
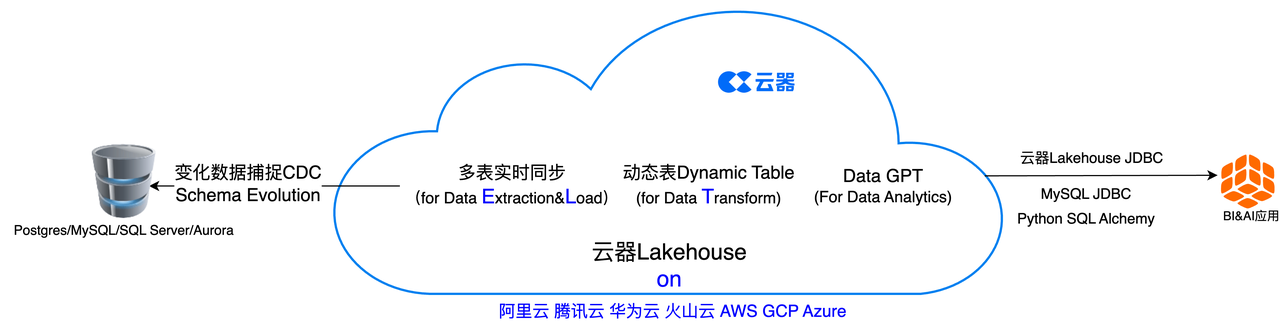
通过云器Lakehouse的多表实时同步和动态表实现变化数据捕获(CDC)及数据处理
概要介绍
在本快速入门中,我们将研究如何使用存储在 PostgreSQL 数据库中的客户交易数据,通过云器Lakehouse的多表实时同步将数据导入云器Lakehouse的表中,通过动态表进行实时数据处理,并进一步通过云器Lakehouse自带的DataGPT进行可视化数据探索和对话式数据分析,从而实现从数据摄取、数据处理和数据分析的实时全链路,以此来了解客户交易进行洞察分析。
从ELT的角度来看,云器Lakehouse的多表实时同步实现了基于CDC的数据抽取(Data Extraction)和加载(Load),并且在该过程中实现了模式演进(Schema Evolution),也就是同步内容会包括源数据库的结构或模式(Schema)的变化。动态表Dynamic Table则以全新的方式实现了数据转换(Data Transform)。
:-: 
环境准备:
-
本地机器上安装的Docker
-
可用于连接 PostgreSQL 数据库的工具
- 例如 Visual Studio Code 或 DBV/DBGrid,以及Python代码等
-
熟悉基本的 Python 和 SQL
-
熟悉数据科学Notebook的使用
-
现有的云器账号,或者前往云器科技注册页面并注册一个免费帐户。注册后,您可以直接登录云器Lakehouse Web控制台。
云器Lakehouse环境
概述
您将使用云器Lakehouse Studio(云器Lakehouse的Web界面来创建云器Lakehouse的对象(虚拟计算集群、空间/数据库、模式、数据库Schema、用户等)。
创建对象并加载数据
- 导航到开发->任务,单击
+以创建新工作目录和工作表任务,然后选择SQL 工作表
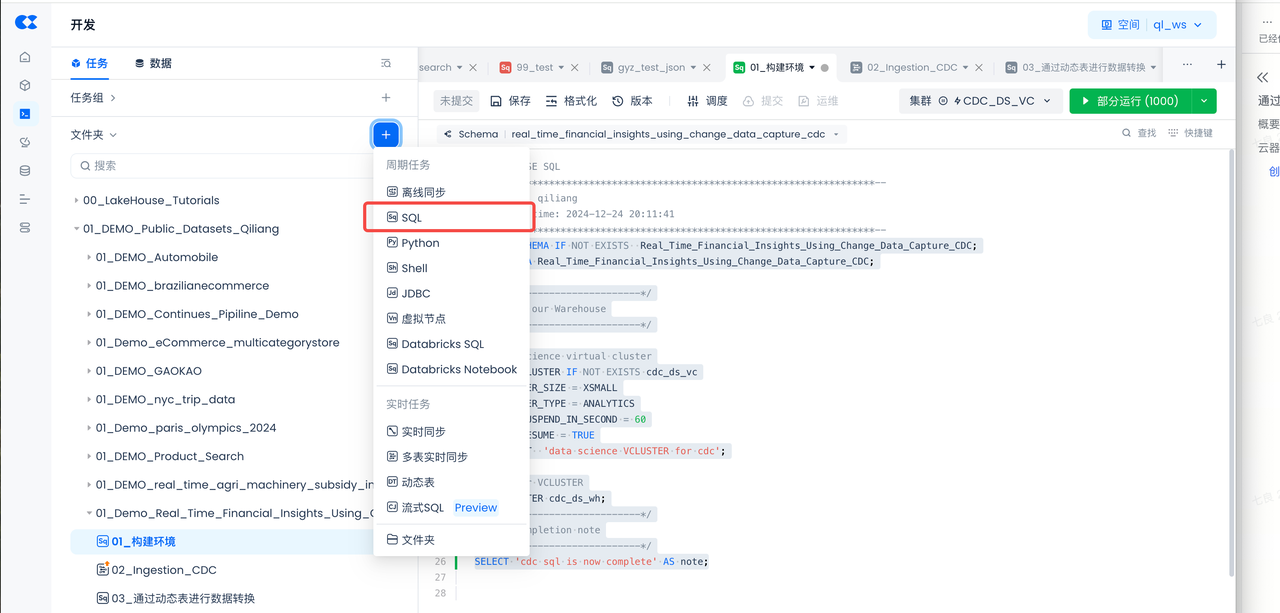
- 工作目录名:01_Demo_Real_Time_Financial_Insights_Using_Change_Data_Capture_CDC
- 任务名:01_构建环境
- 复制并粘贴以下SQL脚本以创建云器Lakehouse对象(虚拟计算集群、数据库Schema),然后单击工作表顶部的“运行”
Postgres环境
概述
在本节中,我们将建立一个 PostgreSQL 数据库并创建表来模拟金融公司的客户交易数据。
启动数据库实例
在开始此步骤之前,请确保已为Mac、Windows或Linux安装了 Docker Desktop 。确保您的机器上已安装Docker Compose 。
- 要使用 Docker 启动 PostgreSQL 数据库,您需要创建一个名为docker-compose.yaml的文件。此文件将包含 PostgreSQL 数据库的配置。如果您有另一个容器客户端,请启动容器并使用下面的 PostgreSQL 映像。
- 打开您选择的 IDE(比如VS Code),通过复制并粘贴以下内容来复制并粘贴此文件:
- 打开终端并导航到docker-compose.yaml文件所在的目录。运行以下命令启动 PostgreSQL 数据库:
连接数据库
要使用 Visual Studio Code 或 DBV/DBGrid/PyCharm 或您选择用于数据库连接的任何 IDE 连接到预配置的数据库,请使用提供的凭据执行以下步骤:
-
打开您选择的工具以连接 PostgreSQL 数据库
- 对于 VSCode,你可以使用PostgreSQL 扩展
- 对于 PyCharm,您可以使用数据库工具和 SQL 插件
-
单击
+符号或类似符号以添加数据源 -
使用这些连接参数:
- 用户:
postgres - 密码:
postgres - 网址:
jdbc:postgresql://localhost:5432/
- 用户:
-
测试连接并保存
-
为了能让云器Lakehouse Studio通过公网访问到Postgres数据库,务必给Postgres数据库做公网NAT映射。
加载数据
- 在 PostgreSQL 中运行以下postgres脚本来创建数据库、模式和表:
-
下载这些 csv 文件并将其保存到本地计算机的目录中:
-
Postgres数据加载方式1,通过PG的Copy命令加载
- 在将数据加载到 PostgreSQL 数据库之前,我们需要将文件从本地计算机移动到 Docker 容器。
- 导航到您的终端,使用以下命令获取 Docker 容器 ID:
-
- 要将 CSV 文件复制到容器,请在终端中运行以下命令,将文件路径替换为实际文件路径,并将其替换
container_id为上一个命令中的实际容器 ID: -
- 返回 PostgreSQL 控制台,运行以下 SQL 命令将文件从容器加载到 PostgreSQL 表:
- Postgres数据加载方式2,通过Python脚本加载
将以下代码Copy进Python文件或者Notebook然后运行,也可以直接下载这个Python文件。
- 接下来,确保运行
CREATE PUBLICATION命令以启用模式中表的逻辑复制raw_cdc。这将允许下文的实时同步任务捕获对 PostgreSQL 数据库中表所做的更改:
发布(Publication)是 PostgreSQL 逻辑复制的一部分,它允许用户定义一组表的变更(插入、更新、删除),这些变更将被传送给一个或多个订阅者(Subscribers)。逻辑复制是 CDC 的一种实现方式,它捕获并传播数据库表中的数据变更。换句话说,执行这条语句之后,PostgreSQL 会捕获数据库中所有表的数据变更,并且这些变更可以被订阅者接收和处理。从而实现 CDC 的数据变化记录。
- 最后,通过运行以下 SQL 命令检查表是否已正确加载:
创建并启动云器Lakehouse CDC多表实时同步任务
概述
您将使用云器Lakehouse Studio来基于界面操作、以无代码的方式来创建多表实时同步任务,将数据从Postgres的表加载到云器Lakehouse的表中。
创建Postgres数据源
导航到管理->数据源,单击“新建数据源”并选择Postgres以创建Postgres数据源,使得Postgres能被云器Lakehouse可访问。
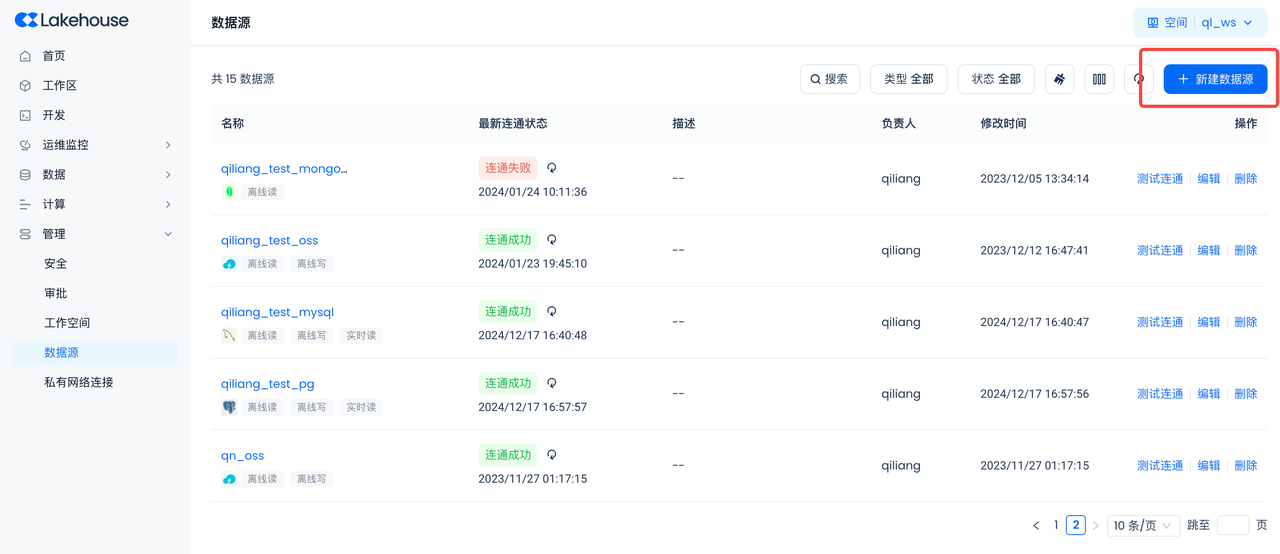
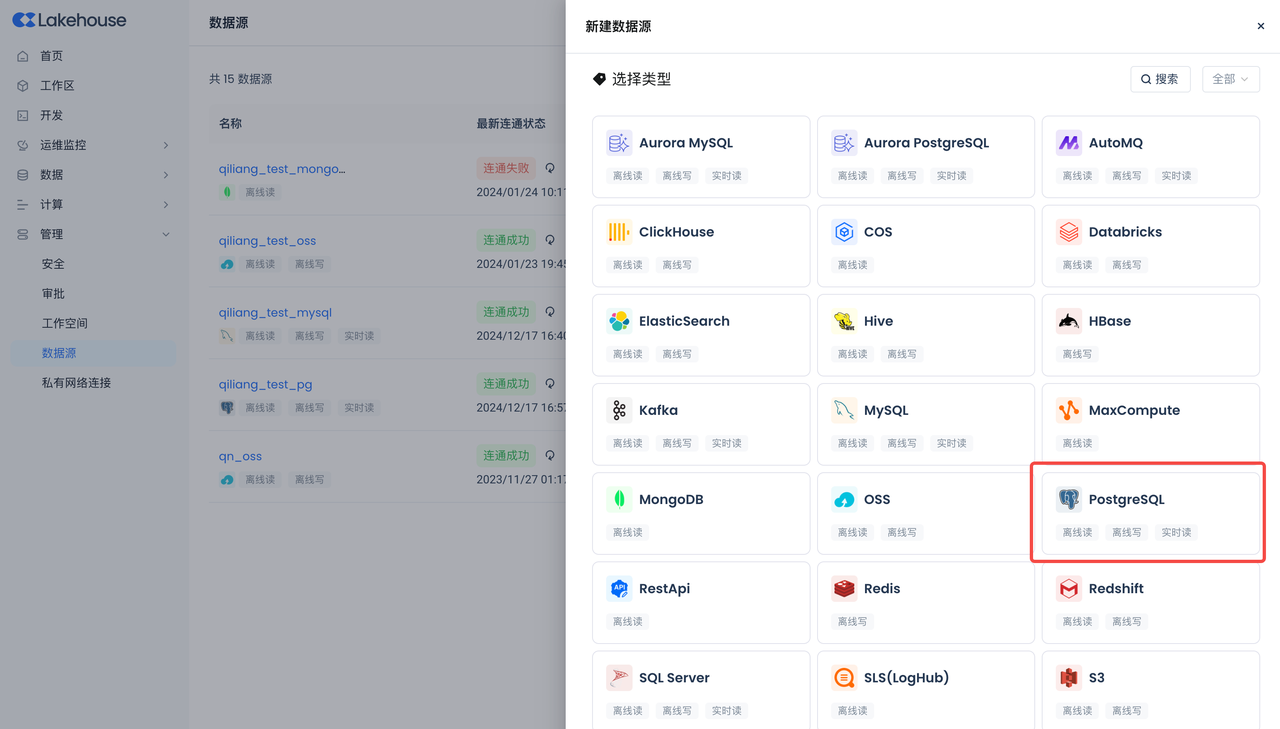
- 数据源名称:PG_CDC_DEMO
- 连接参数:同上节Postgres环境连接参数。
- 请注意务必配置正确的数据库所在的时区,避免数据同步失败。
创建多表实时同步任务
导航到开发->任务,单击+以创建新工作目录和工作表任务,然后选择“多表实时同步”。
- 选择“多表实时同步”:
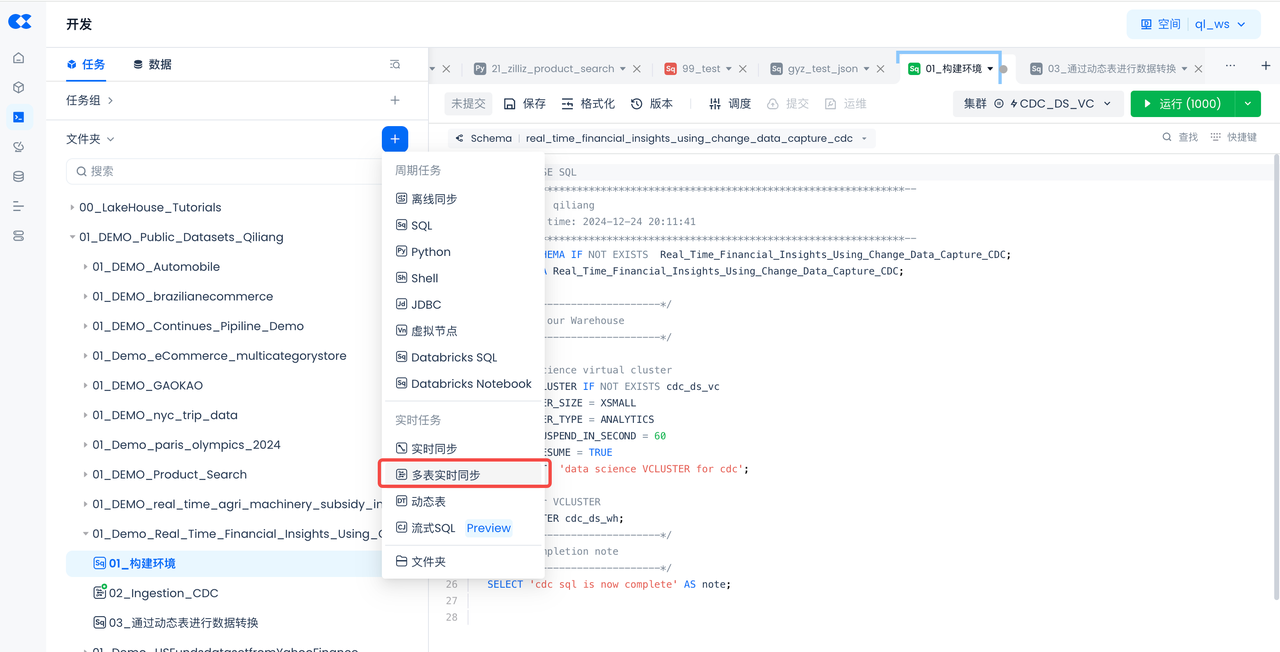
创建多表实时同步任务并存放在刚才构建环境的同一个目录里:
- 任务名称:02_Ingestion_CDC
- 来源数据:选择Postgres
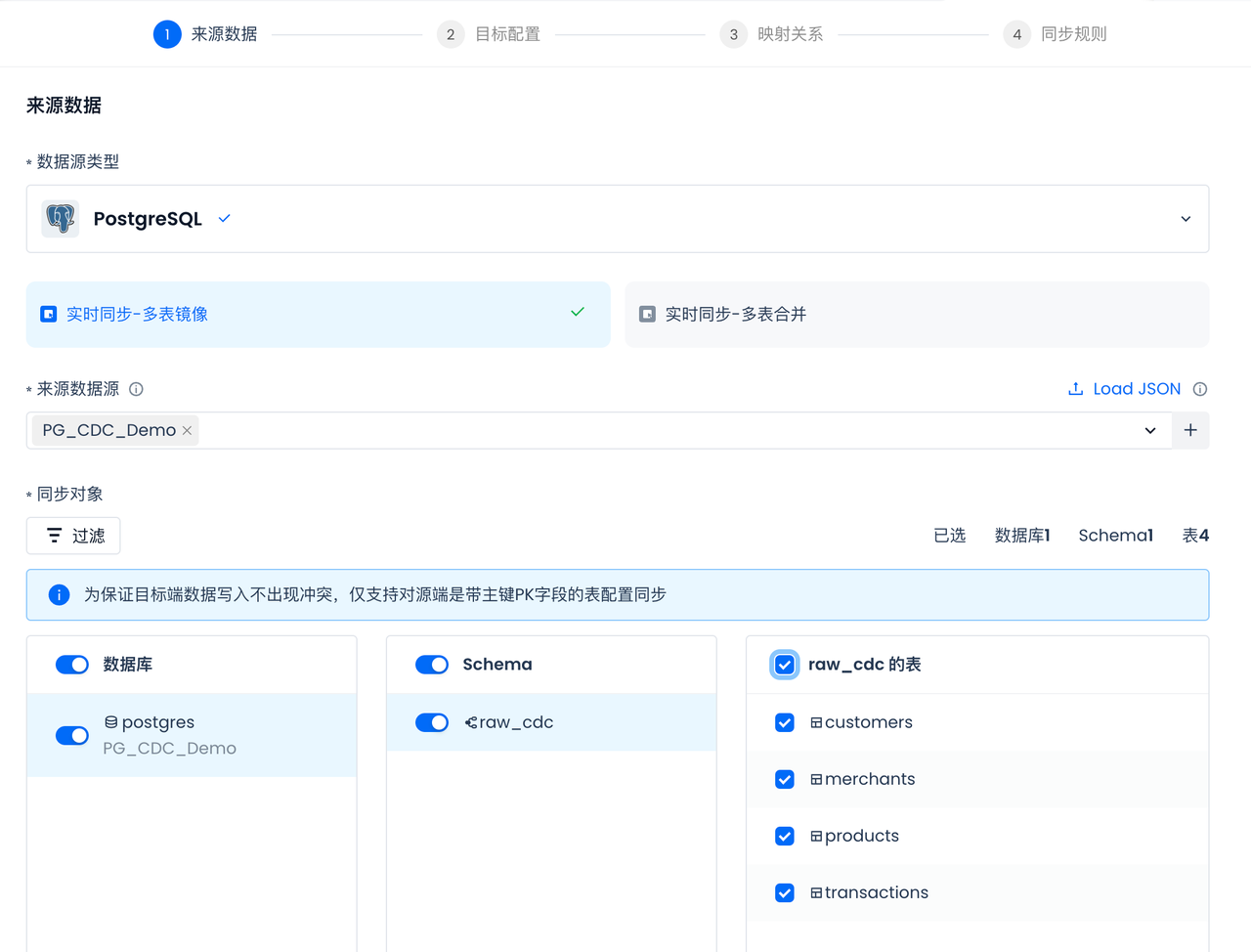
来源数据选择上一步创建的Postgres数据源:PG_CDC_DEMO,选择之后会自动显示该数据源可访问的数据库、Schema和表,并选中所有表(所有表都需要同步):
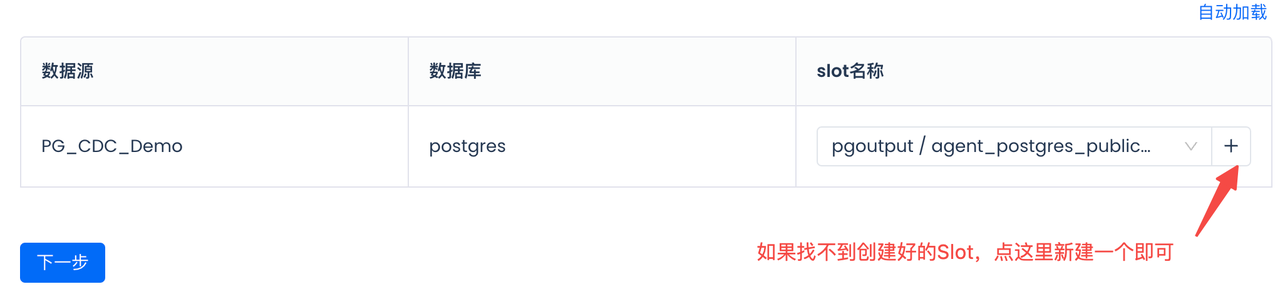
选择或者新建CDC同步的SlotName,请注意同一个Slot不要被两个任务共享消费,以免数据丢失:
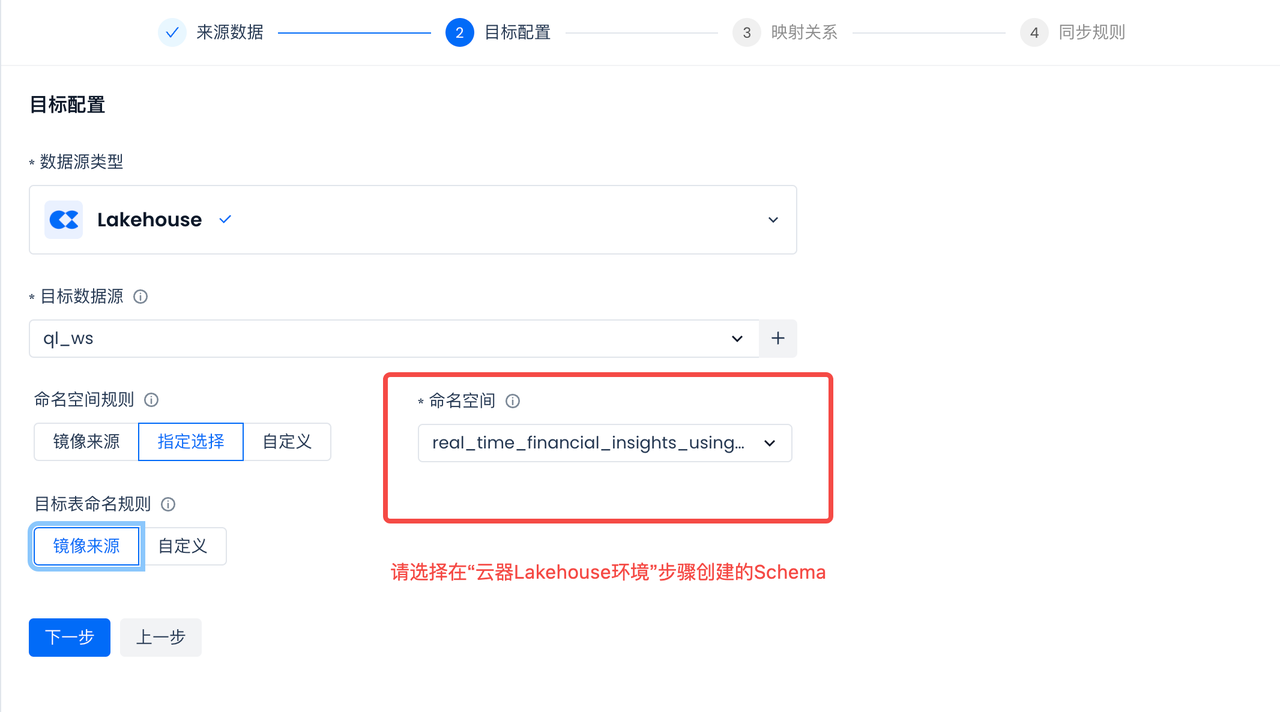
目标表配置:
选择目标数据源下已有的Schema作为目标表存储位置。
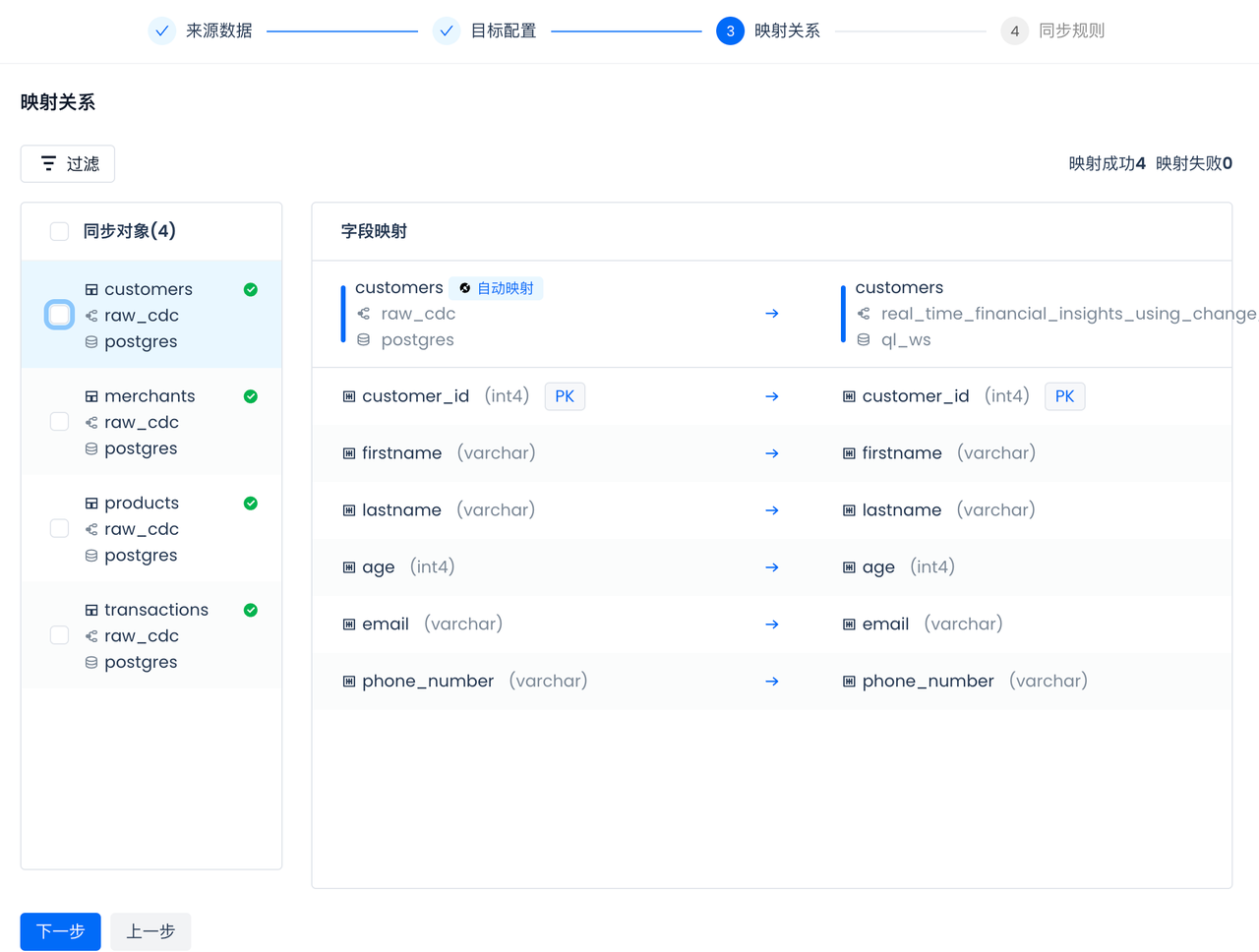
配置并检查表、字段映射关系:
云器Lakehouse会自动形成表和字段的映射,包括数据类型的映射。如果选中的云器Lakehouse命名空间里没有对应的表,多表实时同步任务在任务启动时会自动检查并新建表,无需手动提前创建。 CDC同步要求在源端表都有主键,多表实时同步会在Lakehouse目标表里自动创建对应的主键。
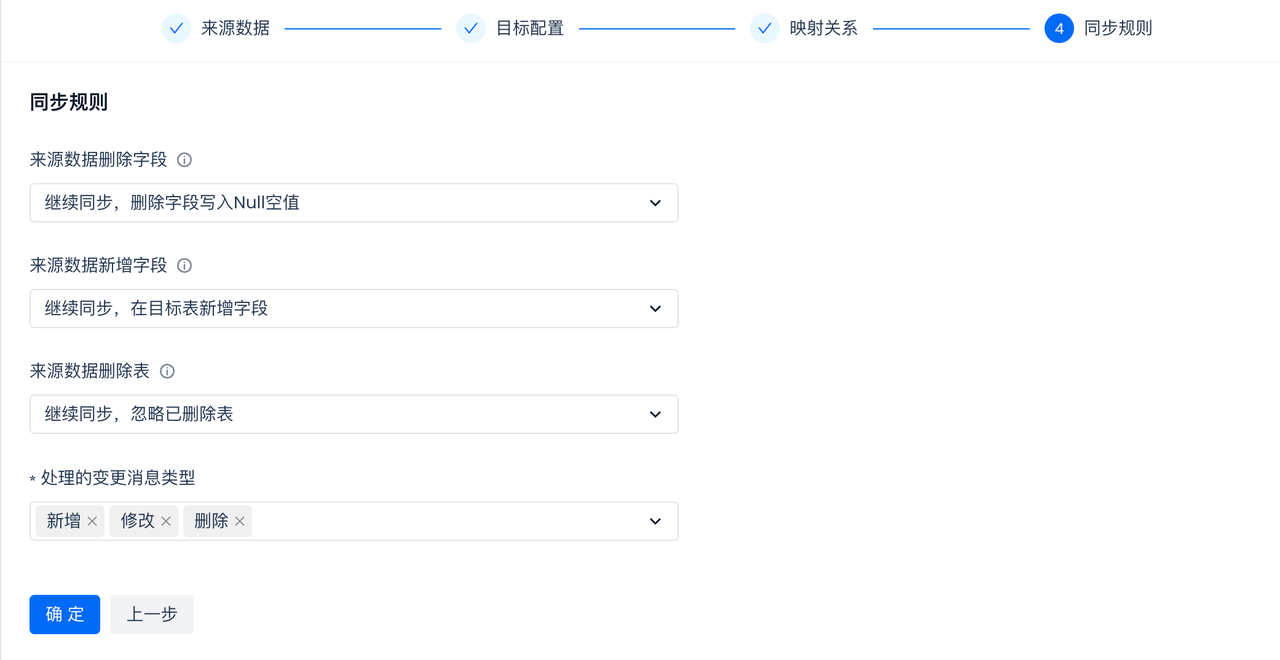
配置同步规则:
Schema Evolution,即“模式演进”,是指在数据库管理系统中,随着时间的推移和需求的变化,数据库的结构或模式(Schema)进行修改和适应的过程。模式演变通常涉及对数据库表结构、字段、数据类型、关系和约束的更改,而这些更改不会中断现有系统的运行或导致数据丢失。
实时同步任务的同步规则中,可以配置对于源端表和字段的变更的自动处理策略:
- 设置来源表删除字段后的行为。
- 设置来源表新增字段的行为。重命名字段视为字段删除、命名后字段被识别为字段新增。
- 设置来源表新增字段后的行为。
- 设置数据源同步对象被删除的行为。重命名表视为删除,重命名后的表视为新建表。
此外,同步规则中也支持设定需要处理的源端变更消息的类型,请按需设定。比如某些场景下,期望目标端的数据一直累加,不处理源端“删除”变更,在改配置中去除掉“删除”选项即可。
提交多表实时同步任务并启动
- 提交多表实时同步任务:

- 运维多表实时任务:
- 启动多表实时任务:
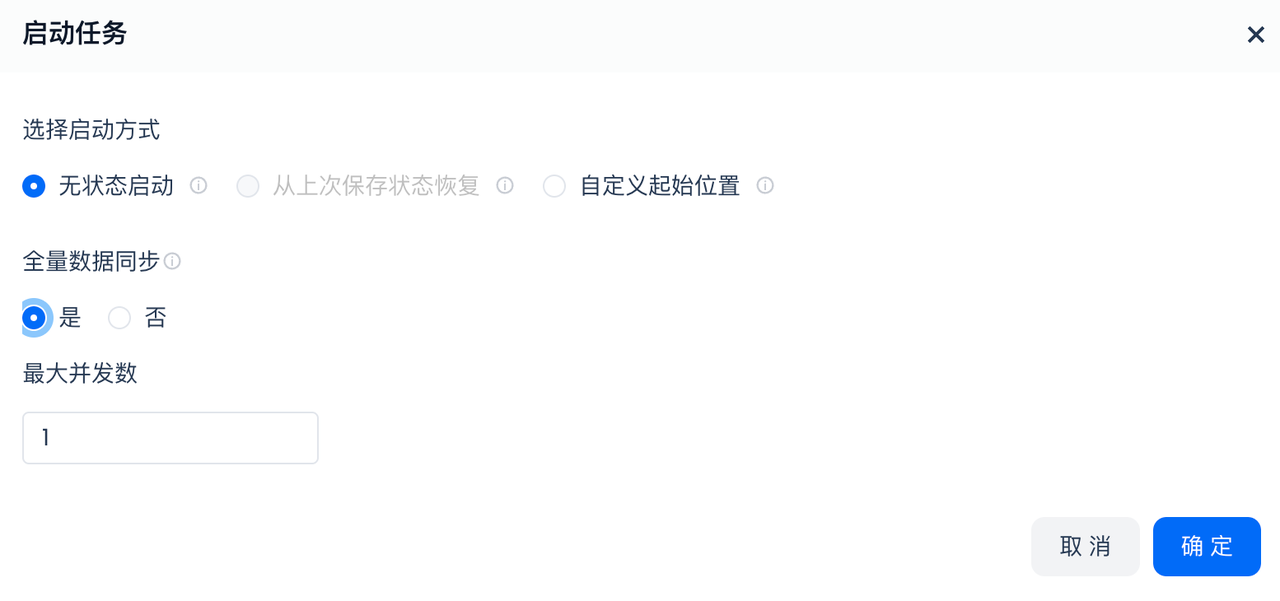
- 并选择“全量数据同步”:
是否在增量同步前,先进行全量的数据同步。请注意,此配置只在任务上线后第一次启动可以选择。
查看全量同步状态
在上文的“Postgres环境”步骤,已经通过Copy或者Python脚本方式,往Postgres的四张表中加载了数据。上一步选择的“全量数据同步”,在增量数据同步开始前,实现全量数据的同步。
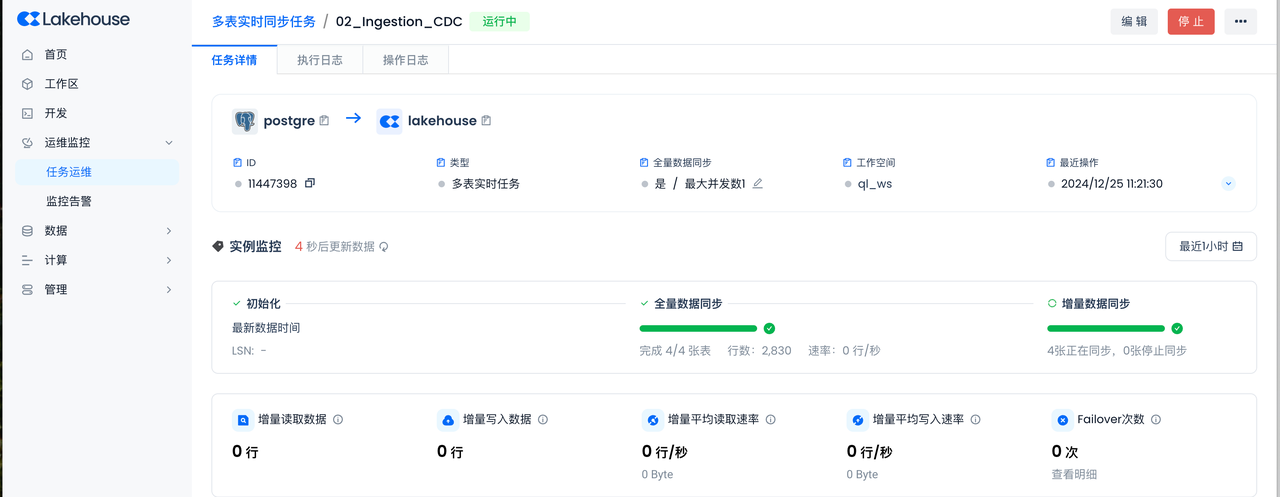
全部4张表的全量同步状态和增量同步状态都正常,没有发生Failover。
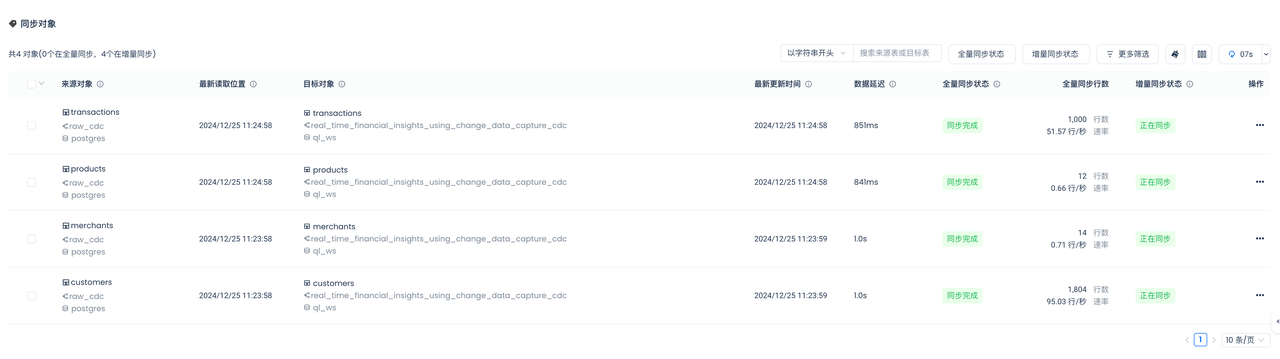
可以看到全量同步已经完成,此后,增量同步状态会自动转换成“正在同步”,不需要人工干预操作。
多表实时同步的增量同步过程
在数据源插入新增数据
在Postgres的源表中插入数据,通过已启动的实时多表同步任务实现增量数据同步,并查看实时多表同步任务的同步状态。
多表实时同步在增量同步过程中,使用了Lakehouse的Java实时编程接口将数据实时写入Lakehouse的主键表中。
将以下代码Copy进Notebook并运行,或者直接下载:
- 创建数据库连接
- 设置增量数据产生的参数
- 数据加载函数
- 调用函数插入交易数据
- 关闭游标和连接
查看增量同步状态
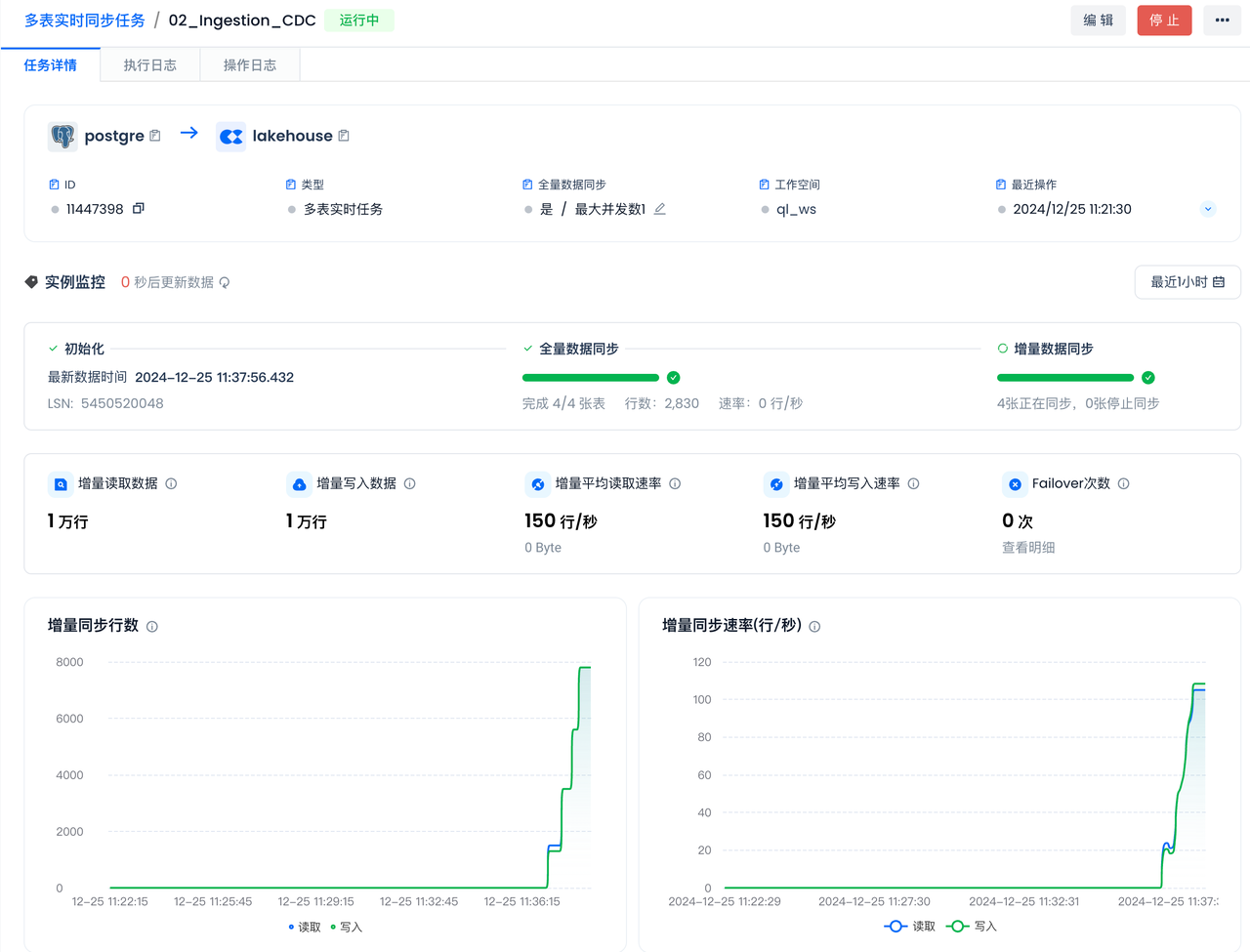
通过动态表处理多表实时同步进来的数据
概述
您将使用云器Lakehouse Studio来创建动态表(Dynamic Table),将从Postgres的表通过多表实时同步到云器Lakehouse的数据进行实时处理。
创建动态表
导航到开发->任务,单击“+选择“动态表”。
- 任务名称:03_customer_purchase_summary
- Schema选择:real_time_financial_insights_using_change_data_capture_cdc
- 表名请输入:customer_purchase_summary
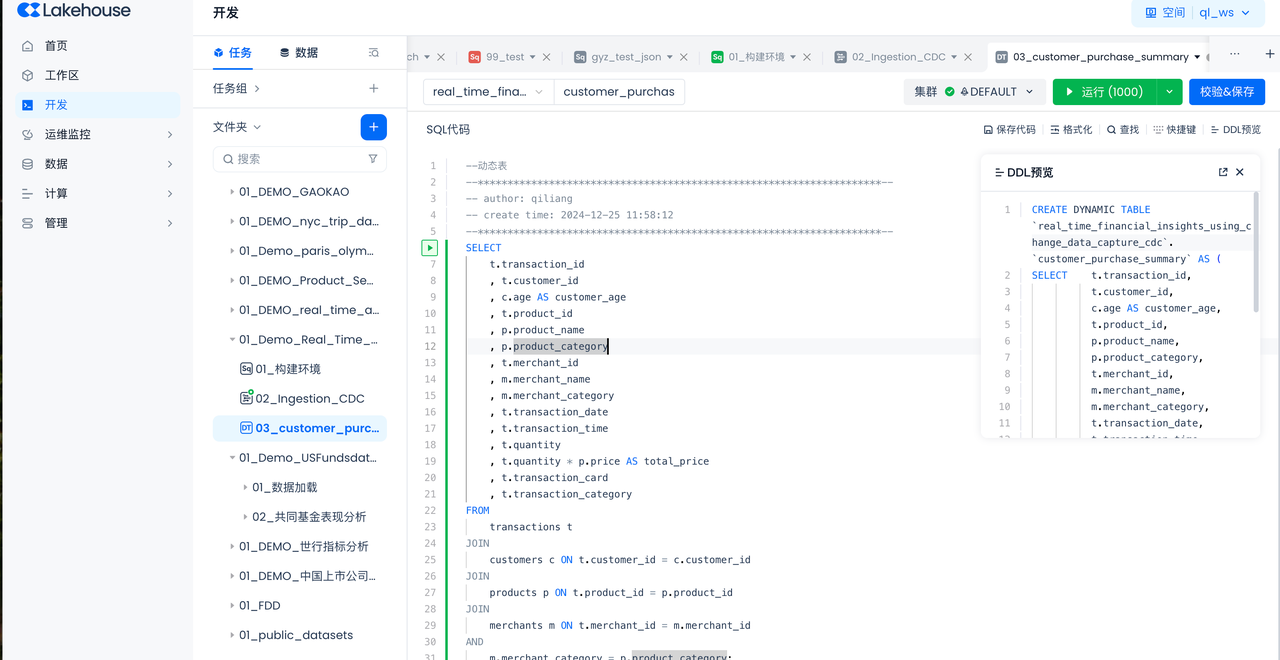
- 在SQL代码里输入:
这段 SQL 查询的具体作用是通过多个表的连接,从 transactions 表中获取详细的交易记录,并从 customers、products 和 merchants 表中获取相关的信息。以下是详细的解释:
-
从 ****``** 表中提取交易记录**:
t.transaction_id:获取每笔交易的唯一标识符。t.customer_id:获取与交易相关联的客户的标识符。t.product_id:获取交易中涉及的产品的标识符。t.merchant_id:获取提供产品或服务的商家的标识符。t.transaction_date和t.transaction_time:获取交易发生的日期和时间。t.quantity:获取交易中购买的产品数量。t.transaction_card:获取用于交易的卡类型(如信用卡或借记卡)。t.transaction_category:获取交易的类别(例如购买或退款)。
-
从 ****``** 表中提取客户信息**:
- 使用
JOIN customers c ON t.customer_id = c.customer_id将transactions表与customers表连接,获取与交易相关联的客户信息。 c.age AS customer_age:获取客户的年龄,并将其命名为customer_age。
- 使用
-
从 ****``** 表中提取产品信息**:
- 使用
JOIN products p ON t.product_id = p.product_id将transactions表与products表连接,获取交易中涉及的产品信息。 p.product_name:获取产品的名称。p.product_category:获取产品的类别。t.quantity * p.price AS total_price:计算每笔交易的总价格(数量乘以产品单价),并将其命名为total_price。
- 使用
-
从 ****``** 表中提取商家信息**:
- 使用
JOIN merchants m ON t.merchant_id = m.merchant_id AND m.merchant_category = p.product_category将transactions表与merchants表连接,并确保商家的类别与产品类别匹配。 m.merchant_name:获取商家的名称。m.merchant_category:获取商家的类别。
- 使用
通过这些连接和数据提取,这段查询语句生成了一个详细的结果集,每条记录包含交易的详细信息、客户信息、产品信息和商家信息,并计算了每笔交易的总价格,从而获得更全面和深入的交易分析。
动态表则会直接根据生命式语法,按照要求定时刷新数据,从而达到数据动态变化的目的。
- 校验并保存,选择“完成SQL开发”:

- 提交前选择运行动态表刷新的虚拟集群
选择在“云器Lakehouse环境”步骤创建的虚拟计算集群“CDC_DS_VS”。
- 提交前选择“自动刷新”
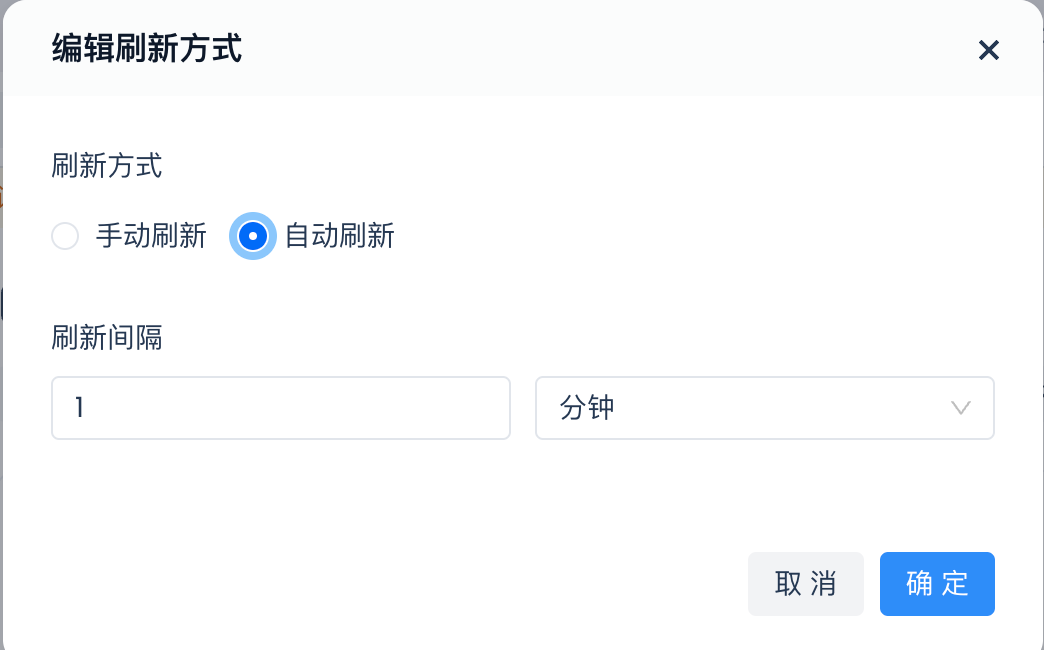
提交,完成动态表的开发
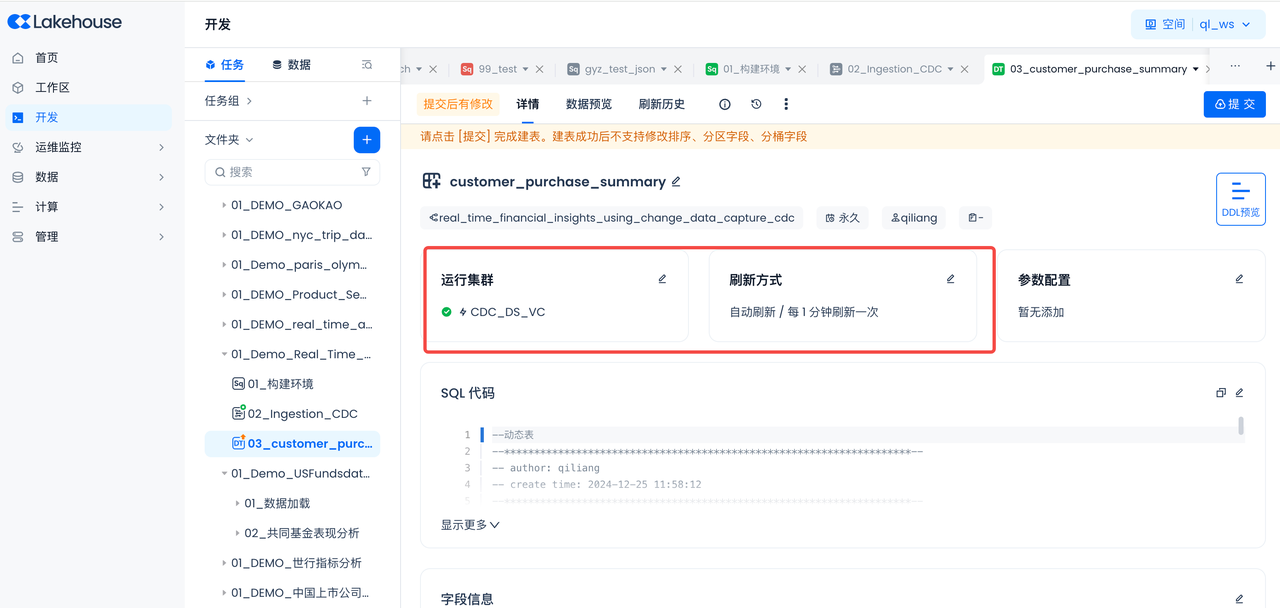
动态表运维
提交成功,可前往运维中心查看当前表的任务详情、刷新历史,支持启动或停止当前表。
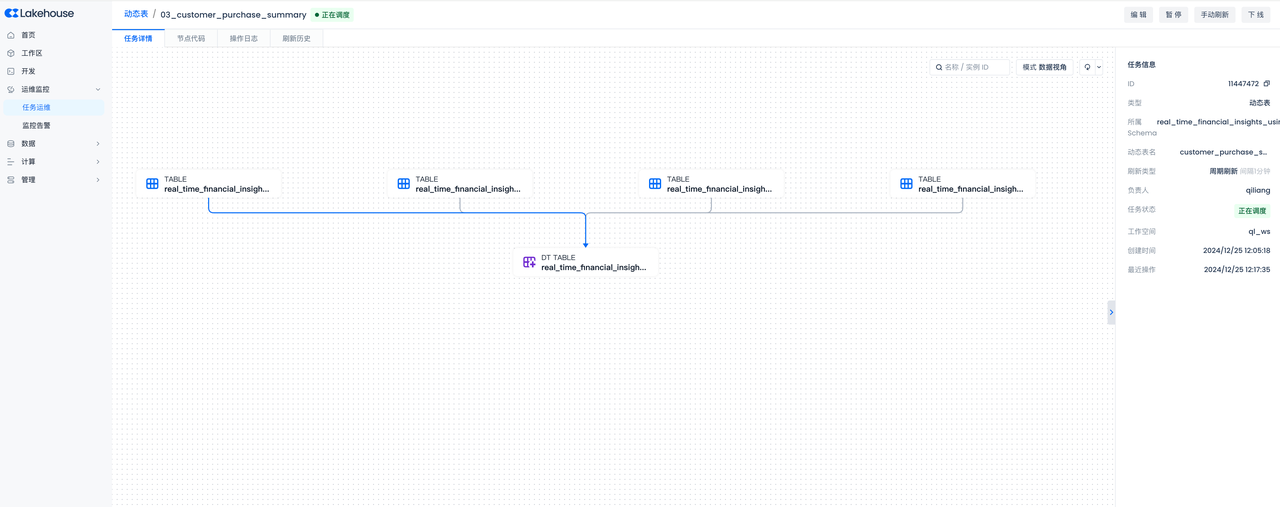
- 任务详情:
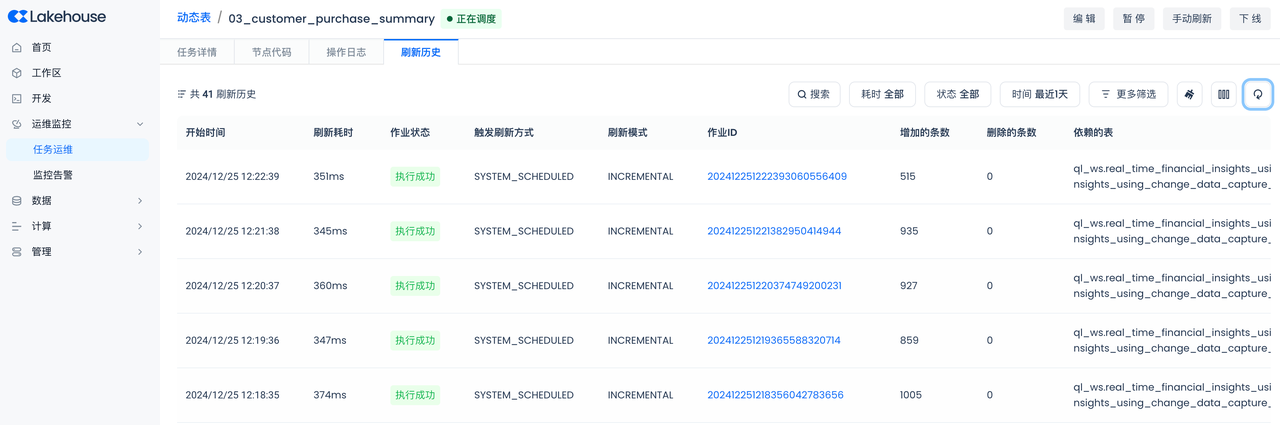
- 刷新历史:
可以查看到每一个刷新周期里增加、删除的行数,从而了解动态表的数据是如何“动态”变化的。
通过云器DataGPT进行问答式数据分析
概述
您将使用云器Lakehouse DataGPT,将从Postgres的表通过多表实时同步到云器Lakehouse的数据,通过问答的方式进行分析。
访问云器DataGPT
导航到账户主页->DataGPT,进入到云器DataGPT。
新建分析域
基于多个数据表、指标、答案构建器、知识和文件进行数据分析,并支持添加用户做权限隔离。
- 分析域名称:CDC交易数据分析。
- 新建成功后,选择“添加数据”,然后选择“添加表”->"导入表",将上一节创建的动态表添加到DataGPT。
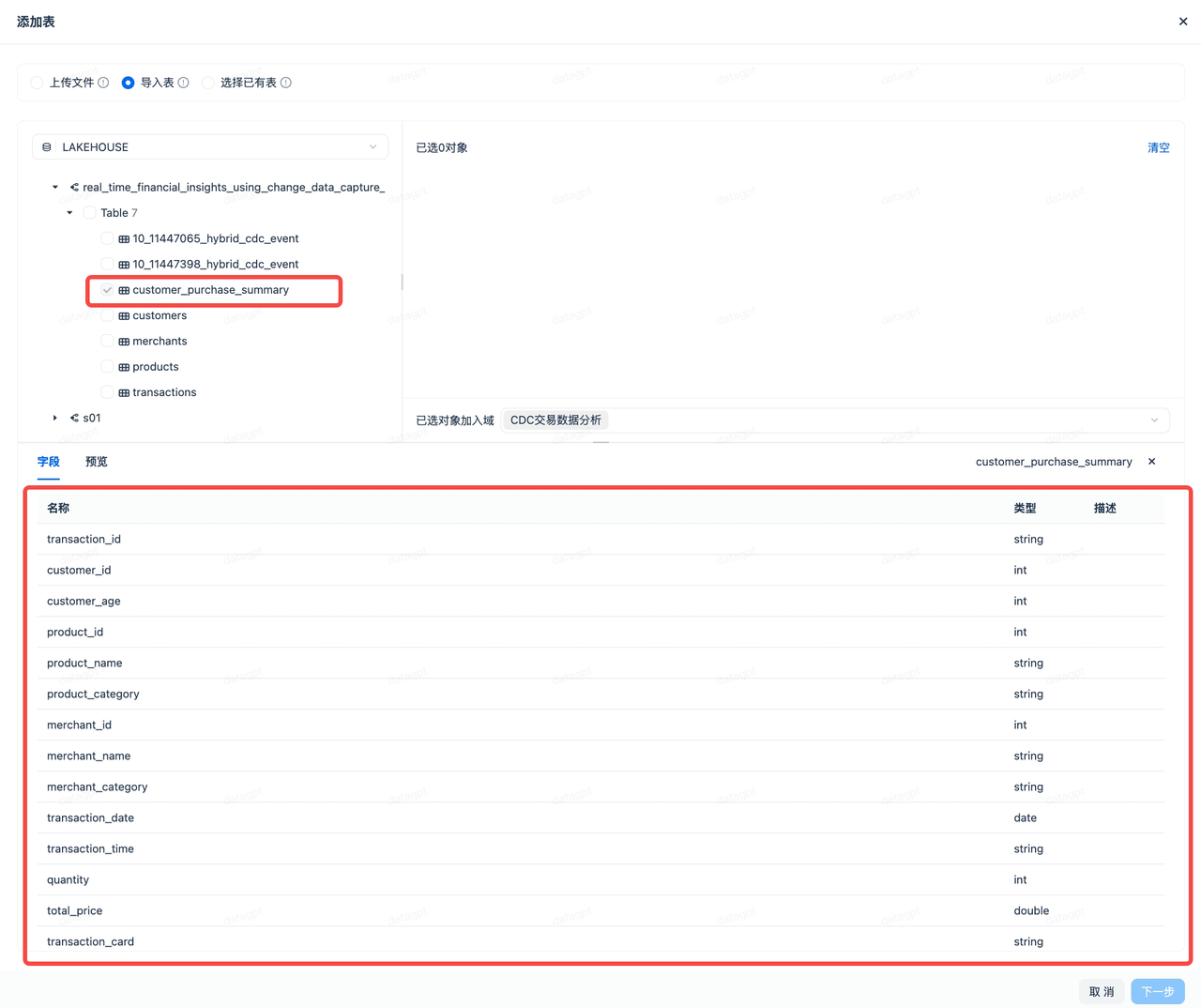
- 点击“描述”右侧的图标,系统将通过大模型为每个字段加上合适的描述,方便中文语义的对齐。
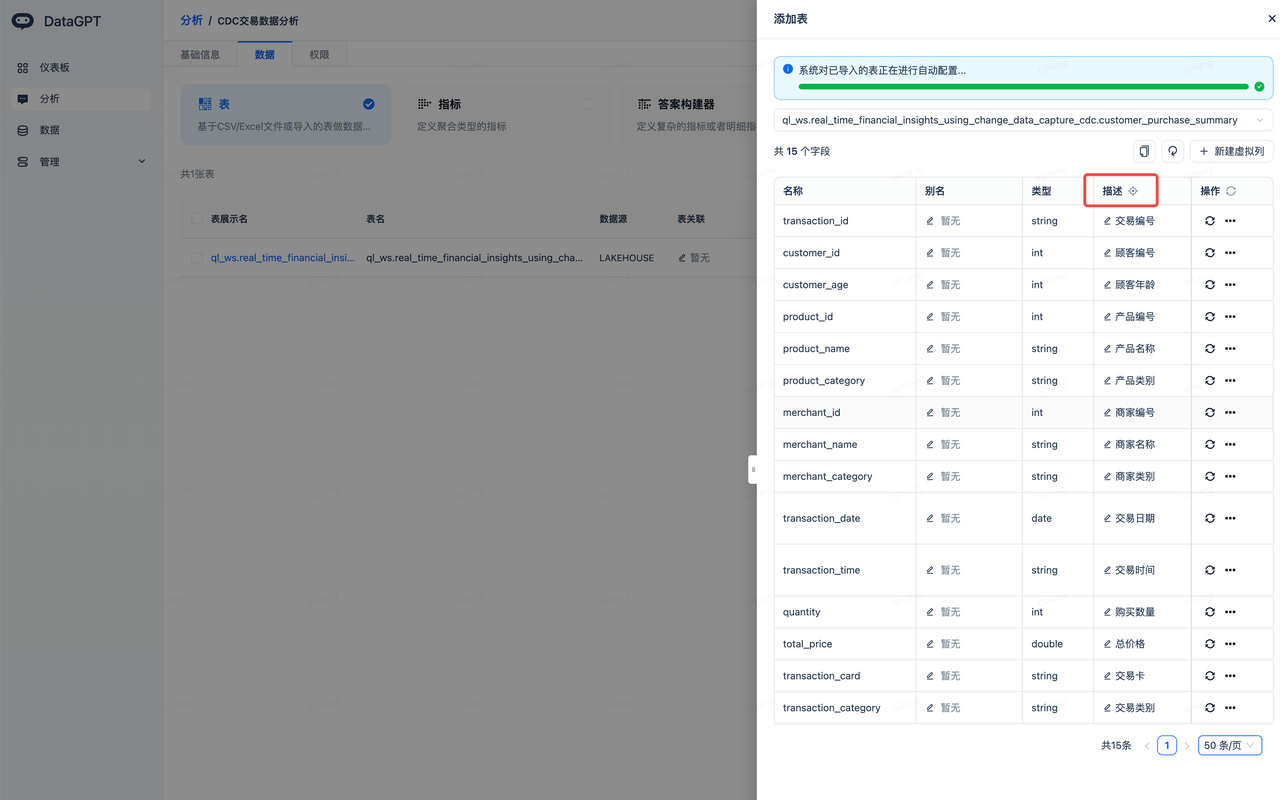
- 采纳大模型自动生成的指标,完成并开始分析:
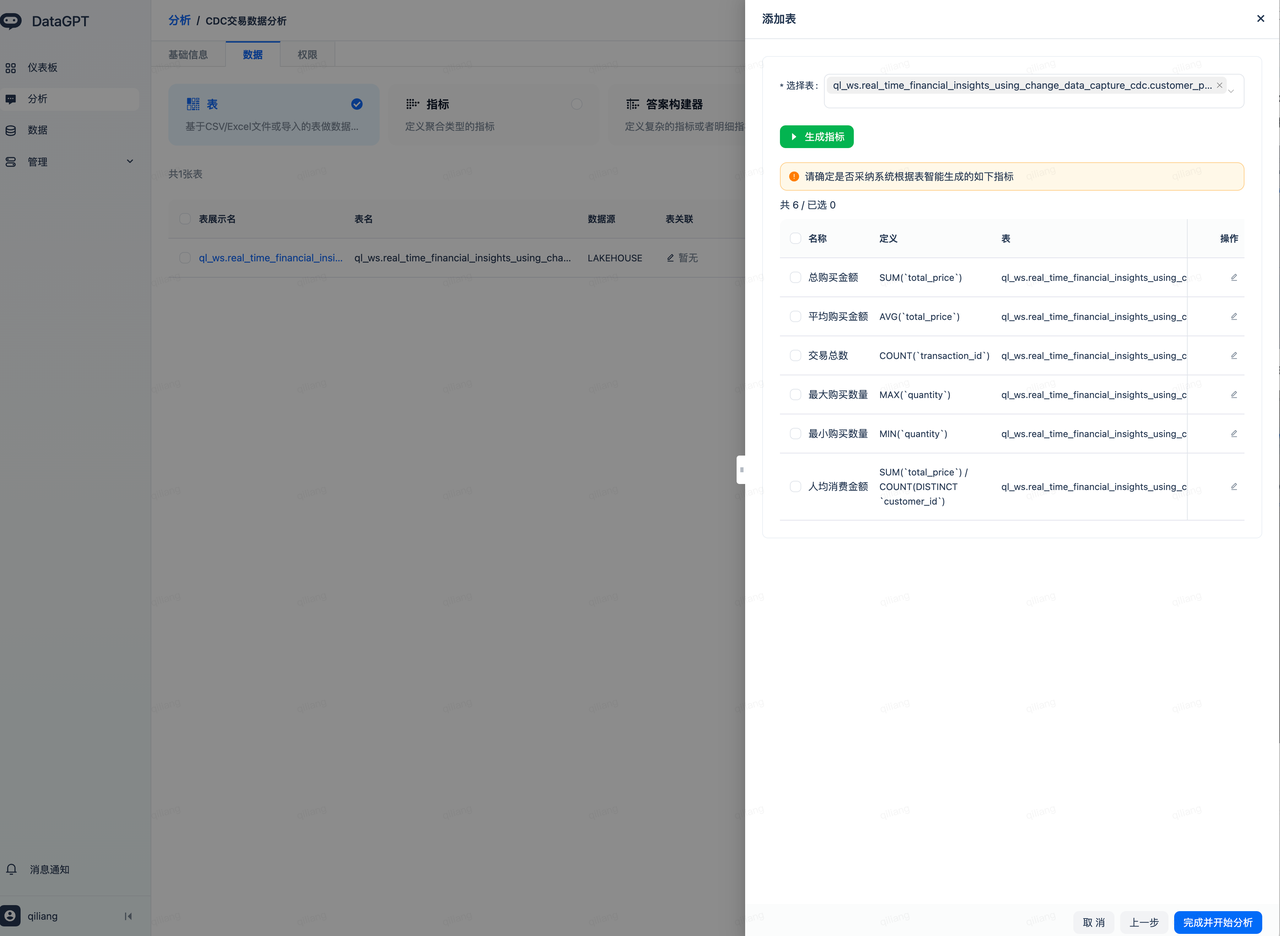
进入下面这个分析域页面,就可以开始数据探索和对话式分析了。
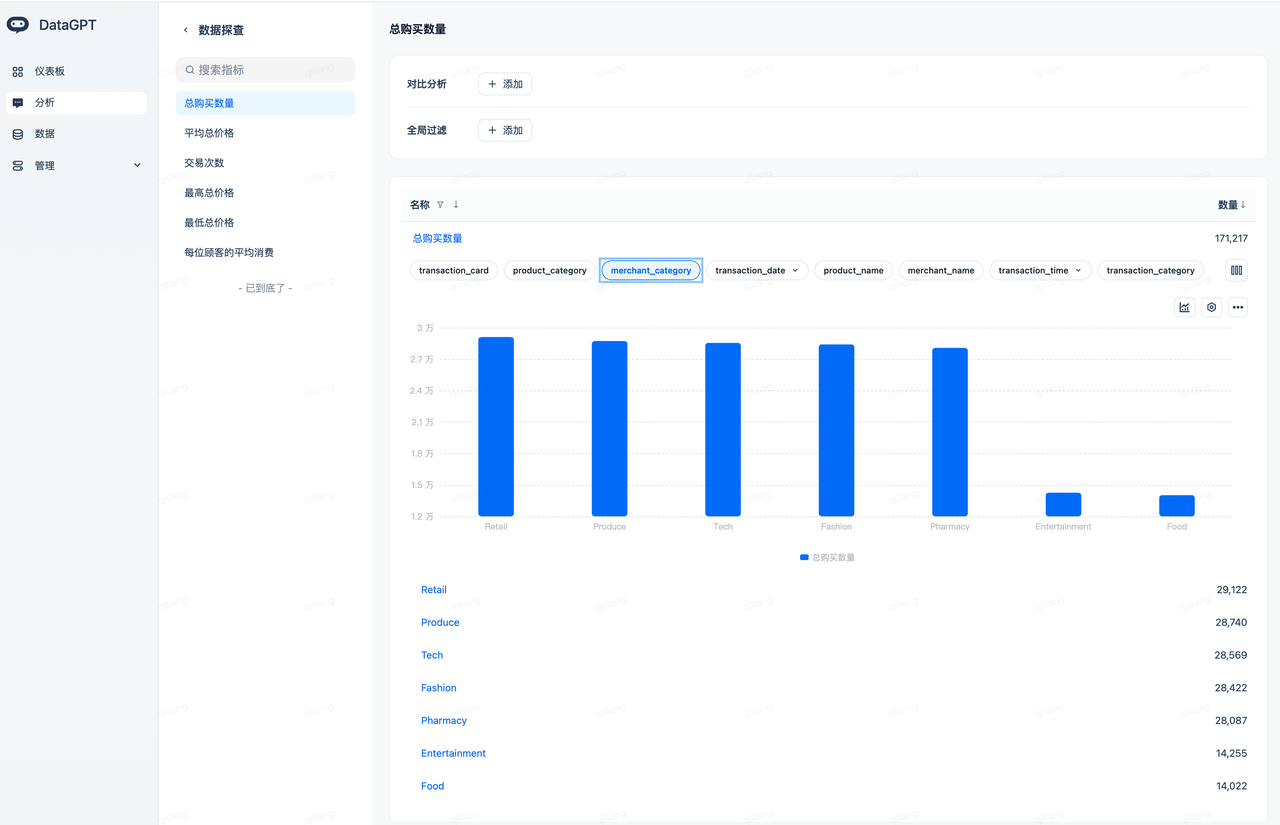
数据探查
导航到分析域(选择“CDC交易数据分析”)->探索,就可以基于刚才自动创建的指标进行数据探索了。
对话式数据分析
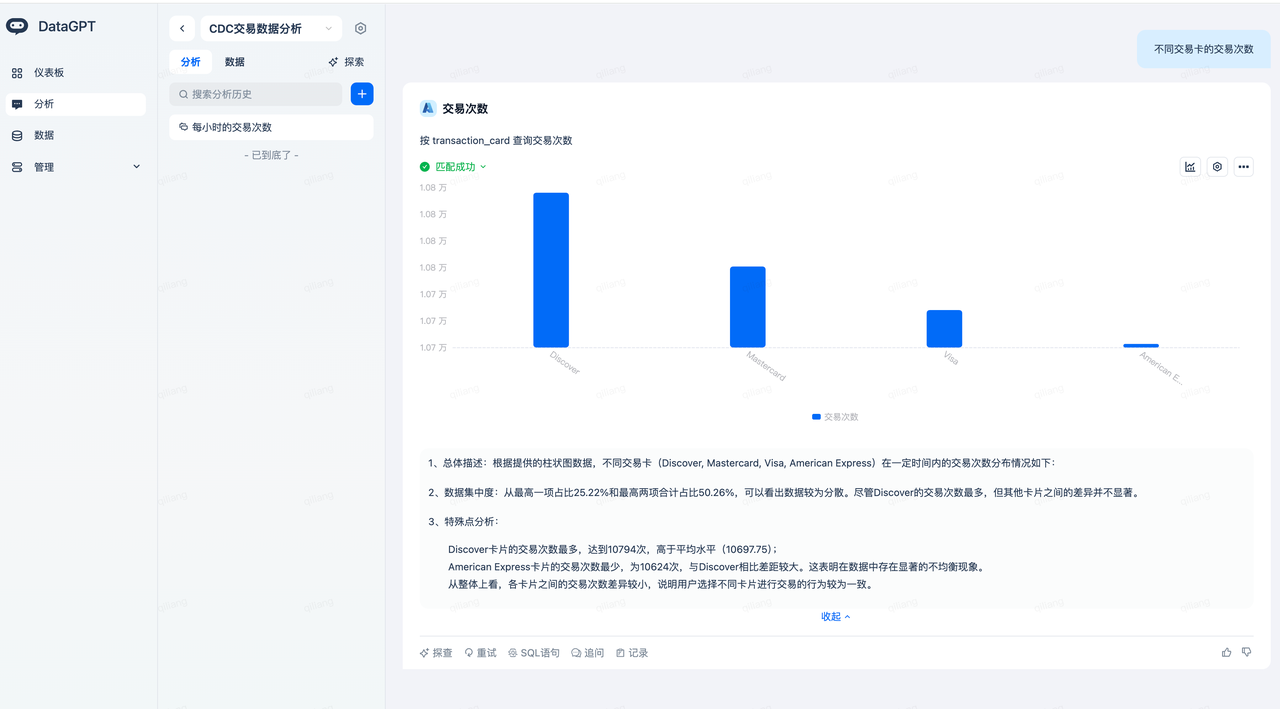
输入问题“Mastercard的交易次数,按照商家类别分布”,得到如下分析结果:
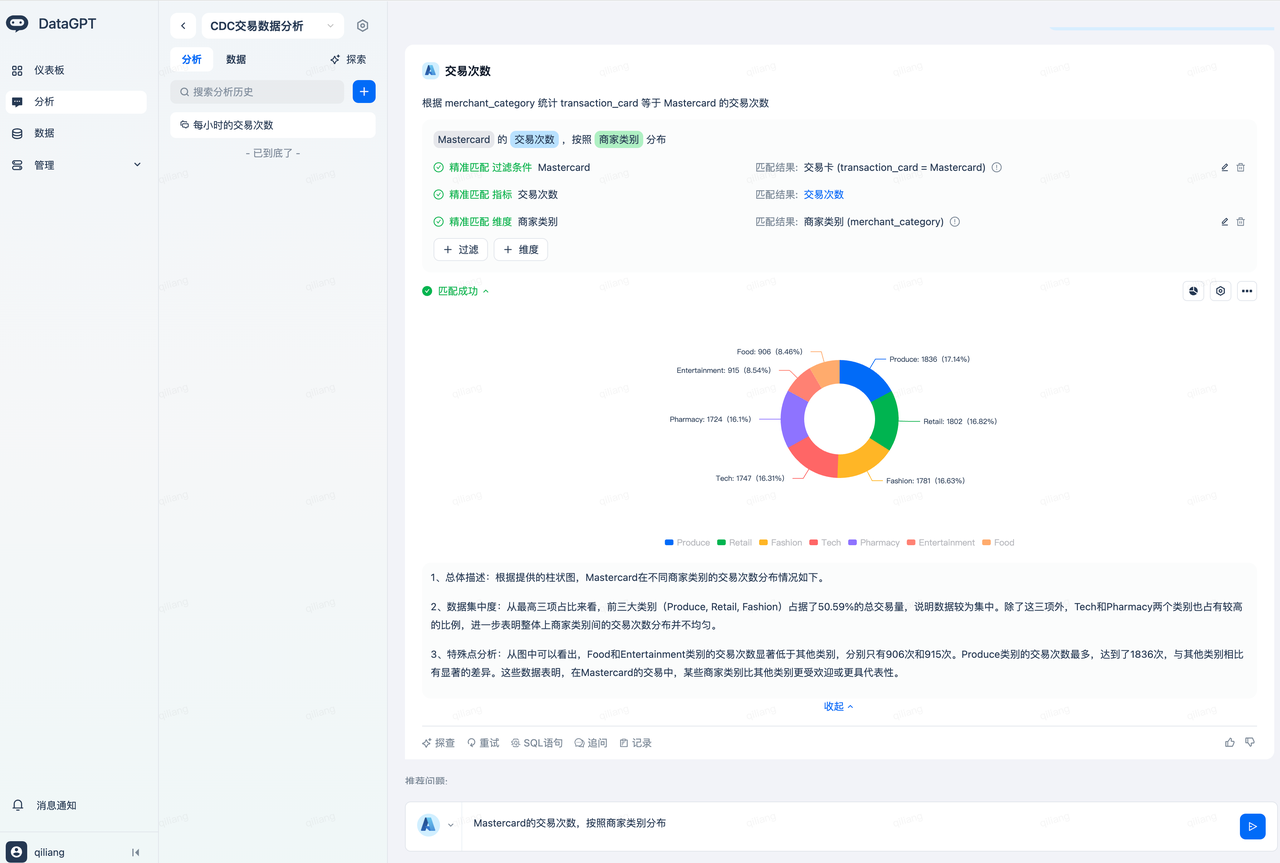
其中,理解到Mastercard是要匹配交易卡 (transaction_card = Mastercard),这受益于DataGPT对transaction_card 字段的值自动做了索引。
交易次数是一个自动创建的指标,实现了指标口径的对齐。
商家类别对应了字段merchant_category,这受益于字段描述的自动生成,快速实现了语义对齐。
输入问题:每个渠道购买‘消毒湿巾’产品的交易总数是多少?得到如下分析结果:
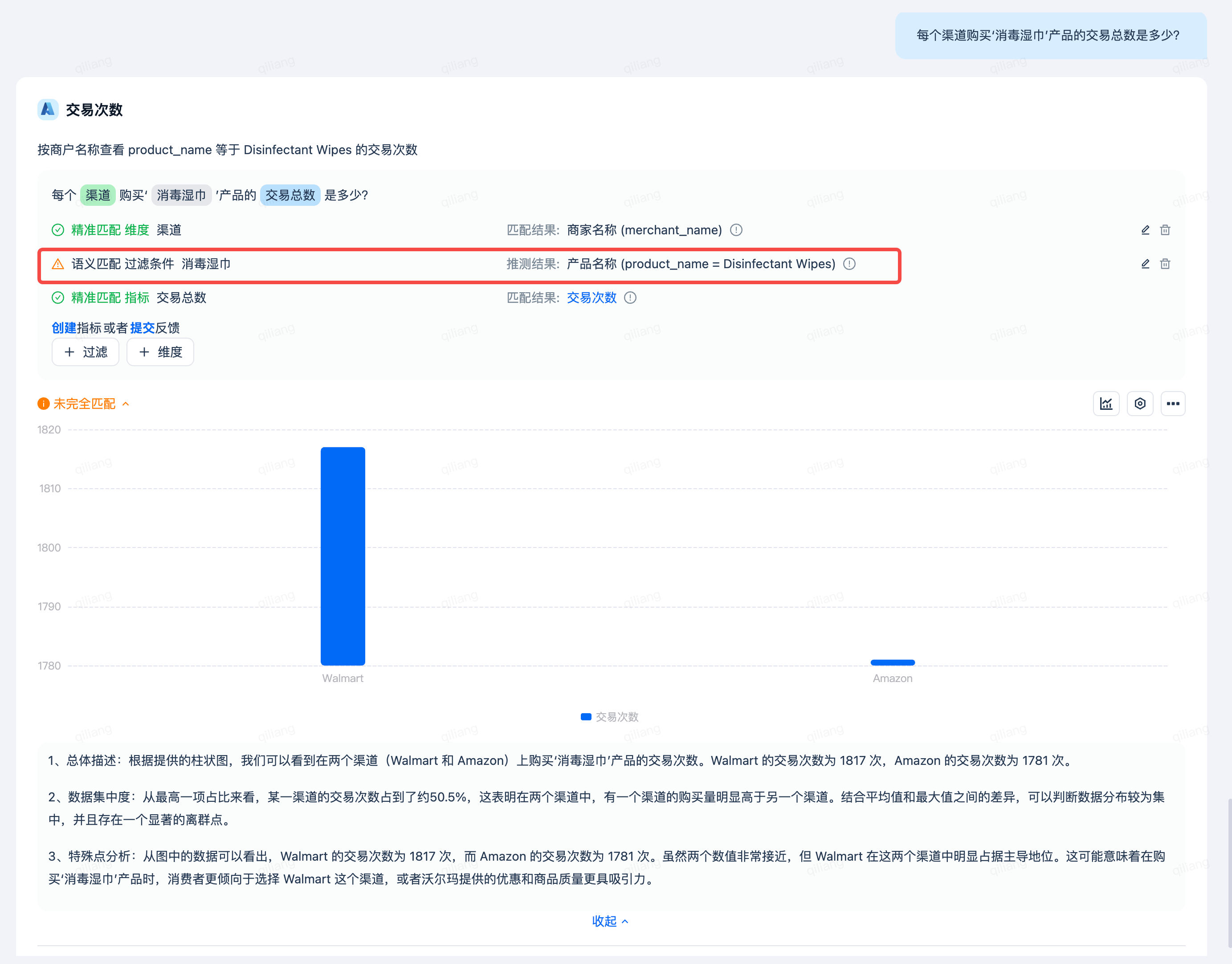
在Lakehouse表中,产品‘消毒湿巾’存储的是英文‘Disinfectant Wipes’。当用户问到‘消毒湿巾’,DataGPT会自动进行翻译从而做到精准适配,而不用用户一定要输入‘Disinfectant Wipes’,这充分发挥了大模型的优势,让数据分析更加简单。
清理
完成本快速入门后,您可以清理在云器Lakehouse中创建的对象。
总结
恭喜!您已完成本快速入门!
重点学习了什么
完成本快速入门后,您现在已经深入了解:
- 如何使用云器Lakehouse多表实时同步将PostgreSQL数据同步到云器Lakehouse的表里,这对应ELT过程的数据抽取(E)和加载(L)。
- 使用动态表处理数据,这对应ELT过程的数据转换(T)。
- 通过云器Lakehouse自带的DataGPT中可视化探索数据和以对话的方式分析数据。
资源
云器Lakehouse问答式数据分析DataGPT