将数据导入云器 Lakehouse 的完整指南
数据入仓:通过云器 Lakehouse Studio 多表实时同步(CDC,公网连接)
概述
使用场景
已有数据源(包括数据库、数据仓库)具备公网可访问的地址(比如做了公网 NAT 映射),需要多表同时同步,对数据新鲜度要求高(往往是分钟级别甚至秒级别),并且能够接受较高的同步成本的情况下,将数据从数据源的表同步到 Lakehouse 的表中。
云器 Lakehouse Studio 多表实时同步支持多表合并,可以将结构相似的多个源表的数据合并到一张云器 Lakehouse 目标表中。
实现步骤
新建多表实时同步任务
导航到 开发 -> 任务,点击“+”,选择“多表实时同步”,新建一个多表实时同步任务。
任务名:06_multi_table_rt_sync_from_pg
来源数据选择“PostgreSQL”
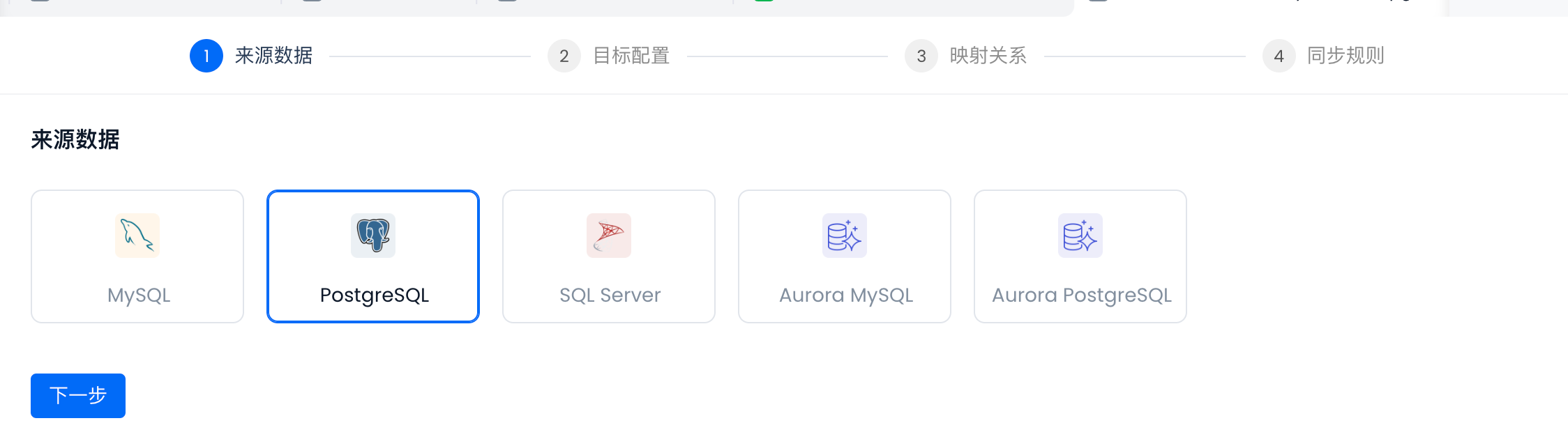
选择同步对象
云器 Lakehouse Studio 会自动同步源库结构供选择:
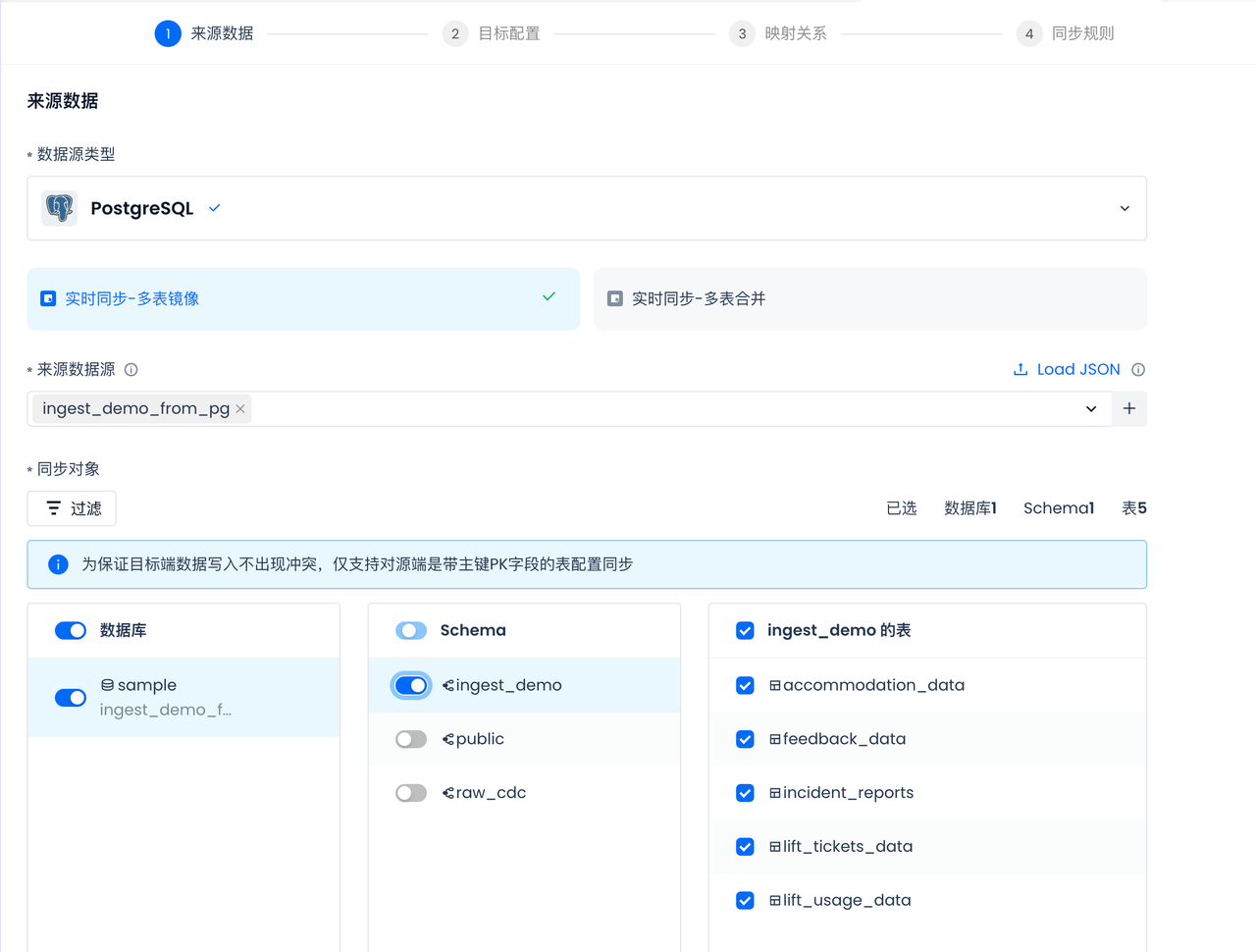
数据库CDC配置
创建一个 Slot
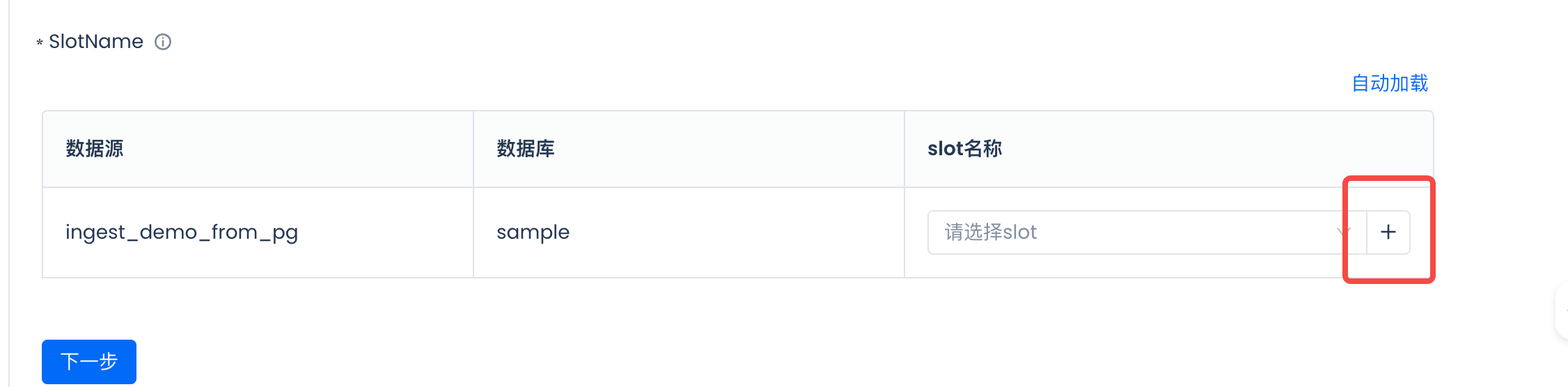
插件类型:pgoutput
Slot名:slot_for_multi_table_ingest_demo
目标配置
规则表达式:multitable_sync_{SOURCE_TABLE}。给目标表加上前缀 multitable_sync_{SOURCE_TABLE},以区分和其它方式同步进来的表。
查看字段映射,确保所有字段都映射成功:
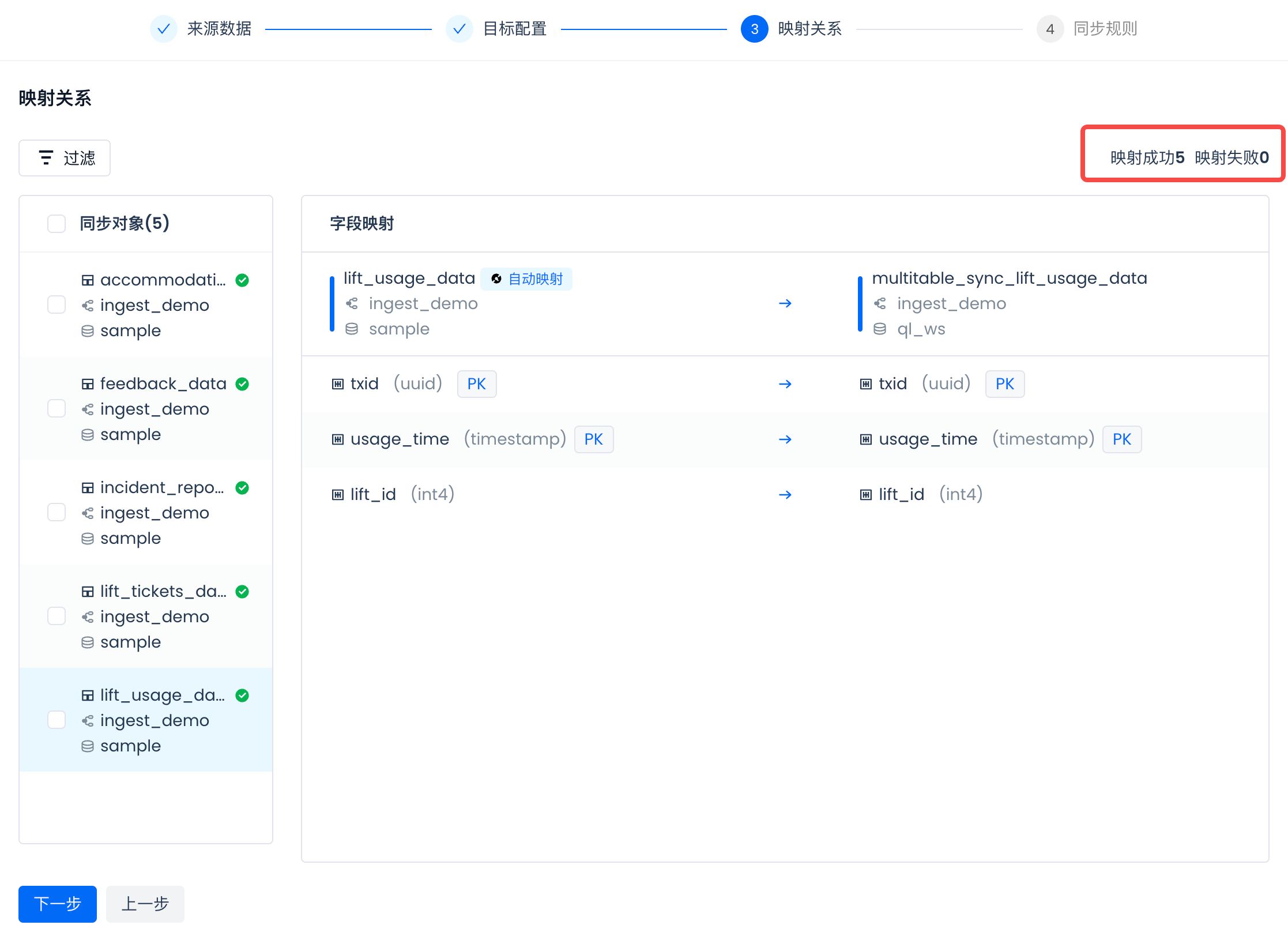
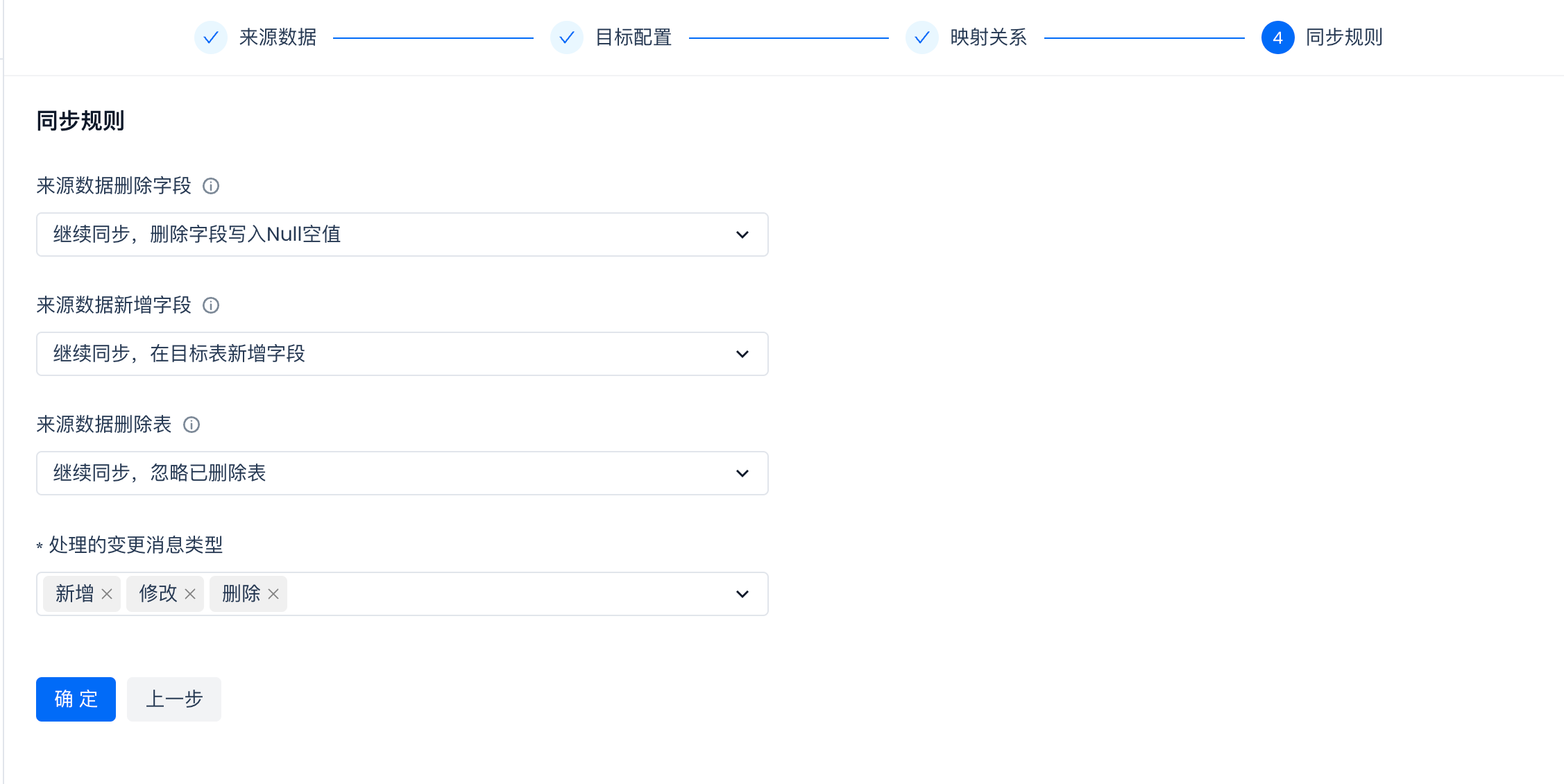
配置同步规则
提交
配置完成后,提交多表实时同步任务:

运维
运维多表实时同步任务:
启动
启动多表实时同步任务:

第一次启动该多表实时同步任务时,选择“无状态启动”和“全量数据同步”:
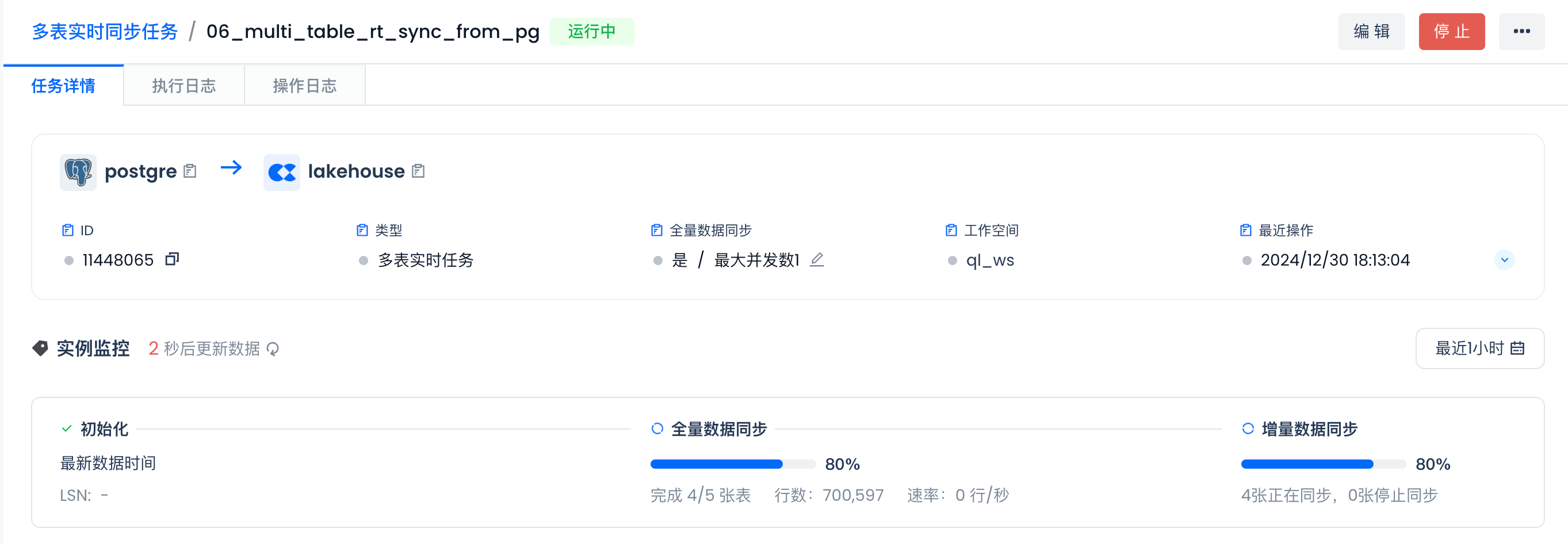
启动后即可查看任务运行的详细情况。等待全量同步完成后,系统会自动开始进行增量实时同步。
进度查看
全量同步进行中:
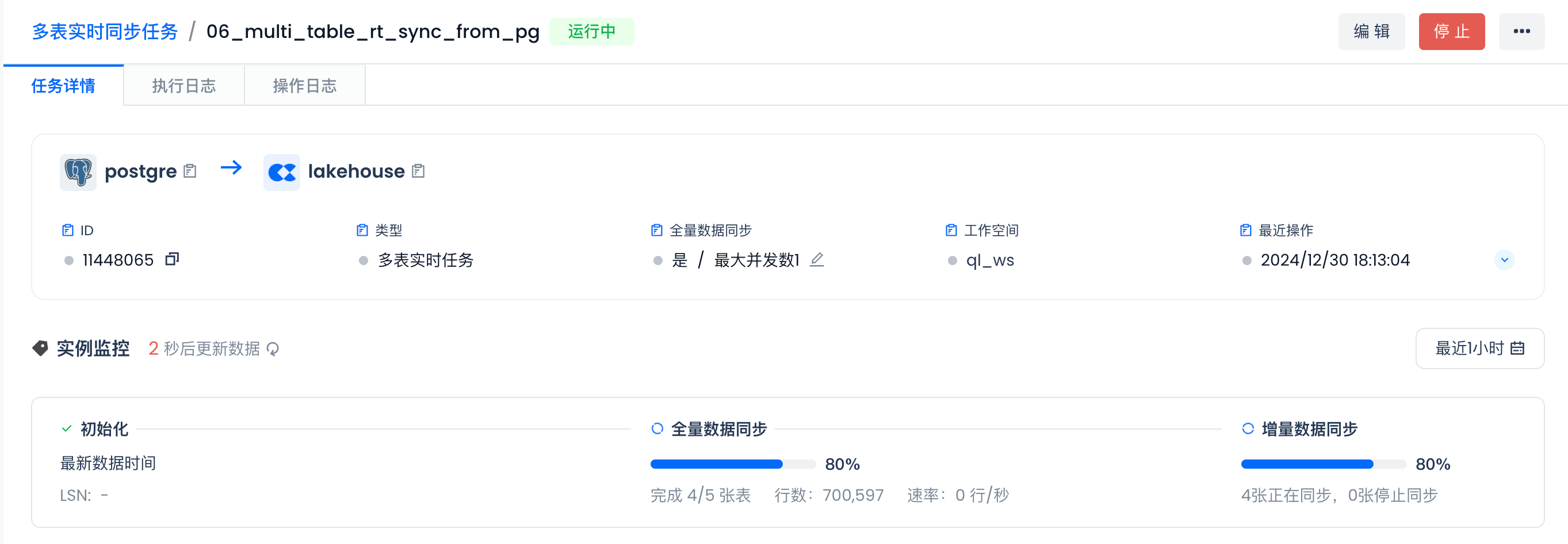
全量同步完成。
开始进行实时同步:
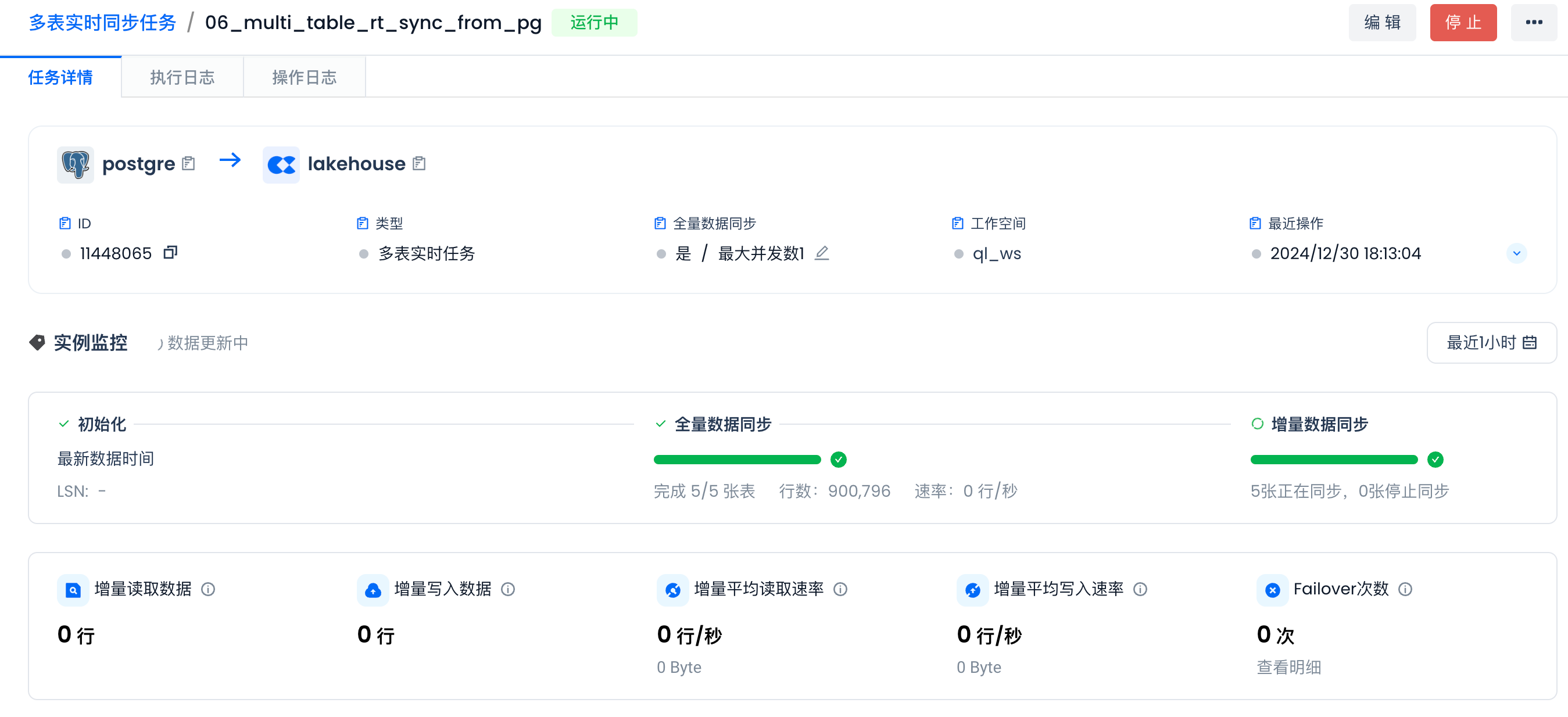
增量实时同步
往 PG 数据库插入增量数据,进行增量实时同步。在 VS Code 里新建一个文件“rt_data_generate_insert_into_pg.py”,将如下代码复制进去:
import os
import sys
import rapidjson as json
import optional_faker as _
import uuid
import random
import time
import psycopg2
from faker import Faker
from datetime import date, datetime, timedelta
from dotenv import load_dotenv
load_dotenv()
fake = Faker('zh_CN') # 使用中文区域
resorts = ["大董烤鸭", "京雅堂", "新荣记", "仿膳饭庄", "全聚德",
"利群烤鸭店", "鼎泰丰", "海底捞", "江苏会所", "店客店来",
"周黑鸭", "夜上海", "香宫", "长安壹号", "翡翠餐厅", "北京饭店",
"四川豆花饭庄", "海底捞火锅", "川办餐厅", "南门火锅",
"胡同", "翠园", "利苑酒家", "御宝轩", "金鼎轩",
"外婆家", "大董", "顺峰海鲜酒家", "小龙坎火锅",
"新大陆中餐厅", "京兆尹", "鼎泰丰(台湾)", "滇池来客",
"绿波廊", "南美时光"]
Load database credentials from environment variables:
DB_NAME = 'postgres'
DB_USER = 'postgres'
DB_PASSWORD = 'postgres'
DB_HOST = 'localhost'
DB_PORT = '5432'
def connect_db():
conn = psycopg2.connect(
dbname=DB_NAME,
user=DB_USER,
password=DB_PASSWORD,
host=DB_HOST,
port=DB_PORT
)
return conn
def random_date_in_2025():
start_date = date(2025, 1, 1)
end_date = date(2025, 12, 31)
return start_date + timedelta(days=random.randint(0, (end_date - start_date).days))
def random_datetime_between(start_year, end_year):
start_datetime = datetime(start_year, 1, 1)
end_datetime = datetime(end_year, 12, 31, 23, 59, 59)
random_seconds = random.randint(0, int((end_datetime - start_datetime).total_seconds()))
return start_datetime + timedelta(seconds=random_seconds)
def insert_lift_ticket(cursor, lift_ticket):
cursor.execute("""
INSERT INTO ingest_demo.lift_tickets_data (txid, rfid, resort, purchase_time, expiration_time, days, name, address_street, address_city, address_state, address_postalcode, phone, email, emergency_contact_name, emergency_contact_phone)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
""", (
lift_ticket['txid'], lift_ticket['rfid'], lift_ticket['resort'],
lift_ticket['purchase_time'], lift_ticket['expiration_time'],
lift_ticket['days'], lift_ticket['name'], lift_ticket['address_street'],
lift_ticket['address_city'], lift_ticket['address_state'],
lift_ticket['address_postalcode'], lift_ticket['phone'],
lift_ticket['email'], lift_ticket['emergency_contact_name'],
lift_ticket['emergency_contact_phone']
))
def generate_lift_ticket():
global resorts, fake
lift_ticket = {
'txid': str(uuid.uuid4()),
'rfid': hex(random.getrandbits(96)),
'resort': fake.random_element(elements=resorts),
'purchase_time': random_datetime_between(2021, 2024),
'expiration_time': random_date_in_2025(),
'days': fake.random_int(min=1, max=7),
'name': fake.name(),
'address_street': fake.street_address(),
'address_city': fake.city(),
'address_state': fake.province(),
'address_postalcode': fake.postcode(),
'phone': fake.phone_number(),
'email': fake.email(),
'emergency_contact_name': fake.name(),
'emergency_contact_phone': fake.phone_number(),
}
return lift_ticket
def main(total_count, batch_size, sleep_time):
conn = connect_db()
cursor = conn.cursor()
batch_data = []
for _ in range(total_count):
lift_ticket = generate_lift_ticket()
batch_data.append(lift_ticket)
if len(batch_data) >= batch_size:
for ticket in batch_data:
insert_lift_ticket(cursor, ticket)
conn.commit()
batch_data = []
time.sleep(sleep_time)
# Insert any remaining data
if batch_data:
for ticket in batch_data:
insert_lift_ticket(cursor, ticket)
conn.commit()
cursor.close()
conn.close()
if __name__ == "__main__":
if len(sys.argv) < 4:
print("请提供总行数, 每批次行数, 每批次休眠秒数。例如:python rt_data_generate_insert_into_pg.py 1000 100 10")
sys.exit(1)
total_count = int(sys.argv[1])
batch_size = int(sys.argv[2])
sleep_time = int(sys.argv[3])
main(total_count, batch_size, sleep_time)
在 VS Code 里新建一个“终端”,并运行如下命令激活在“环境设置”步骤创建的 Python 环境。如果已在 cz-ingest-examples 环境里,请跳过。
conda activate cz-ingest-examples
然后在同一终端里运行如下命令:
将 100000 条数据插入到 ingest_demo.lift_tickets_data 表中,每次插入 100 行,每批次休眠 10 秒。
python rt_data_generate_insert_into_pg.py 100000 100 10
在云器 Lakehouse Studio 查看实时同步进展:
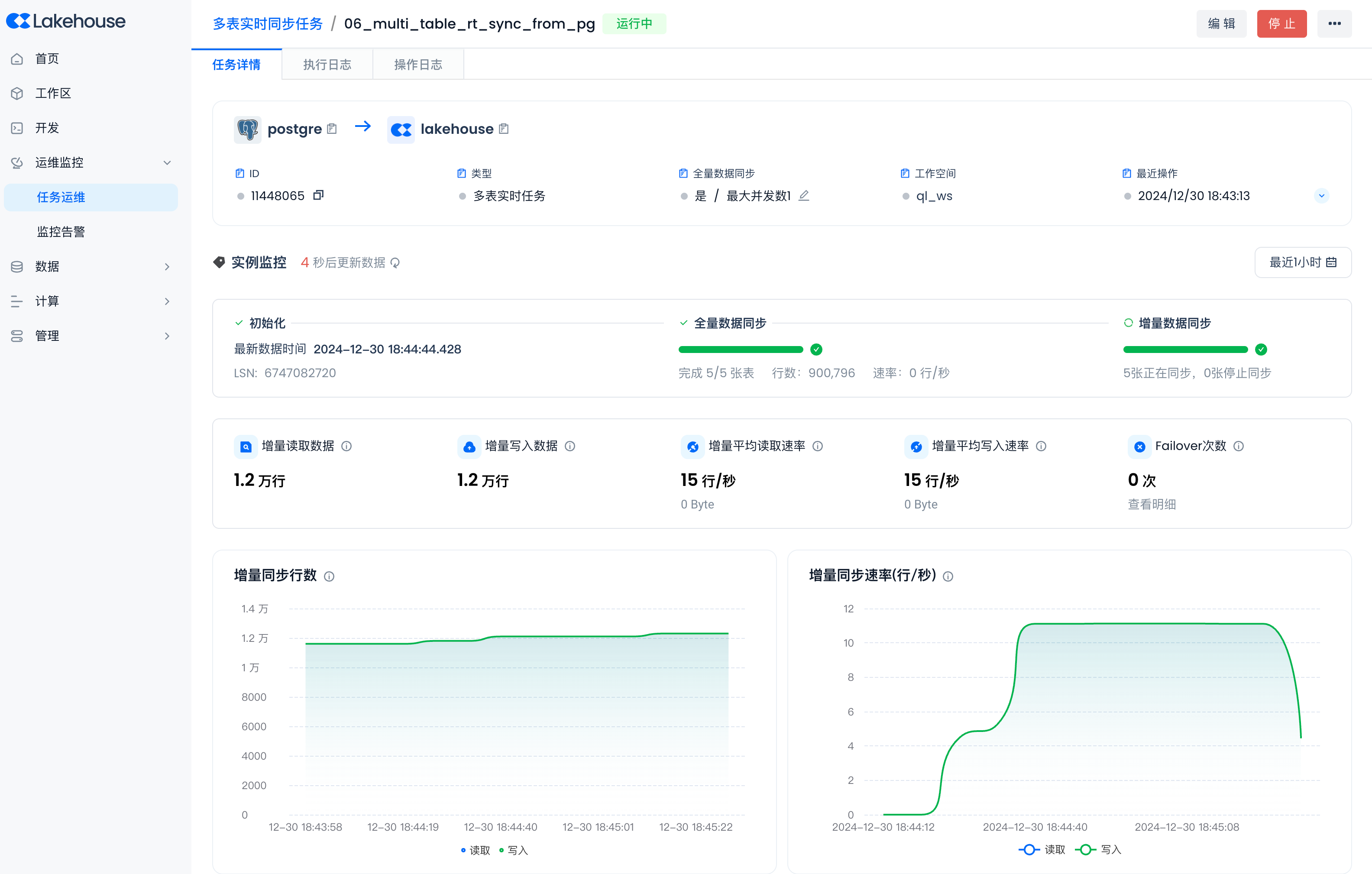
下一步建议
在数据源中插入新数据,查看增量同步的结果。
“停止”该同步任务。运行该任务的虚拟计算集群设置了自动停止,会在作业停止后的设定时间(秒数)内停止运行,从而节省费用,实现按需运行。
资料
实时写入数据
多表实时同步
通过云器Lakehouse的多表实时同步和动态表实现变化数据捕获(CDC)及数据处理
