将数据从阿里云数据湖摄取到云器 Lakehouse 的三层数据仓库中
关于三层数据仓库(3 Layer Data Warehouse)
在现代数据湖仓架构中,三层数据仓库(3 Layer Data Warehouse)通常分为Bronze层、Silver层和Gold层。这种架构提供了一种系统化的方法来管理不同状态的数据,从原始数据到高质量数据。
1. Bronze层(原始数据层)
Bronze层是数据仓库的最底层,用于存储从各种数据源提取的原始数据。这些数据未经处理,保留了数据的原始形式。
特点:
- 数据状态:原始、未经处理的数据。
- 数据来源:各种数据源(数据库、日志、文件等)。
- 目的:提供原始数据的备份和数据追溯,确保数据的完整性和可审计性。
2. Silver层(清洗和转换层)
Silver 层用于存储经过清洗和转换的数据。这一层的数据经过 ETL(Extract, Transform, Load)流程处理,去除了噪声和冗余,转化为结构化和标准化的数据格式。
特点:
- 数据状态:经过清洗和标准化处理的数据。
- 数据操作:清洗、去重、数据转换和整合。
- 目的:提供高质量、结构化的数据,以便进一步处理和分析。
3. Gold层(业务信息层)
Gold 层是面向分析和业务的重要数据层,存储经过进一步优化和聚合的数据。这一层的数据通常支持商业智能(BI)、数据分析和报告等应用。
特点:
- 数据状态:高质量、聚合和优化过的数据。
- 数据操作:数据聚合、多维分析、数据建模。
- 目的:支持数据分析、商业智能和决策支持,提供优化的数据视图。
三层数据仓库架构的优势
- 数据管理效率:分层存储和处理数据,使得管理和维护更加便捷。
- 数据质量提升:清洗和转换层保证了数据的一致性和准确性。
- 高效数据访问:业务信息层经过优化的数据结构,提升了查询性能。
- 灵活性强:适应不同的业务需求,支持各种数据源的整合和处理。
通过这种三层架构,企业可以更有效地管理和分析数据,确保数据从采集到分析的各个阶段都得到妥善处理和优化。
需要什么
基于云器Lakehouse的实现方案
本方案是基于云器 Lakehouse 创建一个多层数据仓库架构,其中有三层:用于数据提取的 Bronze 层、用于清理和转换数据的 Silver 层以及用于业务级聚合和数据修改的 Gold 层。
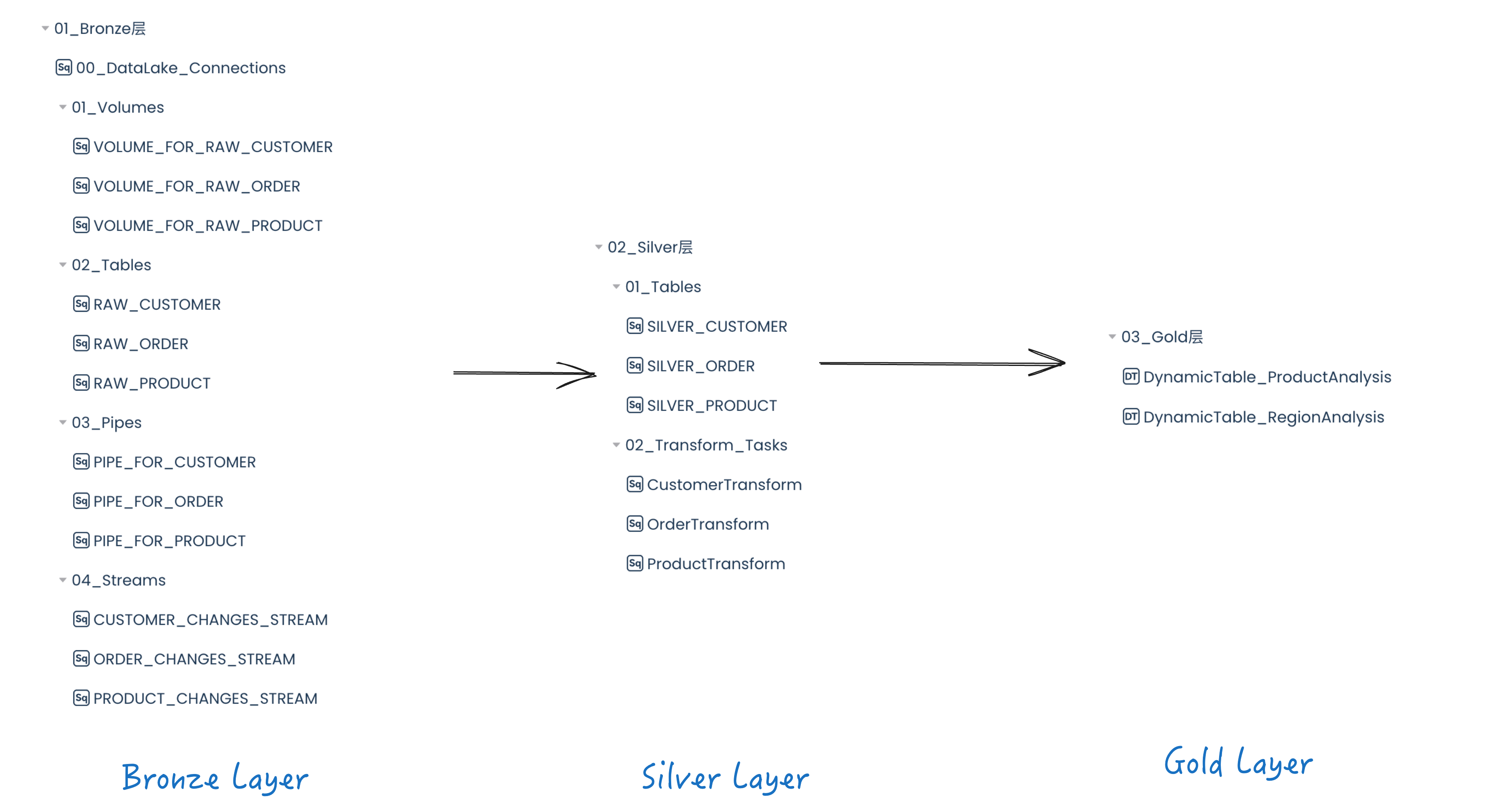
Bronze层
Bronze层专注于从阿里云对象存储OSS到云器Lakehouse的数据摄取。这是通过创建数据湖 Connection 和 External Volume,以及 Lakehouse Pipe、Table Stream 来完成的,该阶段在 External Volume 中指定阿里云 OSS 中数据的位置。使用External Volume,可以使用Lakehouse Pipe自动将数据实时摄入到Lakehouse的表中。
最后,为每个表创建一个 Table Stream,以跟踪和保存对表所做的任何更改。这些流可用于识别 Bronze 层表中的更改并对 Silver 层中的相应表进行更新。
Silver层
Silver层专注于数据清理和转换。它使用来自Bronze层的原始数据,并对其进行转换以满足公司的需求。这些转换包括清理缺失或异常值、数据验证以及删除未使用或不重要的数据。
客户数据清洗与转换
| 转型 | 细节 |
|---|
| 电子邮件验证 | 确保电子邮件不为空 |
| 客户类型 | 将客户类型标准化为“常规”、“高级”或“未知” |
| 年龄验证 | 确保年龄在 18 至 120 岁之间 |
| 性别标准化 | 将性别分类为“男”、“女”或“其他” |
| 总购买量验证 | 确保总购买量是一个数字,如果无效则默认为 0 |
产品数据清洗与转换
| 转型 | 细节 |
|---|
| 价格验证 | 确保价格为正数 |
| 库存数量验证 | 确保库存数量非负 |
| 评级验证 | 确保评分在 0 到 5 之间 |
订单数据清洗与转换
| 转型 | 细节 |
|---|
| 金额验证 | 确保交易金额大于 0 |
| 交易 ID 验证 | 确保交易 ID 不为空 |
Gold层
Gold层旨在利用Silver层的转换数据来创建可用于业务分析的动态表。例如,DT_RegionAnalysis是一个结合所有 3 个表的统一数据视图,用于分析不同地区的销售业绩并确定销售额最好的地区。
除了本项目所展示的简单动态表之外,还可以在Gold层进行许多额外的分析。
数据流
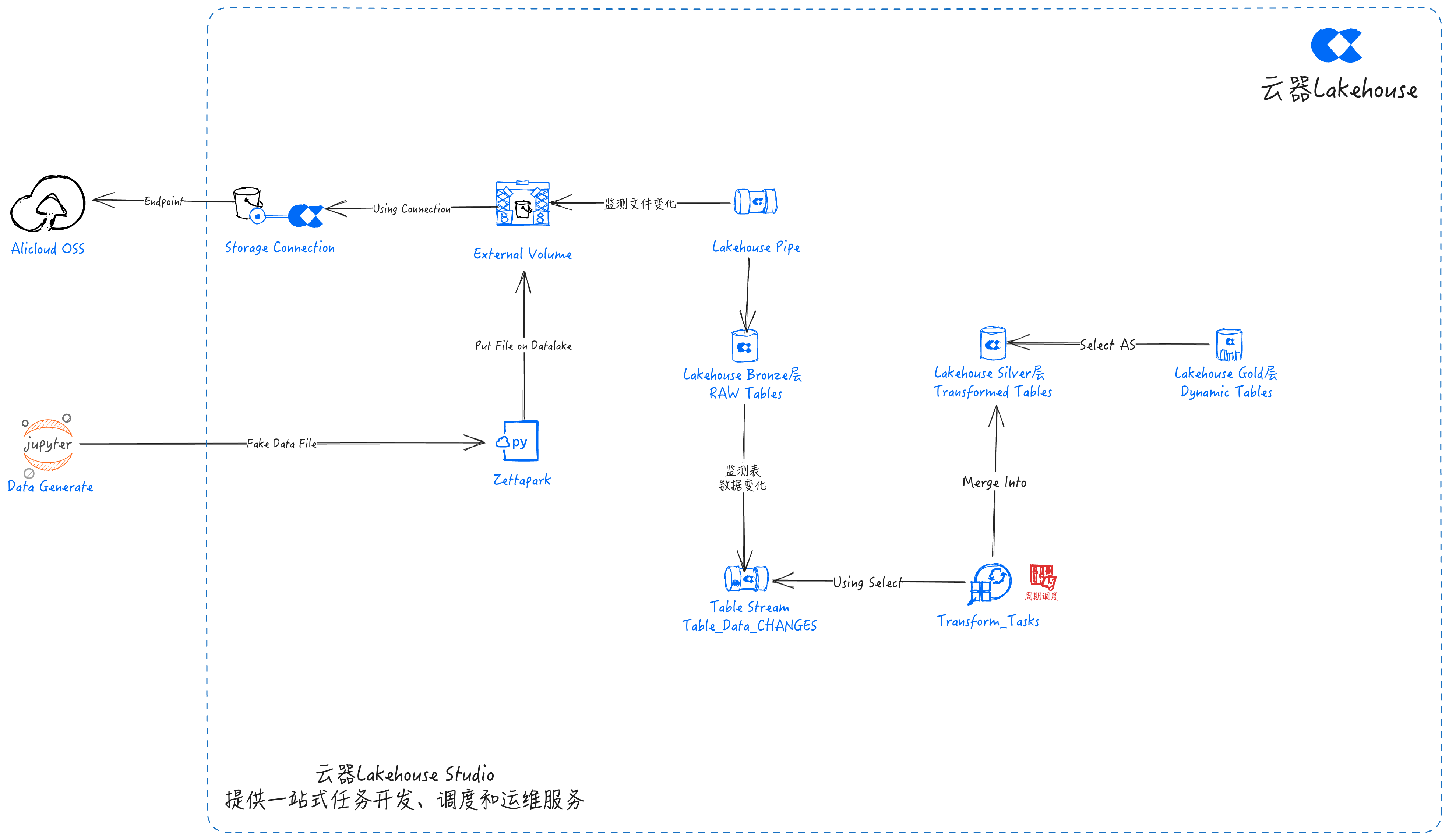
基于云器Lakehouse的实现步骤
导航到Lakehouse Studio的开发->任务,
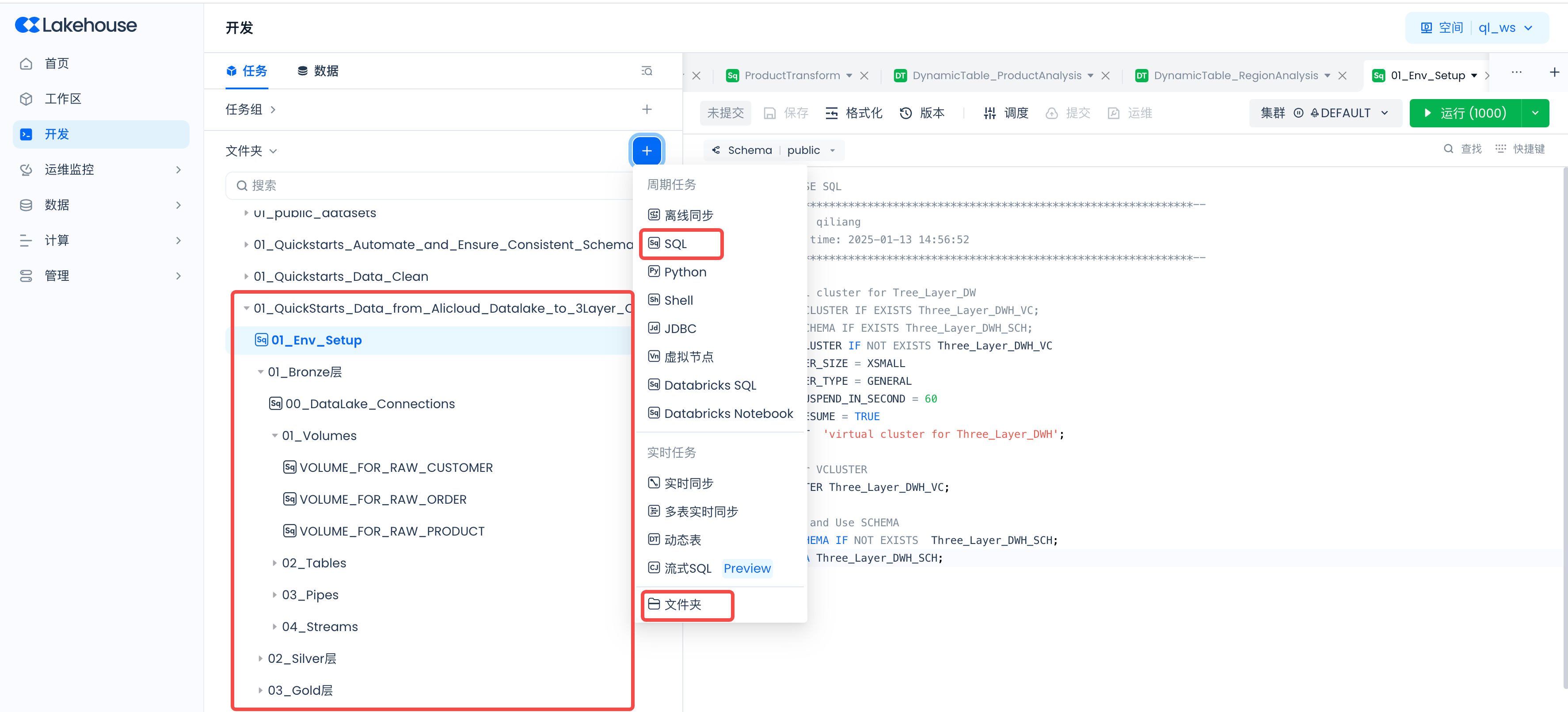
单击“+”新建如下目录:
- 01_QuickStarts_Data_from_Alicloud_Datalake_to_3Layer_Clickzetta_Data_Warehouse
单击“+”新建如下SQL任务,并在创建好后点击运行:

构建Lakehouse环境
新建SQL任务:01_Env_Setup
CREATE VCLUSTER IF NOT EXISTS Three_Layer_DWH_VC
VCLUSTER_SIZE = XSMALL
VCLUSTER_TYPE = GENERAL
AUTO_SUSPEND_IN_SECOND = 60
AUTO_RESUME = TRUE
COMMENT 'virtual cluster for Three_Layer_DWH';
-- Use our VCLUSTER
USE VCLUSTER Three_Layer_DWH_VC;
-- Create and Use SCHEMA
CREATE SCHEMA IF NOT EXISTS Three_Layer_DWH_SCH;
USE SCHEMA Three_Layer_DWH_SCH;
开发Bronze层
新建目录:01_Bronze层
创建数据湖连接
新建SQL任务:00_DataLake_Connections
-- Use our VCLUSTER and SCHEMA
USE VCLUSTER Three_Layer_DWH_VC;
USE SCHEMA Three_Layer_DWH_SCH;
external data lake
创建数据湖Connection,到数据湖的连接
CREATE STORAGE CONNECTION if not exists hz_ingestion_demo
TYPE oss
ENDPOINT = 'oss-cn-hangzhou-internal.aliyuncs.com'
access_id = '请输入您的access_id'
access_key = '请输入您的access_key'
comments = 'hangzhou oss private endpoint for ingest demo';
创建数据湖Volumes
创建数据湖 Volumes,每个 Volume 对应客户、产品和订单数据文件的存储位置。
新建SQL任务:VOLUME_FOR_RAW_CUSTOMER
-- Use our VCLUSTER and SCHEMA
USE VCLUSTER Three_Layer_DWH_VC;
USE SCHEMA Three_Layer_DWH_SCH;
--创建Volume,数据湖存储文件的位置
CREATE EXTERNAL VOLUME if not exists VOLUME_FOR_RAW_CUSTOMER
LOCATION 'oss://yourbucketname/VOLUME_FOR_RAW_CUSTOMER'
USING connection hz_ingestion_demo -- storage Connection
DIRECTORY = (
enable = TRUE
)
recursive = TRUE;
--同步数据湖Volume的目录到Lakehouse
ALTER volume VOLUME_FOR_RAW_CUSTOMER refresh;
--查看云器Lakehouse数据湖Volume上的文件
SELECT * from directory(volume VOLUME_FOR_RAW_CUSTOMER);
新建SQL任务:VOLUME_FOR_RAW_ORDER
-- Use our VCLUSTER and SCHEMA
USE VCLUSTER Three_Layer_DWH_VC;
USE SCHEMA Three_Layer_DWH_SCH;
--创建Volume,数据湖存储文件的位置
CREATE EXTERNAL VOLUME if not exists VOLUME_FOR_RAW_ORDER
LOCATION 'oss://yourbucketname/VOLUME_FOR_RAW_ORDER'
USING connection hz_ingestion_demo -- storage Connection
DIRECTORY = (
enable = TRUE
)
recursive = TRUE;
--同步数据湖Volume的目录到Lakehouse
ALTER volume VOLUME_FOR_RAW_ORDER refresh;
--查看云器Lakehouse数据湖Volume上的文件
SELECT * from directory(volume VOLUME_FOR_RAW_ORDER);
新建SQL任务:VOLUME_FOR_RAW_PRODUCT
-- Use our VCLUSTER and SCHEMA
USE VCLUSTER Three_Layer_DWH_VC;
USE SCHEMA Three_Layer_DWH_SCH;
--创建Volumes,数据湖存储文件的位置
CREATE EXTERNAL VOLUME if not exists VOLUME_FOR_RAW_PRODUCT
LOCATION 'oss://yourbucketname/VOLUME_FOR_RAW_PRODUCT'
USING connection hz_ingestion_demo -- storage Connection
DIRECTORY = (
enable = TRUE
)
recursive = TRUE;
--同步数据湖Volume的目录到Lakehouse
ALTER volume VOLUME_FOR_RAW_PRODUCT refresh;
--查看云器Lakehouse数据湖Volume上的文件
SELECT * from directory(volume VOLUME_FOR_RAW_PRODUCT);
创建Tables
创建 Tables,每个表将对应存储客户、产品和订单的原始数据。
新建SQL任务:RAW_CUSTOMER
-- Use our VCLUSTER and SCHEMA
USE VCLUSTER Three_Layer_DWH_VC;
USE SCHEMA Three_Layer_DWH_SCH;
-- Create the table to store customer data
CREATE TABLE IF NOT EXISTS raw_customer (
customer_id INT,
name STRING,
email STRING,
country STRING,
customer_type STRING,
registration_date STRING,
age INT,
gender STRING,
total_purchases INT,
ingestion_timestamp TIMESTAMP_NTZ DEFAULT CURRENT_TIMESTAMP()
);
新建SQL任务:RAW_ORDER
-- Use our VCLUSTER and SCHEMA
USE VCLUSTER Three_Layer_DWH_VC;
USE SCHEMA Three_Layer_DWH_SCH;
-- Create table to store order data
CREATE TABLE IF NOT EXISTS raw_order (
customer_id INT,
payment_method STRING,
product_id INT,
quantity INT,
store_type STRING,
total_amount DOUBLE,
transaction_date DATE,
transaction_id STRING,
ingestion_timestamp TIMESTAMP_NTZ DEFAULT CURRENT_TIMESTAMP()
);
新建SQL任务:RAW_PRODUCT
-- Use our VCLUSTER and SCHEMA
USE VCLUSTER Three_Layer_DWH_VC;
USE SCHEMA Three_Layer_DWH_SCH;
-- Create the table to store the the product data
CREATE TABLE IF NOT EXISTS raw_product (
product_id INT,
name STRING,
category STRING,
brand STRING,
price FLOAT,
stock_quantity INT,
rating FLOAT,
is_active BOOLEAN,
ingestion_timestamp TIMESTAMP_NTZ DEFAULT CURRENT_TIMESTAMP()
);
创建Pipes
创建 Pipes,每个 Pipe 将对应客户、产品和订单文件里的数据实时摄取到云器 Lakehouse 的原始表中。
新建SQL任务:PIPE_FOR_CUSTOMER
-- Use our VCLUSTER and SCHEMA
USE VCLUSTER Three_Layer_DWH_VC;
USE SCHEMA Three_Layer_DWH_SCH;
CREATE PIPE IF NOT EXISTS PIPE_FOR_CUSTOMER
VIRTUAL_CLUSTER = 'Three_Layer_DWH_VC'
--执行获取最新文件使用扫描文件模式
INGEST_MODE = 'LIST_PURGE'
AS
COPY INTO raw_customer FROM VOLUME VOLUME_FOR_RAW_CUSTOMER (
customer_id INT,
name STRING,
email STRING,
country STRING,
customer_type STRING,
registration_date STRING,
age INT,
gender STRING,
total_purchases INT,
ingestion_timestamp TIMESTAMP_NTZ
)
USING CSV OPTIONS (
'header'='true'
)
--必须添加purge参数导入成功后删除数据
PURGE=true
;
新建SQL任务:PIPE_FOR_ORDER
-- Use our VCLUSTER and SCHEMA
USE VCLUSTER Three_Layer_DWH_VC;
USE SCHEMA Three_Layer_DWH_SCH;
CREATE PIPE IF NOT EXISTS PIPE_FOR_ORDER
VIRTUAL_CLUSTER = 'Three_Layer_DWH_VC'
--执行获取最新文件使用扫描文件模式
INGEST_MODE = 'LIST_PURGE'
AS
COPY INTO raw_ORDER FROM VOLUME VOLUME_FOR_RAW_ORDER (
customer_id INT,
payment_method STRING,
product_id INT,
quantity INT,
store_type STRING,
total_amount DOUBLE,
transaction_date DATE,
transaction_id STRING,
ingestion_timestamp TIMESTAMP_NTZ
)
USING CSV OPTIONS (
'header'='true'
)
--必须添加purge参数导入成功后删除数据
PURGE=true
;
新建SQL任务:PIPE_FOR_PRODUCT
-- Use our VCLUSTER and SCHEMA
USE VCLUSTER Three_Layer_DWH_VC;
USE SCHEMA Three_Layer_DWH_SCH;
CREATE PIPE IF NOT EXISTS PIPE_FOR_PRODUCT
VIRTUAL_CLUSTER = 'Three_Layer_DWH_VC'
--执行获取最新文件使用扫描文件模式
INGEST_MODE = 'LIST_PURGE'
AS
COPY INTO raw_PRODUCT FROM VOLUME VOLUME_FOR_RAW_PRODUCT (
product_id INT,
name STRING,
category STRING,
brand STRING,
price FLOAT,
stock_quantity INT,
rating FLOAT,
is_active BOOLEAN,
ingestion_timestamp TIMESTAMP_NTZ
)
USING CSV OPTIONS (
'header'='true'
)
--必须添加purge参数导入成功后删除数据
PURGE=true
;
创建Table Streams
创建 Table Streams,每个 Stream 将检测原始表中的数据变化并将变化数据存储到 Table Stream 中。
新建SQL任务:CUSTOMER_CHANGES_STREAM
-- Use our VCLUSTER and SCHEMA
USE VCLUSTER Three_Layer_DWH_VC;
USE SCHEMA Three_Layer_DWH_SCH;
CREATE TABLE STREAM IF NOT EXISTS customer_changes_stream
ON TABLE raw_customer
WITH PROPERTIES ('TABLE_STREAM_MODE' = 'APPEND_ONLY');
新建SQL任务:ORDER_CHANGES_STREAM
-- Use our VCLUSTER and SCHEMA
USE VCLUSTER Three_Layer_DWH_VC;
USE SCHEMA Three_Layer_DWH_SCH;
CREATE TABLE STREAM IF NOT EXISTS order_changes_stream
ON TABLE raw_order
WITH PROPERTIES ('TABLE_STREAM_MODE' = 'APPEND_ONLY');
新建SQL任务:PRODUCT_CHANGES_STREAM
-- Use our VCLUSTER and SCHEMA
USE VCLUSTER Three_Layer_DWH_VC;
USE SCHEMA Three_Layer_DWH_SCH;
CREATE TABLE STREAM IF NOT EXISTS product_changes_stream
ON TABLE raw_product
WITH PROPERTIES ('TABLE_STREAM_MODE' = 'APPEND_ONLY');
开发Silver层

创建Tables
创建 Silver 层的 Tables,用来存储清洗转化过后的数据。
新建SQL任务:SILVER_CUSTOMER
-- Use our VCLUSTER and SCHEMA
USE VCLUSTER Three_Layer_DWH_VC;
USE SCHEMA Three_Layer_DWH_SCH;
-- Silver Customer Table
CREATE TABLE IF NOT EXISTS SILVER_CUSTOMER (
customer_id INT,
name STRING,
email STRING,
country STRING,
customer_type STRING,
registration_date DATE,
age INT,
gender STRING,
total_purchases INT,
last_updated_timestamp TIMESTAMP_NTZ DEFAULT CURRENT_TIMESTAMP()
);
新建SQL任务:SILVER_ORDERS
-- Use our VCLUSTER and SCHEMA
USE VCLUSTER Three_Layer_DWH_VC;
USE SCHEMA Three_Layer_DWH_SCH;
-- Silver Order Table
CREATE TABLE IF NOT EXISTS SILVER_ORDERS (
transaction_id STRING,
customer_id INT,
product_id INT,
quantity INT,
store_type STRING,
total_amount DOUBLE,
transaction_date DATE,
payment_method STRING,
last_updated_timestamp TIMESTAMP_NTZ DEFAULT CURRENT_TIMESTAMP()
);
新建SQL任务:SILVER_PRODUCT
-- Use our VCLUSTER and SCHEMA
USE VCLUSTER Three_Layer_DWH_VC;
USE SCHEMA Three_Layer_DWH_SCH;
-- Silver Product Table
CREATE TABLE IF NOT EXISTS SILVER_PRODUCT (
product_id INT,
name STRING,
category STRING,
brand STRING,
price FLOAT,
stock_quantity INT,
rating FLOAT,
is_active BOOLEAN,
last_updated_timestamp TIMESTAMP_NTZ DEFAULT CURRENT_TIMESTAMP()
);
开发数据转换的SQL任务
开发 SQL 任务,对原始数据进行清洗和转化。
新建 SQL 任务:CustomerTransform
-- Use our VCLUSTER and SCHEMA
USE VCLUSTER Three_Layer_DWH_VC;
USE SCHEMA Three_Layer_DWH_SCH;
-- Merge changes into silver layer
MERGE INTO silver_customer AS target
USING (
SELECT
customer_id,
name,
email,
country,
-- Customer type standardization
CASE
WHEN TRIM(UPPER(customer_type)) IN ('REGULAR', 'REG', 'R') THEN 'Regular'
WHEN TRIM(UPPER(customer_type)) IN ('PREMIUM', 'PREM', 'P') THEN 'Premium'
ELSE 'Unknown'
END AS customer_type,
-- Convert registration_date to DATE type for compatibility
CAST(registration_date AS DATE) AS registration_date,
-- Age validation
CASE
WHEN age BETWEEN 18 AND 120 THEN age
ELSE NULL
END AS age,
-- Gender standardization
CASE
WHEN TRIM(UPPER(gender)) IN ('M', 'MALE') THEN 'Male'
WHEN TRIM(UPPER(gender)) IN ('F', 'FEMALE') THEN 'Female'
ELSE 'Other'
END AS gender,
-- Total purchases validation
CASE
WHEN total_purchases >= 0 THEN total_purchases
ELSE 0
END AS total_purchases,
current_timestamp() AS last_updated_timestamp
FROM customer_changes_stream
WHERE customer_id IS NOT NULL AND email IS NOT NULL -- Basic data quality rule
) AS source
ON target.customer_id = source.customer_id
WHEN MATCHED THEN
UPDATE SET
name = source.name,
email = source.email,
country = source.country,
customer_type = source.customer_type,
registration_date = source.registration_date,
age = source.age,
gender = source.gender,
total_purchases = source.total_purchases,
last_updated_timestamp = source.last_updated_timestamp
WHEN NOT MATCHED THEN
INSERT (customer_id, name, email, country, customer_type, registration_date, age, gender, total_purchases, last_updated_timestamp)
VALUES (source.customer_id, source.name, source.email, source.country, source.customer_type, source.registration_date, source.age, source.gender, source.total_purchases, source.last_updated_timestamp);
新建SQL任务:VOLUME_FOR_RAW_ORDER
-- Use our VCLUSTER and SCHEMA
USE VCLUSTER Three_Layer_DWH_VC;
USE SCHEMA Three_Layer_DWH_SCH;
MERGE INTO silver_orders AS target
USING (
SELECT
transaction_id,
customer_id,
product_id,
quantity,
store_type,
total_amount,
transaction_date,
payment_method,
CURRENT_TIMESTAMP() AS last_updated_timestamp
FROM order_changes_stream where transaction_id is not null
and total_amount> 0) AS source
ON target.transaction_id = source.transaction_id
WHEN MATCHED THEN
UPDATE SET
customer_id = source.customer_id,
product_id = source.product_id,
quantity = source.quantity,
store_type = source.store_type,
total_amount = source.total_amount,
transaction_date = source.transaction_date,
payment_method = source.payment_method,
last_updated_timestamp = source.last_updated_timestamp
WHEN NOT MATCHED THEN
INSERT (transaction_id, customer_id, product_id, quantity, store_type, total_amount, transaction_date, payment_method, last_updated_timestamp)
VALUES (source.transaction_id, source.customer_id, source.product_id, source.quantity, source.store_type, source.total_amount, source.transaction_date, source.payment_method, source.last_updated_timestamp);
新建SQL任务:VOLUME_FOR_RAW_PRODUCT
-- Use our VCLUSTER and SCHEMA
USE VCLUSTER Three_Layer_DWH_VC;
USE SCHEMA Three_Layer_DWH_SCH;
MERGE INTO silver_product AS target
USING (
SELECT
product_id,
name AS name,
category,
-- Price validation and normalization
CASE
WHEN price < 0 THEN 0
ELSE price
END AS price,
brand,
-- Stock quantity validation
CASE
WHEN stock_quantity >= 0 THEN stock_quantity
ELSE 0
END AS stock_quantity,
-- Rating validation
CASE
WHEN rating BETWEEN 0 AND 5 THEN rating
ELSE 0
END AS rating,
is_active,
CURRENT_TIMESTAMP() AS last_updated_timestamp
FROM product_changes_stream
) AS source
ON target.product_id = source.product_id
WHEN MATCHED THEN
UPDATE SET
name = source.name,
category = source.category,
price = source.price,
brand = source.brand,
stock_quantity = source.stock_quantity,
rating = source.rating,
is_active = source.is_active,
last_updated_timestamp = source.last_updated_timestamp
WHEN NOT MATCHED THEN
INSERT (product_id, name, category, price, brand, stock_quantity, rating, is_active, last_updated_timestamp)
VALUES (source.product_id, source.name, source.category, source.price, source.brand, source.stock_quantity, source.rating, source.is_active, source.last_updated_timestamp);
开发Gold层

开发动态表
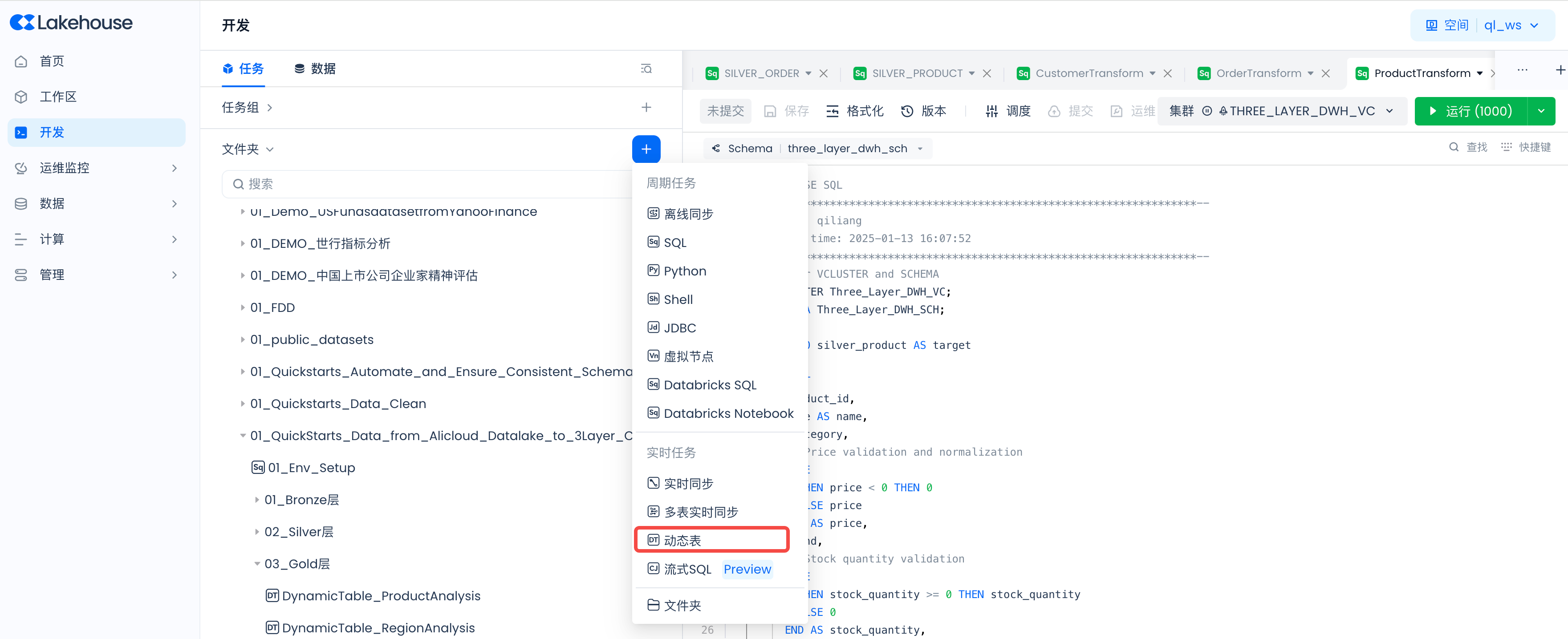
开发动态表,对数据进行业务分析。
新建动态表:DynamicTable_ProductAnalysis
SELECT
p.CATEGORY,
c.GENDER,
SUM(o.TOTAL_AMOUNT) AS TOTAL_SALES,
AVG(p.RATING) AS AVG_RATING
FROM SILVER_ORDERS AS o
JOIN SILVER_PRODUCT AS p
ON o.product_id = p.product_id
JOIN SILVER_CUSTOMER AS c
ON o.customer_id = c.customer_id
GROUP BY
P.CATEGORY,
C.GENDER
ORDER BY
c.GENDER,
TOTAL_SALES DESC;
新建动态表:DynamicTable_RegionAnalysis
SELECT
CASE
WHEN c.COUNTRY IN ('USA', 'Canada') THEN 'NA'
WHEN c.COUNTRY IN ('Brazil') THEN 'SA'
WHEN c.COUNTRY IN ('Australia') THEN 'AUS'
WHEN c.COUNTRY IN ('Germany', 'UK', 'France') THEN 'EU'
WHEN c.COUNTRY IN ('China', 'India', 'Japan') THEN 'ASIA'
ELSE 'UNKNOWN'
END AS REGION,
o.STORE_TYPE,
SUM(o.TOTAL_AMOUNT) AS TOTAL_SALES,
AVG(o.TOTAL_AMOUNT) AS AVG_SALE,
AVG(o.QUANTITY) AS AVG_QUANTITY
FROM SILVER_ORDERS AS o
JOIN SILVER_PRODUCT AS p
ON o.product_id = p.product_id
JOIN SILVER_CUSTOMER AS c
ON o.customer_id = c.customer_id
GROUP BY
REGION,
o.STORE_TYPE
ORDER BY
TOTAL_SALES DESC,
AVG_SALE DESC,
AVG_QUANTITY DESC;
启动Silver层数据转换任务按周期执行
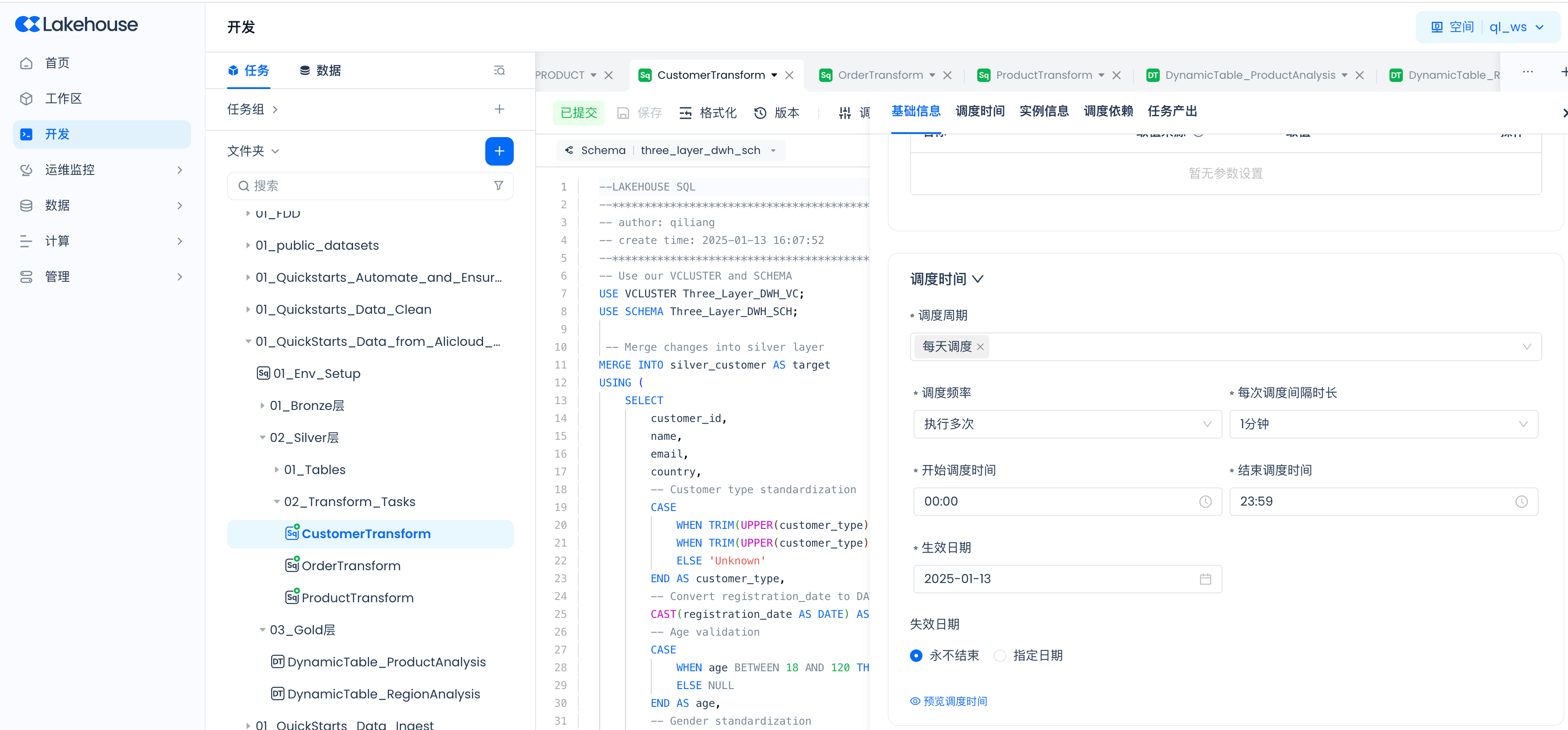
按照如下步骤对 Silver 层的三个数据转换任务按照一分钟周期调度。
设置调度参数:
然后提交:
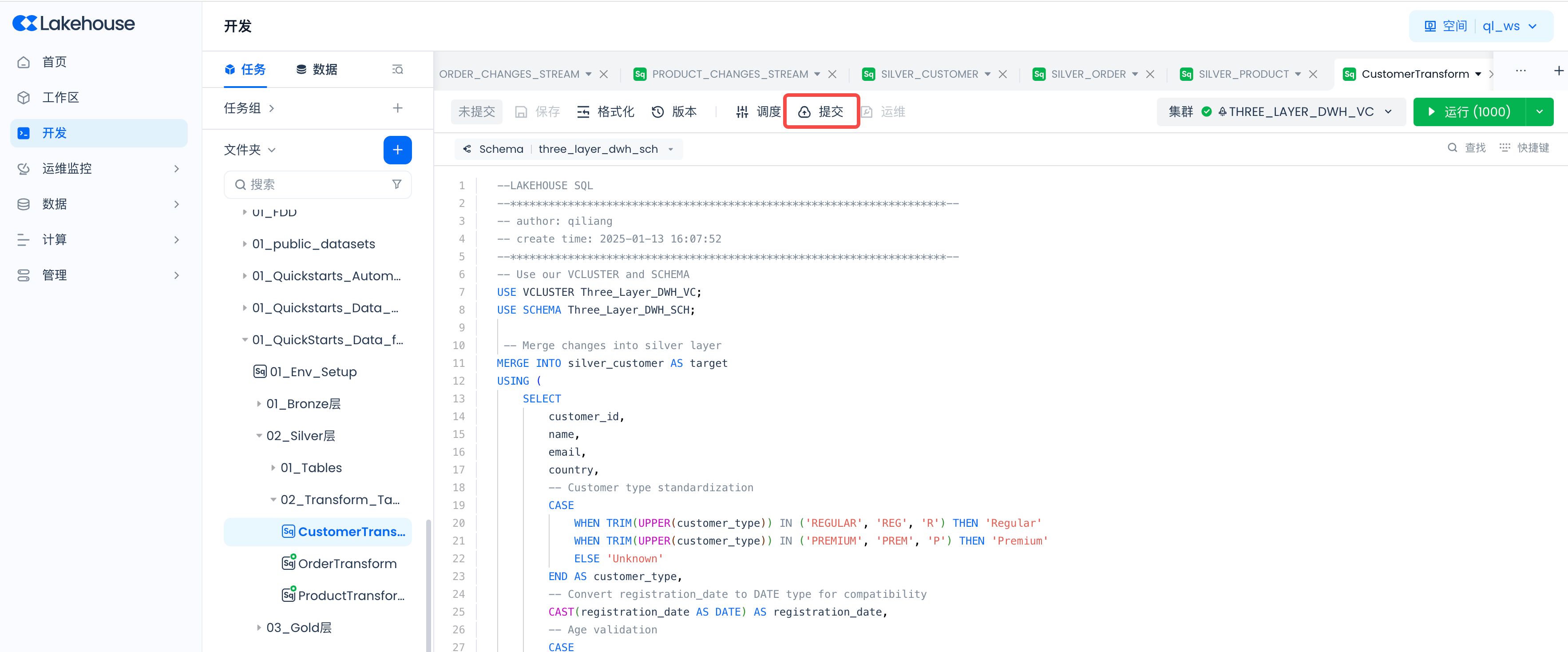
确保重复上述步骤,对三个数据转换任务都进行了调度设置并启动。
调度周期你可以设置为 1 分钟,这样就可以确保在 1 分钟左右就能在 Silver 层的表里看到数据。
启动Gold层动态表自动刷新
按照如下步骤启动动态表。
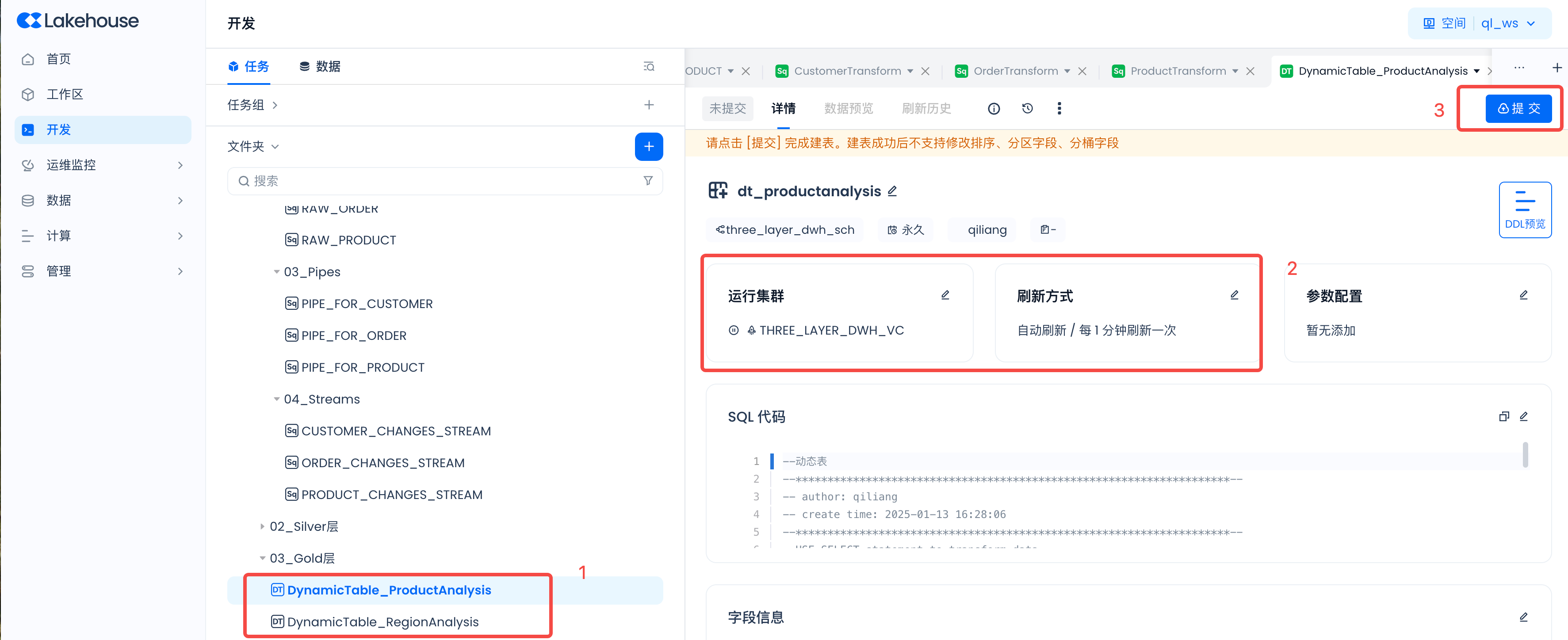
将运行集群设置为“Three_Layer_DWH_VC”,刷新方式设置为“自动刷新”,刷新间隔设置为“1分钟”。然后提交。
检查对象创建结果
导航到开发->任务,新建一个SQL任务“09_测试验证”
SHOW tables;
SHOW volumes;
SHOW pipes;
SHOW table streams;
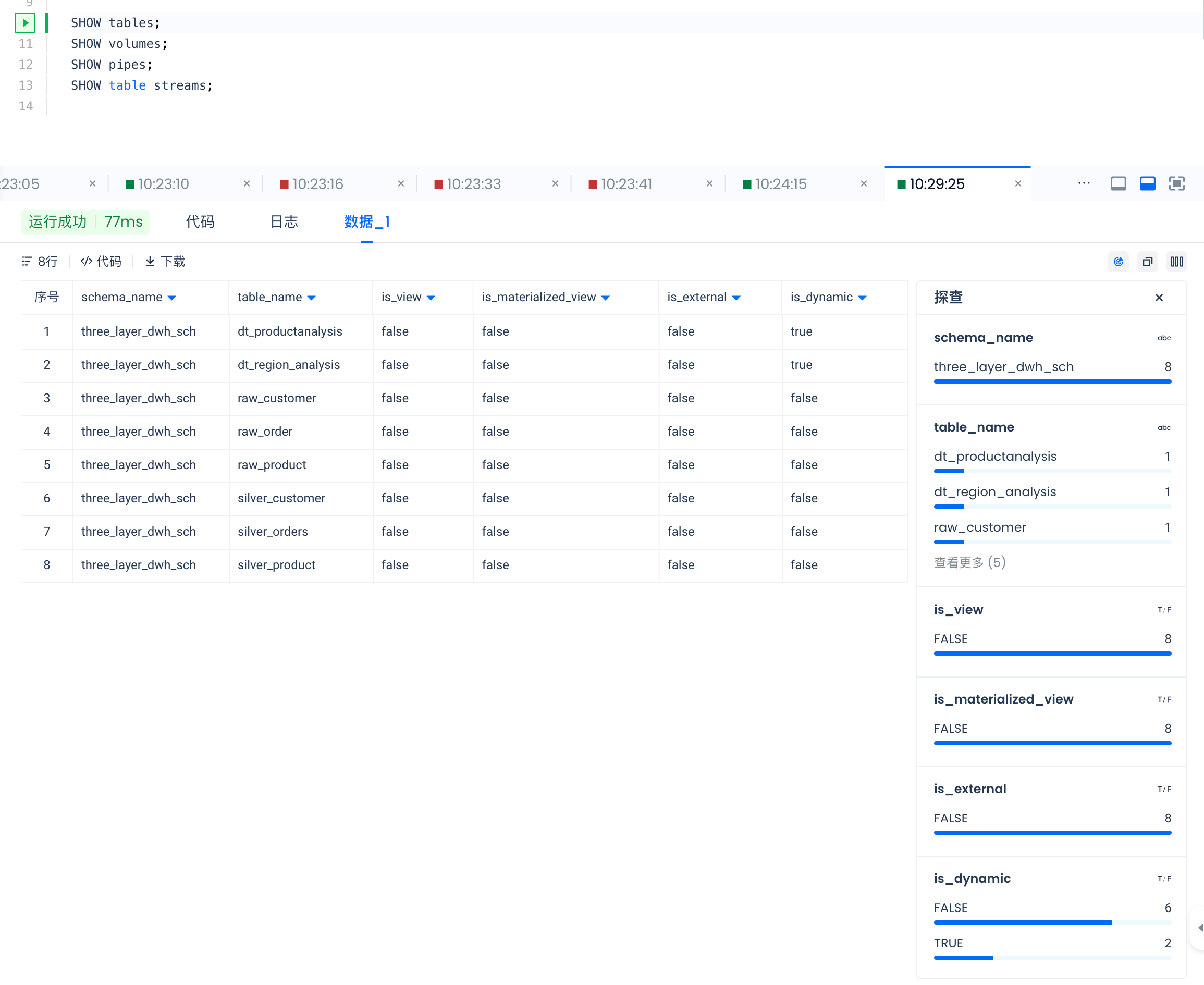
SHOW tables 结果如下:
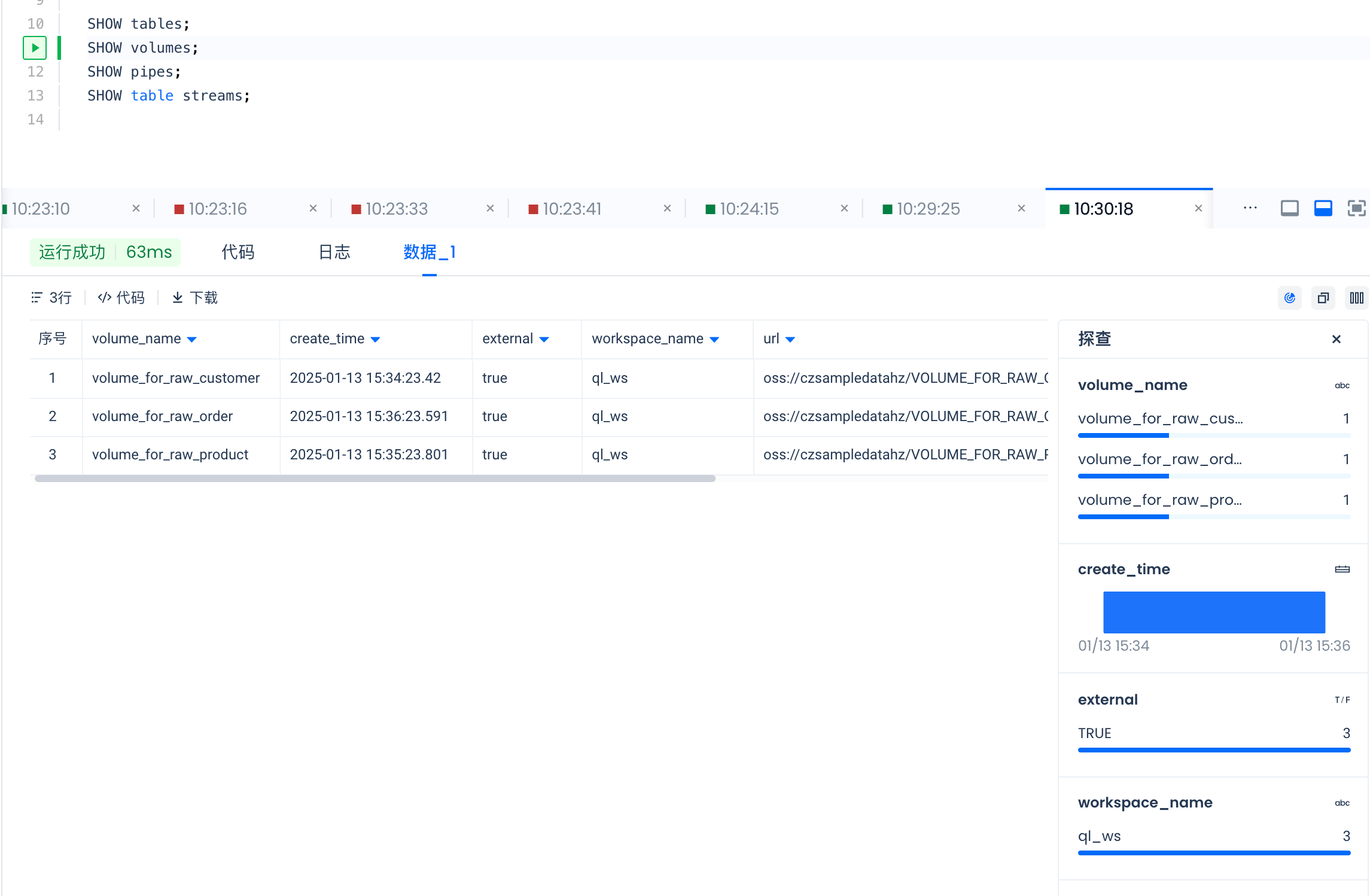
SHOW volumes 结果如下:
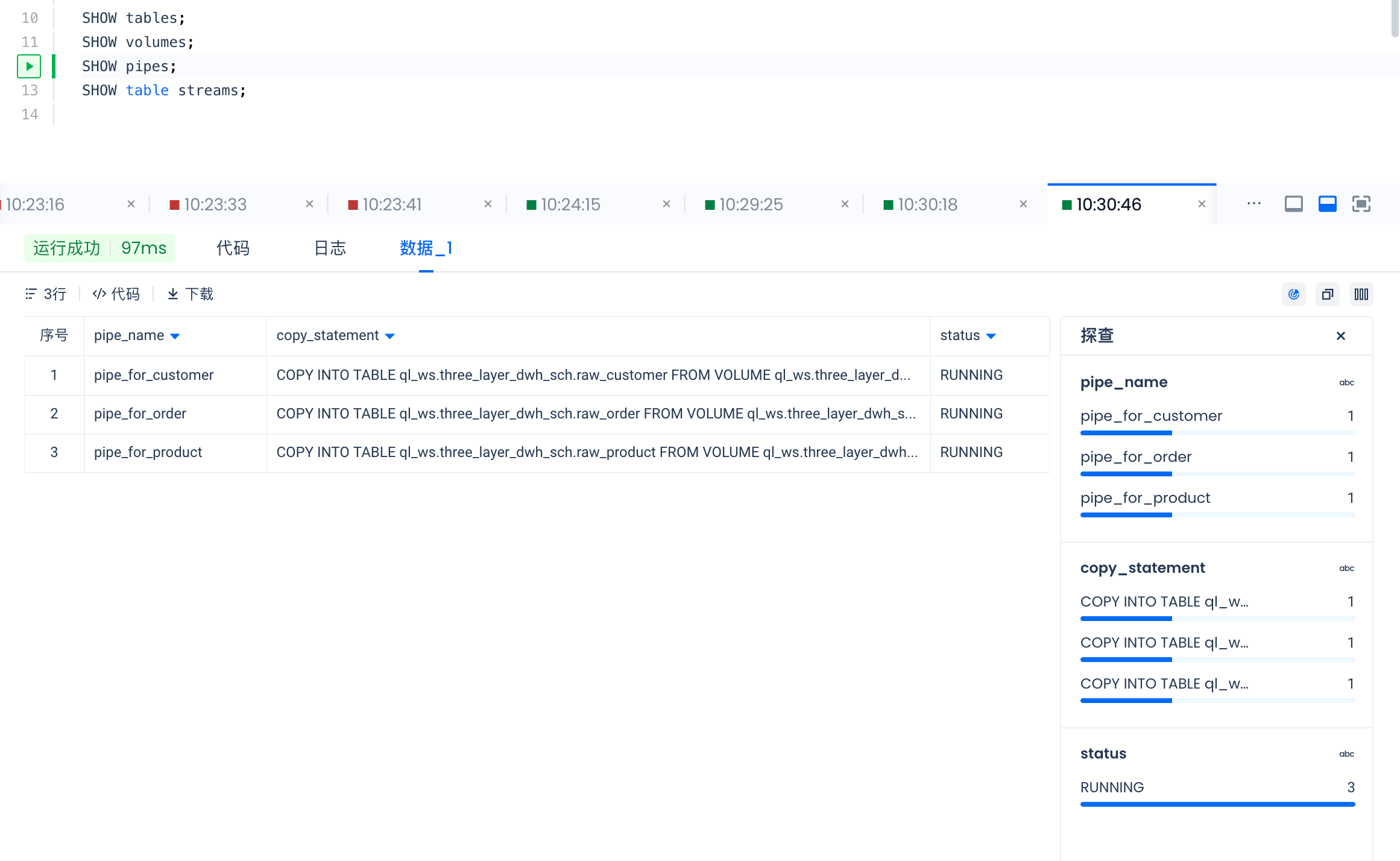
SHOW pipes 结果如下:
SHOW table streams 结果如下:
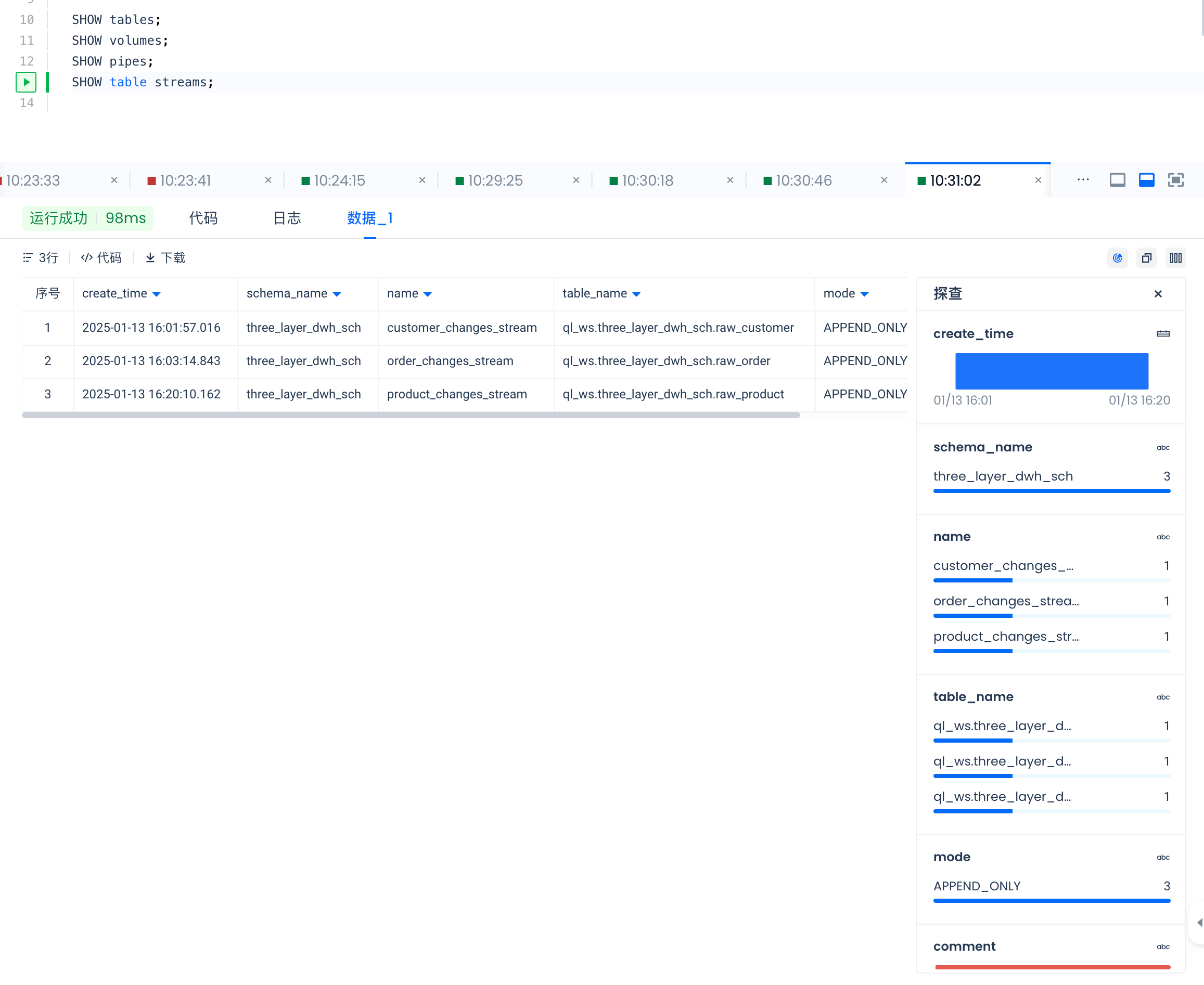
通过如下命令查看各个对象的详细信息:
DESC TABLE EXTENDED raw_customer;
DESC VOLUME volume_for_raw_customer;
DESC PIPE pipe_for_customer;
DESC TABLE STREAM customer_changes_stream;
DESC TABLE EXTENDED dt_productanalysis;
产生测试数据并PUT到数据湖上
from faker import Faker
import csv
import uuid
import random
from decimal import Decimal
from datetime import datetime
from clickzetta.zettapark.session import Session
import json
fake = Faker()
file_path = f'FakeDataset'
# 创建csv文件的函数,根据不同的表生成相应内容
def create_csv_file(file_path, table_name, record_count):
with open(file_path, 'w', newline='') as csvfile:
if table_name == "raw_customer":
fieldnames = ["customer_id", "name", "email", "country", "customer_type",
"registration_date", "age", "gender", "total_purchases", "ingestion_timestamp"]
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for i in range(1, record_count + 1):
writer.writerow(
{
"customer_id": i,
"name": fake.name(),
"email": fake.email(),
"country": fake.country(),
"customer_type": fake.random_element(elements=("Regular", "Premium", "VIP")),
"registration_date": fake.date(),
"age": fake.random_int(min=18, max=120),
"gender": fake.random_element(elements=("Male", "Female", "Other")),
"total_purchases": fake.random_int(min=0, max=1000),
"ingestion_timestamp": fake.date_time_this_year().isoformat()
}
)
elif table_name == "raw_product":
fieldnames = ["product_id", "name", "category", "brand", "price",
"stock_quantity", "rating", "is_active", "ingestion_timestamp"]
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for i in range(1, record_count + 1):
writer.writerow(
{
"product_id": i,
"name": fake.word(),
"category": fake.word(),
"brand": fake.company(),
"price": round(fake.random_number(digits=5, fix_len=False), 2),
"stock_quantity": fake.random_int(min=0, max=1000),
"rating": round(fake.random_number(digits=2, fix_len=True) / 10, 1),
"is_active": fake.boolean(),
"ingestion_timestamp": fake.date_time_this_year().isoformat()
}
)
elif table_name == "raw_order":
fieldnames = ["customer_id", "payment_method", "product_id", "quantity",
"store_type", "total_amount", "transaction_date",
"transaction_id", "ingestion_timestamp"]
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for _ in range(record_count):
writer.writerow(
{
"customer_id": fake.random_int(min=1, max=100),
"payment_method": fake.random_element(elements=("Credit Card", "PayPal", "Bank Transfer")),
"product_id": fake.random_int(min=1, max=100),
"quantity": fake.random_int(min=1, max=10),
"store_type": fake.random_element(elements=("Online", "Physical")),
"total_amount": round(fake.random_number(digits=5, fix_len=False), 2),
"transaction_date": fake.date(),
"transaction_id": str(uuid.uuid4()),
"ingestion_timestamp": fake.date_time_this_year().isoformat()
}
)
def put_file_into_volume(filename,volumename):
# 从配置文件中读取参数
with open('security/config-uat-3layer-dwh.json', 'r') as config_file:
config = json.load(config_file)
# 创建会话
session = Session.builder.configs(config).create()
session.file.put(filename,f"volume://{volumename}/")
session.sql(f"show volume directory {volumename}").show()
session.close()
# 第一次调用:
current_time = datetime.now().strftime("%Y%m%d%H%M%S")
print(current_time)
if __name__ == '__main__':
# 示例调用
create_csv_file(f"{file_path}/customer/raw_customer_{current_time}.csv", "raw_customer", 100)
put_file_into_volume(f"{file_path}/customer/raw_customer_{current_time}.csv","VOLUME_FOR_RAW_CUSTOMER")
create_csv_file(f"{file_path}/product/raw_product_{current_time}.csv", "raw_product", 100)
put_file_into_volume(f"{file_path}/product/raw_product_{current_time}.csv","VOLUME_FOR_RAW_PRODUCT")
create_csv_file(f"{file_path}/order/raw_order_{current_time}.csv", "raw_order", 10000)
put_file_into_volume(f"{file_path}/order/raw_order_{current_time}.csv","VOLUME_FOR_RAW_ORDER")
# 第二次调用:只生成订单数据
current_time = datetime.now().strftime("%Y%m%d%H%M%S")
print(current_time)
if __name__ == '__main__':
create_csv_file(f"{file_path}/order/raw_order_{current_time}.csv", "raw_order", 100000)
put_file_into_volume(f"{file_path}/order/raw_order_{current_time}.csv","VOLUME_FOR_RAW_ORDER")
第一次调用生成产品、客户、订单的数据。第二次及更多次调用,只需要生成订单新数据即可。可以多次执行上传多个订单文件。
注意每次 PUT 到 Volume 上的文件被 Pipe 消费后,会被自动删除。
资料
Connection
External Volume
Pipe
Table Stream
Merge Into
动态表Dynamic Table
