版本要求
| Connector | Spark | Scala |
|---|---|---|
| 1.0.0 | 3.4.0 | 2.12.13 |
获取Connector
请联系Lakehouse技术支持
参数说明
| 参数 | 是否必填 | 描述 |
|---|---|---|
| endpoint | Y | 连接lakehouse的 endpoint 地址, 例如: demo.cn-shanghai-alicloud.api.clickzetta.com |
| username | Y | 用户名 |
| password | Y | 密码 |
| workspace | Y | 使用的工作空间 |
| virtualCluster | Y | 使用的vc |
| schema | Y | 访问的schema名 |
| table | Y | 访问的表名 |
数据类型映射
| Spark数据类型 | Lakehouse数据类型 |
|---|---|
| BooleanType | BOOLEAN |
| ByteType | INT8 |
| ShortType | INT16 |
| IntegerType | INT32 |
| LongType | INT64 |
| FloatType | FLOAT32 |
| DoubleType | FLOAT64 |
| DecimalType | DECIMAL |
| BINARYType | BINARY |
| DateType | DATE |
| TimestampNTZType | Timestamp_NTZ |
| TimestampType | TimestampType_LTZ |
| ArrayType | Array |
| MapType | Map |
| StructType | Struct |
使用及测试
准备工作
本地测试pom依赖
<properties> <spark.version>3.4.0</spark.version> <scala.version>2.12.13</scala.version> <scala.binary.version>2.12</scala.binary.version> </properties> <dependencies> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_${scala.binary.version}</artifactId> <version>${spark.version}</version> <exclusions> <exclusion> <artifactId>log4j-slf4j2-impl</artifactId> <groupId>org.apache.logging.log4j</groupId> </exclusion> <exclusion> <artifactId>log4j-1.2-api</artifactId> <groupId>org.apache.logging.log4j</groupId> </exclusion> <exclusion> <artifactId>log4j-api</artifactId> <groupId>org.apache.logging.log4j</groupId> </exclusion> </exclusions> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_${scala.binary.version}</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-catalyst_${scala.binary.version}</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-compiler</artifactId> <version>${scala.version}</version> </dependency> <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-reflect</artifactId> <version>${scala.version}</version> </dependency> <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-library</artifactId> <version>${scala.version}</version> </dependency> <dependency> <groupId>com.clickzetta</groupId> <artifactId>spark-clickzetta</artifactId> <version>1.0.0-SNAPSHOT</version> <scope>system</scope> <systemPath>${package_path_prefix}/spark-clickzetta-1.0.0-SNAPSHOT-jar-with-dependencies.jar</systemPath> </dependency> </dependencies> # 注意 ${package_path_prefix} 需要替换成本地下载的 jar包路径
创建lakehouse表
CREATE TABLE spark_connector_test_table( v_bool boolean, v_byte byte, v_short short, v_int int, v_long long, v_float float, v_double double, v_string string, v_decimal decimal(10,2), v_timestamp timestamp, v_date date );
使用Spark 写入数据到Lakehouse
写入限制 (Follow bulkload 写入限制)
- 不支持pk表写入
- 必须全字段写入, 不支持部分字段写入
DataFrame写入
val spark = SparkSession.builder .master("local") .appName("ClickzettaSourceSuite") .getOrCreate() val rowSchema = StructType( List( StructField("v_bool", BooleanType), StructField("v_byte", ByteType), StructField("v_short", ShortType), StructField("v_int", IntegerType), StructField("v_long", LongType), StructField("v_float", FloatType), StructField("v_double", DoubleType), StructField("v_string", StringType), StructField("v_decimal", DecimalType.apply(10, 2)), StructField("v_timestamp", TimestampType), StructField("v_date", DateType) ) ) // bulkLoad require full field writing val data = spark.sparkContext.parallelize( Seq( Row(true, 1.byteValue(), 1.shortValue(), 1, 1L, 1.1f, 1.1d, "001", BigDecimal(100.123), Timestamp.valueOf("2024-05-12 17:49:11.873533"), Date.valueOf("2024-05-13") ) ) ) val df = spark.createDataFrame(data, rowSchema) df.write.format("clickzetta") .option(ClickzettaOptions.CZ_ENDPOINT, endpoint) .option(ClickzettaOptions.CZ_USERNAME, username) .option(ClickzettaOptions.CZ_PASSWORD, password) .option(ClickzettaOptions.CZ_WORKSPACE, workspace) .option(ClickzettaOptions.CZ_VIRTUAL_CLUSTER, virtualCluster) .option(ClickzettaOptions.CZ_SCHEMA, schema) .option(ClickzettaOptions.CZ_TABLE, table) .option(ClickzettaOptions.CZ_ACCESS_MODE, accessMode) .mode("append") .save()
使用lakehouse sqlline 查看数据

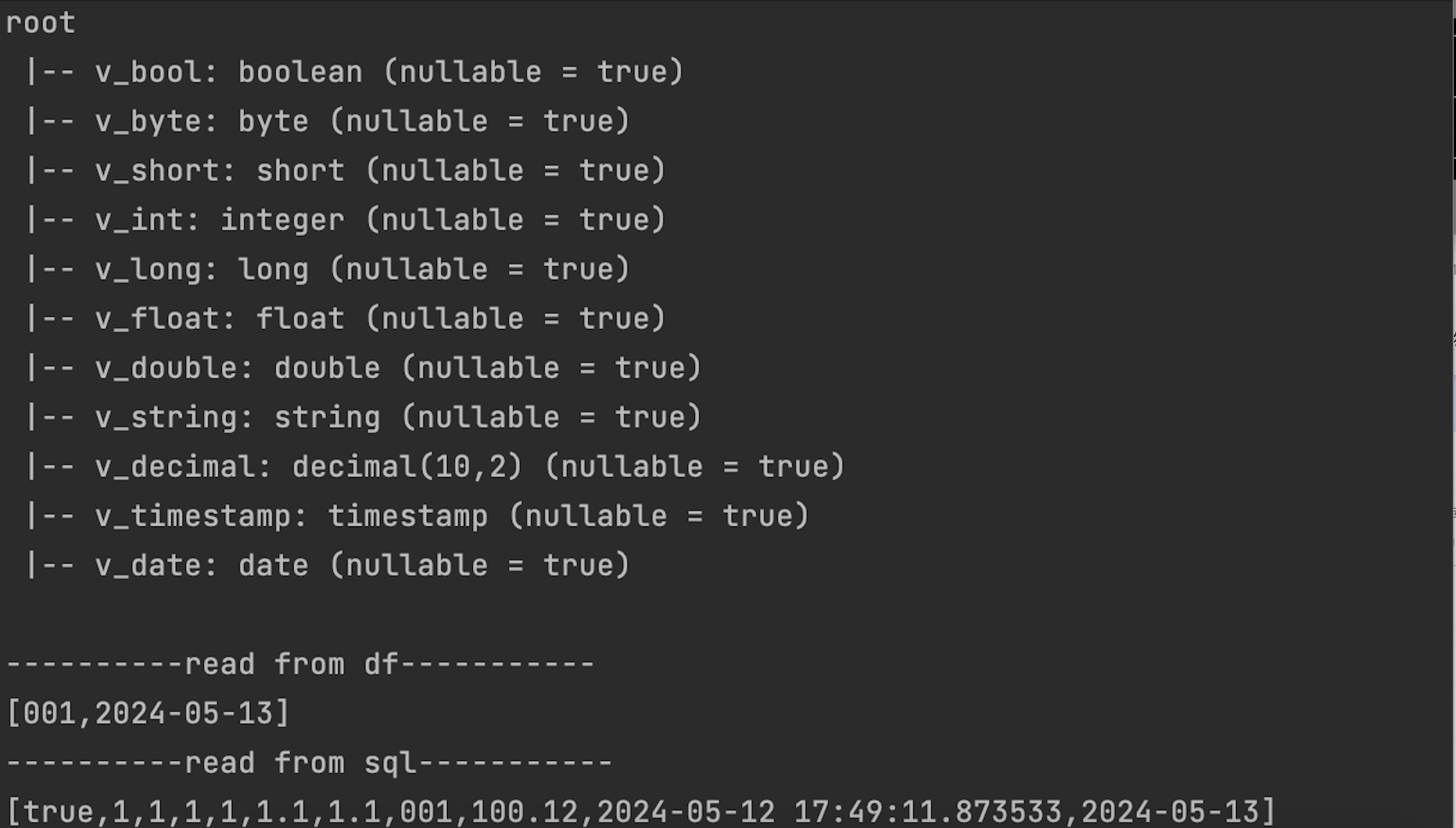
使用Spark 从Lakehouse读数据
val spark = SparkSession.builder .master("local") .appName("ClickzettaSourceSuite") .getOrCreate() val readDf = spark.read.format("clickzetta") .option(ClickzettaOptions.CZ_ENDPOINT, endpoint) .option(ClickzettaOptions.CZ_USERNAME, username) .option(ClickzettaOptions.CZ_PASSWORD, password) .option(ClickzettaOptions.CZ_WORKSPACE, workspace) .option(ClickzettaOptions.CZ_VIRTUAL_CLUSTER, virtualCluster) .option(ClickzettaOptions.CZ_SCHEMA, schema) .option(ClickzettaOptions.CZ_TABLE, table) .option(ClickzettaOptions.CZ_ACCESS_MODE, accessMode) .load() readDf.printSchema() val result1 = readDf.select(col("`v_string`"), col("`v_date`")).collect() println("----------read from df-----------") for (row <- result1) { println(row.toString()) } readDf.createOrReplaceTempView("tmp_spark_connector_test_table") val result2 = spark.sql("select * from tmp_spark_connector_test_table where v_float = 1.1f;").collect() println("----------read from sql-----------") for (row <- result2) { println(row.toString()) }