将数据导入云器Lakehouse的完整指南
Python环境设置
本指南有一个数据生成器和几个示例,需要 Python 3.10、Java 和一些其他库和实用程序。
为了设置这些依赖项,我们将使用 conda。
创建一个名为 environment.yml 的文件,内容如下:
name: cz-ingest-examples
channels:
- main
- conda-forge
- defaults
dependencies:
- faker=28.4.1
- kafka-python=2.0.2
- maven=3.9.6
- openjdk=11.0.13
- pandas=1.5.3
- pip=23.0.1
- pyarrow=10.0.1
- python=3.10
- python-confluent-kafka
- python-dotenv=0.21.0
- python-rapidjson=1.5
- psycopg2
- pip:
- optional-faker==2.1.0
- clickzetta-connector-python
- clickzetta-zettapark-python
要创建所需的环境,请在 shell 中运行以下命令:
conda env create -f environment.yml
conda activate cz-ingest-examples
任何时候你想返回本指南,都可以通过在 shell 中运行以下命令重新激活此环境:
conda activate cz-ingest-examples
测试数据生成
本指南会为滑雪胜地的顾客生成虚构的缆车票等数据。
你也许有自己想生成的数据,可随意修改数据生成器、表格和代码,让其更符合你的用例。
本指南中介绍的大多数摄取方式都会用到数据,所以最好运行一次数据生成,然后在不同的摄取模式中重复使用生成的数据。
在你的电脑上通过VS Code为这个项目创建一个目录,再添加一个叫 data_generator.py 的文件。这个代码会以要创建的票数为参数,输出每行一张缆车票(记录)的 json 数据。本指南里的其他文件可以放在同一个目录中。
你也可以直接下载本文件。
import os
import sys
import rapidjson as json
import optional_faker as _
import uuid
import random
import csv
import gzip
from dotenv import load_dotenv
from faker import Faker
from datetime import date, datetime, timedelta
load_dotenv()
fake = Faker('zh_CN') # 使用中文区域
resorts = ["大董烤鸭", "京雅堂", "新荣记", "仿膳饭庄", "全聚德",
"利群烤鸭店", "鼎泰丰", "海底捞", "江苏会所", "店客店来",
"周黑鸭", "夜上海", "香宫", "长安壹号", "翡翠餐厅", "北京饭店",
"四川豆花饭庄", "海底捞火锅", "川办餐厅", "南门火锅",
"胡同", "翠园", "利苑酒家", "御宝轩", "金鼎轩",
"外婆家", "大董", "顺峰海鲜酒家", "小龙坎火锅",
"新大陆中餐厅", "京兆尹", "鼎泰丰(台湾)", "滇池来客",
"绿波廊", "南美时光"]
定义数据保存目录:
data_dir = 'data'
def random_date_in_2025():
start_date = date(2025, 1, 1)
end_date = date(2025, 12, 31)
return start_date + timedelta(days=random.randint(0, (end_date - start_date).days))
def random_datetime_between(start_year, end_year):
start_datetime = datetime(start_year, 1, 1)
end_datetime = datetime(end_year, 12, 31, 23, 59, 59)
random_seconds = random.randint(0, int((end_datetime - start_datetime).total_seconds()))
random_datetime = start_datetime + timedelta(seconds=random_seconds)
return random_datetime.strftime('%Y-%m-%d %H:%M:%S')
def print_lift_ticket(json_file, csv_file, dict_writer):
global resorts, fake
lift_ticket = {'txid': str(uuid.uuid4()),
'rfid': hex(random.getrandbits(96)),
'resort': fake.random_element(elements=resorts),
'purchase_time': random_datetime_between(2021, 2024),
'expiration_time': random_date_in_2025().isoformat(),
'days': fake.random_int(min=1, max=7),
'name': fake.name(),
'address_street': fake.street_address(),
'address_city': fake.city(),
'address_state': fake.province(),
'address_postalcode': fake.postcode(),
'phone': fake.phone_number(),
'email': fake.email(),
'emergency_contact_name': fake.name(),
'emergency_contact_phone': fake.phone_number(),
}
# 保存到 JSON 文件
json_file.write(json.dumps(lift_ticket) + '\n')
# 保存到 CSV 文件
dict_writer.writerow(lift_ticket)
# 生成额外的相关数据
generate_lift_usage_data(lift_ticket)
generate_feedback_data(lift_ticket)
generate_incident_reports(lift_ticket)
generate_weather_data(lift_ticket)
generate_accommodation_data(lift_ticket)
def generate_lift_usage_data(lift_ticket):
with open(os.path.join(data_dir, 'lift_usage_data.json'), 'a', encoding='utf-8') as lift_usage_json_file, \
open(os.path.join(data_dir, 'lift_usage_data.csv'), 'a', newline='', encoding='utf-8') as lift_usage_csv_file:
usage = {'txid': lift_ticket['txid'],
'usage_time': random_datetime_between(2021, 2024),
'lift_id': fake.random_int(min=1, max=20)}
lift_usage_json_file.write(json.dumps(usage) + '\n')
csv.DictWriter(lift_usage_csv_file, fieldnames=usage.keys()).writerow(usage)
def generate_feedback_data(lift_ticket):
with open(os.path.join(data_dir, 'feedback_data.json'), 'a', encoding='utf-8') as feedback_json_file, \
open(os.path.join(data_dir, 'feedback_data.csv'), 'a', newline='', encoding='utf-8') as feedback_csv_file:
feedback = {'txid': lift_ticket['txid'],
'resort': lift_ticket['resort'],
'feedback_time': random_datetime_between(2021, 2024),
'rating': fake.random_int(min=1, max=5),
'comment': fake.sentence()}
feedback_json_file.write(json.dumps(feedback) + '\n')
csv.DictWriter(feedback_csv_file, fieldnames=feedback.keys()).writerow(feedback)
def generate_incident_reports(lift_ticket):
with open(os.path.join(data_dir, 'incident_reports.json'), 'a', encoding='utf-8') as incident_json_file, \
open(os.path.join(data_dir, 'incident_reports.csv'), 'a', newline='', encoding='utf-8') as incident_csv_file:
incident = {'txid': lift_ticket['txid'],
'incident_time': random_datetime_between(2021, 2024),
'incident_type': fake.word(),
'description': fake.text()}
incident_json_file.write(json.dumps(incident) + '\n')
csv.DictWriter(incident_csv_file, fieldnames=incident.keys()).writerow(incident)
def generate_weather_data(lift_ticket):
with open(os.path.join(data_dir, 'weather_data.json'), 'a', encoding='utf-8') as weather_json_file, \
open(os.path.join(data_dir, 'weather_data.csv'), 'a', newline='', encoding='utf-8') as weather_csv_file:
weather = {'resort': lift_ticket['resort'],
'date': lift_ticket['purchase_time'].split(' ')[0],
'temperature': random.uniform(-10, 10),
'condition': fake.word()}
weather_json_file.write(json.dumps(weather) + '\n')
csv.DictWriter(weather_csv_file, fieldnames=weather.keys()).writerow(weather)
def generate_accommodation_data(lift_ticket):
with open(os.path.join(data_dir, 'accommodation_data.json'), 'a', encoding='utf-8') as accommodation_json_file, \
open(os.path.join(data_dir, 'accommodation_data.csv'), 'a', newline='', encoding='utf-8') as accommodation_csv_file:
accommodation = {'txid': lift_ticket['txid'],
'hotel_name': fake.company(),
'room_type': fake.word(),
'check_in': random_datetime_between(2021, 2024),
'check_out': random_datetime_between(2021, 2024)}
accommodation_json_file.write(json.dumps(accommodation) + '\n')
csv.DictWriter(accommodation_csv_file, fieldnames=accommodation.keys()).writerow(accommodation)
if __name__ == "__main__":
if len(sys.argv) < 2:
print("请提供生成条数的参数。例如:python data_generator.py 100")
sys.exit(1)
total_count = int(sys.argv[1])
os.makedirs(data_dir, exist_ok=True)
with open(os.path.join(data_dir, 'lift_tickets_data.json'), 'w', encoding='utf-8') as json_file, \
open(os.path.join(data_dir, 'lift_tickets_data.csv'), 'w', newline='', encoding='utf-8') as csv_file, \
gzip.open(os.path.join(data_dir, 'lift_tickets_data.json.gz'), 'wt', encoding='utf-8') as json_gzip_file, \
gzip.open(os.path.join(data_dir, 'lift_tickets_data.csv.gz'), 'wt', newline='', encoding='utf-8') as csv_gzip_file:
keys = ['txid', 'rfid', 'resort', 'purchase_time', 'expiration_time', 'days', 'name', 'address_street',
'address_city', 'address_state', 'address_postalcode', 'phone', 'email', 'emergency_contact_name',
'emergency_contact_phone']
dict_writer = csv.DictWriter(csv_file, fieldnames=keys)
dict_writer.writeheader()
gzip_dict_writer = csv.DictWriter(json_gzip_file, fieldnames=keys)
gzip_dict_writer.writeheader()
for _ in range(total_count):
print_lift_ticket(json_file, csv_file, dict_writer)
print_lift_ticket(json_gzip_file, csv_gzip_file, gzip_dict_writer)
要测试此生成器,请在 shell 中运行以下命令:
python ./data_generator.py 1
你应该看到 1 条记录输出,会有两种格式的文件输出:CSV和JSON格式。
为了能够快速为指南的其余部分提供数据,请将数据存储到文件中以供重复使用。
在你的 shell 中运行以下命令:
python ./data_generator.py 100000
你可以将记录的大小增加或减少到你想要的任何数字。这会将示例数据输出到你当前的目录,此文件将在后续步骤中使用,因此请记下你存储此数据的位置并在需要时稍后替换。
你也可以在这里直接访问或者下载 通过“python ./data_generator.py 100000”命令生成的文件。
Postgres和Kafka环境设置
本指南使用Postgres作为数据库数据源。你可以使用已有的Postgres数据库。主要后续的数据库网络地址、数据库名称、Schema名称、用户名密码等保持一致即可。
启动数据库实例
在开始此步骤之前,请确保已为Mac、Windows或Linux安装了 Docker Desktop 。确保你的机器上已安装Docker Compose 。
- 要使用 Docker 启动 PostgreSQL 数据库,你需要创建一个名为docker-compose.yaml的文件。此文件将包含 PostgreSQL 数据库的配置。如果你有另一个容器客户端,请启动容器并使用下面的 PostgreSQL 映像。
- 打开你选择的 IDE(比如VS Code),通过复制并粘贴以下内容来复制并粘贴此文件(你也可以直接下载本文件。):
services:
postgres:
image: "postgres:17"
container_name: "postgres17"
environment:
POSTGRES_DB: 'postgres'
POSTGRES_USER: 'postgres'
POSTGRES_PASSWORD: 'postgres'
ports:
- "5432:5432"
command:
- "postgres"
- "-c"
- "wal_level=logical"
volumes:
- ./postgres-data:/var/lib/postgresql/data
kafka:
image: 'bitnami/kafka:latest'
container_name: kafka
ports:
- "9093:9093"
expose:
- "9093"
environment:
- KAFKA_CREATE_TOPICS="clickzettalakehouserealtimeingest:1:1"
- KAFKA_CFG_AUTO_CREATE_TOPICS_ENABLE=true
- KAFKA_CFG_NODE_ID=0
- KAFKA_CFG_PROCESS_ROLES=controller,broker
- KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CLIENT:PLAINTEXT,EXTERNAL:PLAINTEXT,CONTROLLER:PLAINTEXT
- KAFKA_CFG_LISTENERS=CLIENT://:9092,EXTERNAL://:9093,CONTROLLER://:9094
- KAFKA_CFG_ADVERTISED_LISTENERS=CLIENT://kafka:9092,EXTERNAL://localhost:9093
- KAFKA_INTER_BROKER_LISTENER_NAME=CLIENT
- ALLOW_PLAINTEXT_LISTENER=yes
- KAFKA_CFG_CONTROLLER_QUORUM_VOTERS=0@localhost:9094
- KAFKA_CFG_CONTROLLER_LISTENER_NAMES=CONTROLLER
volumes:
- ./bitnami/kafka:/bitnami/kafka
- 打开终端并导航到docker-compose.yaml文件所在的目录。运行以下命令启动 PostgreSQL 数据库:
docker-compose up -d
创建Kafka Topic
进入 Kafka 容器:
bash
docker exec -it kafka /bin/bash
手动创建主题:
bash
kafka-topics.sh --create --topic clickzetta_lakehouse_realtime_ingest --bootstrap-server localhost:9092 --partitions 1 --replication-factor 1
然后再次列出主题以确认创建是否成功:
bash
kafka-topics.sh --list --bootstrap-server localhost:9092
如果主题成功创建,你应该会看到
clickzetta_lakehouse_realtime_ingest
clickzetta_lakehouse_realtime_ingest
列表中的主题。
连接数据库
要使用 Visual Studio Code 或 DBV/DBGrid/PyCharm 或你选择用于数据库连接的任何 IDE 连接到预配置的数据库,请使用提供的凭据执行以下步骤:
-
打开你选择的工具以连接 PostgreSQL 数据库
- 对于 VSCode,你可以使用PostgreSQL 扩展
- 对于 PyCharm,你可以使用数据库工具和 SQL 插件
-
单击
+
+
符号或类似符号以添加数据源
-
使用这些连接参数:
- 用户:
postgres
postgres
- 密码:
postgres
postgres
- 数据库:
postgres
postgres
- 网址:
jdbc:postgresql://localhost:5432/
jdbc:postgresql://localhost:5432/
-
测试连接并保存
-
为了能让云器Lakehouse Studio通过公网能够访问到Postgres数据库,务必给Posrgres数据库做公网NAT映射。
加载数据
- 在 PostgreSQL 中运行以下postgres脚本来创建模式和表(你也可以直接下载本文件。):
CREATE SCHEMA if not exists ingest_demo;
SET search_path TO ingest_demo;
-- 删除滑雪票数据表
DROP TABLE IF EXISTS lift_tickets_data CASCADE;
-- 删除滑雪票使用数据表
DROP TABLE IF EXISTS lift_usage_data CASCADE;
-- 删除反馈数据表
DROP TABLE IF EXISTS feedback_data CASCADE;
-- 删除事件报告数据表
DROP TABLE IF EXISTS incident_reports CASCADE;
-- 删除天气数据表
DROP TABLE IF EXISTS weather_data CASCADE;
-- 删除住宿数据表
DROP TABLE IF EXISTS accommodation_data CASCADE;
-- 滑雪票数据表
CREATE TABLE lift_tickets_data (
txid UUID PRIMARY KEY, -- 交易ID,唯一标识每张滑雪票
rfid VARCHAR(24), -- 滑雪票的RFID编号
resort VARCHAR(50), -- 度假村名称
purchase_time TIMESTAMP, -- 购买时间
expiration_time DATE, -- 到期日期
days INTEGER, -- 有效天数
name VARCHAR(100), -- 购票人姓名
address_street VARCHAR(100), -- 街道地址
address_city VARCHAR(50), -- 城市
address_state VARCHAR(50), -- 省份
address_postalcode VARCHAR(20), -- 邮政编码
phone VARCHAR(20), -- 电话号码
email VARCHAR(100), -- 电子邮件
emergency_contact_name VARCHAR(100), -- 紧急联系人姓名
emergency_contact_phone VARCHAR(20) -- 紧急联系人电话号码
);
-- 滑雪票使用数据表
CREATE TABLE lift_usage_data (
txid UUID, -- 交易ID
usage_time TIMESTAMP, -- 使用时间
lift_id INTEGER, -- 升降椅编号
PRIMARY KEY (txid, usage_time) -- 复合主键,唯一标识每次使用记录
);
-- 反馈数据表
CREATE TABLE feedback_data (
txid UUID, -- 交易ID
resort VARCHAR(50), -- 度假村名称
feedback_time TIMESTAMP, -- 反馈时间
rating INTEGER, -- 评分
comment TEXT, -- 评论内容
PRIMARY KEY (txid, feedback_time) -- 复合主键,唯一标识每条反馈记录
);
-- 事件报告数据表
CREATE TABLE incident_reports (
txid UUID, -- 交易ID
incident_time TIMESTAMP, -- 事件时间
incident_type VARCHAR(50), -- 事件类型
description TEXT, -- 事件描述
PRIMARY KEY (txid, incident_time) -- 复合主键,唯一标识每条事件记录
);
-- 天气数据表
CREATE TABLE weather_data (
resort VARCHAR(50), -- 度假村名称
date DATE, -- 日期
temperature FLOAT, -- 温度
condition VARCHAR(50), -- 天气状况
PRIMARY KEY (resort, date) -- 复合主键,唯一标识每条天气记录
);
-- 住宿数据表
CREATE TABLE accommodation_data (
txid UUID, -- 交易ID
hotel_name VARCHAR(100), -- 酒店名称
room_type VARCHAR(50), -- 房间类型
check_in TIMESTAMP, -- 入住时间
check_out TIMESTAMP, -- 退房时间
PRIMARY KEY (txid, check_in) -- 复合主键,唯一标识每条住宿记录
);
- 将以下代码Copy进Python文件然后运行
- 在电脑上打开VS Code,创建一个名为 import_csv_into_pg.py 的文件,并将以下代码复制到import_csv_into_pg.py文件中。lift_tickets_data.csv文件为在“测试数据生成”步骤生成的gz文件解压后的文件。(你也可以直接下载本文件。)
import psycopg2
import os
def load_csv_to_postgres(csv_file, table_name):
with open(csv_file, 'r') as f:
cur.copy_expert(f"COPY {table_name} FROM STDIN WITH CSV HEADER DELIMITER ','", f)
conn.commit()
数据库连接信息:
conn = psycopg2.connect(
dbname="postgres",
user="postgres",
password="postgres",
host="localhost",
port="5432"
)
cur = conn.cursor()
设置 search_path:
cur.execute("SET search_path TO ingest_demo;")
Clear all data from the lift_tickets_data table:
cur.execute("TRUNCATE lift_tickets_data;"):
定义CSV文件所在目录:
csv_directory = 'data'
按表的依赖关系排列的CSV文件列表:
csv_files = [
"lift_tickets_data.csv", # 首先导入被依赖的表
"weather_data.csv",
"lift_usage_data.csv",
"feedback_data.csv",
"incident_reports.csv",
"accommodation_data.csv"
]
遍历文件列表并加载到对应的表中:
for filename in csv_files:
csv_file = os.path.join(csv_directory, filename)
table_name = os.path.splitext(filename)[0] # 文件名去掉扩展名作为表名
print(f"Loading {csv_file} into table {table_name}...")
load_csv_to_postgres(csv_file, table_name)
print(f"Loaded {csv_file} into table {table_name} successfully!")
Execute the SELECT query to count the rows in the table:
cur.execute("SELECT count(*) FROM lift_tickets_data;")
count = cur.fetchone()[0]
Print the result:
print(f"Total number of records in lift_tickets_data: {count}")
关闭游标和连接:
cur.close()
conn.close()
在VS Code里新建一个“终端”,并运行如下命令激活在“环境设置”步骤创建的Python环境。如果已在cz-ingest-examples环境里,请跳过。
conda activate cz-ingest-examples
然后在同一终端里运行如下命令:
python import_csv_into_pg.py
输出显示如下,则表示数据导入成功:
Total number of records in lift_tickets_data: 100000
云器Lakehouse设置
概述
你将使用云器Lakehouse Studio 基于WEB界面操作来执行如下操作。
导航到开发->任务,单击
+
+
以创建新工作目录和工作表任务,然后选择SQL 工作表
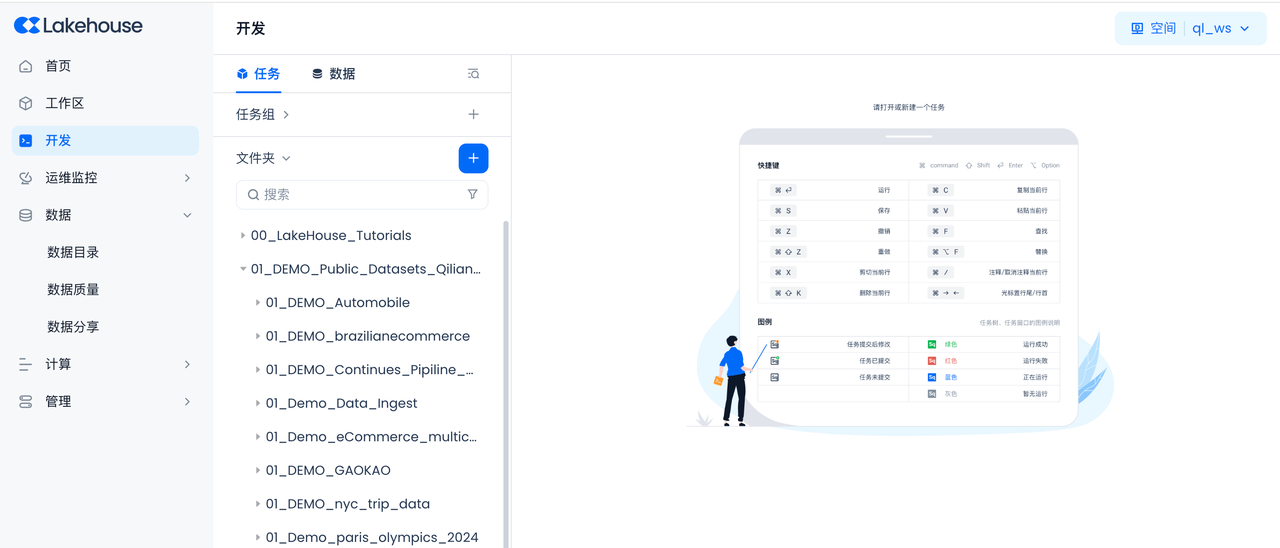
创建工作目录,用来存放本项目所有的任务和代码。工作目录名:01_Demo_Data_Ingest
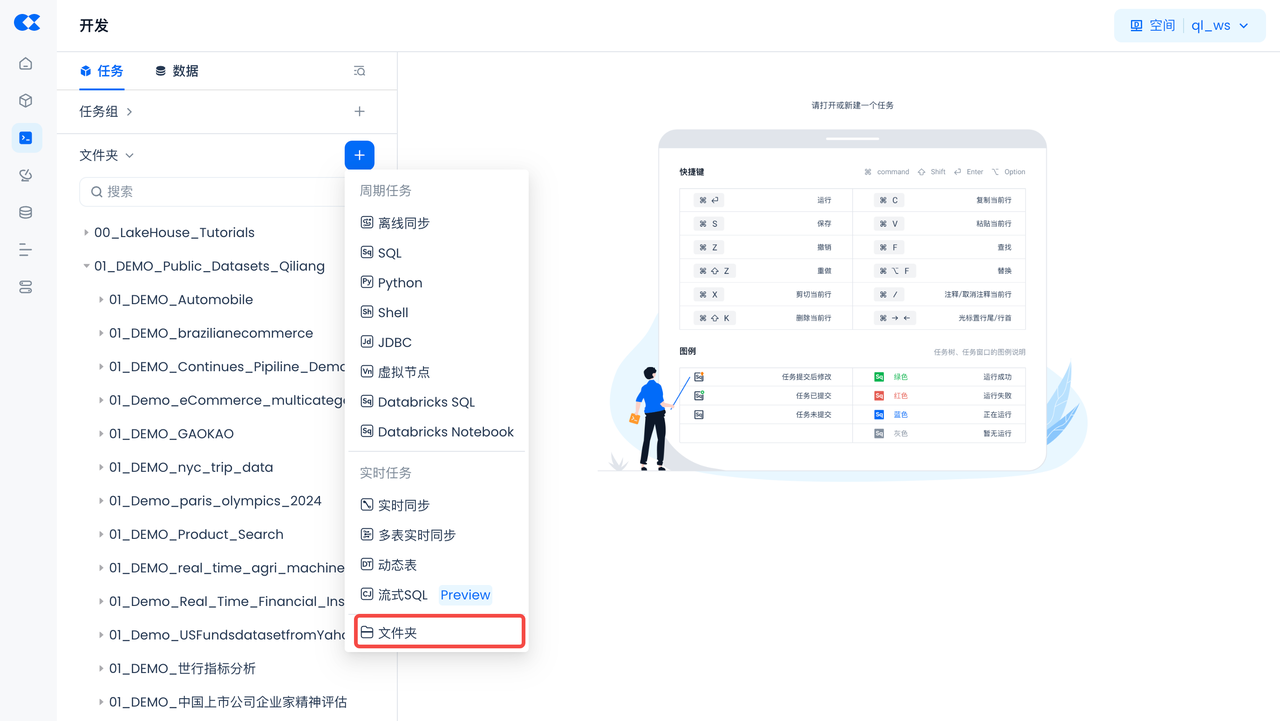
创建第一个任务,类型选择SQL。工作目录任务名:01_构建环境
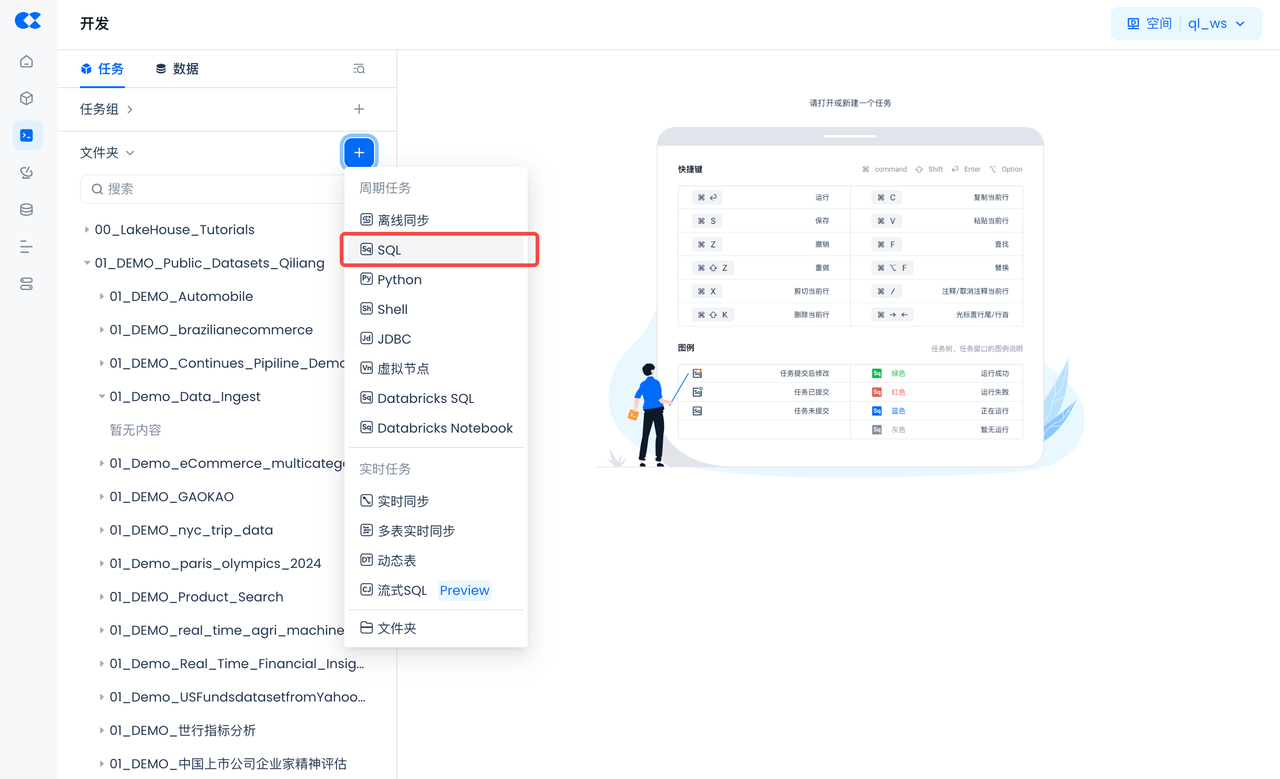
创建虚拟计算集群和Schema、外部Volume
在你的 云器Lakehouse 帐户中创建一个名为 INGEST 的Schema和虚拟计算集群。
复制并粘贴以下SQL脚本以创建云器Lakehouse对象(虚拟计算集群、数据库Schema),然后单击工作表顶部的“运行”(你也可以直接下载本文件。)
-- data ingest virtual cluster
CREATE VCLUSTER IF NOT EXISTS INGEST
VCLUSTER_SIZE = XSMALL
VCLUSTER_TYPE = ANALYTICS
AUTO_SUSPEND_IN_SECOND = 60
AUTO_RESUME = TRUE
COMMENT 'data ingest VCLUSTER for test';
CREATE VCLUSTER IF NOT EXISTS INGEST_VC
VCLUSTER_SIZE = XSMALL
VCLUSTER_TYPE = ANALYTICS
AUTO_SUSPEND_IN_SECOND = 60
AUTO_RESUME = TRUE
COMMENT 'data ingest VCLUSTER for batch/real time ingestion job';
-- Use our VCLUSTER
USE VCLUSTER INGEST;
-- Create and Use SCHEMA
CREATE SCHEMA IF NOT EXISTS INGEST;
USE SCHEMA INGEST;
--external data lake
--创建数据湖Connection,到数据湖的连接
CREATE STORAGE CONNECTION if not exists hz_ingestion_demo
TYPE oss
ENDPOINT = 'oss-cn-hangzhou-internal.aliyuncs.com'
access_id = '请输入你的access_id'
access_key = '请输入你的access_key'
comments = 'hangzhou oss private endpoint for ingest demo'
--创建Volume,数据湖存储文件的位置
CREATE EXTERNAL VOLUME if not exists ingest_demo
LOCATION 'oss://YOUR_BUCKET_NAME/YOUR_VOLUME_PATH'
USING connection hz_ingestion_demo -- storage Connection
DIRECTORY = (
enable = TRUE
)
recursive = TRUE
--同步数据湖Volume的目录到Lakehouse
ALTER volume ingest_demo refresh;
--查看云器Lakehouse数据湖Volume上的文件
SELECT * from directory(volume ingest_demo);
创建JSON文件保存云器Lakehouse的登录信息
通过VS Code等IDE工具,创建一个JSON文件,并保存在你的工作目录下,命名为config-inges.json。(你也可以直接下载本文件,下载后修改为config-ingestjson并输入登录认证信息。)
其中config-ingest.json文件中保存了你的账号登录云器Lakehouse的信息:
{
"username": "请输入你的用户名",
"password": "请输入你的密码",
"service": "请输入你的服务地址,例如 region_id.api.clickzetta.com",
"instance": "请输入你的实例 ID",
"workspace": "请输入你的工作空间,例如 gharchive",
"schema": "请输入你的模式,例如 public",
"vcluster": "请输入你的虚拟集群,例如 DEFAULT_AP",
"sdk_job_timeout": 10,
"hints": {
"sdk.job.timeout": 3,
"query_tag": "a_comprehensive_guide_to_ingesting_data_into_clickzetta"
}
}
创建数据库源
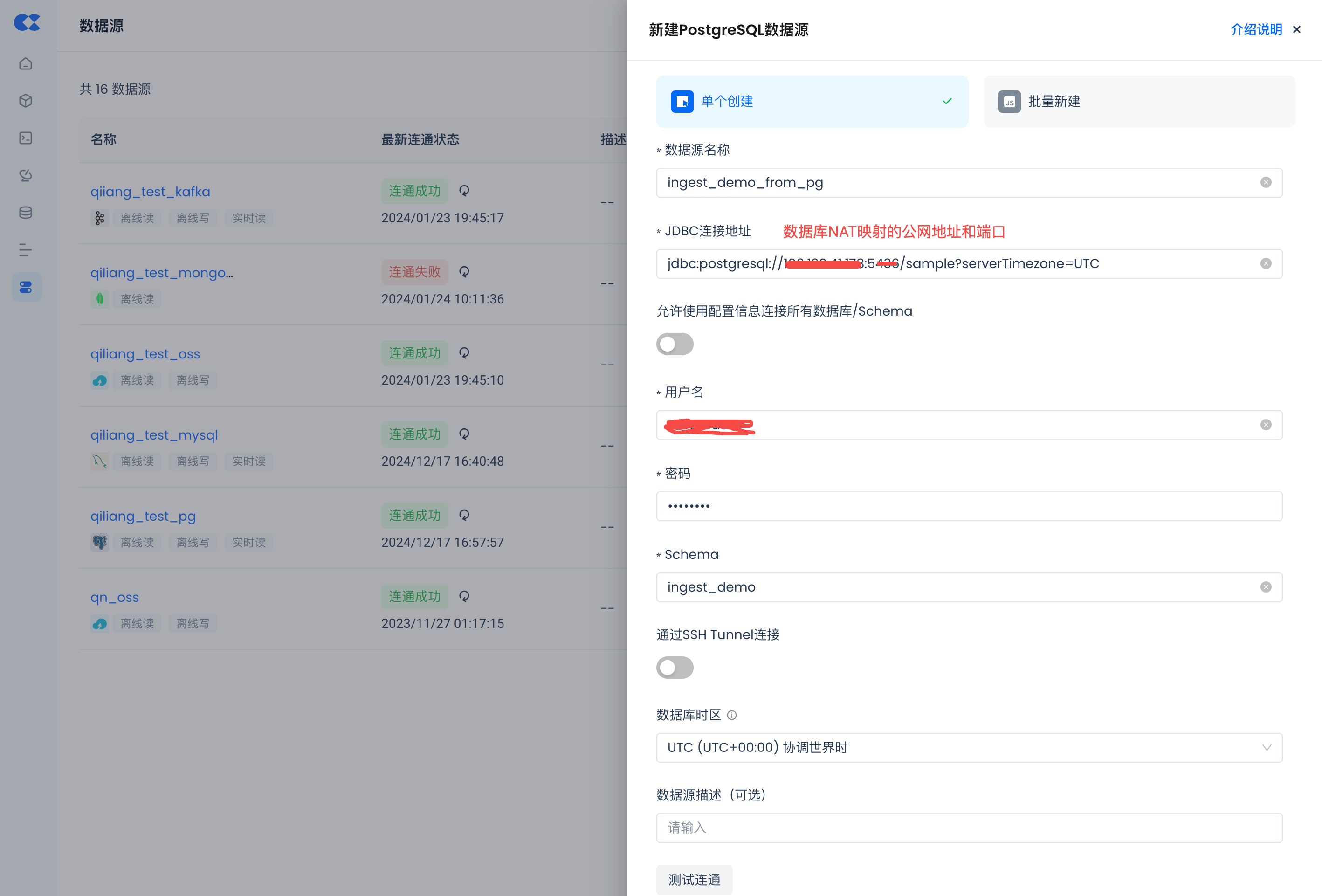
创建Postgres数据源
导航到管理->数据源,单击“新建数据源”并选择Postgres以创建Postgres数据源,使得Postgres能被云器Lakehouse可访问。
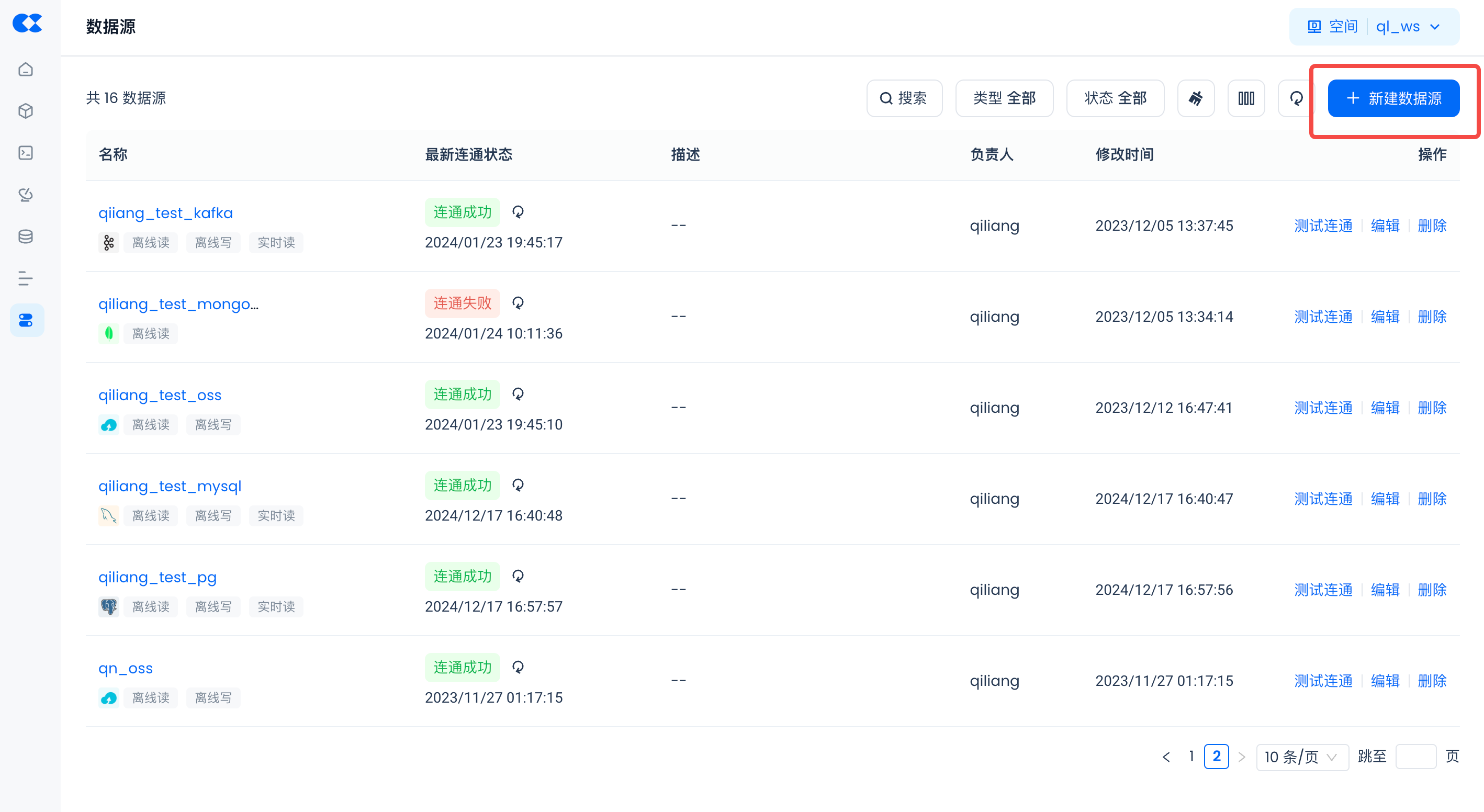
- 数据源名称:ingest_demo_from_pg
- 连接参数:同数据库可环境设置里的环境连接参数。
- 请注意务必配置正确的数据库所在的时区,避免数据同步失败。
环境创建好后就可以使用了
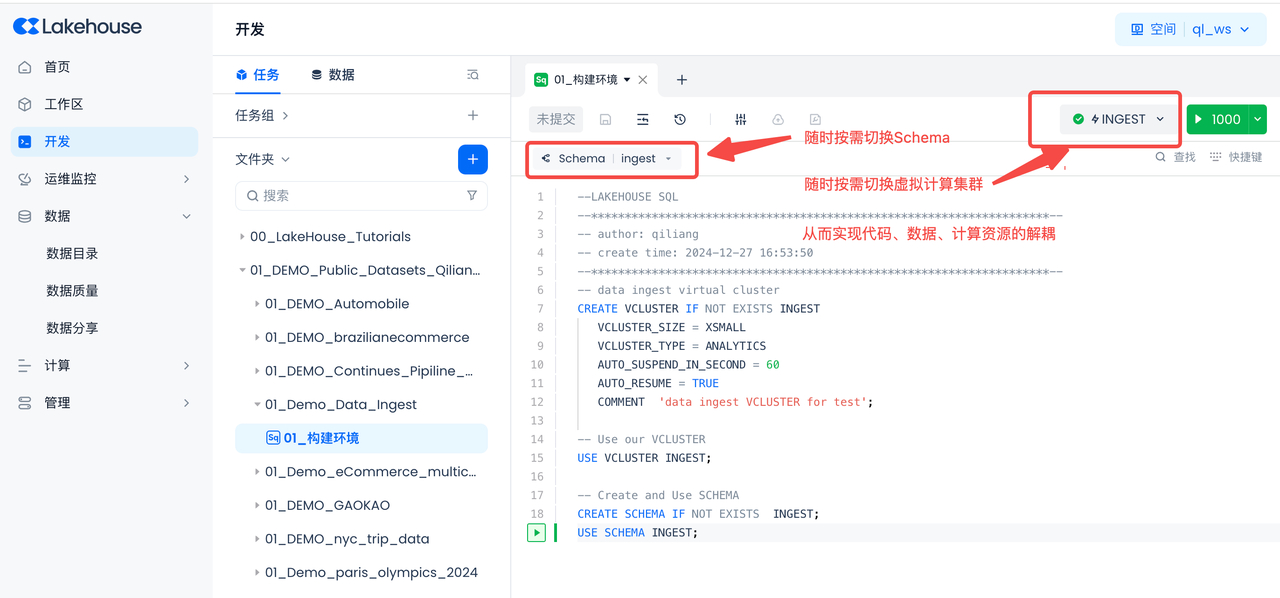
测试连通,提示成功则表示配置成功了。
