基于云器Lakehouse构建面向分析的Modern Data Stack
本文介绍如何基于云器Lakehouse、Metabase和MindsDB构建面向分析的Modern Data Stack。
方案架构
基于云器Lakehouse的Modern Data Stack方案特点:
- 实现从AWS数据仓库到数据湖的演进,通过云器Lakehouse实现湖仓一体的优化提升,大幅降低数据存储、计算和运维成本。
- 无限存储与高效迁移:全链路数据通道采用云对象存储实现存算分离架构,避免了传统方案中服务器节点的带宽和存储容量瓶颈。
- 云器Lakehouse + Metabase:实现极简的BI数据分析,仅需点击两次鼠标即可完成可视化数据探索和分析,极大降低业务人员分析数据的门槛,对业务人员十分友好。
- 云器Lakehouse + MindsDB:实现100%基于SQL的AI与LLM增强分析。无需掌握其他复杂语言,数据工程师和BI分析人员基于SQL就可以实现AI和LLM的增强分析。
- 降低数据全栈(云基础设施、数据湖、数据仓库、BI、AI)对技术人员的要求,降低企业用人门槛,提升人才可得性。
本方案主打简单易用,旨在帮助企业将工作重点从数据基建转向数据分析,实现数据分析的现代化。

上图展示了迁移至并基于云器Lakehouse构建Modern Data Stack的架构,概述如下:
- 使用Redshift UNLOAD命令将数据卸载到S3存储桶中的Parquet文件。
- 通过云器Lakehouse的
SELECT * FROM VOLUME 语句,将AWS S3存储桶中Parquet文件的数据直接加载到云器Lakehouse的表中,实现快速数据入仓(本例中加载2000多万行的一张表,完成数据入仓仅需30秒)。
- BI应用:通过Metabase探索和分析数据(从表格到仪表盘仅需点击两次鼠标——没错,就是两次)。
- AI应用:通过MindsDB对房价进行预测(100%用SQL实现模型预测)。
方案组成
-
AWS:
-
云器
- 云器Lakehouse,多云及一体化数据平台。采用SaaS全托管服务模式,为企业提供极简数据架构。
- 云器Lakehouse Driver for Metabase
- 云器Lakehouse Connector for MindsDB
-
数据分析
- Metabase with Lakehouse Driver on Docker:Metabase是一个完整的BI平台,但在设计理念上与Superset大不相同。Metabase非常注重业务人员(如产品经理、市场运营人员)的使用体验,让他们能自由地探索数据,回答自己的问题。
- MindsDB with Lakehouse Connector on Docker:MindsDB可直接在云器Lakehouse中进行建模,省去了数据处理、模型搭建等专业步骤。数据分析人员、BI分析师无需熟悉数据工程、建模知识,即可开箱使用,降低了建模门槛,让人人都是数据分析师,人人都会应用算法。
- Zeppelin with Lakehouse JDBC Interpreter on Docker
- Zeppelin with MySQL JDBC Interpreter on Docker(连接MindsDB的MySQL接口)
为什么要使用云器Lakehouse?
- 完全托管: 云器Lakehouse提供完全托管、基于云的Lakehouse服务,易于使用和扩展。这意味着您不必担心管理和维护自身的硬件与基础设施,避免了耗时且昂贵的投入,实现安心托付。
- 节省成本:与Redshift相比,云器Lakehouse的总拥有成本(TCO)通常较低,因为它根据使用情况收费,而不需要预先承诺。云器Lakehouse高度灵活的定价模型使您只需为实际使用的资源付费,而无需被锁定在固定成本模型中。
- 可扩展性: 云器Lakehouse 旨在处理大量数据,并且可以根据需要扩展或缩小,这对计算负载波动明显的企业来说是一个不错的选择。云器Lakehouse数据存储在云上的对象存储服务中,在数据规模上实现“无限扩展”。
- 性能: 云器Lakehouse采用Single Engine All Data架构,实现计算与存储分离,使其能够比Redshift更快地处理查询。
- 易于使用: 云器Lakehouse提供了一体化的数据集成、开发、运维和治理平台,这使得开发和管理变得更加容易,无需复杂的方案集成。
- 数据源支持: 云器Lakehouse支持多种数据源和格式,包括结构化和半结构化数据,大多数情况下仅用SQL就可完成BI和AI应用的开发。
- 数据集成: 云器Lakehouse内置的数据集成功能支持广泛的数据源,使数据加载和准备变得更加容易,从而便于进行分析。
总体而言,迁移到云器Lakehouse可以帮助您节省时间和金钱,并使您能够更轻松、更有效地处理和分析数据。
实施步骤
数据抽取(E)
将房价销售数据从Redshift卸载到S3
Redshift UNLOAD 命令:使用 Amazon S3 服务器端加密 (SSE-S3) 将查询结果卸载到 Amazon S3 上的一个或多个文本、JSON 或 Apache Parquet 文件。
UNLOAD ('select-statement')
TO 's3://object-path/name-prefix'
authorization
[ option, ...]
where authorization is
IAM_ROLE { default | 'arn:aws:iam::<AWS account-id-1>:role/<role-name>[,arn:aws:iam::<AWS account-id-2>:role/<role-name>][,...]' }
where option is
| [ FORMAT [ AS ] ] CSV | PARQUET | JSON
| PARTITION BY ( column_name [, ... ] ) [ INCLUDE ]
| MANIFEST [ VERBOSE ]
| HEADER
| DELIMITER [ AS ] 'delimiter-char'
| FIXEDWIDTH [ AS ] 'fixedwidth-spec'
| ENCRYPTED [ AUTO ]
| BZIP2
| GZIP
| ZSTD
| ADDQUOTES
| NULL [ AS ] 'null-string'
| ESCAPE
| ALLOWOVERWRITE
| CLEANPATH
| PARALLEL [ { ON | TRUE } | { OFF | FALSE } ]
| MAXFILESIZE [AS] max-size [ MB | GB ]
| ROWGROUPSIZE [AS] size [ MB | GB ]
| REGION [AS] 'aws-region' }
| EXTENSION 'extension-name'
数据湖数据探索:通过云器Lakehouse探索AWS S3上的Parquet数据
查看总共有多少行数据(需要提前创建好云器Lakehouse的 STORAGE CONNECTION 和 EXTERNAL VOLUME):
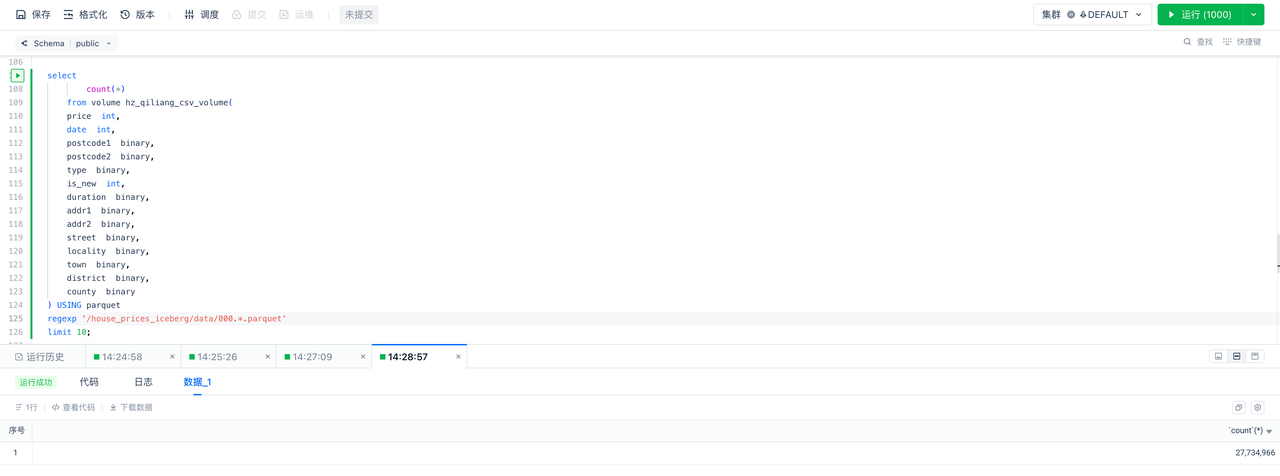
预览数据
select
*
from volume hz_qiliang_csv_volume(
price int,
date int,
postcode1 binary,
postcode2 binary,
type binary,
is_new int,
duration binary,
addr1 binary,
addr2 binary,
street binary,
locality binary,
town binary,
district binary,
county binary
) USING parquet
regexp '/house_prices_iceberg/data/000.*.parquet'
limit 10;
在云器Lakehouse执行上述查询,结果如下:
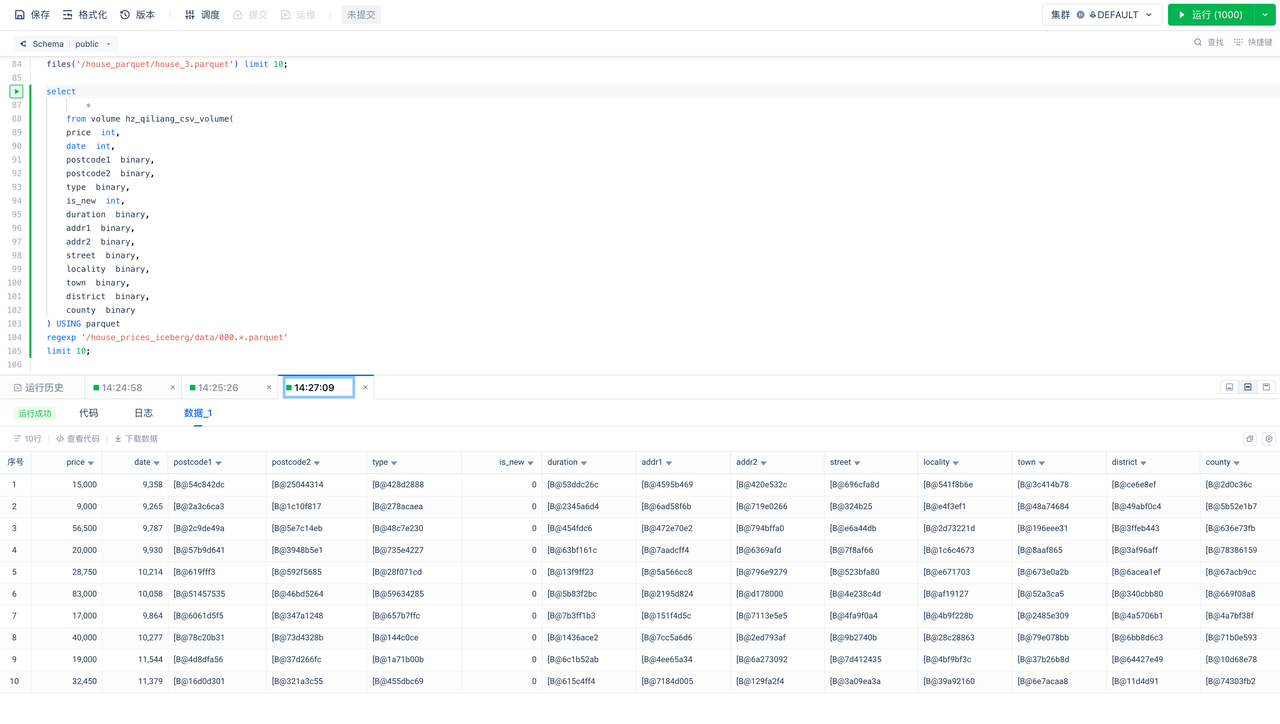
数据入仓:将数据从S3加载(L)到云器Lakehouse并进行数据转换(T)
use schema public_datasets;
create table if not exists house_prices_paid_from_oss_parquet as
select price,
cast(date*24*3600 as timestamp) as date,
cast(postcode1 as string) as postcode1,
cast(postcode2 as string) as postcode2,
cast(type as string) as type,
is_new,
cast(duration as string) as duration,
cast(addr1 as string) as addr1,
cast(addr2 as string) as addr2,
cast(street as string) as street,
cast(locality as string) as locality,
cast(town as string) as town,
cast(district as string) as district,
cast(county as string) as county
from volume public.hz_qiliang_csv_volume(
price int,
date int,
postcode1 binary,
postcode2 binary,
type binary,
is_new int,
duration binary,
addr1 binary,
addr2 binary,
street binary,
locality binary,
town binary,
district binary,
county binary
) USING parquet
regexp '/house_prices_iceberg/data/000.*.parquet'
order by date,county,price;
验证入仓的数据行数:
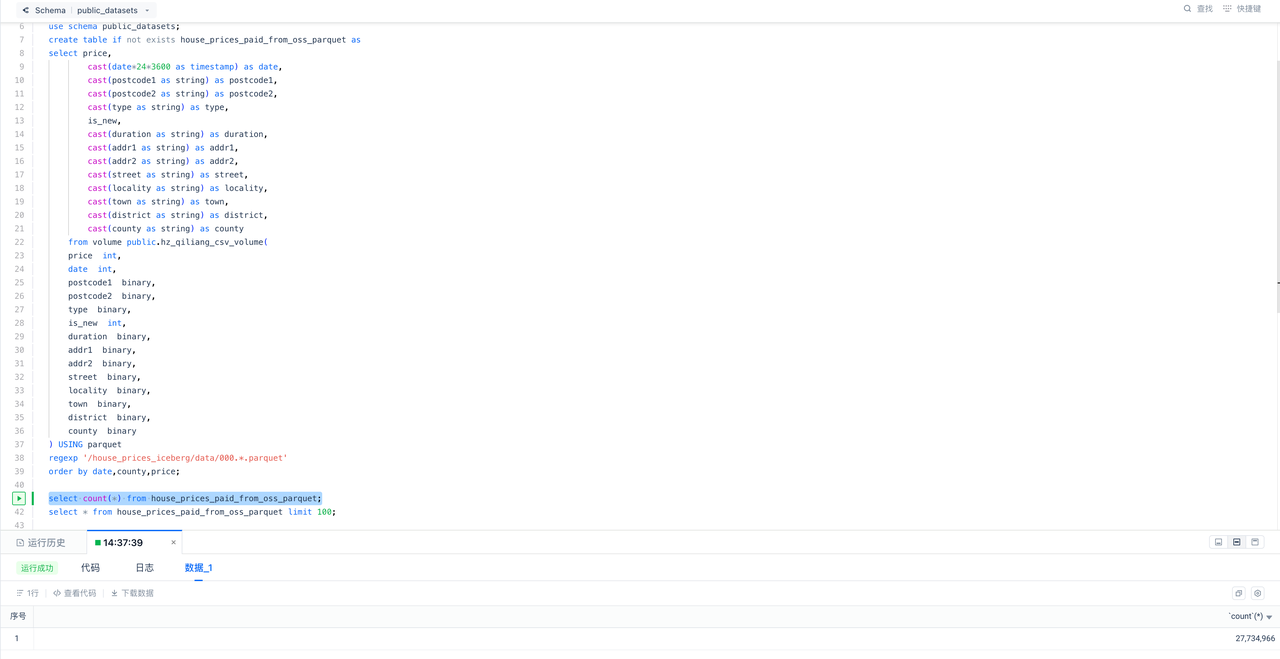
对仓内数据用SQL进行探查:
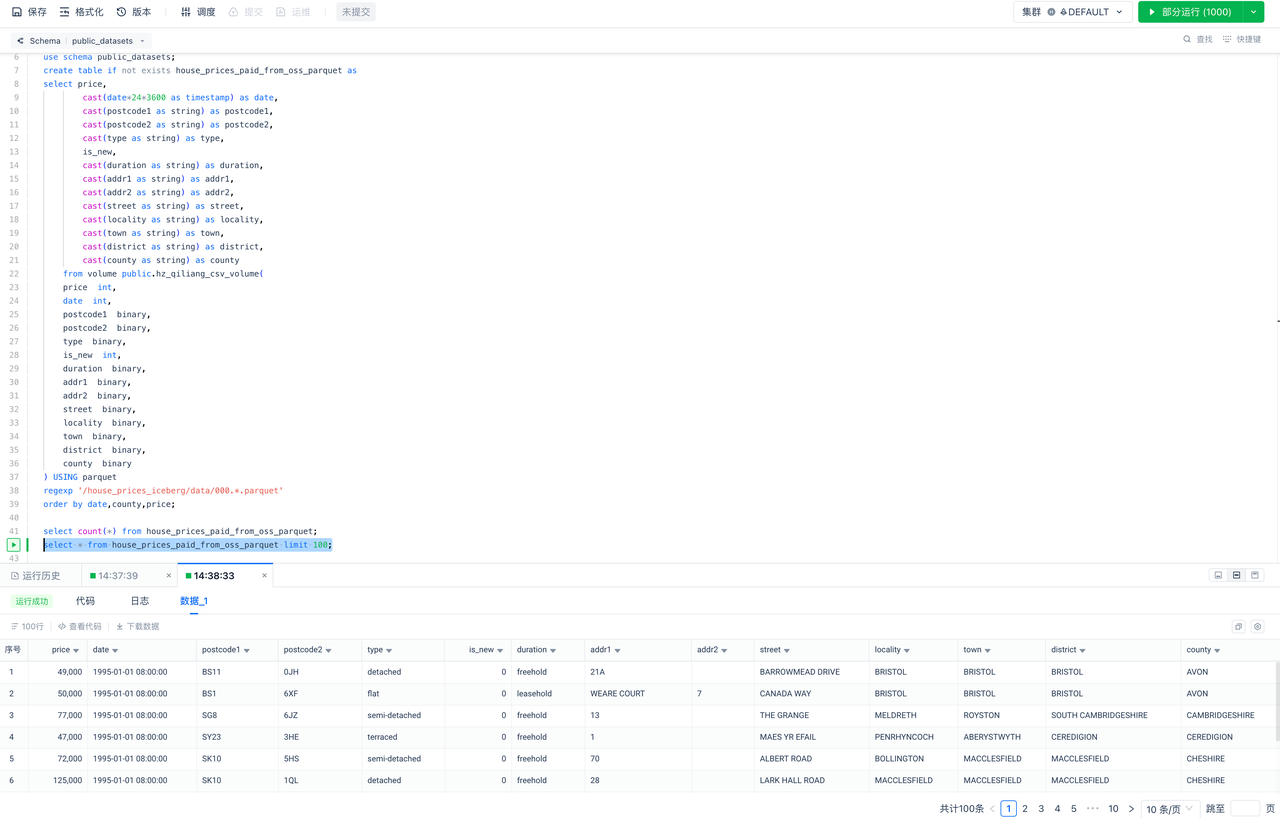
选择数据库与表:
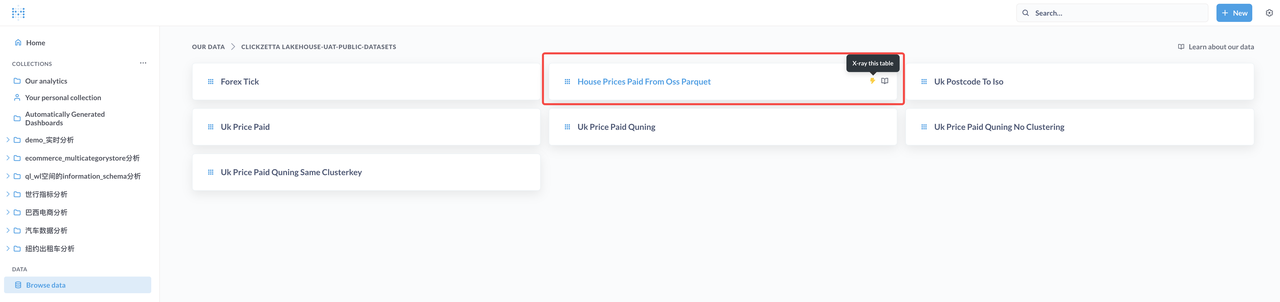
通过Metabase浏览和分析数据
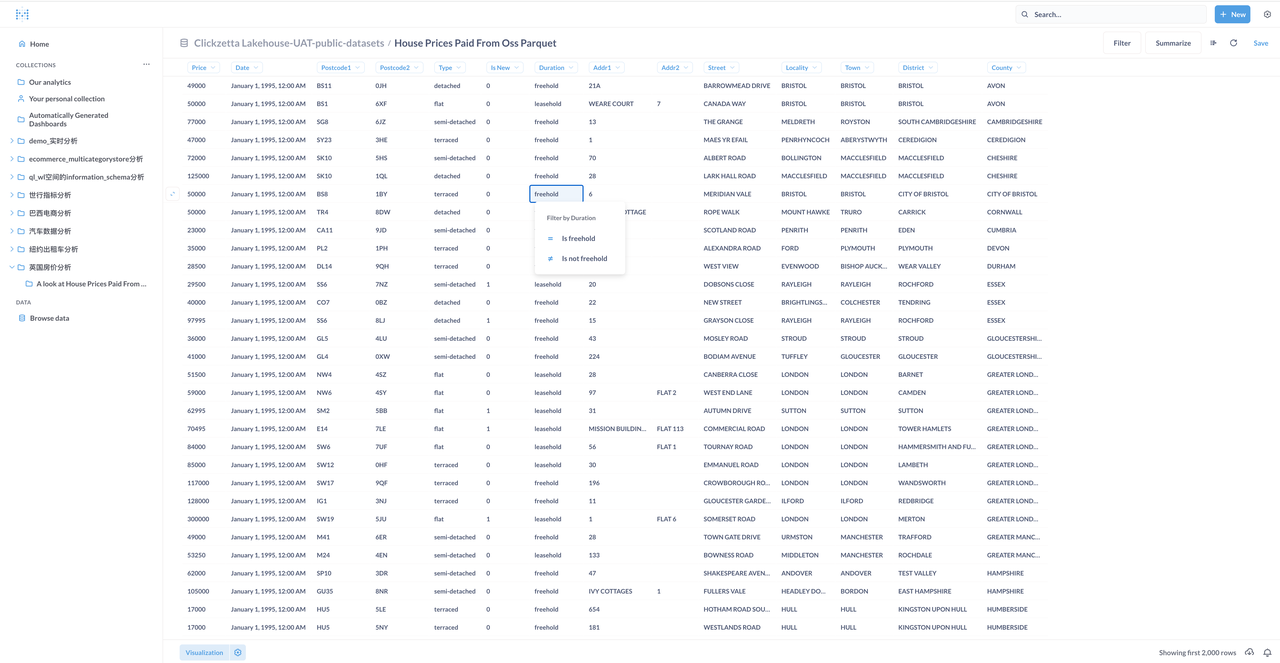
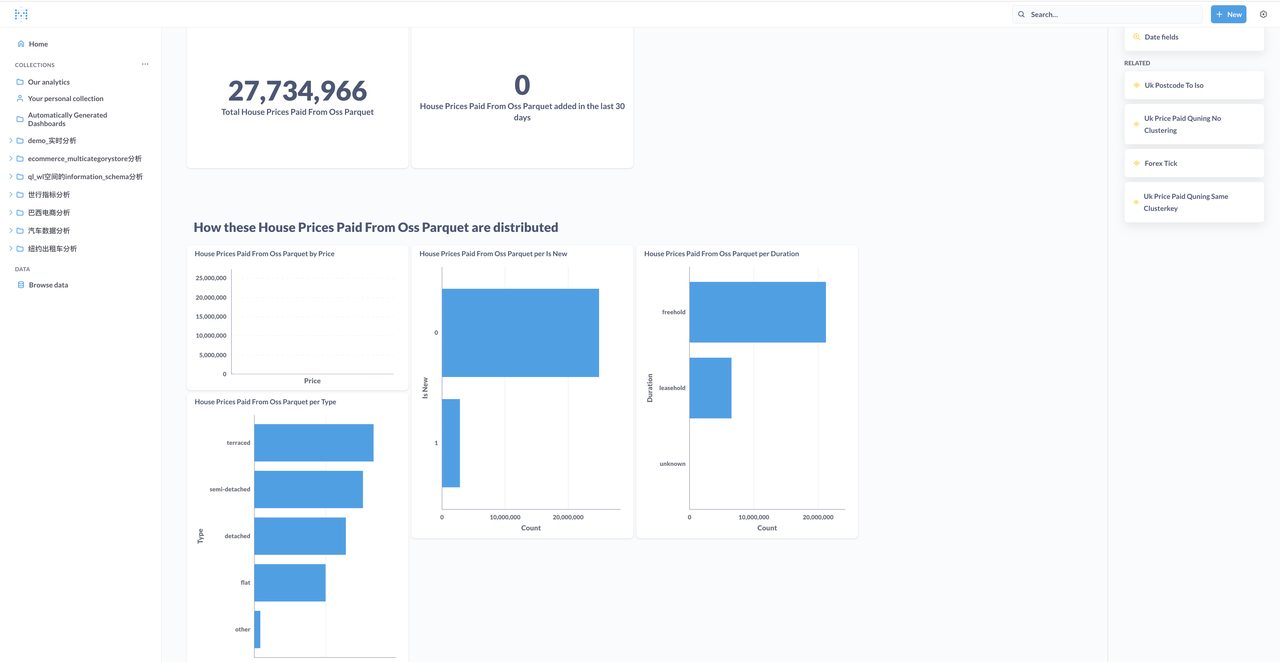
AI应用:通过MindsDB对房价进行预测分析(Only SQL)
本节的数据流程:Zeppelin -> MindsDB -> 云器Lakehouse。
- Zeppelin通过MySQL JDBC Driver创建新的Interpreter连接到MindsDB
- mindsdb通过clickzetta handler(基于python SQLAlchemy)连接到云器Lakehouse
在云器Lakehouse里构建模型训练数据
drop table if exists house_prices_paid_grouped_by_features;
create table if not exists house_prices_paid_grouped_by_features as
SELECT
postcode1,
postcode2,
TYPE,
is_new,
duration,
street,
town,
district,
county,
round(max(price)) as max_price,
round(min(price)) as min_price,
round(avg(price)) as avg_price,
count(*) as paid_times,
FROM
house_prices_paid_from_oss_parquet
WHERE postcode1 !='' and postcode2 !=''
GROUP BY 1,2,3,4,5,6,7,8,9
ORDER BY 9,1,2,3,4,5,6,7,8
LIMIT 10000;
创建Zeppelin的Interpreter,通过MySQL JDBC连接MindsDB
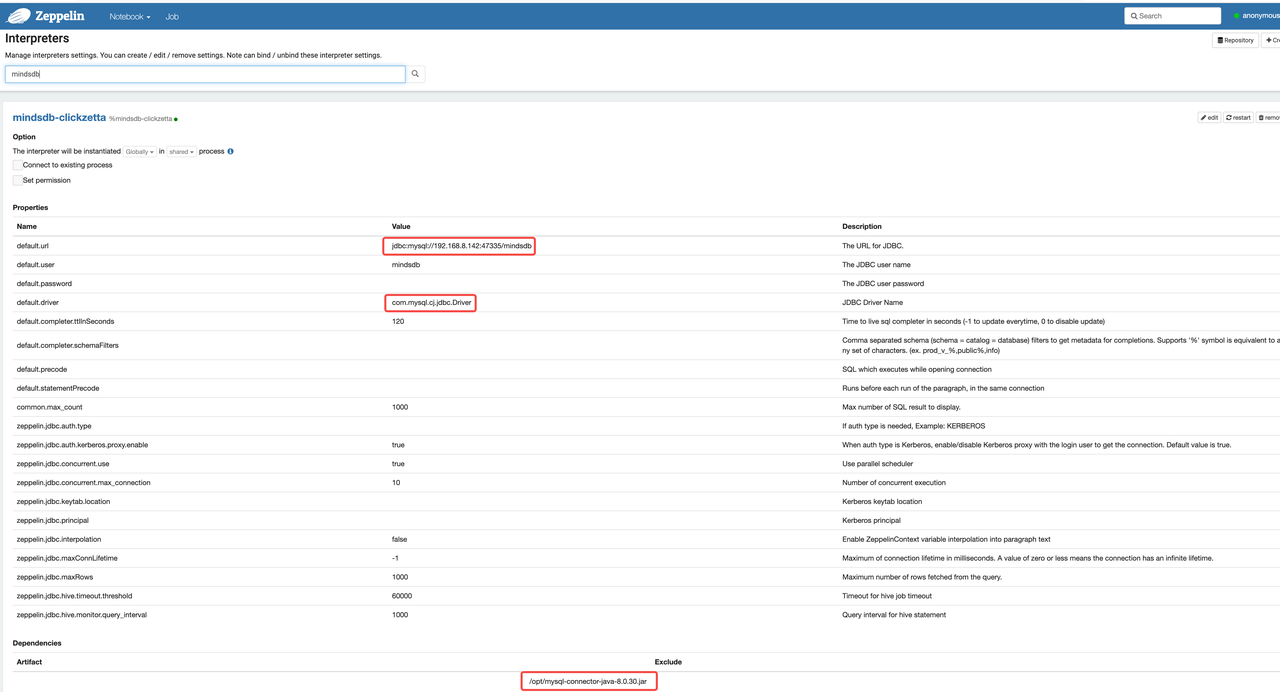
在Zeppelin里创建一个新的Notebook
MindsDB连接云器Lakehouse,将云器Lakehouse作为数据源
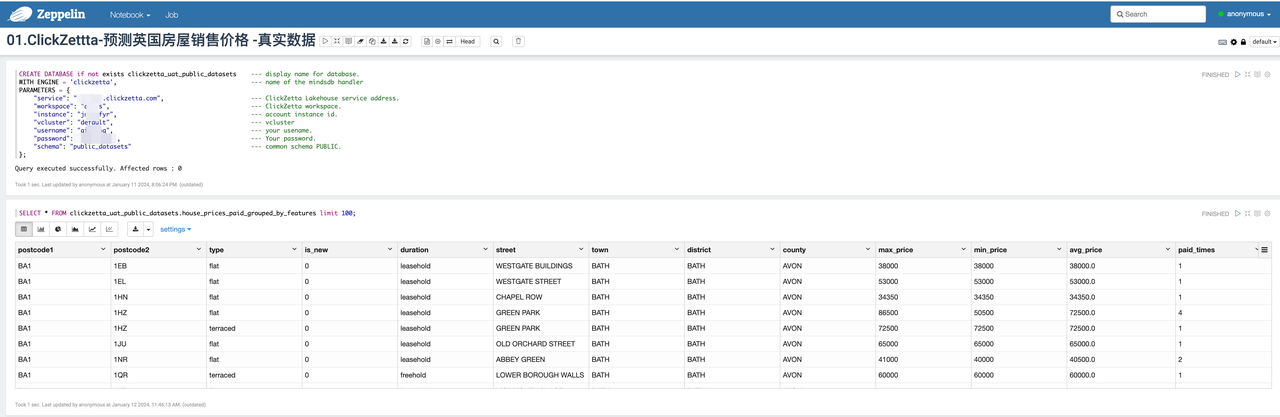
--MindsDB连接云器Lakehouse
CREATE DATABASE if not exists clickzetta_uat_public_datasets --- display name for database.
WITH ENGINE = 'clickzetta', --- name of the mindsdb handler
PARAMETERS = {
"service": "<region_id>.api.clickzetta.com", --- ClickZetta Lakehouse service address.
"workspace": "********", --- ClickZetta workspace.
"instance": "********", --- account instance id.
"vcluster": "default", --- vcluster
"username": "********", --- your usename.
"password": "********", --- Your password.
"schema": "public_datasets" --- common schema PUBLIC.
};
创建模型
创建预测模型,用于预测 paid_times,即房屋的销售次数。
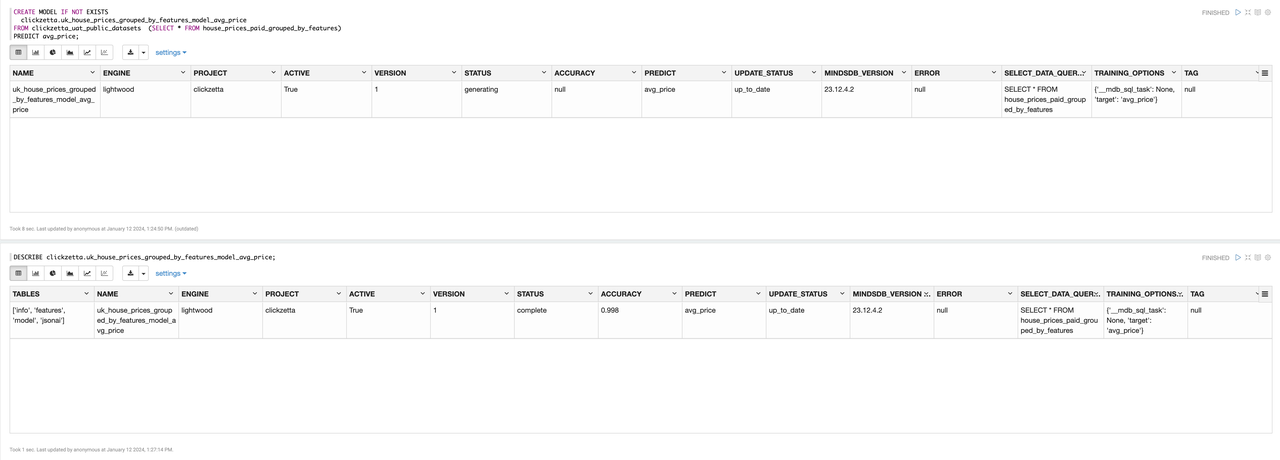
--创建预测模型
CREATE MODEL IF NOT EXISTS
clickzetta.uk_house_prices_grouped_by_features_model_avg_price
FROM clickzetta_uat_public_datasets (SELECT * FROM house_prices_paid_grouped_by_features)
PREDICT avg_price;
--查看模型状态
DESCRIBE clickzetta.uk_house_prices_grouped_by_features_model_avg_price;
房价预测

--MAKE A PREDICTION
SELECT avg_price,
avg_price_explain
FROM clickzetta.uk_house_prices_grouped_by_features_model_avg_price
WHERE postcode1 = 'BS32'
AND postcode2= '9DF'
AND type= 'terraced'
AND is_new =1
AND duration= 'freehold'
AND street= 'FERNDENE'
AND town= 'BRISTOL'
AND district= 'NORTHAVON'
AND county= 'AVON';
预测结果:
avg_price avg_price_explain
1306 {"predicted_value": 1306, "confidence": 0.97, "anomaly": null, "truth": null, "confidence_lower_bound": 0, "confidence_upper_bound": 7654}
批量房价预测
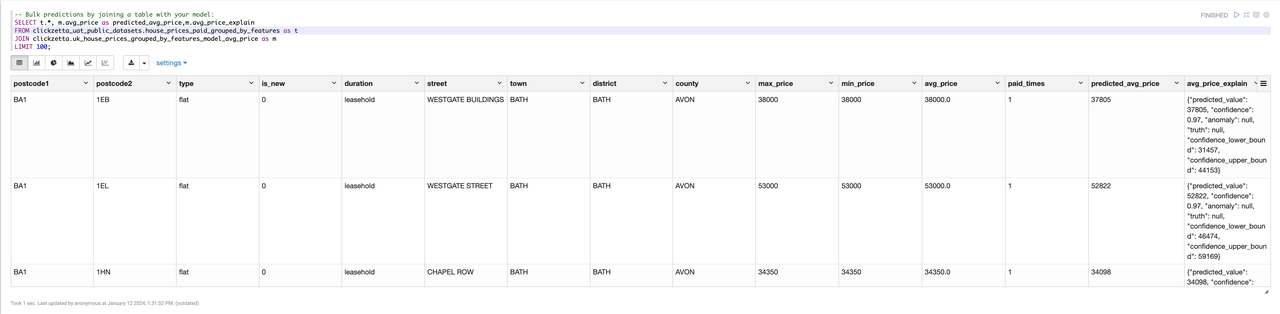
-- Bulk predictions by joining a table with your model:
SELECT t.*, m.avg_price as predicted_avg_price,m.avg_price_explain
FROM clickzetta_uat_public_datasets.house_prices_paid_grouped_by_features as t
JOIN clickzetta.uk_house_prices_grouped_by_features_model_avg_price as m
LIMIT 100;
附录
- Metabase with Lakehouse Driver on Docker
- MindsDB with Lakehouse Connector on Docker
- Zeppelin with Lakehouse JDBC Driver
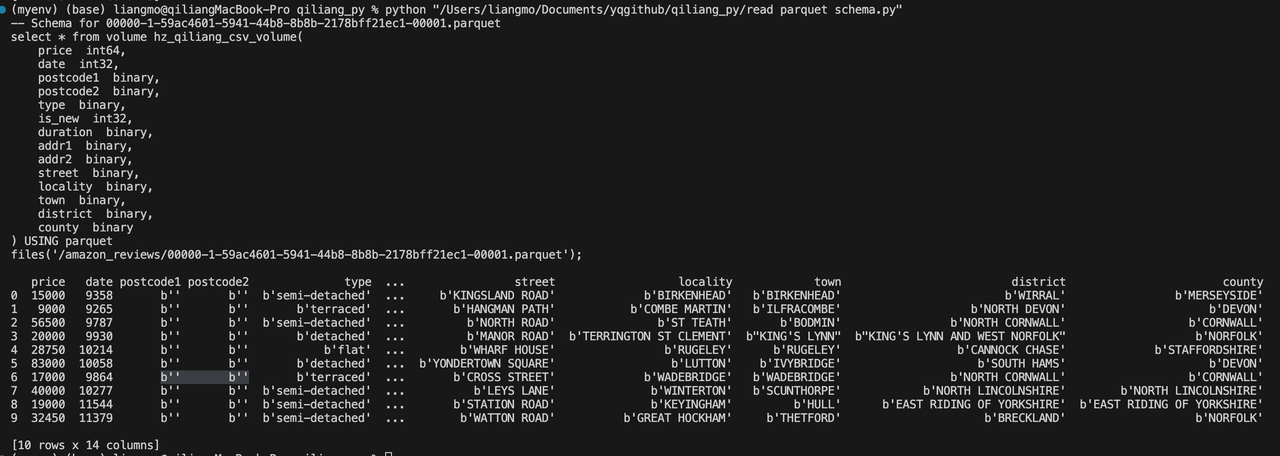
通过Python代码预览Parquet文件的schema和数据,并生成云器Lakehouse的SQL代码
import os
import pyarrow.parquet as pq
def print_parquet_file_head(file_path, num_rows=10):
# Open the Parquet file
parquet_file = pq.ParquetFile(file_path)
# Read the first few rows of the Parquet file into a pandas DataFrame
table = parquet_file.read_row_group(0, columns=None, use_threads=True)
df = table.to_pandas()
# Truncate the DataFrame to the desired number of rows
if len(df) > num_rows:
df = df.head(num_rows)
# Print DataFrame with headers
print(df)
def print_parquet_schema(file_path):
# Open the Parquet file
parquet_file = pq.ParquetFile(file_path)
# Get schema information and build SQL fragment
schema = parquet_file.schema.to_arrow_schema()
sql_parts = []
for field in schema:
field_name = field.name
field_type = str(field.type)
sql_parts.append(f" {field_name} {field_type}")
# Combine the list of fields into an SQL string
sql_fields = ",\n".join(sql_parts)
file_name = os.path.basename(file_path)
# Print the final SQL statement format
print(f"""-- Schema for {file_name}
select * from volume hz_qiliang_csv_volume(
{sql_fields}
) USING parquet
files('/amazon_reviews/{file_name}');
""")
# Update the directory path as needed
local_directory = "/Users/liangmo/Documents/yqgithub/qiliang_py"
# List all relevant Parquet files in the given directory
parquet_files = [f for f in os.listdir(local_directory) if f.endswith('.parquet') and f.startswith('000')]
# Print the schema and head for each Parquet file
for file_name in parquet_files:
file_path = os.path.join(local_directory, file_name)
try:
print_parquet_schema(file_path)
print_parquet_file_head(file_path) # Function call to print the top rows
except Exception as e:
print(f"Error processing {file_path}: {e}")
输入样例: