导读
在以AI为标志的新一轮技术浪潮中,几乎所有的数据从业者和企业决策者都在思考同一个“必答题”——面向AI时代,企业的数据平台该如何演进? 是彻底重建一套为AI“量身定制”的新系统?还是在现有体系上迭代升级,让数据基础设施焕发新生?
在DA Con北京站 上,云器科技CTO关涛 结合前沿实践,给出了他的答案:
“AI时代发展到现在,数据架构的目标开始逐渐清晰,革命还是进化,取决于企业当前的架构状态”
面对AI带来的计算范式、数据类型与查询模式的全面变革,企业不必盲目“重建”。如果仍停留在传统的Lambda架构阶段,数据湖、数据仓库和实时链路割裂严重,确实需要一次架构层面的“革命”;但对于已经迈向湖仓一体、具备处理半结构化与非结构化数据能力的企业,则可以通过“通用增量计算”等方式实现平滑“进化”,逐步构建“Data + AI”融合的新一代智能数据架构,让数据真正成为驱动企业迈向智能时代的核心动力。
第一章:当前主流数据平台的挑战
在讨论未来之前,我们必须先看清“当下”。目前,大多数企业的主流数据平台架构,无论是在公有云还是私有云上,都呈现出相似的形态。
1. “熟悉”的架构:Lambda的现状
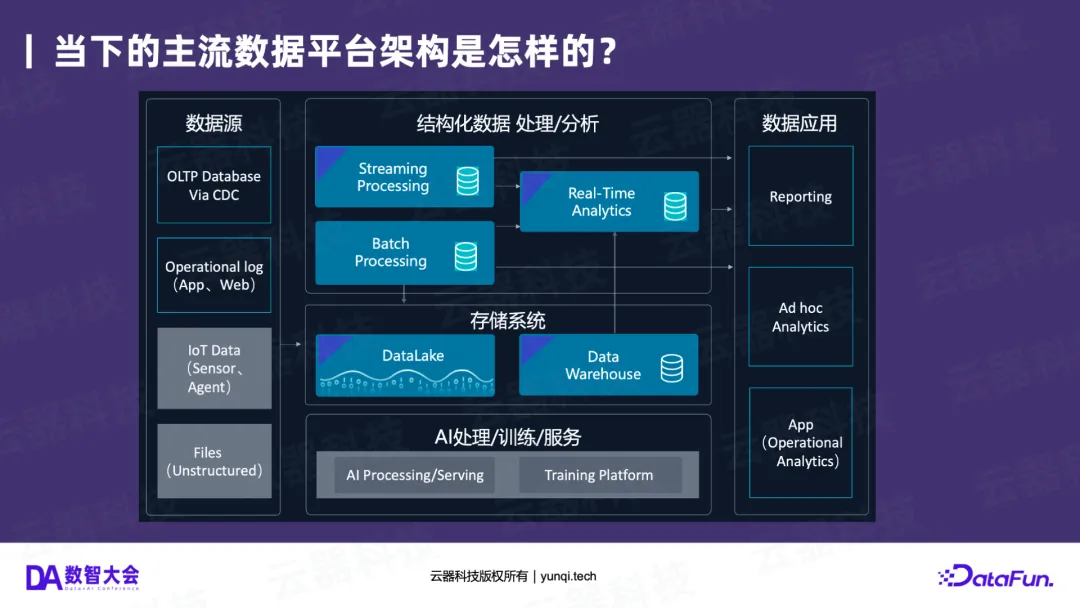
一个典型的“当下”架构通常是这样的:
- 数据源 :包括来自OLTP数据库的CDC数据、Web和App的行为日志,以及正在快速增长的IoT设备数据和非结构化文件(如音视频、文档)。
- 存储系统 :通常是数据湖(DataLake)和数据仓库(Data Warehouse)并存。
- 计算/分析层 :由三套独立的引擎组成
- 批处理/离线计算 (如Spark);
- 流计算/实时处理 (如Flink);
- 交互式分析 (Ad-hoc,如ClickHouse, Doris)。
这种“流、批、交互”三套系统并行的架构,本质上就是Lambda架构 的变体。
2. “三座大山”:Lambda架构的固有顽疾
这种看似“五脏俱全”的架构,在长期的运行中暴露出了三大核心问题,我们称之为数据平台的“三座大山”:
第一座山:Lambda架构的固有顽疾
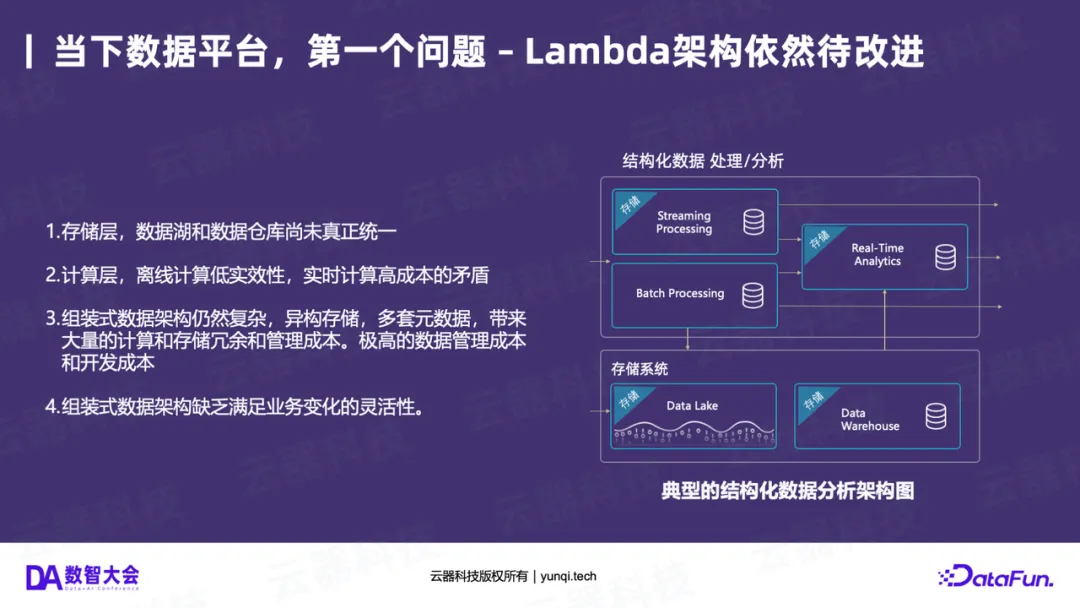
Lambda架构本身带来了诸多问题:
- 存储割裂 :数据湖和数据仓库没有真正统一。当AI带来的非结构化数据只能存入数据湖时,数据割裂问题愈发严重。
- 计算割裂 :离线计算(时效性低)和实时计算(成本高)是两套独立的pipeline。企业经常抱怨实时和离线的数据对不齐,需要花费大量精力“对数”。
- 管理复杂 :这套架构非常复杂。它通常意味着至少四套元数据(湖、仓、流、交互分析)和四套存储系统,带来了极高的数据管理成本、计算冗余和开发成本。
- 灵活性差 :由于系统和编程范式各自独立,想要做一些灵活的资源调配(例如“白天跑实时,晚上跑批处理”)或融合AI的pipeline都非常困难。
第二座山:高昂的TCO(总体拥有成本)
数据平台一直是企业的“成本中心”。高TCO主要源于:
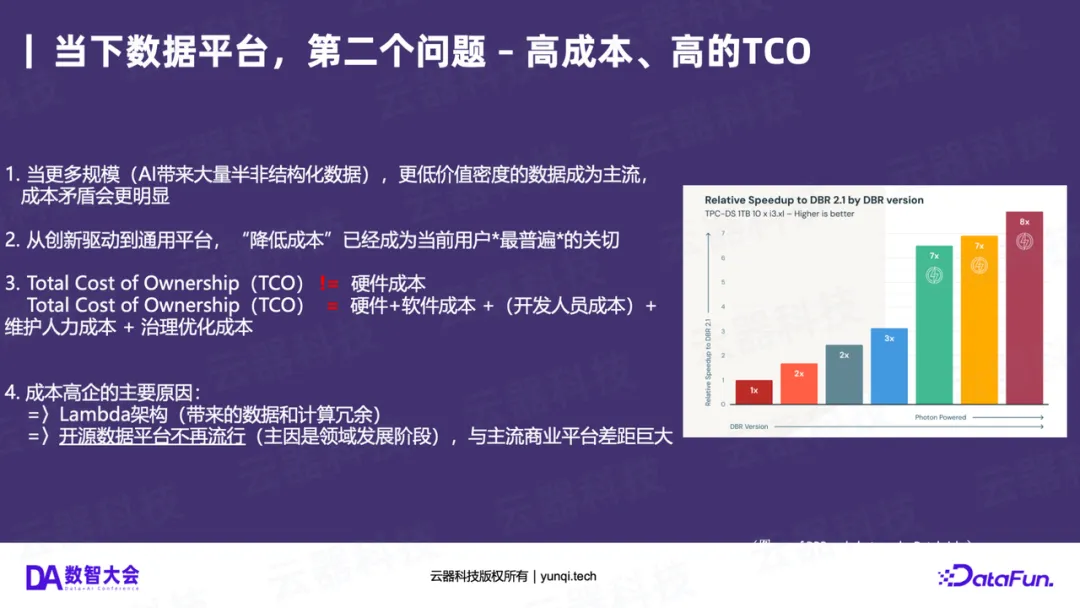
- 架构冗余 :Lambda架构本身带来的数据和计算冗余是成本高的主要原因。
- 开源不“免费” :很多人认为开源(如Spark)等于低成本,但事实是,当一个领域发展成熟时,企业级的优化(如Databricks的Photon引擎)在性能上(可能是开源版的8倍)已远超开源版本。企业为维护和优化开源所投入的人力成本、开发成本和治理成本,共同构成了高昂的TCO。
- AI的新成本 :AI带来了海量的半结构化/非结构化数据,这些数据价值密度更低,进一步放大了成本问题。
第三座山:面向AI负载的转型挑战
这是最新的,也是最关键的挑战。当企业试图将AI引擎(如大模型)插入现有平台时,会发现传统的分析引擎和AI引擎在接口、计算模式上完全不同。我们迫切需要一个“AI-Ready”的平台,而现有架构显然不是。

3. 过去12个月的重要变化
过去一年中,数据平台领域发生了几个标志性的变化。首先,Lakehouse架构已经成为业界的默认选择。Iceberg等开放格式成为新一代湖仓的事实标准,为数据管理和治理提供了统一的基础。

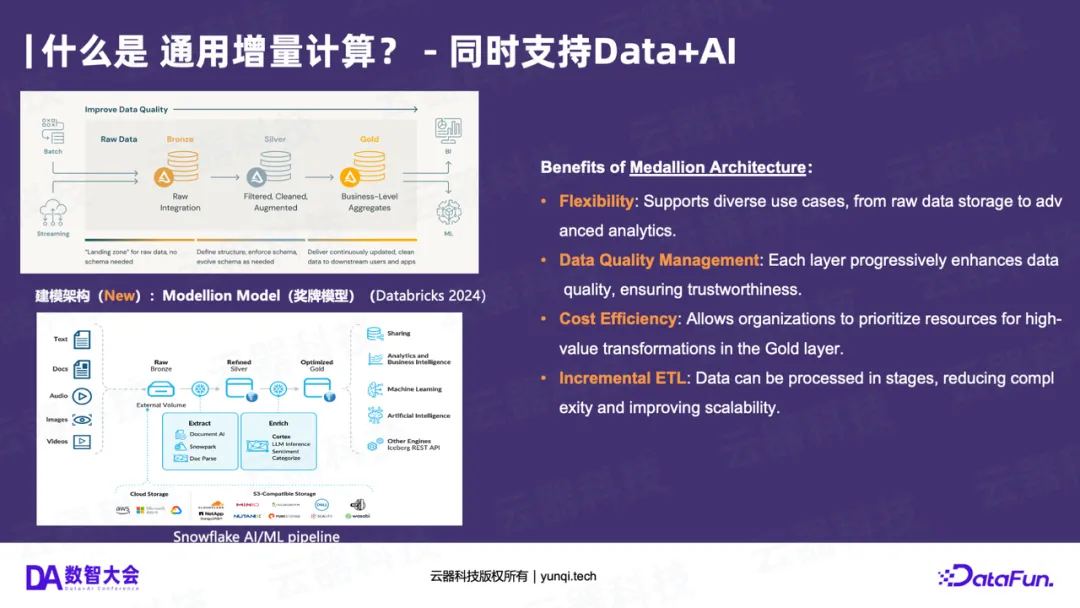
其次,Medallion Architecture(奖牌架构)正在快速普及。这种架构由Databricks提出,并得到Snowflake、微软等主流厂商的支持。它将数据处理分为Bronze(原始数据)、Silver(清洗数据)和Gold(聚合数据)三层,强调数据的逐层加工和价值提升。预计在未来18个月内,这种架构模式将成为企业数据平台的标配。
第三,单引擎一体化趋势明显。业界正在从多引擎协同转向单一引擎支持多种负载,以降低系统复杂度。同时,增量计算(Kappa架构)在海外已经成为默认趋势,国内产业也在加速验证。
最后,也是最重要的一点,AI已经从实验阶段走向生产环境,成为业务升级的主要驱动力。各大云平台纷纷推出AI SQL等新功能,将AI能力深度整合到数据处理流程中。
第二章:AI带来了哪些“变”?
要构建“AI-Ready”的平台,首先要理解AI到底带来了哪些根本性的“变化”。
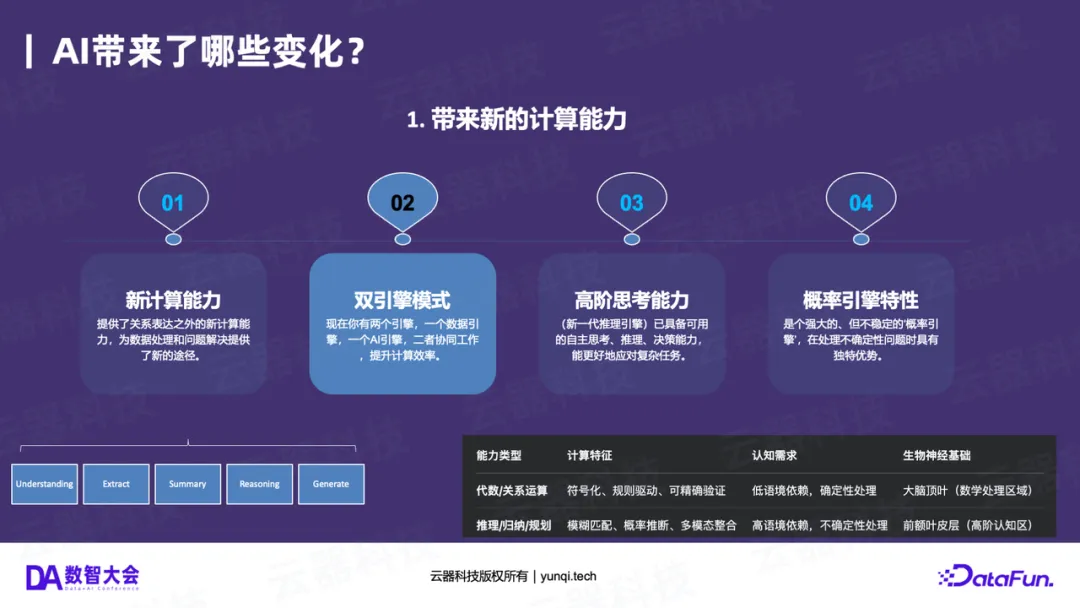
变化一:新的计算能力(从“确定性”到“概率性”)
这是AI带来的最核心变化。过去,我们所有的数据分析(SQL、BI)都是基于“确定性”的计算。1+1=2,一个SQL查询今天和明天跑,结果永远一致。这被认为是“低阶思考”能力。
而AI(特别是大模型)带来的是**“概率性”** 的计算能力,包括理解(Understanding)、抽取(Extract)、总结(Summary)、推理(Reasoning)和生成(Generation)。你两次询问同一个问题,它可能给出不一样的答案。
这意味着,我们的数据平台中插入了第二个“引擎” ,一个“高阶思考”但“不确定”的引擎。我们必须想办法管理这个新引擎,并将其与确定性的SQL引擎相融合。
变化二:解锁“暗数据”(价值的“十倍”增长)
在经典的DIKW金字塔(数据->信息->知识->智慧)中,传统的BI(如报表)最多做到了“信息”层。
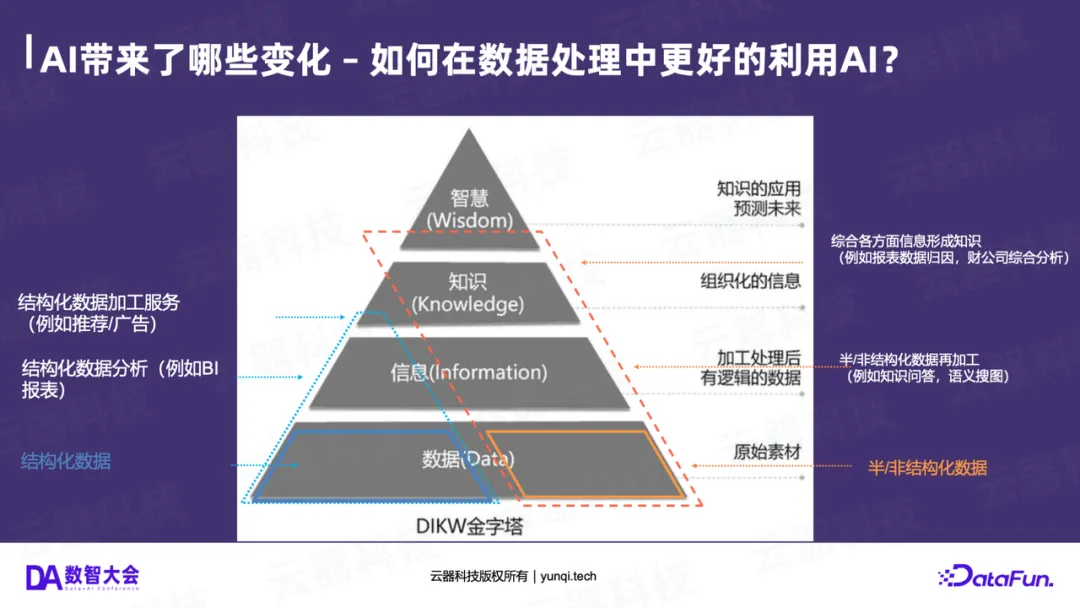
AI的出现带来了两个飞跃:
- 向上飞跃 :AI(如ChatBI)能解读报表,将“信息”加工成“知识”。
- 向外扩展 :AI首次让我们有能力处理企业中占比高达80%的“暗数据”——那些沉睡在文档、聊天记录、会议纪要、图片、视频中的半结构化和非结构化数据。
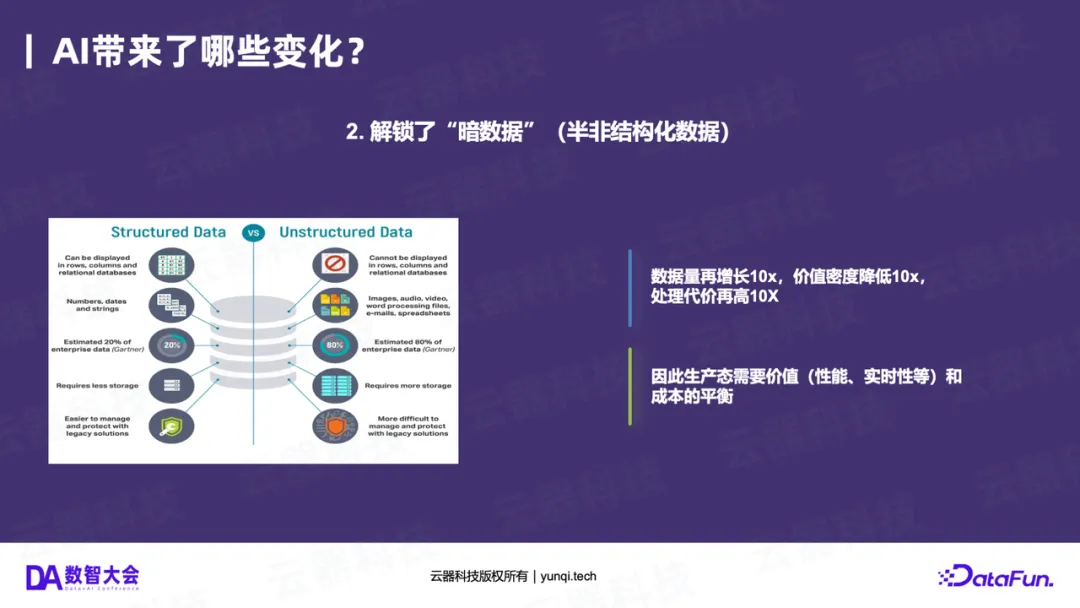
如果说“大数据”时代通过Hadoop解锁了日志数据,带来了10倍的数据增长;那么AI时代解锁“暗数据”,将带来又一个10倍甚至100倍的可用数据量 增长。
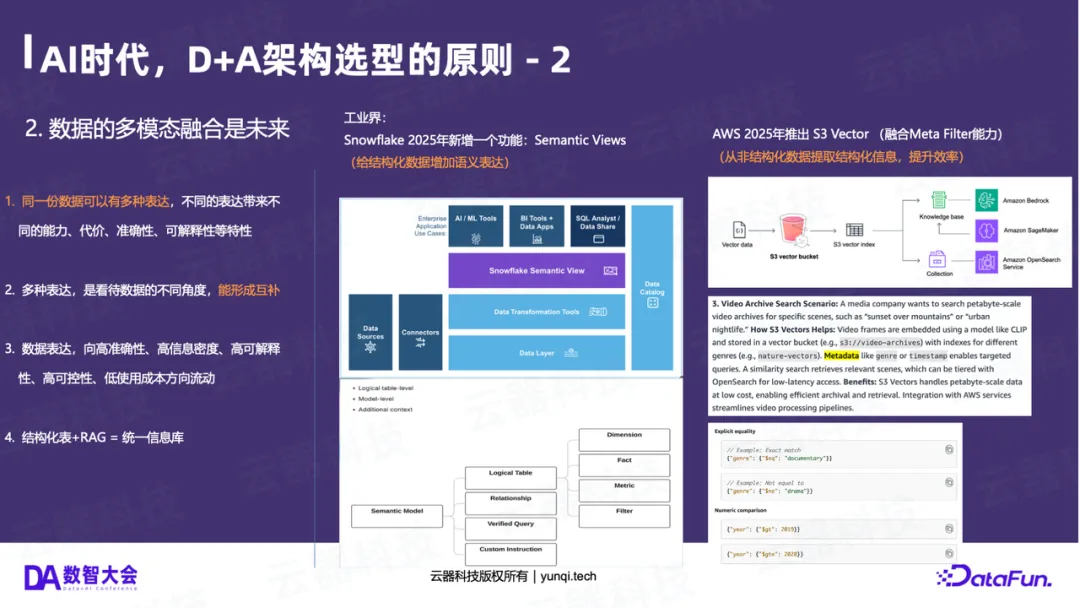
工业界实践:Snowflake AISQL 的启示
面对这些变化,工业界已经开始行动。Snowflake在2025年最新发布重磅功能Cortex AISQL。

- 昨天的做法 :结构化数据用SQL计算;非结构化数据(如文档)构建RAG;再用Python写一个Pipeline将两者粘合起来。这种做法的问题是:数据割裂、无法实现真正的多模态、Pipeline复杂。
- 今天的做法 (AISQL) :Snowflake将AI能力(如AI_EXTRACT、AI_FILTER、AI_AGGREGATE)作为新的SQL算子 ,深度融合到计算引擎中。
例如,分析师可以用SQL写出这样的查询:
SELECT * FROM news_feed JOIN company_events ON AI_FILTER(prompt('分析这条新闻是否与我司相关'))
这标志着AI不再是数据库的“外挂”,而是成为了引擎的“一等公民”,实现了真正的多模态计算 。
变化三:查询负载的根本转变(从“全量扫描”到“精准检索”)
AI的计算(特别是大模型推理)有两个显著特点:

- **“数据窗口”极小 :**即便是“百万Token”的长窗口,折算下来也只有约4MB数据。
- **“计算成本”极高 :**用OpenAI处理1TB数据(每次4MB)的成本可能是几十万美金,而用Snowflake等数仓扫描1TB数据的成本仅为几美金。
这导致了数据平台查询负载的根本转变。AI应用(如RAG)需要的不再是传统BI的“全量扫描”(Scan),而是类似搜索引擎的**“精准检索”(Retrieval)** 。
因此,AI时代的数据平台必须同时满足四个新需求:
- 海量数据作为上下文;
- 极高的准确率;
- 极高的召回率;
- 实时与高并发。
平台的核心任务,是(通过检索)在昂贵的AI模型“计算之前”,就为其准备好最精准、最少量的数据。
第三章:什么“不变”?我们能复用什么?
面对如此多的“变化”,是否意味着现有的平台必须推倒重来?答案是否定的。

数据平台的核心能力并没有改变。无论是过去还是未来,平台都需要提供:
- 数据集成(Data Integration)
- 开发与调度(Development / IDE / Pipeline)
- 数据治理与安全(Governance / Security / Auditing)
- 数据中台与数据管理(Data Management / Middle-office)
这些能力是“不变”的、可复用的。例如,财务报表在BI时代需要权限控制,在AI时代,当AI Agent试图访问这些报表时,同样需要严格的权限控制。
因此,我们的结论是:面向AI的转型,不是推倒重来,而是在现有企业级能力的基础上,进行“AI-Ready”的升级和扩展 。
第四章:AI时代 D+A 架构的五大原则
基于以上的“变”与“不变”,我们为新一代“Data+AI”(D+A)融合架构提炼出五大设计原则。
原则一:投资数据(Data),而非算力或模型
AI三要素:算法(模型)、算力(GPU)、数据。
在今天,大多数企业使用的模型(如OpenAI、Llama)和算力(如NVIDIA GPU)正在快速趋同。对于绝大多数企业而言,唯一能建立差异化竞争壁垒的,就是企业内部的“私有数据”。
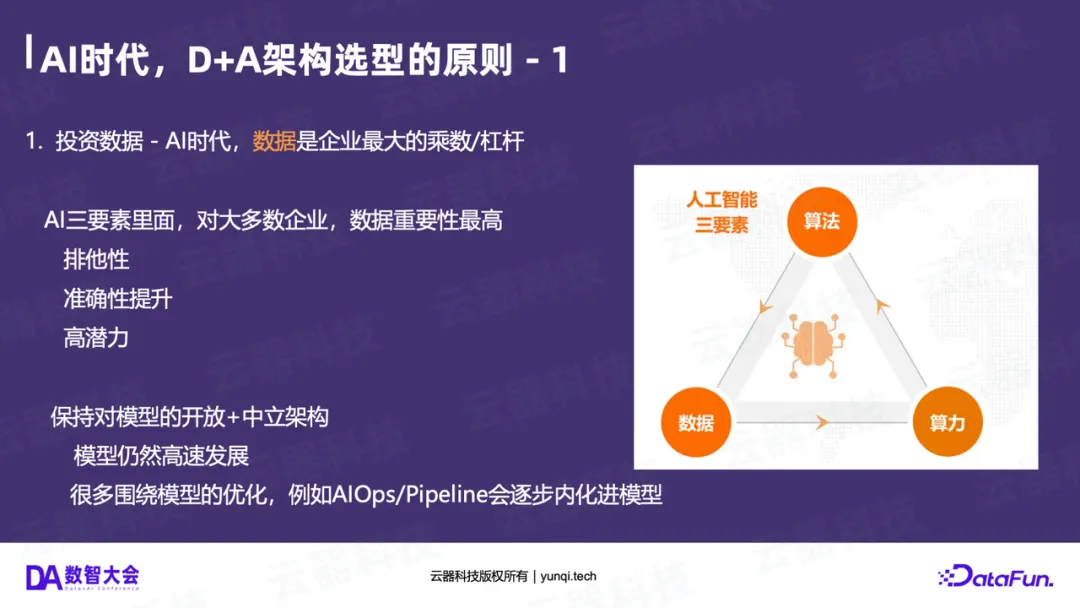
数据是企业在AI时代最大的“乘数”和“杠杆”。因此,企业最明智的投资,是构建一个能高效处理、融合和利用这些私有数据的“AI-Ready”数据基础设施。
原则二:多模态融合,统一信息库
未来不再是结构化数据(Table)和非结构化数据(RAG)“两套系统”。
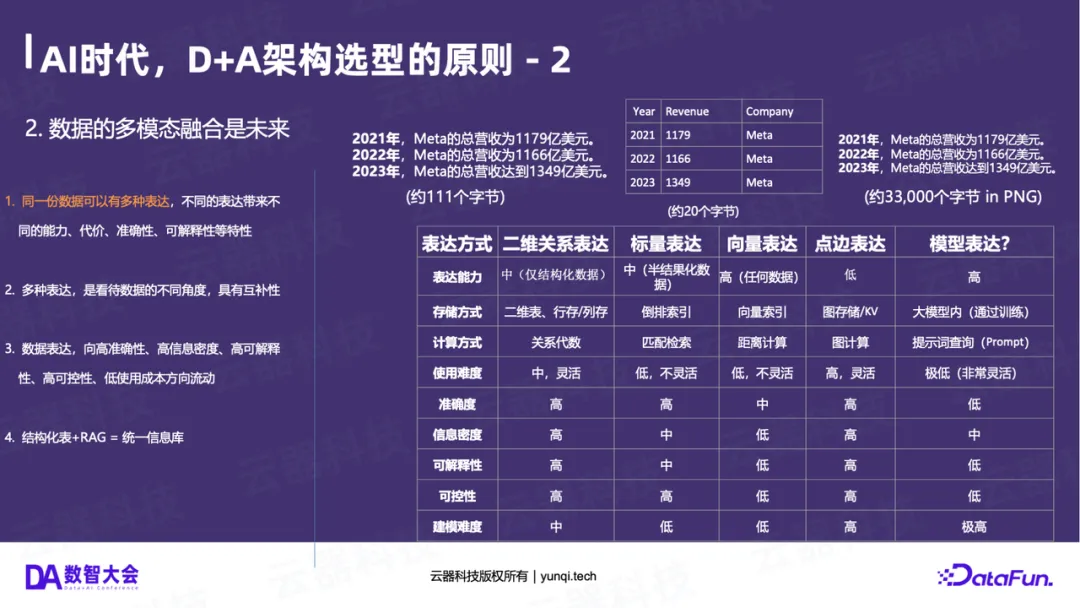

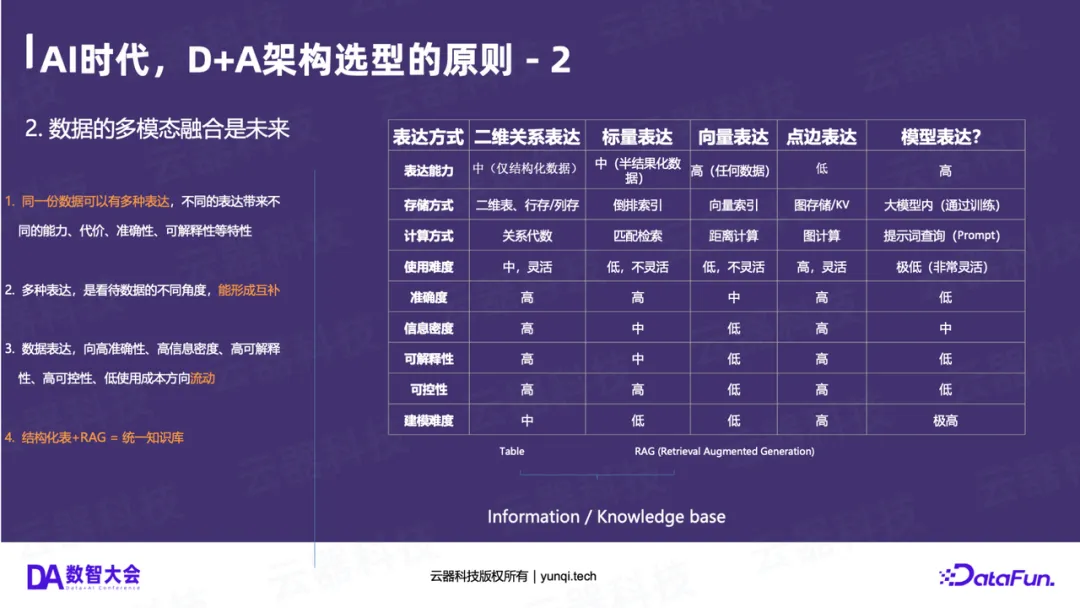
同一份信息可以有多种表达(如表格、文本、图片),它们各有优劣:
- 表格(结构化) :准确度高、可控性高、可解释性高,但建模成本高。
- 模型(AI) :建模成本低(直接问),但准确度低、可控性低、是“概率黑盒”。
未来一定是两者的融合。融合的形态 = 结构化表格 + 语义化描述 + RAG。
例如,光有结构化的营收表(1179)是不够的,AI很难理解“1179”是什么。我们必须为其补充语义(例如Revenue列,单位是亿美元)。
同样,光有非结构化数据(如图片)也是不够的,我们需要为其补充结构化的元数据(如拍摄时间、地点、人物)。
结构化数据 + RAG = 统一的信息知识库 ,这是AI时代数据处理的未来。
原则三:奖牌架构(Medallion),统一Data与AI

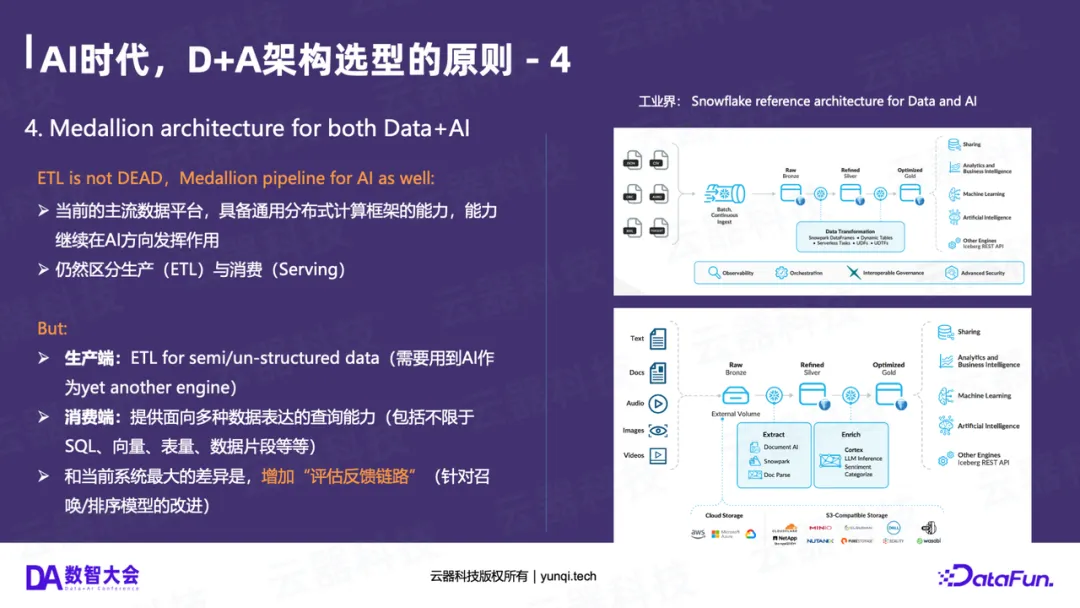
在架构蓝图上,由Databricks和微软(Microsoft Fabric)共同推动的奖牌架构(Medallion Architecture) 正在成为全球共识。
它将数据处理分为三个层次:
- Bronze(铜层) :原始数据(Raw Data),越原始越好,不做任何处理。
- Silver(银层) :清洗、结构化、去重、关联后的数据。
- Gold(金层) :面向业务主题,聚合后的数据(如报表、特征)。
这个架构模式的巧妙之处在于,它同时适用于Data和AI :
- 结构化Data pipeline :Raw (CDC/Log) -> Refined (ODS/DWD) -> Aggregated (ADS)。
- 非结构化AI pipeline :Raw (Docs/Video) -> Extract (文档抽取/特征提取) -> Enrich (情感分析/知识图谱)。
奖牌架构用一个统一的、分层的模型,将Data和AI两条Pipeline融合在了一起。
原则四:通用增量计算(GIC),破局“不可能三角”
奖牌架构是一个单向流动的Kappa架构 ,它解决了Lambda架构的割裂问题。那么,是什么技术在背后支撑它呢?
答案是通用增量计算(Generic Incremental Computing, GIC) 。

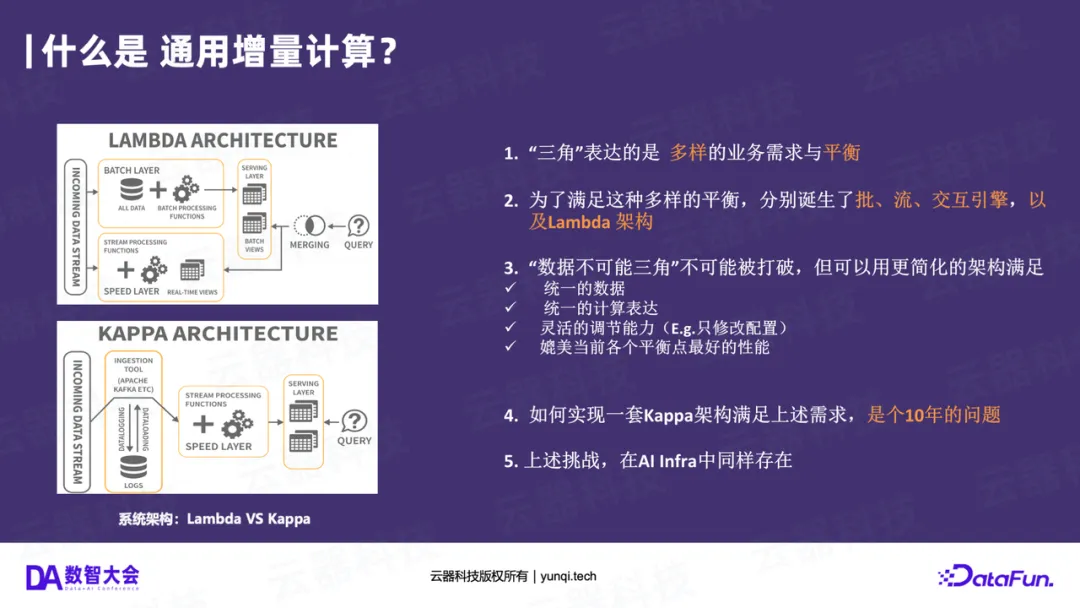
传统数据处理有一个“不可能三角”:数据的实时性(Freshness)、资源成本(Cost)和查询性能(Performance)。Lambda架构为了平衡这三者,被迫拆分成了流、批、交互三套系统。
GIC的核心思想是:只计算数据“变化”(Delta)的部分 。当新数据到来时,它复用上一次的计算结果,只对增量数据进行计算,从而合并结果。

GIC的出现,使得平台可以用一套引擎、一套SQL ,同时满足高性能、低成本、低延迟的优化,完美支撑了“奖牌架构”这种端到端的增量处理流程,是破局Lambda、实现Kappa的“核心引擎”。
原则五:AI-Centric,为“智能体(Agent)”设计平台
这是对未来平台“开发体验”的重大预言:未来,数据平台的最大用户不再是“人”,而是“AI智能体”(Agent) 。

过去,我们为“人”设计了GUI(图形界面)。未来,我们必须为“Agent”设计平台。这意味着:
- API-First :平台必须是API优先的,而不是GUI优先。Agent通过API(而非点选)来操作平台。
- 自然语言交互(NLI) :NLI将成为主流交互方式。
- 建立反馈链路 :AI是概率模型,它一定会犯错。平台必须设计“反馈机制”,让人类(或AI自己)能够纠正它。
在这个新范式下,人类的角色将从“开发者(Developer)”转变为**“审查者(Reviewer)”和“观察者(Observer)”** 。
第五章:落地实践与总结
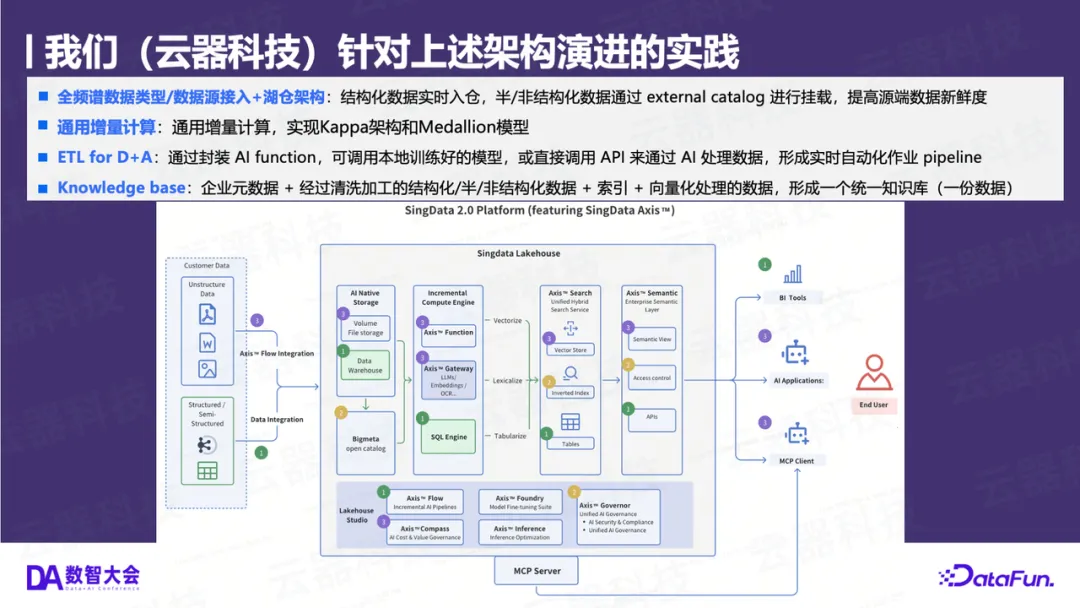
基于上述原则,新一代的 D+A 融合架构已经有了清晰的落地案例。云器科技作为新一代数据架构的探索者,正是在“通用增量计算”和“湖仓一体”方向上实践的代表。
以某头部内容社区(小红书)为例,其基础流量场景就曾是典型的Lambda架构:
- 原架构(Lambda) :Spark负责离线T+1计算,Flink负责实时计算。
- 痛点 :两套链路、两套SQL、两拨人,数据经常对不齐,开发和维护成本极高。
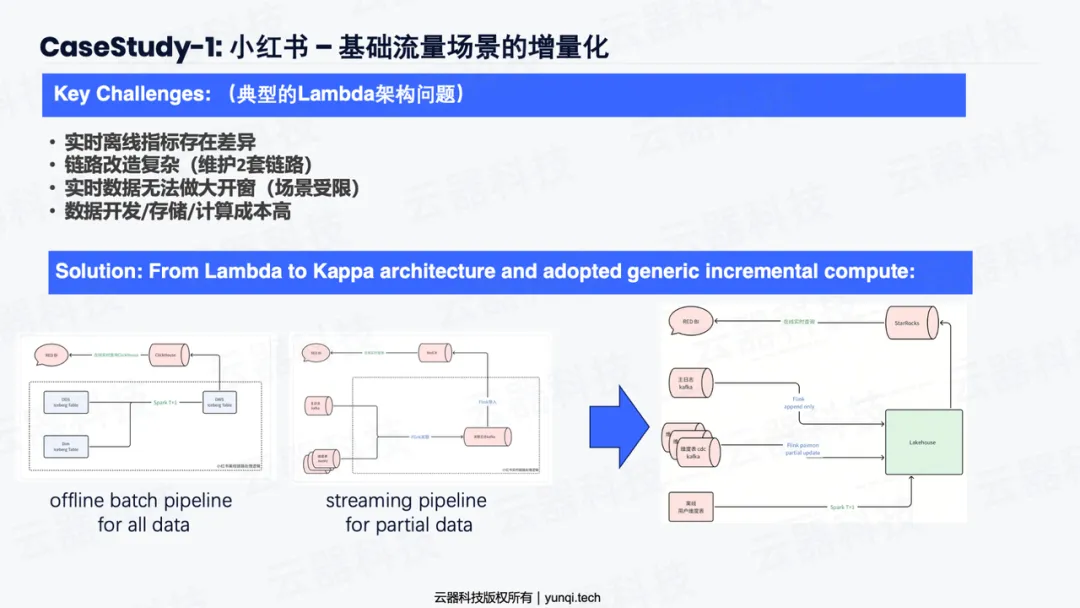
• 解决方案(Kappa + GIC) :该社区在长期寻求架构统一的解决方案、并在进行了多种方案选型(包括对比开源Paimon等方案)后,最终采用了云器科技提供的“通用增量计算”引擎。
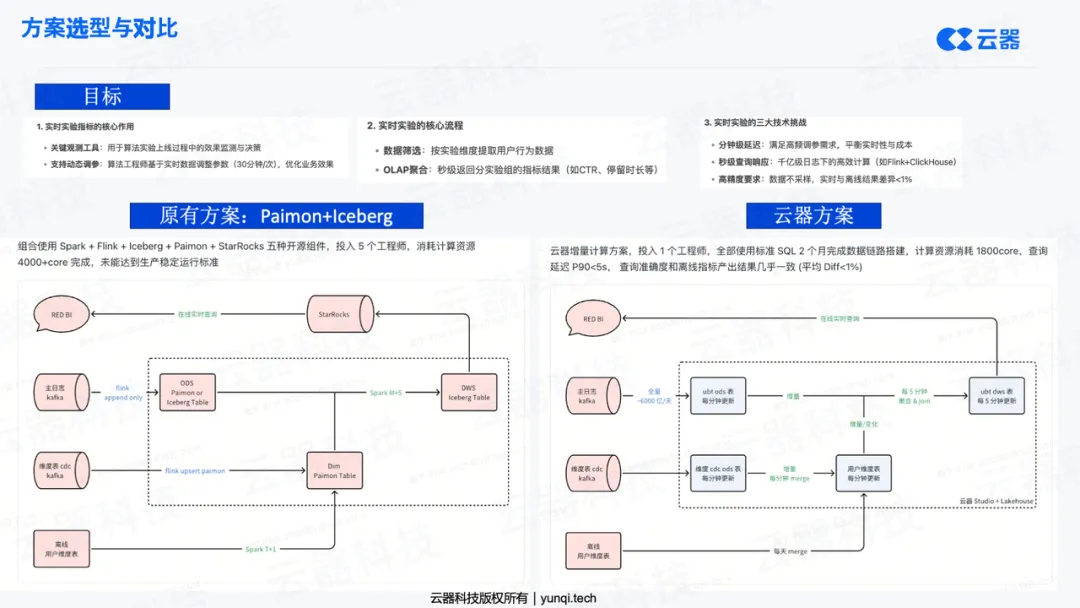
云器科技的方案之所以能胜出,在于其基于Spark强兼容(Highly Compatible)的增量计算能力 。它不是推倒重来,而是在客户现有的Spark体系上进行“即插即用”的升级,将原有的两条独立链路(Spark批处理和Flink流处理)统一为一条端到端的全增量链路(Full Incremental Pipeline) 。这完美契合了第四章提到的“通用增量计算”和“奖牌架构”模型。
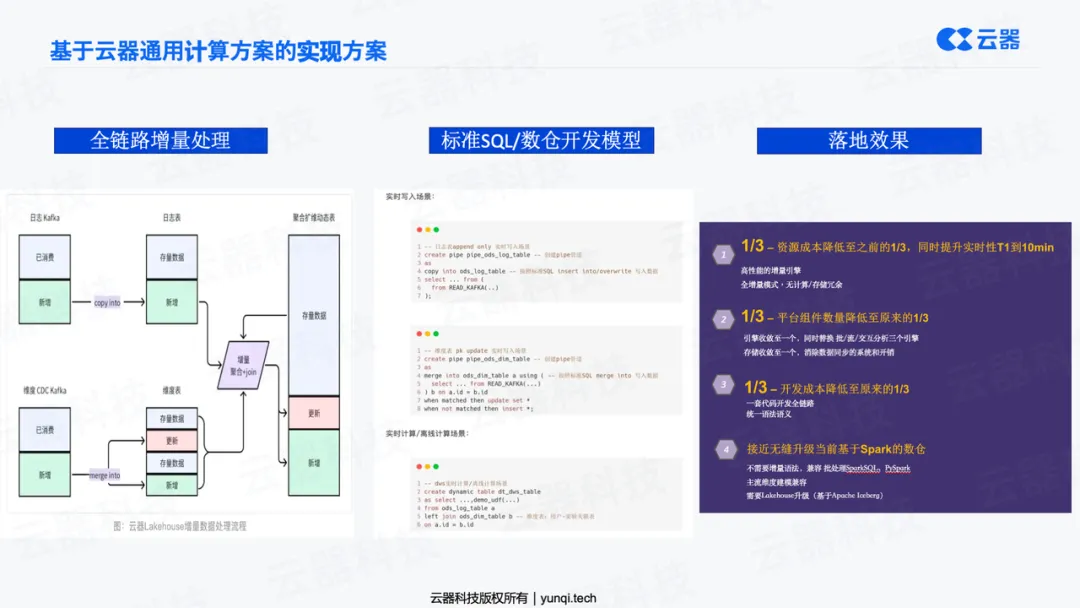
- 落地效果 : 该方案带来了显著的“三合一”收益:
- 资源成本降至1/3 :GIC只计算增量数据,极大节省了计算冗余,释放了2/3的计算资源。
- 开发成本降至1/3 :从维护两套SQL、两个团队,简化为“一套SQL、一个团队”,开发和维护效率大幅提升。
- 数据时效性 :从T+1(天级)提升至分钟级,实现了准实时的业务洞察。
结语
AI时代的浪潮已经到来,数据架构的演进势在必行。这不是一次推倒重来的革命,而是一场深刻的进化。

一个“AI-Ready”的数据基础设施,必须具备以下特征:
- 以 Lakehouse(湖仓一体) 作为统一存储所有(结构化与非结构化)数据类型的底座。
- 将 AI 作为第二个计算引擎 ,并与传统的SQL引擎深度融合。
- 采用通用增量计算 技术,实现奖牌架构(Medallion) ,彻底告别Lambda。
- 在保留所有企业级能力(安全、治理)的同时,转向 AI-Centric(API-First) 的设计,为智能体(Agent)做好准备。
对于大多数企业而言,在AI时代,最明智的战略选择就是投资和升级你的数据基础设施。如果大家对云器科技感兴趣,可以登录我们官网(yunqi.tech )/ 关注我们公众号(云器科技)。