
入门指南:如何快速运行一条SQL
适用场景
Lakehouse 提供了一体化的引擎来支持数据的处理、加工和分析,其开发语言为 SQL。本文概要介绍如何通过Lakehouse Studio的任务开发功能模块快速编写和运行一条SQL语句来进行查询分析。
前置阅读
在阅读本指南之前,建议完成以下文档的阅读和理解:
操作指南
如果要快速在界面运行一条 SQL,需要使用 Lakehouse Studio 的数据开发模块,有两种方式:
方式一:基于样例SQL和样例数据来运行
产品中内置了开箱即用的样例代码和与之配套的样例数据。在页面导航,点击“开发”进入数据开发界面后即可看到
Tpch_100g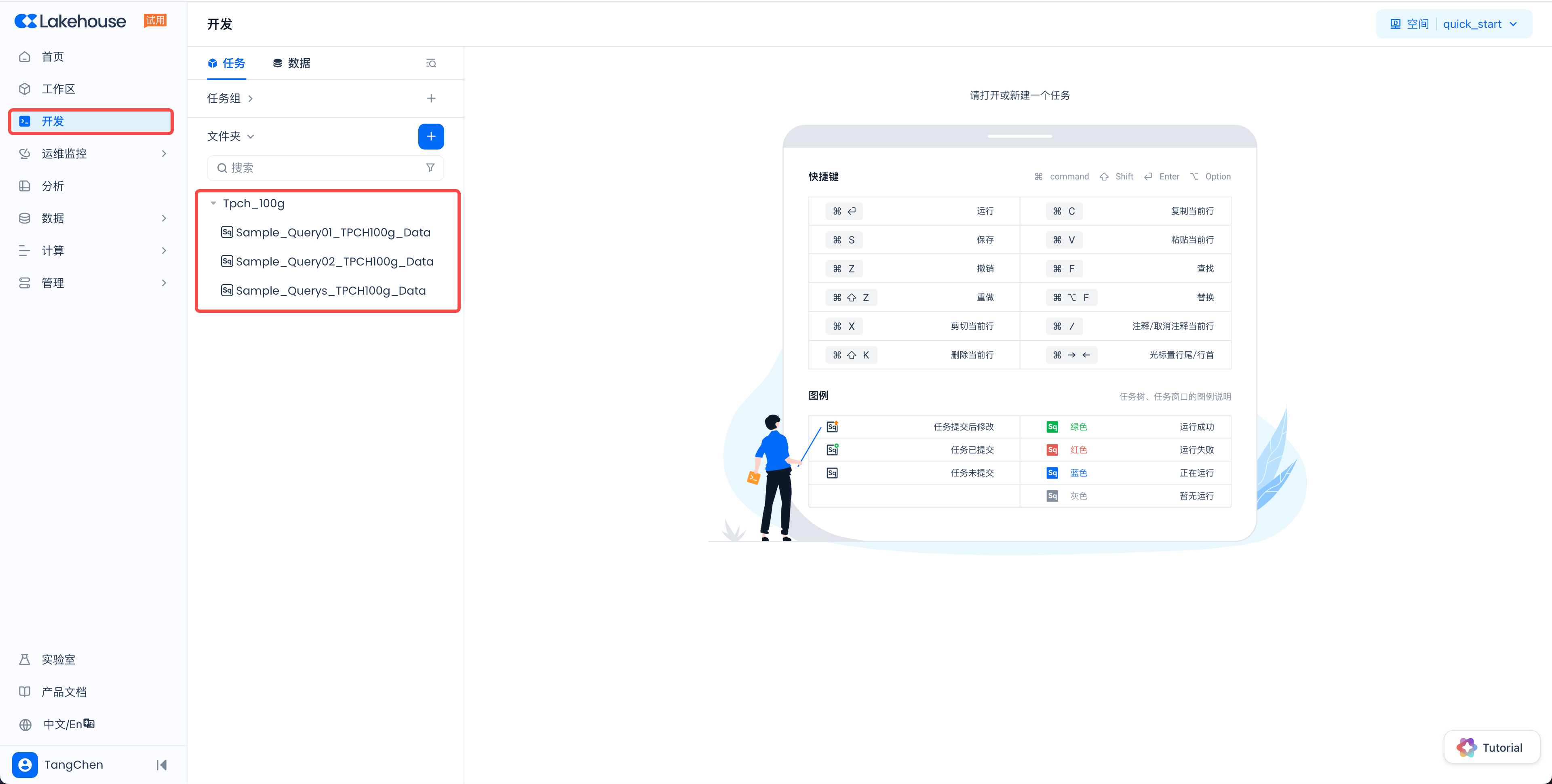
双击一个样例代码文件打开后,点击页面右上角的“运行”按钮,即可触发 SQL 的执行。执行完成后,在页面右下方可以查看执行结果和日志。
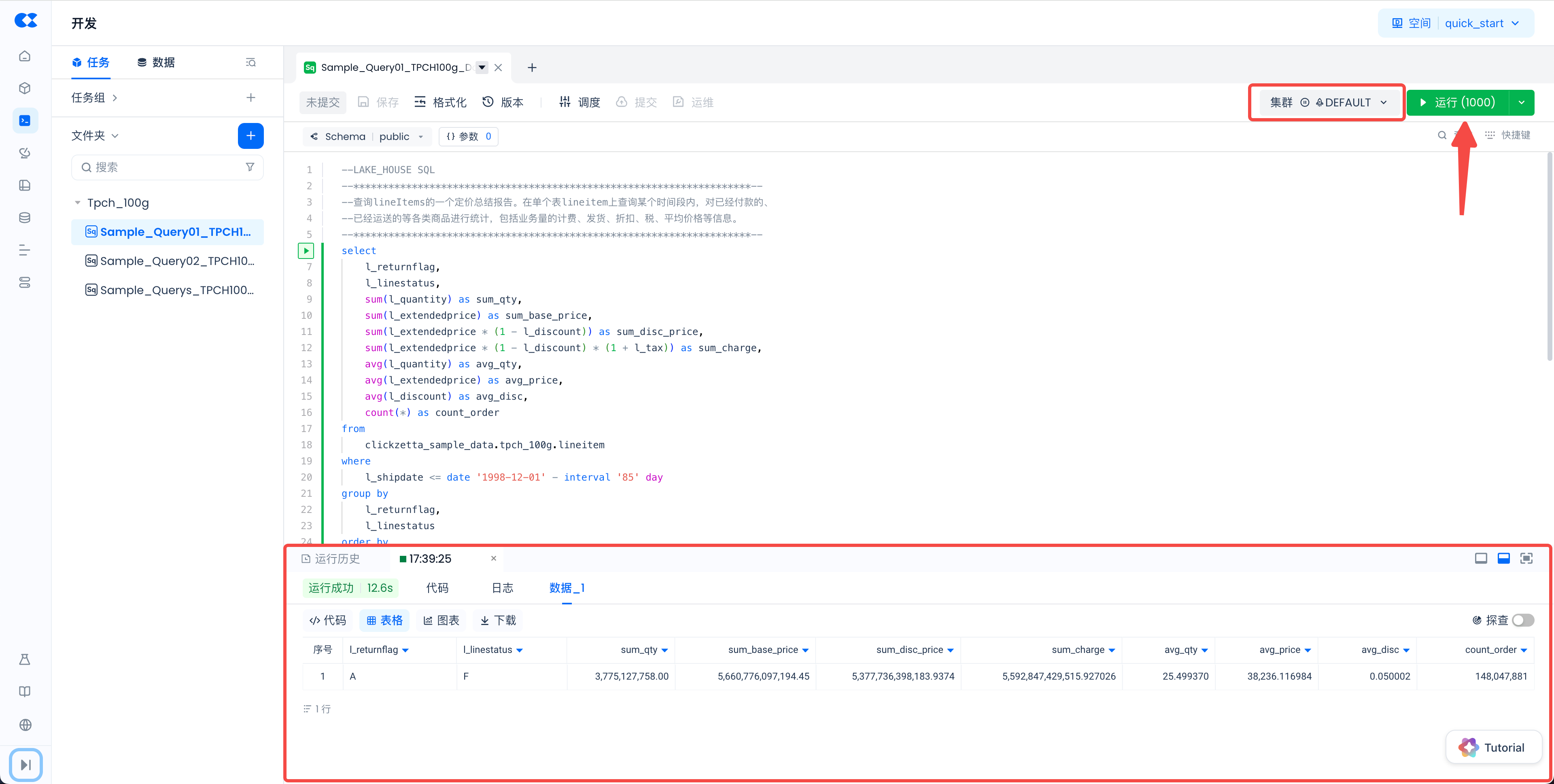
请特别注意页面右上角的集群选项。“集群”是“计算集群”的简称,是 Lakehouse 提供算力的核心概念,可参考 此文档 进行详细了解。工作空间创建后,会默认初始化两个集群:名为
DEFAULT DEFAULT_AP -
通用型(GENERAL PURPOSE,简称 GP):适用于处理离线作业,作业之间共享计算资源,新旧作业采用公平调度方式分配计算资源。适用于周期定时调度任务来处理大批量数据。
-
分析型(ANALYTICS PURPOSE,简称 AP):具备多计算实例和自动弹缩功能,适合处理在线和高并发作业。如果你想体验更强的数据查询性能,请选择此类型的集群。此外,AP 集群会对数据进行智能缓存。经过第一次查询后,后续查询的速度会更快。下图展示了这个差异:
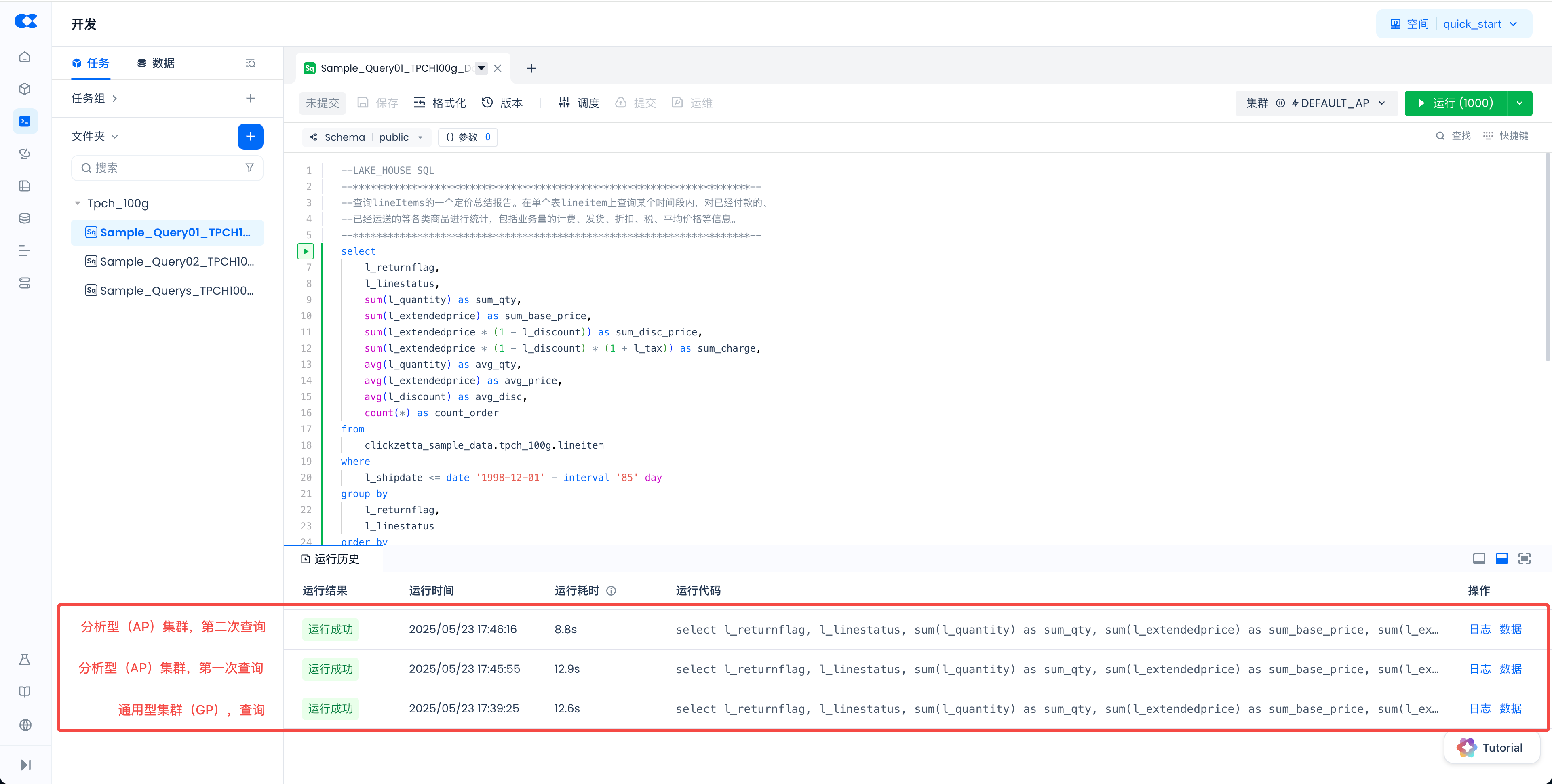
你也可以通过阅读 使用样例数据快速开始查询分析,进一步了解如何基于样例数据进行查询分析。
方式二:自己编写SQL并运行
除了使用样例代码和样例数据之外,你也可以自己编写 SQL 并运行。在页面导航栏,点击“开发”进入数据开发界面,在“任务”下,通过新建菜单,选择“SQL脚本”来创建一个 SQL 任务文件。
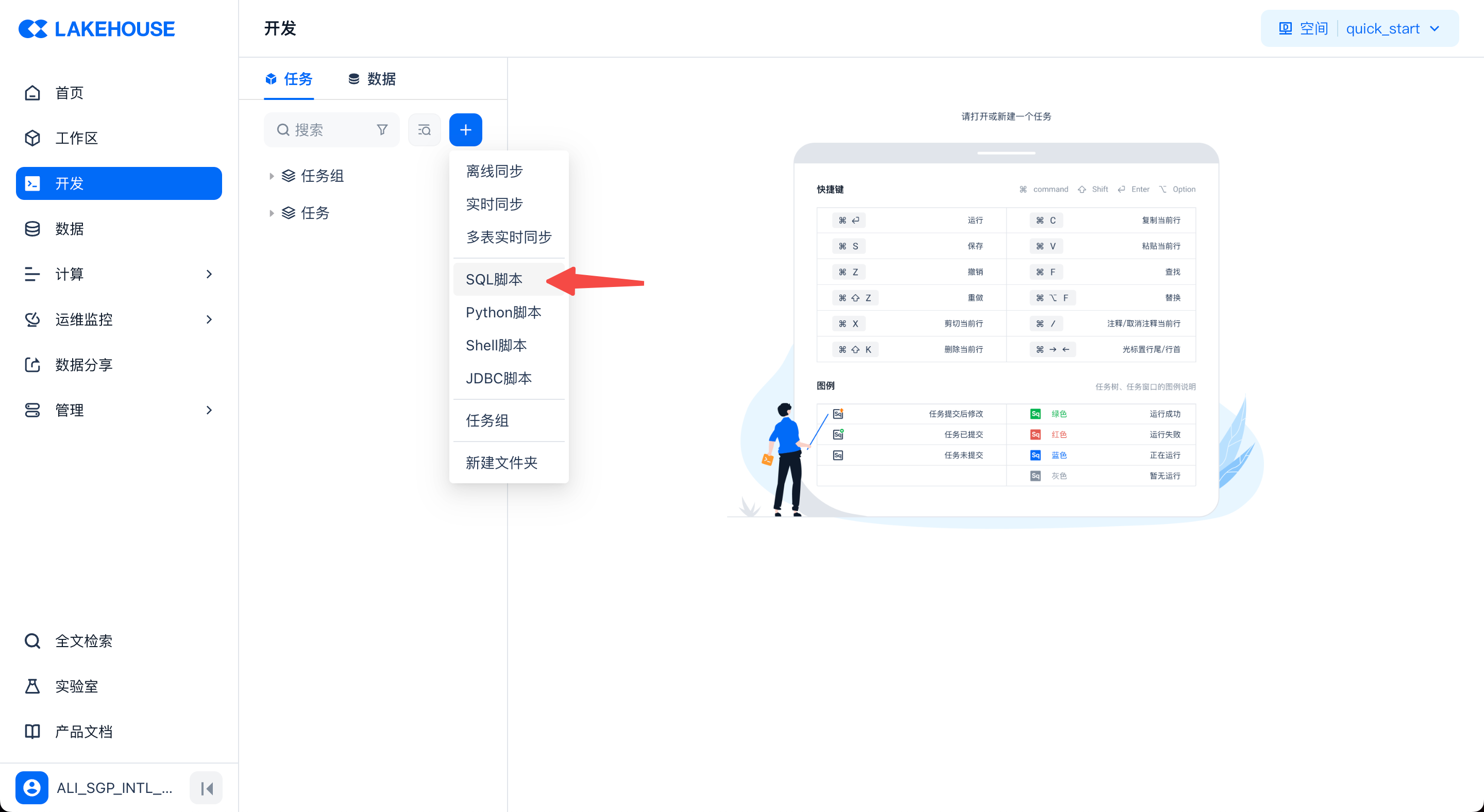
在任务文件中,可按以下步骤编写和运行 SQL:
-
在页面上选择正确的数据 Schema。编写代码时,对于该 Schema 下的表的引用,直接写表名即可;否则,需要使用
两段式或schema.table
三段式格式来引用表。通常使用系统默认 Schema 即可。workspace.schema.table -
在代码编辑区域填写需要运行的 SQL。
-
选择恰当的计算集群类型。对于 ad-hoc 临时查询,或者需要获得更快的查询响应速度,建议选择分析型(AP)集群。通用型(GP)集群适合大批量数据的离线、周期性调度任务的处理分析。
-
点击左侧的运行按钮或右上角的运行按钮来执行代码。左侧按钮只执行光标所在的代码块。右上角的按钮默认执行全部代码;也可以先选择部分代码,然后点击右上角的运行按钮来执行所选部分。
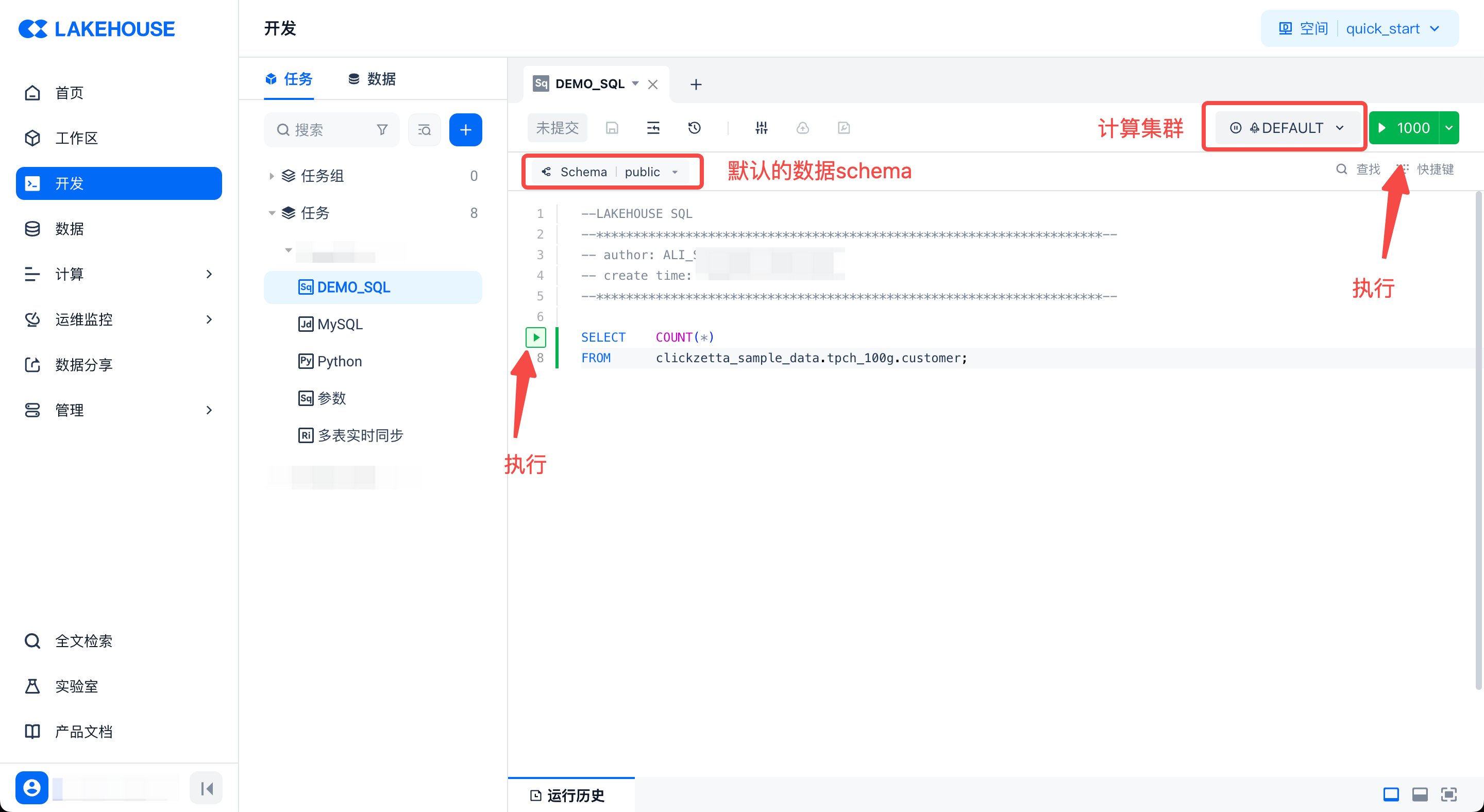
-
运行完成后,在页面下方区域可以查看运行结果、耗时和运行日志等信息:
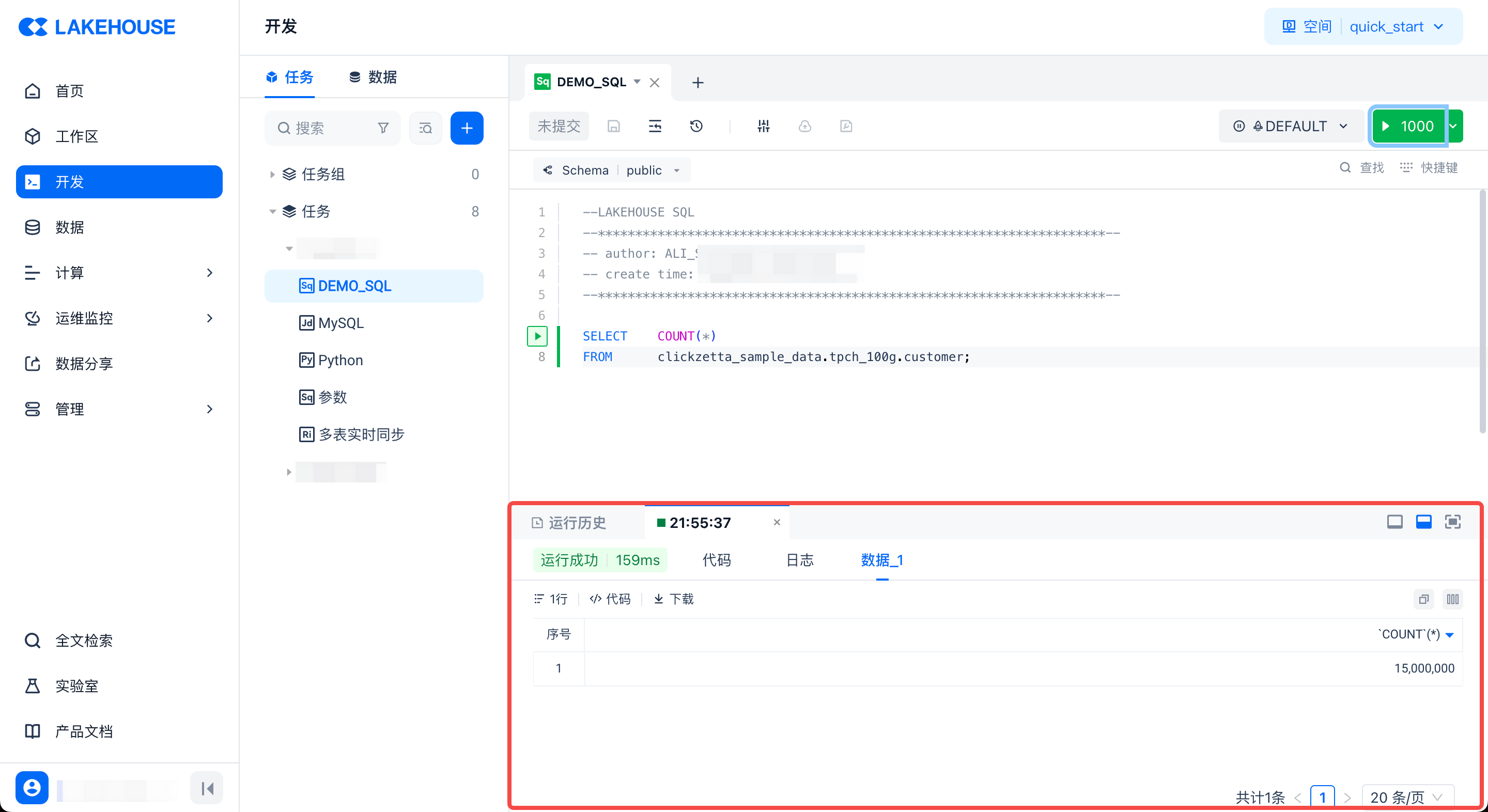
-
在编辑框编写代码时,也可以切换到“数据”标签页,来快速浏览和使用数据。找到所需使用的表后,在操作菜单中可快速插入表的名称、字段名称,或者直接生成查询样例 SQL:
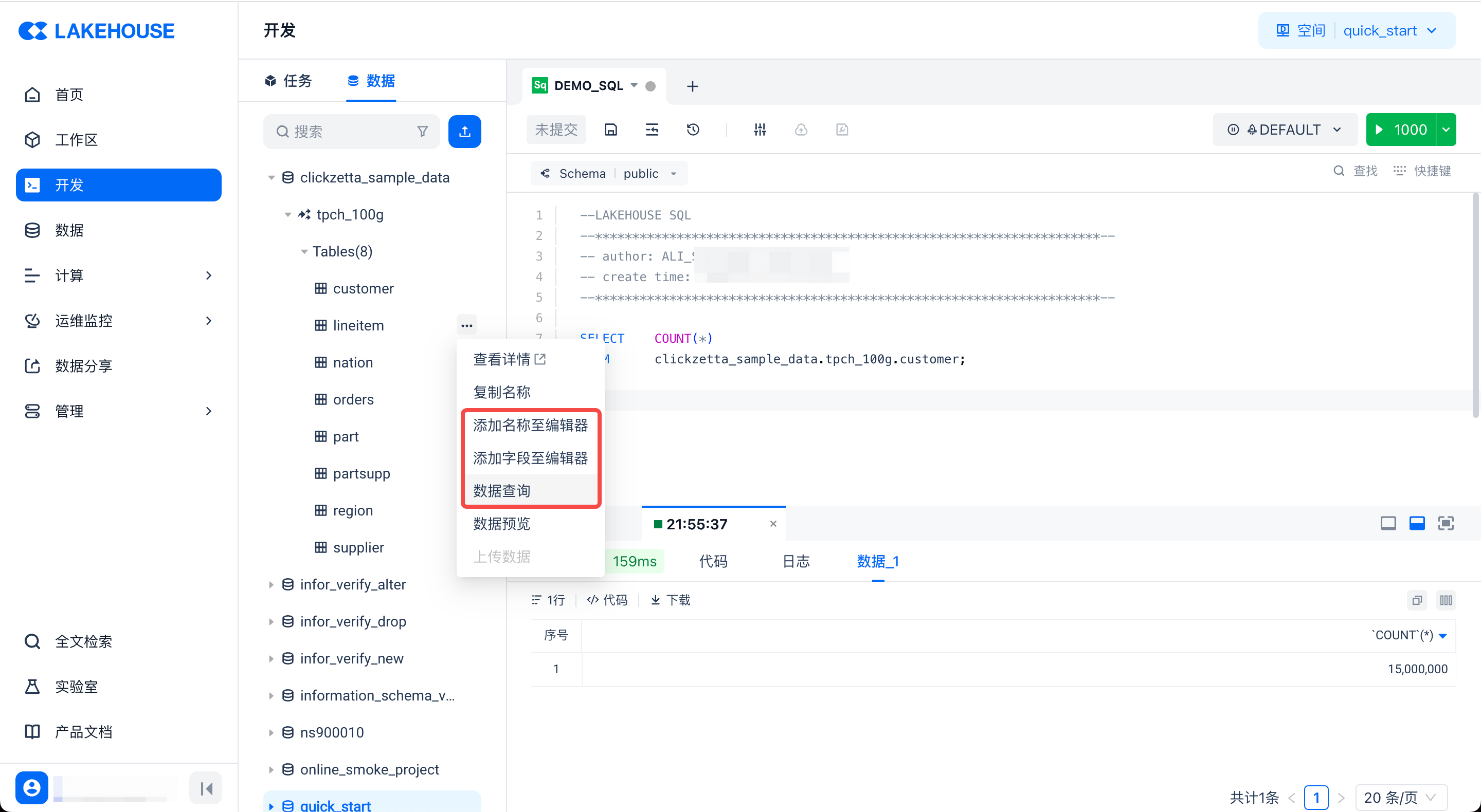
其它常用操作
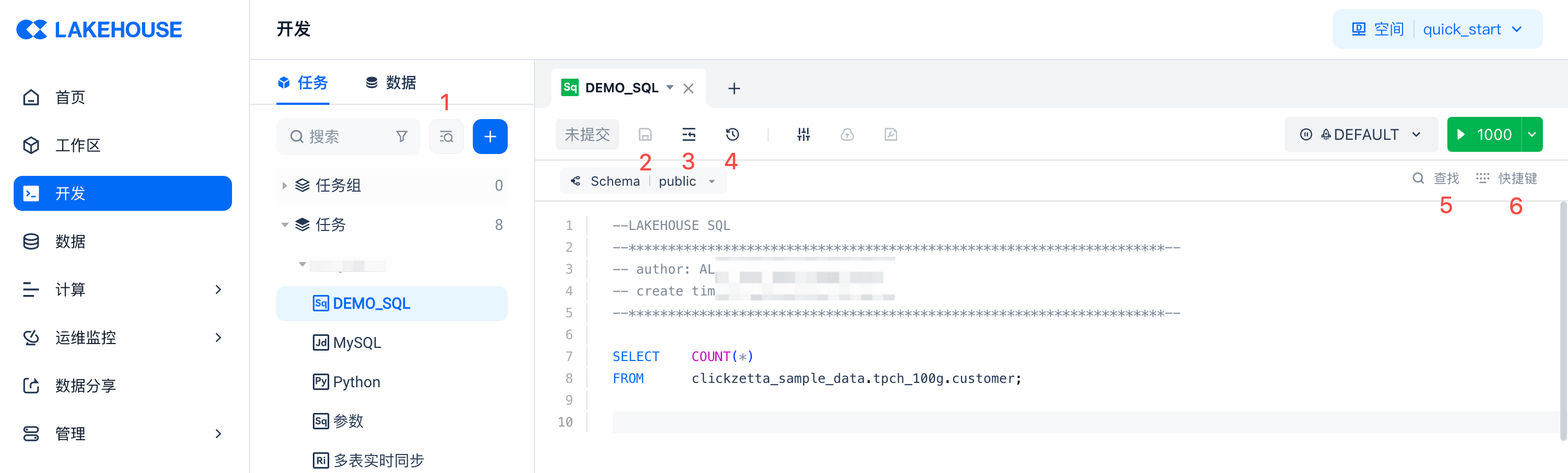
除了“运行”操作,系统还提供如下图所示的功能:
- 全局代码检索:通过代码关键字来查找文件
- 保存:保存当前文件修改的内容
- 格式化:对当前代码进行格式化排版
- 版本历史:可以查看文件的历史版本,并支持对比和回滚
- 查找:在当前文件内部通过关键字查找代码片段
- 快捷键:展示支持的常用快捷键
限制说明
- 权限控制:需要具备
或者工作空间管理员角色(workspace_admin)
权限的用户,才能使用任务开发功能并运行 SQL。工作空间开发角色(workspace_dev)
相关文档
- 你可以阅读 任务开发 来了解如何深度使用任务开发模块提供的详细功能。