
实时数据管道概述
增量计算概述
流式数据处理(Streaming data pipeline)是面向实时数据持续不断地进行数据采集、处理转换,以获得满足业务时效性要求的结果数据的一组任务集合。流式数据处理是分析人员、业务应用开展实时洞察或实时决策的基础。
与周期性离线处理(Batch data pipeline)有所不同,流式数据处理通过编排实时数据采集任务和支持增量数据处理的 SQL 任务,持续产出实时更新的结果数据。处理过程中使用增量处理技术以提高处理效率,同时降低成本。
云器 Lakehouse 流式数据处理过程中,总体处理流程示例如下:
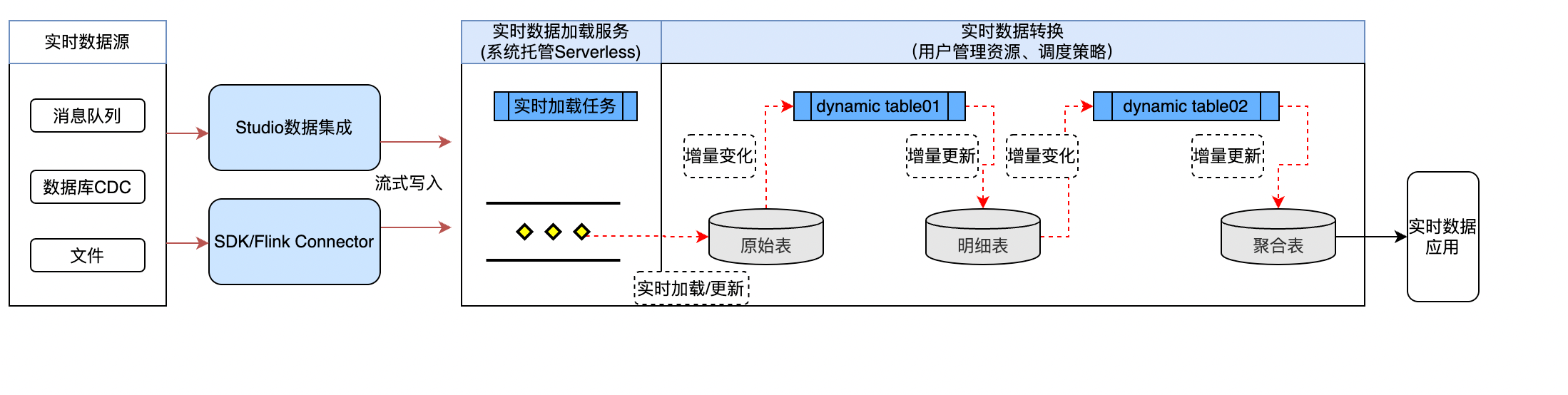
流式数据处理的产品功能特性包括:
| 功能特性 | 特性说明 |
|---|---|
| 实时数据加载 | 实时数据加载服务:通过 SDK/Connector 方式提供 Streaming API,支持实时追加/更新写入、秒级可见的系统托管服务。可使用 SDK 或 Flink Connector 调用接口向目标表写入数据。Studio 数据集成服务:内建的数据集成工具,支持多种实时数据源(如 Kafka、数据库 CDC 等)的实时抽取,写入 Lakehouse 时通过 Streaming API 实时写入目标表。 |
| 增量数据处理 | 动态表:通过动态表声明式定义数据加工逻辑,支持任意 SQL 语法和算子,系统自动读取 Base 表的增量变化,自适应地通过增量/全量算法优化数据处理效率。用户可创建 1 个或多个动态表并设置调度策略,系统自动识别依赖关系并持续调度执行,大大简化实时数据处理的开发过程。注:当前最小支持 1min 的调度间隔。 |
| 变化数据捕获 | Table Stream:Table Stream 是系统内置的 SQL 对象类型,一个 Table Stream 创建在指定的一张表之上,可以记录该表的数据变化(CDC)信息。Table Stream 支持通过 SQL 查询获取指定两个数据版本之间的变化记录数据,例如 5 分钟前至当前这段时间的变化记录。通过 Table Stream,下游的 SQL ETL 可以非常简单易用地读取和处理表变化数据,或者将变化结果同步输出给外部系统。 |
| 连续性调度 | 系统提供两种调度方式: 动态表自身设置调度周期:通过物化视图 DDL 定义时,可通过指定 INTERVAL 关键字设置调度周期。 使用 Studio 调度任务调度:在 Web IDE 中创建 SQL 任务,设置任务调度周期。此种方式同时支持对动态表、使用 Table Stream 的 SQL ETL 作业这两种任务进行调度。注:使用 Studio 调度系统,可获得更好的任务执行观测性和运维告警能力。 |
下一步
根据你的数据源和场景,选择对应的接入和处理方式:
数据接入
| 数据源 | 方案 | 文档 |
|---|---|---|
| 数据库 CDC(MySQL / PG / Oracle 等) | Studio 实时同步任务 | 实时同步任务 |
| 整库迁移 | Studio 多表实时同步 | 多表实时同步 |
| Kafka / AutoMQ 消息流 | Kafka Pipe 或 Studio Kafka 同步 | Pipe 持续导入 |
| OSS / S3 / COS 文件 | Pipe | Pipe 持续导入 |
增量数据处理
- Dynamic Table(动态表) — 声明式定义转换逻辑,系统自动增量刷新
- Table Stream — 捕获表的增量变更,驱动下游 CDC 消费
- Studio 工作流 — 将多个任务编排为 DAG,统一调度和监控
端到端示例
联系我们