将数据导入云器Lakehouse的完整指南
数据入湖:通过云器Lakehouse Studio内置的Python节点从web加载文件入湖
概述
云器Lakehouse Studio内置了Python节点,可以开发和运行Python代码。
使用场景
适合在数据入湖时需要调用第三方Python代码库对文件进行处理,比如本示例中调用了阿里云对象存储OSS的Python代码库。
实现步骤
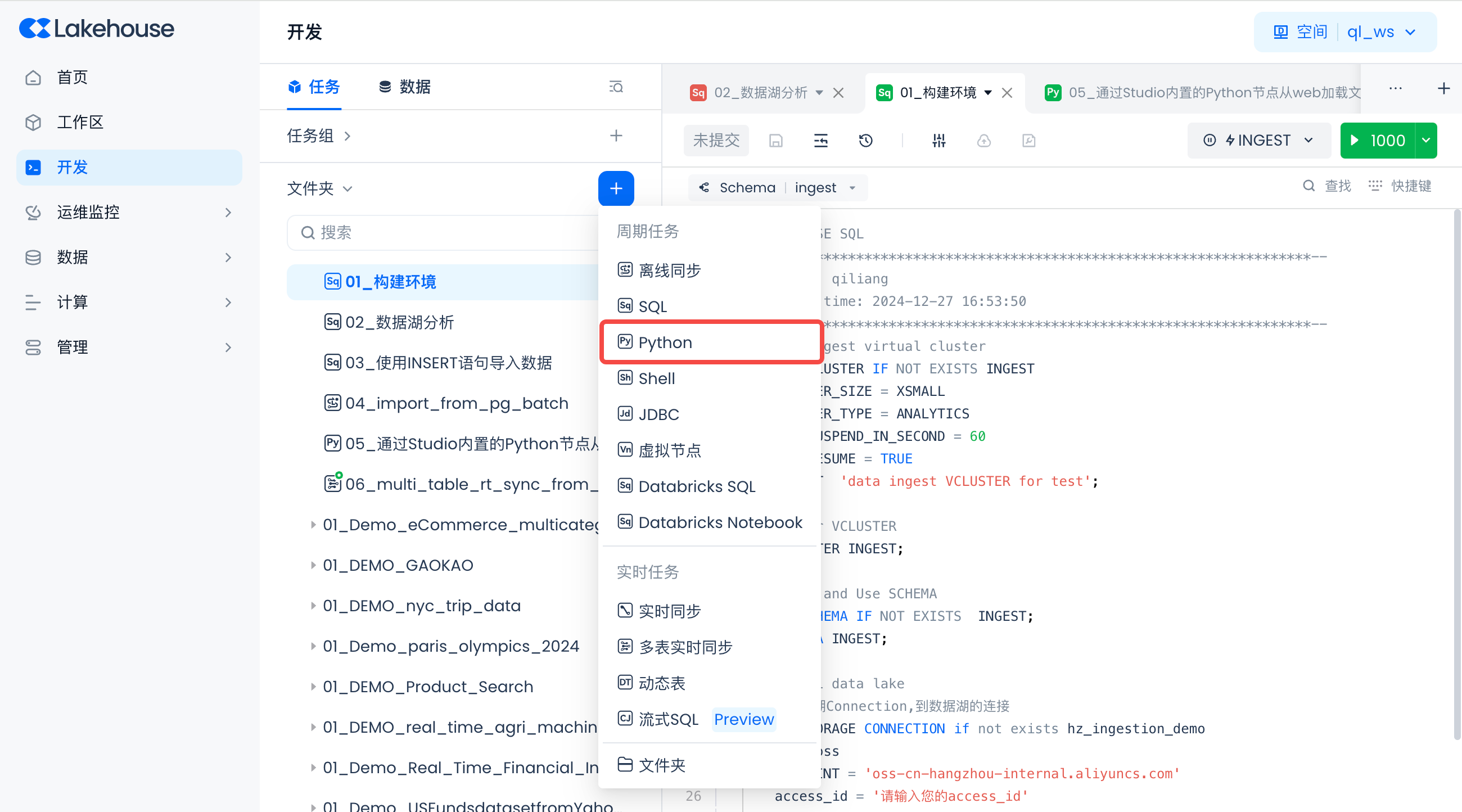
新建Python任务
导航到开发->任务,单击“+”,新建一个Python任务。
任务名:05_通过Studio内置的Python节点从web加载文件入湖。
开发Python任务代码
将如下代码粘贴到新建Python任务的代码编辑器里:
import os,io
import subprocess
from datetime import datetime, timedelta
import oss2
阿里云OSS配置:
ACCESS_KEY_ID = '${ak}'
ACCESS_KEY_SECRET = '${sk}'
BUCKET_NAME = '你的bucketname'
ENDPOINT = 'oss-cn-hangzhou-internal.aliyuncs.com'
ROOT_PATH = f'{BUCKET_NAME}/ingest_demo/from_web'
try:
# 构建wget命令
url = f"https://github.com/yunqiqiliang/clickzetta_quickstart/blob/main/a_comprehensive_guide_to_ingesting_data_into_clickzetta/data/lift_tickets_data.csv.gz"
cmd = ["wget", "-qO-", url]
print(f"wget cmd: {cmd}")
# 执行wget命令并捕获输出
wget_output = subprocess.check_output(cmd)
print(f"Wget file done...")
# 将输出转换为内存中的文件对象
file_obj = io.BytesIO(wget_output)
except Exception as e:
print(f"An error occurred: {e}")
file_obj = None
raise
if file_obj:
try:
# 初始化阿里云OSS
auth = oss2.Auth(ACCESS_KEY_ID, ACCESS_KEY_SECRET)
bucket = oss2.Bucket(auth, ENDPOINT, BUCKET_NAME)
# 上传文件到OSS
oss_path = f"{ROOT_PATH}/lift_tickets_data.csv.gz"
print(f"osspath: {oss_path}")
bucket.put_object(oss_path, file_obj)
print(f"Put file to oss done...")
except Exception as e:
print(f"An error occurred: {e}")
finally:
# 关闭内存中的文件对象
file_obj.close()
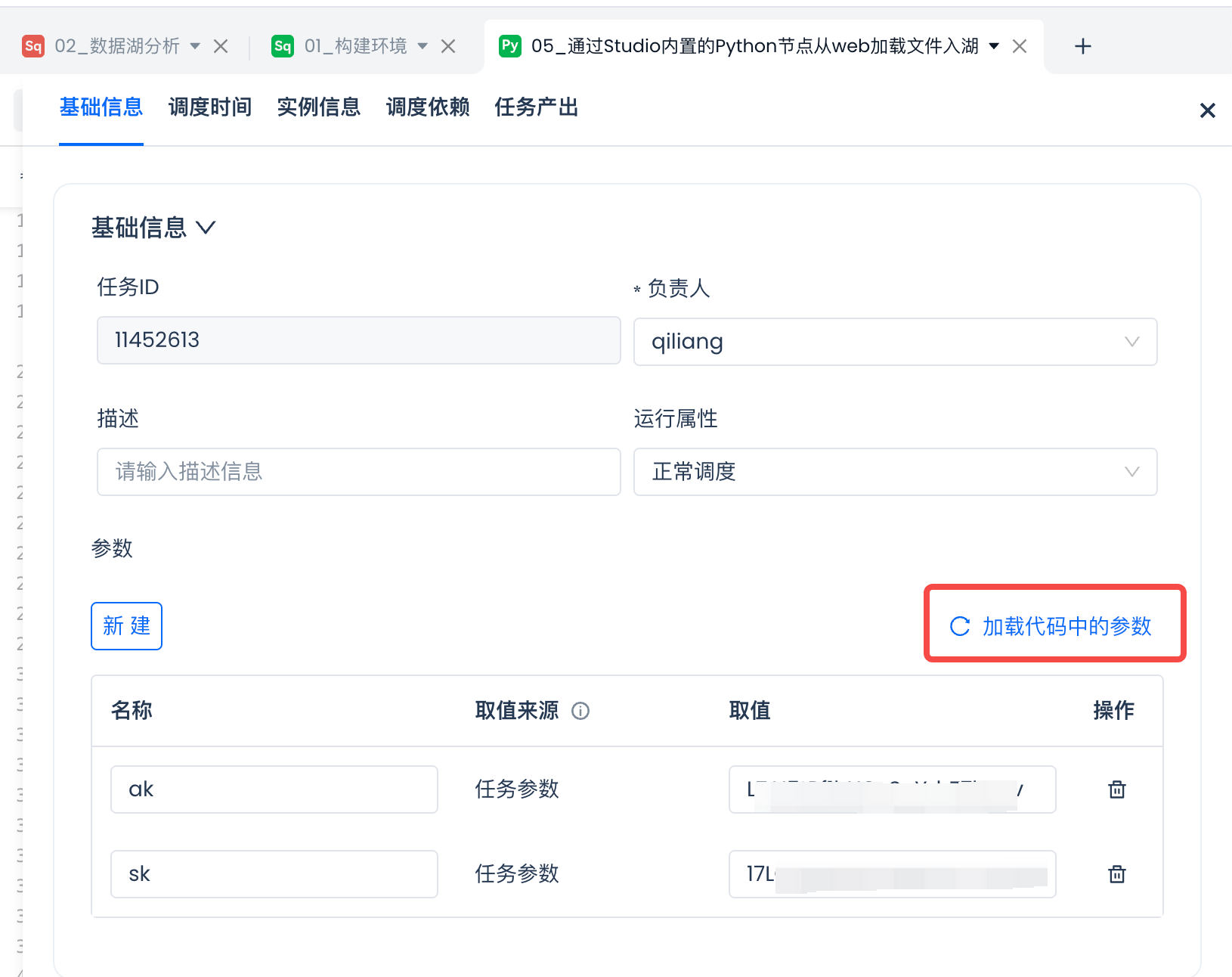
给任务配置参数
其中有两个参数:
ACCESS_KEY_ID = '${ak}'ACCESS_KEY_SECRET = '${sk}'
通过点击“调度”为参数填上默认值:

点击“加载代码中的参数”,并为参数填写对应的值:
运行测试
点击“运行”,执行Python代码。
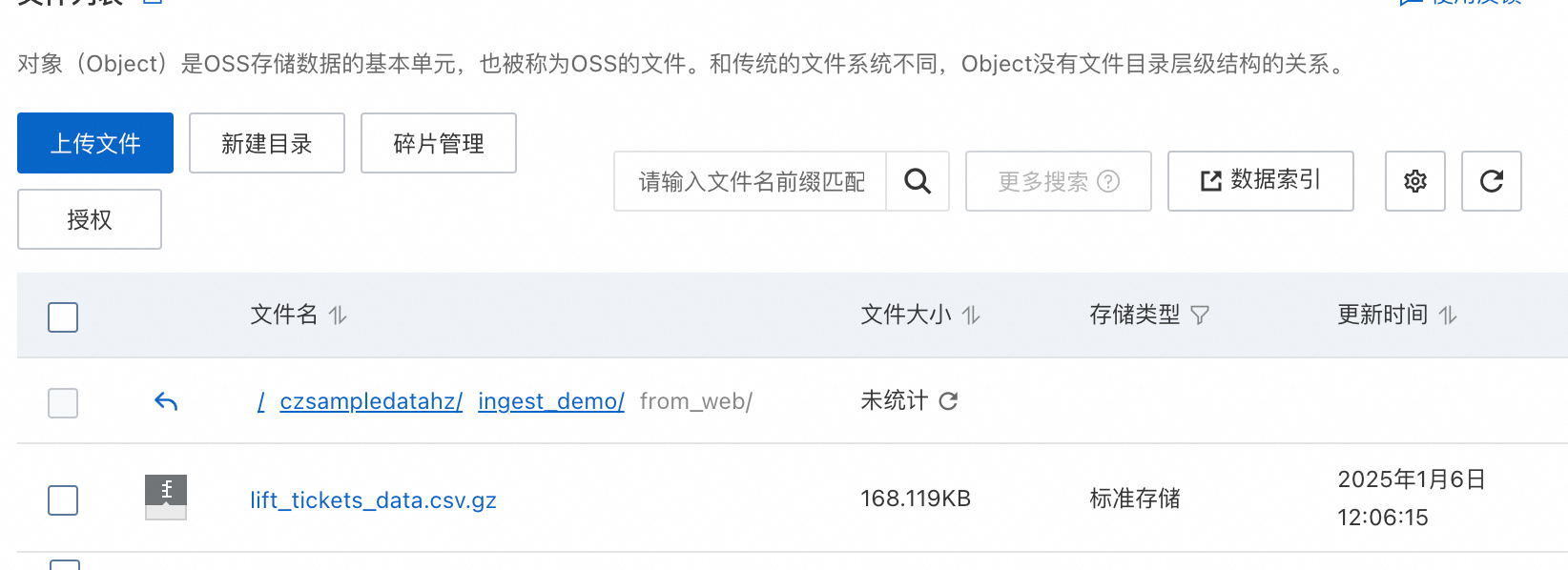
检查上传结果
登录阿里云对象存储,查看上传的文件。
下一步建议
- 调度Python任务,实现周期性数据入湖。
- 对加载到数据湖里的文件通过SQL进行数据湖分析。
- 与其他任务形成完整的ELT工作流。
资料
Studio Python任务节点
