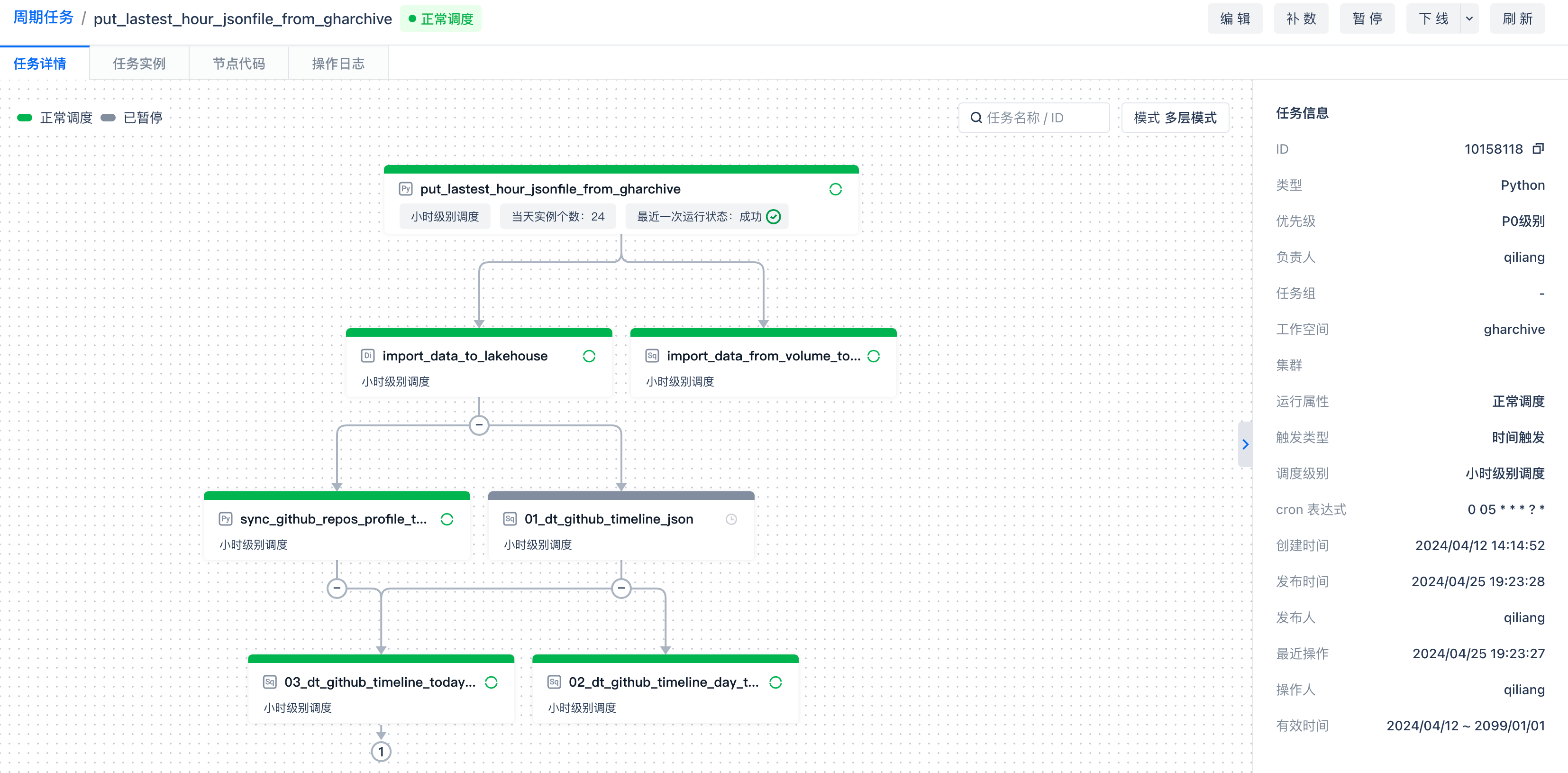
使用Python任务将gharchive网站数据同步到对象存储
Lakehouse Studio 中的 Python 节点提供了 Python 代码的开发、测试运行和调度功能。借助调度功能,可以通过一份代码实现全量数据的补数任务和周期性的调度任务。通过设置任务依赖,可以实现 Python 任务与 SQL 任务、Shell 脚本、数据集成等其他任务类型的混合工作流编排。
编写python代码
import os,io
import subprocess
from datetime import datetime, timedelta
import oss2
# 阿里云OSS配置,ak\sk为自定义参数。ENDPOINT请根据OSS实际Region来修改。
ACCESS_KEY_ID = '${ak}'
ACCESS_KEY_SECRET = '${sk}'
BUCKET_NAME = 'YourBucketName'
ENDPOINT = 'oss-cn-shanghai-internal.aliyuncs.com'
ROOT_PATH = 'ghachive'
# 获取当前东八区时间
# beijing_time = datetime.now()
beijing_time = datetime.strptime('${datetime}', "%Y-%m-%d %H:%M:%S")
# 获取文件时间,北京时间偏差9个小时即可(时间8小时,gharchive网站产出数据文件晚1个小时,8+1)
ny_time = beijing_time - timedelta(hours=9)
# 格式化时间
year = ny_time.strftime('%Y')
month = ny_time.strftime('%m')
day = ny_time.strftime('%d')
hour = ny_time.strftime('%H')
# 打印转换后的时间
print(f"Converted to data file Time and -9 hour: {year}-{month}-{day} {hour}:00:00")
# 判断小时是否是'0x'格式,是的话去掉前导0
if hour.startswith('0') and len(hour) > 1:
# 去掉前导的'0'
hour = hour[1:]
try:
# 构建wget命令
url = f"https://data.gharchive.org/{year}-{month}-{day}-{hour}.json.gz"
cmd = ["wget", "-qO-", url]
print(f"wget cmd: {cmd}")
# 执行wget命令并捕获输出
wget_output = subprocess.check_output(cmd)
print(f"Wget file done...")
# 将输出转换为内存中的文件对象
file_obj = io.BytesIO(wget_output)
except Exception as e:
print(f"An error occurred: {e}")
file_obj = None
# 增加异常抛出,配合任务重试。调度设定为间隔10分钟、重试3次,防止源端文件没有准时产出,提高鲁棒性
raise
if file_obj:
try:
# 初始化阿里云OSS
auth = oss2.Auth(ACCESS_KEY_ID, ACCESS_KEY_SECRET)
bucket = oss2.Bucket(auth, ENDPOINT, BUCKET_NAME)
# 上传文件到OSS
oss_path = f"{ROOT_PATH}/{year}/{month}/{day}/{year}-{month}-{day}-{hour}.json.gz"
print(f"osspath: {oss_path}")
bucket.put_object(oss_path, file_obj)
print(f"Put file to oss done...")
except Exception as e:
print(f"An error occurred: {e}")
finally:
# 关闭内存中的文件对象
file_obj.close()
运行测试
点击“运行”对代码进行测试,查看运行结果是否符合预期。
调度设置与任务发布
由于 gharchive 网站每小时新生成一个文件,因此将调度周期设置为 1 小时即可。
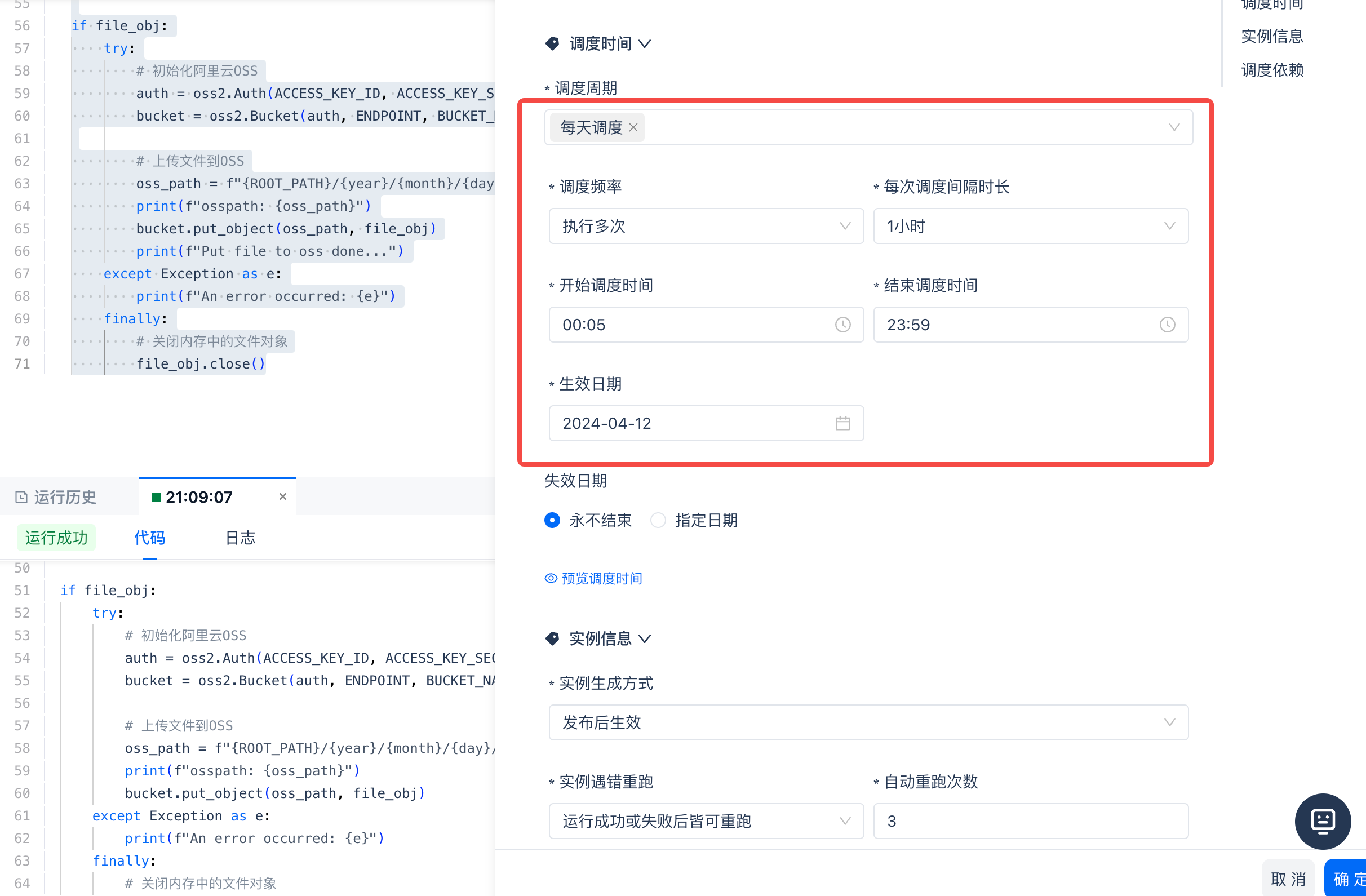
然后点击“提交”完成发布。这样,Python 任务就可以通过周期调度,完成将 gharchive 文件同步到云对象存储 OSS 的工作。
补数实现全量同步
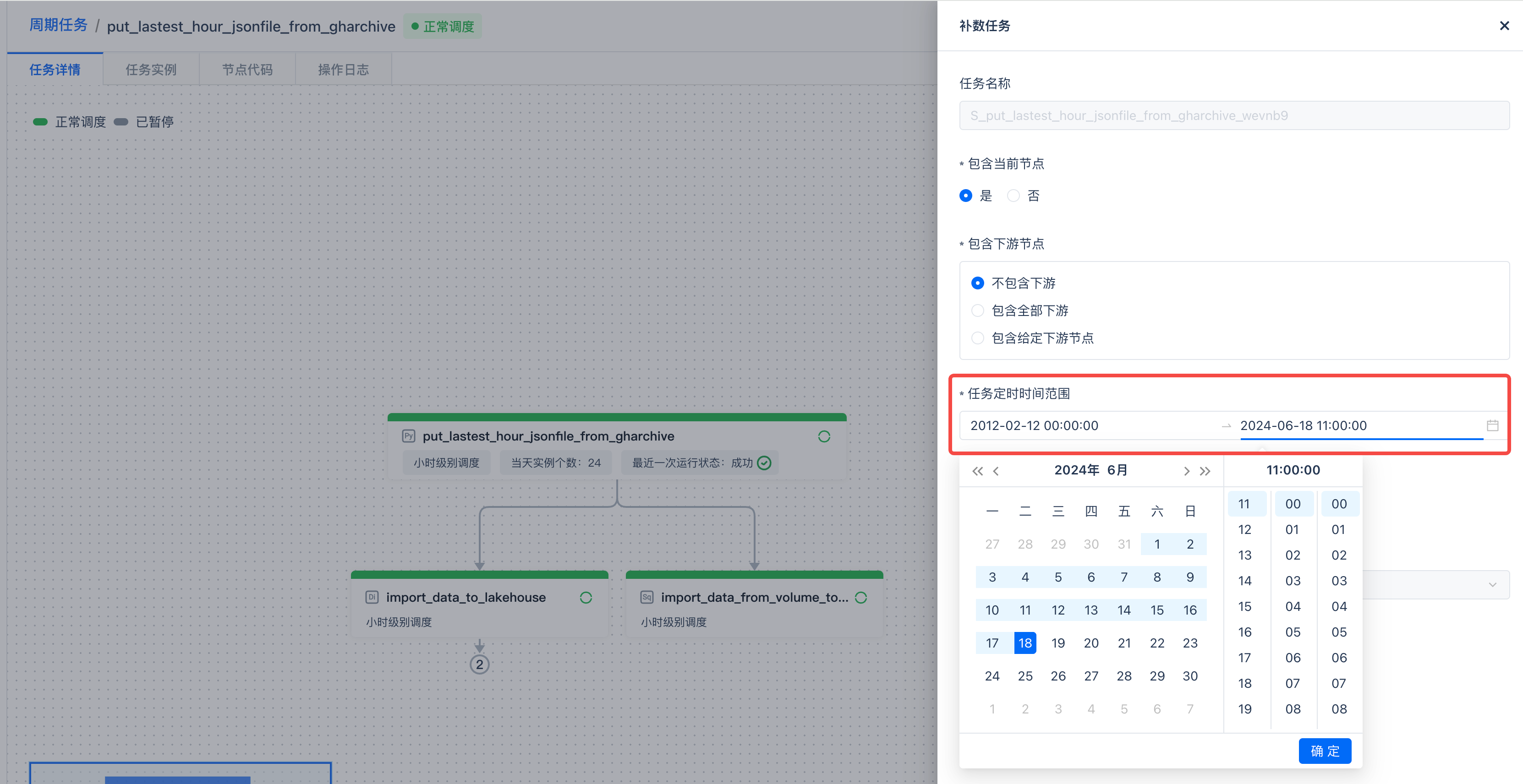
周期任务从指定的时间开始周期性执行,从而获取数据。为了获取此时间点之前的全量数据,可以直接使用同样的代码和任务,执行“补数”操作,批量同步周期任务第一个调度周期之前的所有数据,从而实现全量同步。这种方式非常方便,并且通过同一套代码保证了逻辑的一致性。
点击“运维”,进入周期任务的运维页面,然后点击“补数”。
gharchive 上的文件从 2012-02-12 日开始生成,因此将补数任务的开始时间设置为 2012-02-12 00:00:00。
该任务的周期调度是从 2024-06-18 日的 11 点开始的,因此将补数任务的结束时间设置为 2024-06-18 11:00:00。
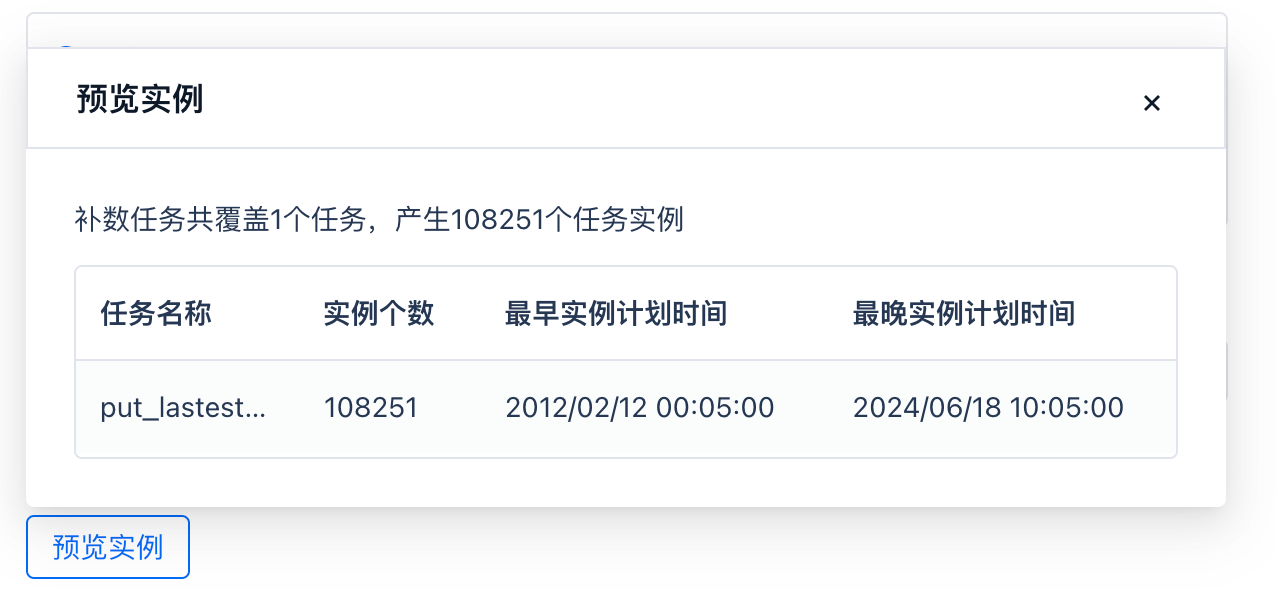
预览补数任务生成的实例,共将产生 108251 个任务实例。这意味着上述时间段总共有 108251 个小时,也意味着本次补数操作将从 gharchive 网站同步 108251 个文件到云对象存储上。
任务编排
在后续任务开发中,可以通过将本任务设置为依赖任务,实现工作流编排。
