通过窗口函数(Windows)进行数据转换
我们先了解一下在 ETL/ELT(Extract, Transform, Load)过程中使用窗口函数进行数据转换的基本概念和常见使用场景。
基本概念
窗口函数是SQL中专门用于在指定的数据集合(即“窗口”)中执行复杂多行操作的一类函数。窗口函数可以保留行级别详细信息,同时在特定数据窗口内部执行计算。
基本语法:
窗口函数() OVER (PARTITION BY column_name ORDER BY column_name)
常见窗口函数
- RANK():排序函数,为每个分区的每个行分配一个排名。
- DENSE_RANK():类似于 RANK(),但不会跳过排名。
- ROW_NUMBER():为每个分区的行分配唯一编号。
- SUM():累计求和。
- AVG():计算平均。
- LAG():向前获取某行的数据。
- LEAD():向后获取某行的数据。
使用场景
1. 数据去重和标记
窗口函数常用于数据去重,标记重复行。
前提条件:表中需要有唯一标识符(如自增 ID、UUID 或业务主键),用于精确定位要删除的行。
例如,我们可以使用窗口函数为每个分组编号,并删除第一个以外的重复行。
DELETE FROM table_name
WHERE id IN (
SELECT id FROM (
SELECT
id, -- 唯一标识符
ROW_NUMBER() OVER (
PARTITION BY column_field -- 按此字段判断重复
ORDER BY identifier_field -- 决定保留哪一条
) AS rn
FROM table_name
) WHERE rn > 1
);
或者使用MERGE INTO方式,支持更复杂的匹配逻辑
MERGE INTO table_name t
USING (
SELECT id FROM (
SELECT id, ROW_NUMBER() OVER (PARTITION BY column_field ORDER BY identifier_field) AS rn
FROM table_name
) WHERE rn > 1
) s
ON t.id = s.id
WHEN MATCHED THEN DELETE;
注意:窗口函数不能直接在 DELETE 的 WHERE 子句中使用,以下写法会报错:
-- ❌ 错误写法
DELETE FROM table_name
WHERE ROW_NUMBER() OVER (PARTITION BY column_field ORDER BY identifier_field) > 1;
2. 数据分区和聚合
窗口函数可以用于执行分区内的聚合操作,如累计求和和移动平均值。
SELECT
product_id,
order_date,
SUM(order_amount) OVER (PARTITION BY product_id ORDER BY order_date) cumulative_sales
FROM orders;
3. 数据排序和排名
通过窗口函数可以对数据进行排序和排名,并将结果用于后续计算。
SELECT
customer_id,
purchase_amount,
RANK() OVER (PARTITION BY region ORDER BY purchase_amount DESC) purchase_rank
FROM purchases;
4. 数据补全与滞后/前瞻列
利用
LAG()
LAG()
和
LEAD()
LEAD()
函数,可以获取前/后行数据,用于补全缺损数据。
SELECT
customer_id,
order_date,
order_amount,
LAG(order_amount) OVER (PARTITION BY customer_id ORDER BY order_date) previous_order_amount
FROM orders;
使用窗口函数进行 ETL 数据转换,可以有效地提高数据处理的灵活性和效率,使得复杂的数据分析和转换操作变得更加快捷和简洁。
数据模型
TPC-H 数据代表一个汽车零部件销售商的数据仓库,其中记录了订单、构成订单的项目(lineitem)、供应商、客户、销售的零部件(part)、地区、国家和零部件供应商(partsupp)。
云器Lakehouse内置了共享的TPC-H数据,每个用户可以通过加上数据上下文直接使用,比如:
SELECT * FROM
clickzetta_sample_data.tpch_100g.customer
LIMIT 10;
通过云器Lakehouse SQL窗口函数进行数据转换
窗口函数有四个基本部分
- 分区:根据指定列的值定义一组行。如果没有指定分区,则整个表被视为一个分区。
- ORDER BY:这个可选子句指定如何在分区内部对行进行排序。
- 函数:应用于当前行的函数。函数结果在输出中添加一个额外的列。
- 窗口框架:在分区内部,窗口框架允许你指定函数计算中要考虑的行。
SELECT
o_custkey,
o_orderdate,
o_totalprice,
SUM(o_totalprice) -- 函数
OVER (
PARTITION BY
o_custkey -- 分区
ORDER BY
o_orderdate -- Order By;除非指定为 DESC,否则为升序
) AS running_sum
FROM
clickzetta_sample_data.tpch_100g.orders
WHERE
o_custkey = 4
ORDER BY
o_orderdate
LIMIT
10;
函数
SUM
SUM
在上述查询中是一个聚合函数。注意
running_sum
running_sum
如何在所有行上累加(即聚合)
o_totalprice
o_totalprice
。行本身按其订单日期升序排列。
参考:标准聚合函数是
MIN, MAX, AVG, SUM, & COUNT
MIN, MAX, AVG, SUM, & COUNT
,现代数据系统提供了各种强大的聚合函数。请查阅你的数据库文档以了解可用的聚合函数。请
阅读此文 了解 Lakehouse 中可用的聚合函数列表。
使用排名函数获取前/后 n 行
如果你正在处理一个需要获取前/后 n 行(根据某个值定义)的问题,那么使用 行 函数。
让我们看看如何使用行函数的一个例子:
从
orders
orders
表中
获取每天消费最高的前 3 个客户。
orders
orders
表的架构如下所示:
SELECT
*
FROM
(
SELECT
o_orderdate,
o_totalprice,
o_custkey,
RANK() -- 排名函数
OVER (
PARTITION BY
o_orderdate -- 按订单日期分区
ORDER BY
o_totalprice DESC -- 按总价格降序排列分区内的行
) AS rnk
FROM
clickzetta_sample_data.tpch_100g.orders
)
WHERE
rnk <= 3
ORDER BY
o_orderdate
LIMIT
5;
标准排名函数
RANK()
RANK()
:在窗口框架内从 1 到 n 对行进行排名。对具有相同值(由 "ORDER BY" 子句定义)的行进行相同的排名,并跳过如果值不同则会存在的排名数字。DENSE_RANK()
DENSE_RANK()
:在窗口框架内从 1 到 n 对行进行排名。对具有相同值(由 "ORDER BY" 子句定义)的行进行相同的排名,并不跳过任何排名数字。ROW_NUMBER()
ROW_NUMBER()
:在窗口框架内从 1 到 n 添加行号,并不创建任何重复值。
-- 让我们看看一个显示 RANK、DENSE_RANK 和 ROW_NUMBER 之间区别的例子
SELECT
order_date,
order_id,
total_price,
ROW_NUMBER() OVER (PARTITION BY order_date ORDER BY total_price) AS row_number,
RANK() OVER (PARTITION BY order_date ORDER BY total_price) AS rank,
DENSE_RANK() OVER (PARTITION BY order_date ORDER BY total_price) AS dense_rank
FROM (
SELECT
'2024-07-08' AS order_date, 'order_1' AS order_id, 100 AS total_price UNION ALL
SELECT
'2024-07-08', 'order_2', 200 UNION ALL
SELECT
'2024-07-08', 'order_3', 150 UNION ALL
SELECT
'2024-07-08', 'order_4', 90 UNION ALL
SELECT
'2024-07-08', 'order_5', 100 UNION ALL
SELECT
'2024-07-08', 'order_6', 90 UNION ALL
SELECT
'2024-07-08', 'order_7', 100 UNION ALL
SELECT
'2024-07-10', 'order_8', 100 UNION ALL
SELECT
'2024-07-10', 'order_9', 100 UNION ALL
SELECT
'2024-07-10', 'order_10', 100 UNION ALL
SELECT
'2024-07-11', 'order_11', 100
) AS orders
ORDER BY order_date, row_number;
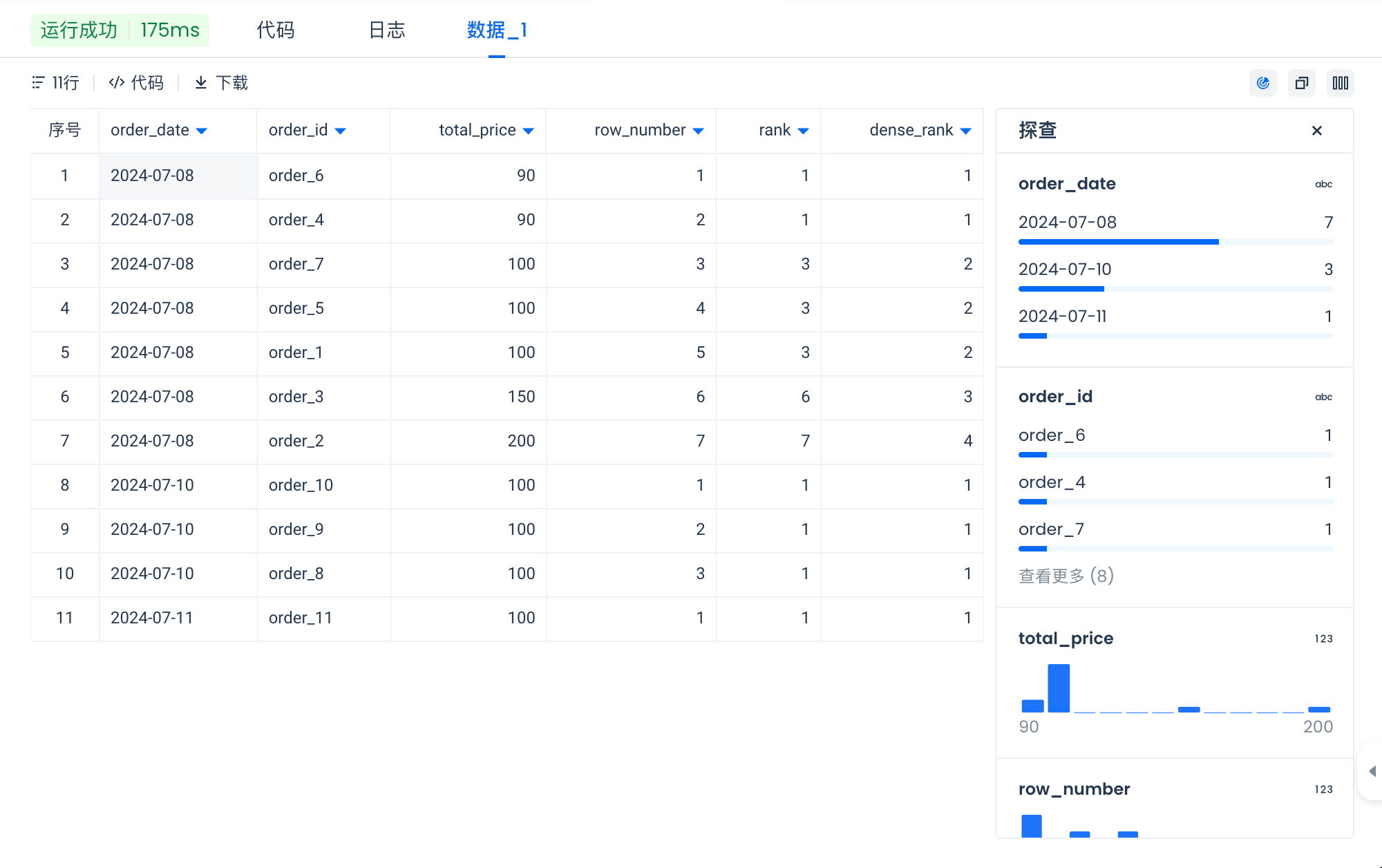
现在我们已经看到了如何使用窗口函数以及如何使用排名和聚合函数。
为什么在有分区的情况下定义窗口框架?
虽然我们的函数在分区中的行上操作,但窗口框架提供了更精细的方式来操作分区中的一组选定行。
当我们需要在一个分区中操作一组行(例如,滑动窗口)时,我们可以使用窗口框架来定义这些行。
考虑一个场景,你有销售数据,你想计算每个商店的 3 天移动平均销售额:
SELECT
store_id,
sale_date,
sales_amount,
AVG(sales_amount) OVER (
PARTITION BY store_id
ORDER BY sale_date
ROWS BETWEEN 2 PRECEDING AND CURRENT ROW
) AS moving_avg_sales
FROM
sales;
在这个示例中:
- PARTITION BY store_id 确保为每个商店分别进行计算。
- ORDER BY sale_date 定义每个分区内部行的顺序。
- ROWS BETWEEN 2 PRECEDING AND CURRENT ROW 指定窗口框架,考虑当前行和前两行来计算移动平均值。
如果没有定义窗口框架,函数可能无法提供你需要的具体移动平均值计算。
使用 ROWS 定义窗口框架
ROWS:用于根据位置选择与当前行相关的行集。
-
行定义格式
ROWS BETWEEN start_point AND end_point
ROWS BETWEEN start_point AND end_point
。
-
start_point 和 end_point 可以是以下三个中的任意一个(按正确顺序):
- n PRECEDING:当前行前 n 行。UNBOUNDED PRECEDING 表示当前行之前的所有行。
- n FOLLOWING:当前行后 n 行。UNBOUNDED FOLLOWING 表示当前行之后的所有行。
让我们看看如何使用相对行号来定义窗口范围。
考虑这个窗口函数:
AVG(total_price) OVER ( -- 函数:运行平均值
PARTITION BY o_custkey -- 按客户分区
ORDER BY order_month
ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING -- 窗口框架定义为 1 行前到 1 行后
)
编写一个SQL查询,从 orders 表中获取以下输出:
-
- o_custkey
- order_month:格式为 YYYY-MM,使用
date_format(o_orderdate, 'yyyy-MM') AS order_month
date_format(o_orderdate, 'yyyy-MM') AS order_month
- total_price:该月的 o_totalprice 总和
- three_mo_total_price_avg:该客户过去、当前和下一个月的 total_price 平均值
SELECT
order_month,
o_custkey,
total_price,
ROUND(
AVG(total_price) OVER ( -- 函数:运行平均值
PARTITION BY
o_custkey -- 按客户分区
ORDER BY
order_month ROWS BETWEEN 1 PRECEDING
AND 1 FOLLOWING -- 窗口框架定义为 1 行前到 1 行后
),
2
) AS three_mo_total_price_avg
FROM
(
SELECT
date_format (o_orderdate, 'yyyy-MM') AS order_month,
o_custkey,
SUM(o_totalprice) AS total_price
FROM
clickzetta_sample_data.tpch_100g.orders
GROUP BY
1,
2
)
LIMIT
5;
使用 RANGE 定义窗口框架
-
RANGE:用于根据
ORDER BY
ORDER BY
子句中指定的列的值选择与当前行相关的行集。
-
范围定义格式
RANGE BETWEEN start_point AND end_point
RANGE BETWEEN start_point AND end_point
。
-
start_point 和 end_point 可以是以下任意一个:
- CURRENT ROW:当前行。
- n PRECEDING:所有值在指定范围内且小于或等于当前行值的 n 个单位之前的行。
- n FOLLOWING:所有值在指定范围内且大于或等于当前行值的 n 个单位之后的行。
- UNBOUNDED PRECEDING:分区中当前行之前的所有行。
- UNBOUNDED FOLLOWING:分区中当前行之后的所有行。
-
RANGE
RANGE
在处理数值或日期/时间范围时特别有用,允许进行如运行总计、移动平均值或累积分布等计算。
让我们看看
RANGE
RANGE
如何与
AVG(total price) OVER (PARTITION BY customer id ORDER BY date RANGE BETWEEN INTERVAL '1' DAY PRECEDING AND '1' DAY FOLLOWING)
AVG(total price) OVER (PARTITION BY customer id ORDER BY date RANGE BETWEEN INTERVAL '1' DAY PRECEDING AND '1' DAY FOLLOWING)
一起工作。
现在我们已经看到了如何使用 ROWS 创建窗口框架,让我们探索如何使用 RANGE 来做这件事。
-
编写一个查询,从 orders 表中获取以下输出:
- order_month,
- o_custkey,
- total_price,
- three_mo_total_price_avg
- consecutive_three_mo_total_price_avg:该客户的连续 3 个月 total_price 平均值。注意,这应该只包括按时间顺序排列的月份。
SELECT
order_month,
o_custkey,
total_price,
ROUND(
AVG(total_price) OVER (
PARTITION BY
o_custkey
ORDER BY
CAST(order_month AS DATE) RANGE BETWEEN INTERVAL '1' MONTH PRECEDING
AND INTERVAL '1' MONTH FOLLOWING
),
2
) AS consecutive_three_mo_total_price_avg,
ROUND(
AVG(total_price) OVER (
PARTITION BY
o_custkey
ORDER BY
order_month ROWS BETWEEN 1 PRECEDING
AND 1 FOLLOWING
),
2
) AS three_mo_total_price_avg
FROM
(
SELECT
date_format (o_orderdate, 'yyyy-MM-01') AS order_month,
o_custkey,
SUM(o_totalprice) AS total_price
FROM
clickzetta_sample_data.tpch_100g.orders
GROUP BY
1,
2
)
ORDER BY
o_custkey,
order_month
LIMIT
50;
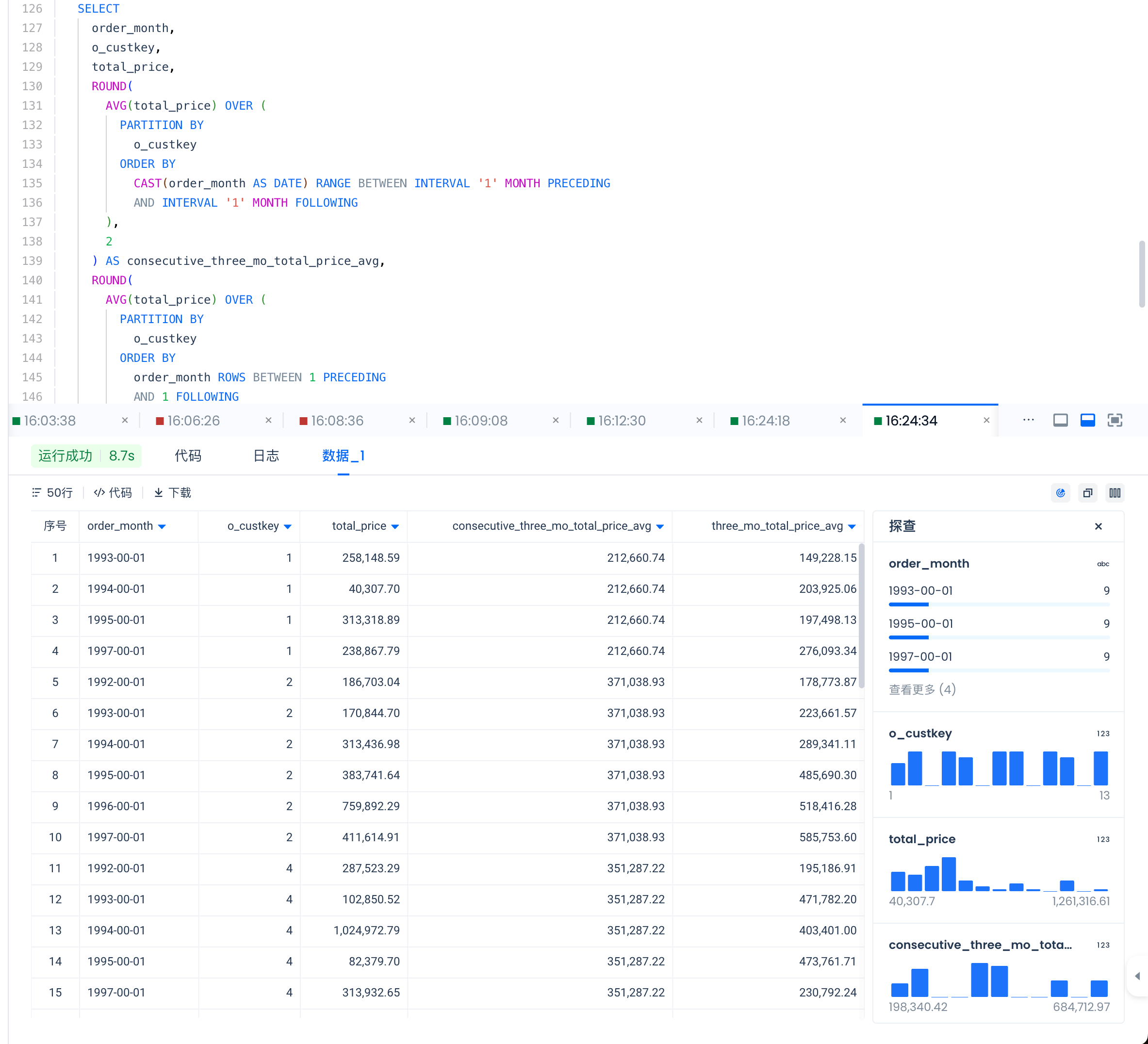
回顾
-
使用窗口函数时:
- 计算运行指标(类似于
GROUP BY
GROUP BY
,但保留所有行)
- 根据特定列对行进行排名
- 从当前行访问其他行的值
-
窗口有四个关键部分:分区、Order By、函数、窗口框架
-
使用 ROWS 或 RANGE 定义窗口框架
-
窗口函数成本较高;注意性能
资料
窗口函数(Window Functions)
窗口函数列表
