
计算集群
计算集群(Virtual-Cluster,简称:VCluster)是云器Lakehouse提供的一项核心服务,旨在为用户提供高效、可扩展的计算资源。计算集群为Lakehouse中的查询分析、ETL作业、流式分析和即席查询等任务提供必要的CPU、内存和临时存储资源。通过计算集群,用户可以在Lakehouse中执行各种复杂的数据处理任务。
核心概念
集群名称
每个计算集群都需要一个唯一的名称,该名称在工作空间内必须唯一。集群名称一旦创建,将无法更改。在Lakehouse中,集群的完整标识由工作空间名称和计算集群名称共同构成。
规格
计算集群的规格定义了集群中每个计算副本可用的计算资源数量,以Compute Resource Unit(CRU)为单位。CRU是云器Lakehouse对IaaS计算资源算力的抽象,以便在不同云平台、不同CPU架构和规格下,均能获得一致的算力。
说明:自2024年12月起,计算集群旧有从XS到5XLarge的规格代码变更为使用数字表达的规格。变更详见:计算集群规格代码变更说明。
| 类型 | 最小规格(CRU) | 最大规格(CRU) | 默认值(CRU) | 步长 (规格增减的最小单位) |
|---|---|---|---|---|
| 通用型 (GP VCluster) | 1 | 256 | 1 | 规格变更步长为:1CRU。 规格示例:1,2,3,4,5,6...256 |
| 分析型 (AP VCluster) | 1 | 256 | 1 | 规格变更步长为:2的n次幂CRU。 规格示例:1,2,4,8,16,32,64,128,256 |
| 同步型 (Integration VCluster) | 0.25 | 256 | 0.5 | 支持任意小数规格。 规格示例:0.25,0.5,0.75,1,1.25...256 |
每个集群每小时消耗的计算资源量为其CRU规格*1小时,即单位为CRU*时。例如规格为3 CRU的分析型计算集群,运行1小时的资源消耗为 3CRU * 1小时=3CRU*时。其费用也按照计算集群所在区域的“CRU*时”的单价计算。
集群类型
计算集群分为通用型、分析型和同步型,三大类:
- 通用型(GENERAL)):适用于处理离线作业,作业之间共享计算资源,新旧作业采用公平调度方式分配计算资源。
- 分析型(ANALYTICS):具备多计算实例和自动弹缩功能,适合处理在线和高并发作业。当作业并发数达到上限时,后续作业将排队等待执行,确保先提交的作业优先执行。
- 同步型(INTEGRATION):适用于处理离线集成和实时集成任务。多个集成任务可共用一个同步型计算集群实例。超出集群计算能力的集成任务将进入队列排队。
不同集群类型与下图中任务类型的对应关系如下:
| 任务类型 | 可使用集群类型 | 建议使用集群类型 |
|---|---|---|
| 离线同步 | 同步型 | 同步型 |
| SQL | 通用型、分析型 | ETL任务:通用型 Ad-hoc查询:分析型 |
| Python | 不使用计算集群 | / |
| Shell | 不使用计算集群 | / |
| JDBC | 不使用计算集群 | / |
| 虚拟节点 | 不使用计算集群 | / |
| Databricks SQL | 不使用计算集群 | / |
| Databricks Notebook | 不使用计算集群 | / |
| 实时同步 | 同步型 | 同步型 |
| 多表实时同步 | 同步型 | 同步型 |
| 动态表 | 通用型、分析型 | 低频率大数据量:通用型 高频率小数据量:分析型 |
| 流式SQL | 通用型、分析型 | 低频率大数据量:通用型 高频率小数据量:分析型 |
实例最小值
仅分析型计算集群支持此属性。指计算集群初始启动时集群实例数量,默认为1 个实例。
实例最大值
仅分析型计算集群支持此属性。指计算集群可以使用的最大实例数量,默认为2 个实例。当新的查询超过当前实例的最大并发数时,将触发计算集群的自动扩容,新增一个计算集群实例。扩容计算集群实例的上限为实例最大值。
自动停止
当计算集群在自动停止配置指定的时间内无作业运行时,计算集群自动停止、释放资源,停止消耗计算费用。自动停止配置最小单位为“秒”,最小可配置为15秒。
因运行不足1分钟的计算集群,将按照1分钟收费。所以当选择自动停止时间小于1分钟时,请谨慎确认,避免产生不必要的费用。1
自动启动
当有新作业提交时,若计算集群已停止,开启自动启动功能的计算集群将自动启动并执行作业。关闭该配置则指定计算集群需要手动启动。手动启动集群可参考本文中的“启动与停止集群”操作,或使用Alter Vcluster <vcluster_name> resume;语句。
管理计算集群
云器Lakehouse提供两种管理控制计算集群的方式:1)Web-UI方式;2)通过SQL方式。
Web-UI方式
查看集群信息
登录Lakehouse平台,点击左侧菜单的“计算”功能,进入“计算集群”列表页面。在此页面,你可以查看当前工作空间内所有授权访问的计算集群。
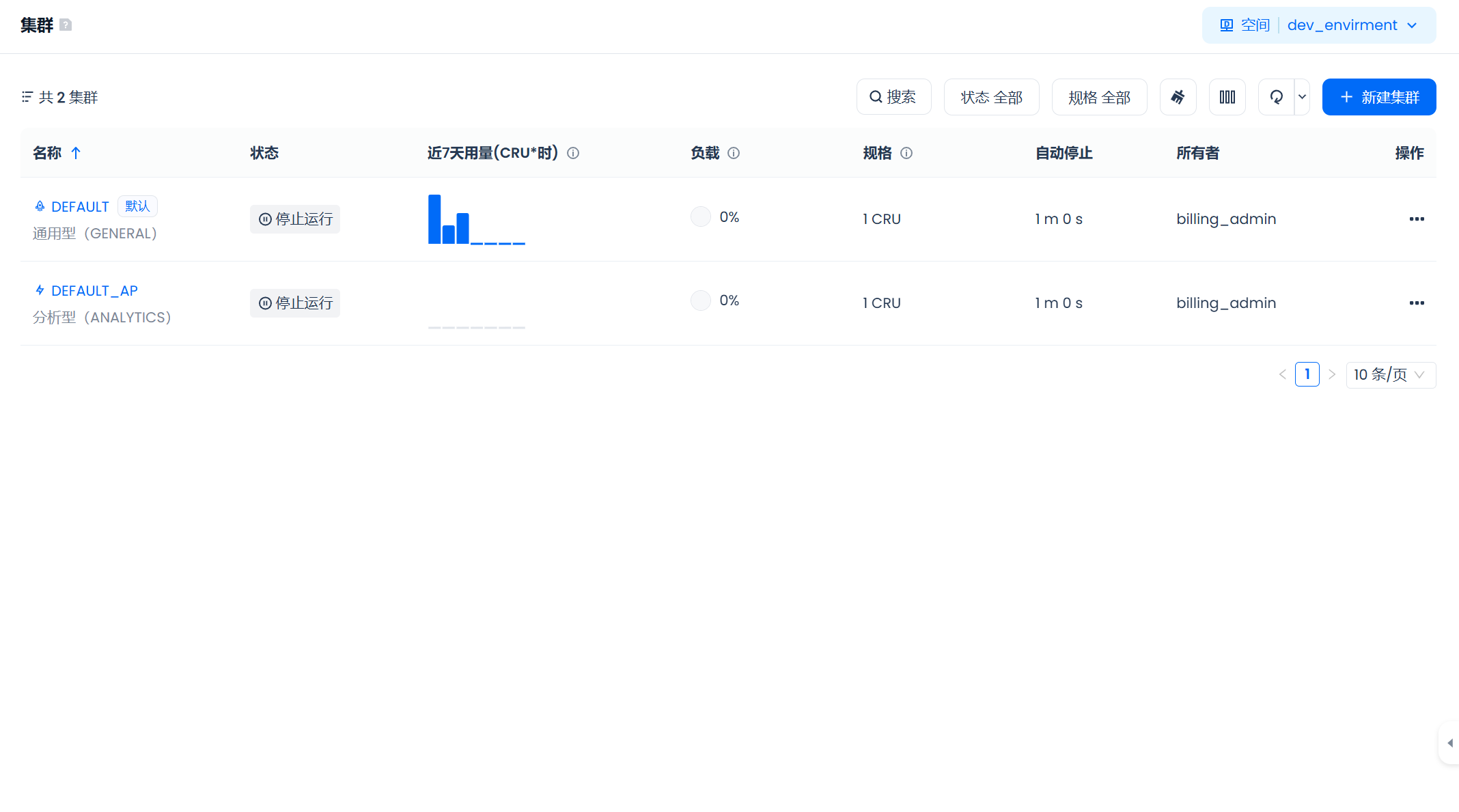
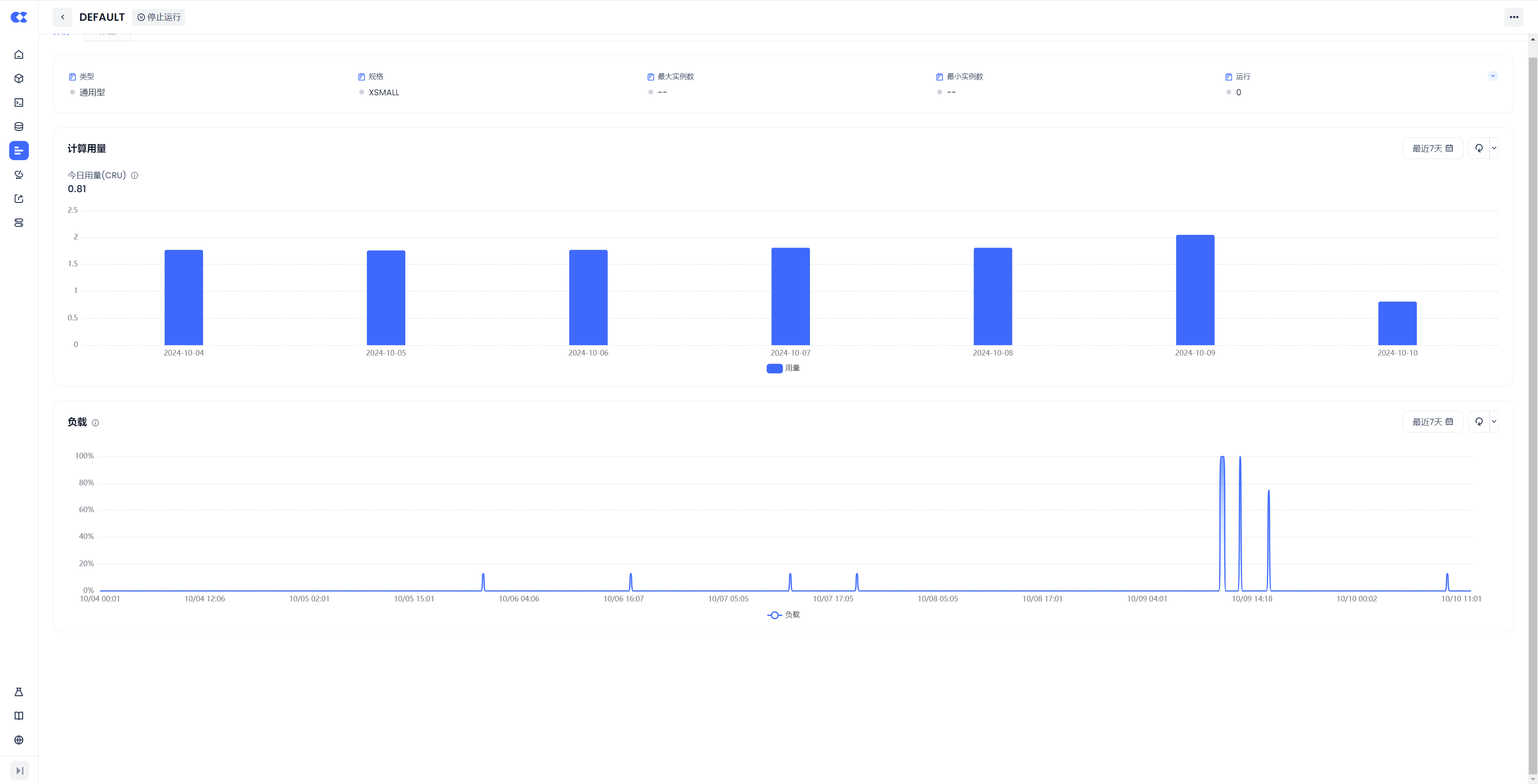
点击任一集群名称,进入详情页面,你可以查看集群的作业执行情况、配置详情以及当前用户对该集群的权限。
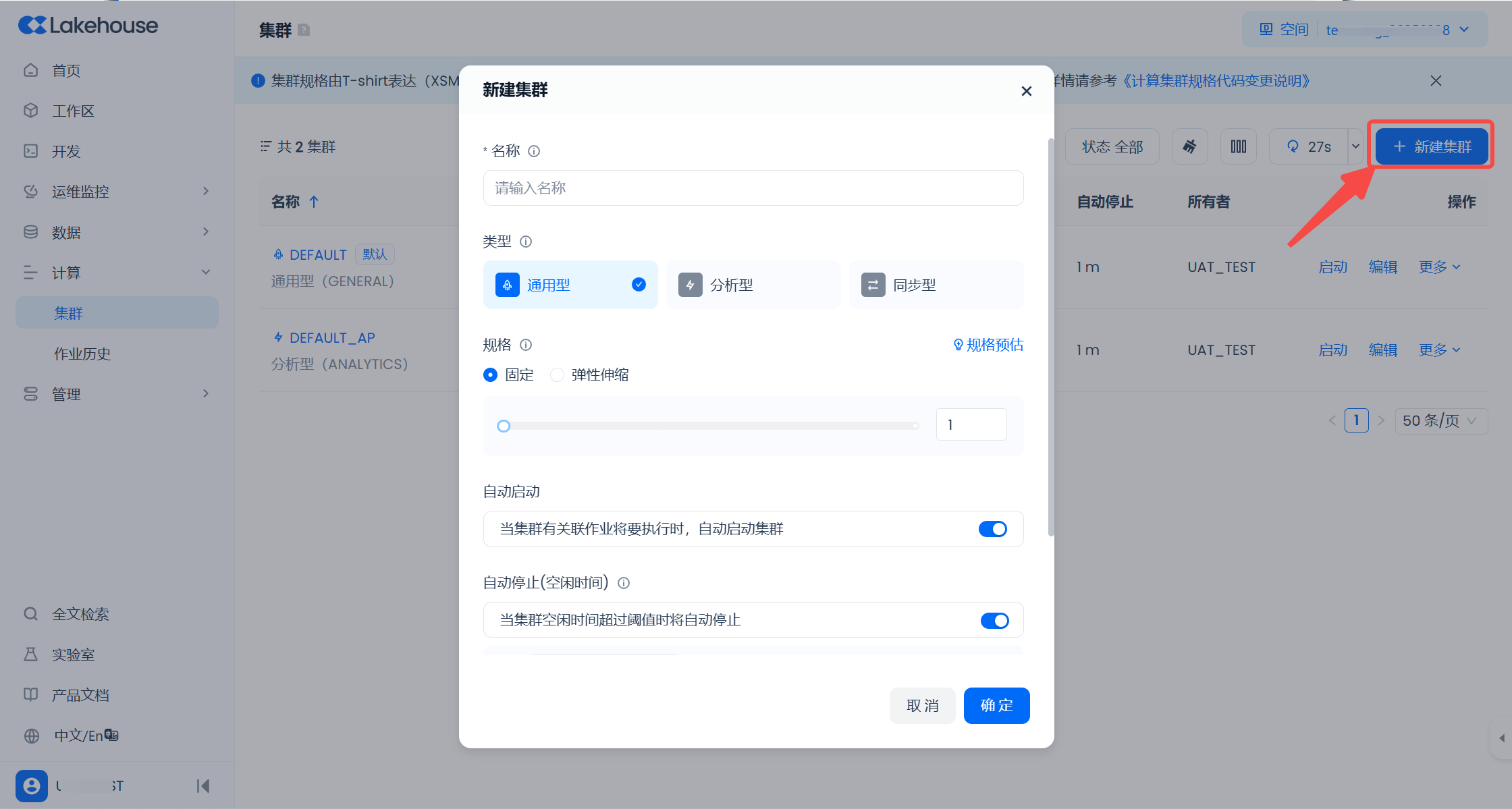
创建计算集群
在“计算集群”列表页面,点击“新建集群”按钮,进入新建集群界面。填写集群名称、选择集群类型、配置规格等信息后,点击“创建集群”完成集群创建。新集群将在列表中显示,并在状态变为“运行中”后即可使用。
创建通用型集群
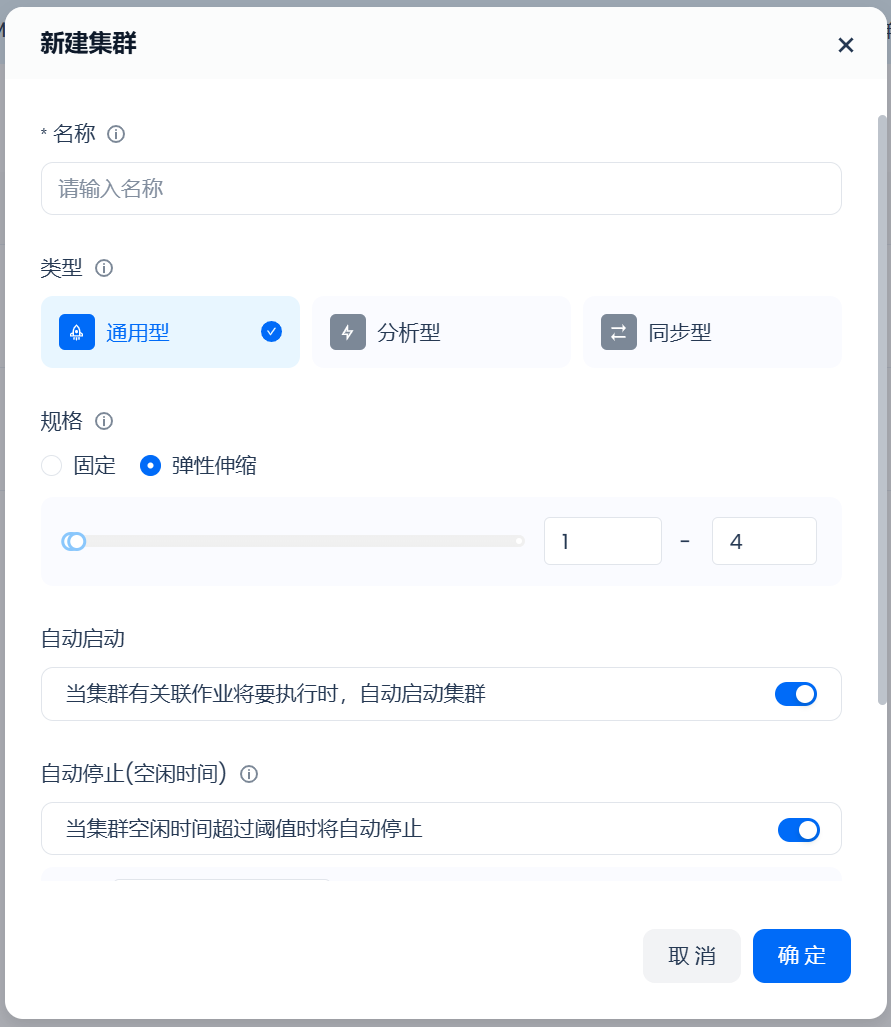
如果需要处理ETL等批量类型的作业,建议创建通用型计算集群:
- 在“类型”属性中选择“通用型”。
- 在“规格”属性中,可以选择“固定”和“弹性伸缩”两种方式。“固定”意味着该集群的规格大小不会随着负载而弹缩,可以有效控制集群所消耗资源,进而控制计算成本;“弹性伸缩”意味着该集群的规格大小会随着负载而弹缩,更有利于对任务SLA有强保障需求的场景。
- 选择是否开启“自动启动”和“自动停止”,并配置合理的“自动停止”时间。推荐开启“自动启动”,以及时处理作业任务,配置“自动停止”时间为1分钟,以当作业结束时能尽快关闭计算集群,节省成本。
完成上述配置后,点击“确定”即完成通用型计算集群的创建。
创建分析型集群
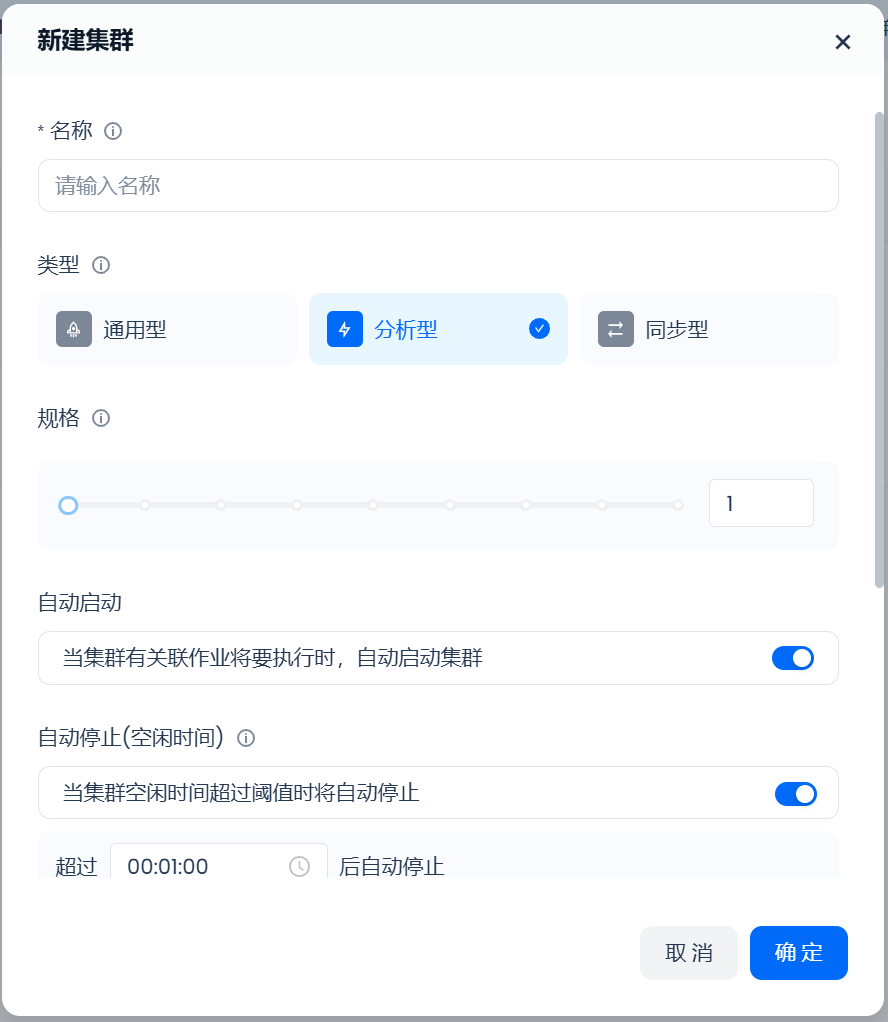
如需要为即席查询或BI看板等查询分析场景提供计算资源,建议创建分析型集群:
- 在“类型”属性中选择“通用型”。
- 在“规格”属性中,选择符合业务需要的规格。规格大小通常和该计算集群要负载的请求并发数、查询数据量、查询复杂度正相关,与预期查询结果返回时间负相关。可以在创建计算集群后,通过并发测试,逐步调整至满足查询效率需要且能够取得最优成本的规格。
- 选择是否开启“自动启动”和“自动停止”,并配置合理的“自动停止”时间。推荐开启“自动启动”,以及时处理作业任务,配置“自动停止”时间为30分钟以上,以尽量利用分析型集群的缓存加速查询结果,使终端用户获得更好的查询体验。
- 配置“最大并发数”。最大并发数指该集群每个实例所能够支持的最大并发数,当作业并发数超过该值时,作业会开始排队或触发扩容新的实例。
- “实例最小值”和“实例最大值”指该集群弹缩时的最小和最大实例数。当该计算集群当前所有实例的负载都达到“最大并发数”配置时,实例开始扩容,直至满足作业并发或达到“实例最大值”,实例扩容时,排队队列中的作业或新提交的作业会分配至新实例上,正在处理的作业不受影响;当该计算集群缩容一个实例仍可以满足所有并发时,开始缩容,直至缩容至能满足所有并发的最小实例数或该集群配置的“实例最小值”,实例缩容时,排队队列中的作业或新提交的作业不再分配至将要缩容的实例上,正在处理的作业不受影响,当正在处理的作业完成后,该实例完成释放。
创建同步型集群
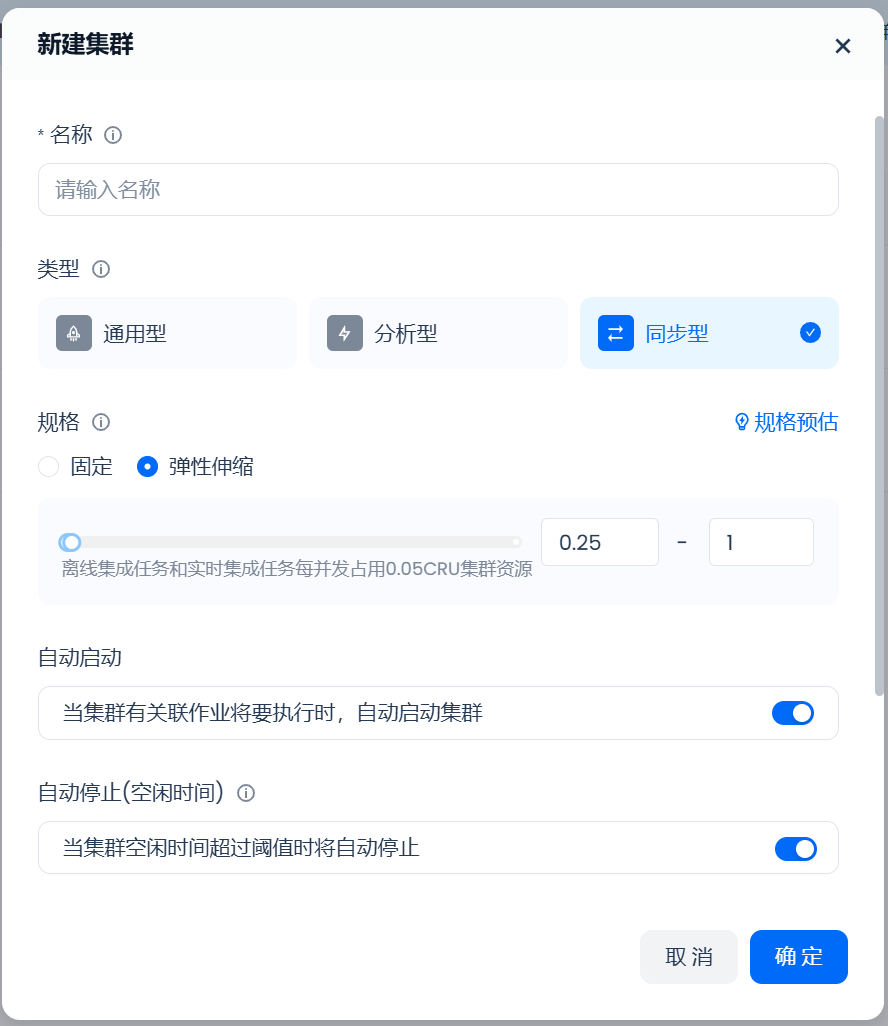
如果需要处理离线或实时集成任务,需要创建同步型集群:
- 在“类型”属性中选择“同步型”。
- 在“规格”属性中,可以选择“固定”和“弹性伸缩”两种方式。“固定”意味着该集群的规格大小不会随着负载而弹缩,可以有效控制集群所消耗资源,进而控制计算成本;“弹性伸缩”意味着该集群的规格大小会随着负载而弹缩,更有利于对任务SLA有强保障需求的场景。
- 同步型计算集群提供了“规格预估”功能,辅助选择合适的同步型集群规格。可通过输入“任务数”和“平均任务并发数”,按照“规格=任务数 * 平均任务并发数 * 0.05”的公式计算出预估的集群规格。
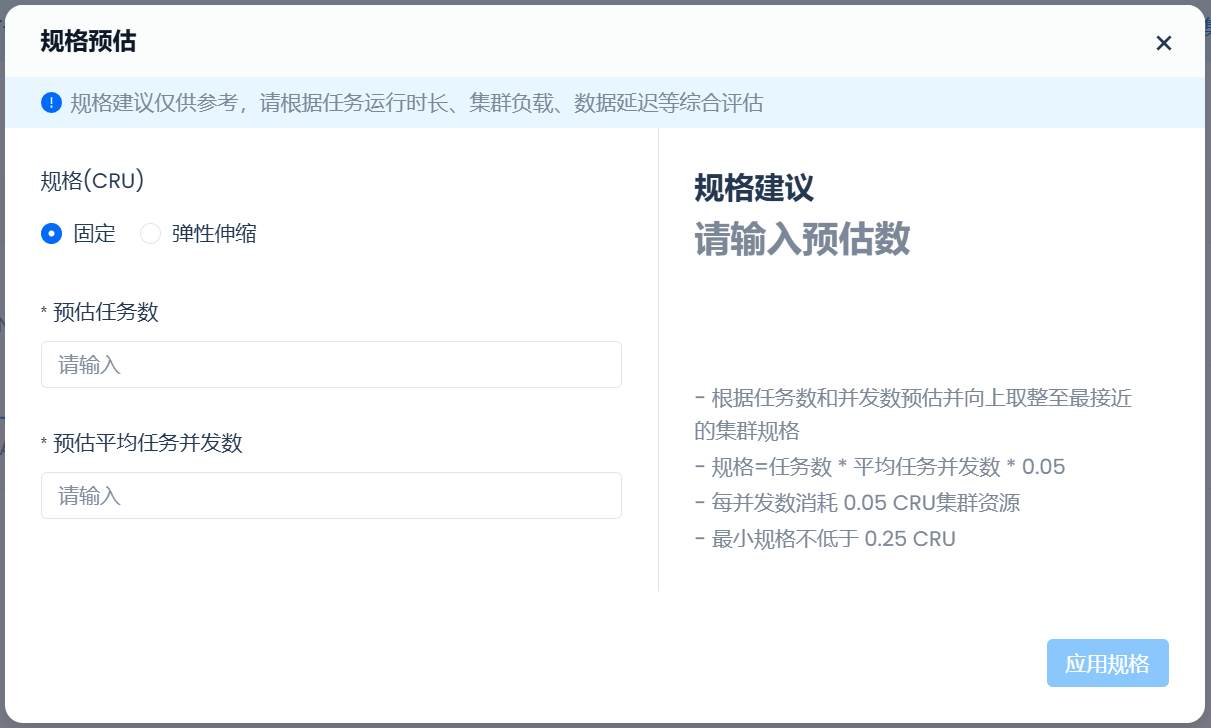
- 选择是否开启“自动启动”和“自动停止”,并配置合理的“自动停止”时间。推荐开启“自动启动”,以及时处理作业任务,配置“自动停止”时间为1分钟,以当作业结束时能尽快关闭计算集群,节省成本。
修改计算集群属性
在集群列表中,选择相应集群,点击“操作”列的“修改”按钮,即可对集群配置进行调整。修改后的集群配置可能影响集群状态,请注意在修改规格、实例数等关键属性时,确保集群上没有正在运行的作业。
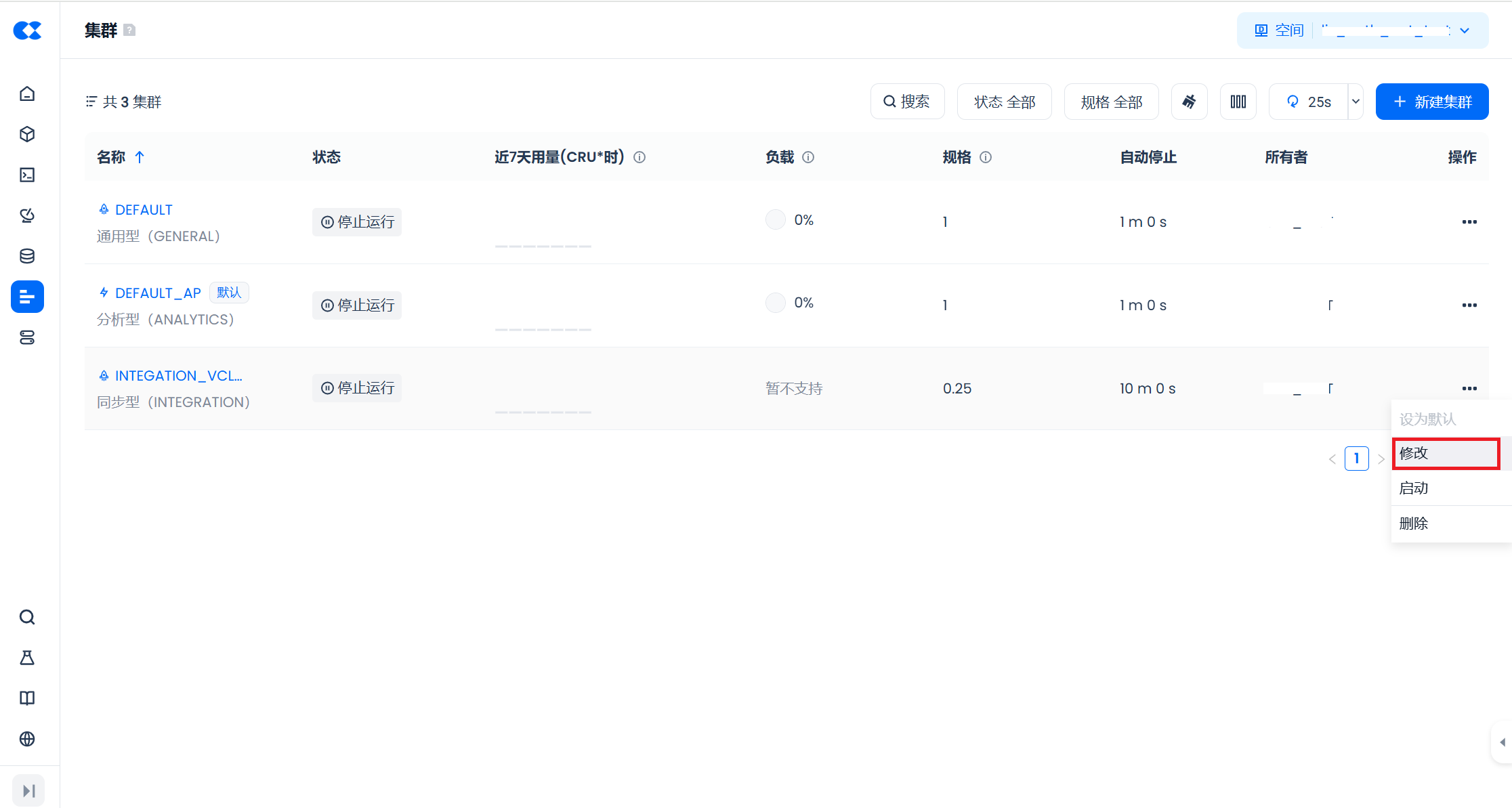
启动与停止计算集群
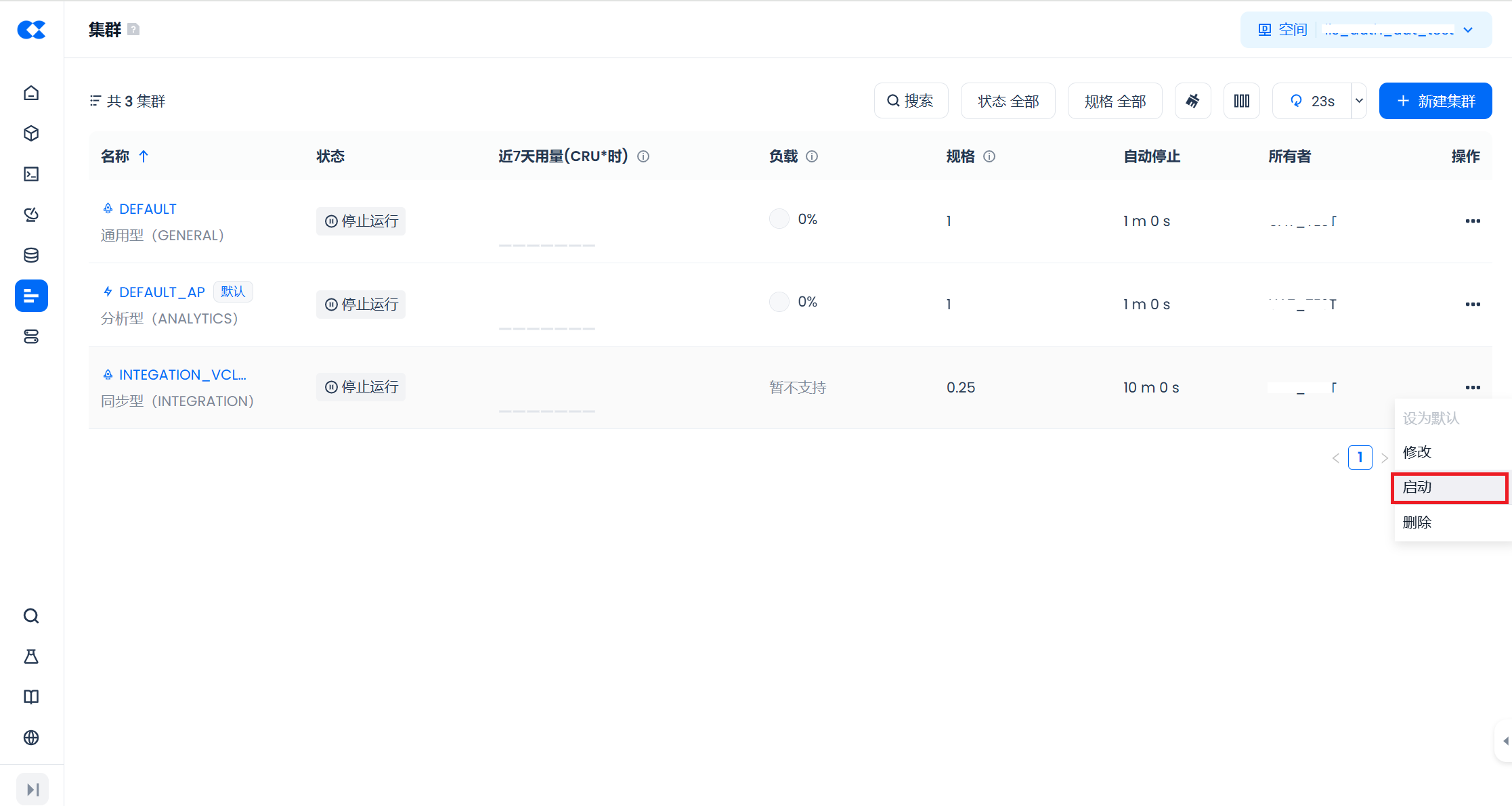
在集群列表中,点击“操作”列的“启动”或“停止”按钮,即可对计算集群进行启动或停止操作。请注意,停止集群时,正在执行的作业将等待完成后集群才会停止。
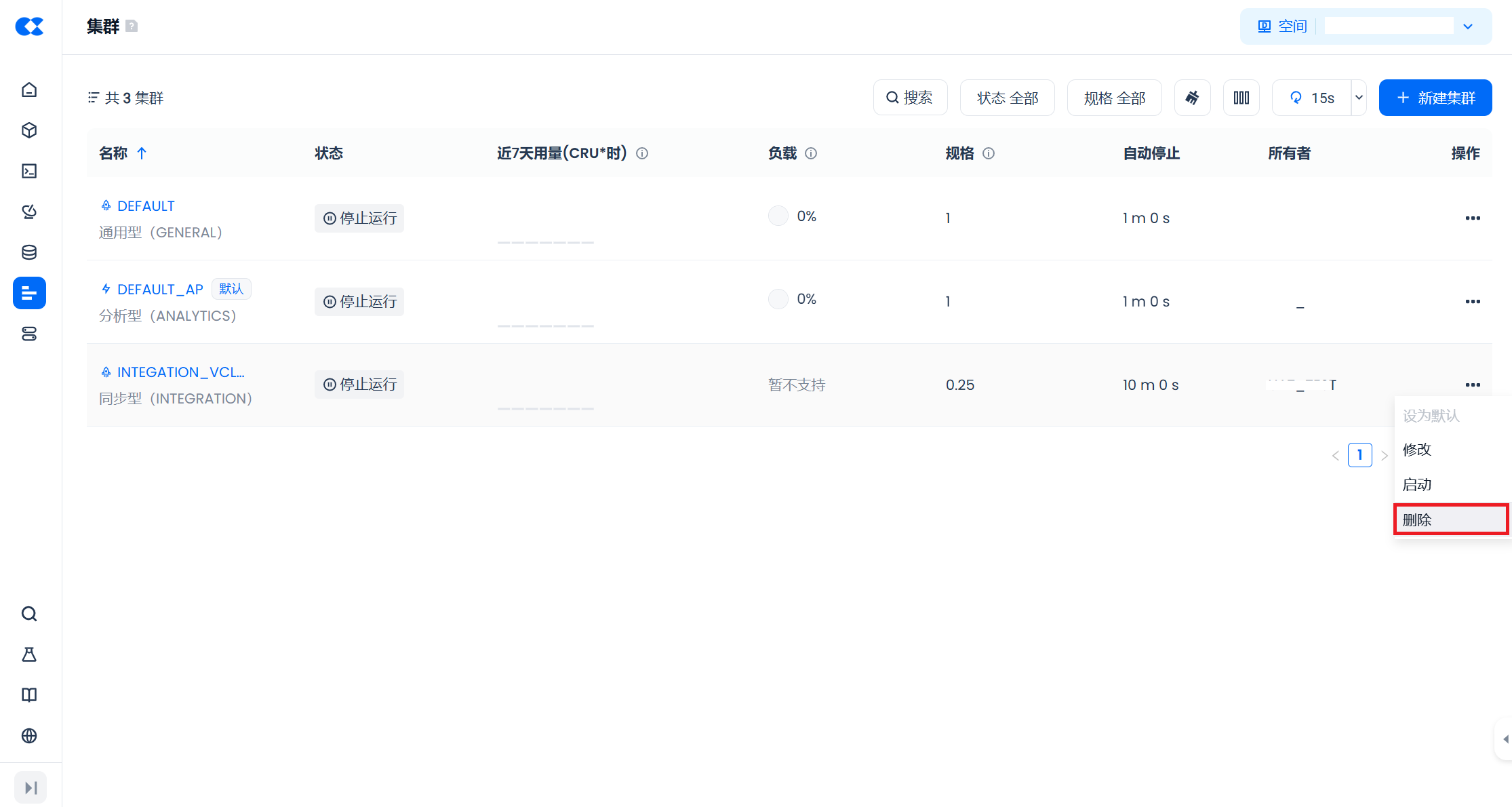
删除计算集群
在集群列表中,点击“操作”列的“删除”按钮,即可删除指定的计算集群。删除集群前,需要先停止集群,并等待所有作业完成后才能完成删除操作。
SQL方式
除了Web-UI,Lakehouse还支持使用SQL命令直接操作计算集群。具体命令和使用方法,请参考计算资源DDL文档。
计算集群配置实践
自动化管理计算集群
计算集群实例可在停止状态下,被提交的任务唤醒,秒级启动并开始执行作业,并可在集群空闲时自动关机,以节约成本。充分利用这一特性,可使计算集群的成本尽量贴合业务的负载,大幅提高资源利用率。
- 配置自动暂停和恢复:在创建或修改计算集群实例的窗口,可以找到“自动启动”和“自动停止”的配置项。通常情况下,这两个配置是配合进行配置的:打开“自动启动”,并且设置“自动停止”时间。
- 设置合适的超时限制:计算集群的“自动停止”时间可以设置从1分钟到3小时不等。合理选择“自动停止”时间需要考虑到计算集群的启动和停止对作业带来的影响:
- 1)对离线作业可以将“自动停止”时间设置得尽量短,例如1分钟。以便集群在完成作业后能够尽快停止运行,避免空闲时间带来的资源浪费。
- 2)对在线查询服务则需要适当延长”自动停止”时间,例如30分钟。这样做首先可以尽量减少计算集群从”停止”状态到”启动”状态带来的查询请求延迟,保证查询体验;其次也可以尽量延长计算结果缓存的时间(针对分析型计算集群),提升查询效率。如需主动将热点表预加载到集群缓存以进一步加速查询,参考计算集群缓存。
- 3)强烈不建议将“自动停止”时间配置到1分钟以内。由于计算集群计费是以秒级计费的,当运行时间不足60秒时会按照60秒计费。当配置自动停止时间为1分钟以内时,如果该计算集群上执行的作业运行时间非常短,可能造成1分钟内计算集群多次启动和停止,从而产生多个60秒的费用,造成费用上升。仅当对确认该集群上运行的作业时长不会造成集群1分钟内多次启停时,才可以配置自动停止时间小于1分钟。
合理扩大或减小计算集群规格
实例规格是对虚拟集群进行垂直伸缩的选项,调整实例规格可以让单个作业获得更大的算力以提升作业性能。
在实际的业务场景中,对于面向用户的数据产品往往有SLA的要求,如100并发下P99的查询延迟小于2秒。同时,也希望计算资源得到充分的利用,在满足业务需求的前提下尽可能降低资源成本。
在实际业务使用中,推荐使用不同大小的计算集群规格运行查询(例如使用从8 CRU->1 CRU几种规格分别进行测试),找到集群规格尽可能小、同时性能下降不明显的资源规格。
从业务负载类型、执行频率、作业并发、处理数据规模、SLA要求几个维度提供样例的资源规格设计,供参考使用:
| 业务场景 | 负载类型 | 执行频率 | 作业并发 | 处理数据规模 | VCluster类型 | 作业时延SLA | VCluster Size |
|---|---|---|---|---|---|---|---|
| ETL调度作业 | 近实时离线处理 | 小时 | 1 | 1 TB | 通用型 | 15 分钟 | 4 |
| T+1离线处理 | 天 | 1 | 10 TB | 通用型 | 4 小时 | 8 | |
| Tableau/FineBI | Ad-Hoc Analytics | Ad-Hoc | 8 | 1 TB | 通用型 | <1 分钟 TP90 <5秒 | 16 |
| 数据应用产品 | Applications | 按需 | 8 | 100 GB | 分析型 | <1秒 | 4 |
| 按需 | 96 | 100 MB | 分析型 | <1秒 | 4 | ||
| ClickZetta Web-UI<数据开发测试> | Ad-Hoc Analytics | Ad-Hoc | 8 | 3 TB | 通用型 | < 1 分钟 TP90:<15 秒 | 16 |
通过多计算资源实现负载隔离
-
使用多个独立的计算支撑不同业务负载(Workload)。可根据周期性ELT、线上业务报表、分析师数据分析等不同需求,创建不同的计算资源并分配给不同的用户或应用使用,避免不同业务或人员资源争抢导致的SLA下降。 例如:
-
周期性ELT任务和线上业务报表查询任务应当使用不同计算集群进行隔离,并分别使用通用型和分析型两种类型的计算集群,以充分发挥不同类型计算集群的性能特性,并且易于配置不同的自动停止时间——运行周期性ELT任务的计算集群的自动停止时间配置尽量短,比如1分钟;运行线上业务报表查询任务的计算集群自动停止时间配置稍长,比如5分钟。
-
将运行大作业和小作业的计算集群进行隔离,为大作业配置较大规格的计算集群,保障大作业的运行时间,为小作业配置较小规格的计算集群避免不能跑满计算集群负载,造成资源浪费。