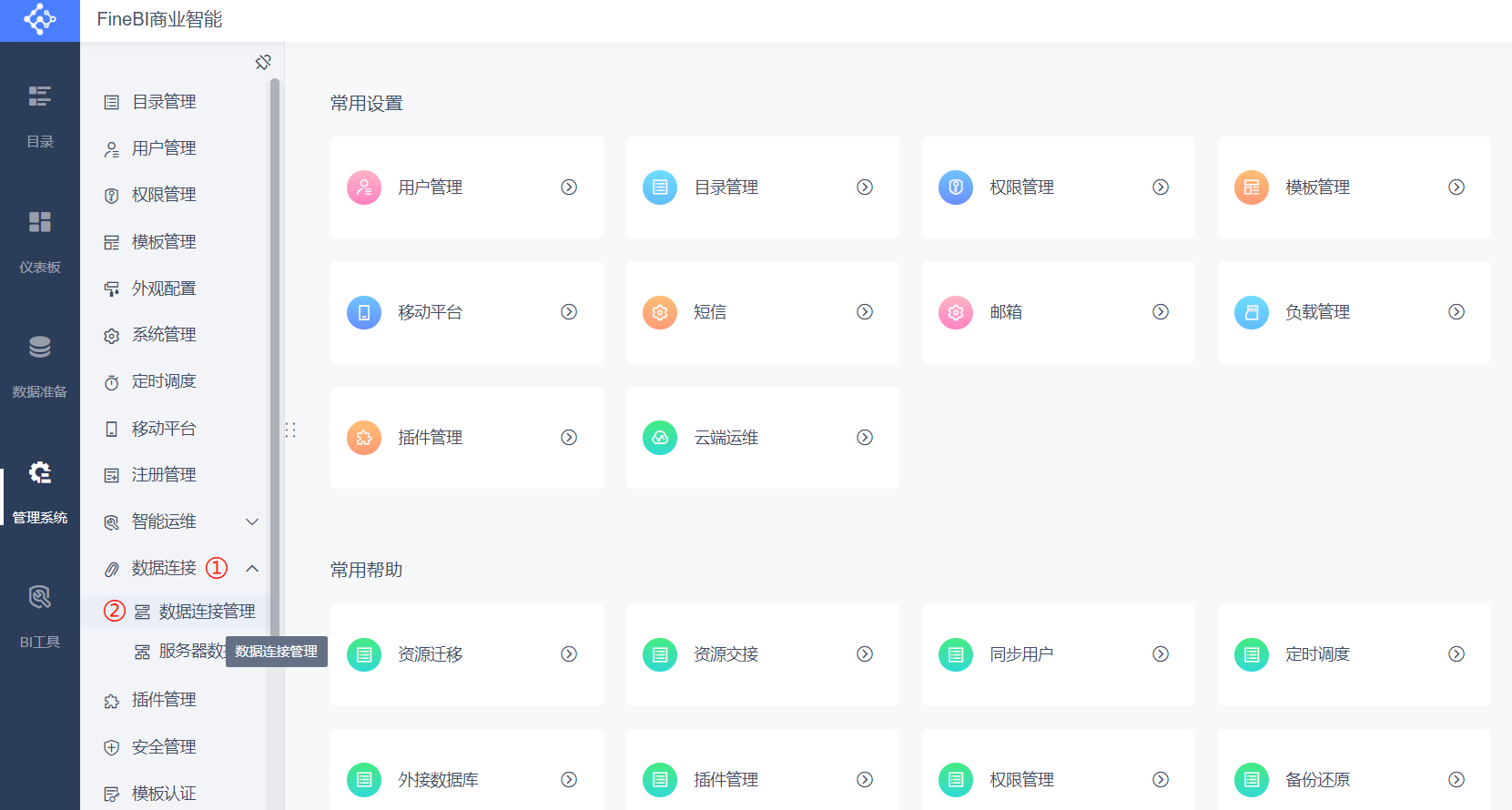
在右侧的页面中选择 [驱动管理] → [新建驱动]
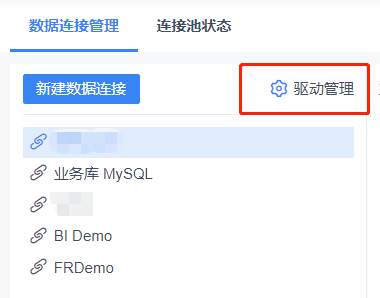
驱动名称可以自定义命名。
按图上 ① 处上传文件,文件上传及解析后在 ② 处点选 ③ 的类。
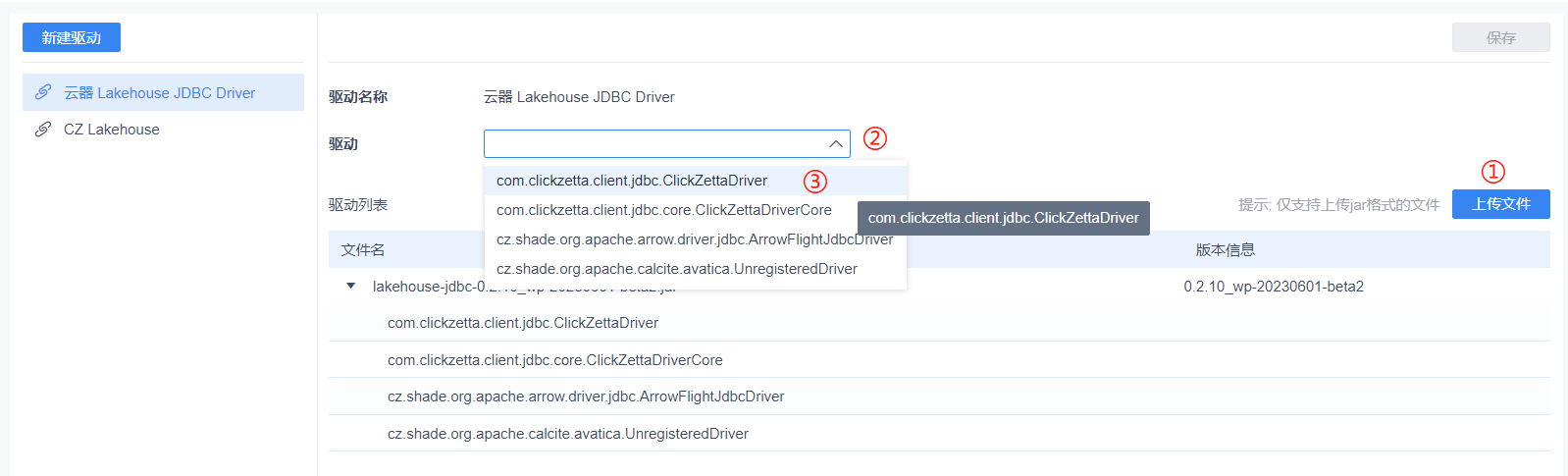
点击右上角进行驱动的保存。

配置完成后,我们退回到数据连接管理,就可以新建 Lakehouse 的数据源了。
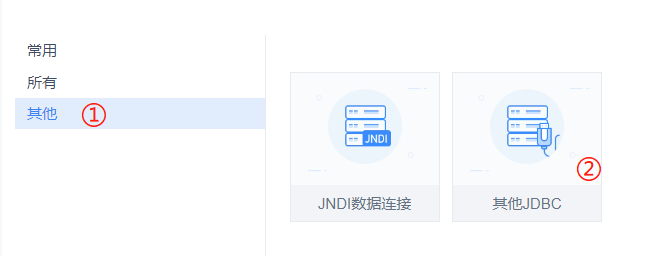
由于我们目前还属于第三方连接驱动,因此我们选择 [其他] → [其他 JDBC]
在这里,我们选择驱动类型中的 [自定义]
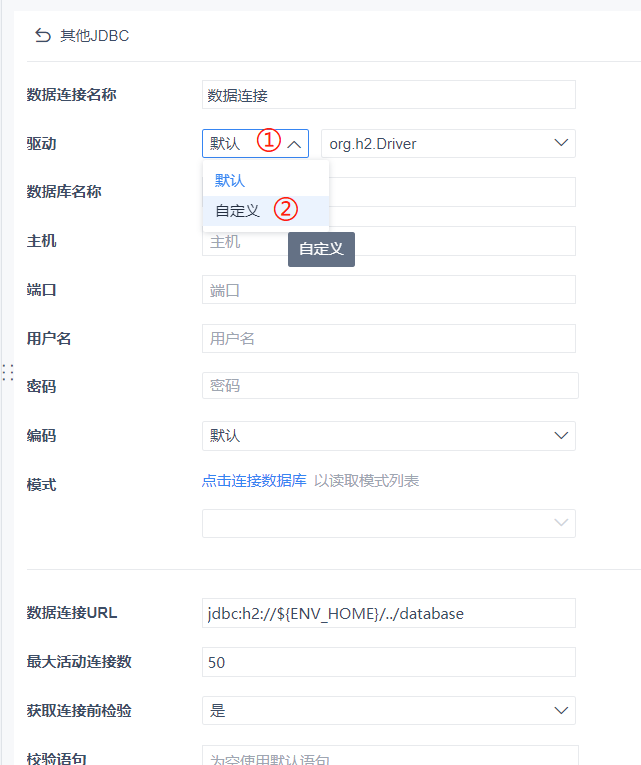
如果找得到我们刚才添加的驱动选项则直接选择,如果找不到则点击右侧的 [添加驱动]
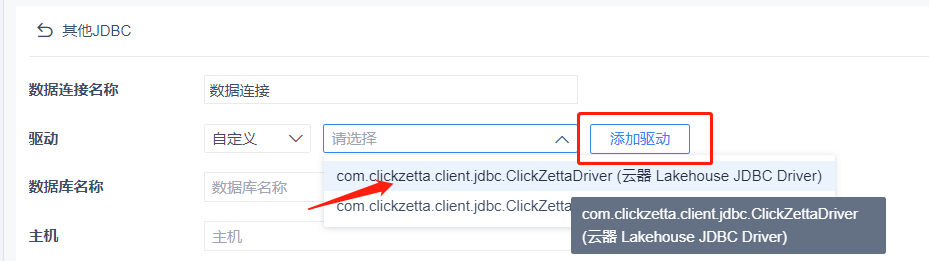
我们仅需要定义一个 [数据库名称],以及填写 [用户名]、[密码]、 [数据连接 URL] 等信息。不清楚 URL 如何填写的用户,可以查看帮助文档的 SDK 章节,或联系你们的客户经理。
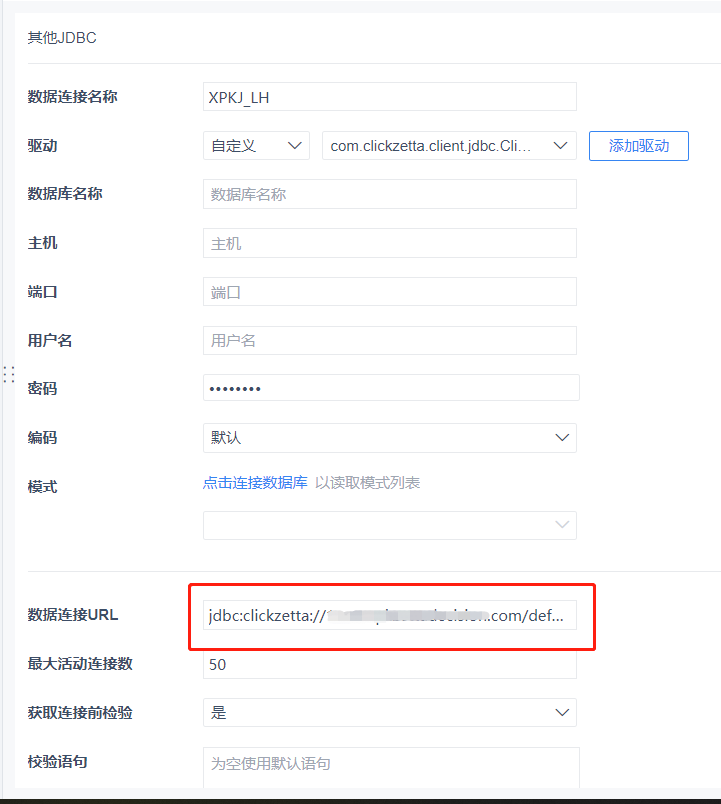
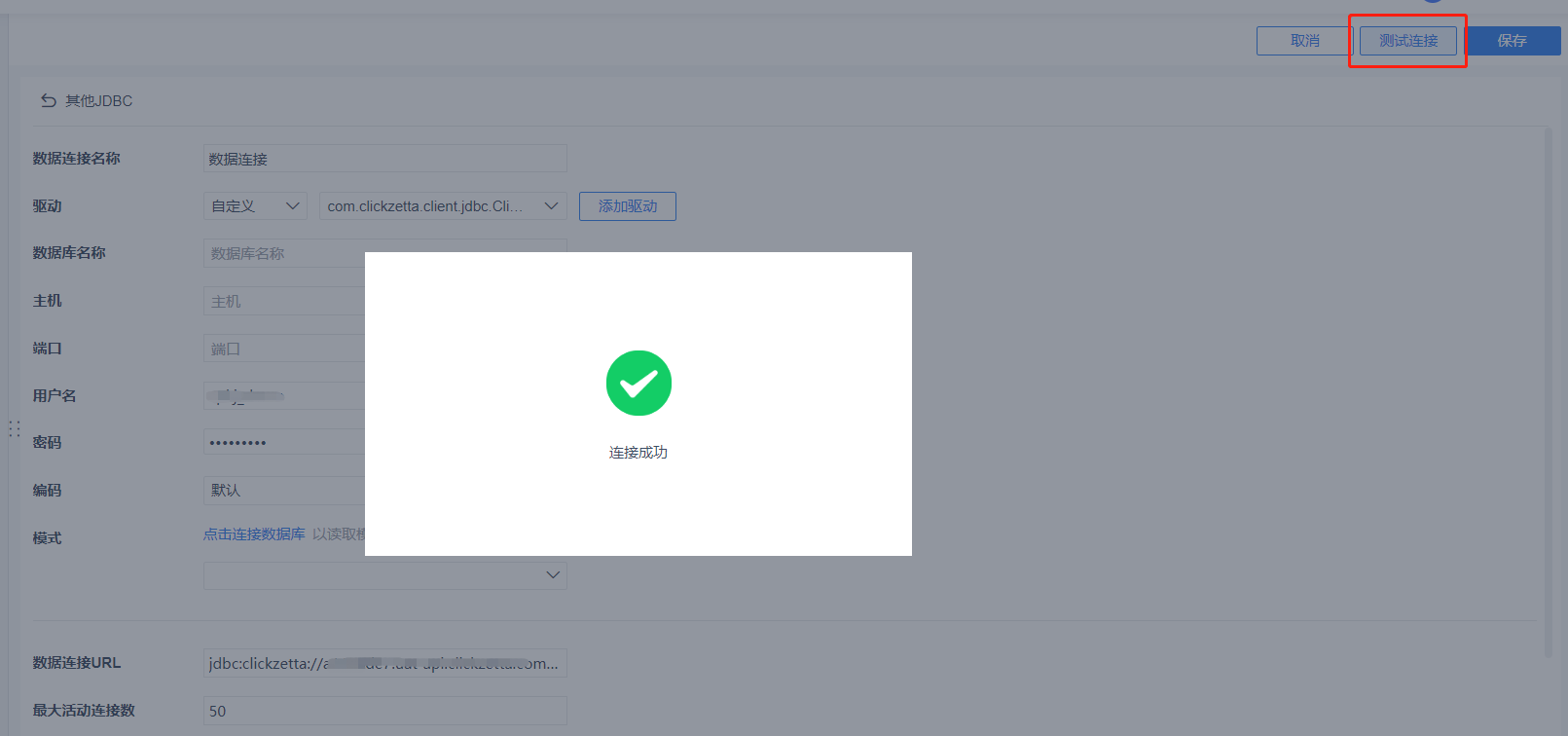
填写后点击 [测试连接],如果配置正确会显示【连接成功】,点击 [保存] 按钮完成创建。
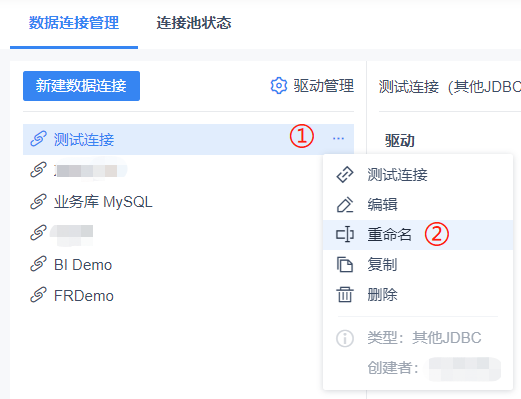
如果连接名称显示受 URL 影响,也可以通过 [重命名] 的方式进行自定义。
数据连接创建成功后,BI 工具就可以像访问其他数据库一样访问 云器 Lakehouse 了。基于数据源创建数据集,添加数据库表,就可以访问 Lakehouse 中的表了。
创建仪表板引用数据集进行编排,感兴趣的同学可以参考帆软 BI 的帮助文档。 https://help.fanruan.com/finebi/
通过一定的看板样式设计,我们可以做出丰富多彩的 BI 看板了。 以下图片是基于 mock 数据的 demo 演示样例