引言
在数据驱动的时代,企业需要快速、灵活地处理数据,以支持实时决策和创新。然而,传统的数据平台架构和开源引擎在处理大规模、多类型的数据时,通常面临性能瓶颈和架构复杂性的问题。为了应对这些挑战,许多企业选择了数据湖仓(Lakehouse)架构,旨在将数据湖的存储能力与数据仓库的高性能分析整合为一体。然而,市场上大多数开源数据引擎,如ClickHouse、Spark、Trino、Flink等,虽然各具优势,但在提供一致、高效的分析性能和灵活处理能力方面仍然存在局限性,包括:
-
多引擎复杂性: 开源引擎各有所长,ClickHouse擅长快速查询,Spark适合大规模数据处理,Trino支持多数据源整合,Flink则偏重流式数据处理。但将这些引擎集成以实现统一存储和计算,增加了技术复杂度和用户使用门槛,不同的技术组件尤其在调优和运维上耗费人力。
-
性能不足: 现有开源引擎在大数据场景中性能常受限,例如Spark在低延时查询中表现不佳,而ClickHouse在复杂计算场景下也易遇瓶颈。这种局限增加了多引擎选择的开发和维护成本。
-
新场景适配难: 企业对实时分析和实时与离线整合的需求增加,而传统开源引擎难以支持复杂的流批处理需求,例如Flink在高吞吐流式场景下成本过高。
-
技术债务累积: 多开源组件的堆叠导致平台维护、版本兼容等问题不断。长期来看,这种架构在运维、故障排查和性能优化方面的成本高企,难以聚焦创新。
云器科技推出的Lakehouse产品以单引擎架构为核心,通过自研高性能SQL引擎,将数据湖的存储能力与数据仓库的高效查询分析能力融为一体,实现了以下关键优势:
-
一体化架构,降低运维负担: 云器Lakehouse通过单一引擎架构,将批处理、流处理和交互式分析的能力集中在一个统一的平台中,不再需要企业引入多种引擎和组件。这种简化的架构大大降低了运维复杂性,减少了技术债务累积,为企业带来了更具可扩展性的成本结构。
-
全场景下的高性能: 在业界常用的基准测试中,云器Lakehouse分别在实时分析、即席查询、大规模批量处理等经典场景下性能相较开源引擎显著提升,为企业在海量数据下实现实时洞察提供了可靠的支持。同时,云器Lakehouse在设计上充分考虑了流批一体的需求,采用创新的增量计算机制,使得企业能够以单一平台管理批量和实时数据分析任务,减少了跨平台的数据搬迁和资源重复使用的成本。
-
灵活的资源管理: 相比传统的数据引擎,云器Lakehouse引入了动态资源管理机制,提供负载隔离、根据负载自动伸缩的能力,确保在业务峰谷变化状态下仍然提供高效、稳定的系统表现。
性能报告
概述
在报告中,我们提供了云器Lakehouse在4个典型大数据业务负载下的性能数据,同时分别与每个典型负载下的主流开源引擎在等效计算资源下进行测试对比,以下是一些关键测试结果的概述:
| 场景 | 测试基准 | 指标 | 云器Lakehouse | 开源产品 | 云器VS 开源 |
|---|---|---|---|---|---|
| 离线批处理 | TPC-DS 10TB | 执行时间 | 1869.187 秒 | Spark: 17779.636秒 | 9.51 倍 |
| 即席查询 | TPC-H 100GB | 执行时间 | 7.402 秒 | Trino: 72.86 秒 | 9.84 倍 |
| 实时分析 | SSB-FLAT 100GB | 执行时间 | 1.784 秒 | ClickHouse: 2.645 秒 | 1.48 倍 |
| 增量计算 | 自定义 | 资源成本 | 27.73 ~ 42403.86 core*s | Flink: 115200 core*s | 10 倍~1000 倍 |
-
离线批处理: 在复杂批处理任务中,云器Lakehouse相较Spark表现出9.51倍性能提升。
-
即席查询: 在交互式分析场景下,云器Lakehouse相较Trino表现出9.84倍性能提升。
-
实时分析: 在基于宽表的实时分析场景下,云器Lakehouse相较Clickhouse表现出1.48倍性能提升。
-
增量计算: 云器Lakehouse支持秒级、分钟级、小时级的数据新鲜度调节。相较于Flink常驻任务,云器Lakehouse可通过调整时效性平衡资源成本,在近实时场景下可节省10倍~1000倍的成本。
离线批处理场景,Spark 9.51X 性能提升
TPC-DS(Transaction Processing Performance Council - Decision Support)是一种由交易处理性能评估委员会(TPC)发布的基准测试标准,旨在评估决策支持系统(Decision Support Systems,DSS)的性能。相较于更适合评估即席查询和报表分析性能的TPC-H,TPC-DS 包含了对报表分析、交互查询、数据挖掘等复杂应用的评估,更接近真实的数据仓库使用场景。
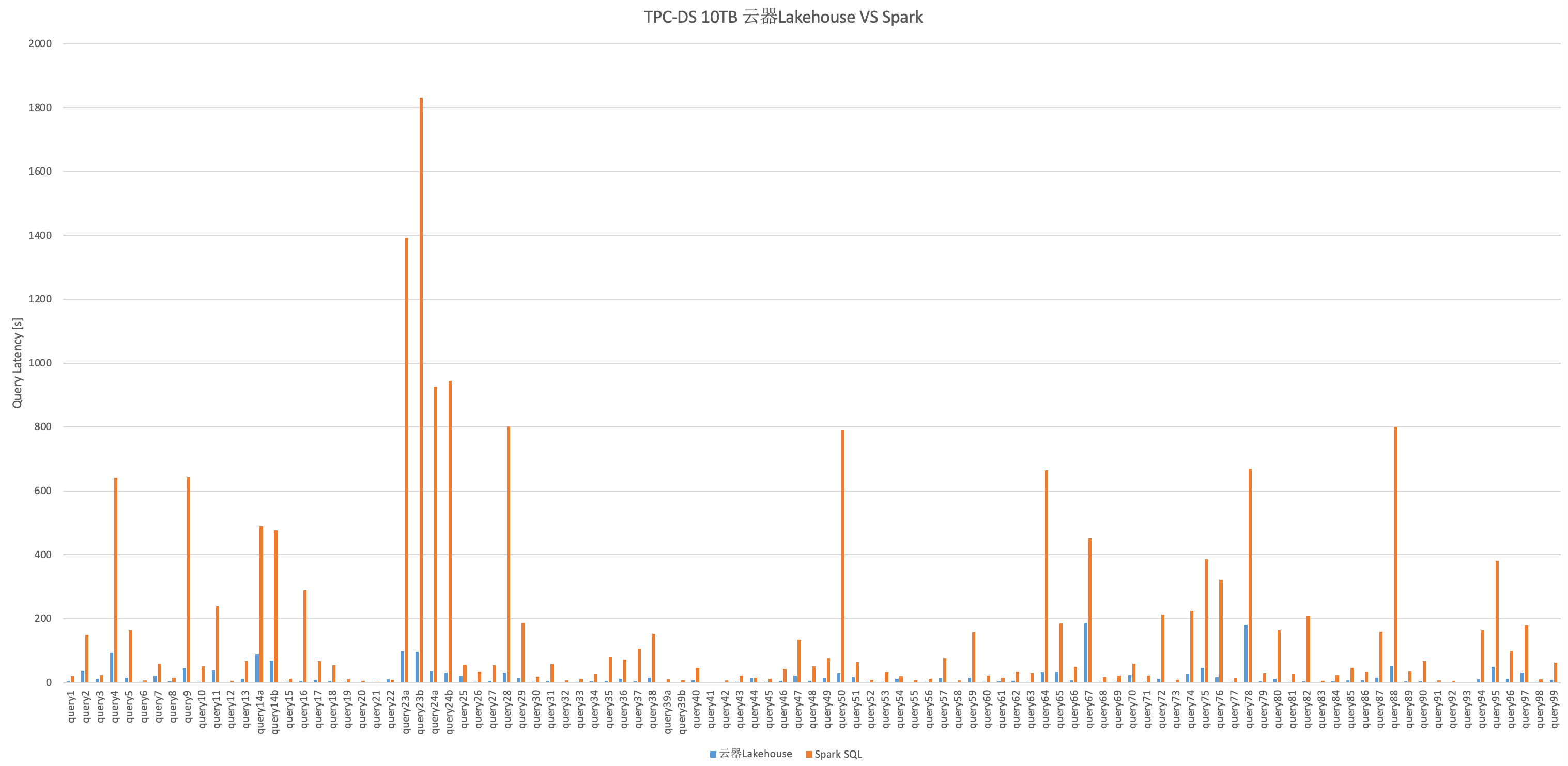
本报告为您提供了云器Lakehouse与Spark SQL在TPC-DS测试集10TB规模上的测试结果,性能表现如下:
-
云器Lakehouse在所有103个查询中的总体性能表现优于Spark,Spark的总耗时是云器Lakehouse的9.51倍。
-
云器Lakehouse对Spark的长执行作业有显著的性能提升。
即席查询场景,Trino 9.8X 性能提升
TPC-H是一个决策支持基准测试,由事务处理性能委员会(TPC)开发,包含一系列面向业务的即席查询和并发数据修改操作,常用于验证报表分析、数据探查的处理性能。
本报告为您提供了云器Lakehouse与Trino在TPC-H测试集100GB规模上的测试结果,性能表现如下:
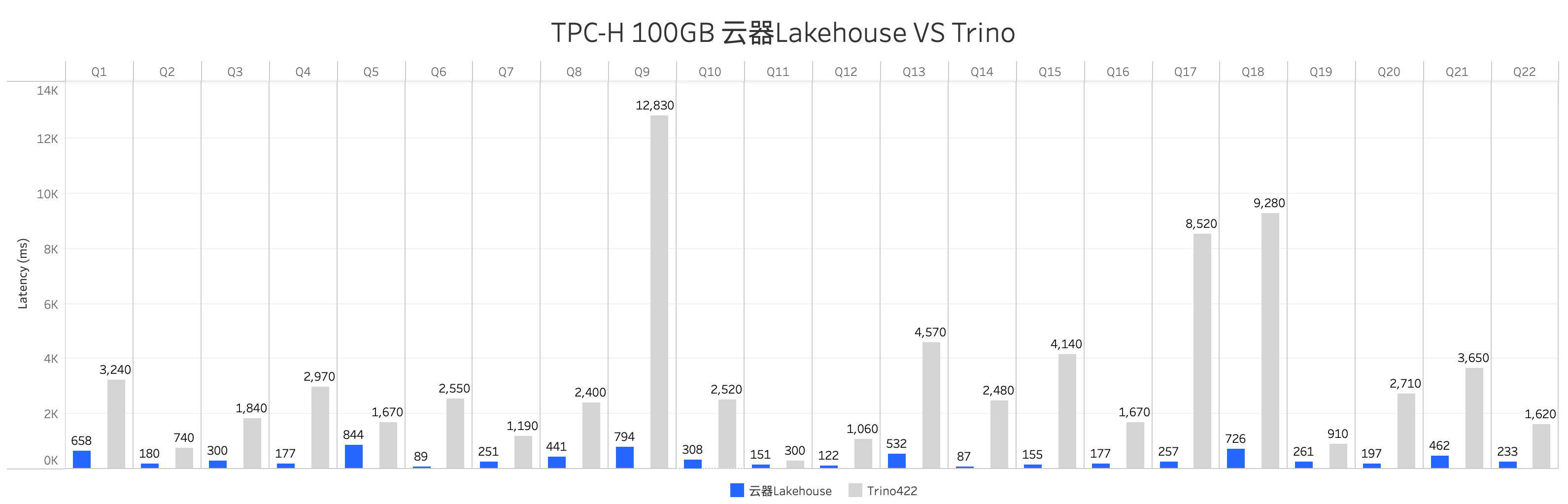
说明:Trino使用128vCPU计算资源,云器Lakehouse使用等效计算资源。
-
云器Lakehouse在所有22个查询中的总体性能表现优于Trino,Trino的总耗时是云器Lakehouse的9.84倍。
-
云器Lakehouse在所有查询中性能优于Trino。
实时分析场景,ClickHouse 1.48X 性能提升
Star Schema Benchmark(简称SSB) 是一种用于评估OLAP系统性能的基准测试。SSB 基于 TPC-H 提供了一个简化版的星型模型数据集,主要用于测试在星型模型下多表关联查询的性能表现。ClickHouse官方将SSB的星型模型打平转化成宽表改造成了一个单表测试集,常用于验证实时数据分析性能。
本报告为您提供了云器Lakehouse与ClickHouse在SSB单表测试集100GB规模上的测试结果,性能表现如下:
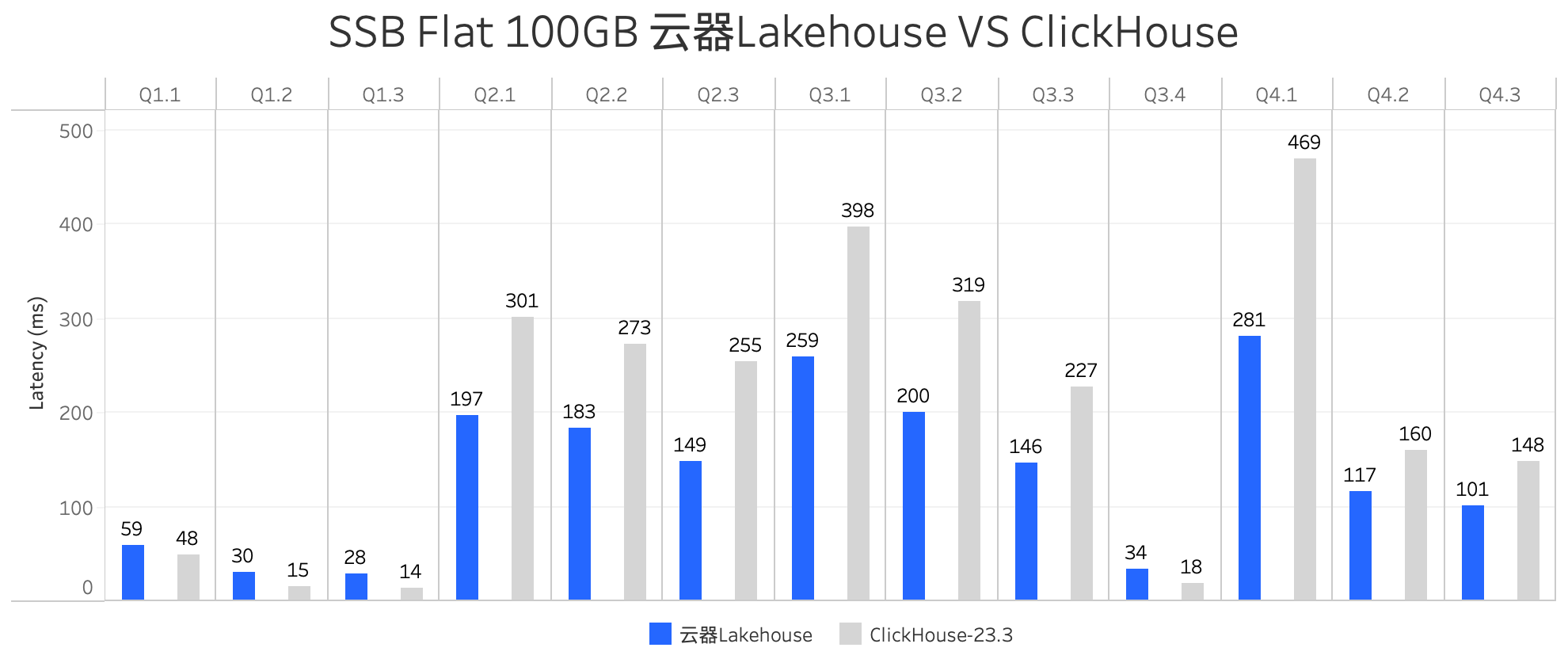
说明:ClickHouse使用64vCPU计算资源,云器Lakehouse使用等效计算资源。
- 在SSB单表测试集100G规模数据集上执行的 13 个查询中,ClickHouse总耗时是云器Lakehouse的 1.48 倍,云器Lakehouse性能更优。
增量计算场景,Flink 10X~1000X成本降低
和传统流计算的典型场景有所不同,我们本测试的目标是从用户易用性角度出发,摒弃Lamda架构、提供统一的声明式SQL进行增量处理、保证(近)实时计算的结果和静态全量计算结果对齐一致为目标。
业界目前没有面向基于增量计算的标准测试集,本测试根据实际业务中常见的4种数据处理逻辑设计场景,在测试时通过调整云器Lakehouse增量计算任务的刷新周期观察在满足不同的数据新鲜度下Lakehouse资源成本变化,并与经典流计算引擎进行对比。
本报告为您提供了云器Lakehouse与Flink在本次自定义测试集上的测试结果:
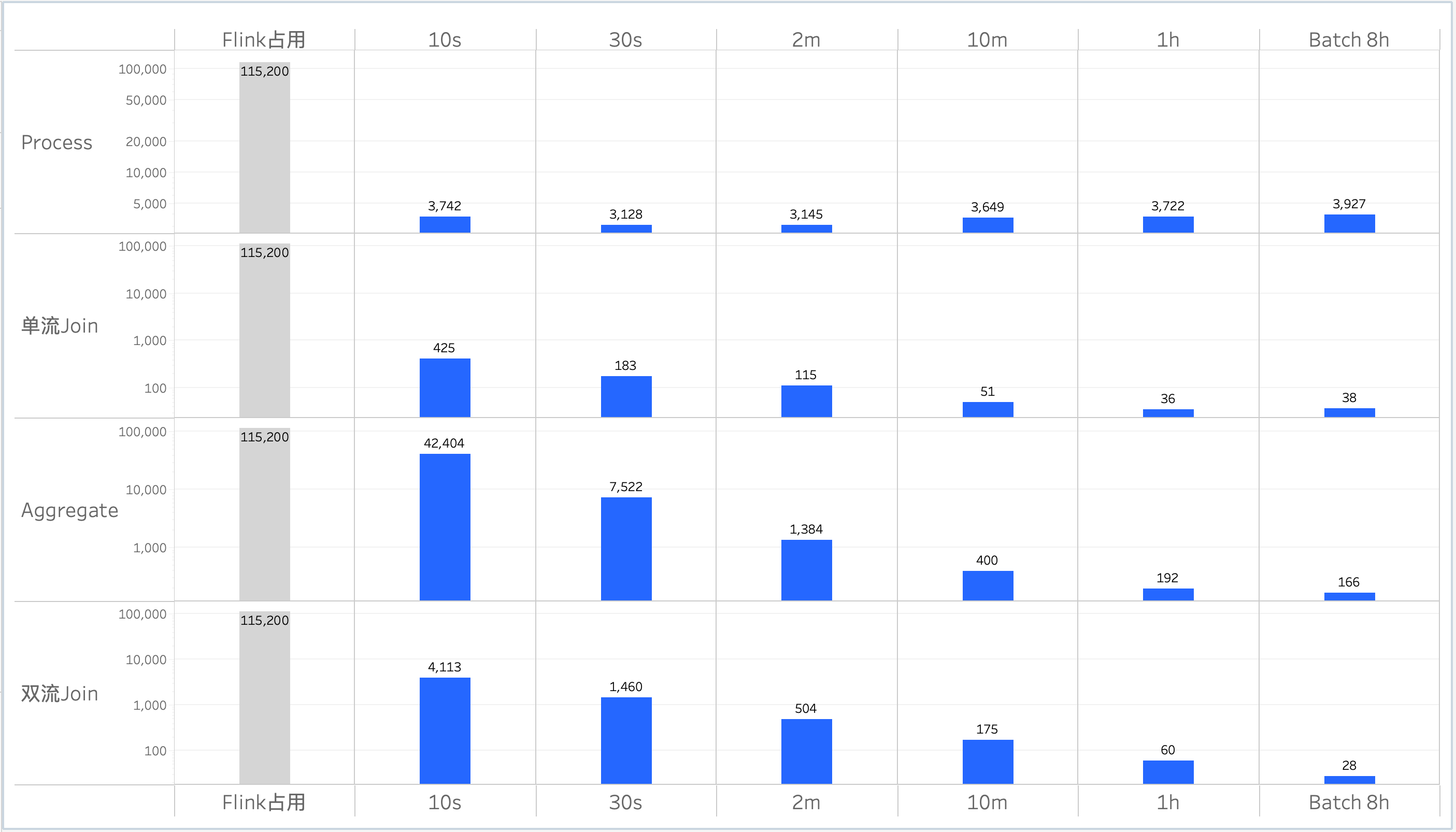
说明:Flink占用: 指Flink常驻运行,不释放资源;云器Lakehouse通过申明式SQL进行增量处理,分别设置不同刷新周期(10s/30s/2m/10m/1h/8h)并观察资源消耗;纵轴为资源消耗,单位:cores。*
-
云器Lakehouse支持秒级、分钟级、小时级的数据新鲜度调节。在流和批的两个极端中间可通过调整新鲜度控制成本。
-
选取的 4 种典型的流式数据处理场景(Process、单流Join、Aggregate、双流Join)下,采用近实时增量计算的云器Lakehouse资源消耗更低。在满足不同数据新鲜度的状态下,相比于 Flink 节省 10x -1000x 的资源成本。
(详细对比分析报告将在稍后提供,敬请关注。)
结论
Lakehouse产品的单引擎架构通过自研的高性能SQL引擎,结合创新的增量计算和流批一体化支持,实现了单一引擎支持多负载的独特能力,显著提升了数据平台的整体效能,帮助企业在降低数据管理成本的同时,获得了更高效的数据洞察能力。借助Lakehouse,企业可以一站式地满足批处理、流处理和实时分析的需求,简化架构并降低长期运维成本,为业务增长提供了灵活、高效的数据平台支持。
Lakehouse产品致力于成为开源数据平台的高性能升级、替代方案。其一体化、托管化的服务模式不仅提高了平台的稳定性和可靠性,还极大地降低了企业的技术负担和总拥有成本,帮助企业实现数据驱动的业务增长。

