
将数据导入云器Lakehouse的完整指南
数据入仓:通过云器Lakehouse Studio 批量加载(公网连接)
概述
使用场景
已有数据源(包括数据库、数据仓库)具备公网可访问的地址(比如做了公网NAT映射),单表数据量大,且要求同步成本低,对数据新鲜度要求低(往往是小时级别甚至天级别)的情况下,将数据从数据源的表同步到Lakehouse的表中。
实现步骤
导航到开发->任务,点击“+”,选择“离线同步”,新建一个“离线同步”作业。
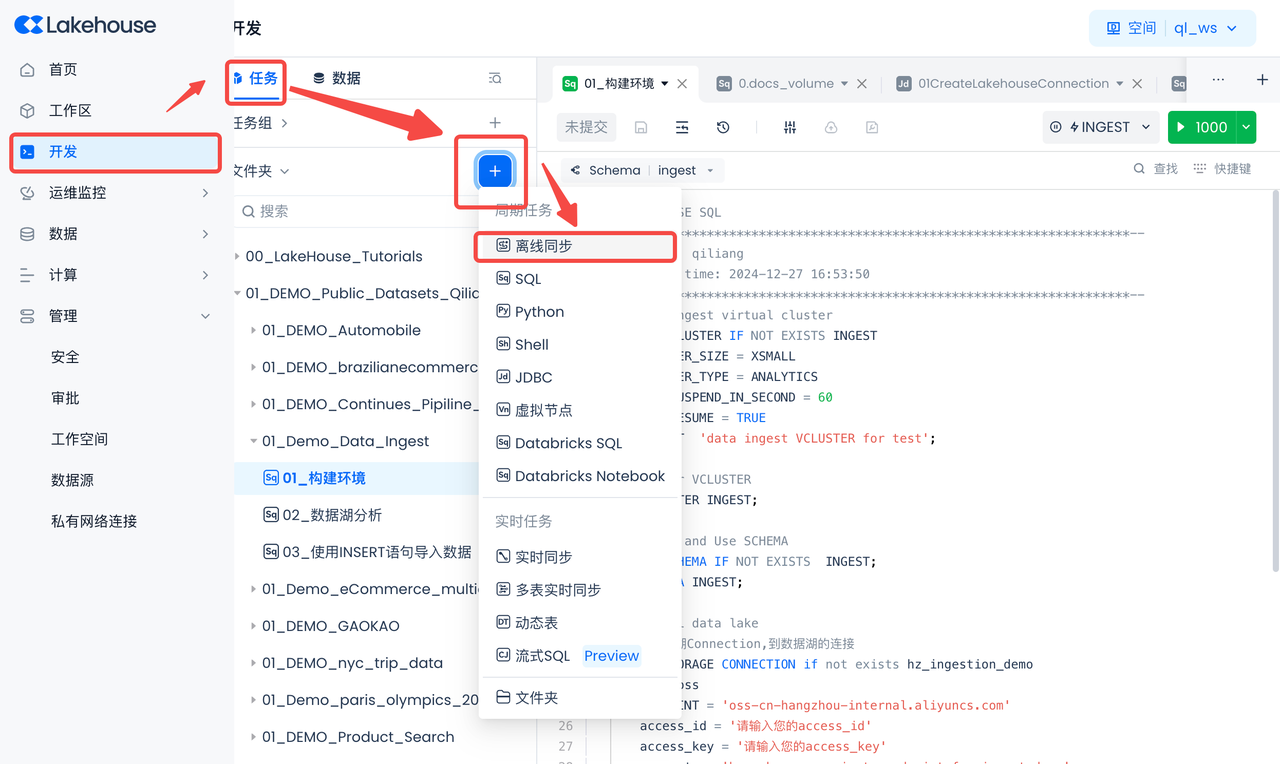
其它参数配置如下:
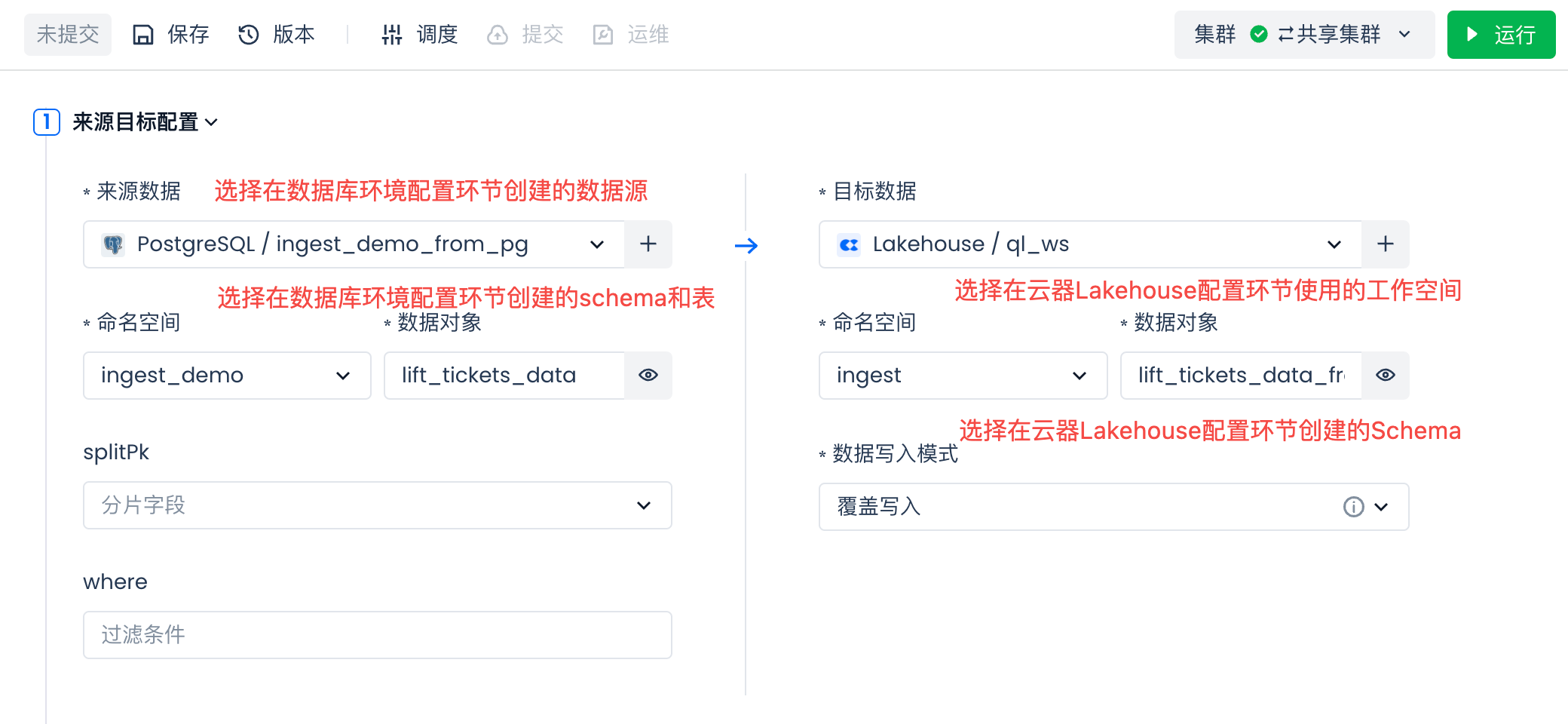
然后选择新建数据表:lift_tickets_data_from_pg_batch。
在"新建数据表"SQL代码里,将表名改为"lift_tickets_data_from_pg_batch"。
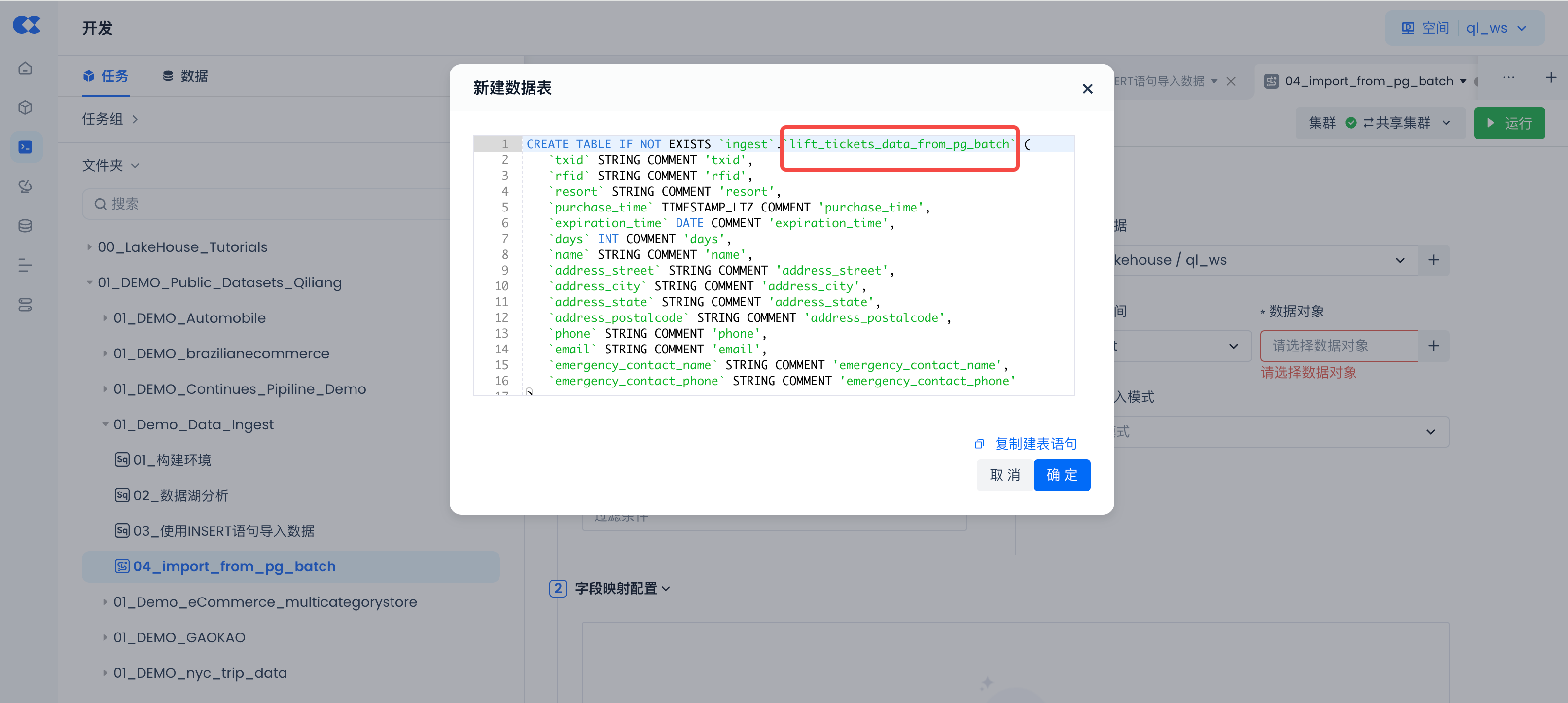
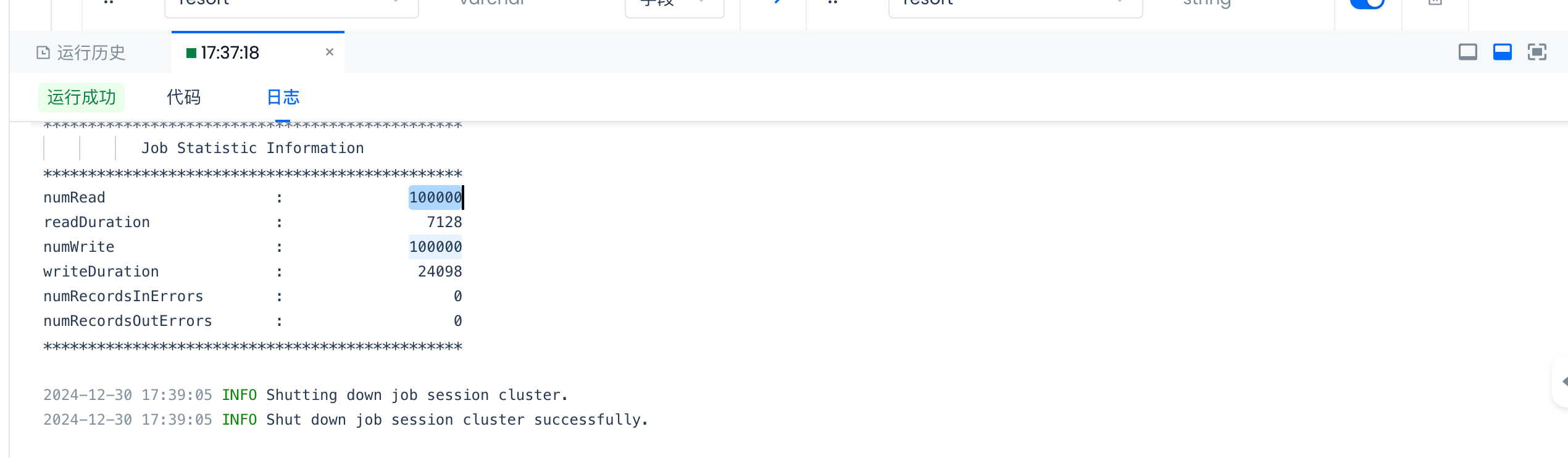
检查字段映射是否符合预期,然后测试运行同步任务:
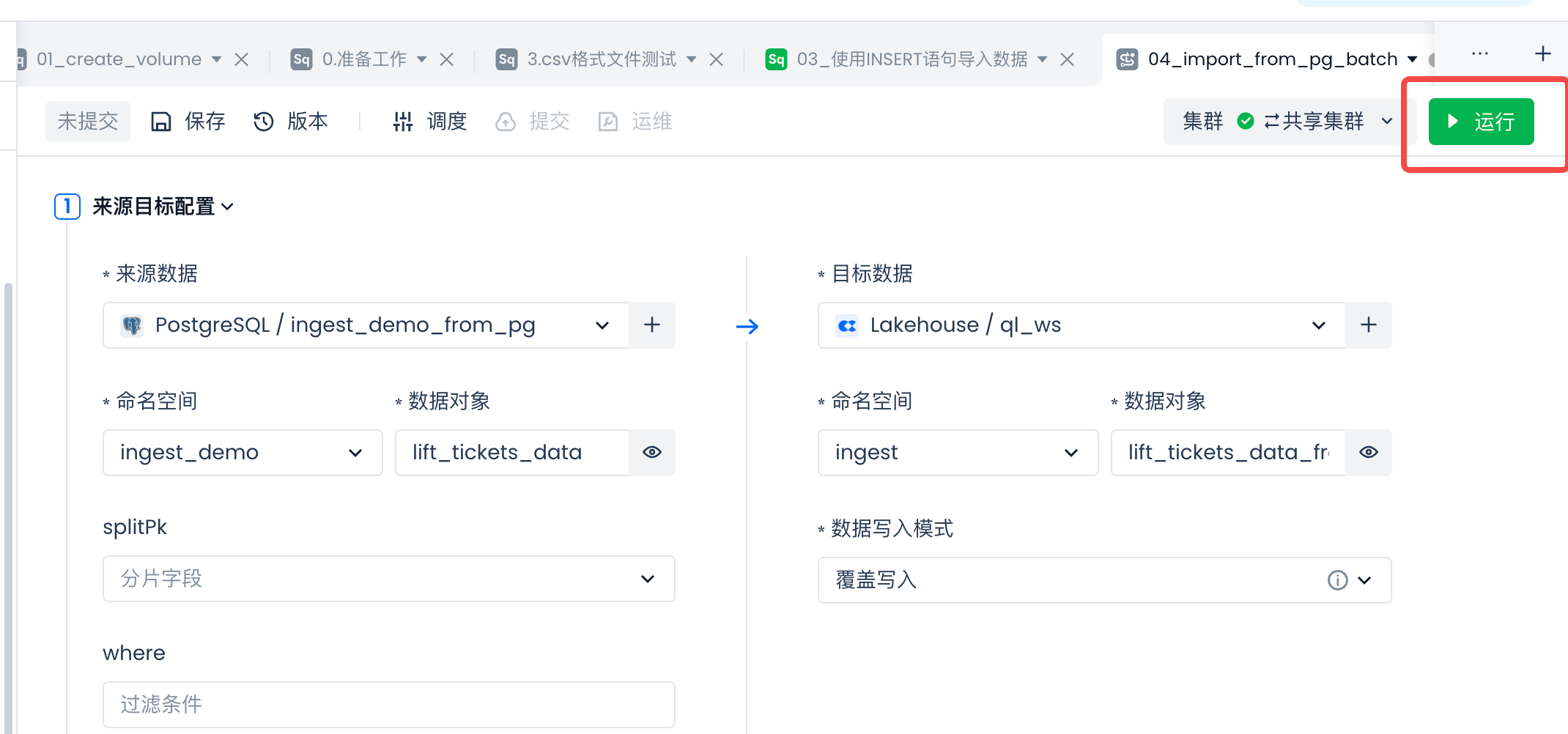
检查测试结果:
查看测试任务的日志,检查numWrite的数量和源表的数据行数一致。
下一步建议
-
配置where条件,设置每次运行需要同步的数据,而不是全量。一般是基于时间字段的过滤。
-
配置调度参数并提交、运维,周期性同步数据。
- 如果是适合数据量小的维表数据,则无需设置where条件,将数据写入模式设置为"覆盖写入",每次都进行全量覆盖。
- 如果是数据量大的事实表数据,需要设置where条件,将数据写入模式设置为“追加写入”,每次都进行增量追加写入,以降低每次的同步数据量和同步成本。避免每次都全量同步带来的高成本。
-
离线同步任务作为数据ELT的数据抽取(E)和加载(L)的开始,可以进一步通过SQL任务对加载进数仓的数据进行清洗和转化(T)。
资料
联系我们