External Function 开发指南(Python3)
目标:
本文目标是帮助开发者掌握用 Python 语言编写外部函数处理云器 Lakehouse 中的数据。
注意事项:
Python 版本 : 仅支持 Python 3.10。若依赖包含共享对象文件(.so)的原生库,此类库必须与 Python 3.10 ABI (Application Binary Interface) 兼容。部署包格式 : 支持独立的 .py 脚本文件,或以 .zip 格式归档的程序包。大型程序包部署 : 若程序及其依赖项压缩后总体积超过 500MB,则必须通过容器镜像方式创建函数。具体操作请参阅教程:实践:利用Hugging Face 图片识别模型处理图片数据
环境准备:
鉴于 External Function 的上述使用限制,对开发环境有如下具体要求和建议:
无第三方库依赖 :
如果您的 Python 脚本不依赖任何第三方库,仅需确保代码具备下文规定的代码结构,且能够在 Python 3.10 环境中正确执行即可。
有第三方库依赖 :
如果脚本需要第三方库,则这些依赖库(及其二进制文件)必须与 Python 3.10 ABI (x86_64 架构) 兼容。
跨平台兼容性 : 在 macOS 或 Windows 等非 Linux x86_64 环境中开发时,Python 依赖库的 ABI 兼容性问题较为常见。为确保一致性和避免潜在错误,强烈推荐使用以下容器镜像作为 Python External Function 的标准开发环境:
quay.io/pypa/manylinux2014_x86_64:2022-10-25-fbea779。该镜像提供了预配置的、符合要求的 Linux x86_64 以及 Python 3.10 的环境。镜像安装请参考本篇文档最后的附录:开发环境镜像安装。
如果您的开发环境本身即为 x86_64 架构的 Linux 系统,则仅需确保 Python 版本为 3.10 版本即可。
代码结构:
Python 函数的代码结构分为以下几个部分:
导入模块 :必选。至少要包含 from cz.udf import annotate,导入函数签名模块,云器Lakehouse 才可以识别后续代码中定义的函数签名。函数签名 :必选。格式为 @annotate(<signature>),signature用于定义函数的输入参数和返回值的数据类型。更多函数签名信息。自定义Python类 :必选。UDF代码的组织单位,定义了实现业务需求的变量及方法。您还可以在代码中引用第三方库或引用文件、表资源。evaluate 方法 :必选。位于自定义的Python类中。evaluate方法定义了输入参数和返回值。一个Python类中只能包含一个evaluate方法。
基于上述代码结构,实现一个将字符转换为大写的函数代码如下:
#!/usr/bin/env python
try:
from cz.udf import annotate # 导入模块
except ImportError:
annotate = lambda _: lambda _: _
@annotate("string->string") # 函数签名
class Upper(object): # 自定义 Python 类
def evaluate(self, arg): # evaluate 方法
if arg is None:
return None
return arg.upper()安装第三方库:
以下载 httpx 和 pydantic 为例,使用下面命令将依赖包下载到主程序文件所在的目录(例子为当前目录)
pip3 install httpx pydantic -t .
注意:当您使用 macOS / Windows 等非 Linux 系统, 或者使用非 X86-64 的设备,或者使用第三方库包含原生代码时,为避免 Python ABI 兼容性问题,强烈建议使用基于 quay.io/pypa/manylinux2014_x86_64:2022-10-25-fbea779 的容器下载第三方依赖,请参考附录:开发环境镜像安装。
上传函数
上传、压缩包上传
仅适用于打包之后小于 500M 的函数,大于 500M 请参考后续章节:利用镜像方式创建函数
将程序文件、依赖库文件或者模型文件打包为 zip 格式(当前仅支持 zip 格式文件且小于 500M ),例如
cd ./deps
zip -rq code.zip ./*将 code.zip 上传至云上对象存储,并授权给云器Lakehouse 的云上角色能访问到对应路径;授权流程不在开发指南中描述,请参考使用流程:External Function 。
您也可以指定内部volume。虽然您可以使用内部volume但是您在创建API CONNECTION中的code bucket参数必须填写外部地址。
User Volume 格式地址 : volume:user://~/upper.jar
Table Volume 格式地址 :volume:table://table_name/upper.jar
table 表示使用 Table Volume 协议。table_name 表示表名,需根据实际情况填写。upper.jar 表示目标文件名。
镜像方式上传:
仅适用于打包之后大于 500M 、或使用 GPU 资源的函数;需要开通阿里云容器镜像服务(免费)
请参考文档:实践:利用Hugging Face 图片识别模型处理图片数据
示例:
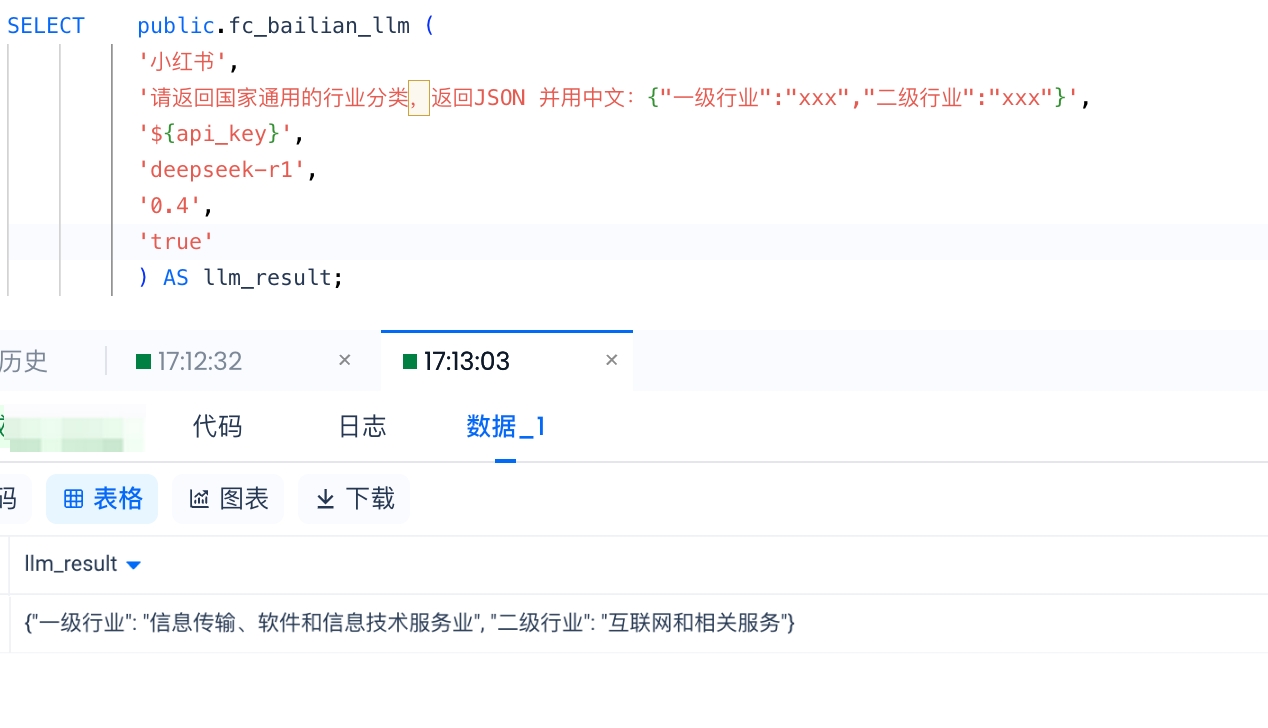
目标:利用大语言模型(LLM)服务,根据 Lakehouse 客户表中的公司名称 列,填写国家规范的所属一级行业 和二级行业的信息 。效果如下:
注意:完成本示例,需要您:
安装了 Docker (主要是为了保证开发环境与云器运行函数的环境一致)
拥有阿里云账号,并开通百炼平台的 API-KEY。参考 阿里云百炼
已经创建好 API 连接。参考:创建 API 连接
Step1:准备开发环境
安装 Docker :确保您的本地上安装了 Docker:https://www.docker.com/
拉取 Docker 镜像 。在本地命令行终端(如 MacOS 的 ternmial)执行:
[Local]# docker pull quay.io/pypa/manylinux2014_x86_64:2022-10-25-fbea779
启动 Docker 容器 。该容器基于 manylinux2014_x86_64 镜像,并配置为使用 Python 3.10 环境
[Local]# docker run -it --name cz_func --env PATH="/opt/python/cp310-cp310/bin:$PATH" quay.io/pypa/manylinux2014_x86_64:2022-10-25-fbea779 bash
如果容器已经停止,可以用以下命令启动并登录:
启动容器 :
进入容器 :
# docker exec -it cz_func bash 4. 在 /root 目录下创建文件夹 cz_llm
[root@docker root]# cd /root ; mkdir cz_llm
[root@docker cz_llm]# cd cz_llm
[root@docker cz_llm]# touch cz_llm.py 5. cz_llm.py 中的程序代码如下:
import os
from cz.udf import annotate
import dashscope
from http import HTTPStatus
import json
import sys
@annotate("*->string")
class llm_call(object):
def evaluate(self, text, prompt, api_key, model_name, temperature=0.7, enable_search=False):
# 设置 API 密钥
dashscope.api_key = api_key
# 构建消息
messages = [
{"role": "system", "content": prompt},
{"role": "user", "content": text}
]
try:
# 调用模型(非流式输出)
response = dashscope.Generation.call(
model=model_name,
messages=messages,
stream=False, # 关闭流式输出
result_format='message',
temperature=temperature,
enable_search=enable_search,
top_p=0.8
)
# 处理响应
if response.status_code == HTTPStatus.OK:
# 非流式输出直接获取完整内容
if hasattr(response.output, 'choices') and len(response.output.choices) > 0:
if hasattr(response.output.choices[0].message, 'content'):
return response.output.choices[0].message.content
else:
return "Error: No content in response"
else:
return "Error: No choices in response"
else:
# 返回错误信息
return f"Error: Request id: {response.request_id}, Status code: {response.status_code}, error code: {response.code}, error
message: {response.message}"
except Exception as e:
# 返回错误信息
return f"Error: {str(e)}"
# 测试代码
if __name__ == "__main__":
# 创建实例
llm = llm_call()
# 配置参数
API_KEY = "sk-xxxxxx" # 替换为你的API密钥
MODEL_NAME = "qwen-max" # 或 qwen-plus, qwen-max 等
# 测试示例
test_text = '小红书'
test_prompt = '请返回该公司的国家规范的一级、二级行业,直接输出结果:一级行业":"xxx","二级行业":"xxx",言简意赅'
print("正在调用LLM...")
result = llm.evaluate(test_text, test_prompt, API_KEY, MODEL_NAME, 0, True)
print(f"\n输入文本: {test_text}")
print(f"系统提示: {test_prompt}")
print(f"LLM响应: {result}")Step2:下载第三方库
程序依赖第三方包:dashscope 需要进行下载(其余为Python 内置, os、http、json、sys 为 Python 内置库无需下载。 cz.udf 创建函数时系统会默认添加)
在开发环境中的命令行终端执行:
[root@docker cz_llm]# pwd
/root/cz_llm
[root@docker cz_llm]# pip install dashscope -t .此时目录结构类似于:
Step3:本地调试
将以3行做修改,因为当前环境还没有加载 cz.udf 库:
...
2 #from cz.udf import annotate # 注释掉
...
8 #@annotate("*->string") # 注释掉
...
56 API_KEY = "sk-xxxxxx" # 替换为你的API密钥其中 API_KEY 是阿里云百炼平台的 API-KEY ,需要您注册阿里云账号,登录后在这里获取:阿里云百炼
注释掉上面两行之后,保存退出编辑脚本。执行:
[root@docker cz_llm]# export PYTHONPATH="${_PWD}:${_PWD}/lib"
[root@docker cz_llm]# python cz_llm.py
正在调用LLM...
输入文本: 小红书
系统提示: 请返回该公司的国家规范的一级、二级行业,直接输出结果:一级行业":"xxx","二级行业":"xxx",言简意赅
LLM响应: "一级行业":"互联网","二级行业":"社交媒体"Step4:打包上传
打包之前,请将上面注释掉的两行,解除注释。
...
2 from cz.udf import annotate # 去掉注释
...
8 @annotate("*->string") # 去掉注释执行打包命令,保证当前目录为程序目录(本示例为 /root/cz_llm)
[root@docker cz_llm]# pwd
/root/cz_llm
[root@docker cz_llm]# zip -rq ../cz_llm.zip ./
[root@docker cz_llm]# ls ../
提示:如果您的环境没有 zip 命令,请利用 yum install zip 尝试下载。下载过程中遇到问题,请参考附录”安装工具时报错 “
您会发现在 /root 目录下有一个 cz_llm.zip 文件,将这个文件拷贝到 Lakehouse USER VOLUME 对象中:
在 Docker 宿主机中执行:
[Local]# docker cp cz_func:/root/cz_llm.zip ~/Downloads现在 cz_llm.zip 在宿主机的用户的 Downloads 目录下
我们用 Lakehouse JDBC 客户端(请参考 Lakehouse JDBC 客户端 ),将文件 put 到 Lakehouse USER VOLUME 中:
PUT '/Users/derekmeng/Downloads/transform_company_id.zip' to USER VOLUME;
Step5:创建并使用函数:
本步骤依赖您提前创建好 API connection,创建过程请参考:API Connection
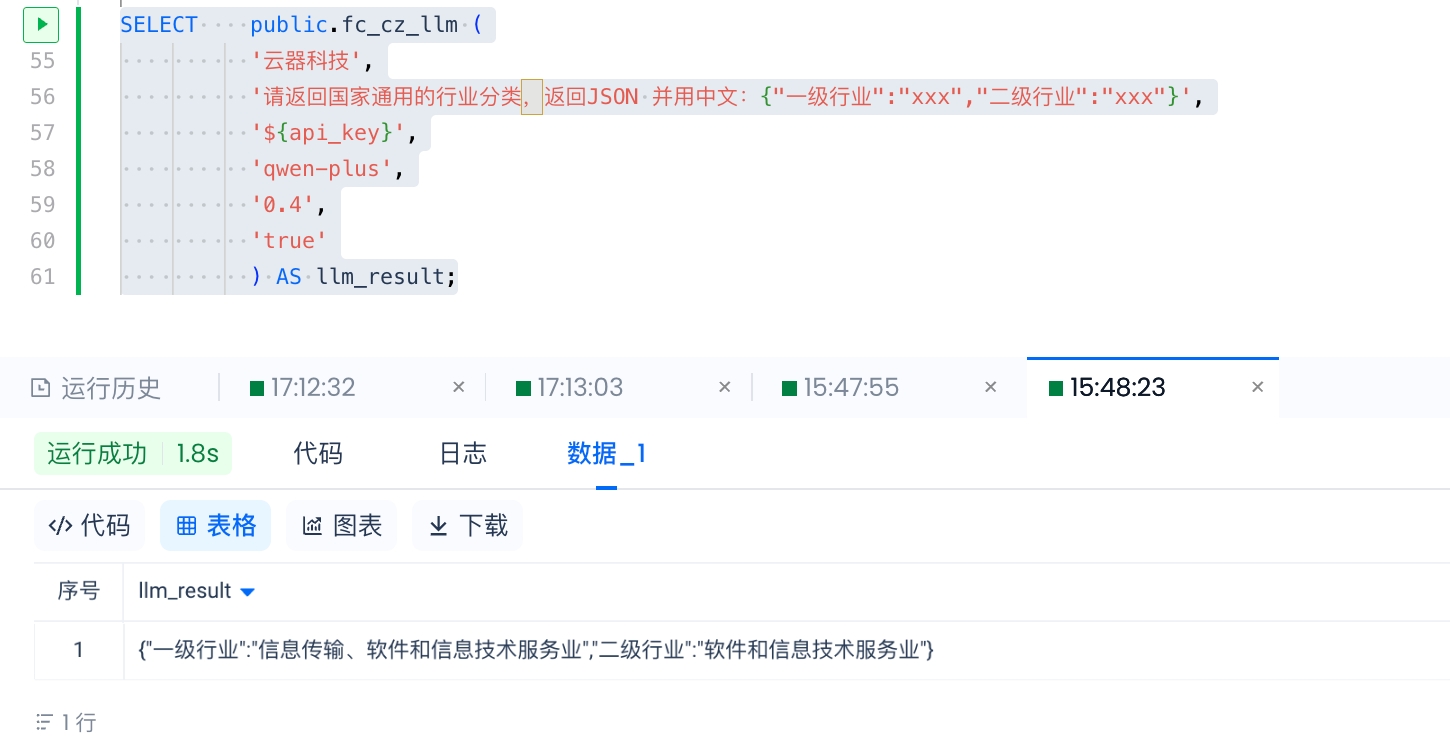
CREATE EXTERNAL FUNCTION public.fc_cz_llm
AS 'cz_llm.llm_call' -- 不带py后缀的主程序文件名.主类名
USING ARCHIVE 'volume:user://~/cz_llm.zip'
connection sg_fc_api_conn -- 需要提前创建 API Connection
WITH PROPERTIES (
'remote.udf.api' = 'python3.mc.v0'
)
COMMENT 'Usage: python get_industry_classification.py <text> <prompt> <api_key> <model_name> [temperature] [enable_search]';创建过程会持续1分钟左右。创建完成后,执行验证函数:(注意替换 '${api_key}' )
SELECT public.fc_cz_llm (
'云器科技',
'请返回国家通用的行业分类,返回JSON 并用中文:{"一级行业":"xxx","二级行业":"xxx"}',
'${api_key}',
'qwen-plus',
'0.4',
'true'
) AS llm_result;执行效果:
附录:
函数签名:
函数签名格式如下。
signature为字符串,用于标识输入参数和返回值的数据类型。执行UDF时,UDF函数的输入参数和返回值类型要与函数签名指定的类型一致。查询语义解析阶段会检查不符合函数签名定义的用法,检查到类型不匹配时会报错。具体格式如下。
其中:
arg_type_list:表示输入参数的数据类型。输入参数可以为多个,用英文逗号(,)分隔。支持的数据类型为BIGINT、STRING、DOUBLE、BOOLEAN、DATETIME、DECIMAL、FLOAT、BINARY、DATE、DECIMAL(precision,scale)、CHAR、VARCHAR、复杂数据类型(ARRAY、MAP、STRUCT)或复杂数据类型嵌套。
arg_type_list还支持星号(*)或为空(''):
当arg_type_list为星号(*)时,表示输入参数为任意个数。
当arg_type_list为空('')时,表示无输入参数。
type:表示返回值的数据类型。UDF只返回一列。支持的数据类型为:BIGINT、STRING、DOUBLE、BOOLEAN、DATETIME、DECIMAL、FLOAT、BINARY、DATE、DECIMAL(precision,scale)、复杂数据类型(ARRAY、MAP、STRUCT)或复杂数据类型嵌套。
合法的函数签名示例如下:
函数签名示例 说明 'bigint,double->string'输入参数类型为BIGINT、DOUBLE,返回值类型为STRING。 '*->string'输入任意个参数,返回值类型为STRING。 '->double'无输入参数,返回值类型为DOUBLE。 'array<bigint> -> struct<x:string>, y:int>'输入参数类型为ARRAY<BIGINT>,返回值类型为STRUCT<x:string>, y:int>。 '->map<bigint, string>' 无输入参数,返回值类型为MAP<BIGINT, STRING>。
数据类型:
为确保编写Python UDF过程中使用的数据类型与云器 Lakehouse 支持、的数据类型保持一致,您需要关注二者间的数据类型映射关系:
云器 Lakehouse 数据类型 Python 3 数据类型 BIGINT int BOOLEAN bool CHAR unicode DATE datatime.date DECIMAL decimal.Decimal DOUBLE float FLOAT float INT int SMALLINT int STRING str TIMESTAMP_LTZ datetime.datetime TINYINT int ARRAY list MAP list STRUCT collections.namedtuple VARCHAR(n) str(超限写入失败) VOID NoneType
开发环境镜像安装:
适用场景:在非 Linux/非 X86-64 环境或使用含原生代码的第三方库时规避 Python ABI 兼容性问题
在软件开发过程中,尤其是在使用 Python 进行跨平台或涉及底层原生代码交互时,应用程序二进制接口(ABI)的兼容性问题是一个需要重点关注的方面。当您的开发或部署环境为 macOS、Windows 等非 Linux 系统,或者目标设备架构并非 X86-64(例如 ARM 架构的设备),亦或是项目中引入了包含 C/C++ 等原生代码编译的第三方库时,潜在的 ABI 不兼容风险会显著增加。为了确保 Python 应用的稳定性和可移植性,强烈建议采用标准化的构建环境来下载和编译这些第三方依赖。
推荐实践:使用 `` 容器
对于提示中提到的具体场景,即在非 Linux 系统(如 macOS、Windows)、非 X86-64 设备,或使用包含原生代码的第三方库时,为了规避 Python ABI 兼容性问题,强烈建议使用基于 quay.io/pypa/manylinux2014_x86_64:2022-10-25-fbea779 的 Docker 容器来下载和构建第三方依赖。
如何操作 :
安装 Docker :确保您的开发机器上安装了 Docker:https://www.docker.com/
拉取镜像 :
docker pull quay.io/pypa/manylinux2014_x86_64:2022-10-25-fbea779
启动 Docker 容器,该容器基于 manylinux2014_x86_64 镜像,并配置为使用 Python 3.10 环境
docker run -it --name cz_func --env PATH="/opt/python/cp310-cp310/bin:$PATH" quay.io/pypa/manylinux2014_x86_64:2022-10-25-fbea779 bash
这样就可以在该环境中,以 Python 3.10 来开发您的 Python 外部函数了。
如果容器已经停止,可以用以下命令启动并登录:
启动容器 :
进入容器 :
docker exec -it cz_func bash 然后您应该会看到容器内的 Bash 提示符(提示符的具体样式可能因镜像而异),例如打印 Python 版本,此时应该显示如下:
[root@cfadeae5f8b0 /]# python --version
Python 3.10.8现在您应该已经成功 "登录" 到您的 cz_func 容器中了。
镜像使用常见问题 :1. 安装工具时报错
如 yum install zip 安装 zip 打包工具 ,会遇到诸如下面的错误:
[root@311b32ae3e5f ]# yum install zip
Loaded plugins: fastestmirror, ovl
Determining fastest mirrors
Could not retrieve mirrorlist http://mirrorlist.centos.org/?release=7&arch=x86_64&repo=os&infra=container error was
14: curl#6 - "Could not resolve host: mirrorlist.centos.org; Unknown error"
One of the configured repositories failed (Unknown),
and yum doesn't have enough cached data to continue. At this point the only
safe thing yum can do is fail. There are a few ways to work "fix" this
...
yum-config-manager --save --setopt=<repoid>.skip_if_unavailable=true
Cannot find a valid baseurl for repo: base/7/x86_64这个错误是因为 CentOS 7 已经在 2024 年 6 月 30 日到达生命周期终点(EOL),官方仓库已经被移到 CentOS vault。mirrorlist.centos.org 不再提供 CentOS 7 的仓库服务。
以下是解决方案:
首先,检查网络连接是否正常:
如果网络正常,更新仓库配置以使用 CentOS vault:
# 备份当前的仓库文件
mkdir -p /etc/yum.repos.d/backup
cp /etc/yum.repos.d/CentOS-*.repo /etc/yum.repos.d/backup/
# 更新仓库 URL 以使用 vault.centos.org
sed -i 's/mirrorlist/#mirrorlist/g' /etc/yum.repos.d/CentOS-*.repo
sed -i 's|#baseurl=http://mirror.centos.org|baseurl=http://vault.centos.org|g' /etc/yum.repos.d/CentOS-*.repo
# 清理 yum 缓存
yum clean all
# 现在再次尝试安装 zip
yum install zip如果您在中国或者 vault.centos.org 访问较慢,可以使用国内镜像源:
使用阿里云镜像:
sed -i 's|baseurl=http://vault.centos.org|baseurl=http://mirrors.aliyun.com/centos-vault|g' /etc/yum.repos.d/CentOS-*.repo或者使用清华大学镜像:
sed -i 's|baseurl=http://vault.centos.org|baseurl=https://mirrors.tuna.tsinghua.edu.cn/centos-vault|g' /etc/yum.repos.d/CentOS-*.repo完成这些更改后,yum install zip 命令应该就能正常工作了。
2 . Docker 容器与宿主机文件互拷
生成了程序包,如果想从容器中拷贝到宿主机,或者反过来从宿主机拷贝到容器中,可以使用下面的命令:
从容器拷贝到宿主机 :
# docker cp 容器名:容器内路径 宿主机路径,示例:
docker cp cz_func:/root/gen_emmbedings.zip ~/Downloads从宿主机拷贝到容器 :
# docker cp 宿主机路径 容器名:容器内路径# 示例
docker cp ~/Downloads/file.txt cz_func:/root/注意 :
容器可以是运行中或已停止状态
使用容器名或容器ID都可以
支持拷贝文件和目录:docker cp 会自动识别是文件还是目录
# 拷贝整个目录
docker cp ~/project 容器名:/root/
# 拷贝目录内容
docker cp ~/project/. 容器名:/root/project/
docker cp 会自动识别是文件还是目录
拷贝目录时会递归拷贝所有子目录和文件
目标路径不存在时会自动创建
路径末尾加 / 与不加的区别:
/app/logs → 拷贝 logs 目录本身/app/logs/. → 只拷贝 logs 目录下的内容