Pipe 对象存储导入
Pipe 是 Lakehouse 平台中的一项强大数据导入功能,它允许用户以固定频率直接从对象存储中读取数据并导入到 Lakehouse。通过实现文件检测机制,Pipe 支持以微批处理方式加载文件,使得用户能够迅速访问最新数据。特别适合需要实时或近实时数据处理的场景。
对象存储 Pipe 像一个持续扫描收件箱的程序——你只要把文件上传到 OSS/S3/COS,它自动检测并导入,无需任何人工触发。
Pipe 工作原理
文件检测 :
EVENT_NOTIFICATION_MODE :需要开通消息服务,利用阿里云消息服务通知Lakehouse新文件的上传,目前只支持阿里云OSS和AWS S3。LIST_PURGE模式 :定期扫描目录,同步未记录的文件,并在同步后删除原文件。
COPY 语句 :定义数据文件的源位置和目标表,支持多种文件格式。
自动化加载 :自动检测新文件并执行COPY语句。
避免导入重复机制 :为了避免重复导入,load_history函数记录了当前表的copy导入历史文件。Pipe在执行时会根据load_history表名和导入文件名称去重,确保不会重复导入已有的文件。如果需要导入已记录的文件,可以手动执行copy命令。load_history记录目前会保留7天。
Pipe导入作业历史 :由于每次都是Pipe下发copy执行,你可以在作业历史中查看所有操作。通过作业历史中的query_tag来筛选,所有的pipe执行的copy作业都会在query_tag打上标签,格式为
pipe.``workspace_name``.schema_name.pipe_namepipe.``workspace_name``.schema_name.pipe_name
,方便追踪和管理。
使用场景
实时数据同步 :当你的数据存储在对象存储中,且需要频繁同步以及时获取最新数据。成本优化 :在对象存储上进行数据导入导出可以避免产生网络公网流量费用。特别是在相同region下,可以指定对象存储为内网传输,进一步降低成本。
注意事项
使用EVENT_NOTIFICATION_MODE时,需要使用role arn授权方式创建存储连接。
LIST_PURGE模式支持密钥和role arn两种授权方式。
文件大小推荐 :gzip 压缩文件建议在 50MB。CSV、PARQUET 未压缩文件建议在 128MB 到 256MB 之间。数据加载顺序 :数据加载无法保证严格有序 。Pipe 延迟 :Pipe加载时间受多种因素影响,包括文件格式、大小和COPY语句的复杂性。Pipe 与 Volume 对应关系 : 每个 Pipe 需对应独立的 Volume,不可复用。
成本
根据加载文件时使用的计算资源计费。
PIPE语法
-- 从对象存储创建Pipe的语法
CREATE PIPE [ IF NOT EXISTS ] <pipe_name>
VIRTUAL_CLUSTER = 'virtual_cluster_name'
INGEST_MODE='LIST_PURGE'|'EVENT_NOTIFICATION'
[COPY_JOB_HINT='']
AS <copy_statement>;
<pipe_name><pipe_name>
:你要创建的Pipe对象的名称。
VIRTUAL_CLUSTERVIRTUAL_CLUSTER
:指定虚拟集群的名称。
INGEST_MODEINGEST_MODE
:确定数据导入模式,二选一:
LIST_PURGELIST_PURGE
:定期轮询扫描目录 — 配置简单,适合大多数场景;导入成功后会删除源文件(不可恢复) EVENT_NOTIFICATIONEVENT_NOTIFICATION
:收到对象存储事件通知后立即触发 — 适合需要近实时导入且不能删除源文件的场景;需要额外配置 MNS 队列
⚠️ 警告 :
LIST_PURGELIST_PURGE
模式会在导入成功后
永久删除 对象存储中的源文件。如果需要保留原始文件,请使用
EVENT_NOTIFICATIONEVENT_NOTIFICATION
模式。
COPY_JOB_HINTCOPY_JOB_HINT
:可选,Lakehouse保留参数
copy_statement:
<copy_statement><copy_statement>
支持 中的中的文件参数都支持。当设置 ON_ERROR=CONTINUE|ABORTON_ERROR=CONTINUE|ABORT
参数时,可控制数据加载过程中遇到错误时的处理策略,且添加该参数后会返回导入文件列表:
CONTINUECONTINUE
:跳过错误行,继续加载后续数据。适用于容忍部分错误,且要求最大限度完成数据加载的场景。目前,可忽略的错误仅限于文件不格式匹配的情况,例如命令中指定为 zip 压缩格式,而文件中存在 zstd 压缩格式。ABORTABORT
:立即终止整个COPYCOPY
操作。适用于数据质量要求严格,任何错误都需要人工介入检查的场景。
支持的文件格式
参考COPY INTO导入 。
使用PIPE加载案例
使用扫描文件模式
具体使用步骤
步骤 1: 创建 connection 和 volume
--创建连接用来连接对象存储
CREATE STORAGE CONNECTION if not exists my_connection_exnet
TYPE OSS
ENDPOINT = 'oss-cn-hangzhou.aliyuncs.com'
ACCESS_KEY = 'LTAI5tMmbq1Ty1xxxxxxxxx'
SECRET_KEY = '0d7Ap1VBuFTzNg7gxxxxxxxxxxxx'
COMMENT = 'OSS public endpoint';
--创建volume, 用于映射对象存储目录
CREATE EXTERNAL VOLUME pipe_volume
location 'oss://ossmy/autoloader/pipe/'
using connection my_connection_exnet
directory = (
enable=true,
auto_refresh=true
)
recursive=true;
步骤 2: 单独执行copy命令看是否可以导入成功
copy into pipe_purge_mode from volume pipe_volume(id int,col string)
using csv OPTIONS(
'header'='false'
) ;
步骤 3: 使用上面的语句构建pipe对象
create pipe volume_pipe_list_purge
VIRTUAL_CLUSTER = 'DEFAULT'
--执行获取最新文件使用扫描文件模式
INGEST_MODE = 'LIST_PURGE'
as
copy into pipe_purge_mode from volume pipe_volume(id int,col string)
using csv OPTIONS(
'header'='false'
)
--必须添加purge参数导入成功后删除数据
purge=true
;
步骤 4: 查看pipe执行历史和已经导入的文件
通过作业历史中的query_tag来筛选,所有的pipe执行的copy作业都会在query_tag打上标签:格式为pipe.worksapce_name.schema_name.pipe_name
select * from load_history('schema_name.table_name');
使用消息服务通知模式(只支持阿里云OSS和AWS S3)
步骤 1: 开通阿里云消息服务 (MNS)
在阿里云控制台中开通消息服务 MNS。
配置 MNS 监听要同步的 OSS (Object Storage Service) 文件夹。具体参考文档
步骤 2: 授权 Lakehouse 读取 OSS
具体方式参考使用role arn方式阿里云存储连接创建 授权 Lakehouse 读取对应 OSS Bucket 的权限。
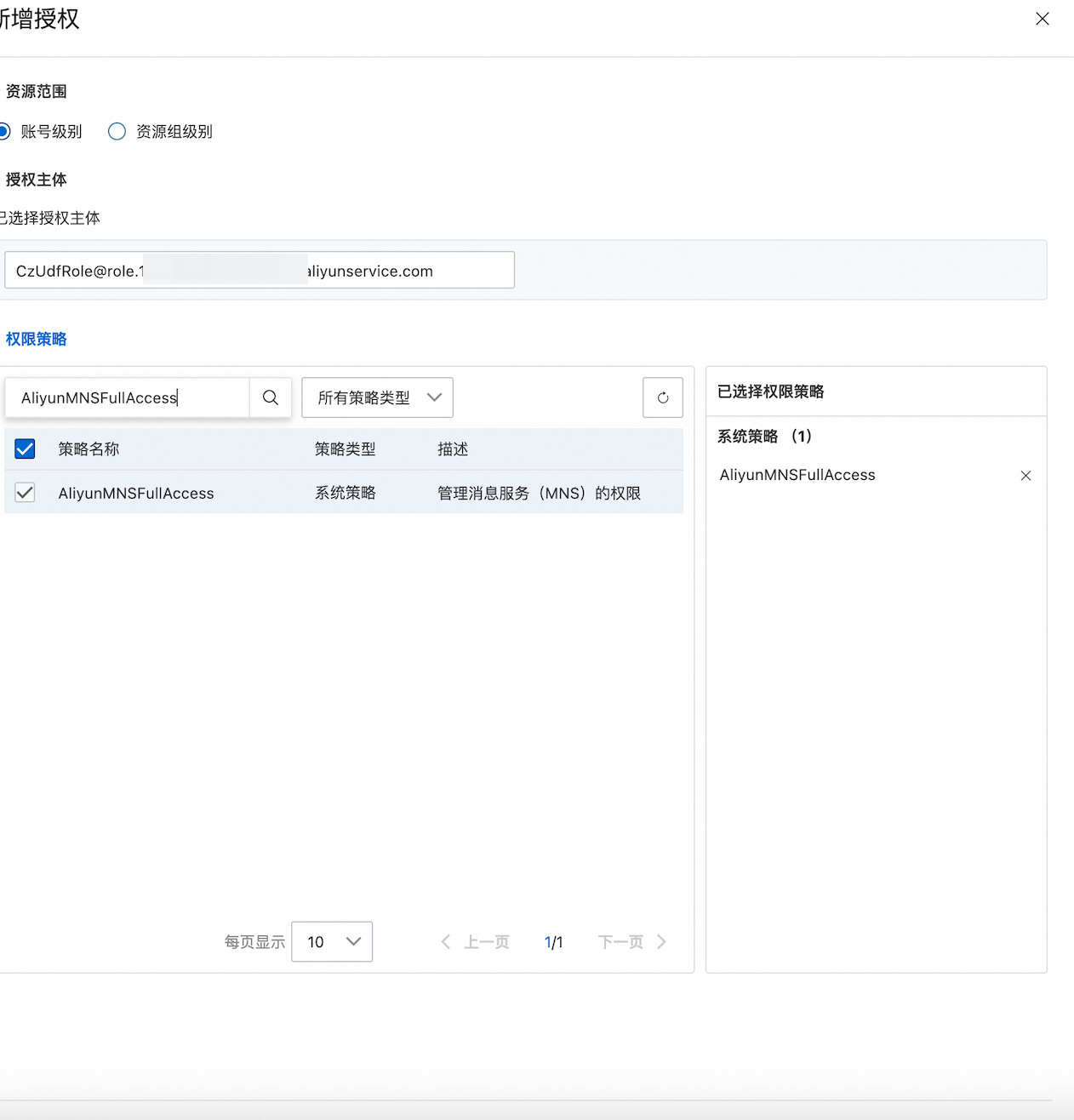
步骤 3: 授权 MNS 给 Lakehouse
在阿里云 RAM 控制台中,将 `AliyunMNSFullAccess` 权限授权给步骤二中的 Role,步骤二中案例为CzUDFRole
步骤 4: 创建 Storage Connection
CREATE STORAGE CONNECTION my_connection_exnet_role
TYPE oss
REGION = 'cn-hangzhou' -- 根据 OSS 所在的区域选择
ROLE_ARN = 'acs:ram::...:role/czudfrole' -- 替换为你的 Role ARN
ENDPOINT = 'oss-cn-hangzhou.aliyuncs.com'; -- 根据 OSS 所在的区域选择 Endpoint
步骤 5: 创建 Volume
CREATE EXTERNAL VOLUME my_volume_exnet_role
LOCATION 'oss://function-compute-my1/autoloader' -- 替换为 OSS Bucket 的路径
USING connection my_connection_exnet_role
DIRECTORY = (
enable = TRUE,
auto_refresh = TRUE
)
RECURSIVE = TRUE;
步骤 6: 创建 Pipe
CREATE PIPE my_pipe
VIRTUAL_CLUSTER='TEST_VC'
ALICLOUD_MNS_QUEUE = 'lakehouse-oss-event-queue' -- 使用创建的 MNS 队列
AS
COPY INTO pipe_log_json FROM (
SELECT parse_json(col) json_col
FROM volume my_volume_exnet_role(col string)
USING csv
OPTIONS ('header' = 'false', 'sep' = '\001', 'quote' = '\0')
);
状态监控与管理
查看Pipe状态
DESC PIPE EXTENDED kafka_pipe_stream
+--------------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| info_name | info_value |
+--------------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| name | kafka_pipe_stream |
| creator | UAT_TEST |
| created_time | 2025-03-05 10:40:55.405 |
| last_modified_time | 2025-03-05 10:40:55.405 |
| comment | |
| properties | ((virtual_cluster,test_alter)) |
| copy_statement | COPY INTO TABLE qingyun.pipe_schema.kafka_sink_table_1 FROM (SELECT `current_timestamp`() AS ```current_timestamp``()`, CAST(kafka_table_stream_pipe1.`value` AS string) AS `value` |
| pipe_status | RUNNING |
| output_name | xxxxxxx.pipe_schema.kafka_sink_table_1 |
| input_name | kafka_table_stream:xxxxxxx.pipe_schema.kafka_table_stream_pipe1 |
| invalid_reason | |
| pipe_latency | {"kafka":{"lags":{"0":0,"1":0,"2":0,"3":0},"lastConsumeTimestamp":-1,"offsetLag":0,"timeLag":-1}} |
+--------------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
查看Pipe运行历史
由于每次都是Pipe下发copy执行,你可以在作业历史中查看所有操作。通过作业历史 中的query_tag来筛选,所有的pipe执行的copy作业都会在query_tag打上标签,格式为
pipe.``workspace_name``.schema_name.pipe_namepipe.``workspace_name``.schema_name.pipe_name
,方便追踪和管理。
停止和启动Pipe
ALTER PIPE pipe_name SET PIPE_EXECUTION_PAUSED = true;
ALTER PIPE pipe_name SET PIPE_EXECUTION_PAUSED = false
修改Pipe属性
你可以修改 PIPE 的属性,但每次只能修改一个属性。如果需要修改多个属性,则需要多次执行
ALTERALTER
命令。以下是可修改的属性及其语法:
ALTER PIPE pipe_name SET
[VIRTUAL_CLUSTER = 'virtual_cluster_name']
[BATCH_INTERVAL_IN_SECONDS='']
[BATCH_SIZE_PER_KAFKA_PARTITION='']
[MAX_SKIP_BATCH_COUNT_ON_ERROR='']
[RESET_KAFKA_GROUP_OFFSETS='']
[COPY_JOB_HINT='']
案例
--修改计算集群
ALTER PIPE pipe_name SET VIRTUAL_CLUSTER = 'DEFAULT'
--设置COPY_JOB_HINT
ALTER PIPE pipe_name SET COPY_JOB_HINT='{"cz.mapper.kafka.message.size": "2000000"}'