
场景案例1:基于静态分区的ETL任务增量改造(无维度表或维度表不变)
业务背景
针对传统按天调度的全量批处理任务(T+1模式),通过动态分区表技术实现增量处理优化。改造后可达成:
- 数据时效提升:支持小时级/分钟级调度间隔
- 资源利用率优化:减少冗余计算约60%-80%
- 运维效率提升:支持分区级数据修复与回溯
场景特征
适用对象需满足:
- 业务时间对齐自然日:如订单交易、日志采集等典型日切场景
- 固定调度时段:建议在数据就绪时段(如00:30-01:00)集中处理
- 分区字段标准化:源表需包含标准日期分区字段(如event_day/pt/ds等)
改造方案:使用分区动态表
1. 创建分区动态表
在创建分区动态表时,通过定义参数 SESSION_CONFIGS()['dt.args.event_day'] 来指定源表要扫描的分区或者分区范围。此参数在 SQL 加工逻辑中使用,通过 SESSION_CONFIGS()['dt.arg.xx'] 进行定义,表示查询源表的分区字段。
- 参数格式:
SESSION_CONFIGS()['dt.args.xx'],其中xx是自定义的参数名称,必须以dt.args.开头,以避免与系统内部字段冲突。 - 等价表达:与传统调度中的
SELECT * FROM source_table WHERE pt = ${bizdate}等价。例如,SESSION_CONFIGS()['dt.args.pt']等价于pt = ${bizdate}。
2. 动态表刷新
在刷新动态表时,使用以下命令指定分区值:
- 对应传统操作:等同于传统的
INSERT OVERWRITE target_table PARTITION (pt = ${bizdate})。
改造实施步骤
将离线任务转换为增量任务
本节将指导用户如何将原有的离线任务转换为增量任务,以实现更高效的数据处理。以下是一个基于“传统数据库”的具体操作步骤,适用于业务逻辑按天对齐和按天调度刷新的场景。
步骤1:任务改造
原始SQL
首先,需要将原始SQL中的所有由调度引擎传入的参数${bizdate}替换为SESSION_CONFIGS()['dt.args.bizdate']。
-
找到连续的两个调度任务,如上文所示 20250101 调度 和 20250102 调度
-
找到其中变化的部分 如 上文两处标记为黄色的部分
-
将其替换为 SESSION_CONFIG()['dt.args.xx']
- 值得重点注意的是,SESSION_CONFIG()['dt.args.xx'] 返回的结果是string,如果变量是int需要用SQL进行类型转换,例如 CAST(SESSION_CONFIG()['dt.args.xx'] AS BIGINT)
- 并且设置上刷新的语句
-
步骤2:调度刷新命令
增量任务数据补数和运维
在某些情况下,用户可能需要向已有的分区中补充数据。
方法1:向源表补充数据
用户可以直接向源表中补充数据。这些补充的数据将通过相应的REFRESH任务自动反映到Dynamic Table(DT)中。
操作步骤:
- 直接向源表插入或更新数据。
- 执行REFRESH任务,以将更改同步到DT中。
方法2:使用DML语句直接向DT补充数据
用户可直接运用DML语句向DT的指定分区插入数据。但需注意,若上游数据未发生变动,下一次刷新操作将执行全量刷新,此时数据会恢复至未修改前的状态。
操作步骤:
- 使用DML语句向DT的特定分区插入数据。
- 请注意,直接修改DT将导致下一次该分区的全量刷新。如果用户不希望出现全量刷新的结果,应避免调度该分区的REFRESH任务。
示例代码:
注意事项:
- 直接向DT插入的数据将参与DT的下游计算。如果下游的老分区不需要这些数据,请不要调度涉及这些数据的分区的REFRESH任务。
- 其他未受影响的分区仍然可以进行增量刷新。
场景案例2:基于动态分区的ETL任务优化方案(无维度表或维度表不变)
场景特征
- 动态数据特征:源数据存在历史分区更新可能性
- 时间窗口要求:业务需要持续处理N天内可能变更的数据
- 维度表情况:维度表不变、无需保留历史维度,或不存在维度表。
将离线任务转换为增量任务
- 如果用户原本就是一个依赖调度系统填参数的静态分区调度的作业,不建议改写为动态分区
- 如果用户希望 老分区的数据在某个阶段后便不再改变 了,也不建议改写为动态分区
- 动态分区改写时,主要遵循的原则是:一切计算都由数据驱动。即每一条数据都应该按照定义好的计算逻辑,和其他数据发生交互,并且写入对应的目标分区中。
- 过滤条件中需要根据实际业务需求加个窗口过滤,比如1周/1个月/3个月/一年,防止DT数据持续增加,时间长了之后可能会影响性能。
接下来我们来尝试把上述的静态分区的SQL改写为动态分区
增量任务数据补数和运维
-
需要先对源表数据进行补数,如果表是来自于外部数据需要使用数据集成工具重新同步,
-
历史数据补数:
-
影响:补进来的数据会作为增量数据进行加工,这一批次加工会变慢,影响最新数据加工的新鲜度。
-
建议:
- 建议提前扩大计算资源保证加工性能,补数进行分批操作,减少一次计算的量;
- 另外就是可以补数完,触发一次全量加工
-
-
维度表修改:
-
影响:维度表修改会直接影响增量计算,如果修改的内容影响加工的范围过大,可能会影响加工性能
-
建议:
- 如果影响范围小,直接修改即可,增量计算自动识别加工
- 如果影响范围大,可修改完进行一次全量加工
- 如果影响代码逻辑(比如增加列,要加计算逻辑),则需要修改dt逻辑,重新全量计算
-
场景案例3:按天分区任务(需要保留历史维度)
业务背景
针对维度表持续变化的按天分区ETL场景,通过构建维度表实时同步体系与动态加工链路,实现事实表与维度表的增量协同计算。改造后可达成:
- 维度数据时效性提升:维度变更延迟从T+1缩短至分钟级
- 跨表数据一致性保障:建立维度-事实表的版本对齐机制
- 资源消耗降低:避免维度表全量同步带来的冗余计算
场景特征
适用对象需满足:
- 混合数据处理模式:维度表需支持实时更新+历史版本保留
- 版本对齐要求:事实表处理需绑定对应时间点的维度快照
将离线任务转换为增量任务
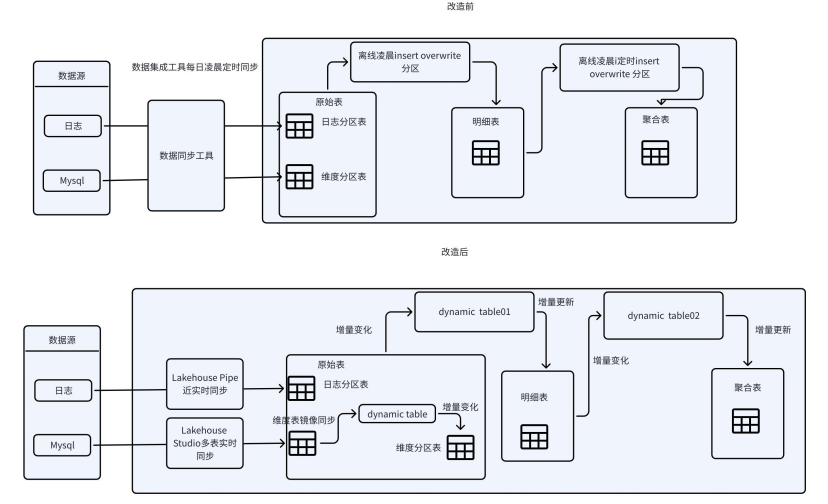
改造实施步骤
一、维度表实时化改造
1. 多源同步架构
- 实时同步层:如果数据来源是外部系统(如MySQL),通过StudioCDC捕获工具实现源库多表实时同步。实时同步要求和源端字段必须保持一致,因此如果维度表含有分区,需要新建一张维度表存储每日维度分区快照。
二、加工任务增量改造
- 版本绑定:事实表的事件时间自动关联对应日的维度分区。
加工任务增量改造示例如下,假设t1是日维度分区表,t2是事实表:
增量任务数据补数和运维
-
历史数据补数:通过补数功能按天修改输入表数据,之后按天刷新Dynamic Table即可。增量计算分区表可以按天刷新,不影响当天最新数据的计算。
-
修改维度表:
- 如果影响范围小,直接修改即可,增量计算自动识别加工
- 如果影响范围大,可修改完进行一次全量加工
- 如果影响代码逻辑(比如增加列,要加计算逻辑),则需要修改dt逻辑,重新全量计算
特殊场景下的增量计算效果说明
在以下场景中,增量计算仍然可以正常执行,但性能优化效果可能有限。在最坏情况下,计算性能可能与全量计算相当。建议在这些场景下进行实际测试,评估增量计算的收益后再决定是否采用。
- Outer Join 右表频繁变更:数据查询中包含大量的 Outer Join,且参与 Outer Join 的右表数据处于频繁变更状态,每次变化数据量大于5%。
- 大量排序操作:查询操作里存在大量数据排序需求,例如使用了 Order by 子句。
- Window 函数排序与大分区:Window 函数需要对数据进行排序(RowNumber=1 的情况除外),并且增量数据中包含多个数据量特别大的 Partition。
- 数据聚集性较差:数据缺乏良好的聚集性,无法通过 Join key、Aggregate key、Window partition key 等清晰地将冷数据和热数据区分开来。