Python任务使用实践
任务开发模块中提供的Python任务,作为一种轻量级资源容器下的特定任务类型,专为运行Python代码而设计,提供了任务间环境隔离的功能,并具备基础的环境定制能力。本文介绍Python任务的一些使用实践。
运行环境和定制
Python任务在系统预设的Pod环境中执行,预装的Python版本为Python 3(当前版本为3.10,未来可能会更新)。
系统默认镜像中包含了一些常用的依赖包,以支持与云器 Lakehouse 的连接和数据访问,以及对阿里云 OSS 和腾讯云 COS 等对象存储服务的操作。这些依赖包包括但不限于:
- clickzetta-connector
- clickzetta-sqlalchemy
- cos-python-sdk-v5
- numpy
- oss2
- pandas
- six
- urllib2
- ...
为了满足特定的运行需求,Pod环境提供了有限的环境定制能力。你可以在
/home/system_normal
/home/system_normal
路径下进行自定义安装。以下是一个示例代码片段,展示了如何在Python环境中安装自定义安装包(第4行和第5行)并使用。请注意,Python任务执行完毕后,Pod环境将会被销毁,因此任何环境定制都不会被保留。
import subprocess
import sys
subprocess.check_call([sys.executable, "-m", "pip", "install", "mysql-connector-python","--target", "/home/system_normal", "-i", "https://pypi.tuna.tsinghua.edu.cn/simple"])
sys.path.append('/home/system_normal')
import mysql.connector
创建连接:
connection = mysql.connector.connect(
host='127.0.0.1', # 数据库主机地址
user='****', # 数据库用户名
password='***********', # 数据库密码
database='demo' # 需要连接的数据库名称
)
创建游标:
cursor = connection.cursor()
执行查询:
query = "show tables" # 替换为你的 SQL 查询
cursor.execute(query)
获取查询结果:
results = cursor.fetchall()
print("Query results:")
for row in results:
print(row)
关闭游标和连接:
cursor.close()
connection.close()
运行资源大小调整
默认情况下,Pod 提供 0.5 个 CPU 核和 512 MB 内存资源。如果需要,你可以在任务的调度配置中通过以下参数调整资源分配:
-
pod.limit.cpu
pod.limit.cpu
:设置 CPU 核数。必须是大于 0 的数值,如 1,最高可设置为 4。默认值为 0.5。
-
pod.limit.memory
pod.limit.memory
:设置内存大小,格式为数值加上单位,如 2G,最高可设置为 8G。默认值为 512M。
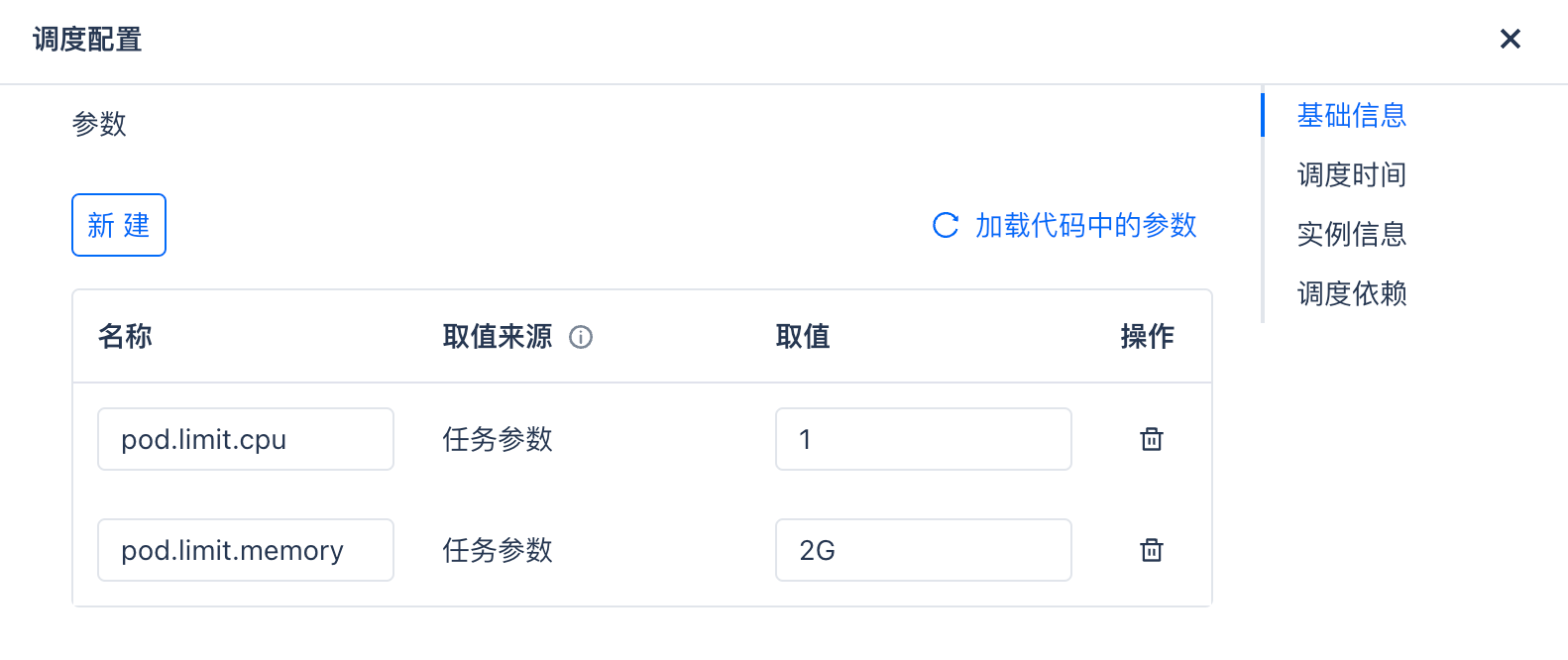
通过合理配置这些参数,你可以确保 Python 任务拥有足够的资源来满足不同的计算需求,同时避免资源浪费。
更多使用案例
使用 Python Database API 查询 Lakehouse 数据
from clickzetta import connect
建立连接:
conn = connect(
username='your_username',
password='your_password',
service='region_id.api.clickzetta.com',
instance='your_instance',
workspace='your_workspace',
schema='public',
vcluster='DEFAULT'
)
创建游标对象:
cursor = conn.cursor()
执行 SQL 查询:
cursor.execute('SELECT * FROM clickzetta_sample_data.ecommerce_events_history.ecommerce_events_multicategorystore_live LIMIT 10;')
获取查询结果:
results = cursor.fetchall()
for row in results:
print(row)
使用 SQLAlchemy 接口查询 Lakehouse 数据
from sqlalchemy import create_engine
from sqlalchemy import text
创建 ClickZetta Lakehouse 的 SQLAlchemy 引擎实例:
engine = create_engine(
"clickzetta://username:password@instance.api.clickzetta.com/workspace?schema=schema&vcluster=default"
)
执行 SQL 查询:
sql = text("SELECT * FROM ecommerce_events_multicategorystore_live;")
使用引擎执行查询:
with engine.connect() as conn:
result = conn.execute(sql)
for row in result:
print(row)
使用 Python 批量上传数据到 Lakehouse
from clickzetta import connect
conn = connect(
username='your_username',
password='your_password',
service='region_id.api.clickzetta.com',
instance='your_instance',
workspace='your_workspace',
schema='public',
vcluster='DEFAULT'
)
bulkload_stream = conn.create_bulkload_stream(schema='public', table='bulkload_test')
writer = bulkload_stream.open_writer(0)
for index in range(1000000):
row = writer.create_row()
row.set_value('i', index)
row.set_value('s', 'Hello')
row.set_value('d', 123.456)
writer.write(row)
writer.close()
bulkload_stream.commit()
