
如何让 DataGPT 回答得更准确
作为一个基于数据的问答系统,回答的准确性尤为重要。系统提供以下手段来保障准确性:
1.数据治理
- 数据画像(DataGPT Profile):系统提供数据画像功能,让您了解底层数据集表的数据状态。通过 左侧导航栏 -> 数据 -> 数据表,在表详情页的 统计分析 页签,可以查看数据状态,帮助您进行数据治理。建立数据画像,也有助于通过自然语言找到合适的目标数据。
-
表、列描述与列别名配置:为表和列添加准确的描述和别名信息,这有助于系统精确地将问题与数据做匹配。在 左侧导航栏 -> 数据 -> 数据表 中,可以分别配置表级别的描述、列的别名(Alias)和列的描述(Description)。数据表和列有清晰准确的别名和描述,不同表和列在名称和描述上的歧义越小,回答的准确度越高。
-
列类型与用途:请根据列的实际含义填写列类型(ColumnType)与用途(Intended For)。该选项会影响系统是否选择该列作为数据来源。
2. 划分分析域
拆分业务域(或分析域)有助于系统更加聚焦于特定数据。
- 预先划分分析域,减少每个 Domain 里涉及的数据表范围和知识范围。
- 针对域(Domain)提问更为聚焦,同时域会绑定用户,能做到表级别的数据隔离。
3. 创建指标与答案构建器
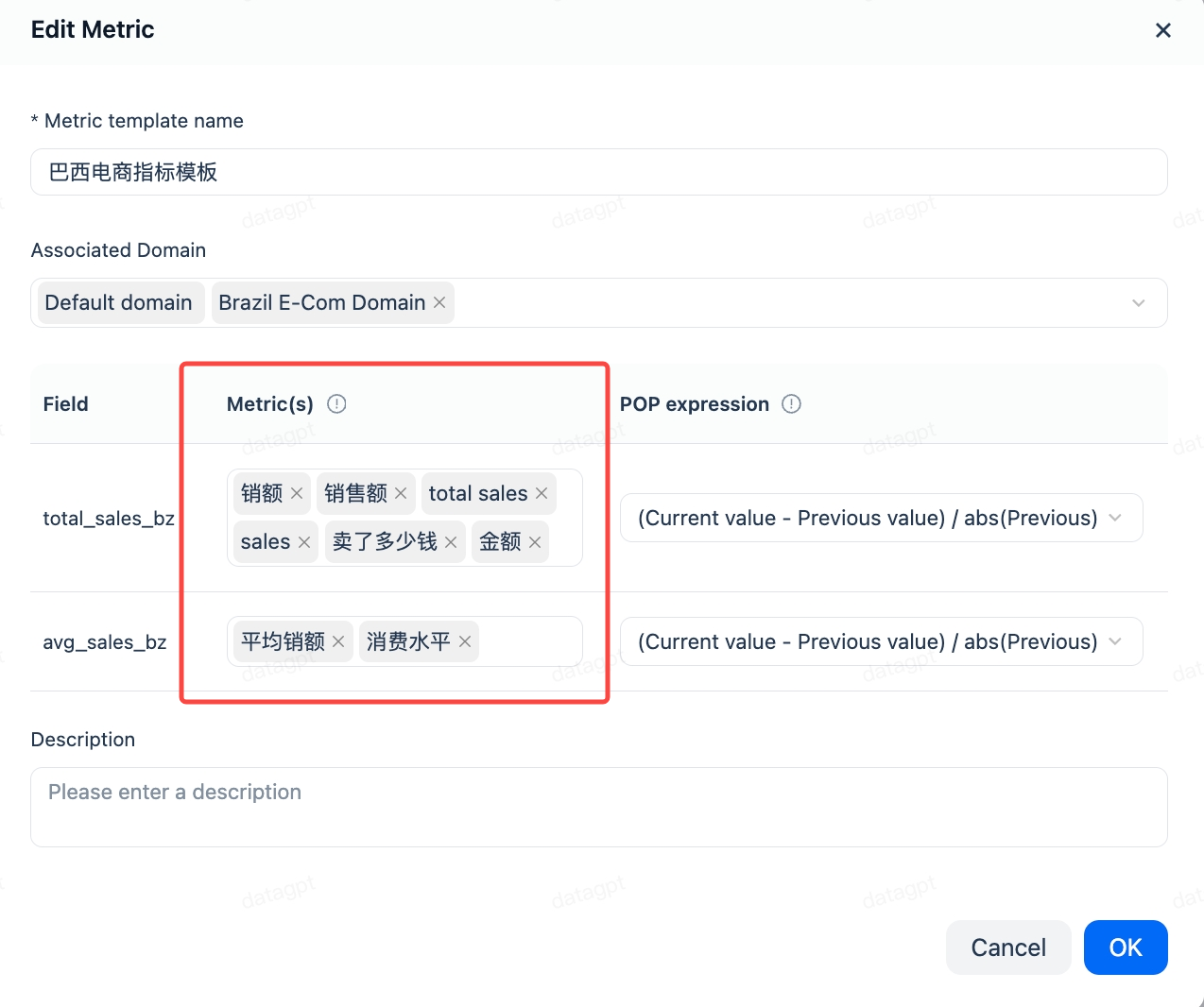
指标是聚合函数或基于聚合函数的计算结果,答案构建器是基于 SQL 的模板定义,两者均为预定义对象。基于指标和答案构建器进行回答,会使准确率大幅提升。如果对问答准确率有严格要求,建议预先定义好它们。指标支持别名,用于匹配更多的表达方式。请参考指标与答案构建器
4. 采用输入提示
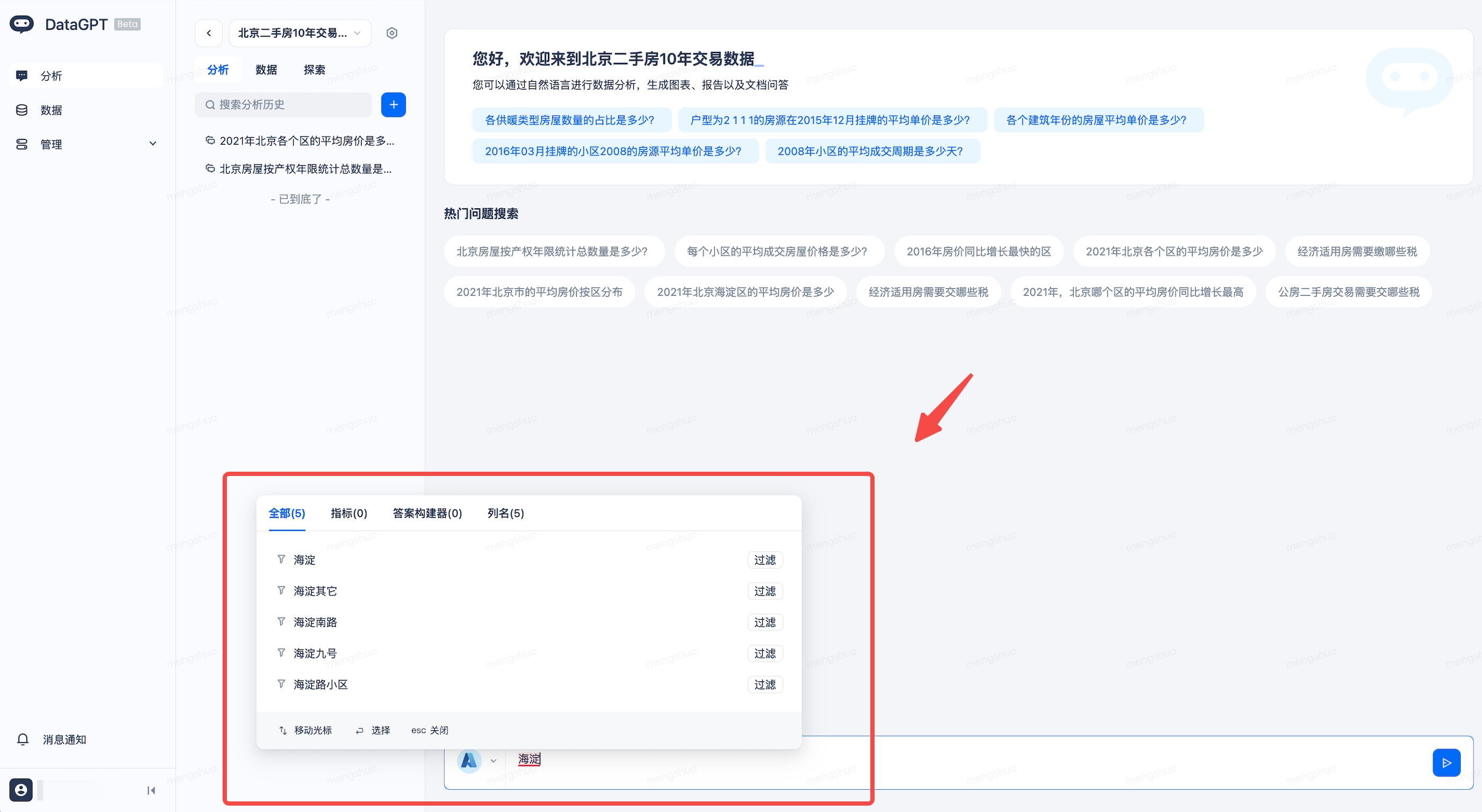
列值智能匹配:启用列值索引功能后,系统将在您输入时提供实时数据值提示,以确保查询结果的准确性与相关性。
联系我们