SELECT *
FROM read_kafka(
'kafka-bootstrap-1:9092,kafka-bootstrap-2:9092,kafka-bootstrap-3:9092', -- bootstrap
'topic-name', -- topic
'', -- reserved
'test', -- kafka group id, for keeping read position
'', '', '', '', -- reserved
'raw', -- key format, can only be raw
'raw', -- value format, can only be raw
0,
MAP(
'kafka.security.protocol','PLAINTEXT',
'kafka.auto.offset.reset','latest'
)
)
LIMIT 10;
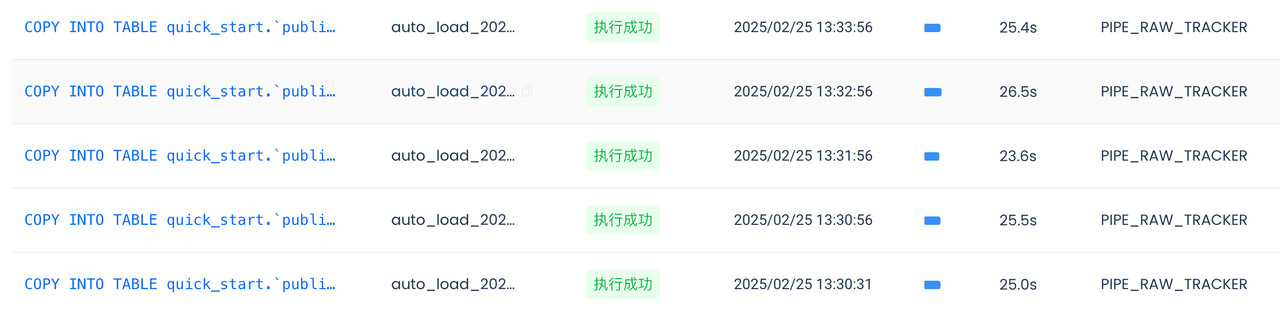
read_kafka 函数参数众多,但是实际需要填写的只有 bootstrap 地址、topic 和 group id。探查阶段我们使用 test 作为 group id
SELECT *
FROM read_kafka(
'kafka-bootstrap-1:9092,kafka-bootstrap-2:9092,kafka-bootstrap-3:9092', -- bootstrap
'topic-name', -- topic
'', -- reserved
'test', -- kafka group id, for keeping read position
'', '', '', '', -- reserved
'raw', -- key format, can only be raw
'raw', -- value format, can only be raw
0,
MAP(
'kafka.security.protocol','SASL_PLAINTEXT',
'kafka.sasl.mechanism','PLAIN',
'kafka.sasl.username','<username>',
'kafka.sasl.password','<password>',
'kafka.auto.offset.reset','latest'
)
)
LIMIT 10;
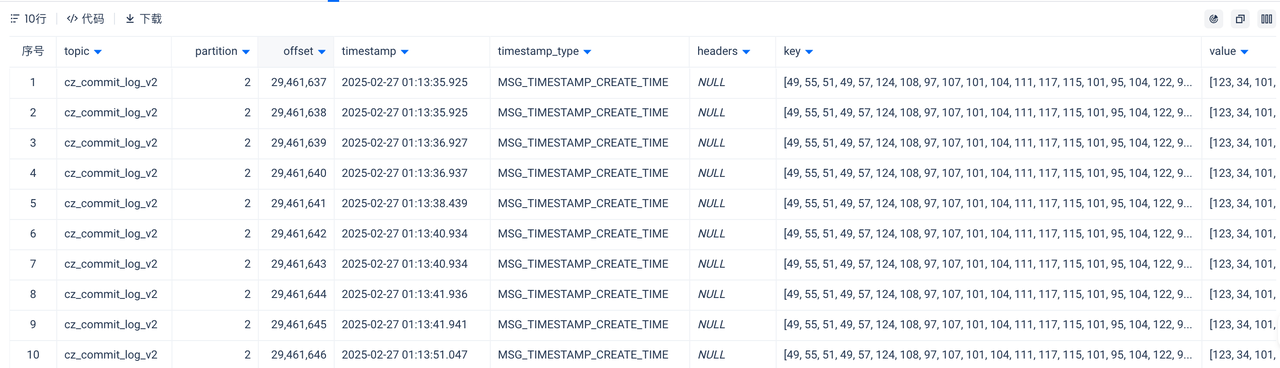
如果参数配置无误,执行上述 SQL 将获得 10 行样例数据
预览
小批量读取数据确认 schema 并创建目标表
kafka 数据中的 key 和 value 都是 binary 类型。通常我们更关心的是 value 的内容。如果其中本来存放就是字符串,可以在 select 的时候 cast 成 string 来快速探查其中内容。
SELECT key::string, value::string
FROM read_kafka(
'kafka-bootstrap-1:9092,kafka-bootstrap-2:9092,kafka-bootstrap-3:9092', -- bootstrap
'topic-name', -- topic
'', -- reserved
'test', -- kafka group id, for keeping read position
'', '', '', '', -- reserved
'raw', -- key format, can only be raw
'raw', -- value format, can only be raw
0,
MAP(
'kafka.security.protocol','PLAINTEXT',
'kafka.auto.offset.reset','latest'
)
)
LIMIT 10;
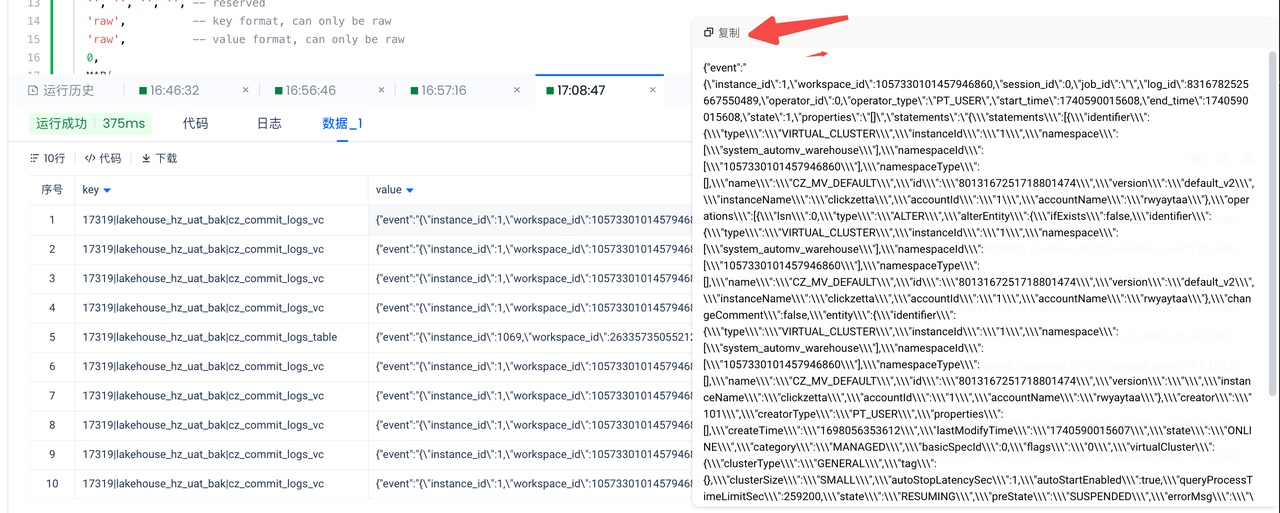
预览
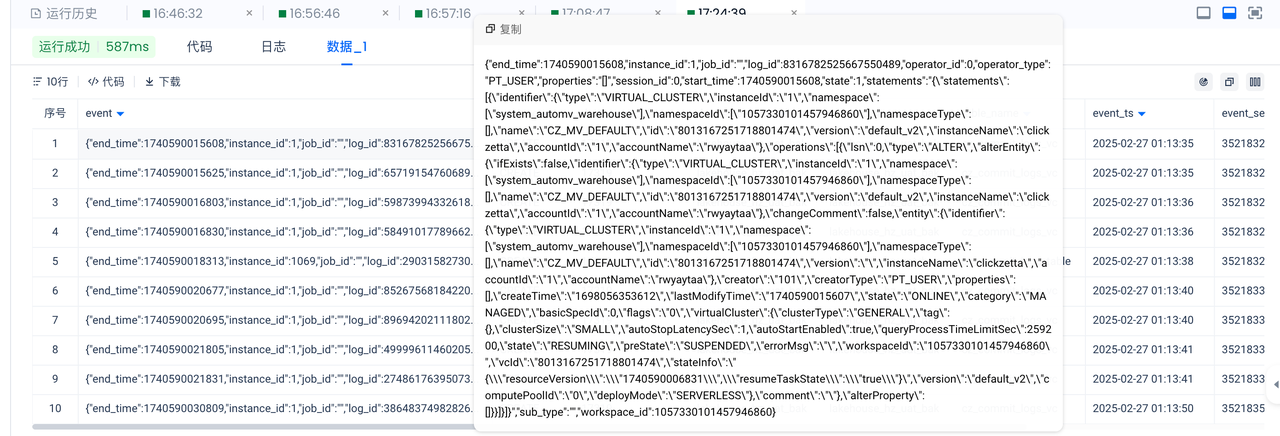
点击「复制」获取样例数据并探查,可见 value 大体是个 JSON,但是 JSON 中有些 string field 还是个完整的 JSON,看起来还不止一层,结构略复杂:
调整 select 语句,使用 parse_json 将 value 字段和其中的 event 展开:
SELECT
parse_json(j['event']::string) as event,
j['op_type']::string as op_type,
j['datasource_id']::string as datasource_id,
j['database_name']::string as database_name,
j['schema_name']::string as schema_name,
j['table_name']::string as table_name,
timestamp_millis(j['event_ts']::bigint) as event_ts,
j['event_seq']::string as event_seq,
timestamp_millis(j['server_ts']::bigint) as server_ts,
j['server_seq']::bigint as server_seq
FROM (
SELECT parse_json(value::string) as j
FROM read_kafka(
'kafka-bootstrap-1:9092,kafka-bootstrap-2:9092,kafka-bootstrap-3:9092', -- bootstrap
'topic_name', -- topic
'', -- reserved
'test', -- kafka group id, for keeping read position
'', '', '', '', -- reserved
'raw', -- key format, can only be raw
'raw', -- value format, can only be raw
0,
MAP(
'kafka.security.protocol','PLAINTEXT',
'kafka.auto.offset.reset','latest'
)
)
LIMIT 10
);
SELECT
parse_json(j['event']::string) as event,
parse_json(parse_json(j['event']::string)['statements']::string) as statements,
j['op_type']::string as op_type,
j['datasource_id']::string as datasource_id,
j['database_name']::string as database_name,
j['schema_name']::string as schema_name,
j['table_name']::string as table_name,
timestamp_millis(j['event_ts']::bigint) as event_ts,
j['event_seq']::string as event_seq,
timestamp_millis(j['server_ts']::bigint) as server_ts,
j['server_seq']::bigint as server_seq
FROM (
SELECT parse_json(value::string) as j
FROM read_kafka(
'kafka-bootstrap-1:9092,kafka-bootstrap-2:9092,kafka-bootstrap-3:9092', -- bootstrap
'topic_name', -- topic
'', -- reserved
'test', -- kafka group id, for keeping read position
'', '', '', '', -- reserved
'raw', -- key format, can only be raw
'raw', -- value format, can only be raw
0,
MAP(
'kafka.security.protocol','PLAINTEXT',
'kafka.auto.offset.reset','latest'
)
)
LIMIT 10
);
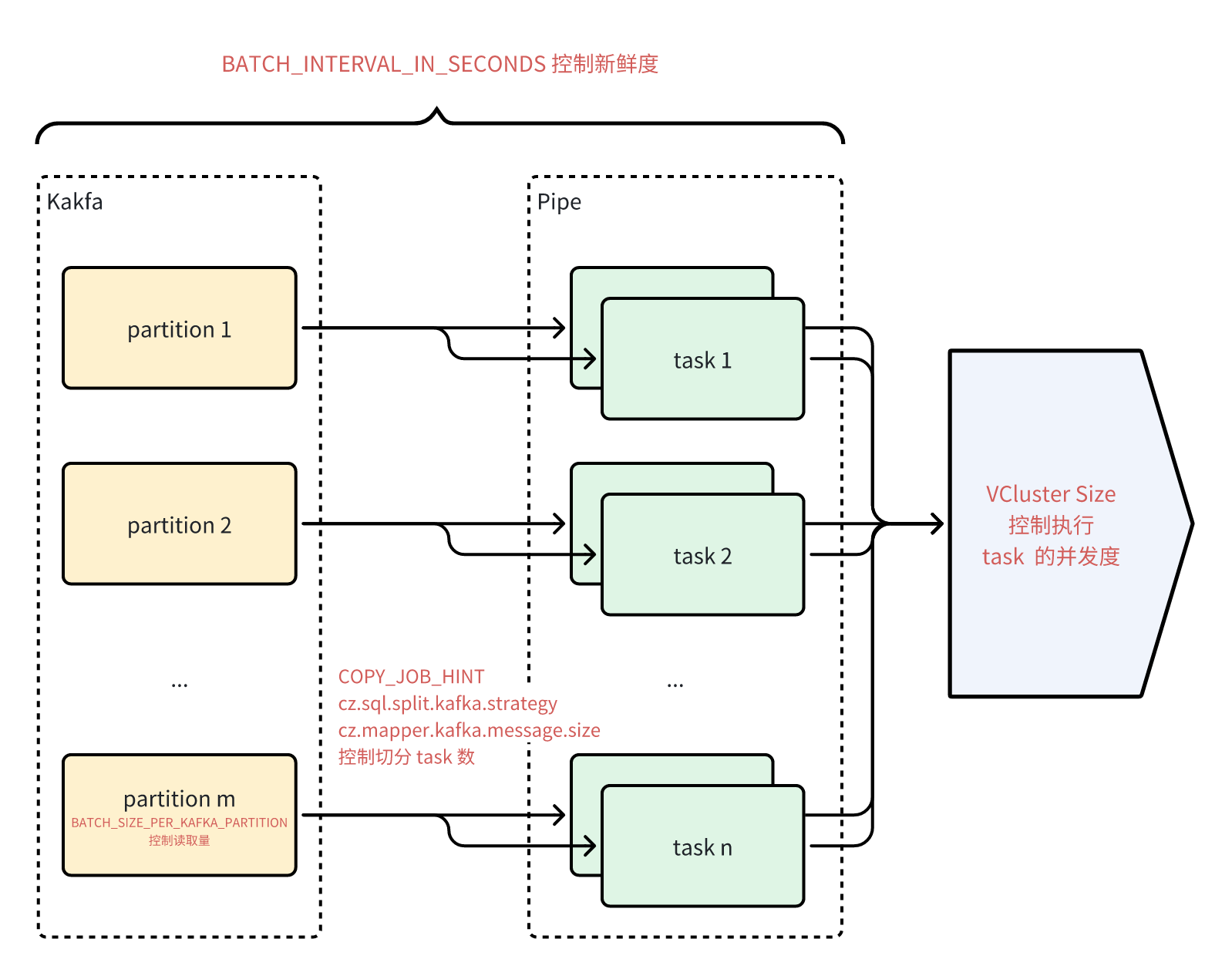
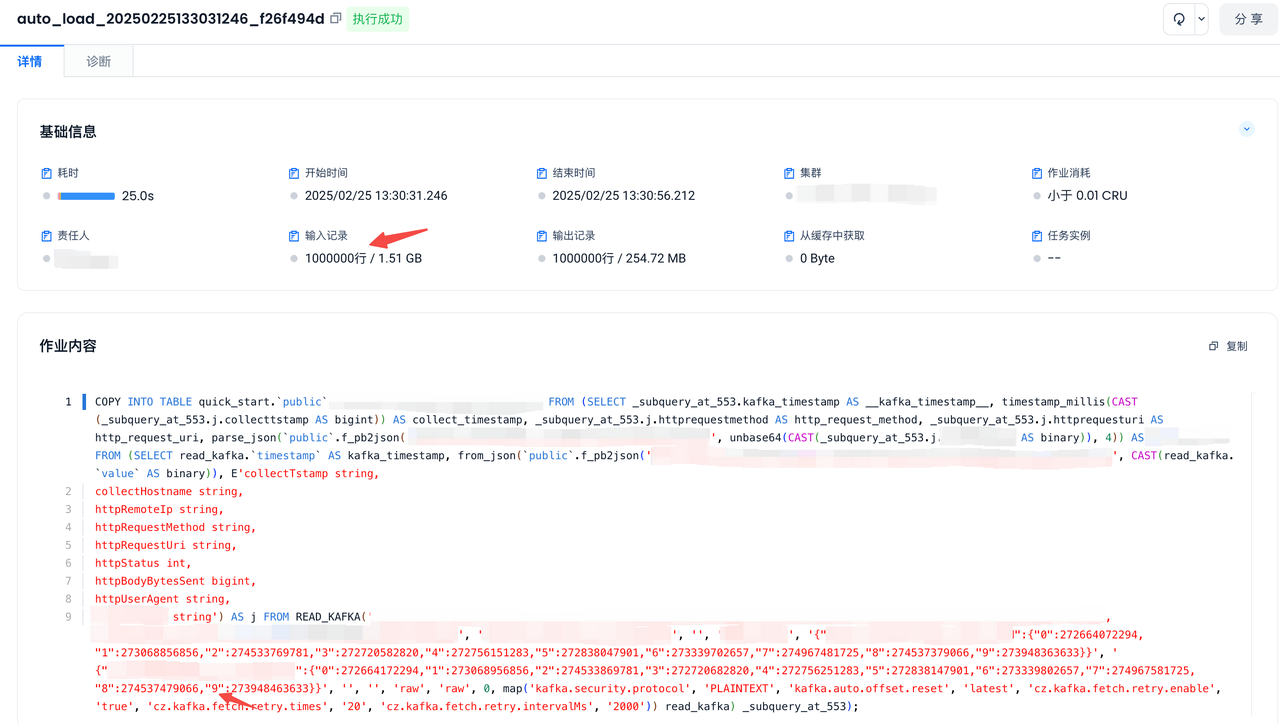
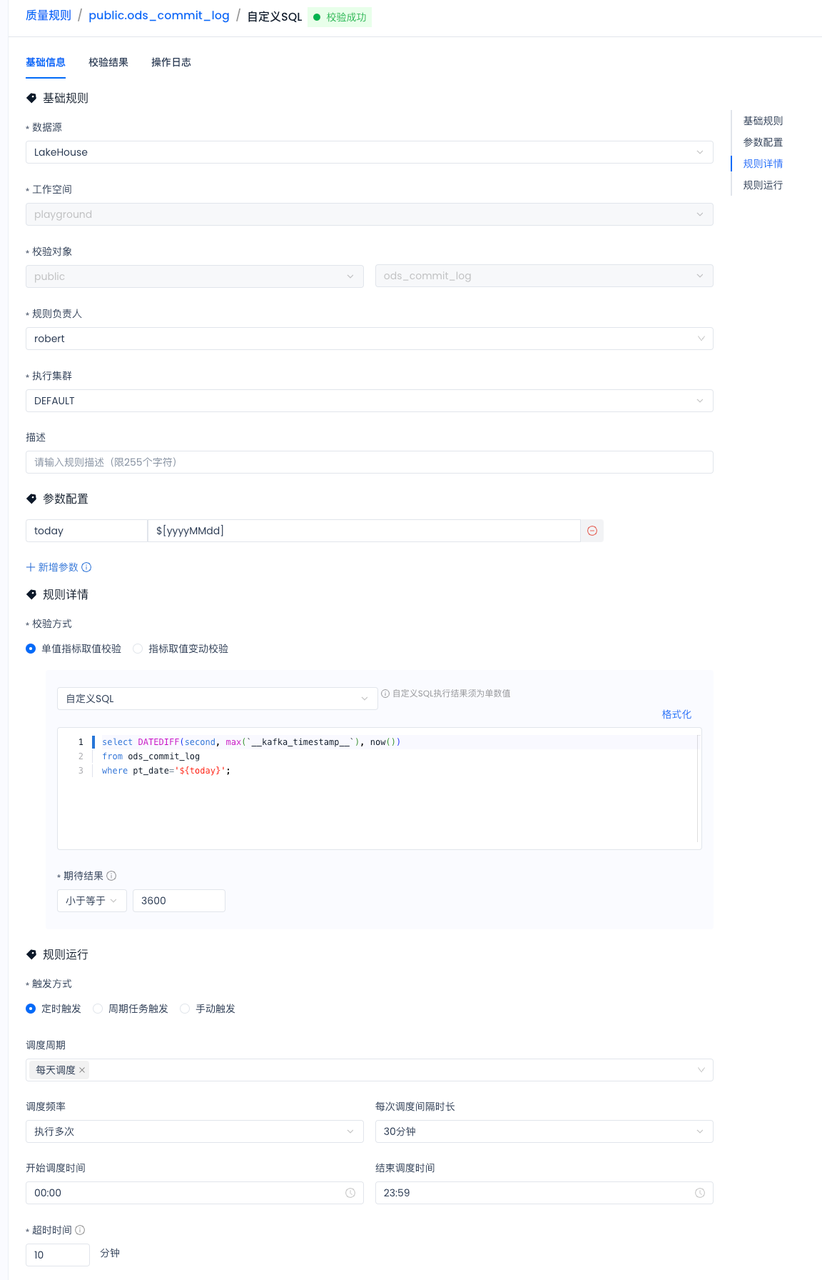
CREATE PIPE pipe_ods_commit_log
VIRTUAL_CLUSTER = 'pipe_ods_commit_log'
BATCH_INTERVAL_IN_SECONDS = '60'
RESET_KAFKA_GROUP_OFFSETS = '1740931200000' -- epoch in millis of 2025-03-03 00:00:00
AS COPY INTO ods_commit_log FROM (
SELECT
parse_json(j['event']::string) as event,
parse_json(parse_json(j['event']::string)['statements']::string) as statements,
j['op_type']::string as op_type,
j['datasource_id']::string as datasource_id,
j['database_name']::string as database_name,
j['schema_name']::string as schema_name,
j['table_name']::string as table_name,
timestamp_millis(j['event_ts']::bigint) as event_ts,
j['event_seq']::string as event_seq,
timestamp_millis(j['server_ts']::bigint) as server_ts,
j['server_seq']::bigint as server_seq,
`timestamp` as __kafka_timestamp__
FROM (
SELECT `timestamp`, parse_json(value::string) as j
FROM read_kafka(
'kafka-bootstrap-1:9092,kafka-bootstrap-2:9092,kafka-bootstrap-3:9092', -- bootstrap
'topic_name', -- topic
'', -- reserved
'sub2cz', -- kafka group id, for keeping read position
'', '', '', '', -- reserved
'raw', -- key format, can only be raw
'raw', -- value format, can only be raw
0,
MAP(
'kafka.security.protocol','PLAINTEXT',
'cz.kafka.fetch.retry.enable','true',
'cz.kafka.fetch.retry.times','20',
'cz.kafka.fetch.retry.intervalMs','2000'
)
)));
对已有 pipe drop pipe 和 alter pipe,会被 pipe 当前正在运行的作业阻塞,直到作业结束后才会返回,可能会需要些时间。
重建 pipe(注意去掉 RESET_KAFKA_GROUP_OFFSETS 参数)
CREATE PIPE pipe_ods_commit_log
VIRTUAL_CLUSTER = 'pipe_ods_commit_log'
BATCH_INTERVAL_IN_SECONDS = '60'
BATCH_SIZE_PER_KAFKA_PARTITION = 2000000
-- RESET_KAFKA_GROUP_OFFSETS = '1740931200000' -- epoch in millis of 2025-03-03 00:00:00
COPY_JOB_HINT = '{"cz.sql.split.kafka.strategy":"size","cz.mapper.kafka.message.size":"200000"}' -- to accelerate load
AS COPY INTO ods_commit_log FROM (
SELECT
remove_json(parse_json(j['event']::string), '$.statements') as event,
parse_json(parse_json(j['event']::string)['statements']::string) as statements,
j['op_type']::string as op_type,
j['datasource_id']::string as datasource_id,
j['database_name']::string as database_name,
j['schema_name']::string as schema_name,
j['table_name']::string as table_name,
timestamp_millis(j['event_ts']::bigint) as event_ts,
j['event_seq']::string as event_seq,
timestamp_millis(j['server_ts']::bigint) as server_ts,
j['server_seq']::bigint as server_seq,
`timestamp` as __kafka_timestamp__
FROM (
SELECT `timestamp`, parse_json(value::string) as j
FROM read_kafka(
'kafka-bootstrap-1:9092,kafka-bootstrap-2:9092,kafka-bootstrap-3:9092', -- bootstrap
'topic_name', -- topic
'', -- reserved
'sub2cz', -- kafka group id, for keeping read position
'', '', '', '', -- reserved
'raw', -- key format, can only be raw
'raw', -- value format, can only be raw
0,
MAP(
'kafka.security.protocol','PLAINTEXT',
'cz.kafka.fetch.retry.enable','true',
'cz.kafka.fetch.retry.times','20',
'cz.kafka.fetch.retry.intervalMs','2000'
)
)));
Pipe 使用 kafka group 来记录读取的点位,因此只要使用相同的 kafka 集群、topic 及 group id,即使重建 pipe,点位也不会丢失,可以实现「断点续传」的效果。
但是 RESET_KAFKA_GROUP_OFFSETS 会强制改写 group id 中记录的点位,需要谨慎使用。