VOLUME中的结构化、半结构化数据分析
语法
SELECT { <column_name>,... | * }
FROM [ VOLUME <volume_name> | TABLE VOLUME <table_name> | USER VOLUME ]
[ ( <column_name> <column_type>, <column_name> <column_type> ... ) ]
USING CSV|PARQUET|ORC|JSON|BSON
OPTIONS(
FileFormatParams
)
FILES|SUBDIRECTORY|REGEXP <pattern>;
参数说明
<column_name> <column_type>
<column_name> <column_type>
:可选,lakehouse支持自动识别文件内的表结构信息。推荐不用填写,当指定文件中包含的列名和文件中类型需与文件中预定义的列类型相匹配,
- 自动识别文件schema对于csv文件则会则会自动生成字段,字段编号以 f0 开始,目前自动识别的类型为int、double、string、bool
- 对于 parquet、orc 格式将会根据文件中存储的字段名和类型自动识别。如果指定的文件中列的个数不一致。Lakehouse 会尝试合并,无法合并则会报错
USING CSV
USING CSV
:
USING Parquet | ORC | JSON | BSON
USING Parquet | ORC | JSON | BSON
:
FILES
FILES
:指定文件。例如:
files('part-00002.snappy.parquet','part-00003.snappy.parquet')
files('part-00002.snappy.parquet','part-00003.snappy.parquet')
SUBDIRECTORY
SUBDIRECTORY
:指定子路径。例如:
subdirectory 'month=02'
subdirectory 'month=02'
REGEXP <pattern>
REGEXP <pattern>
:支持使用正则表达式匹配文件。需要注意的是,正则表达式匹配的目标是文件的
完整的对象存储路径(如 's3://cz-udf-user/volume-data/1234321.csv.gz'),而不是以文件在 Volume 对象的相对路径。
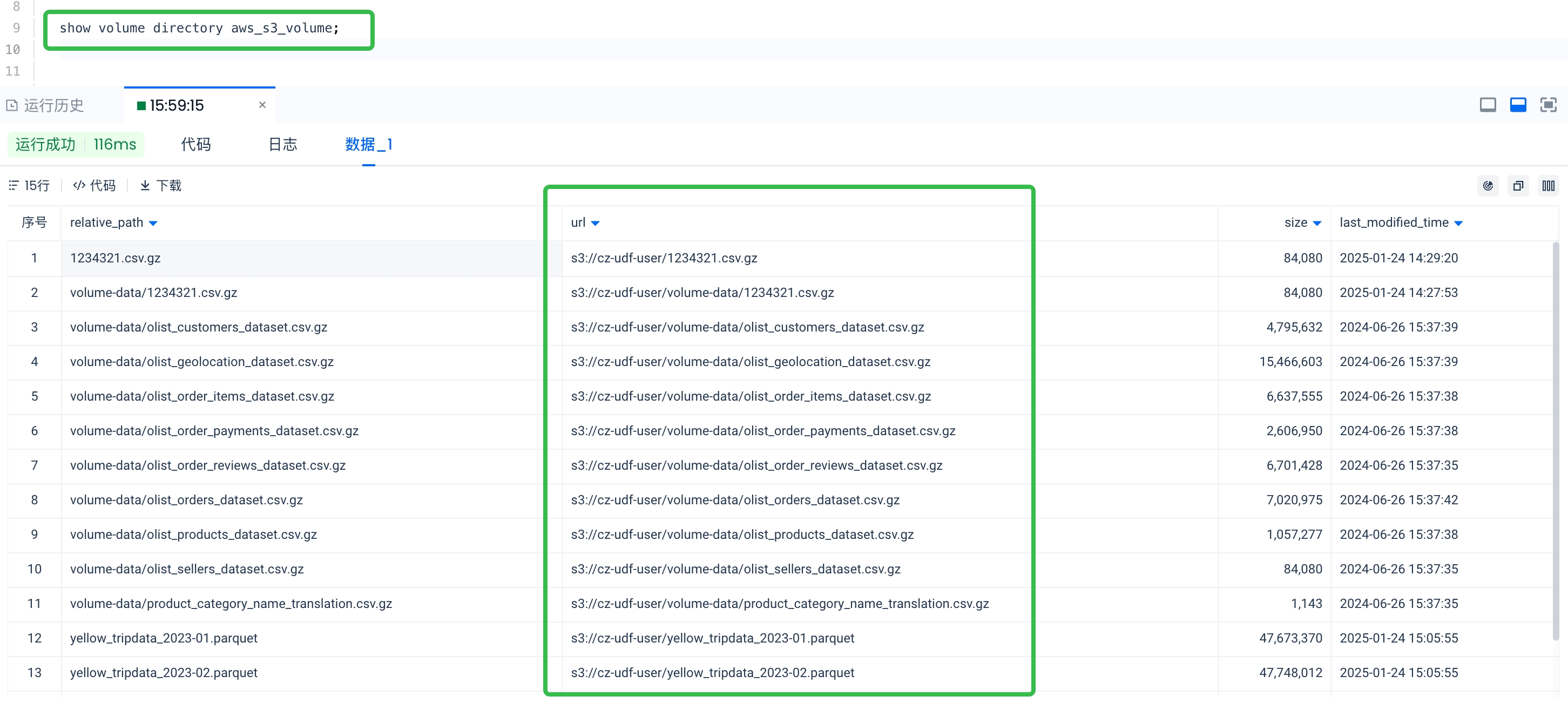
匹配规则:
.
.
- 匹配任意单个字符,不包括换行符*
*
- 匹配前面的元素零次或多次,经常与.
.
配合使用,如 .*
.*
组合表示匹配任意字符任意次数+
+
- 匹配前面的元素一次或多次,经常与.
.
配合使用,如 .+
.+
表示匹配任意字符一次或多次?
?
- 匹配前面的元素零次或一次[abc]
[abc]
: 匹配 a、b 或 c 中的任意一个字符[abc]
[abc]
: 匹配除了 a、b、c 之外的任意字符[a-z]
[a-z]
: 匹配小写字母 a 到 z[A-Z]
[A-Z]
: 匹配大写字母 A 到 Z[0-9]
[0-9]
: 匹配数字 0 到 9
例如:
REGEXP '.*.parquet'
REGEXP '.*.parquet'
匹配以 parquet
parquet
后缀的文件REGEXP '.*yellow_tripdata_202[0-4]-0[23].parquet'
REGEXP '.*yellow_tripdata_202[0-4]-0[23].parquet'
匹配包含 yellow_tripdata_
yellow_tripdata_
,年份为 2020
2020
到 2024
2024
,月份为 02
02
或 03
03
,并且以 .parquet
.parquet
结尾的文件名
示例:
查询 CSV 格式文件:
数据准备:
创建 volume 对象:
hz_csv_volume
hz_csv_volume
,绑定阿里云 OSS 路径:
oss://hz-datalake/csv_files/
oss://hz-datalake/csv_files/
,该路径下的文件结构为巴西电商数据集的 CSV 文件:
-------------oss://hz-datalake/csv_files/ 的对象存储目录结构 ------------------
-- brazil-ecommerce/olist_customers_dataset.csv
-- brazil-ecommerce/olist_geolocation_dataset.csv
-- brazil-ecommerce/olist_order_items_dataset.csv
-- brazil-ecommerce/olist_order_payments_dataset.csv
-- brazil-ecommerce/olist_order_reviews_dataset.csv
-- brazil-ecommerce/olist_orders_dataset.csv
-- brazil-ecommerce/olist_products_dataset.csv
-- brazil-ecommerce/olist_sellers_dataset.csv
-- brazil-ecommerce/product_category_name_translation.csv
查询示例:
-- 查询文件:olist_customers_dataset.csv
SELECT * FROM VOLUME hz_csv_volume
USING CSV
OPTIONS(
'header'='true',
'sep'=','
)
FILES('brazil-ecommerce/olist_customers_dataset.csv');
-- 查询文件 olist_geolocation_dataset.csv
SELECT * FROM VOLUME hz_csv_volume USING csv
OPTIONS(
'header'='true',
'sep'=','
)
FILES('brazil-ecommerce/olist_geolocation_dataset.csv');
如果文件的字段中包含向量字段,因为它的特殊格式,建议使用参数
'multiLine'='true'
'multiLine'='true'
,否则可能会遇到报错。
SELECT * FROM USER volume
USING csv
OPTIONS(
'header'='true',
'sep'=',',
'multiLine'='true'
)
FILES('cz_knowledge.csv');
数据导入到 Lakehouse 中:
你可以通过 create table as select 方式将数据导入到云器 Lakehouse 内表:
CREATE TABLE olist_customers_dataset as
SELECT * FROM VOLUME hz_csv_volume
USING CSV
OPTIONS(
'header'='true',
'sep'=','
)
FILES('brazil-ecommerce/olist_customers_dataset.csv');
查询 Parquet 格式文件:
数据准备:
创建 volume 对象:
hz_parquet_volume
hz_parquet_volume
,绑定阿里云 OSS 路径:
oss://hz-datalake/yellowtrip-partitioned/
oss://hz-datalake/yellowtrip-partitioned/
,该路径下的文件结构为纽约出租车数据集以及其它的一些零散的 parquet 格式文件,目的是展示如何利用
FILES | SUBDIRECTORY | REGEXP
FILES | SUBDIRECTORY | REGEXP
这几种文件匹配的选项查询目标数据文件。文件的组织形式为:
--------- oss://hz-datalake/yellowtrip-partitioned/ 的对象存储目录结构 ----
-- month=01/yellow_tripdata_2023-01.parquet
-- month=02/yellow_tripdata_2023-02.parquet
-- month=03/yellow_tripdata_2023-03.parquet
-- month=04/yellow_tripdata_2023-04.parquet
-- month=05/yellow_tripdata_2023-05.parquet
-- part-00000-d87581e8-afdb-49ba-abd4-d8f9f5a37a6e-c000.snappy.parquet
-- part-00002-d87581e8-afdb-49ba-abd4-d8f9f5a37a6e-c000.snappy.parquet
-- part-00005-d87581e8-afdb-49ba-abd4-d8f9f5a37a6e-c000.snappy.parquet
-- part-00007-d87581e8-afdb-49ba-abd4-d8f9f5a37a6e-c000.snappy.parquet
查询示例:
查询1:查询 month 分区1-5的 parquet 文件
SELECT * FROM VOLUME hz_parquet_volume
USING parquet
REGEXP '.*month=0[1-5].*.parquet' ;
查询2:查询以 part- 开头的 parquet 后缀的文件,其中包含复杂类型:
SELECT * FROM VOLUME hz_parquet_volume
USING parquet
REGEXP '.*part-.*.parquet';
查询3:用files 参数包含具体文件,复杂类型查询:
SELECT id, array_col[0], map_col['Key2'], struct_col.field2 FROM volume hz_parquet_volume(
id INT,
string_col STRING,
int_col INT,
float_col FLOAT,
boolean_col BOOLEAN,
date_col STRING,
timestamp_col STRING,
array_col ARRAY<STRING>,
struct_col STRUCT<field1: STRING, field2: INT>,
map_col MAP<STRING, INT>
) USING parquet files(
'part-00002-d87581e8-afdb-49ba-abd4-d8f9f5a37a6e-c000.snappy.parquet',
'part-00005-d87581e8-afdb-49ba-abd4-d8f9f5a37a6e-c000.snappy.parquet'
);
查询 ORC 格式文件:
数据准备:
创建 volume 对象:
hz_orc_volume
hz_orc_volume
,绑定阿里云 OSS 路径:
oss://hz-datalake/orcfiles/
oss://hz-datalake/orcfiles/
,该路径下的文件结构为:
--------- oss://hz-datalake/orcfiles/ 的对象存储目录结构 ----------
-- t_search_log/dt=20230401/hours=06/part-00000-7342ed8826c5.c000
-- t_search_log/dt=20230401/hours=07/part-00002-7342ed8826c5.c000
查询示例:
SELECT * FROM volume hz_orc_volume (
dpt_city_code STRING,
dpt_city_name STRING,
month_year STRING
) USING orc subdirectory 't_search_log/dt=20230401/hours=06/'
limit 10;
查询 JSON 格式文件:
SELECT * FROM USER VOLUME
USING JSON
FILES('lake_demo/products_json/part00001.json')
LIMIT 5;
查询 BSON 格式文件:
--Query bson files
SELECT * FROM VOLUME my_external_vol
(name string, age bigint, city string, interests array<string>)
using bson
FILES( 'data.bson');
