Spark Connector概述
Lakehouse Connector for Spark 允许使用 Lakehouse 作为 Apache Spark 数据源,类似于其他数据源(PostgreSQL、HDFS、S3 等)。
Lakehouse和Spark之间的交互
该连接器支持 Lakehouse和 Spark 集群之间的双向数据移动。使用连接器,你可以执行以下操作:
- 读取Lakehouse 中的表转化为Spark DataFrame
- 将 Spark DataFrame 的数据写入 Lakehouse的表中。
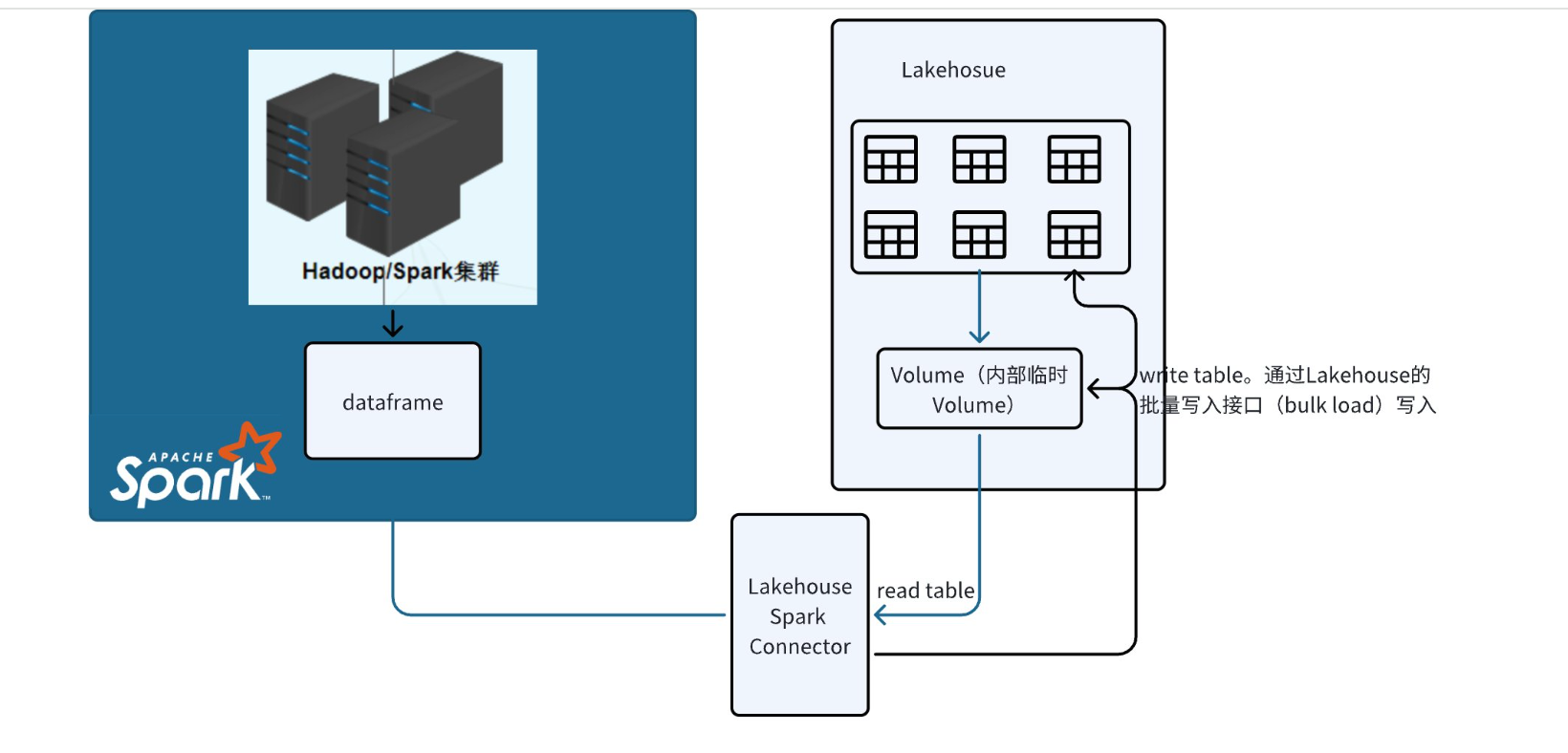
数据传输过程
两个系统之间的数据传输通过连接器自动创建和管理的Lakehouse volume实现.
- 连接到Lakehouse,执行查询时会将数据加载到临时volume中,connector使用该volume来存储数据。
- 写入Lakehouse,通过调用Lakehouse的bulkload批量写入sdk写入。
连接参数
| 参数 | 是否必填 | 描述 |
|---|
| endpoint | Y | 连接lakehouse的 endpoint 地址, eg:6861c888.cn-shanghai-alicloud.api.clickzetta.com。可以在Lakehouse Studio管理-》工作空间中看到jdbc连接串,jdbc连接串的中的域名就是endpoint |
| username | Y | 用户名 |
| password | Y | 密码 |
| workspace | Y | 使用的工作空间 |
| virtualCluster | Y | 使用的vc |
| schema | Y | 访问的schema名 |
| table | Y | 访问的表名 |
使用Spark命令行连接Lakehouse
- 从Spark官网下载Spark 3.4 jar包,本次案例下载是spark-3.4.3-bin-hadoop3.tgz
- 使用spark-shell命令行本地连接Lakehouse
bin/spark-shell --jars ./spark_conenctor/spark-clickzetta-1.0.0-SNAPSHOT-jar-with-dependencies.jar
import org.apache.spark.sql.functions.col
import com.clickzetta.spark.clickzetta.ClickzettaOptions
val readDf = spark.read.format("clickzetta").option(ClickzettaOptions.CZ_ENDPOINT, "lakehouse_url").option(ClickzettaOptions.CZ_USERNAME, "user").option(ClickzettaOptions.CZ_PASSWORD, "password").option(ClickzettaOptions.CZ_WORKSPACE, "quikc_start").option(ClickzettaOptions.CZ_VIRTUAL_CLUSTER, "default").option(ClickzettaOptions.CZ_SCHEMA, "public").option(ClickzettaOptions.CZ_TABLE, "birds_test").load()
readDf.show()
- 使用spark-sql命令行连接Lakehouse
bin/spark-sql --jars ./jars/spark-clickzetta-1.0.0-SNAPSHOT-jar-with-dependencies.jar
CREATE TABLE lakehouse_table
USING clickzetta
OPTIONS (
endpoint 'lakehouse_url',
username 'user',
password 'password',
workspace 'quikc_start',
virtualCluster 'default',
schema 'public',
table 'birds_test'
);
- 使用pyspark命令行连接Lakehouse
bin/pyspark --jars ./jars/spark-clickzetta-1.0.0-SNAPSHOT-jar-with-dependencies.jar
df=spark.read.format("clickzetta").option("endpoint", "demo.cn-shanghai-alicloud.api.clickzetta.com").option("username", "user").option("password", "password").option("workspace","quick_start").option("virtualCluster", "default").option("schema", "public")option("table","birds_test").load()
df.show()
Lakehouse Spark Connector使用限制
- 不支持pk表写入
- 必须全字段写入, 不支持部分字段写入
使用Spark Connector实践案例
使用Spark写入Lakehouse数据
概述
不同平台之间的无缝数据传输对于有效的数据管理和分析至关重要。我们帮助许多客户解决的一个常见场景是使用Spark处理完数据写入到Lakehouse中,BI报表连接Lakehouse查询。
我们编写一个Spark程序,并在Spark环境中运行它,使用Lakehouse提供的Connector将数据写入到Lakehouse中
环境要求
-
具备Spark编程能力。可以参考使用 IntelliJ IDEA开发Spark
-
本次案例使用的数据是spark github上电影评分数据集,你可以通过此链接点击下载按钮下载
-
在Lakehouse中创建表
-
下载Lakehouse提供的Spark Connector包(目前由Lakehouse支持提供下载包),下载完成将jar打入到本地maven库中,方便在maven项目中引用和打包
-
修改pom.xml文件,添加如下依赖
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<spark.version>3.4.0</spark.version>
<scala.version>2.12.17</scala.version>
<scala.binary.version>2.12</scala.binary.version>
</properties>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-catalyst_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-compiler</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>com.clickzetta</groupId>
<artifactId>spark-clickzetta</artifactId>
<version>1.0.0-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<!-- scala编译插件 -->
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
</plugin>
<!-- java编译插件 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<!-- 插件的版本 -->
<version>3.8.1</version>
<!-- 编译级别 强制为jdk1.8-->
<configuration>
<source>1.8</source>
<target>1.8</target>
<!-- 编码格式 -->
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<!-- maven 打包插件 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<!-- 指定main的位置 -->
<mainClass>*</mainClass>
</transformer>
</transformers>
<filters>
<filter>
<artifact>*:*</artifact>
<!-- 过滤不需要的jar包 -->
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
import com.clickzetta.spark.clickzetta.ClickzettaOptions
import org.apache.spark.sql.SparkSession
object SparkLH {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder
.master("local")
.appName("ClickzettaSourceSuite")
.getOrCreate()
// 读取数据文件
val rdd = spark.sparkContext.textFile("./Downloads/sample_movielens_data.txt")
// 切割数据
val rddSplit = rdd.map(line => line.split("::"))
// 转换为DataFrame
import spark.implicits._
val df= rddSplit.map(arr => (arr(0).toInt, arr(1).toInt, arr(2).toFloat)).toDF()
//写入到Lakehouse中
df.write.format("clickzetta")
.option(ClickzettaOptions.CZ_ENDPOINT, "demo.cn-shanghai-alicloud.api.clickzetta.com")
.option(ClickzettaOptions.CZ_USERNAME, "username")
.option(ClickzettaOptions.CZ_PASSWORD, "paswword")
.option(ClickzettaOptions.CZ_WORKSPACE, "quick_start")
.option(ClickzettaOptions.CZ_VIRTUAL_CLUSTER, "default")
.option(ClickzettaOptions.CZ_SCHEMA, "public")
.option(ClickzettaOptions.CZ_TABLE, "sample_movie_data")
.mode("overwrite")
.save()
spark.stop()
}
}
使用Spark ML处理Lakehouse数据
目标:
通过读取存在于Lakehouse的数据,使用Spark ML训练一个推荐模型来预测用户对电影的评分,并且使用排名指标来评估模型的性能。
环境准备
pip install pytspark
$example off$:
from pyspark import SparkConf, SparkContext
from pyspark.sql import SQLContext
from pyspark.sql.types import *
$example on$:
from pyspark.mllib.recommendation import ALS, Rating
from pyspark.mllib.evaluation import RegressionMetrics
import os
os.environ['PYSPARK_SUBMIT_ARGS'] = '--jars 。/Downloads/spark-clickzetta-1.0.0-SNAPSHOT-jar-with-dependencies.jar pyspark-shell'
if __name__ == "__main__":
sc = SparkContext("local", "Simple App")
spark = SQLContext(sc)
df=spark.read.format("clickzetta").option("endpoint", "demo.cn-shanghai-alicloud.api.clickzetta.com").option("username", "user").option("password", "password").option("workspace", "qucik_start").option("virtualCluster", "default").option("schema", "public").option("table", "sample_movie_data").load()
# 将DataFrame转换为RDD并解析为Rating对象
ratings = df.rdd.map(lambda row: Rating(row.user_id, row.movie_id, row.rating-2.5))
# 继续后续的模型训练和评估步骤
model = ALS.train(ratings, rank=10, iterations=10, lambda_=0.01)
usersProducts = ratings.map(lambda r: (r.user, r.product))
predictions = model.predictAll(usersProducts).map(lambda r: ((r.user, r.product), r.rating))
ratingsTuple = ratings.map(lambda r: ((r.user, r.product), r.rating))
scoreAndLabels = predictions.join(ratingsTuple).map(lambda tup: tup[1])
metrics = RegressionMetrics(scoreAndLabels)
# Root mean squared error
print("RMSE = %s" % metrics.rootMeanSquaredError)
# R-squared
print("R-squared = %s" % metrics.r2)
# $example off$
