Lakehouse作业历史
通过作业历史页面,你可以查看过去 7 天内在 Lakehouse 帐户中执行的查询的详细信息。该页面显示查询的历史作业列表,包括使用 JDBC jar 提交的任务、Studio 临时查询、Studio 周期调度任务。
作业历史
查看历史记录
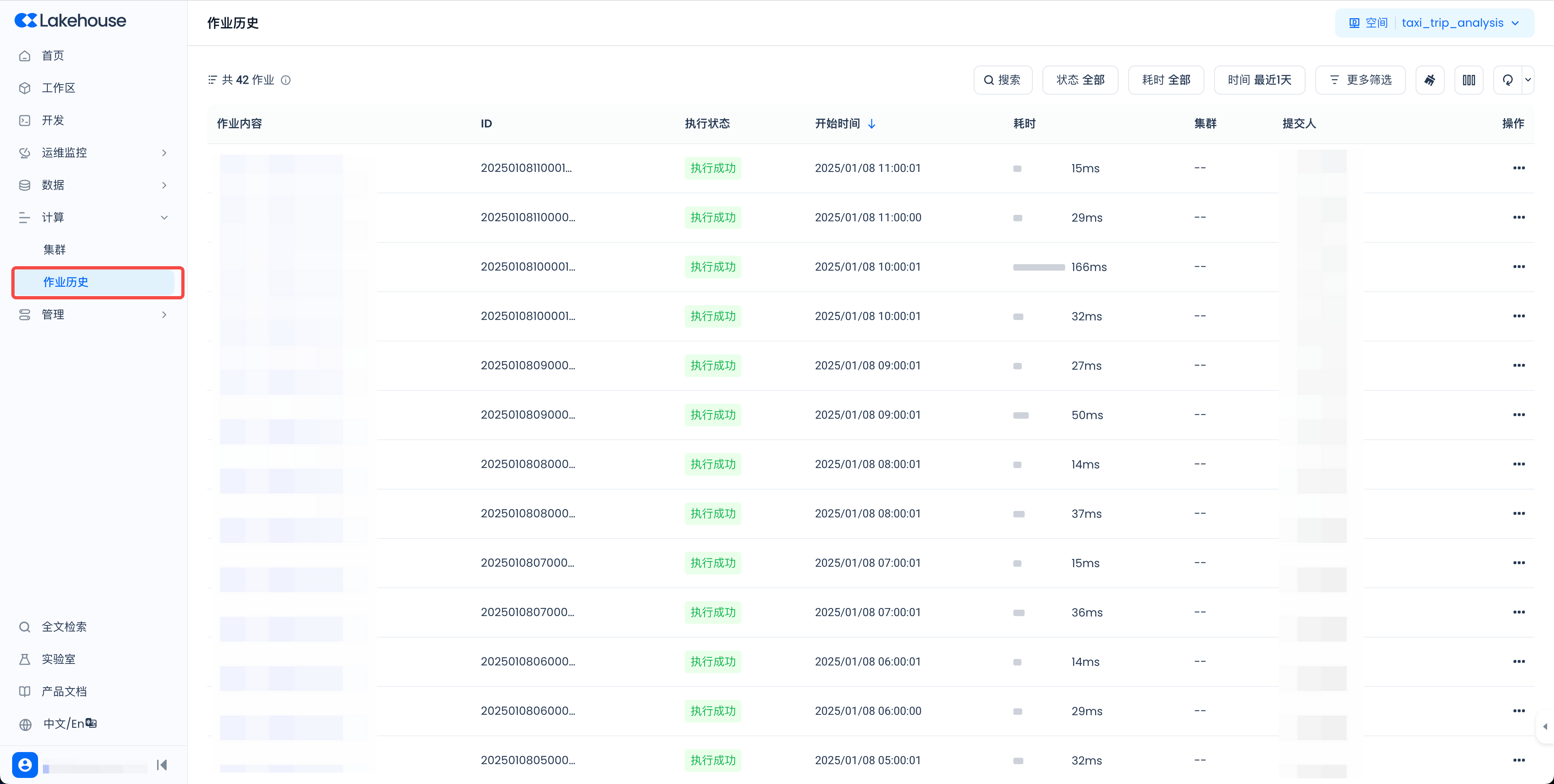
通过左侧导航栏点击“计算”,再点击“作业历史”,可以进入作业历史页面:
界面
- 支持根据SQL作业产生的作业ID进行搜索
- 支持根据状态搜索
- 初始化:SQL初始化阶段,包含编译优化等操作
- 集群启动中:等待启动vc耗时,如果长时间未拉起请联系技术支持
- 等待执行:作业排队等待资源,如果耗时较长建议查看vc资源是否占满,建议扩容vc
- 正在执行:SQL处理数据时间,可以点到诊断查看每个算子耗时
- 执行成功:运行结束,部分作业可能在这一阶段清理过程,会产生耗时
- 支持按耗时筛选
- 支持按时间筛选,目前最多能查询到近七天的一万条作业
- 支持按照作业运行的集群名称进行筛选
- 支持按照作业的提交人进行筛选
- 支持根据 queryTag 筛选
用户在提交 SQL 的时候可以通过命令
用来表示作业来源和给作业打标,并且在这个界面方便过滤。set query_tag=""- 在studio界面设置query_tag,选中两条SQL同时执行
- 在jdbc url中添加query_tag,这样提交的每条SQL都会带上query_tag用来标示来源,可以在页面中进行过滤
- python代码中设置query_tag
- 作业的默认 Schema,提交 SQL 时运行的上下文环境,可以通过
获取。select current_schema()
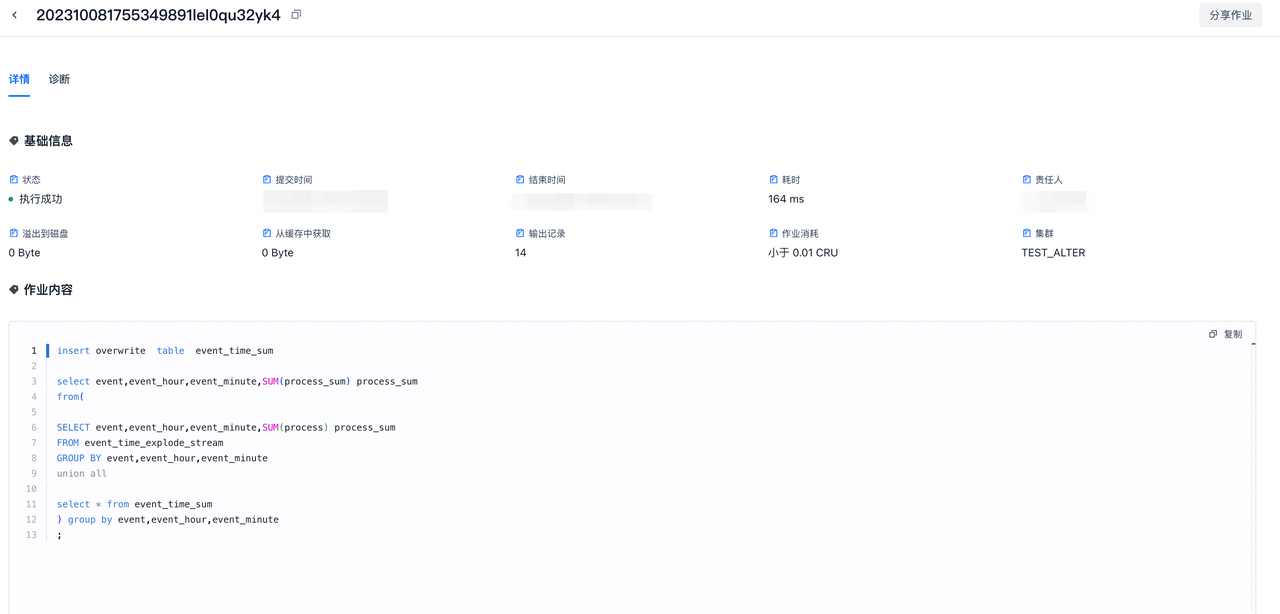
作业详情
进入作业详情可以查看作业的详细信息。
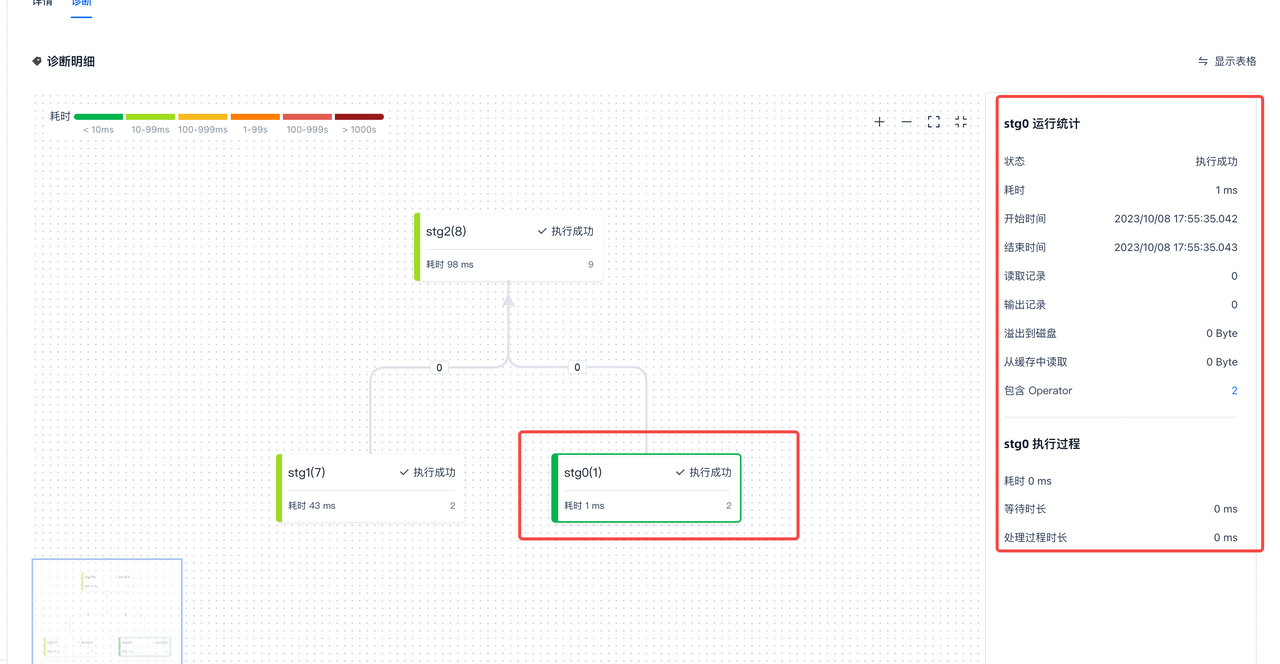
stage界面
SQL执行划分成每个stage,stage由下往上执行。点击具体的stage可以看到每个stage的具体耗时
字段信息解释如下
| 字段 | 描述 |
| 状态 | 表示作业的状态,当前包含 等待执行:等待资源 正在执行:正在运行,作业正在处理数据 执行成功:作业运行成功 执行失败:作业运行失败 |
| 开始时间 | stage的开始时间,在分析型集群stage会同时运行 |
| 结束时间 | 作业运行结束时间 |
| 耗时 | stage运行耗时时长 |
| 溢出到磁盘 | 溢出到磁盘的数据大小,此参数可以了解到是否是因为集群内存资源不够导致性能慢 |
| 从缓存中读取 | 在分析型集群中,已经读取的数据会先cache数据。加速计算 |
| 包含operator | stage |
operator界面
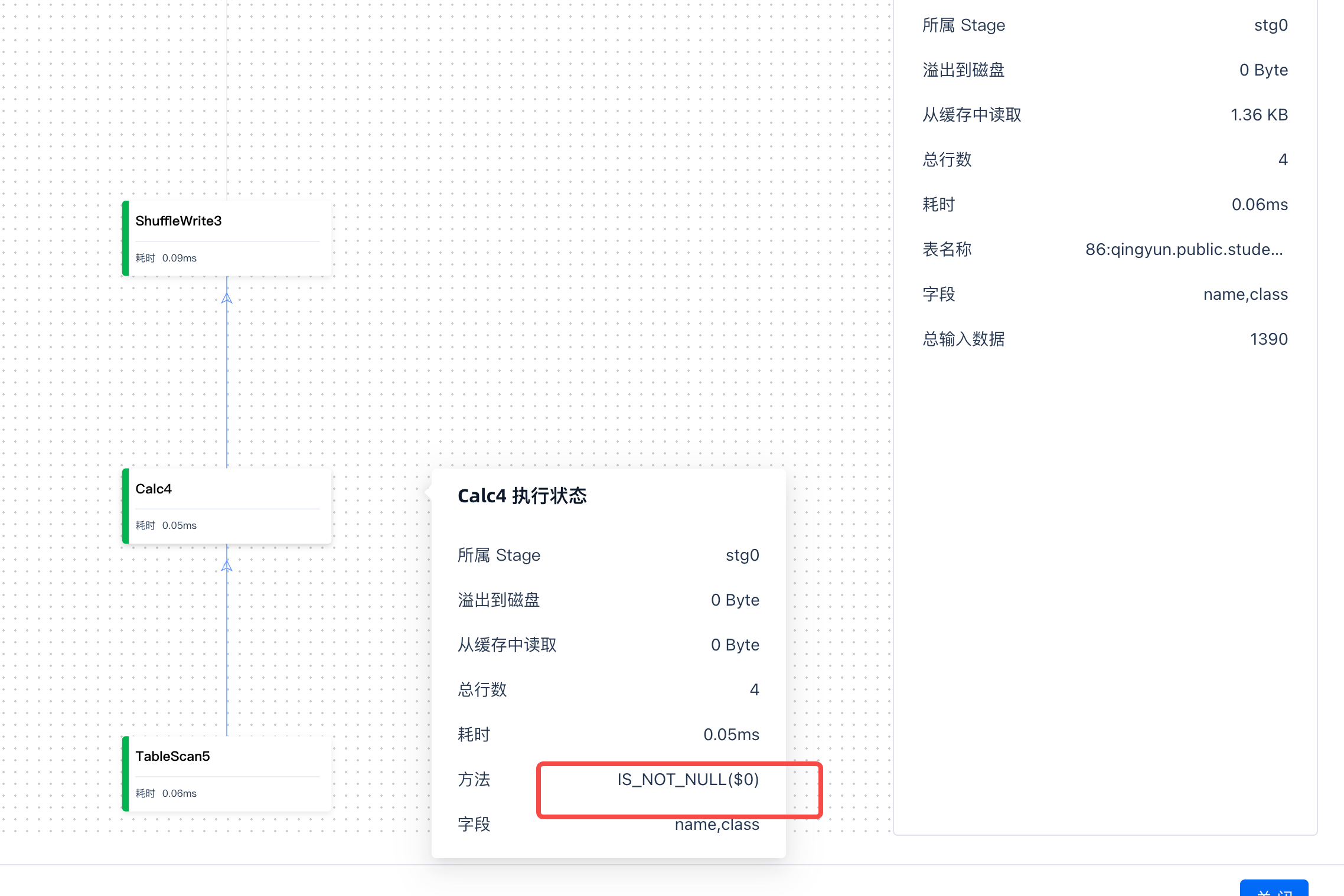
在operator界面可以查看每个operator类型和上下游依赖关系。Operator 是查询计划中的一个概念,它表示执行一个查询的具体步骤和策略,包括数据访问、转换和更新。
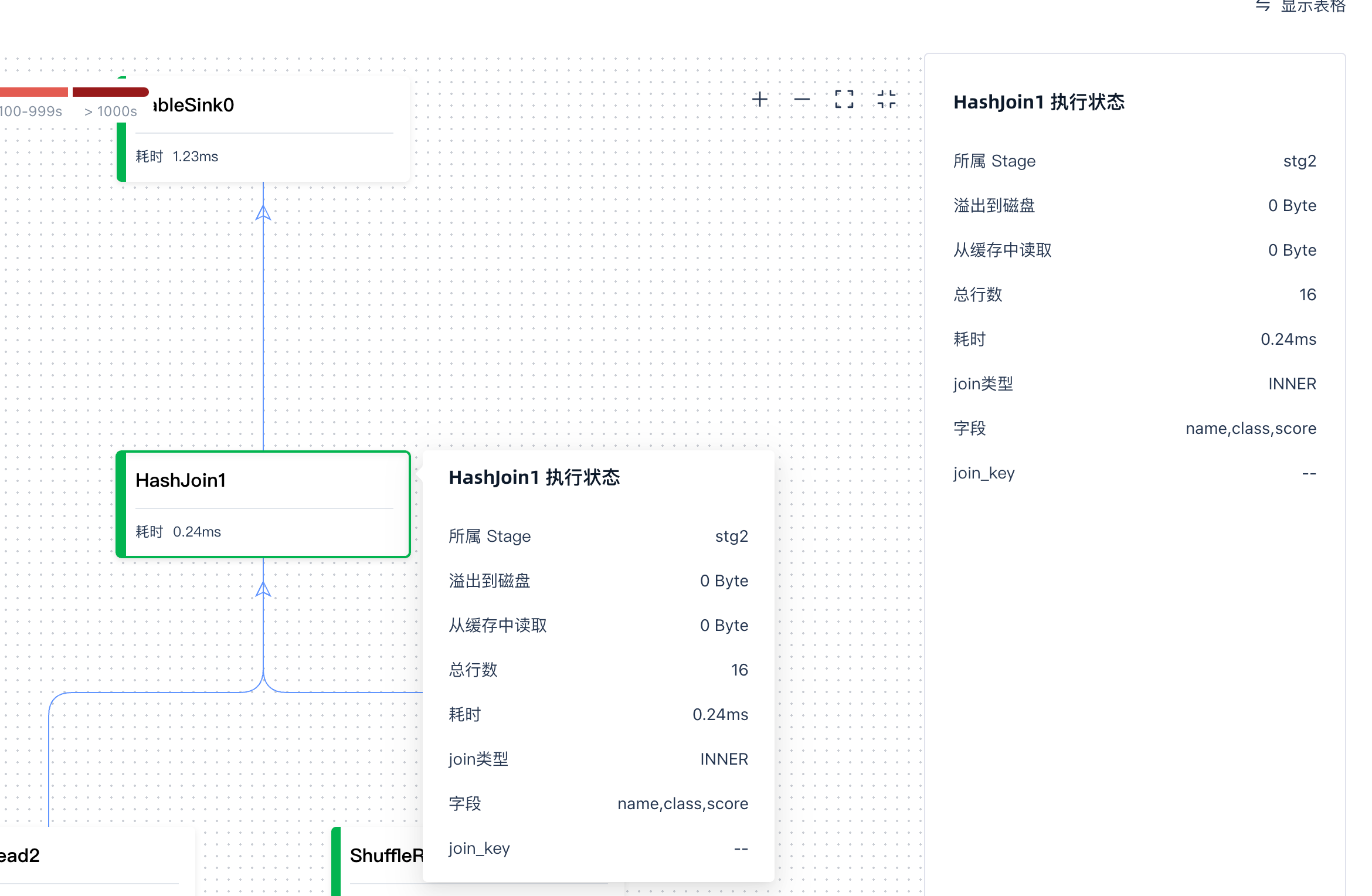
字段信息解释如下
| 字段 | 描述 |
|---|---|
| 所属 stage | 对应 operator 的 stage |
| 溢出到磁盘 | 溢出到磁盘的数据大小,此参数可以了解到是否是因为集群内存资源不够导致性能慢 |
| 从缓存中读取 | 在分析型集群中,已经读取的数据会先 cache 数据,以加速计算 |
| 总行数 | 当前 operator 处理的数据 |
| 耗时 | operator 会并发运行,当前显示为 operator 的平均时间 |
| 字段 | 和 SQL 脚本对应的字段 |
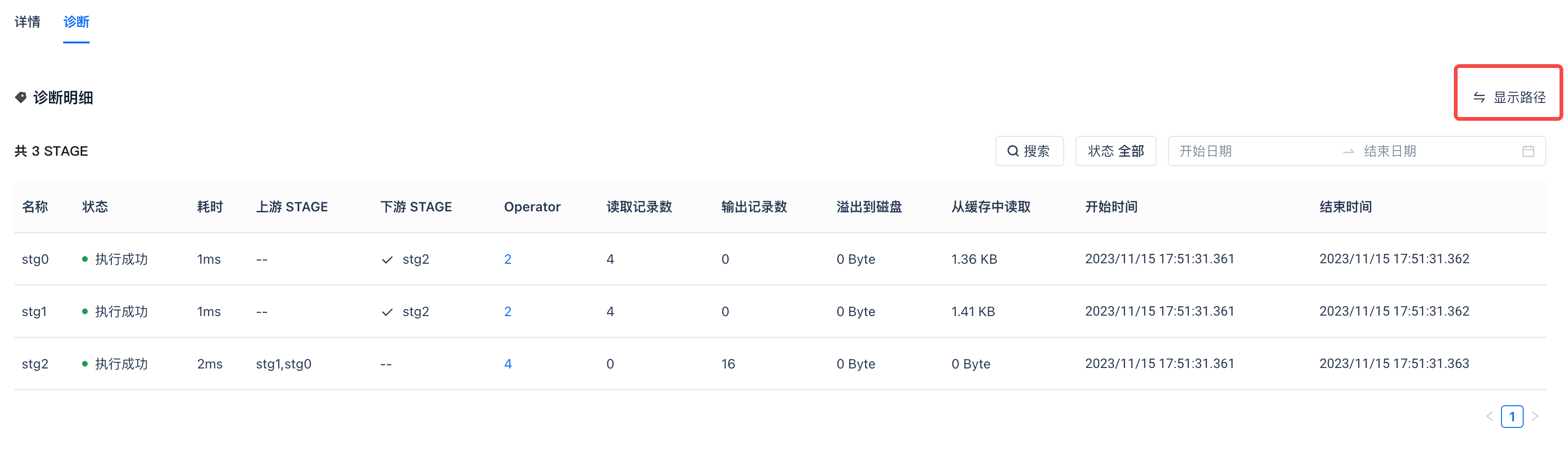
表格模式
支持stage切换表格模式
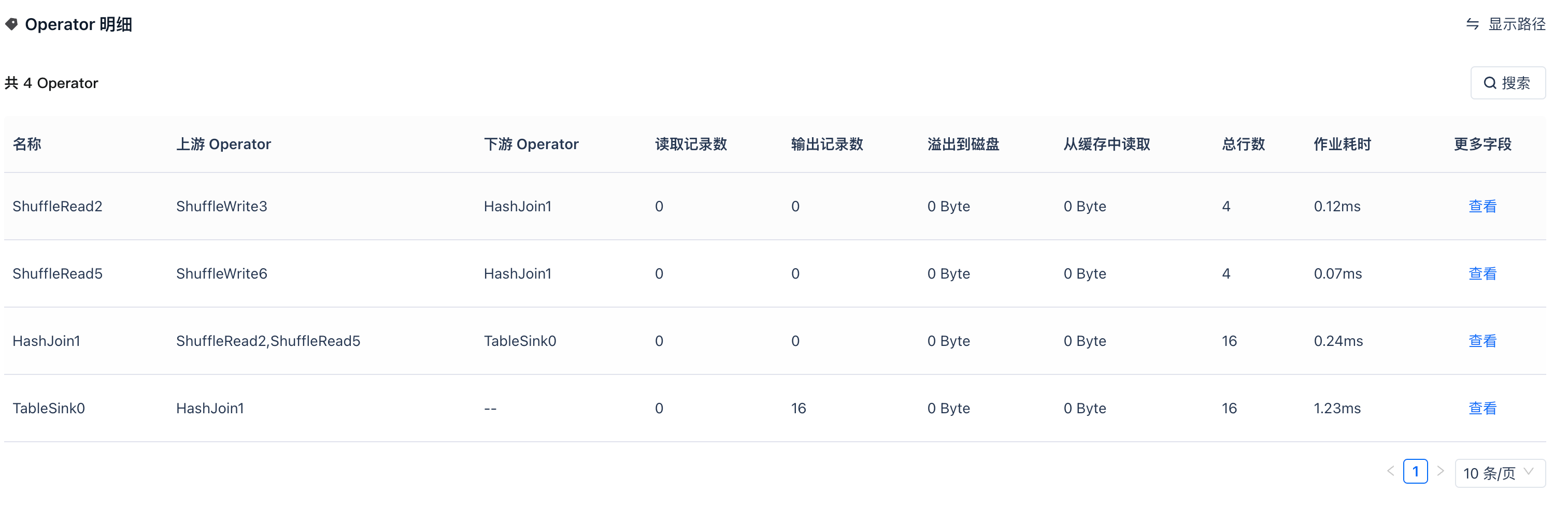
支持 operator 切换表格模式
分析运行出错的作业
当作业运行失败时,你可以通过作业的job profile中的详情来查看失败原因。以下是一些常见的失败原因及解决方法:
SQL语法错误
错误示例:
错误码 CZLH-42000 表示与 SQL 语言解析相关的错误。
[1,15]ttt分析运行缓慢的作业
运行缓慢的作业可能在编译阶段、拉起virtual cluster阶段或执行阶段出现问题。以下是针对这些阶段的分析和解决方法:
编译阶段
问题现象:作业状态显示为“初始化”。
可能原因及解决措施:
- 执行计划复杂:作业可能需要较长时间进行优化。请耐心等待,正常情况下不会超过10分钟。
- 编译资源被占满:如果你一瞬间提交了大量SQL,可能导致编译资源不足。请减少提交SQL的频率。如有大量高并发查询需求,请提交工单寻求帮助。
拉起virtual cluster阶段
问题现象:作业状态显示为“集群启动中”。(当前状态为正在拉起计算集群)
等待执行阶段
问题现象:作业状态显示为“等待执行”。
可能原因及解决措施:
- 当前集群的计算资源不足:可以通过界面筛选查看当前正在运行的作业,可能因大量作业正在运行导致等待资源。可以扩容资源,或者将正在运行的大作业终止以释放资源。
执行阶段
问题现象:作业状态显示为“正在执行中”。在这一阶段你可以点进查看每个算子的执行情况。
可能原因及解决措施:
- 等待资源:作业可能在等待资源分配。请检查资源使用情况,如有需要,请提交工单寻求帮助。
- 数据读取速度慢:作业可能因为数据读取速度慢而导致执行缓慢。请检查数据存储和读取策略,如有需要,请优化数据存储结构或调整读取策略。
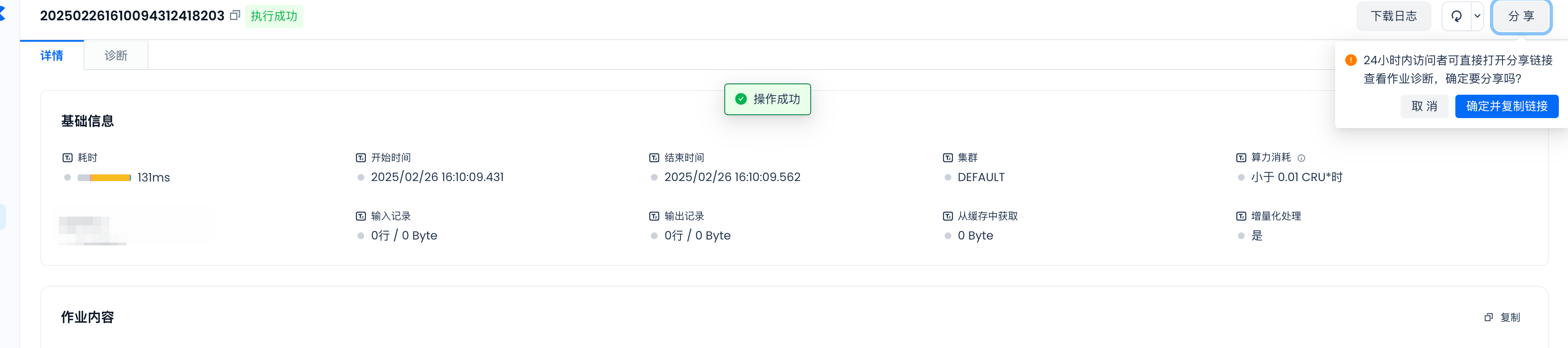
分享给其他人诊断
进入作业详情页面后,点击“分享”按钮,即可将作业分享给第三方。接收者无需登录即可查看内容。
查看执行计划和Operator详情
在执行阶段,你可以通过点击具体的 operator 来查询其执行步骤和策略。例如,将鼠标移动到具体的 operator 上,可以对应到 SQL 中具体执行的算子。这有助于你发现具体是哪个 operator 导致作业缓慢。