作者:石静猛 云器科技解决方案总监
导读
当企业的数据体系被不断增加的链路、组件和成本拖住脚步时,真正阻碍创新的从不是算力,而是复杂度本身。云器 Lakehouse 重写了这一底层公式:以统一架构与通用增量计算,消除数据平台的结构性冗余,让实时变得简单,让全域数据真正可控。复杂度一旦被削平,成本就会成倍下降,效率就会自然涌现,而企业才能把资源回到最重要的地方——推动业务增长。
本文将通过以下三个部分进行分享:
- 降本增效问题的根源分析。
- 四大典型场景与最新技术实践——基于真实的客户场景,探讨增量计算、Kappa架构、资源管理新模式和高性能引擎等技术。
- 大数据平台架构的演进总结。
一、降本增效问题的根源分析
复杂度困局:TCO远超硬件成本
即使在AI如此火爆的今天,"降本增效"依然是所有客户交流中最普遍的关切之一。但大家往往容易将成本等同于硬件成本或资源成本。根据我们在众多真实客户场景中的分析,得出一个结论:
一个大数据平台的整体拥有成本(TCO)通常是硬件成本的三倍以上。
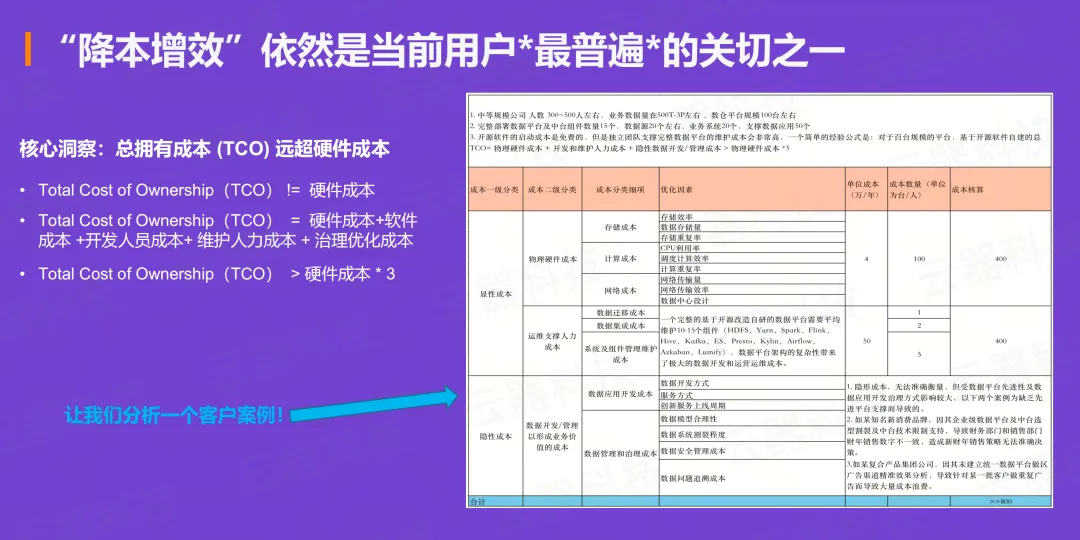
总拥有成本(TCO)的真实构成:
- 硬件成本: 物理资源投入
- 软件成本: 基于众多开源组件的自建成本
- 开发人员成本: 数据开发和管理的隐性成本
- 维护人力成本: 运维支撑团队的持续投入
- 治理优化成本: 数据质量、安全、血缘管理等成本
在一个真实的客户案例中,一个百台规模的平台,其物理硬件成本可能只占总成本的不到30%。而基于众多开源组件(如HDFS、Spark、Flink、Hive等)进行自建和的运维支撑所投入的成本,加起来远远超过了硬件本身。
根本原因:平台能力落后于业务创新速度
成本高企、效率低下的主要原因在于平台能力的发展落后于业务创新的速度。一开始成本问题不凸显,但随着业务发展、数据量增大、业务场景增多,大家不断地在原有架构上"堆积木"或"堆组件",这些非最优解最终导致成本问题愈发突出。
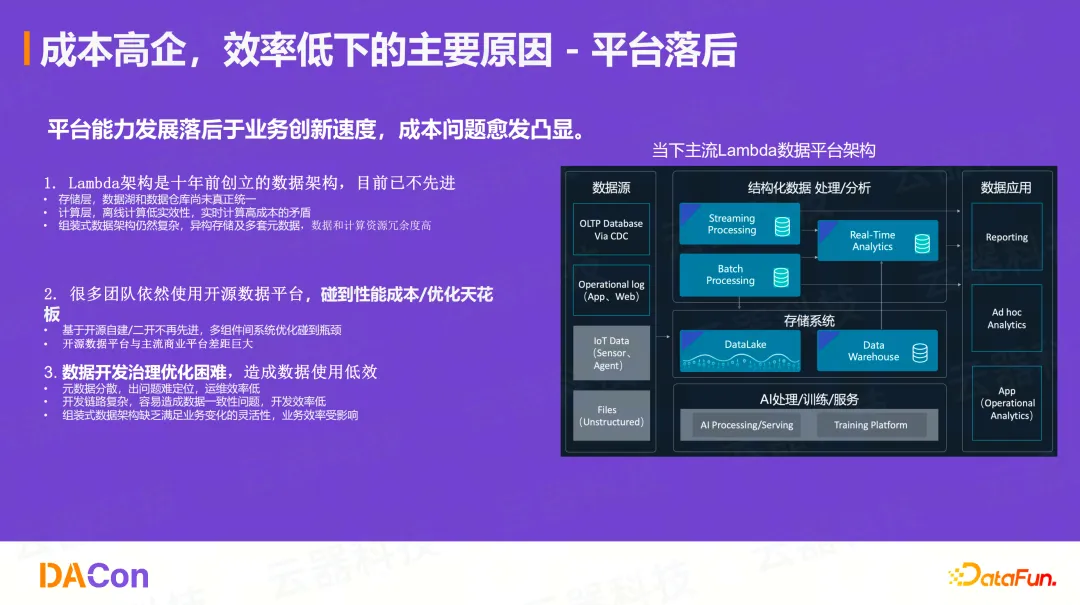
1、Lambda架构的三大结构性问题:
- 存储层: 数据湖和数据仓库尚未真正统一,造成数据冗余
- 计算层: 离线计算的时效性低,而实时计算的成本又过高,两者间的矛盾非常突出
- 架构层: 这种"组装式"架构非常复杂,异构存储和多套元数据导致数据和计算资源冗余度很高
2、开源组件的优化天花板
很多团队依然使用基于开源数据平台的多组件组装模式。当他们尝试进行性能优化时,很快会碰到"天花板"。一个端到端的链路可能涉及五个组件,其整体性能受限于木桶效应,即最差的那个组件。包括数据在不同组件间的导入导出环节,都极难优化。
这导致了:
- 端到端的性能极难优化,需要优化链路上的每一个环节,并且上限明显
- 数据分散且冗余,成本高昂,同时数据一致性难保证
- 元数据分散,出问题后定位困难,运维效率低
- 开发链路复杂,一个新业务可能涉及3-5个组件、3种SQL方言和Java
- 组装式架构缺乏灵活性,难以快速响应业务变化
二、四大典型场景与技术突破
我们总结了Lambda架构暴露出的"高成本、低效率"四大典型场景,并针对每个场景提供了基于统一架构和通用增量计算的创新解法。

- 场景一:实时加工成本高(成本相关)
- 场景二:资源割裂,数据冗余(成本相关)
- 场景三:多场景、多组件带来的开发效率低下(效率相关)
- 场景四:引擎性能低,算不出来(效率相关)
场景一:实时加工成本高——用通用增量计算重写成本结构
问题根源:Flink架构的四大成本困境
以主流的Flink实时数仓架构为例,其高成本主要源于:
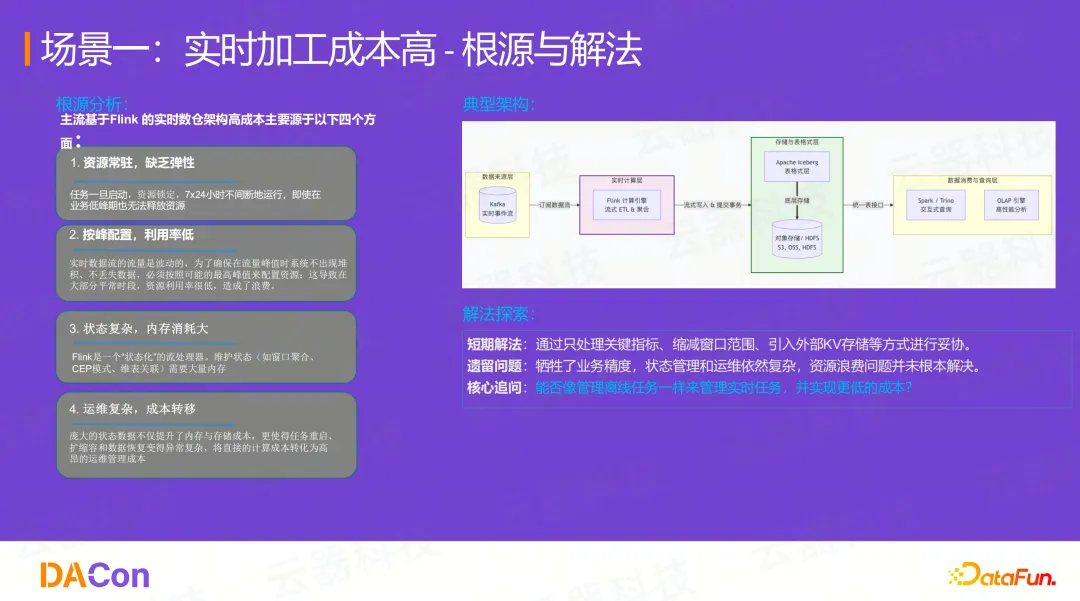
- 资源常驻,缺乏弹性: 任务7x24小时运行,即使在业务低谷,资源也无法释放;
- 按峰配置,利用率低: 必须按最高峰值配置资源,导致大部分平峰时段资源利用率极低;
- 状态复杂,内存消耗大: 维护窗口聚合、维表关联等状态需要消耗大量内存;
- 运维复杂,成本转移: 庞大的状态数据使得任务重启、扩缩容和数据恢复变得异常复杂。
传统解法的妥协困局
为了控制成本,业界的短期解法通常是"妥协":
- **牺牲指标:**100个指标中只选取10个最关键的指标做实时计算
- 牺牲精度: 业务逻辑本需要2小时的窗口,为了防止内存爆炸,强行缩减到30分钟
- 引入外部K/V: 引入Redis等系统来管理复杂的状态或维表
这些妥协牺牲了业务精度,但状态管理和资源浪费问题并未根本解决。
云器方案:通用增量计算(GIC)重写成本公式
云器科技的答案是通用增量计算(Generic Incremental Compute, GIC) 。GIC的核心思想是:用一套标准的、类似离线的SQL代码,通过动态调控计算周期(例如从天级调整到分钟级),灵活地在成本和新鲜度之间找到最佳平衡,同时解放开发效率。

通用增量计算(GIC)的本质,是将近实时的流式计算,转变为"主动计算"模式,使其在开发和管理上无限趋近于离线批处理,但又能达到分钟级的实时性。
通用增量计算(GIC)关键技术:

- 增量数据的获取 (增删改): 基于MVCC(多版本并发控制),快速获得两个版本间的Delta数据(增、删、改)。
- 完整的增量语法语义支持: 这是“通用”二字的核心。必须支持所有SQL算子(如Filter, Aggregate, 各种Join, 窗口函数, UDF)的增量计算,如果覆盖度不全,将很难在真实生产中大规模落地。
- 增量数据写入: 高效地将计算出的增量结果写入目标表。
通用增量计算(GIC)GIC的黄金标准:SPOT

- S (Standard SQL): 支持标准、统一、完整的SQL语法、语义及UDF
- P (Performance): 显著提升性能、降低成本。在同等新鲜度下(如5分钟),成本应成倍低于流计算
- O (Open Format): 数据采用开放格式(如Iceberg+Parquet),可被其他引擎直读
- T (Trade-off): 可通过参数动态调整调度周期,无缝在T+0和T+1间权衡
客户案例:某生活方式平台
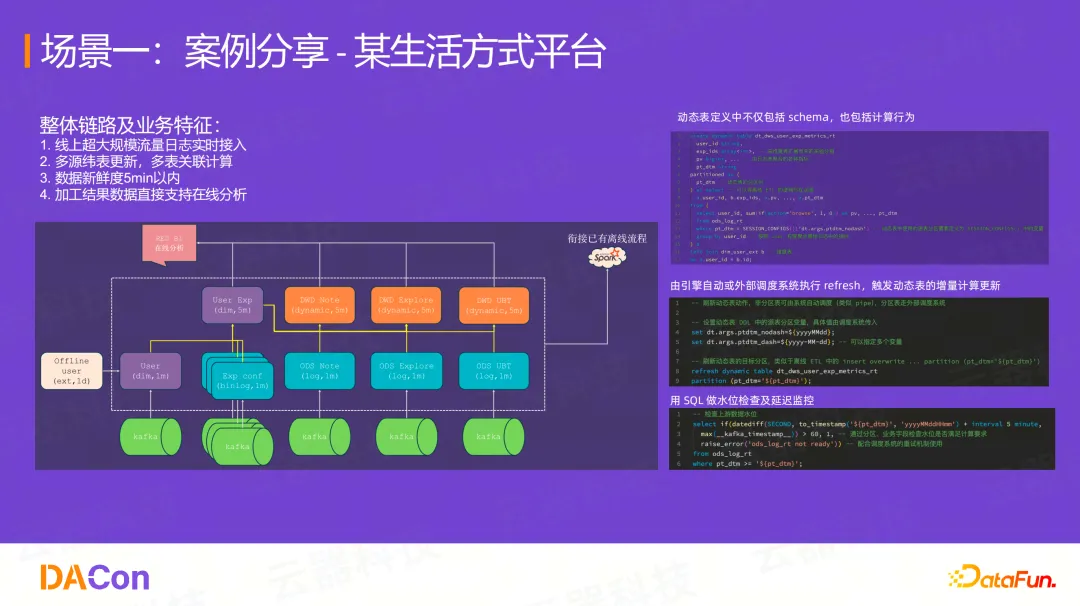
业务特征: 超大规模流量日志实时接入、多源维表更新、多表关联计算、数据新鲜度要求5分钟以内,且加工结果数据直接支持在线分析。
解决方案:
通过使用通用增量计算(GIC),用 CREATE DYNAMIC TABLE ... AS SELECT ... 语句来定义动态表。AS SELECT 之后的部分,完全就是用户T+1的离线SQL代码,可能只需改几个参数。
创建后,用户只需通过调度系统(例如每5分钟)执行一次 REFRESH DYNAMIC TABLE ...,系统便会自动获取这5分钟的增量数据,执行增量计算。
实施效果:

- 业务提升: 指标从原先受限于成本只能做的十几个,扩展到了上百个
- 架构简化: 替代了原有的Flink + Spark + Doris等多组件方案
- 成本降低: 实现了1/3的总成本(TCO)
- 资源成本1/3:降低了70%的整体资源消耗
- 开发成本1/3:统一增量链路,无需维护两套代码
- 架构成本1/3:Kappa架构一体化引擎替换了3个引擎的组合
场景二:资源割裂、数据冗余——用统一架构消除结构性浪费
问题根源:"1+N"平台体系
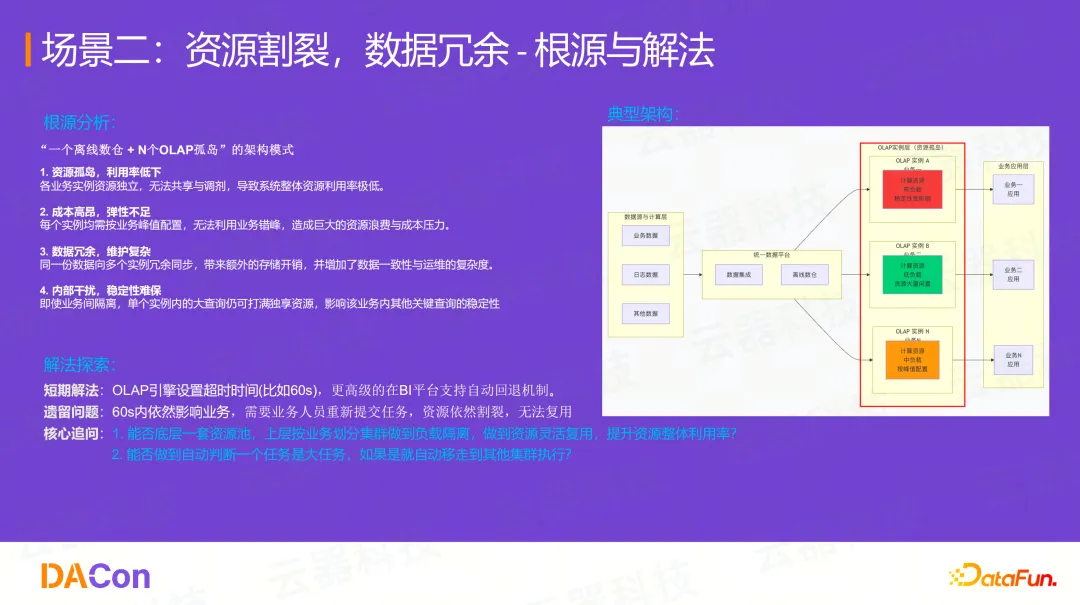
这是一个非常典型的架构:"1个离线数仓 + N个OLAP孤岛"。不同业务线为了避免互相干扰,各自部署一套OLAP实例(如ClickHouse、Doris等)。
这导致:
- 资源孤岛: 实例间资源无法共享,利用率低下(整体利用率不足30%)
- 成本高昂: 每个实例都需按峰值配置,弹性不足
- 数据冗余: 同一份数据被导入到N个实例中
- 稳定性差: 单个实例内的一个大查询能打满该集群资源,影响其他关键查询
传统解决方案:
常见的做法是在引擎层设置超时,如60秒。更高级的会在BI平台支持自动回退机制,即OLAP查询失败后自动回退到Spark上执行。但这依然会在60秒内影响业务,且资源割裂问题依旧存在。
核心追问:
1、能否实现底层一套资源池,上层按业务划分集群(负载隔离),同时做到资源灵活复用?
2、能否在任务运行前就自动判断其为“大任务”,并将其自动路由到其他集群执行?
云器方案:Virtual Cluster + 智能路由
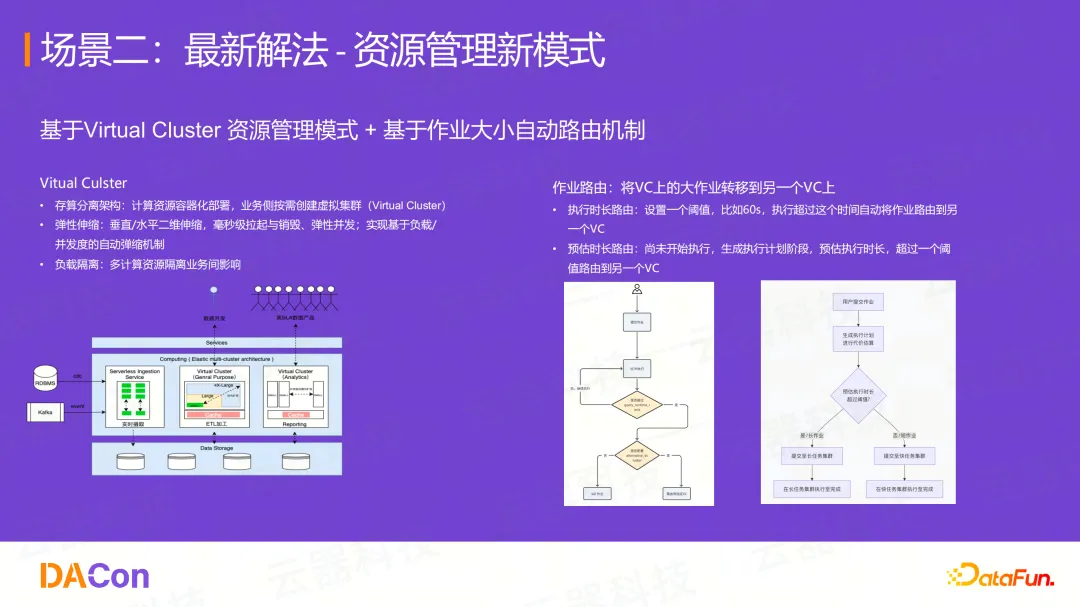
1、Virtual Cluster(VC)资源管理模式
基于存算分离和计算资源容器化,可以在一套物理资源池之上,按需创建虚拟集群。
- 弹性伸缩: VC支持垂直/水平的毫秒级拉起与销毁,实现基于负载的自动弹缩
- 负载隔离: 不同VC间实现计算资源隔离
- 资源复用: 底层资源池是共享的,可以灵活调度,实现"忙时多用,闲时少用",大幅提升整体资源利用率(如从30%提升到60%)
2、基于作业大小的智能路由机制
将VC上的大作业自动转移到另一个VC上(例如一个降级的VC)。
- 按执行时长路由: 设置阈值(如60秒),执行超过该时间自动路由。但这60秒内依然会影响集群。
- 按预估时长路由: 这才是更优解。 在任务尚未开始执行、生成执行计划的编译优化阶段,就预估其执行时长。如果超过阈值,则直接路由到其他VC执行,完全不影响当前集群的稳定性。
关键技术:
- 平台需支持多集群弹性资源管理 (VC)。
- 在编译优化阶段实现作业预估。
- 作业调度能按用户定义的规则(通过SQL透出)进行路由。

场景三:多场景、多组件——用统一引擎提升开发效率
问题根源:Lambda架构的"搭积木"模式
Lambda架构下,一个新场景引入一个新组件。离线链路用Hadoop/Spark,实时链路用Flink,即席查询用Presto,OLAP用Doris...
这导致了多开发语言、各种数据导出任务、血缘割裂、数据一致性难保证、治理困难等一系列问题。
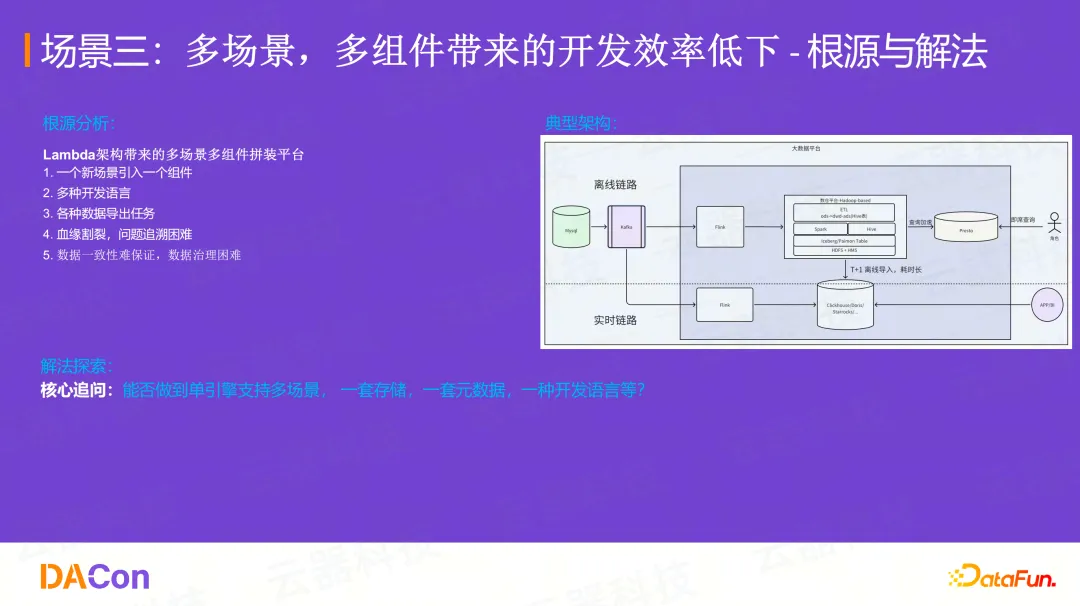
**核心追问:**能否做到单引擎支持多场景?并且是基于一套存储、一套元数据、一种开发语言来支持?
云器方案:从Lambda到Kappa架构的演进
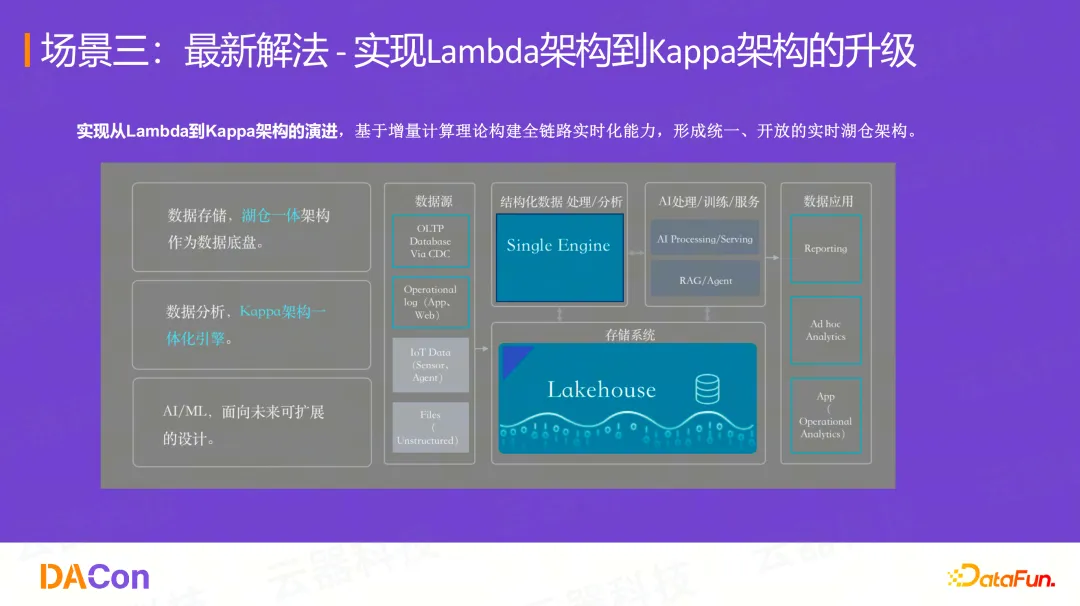
基于通用增量计算(GIC)理论,构建全链路的实时化能力,形成统一、开放的实时湖仓(Real-time Lakehouse)架构。对比之前的Lambda架构,Kappa架构实现了:
- 存储统一: Lakehouse作为统一的数据底座
- 计算统一: Single Engine支持结构化处理、分析、AI等全场景
- 元数据统一: 一套元数据管理所有数据
客户实践效果
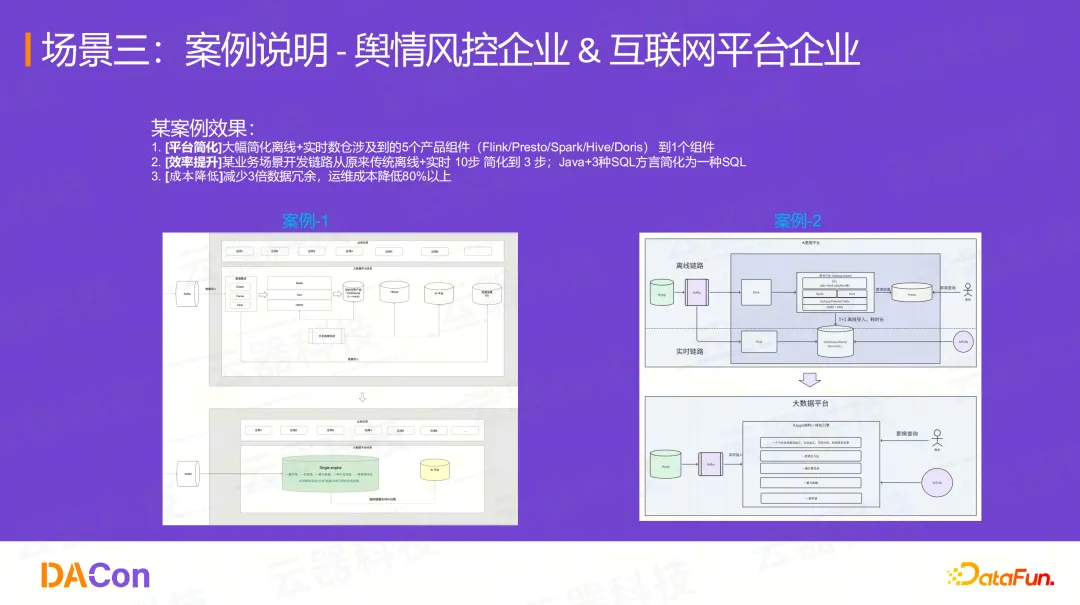
在多个实际客户案例中,我们实现了:
- 平台简化: 将原有的5个产品组件(Flink/Presto/Spark/Hive/Doris)简化为1个组件
- 效率提升: 开发链路从离线+实时的10步简化到3步;开发语言从Java + 3种SQL方言简化为1种标准SQL
- 成本降低: 减少3倍数据冗余,运维成本降低80%以上
场景四:引擎性能低——用高性能引擎消除计算瓶颈
典型场景:JSON数据查询
单表有数百TB的JSON数据,JSON中的Key有上千个且经常变动。业务人员需要对原始明细数据进行即席分析和抽样。
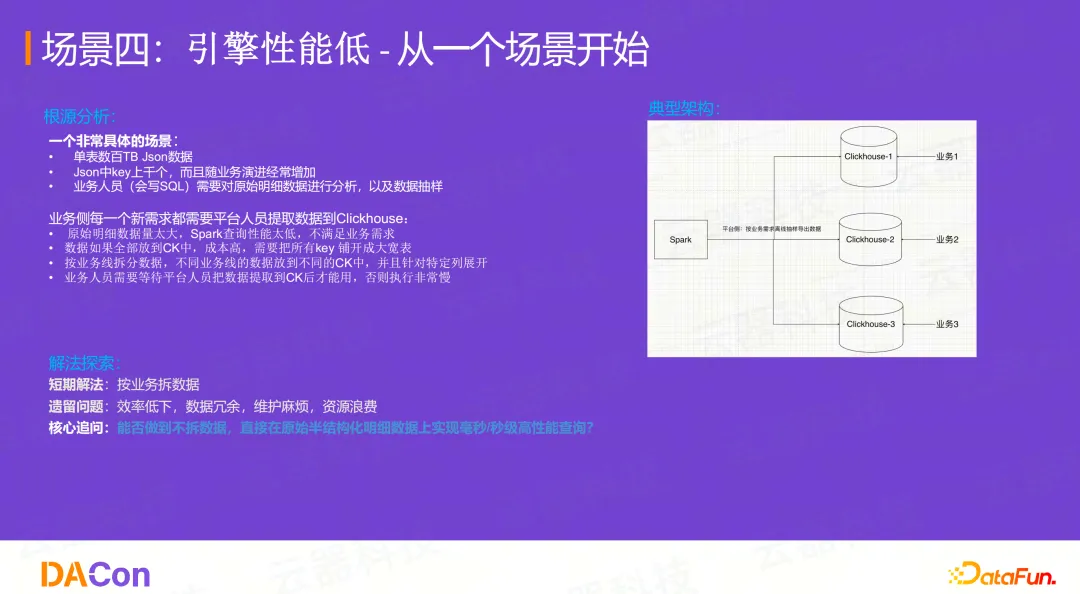
传统解决方案:
- Spark直接查原始数据,性能太低,不满足业务需求。
- 平台人员被迫将数据提取到ClickHouse中。但所有Key都展开成大宽表,成本过高。
- 最终只能按业务线拆分数据,放到不同的CK实例中,并且只针对特定列展开。
- 当业务人员需要一个新的Key时,平台人员必须重新提取一次数据,效率极低。
核心追问:
能否做到不拆分、不预处理数据,直接在原始的半结构化明S细数据上实现毫秒/秒级的高性能查询?
云器方案:JSON查询加速技术

通过JSON类型 + 生成列(Generated Column)+ 建索引 的组合:
- 使用JSON原生数据类型优化存储和查询
- 使用生成列将常用的Key虚拟化为列(不占存储),并通过DDL/Alter灵活增删
- 对"生成列"建立索引(如倒排索引)
通过这套技术,实现了在数百TB的原始JSON明细数据上进行毫秒到秒级的查询。
性能优化是永无止境的旅程
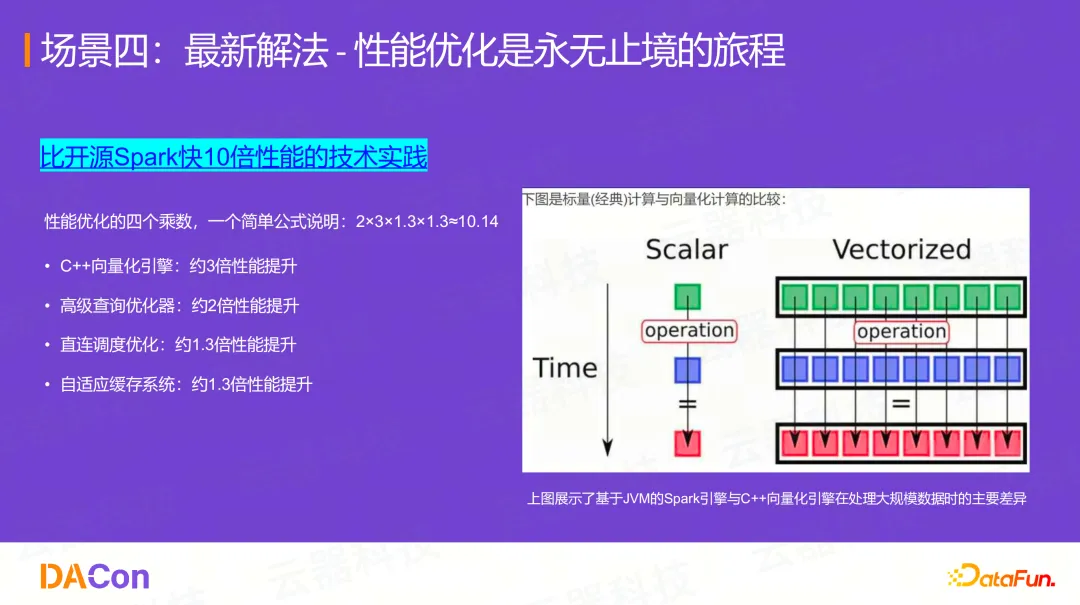
云器科技的引擎在标准TPC-H测试上能做到比开源Spark快10倍。这不是单一技术实现的,而是多个优化项的乘积效应:
2(高级查询优化器)× 3(C++向量化引擎)× 1.3(直连调度优化)× 1.3(自适应缓存)≈ 10.14
这背后是基于JVM的Spark引擎与C++原生向量化引擎在设计上的根本差异。
客户案例

- 舆情风控企业: 实现了数百TB级原始明细JSON数据的毫秒~秒级即席查询,解放了平台人员
- B2B SaaS企业:
- 在离线全量场景,资源消耗降低10倍以上
- 将其改造为全域增量计算,实现了全业务的实时化(5分钟一次),而总成本基本与原来T+1的离线成本持平
三、大数据平台架构演进总结
我们回顾一下“高成本、低效率”的四大场景和新解法:
| 场景 | 场景解读 | 新解法 |
|---|---|---|
| 场景一:实时加工成本高 | Flink 资源常驻、按峰配置,成本高。 | 通用增量计算 (GIC) |
| 场景二:资源割裂,数据冗余 | "1+N" OLAP孤岛,利用率低,稳定性差。 | 高性能引擎 + 资源管理新模式 (VC) |
| 场景三:多组件,开发效率低 | Lambda 架构组件繁杂,开发语言不统一。 | Kappa 架构 (单一引擎支持多场景) |
| 场景四:引擎性能低,算不出 | 数据需预处理,无法即席查询明细。 | 多场景高性能引擎 (及专项优化) |
下一代数据平台的演进之路
最后,总结一下大数据平台架构的演进之路:
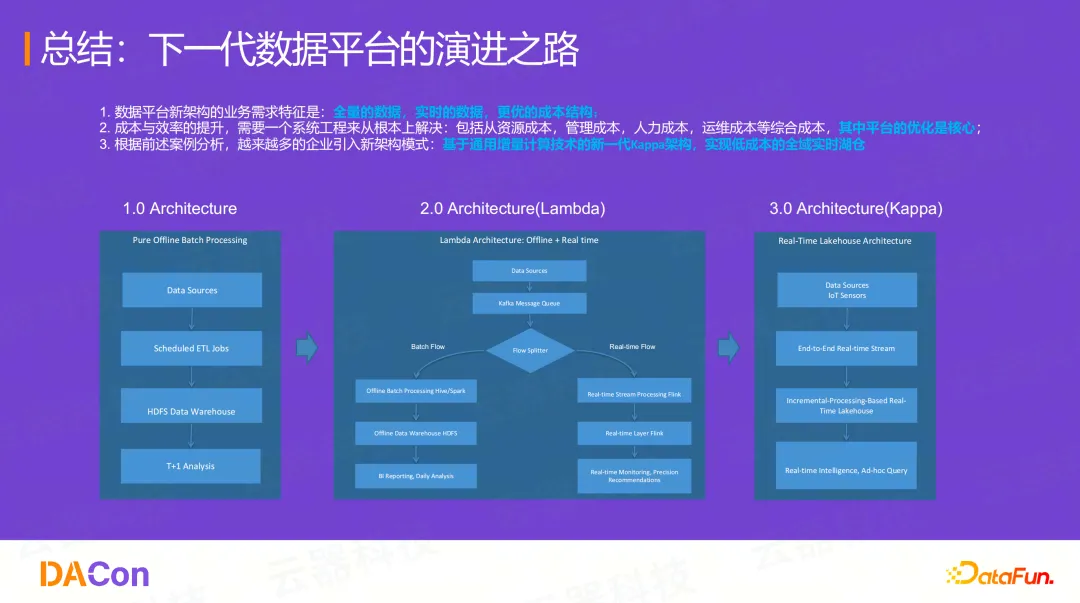
- 1.0 架构 (Pure Offline): 纯离线批处理 (T+1)。
- 2.0 架构 (Lambda): 离线 + 实时,两套链路。
- 3.0 架构 (Kappa): 端到端的实时流处理,基于增量计算的实时湖仓。
总结:
- 数据平台新架构的业务需求特征是:全量的数据、实时的数据、更优的成本结构 。
- 成本与效率的提升,是一个系统工程。它不只是资源成本,还包括管理、人力、运维等综合成本,而平台的优化是核心 。
- 根据前述案例分析,我们认为:基于通用增量计算(GIC)技术的新一代Kappa架构,是实现低成本、全域实时湖仓的演进方向 。
