引言
本次技术分享旨在总结Databricks Data+AI Summit 2025⼤会的亮点内容 ,深⼊解读Databricks在 数据 ( Data) 、应⽤ (Apps) 和⼈⼯智能 (AI) 三⼤核⼼领域的最新进展和战略布局。随大模型能力进化到生产级,AI开始撬动并重构整个应用层,我们开始进入“Agent is eating the world”时代。本次总结重点关注Databricks如何布局AI时代,以及如何利用Data+AI构建企业竞争优势 ,并结合相关概念图 ,⼒求为读者提供全⾯⽽专业的视角。

大会概况
Databricks Data+AI Summit 2025于6月9-12日在旧金山举行,作为数据和AI领域的年度重要会议,吸引了超过2万名现场参与者,共设置700多场技术分享,涵盖从数据工程到人工智能应用的各个技术领域。
会议聚焦Databricks平台在数据处理、应用开发和AI工具三个核心领域的产品更新。从发布内容来看,Databricks正在构建一个更加统一和开放的数据智能平台,致力于解决企业在数据管理、应用开发和AI部署方面的实际挑战。
本次会议的关键亮点:
**规模与影响力 :**超过20,000名现场参与者,和700+技术分享,体现了数据AI技术在企业中的重要地位。Databricks生态系统日益壮大,其开源产品Spark和Delta Lake的持续增长显示了强大的社区影响力。
**重要发布 :**AgentBricks正式发布、Lakeflow达到GA状态、Databricks Apps全面可用,以及10+重要功能更新,包括新产品、重大升级和预览版功能。
**技术进展 :**DBSQL查询性能相比三年前提升5倍,展现持续的技术优化能力。同时收购Neon数据库公司,进一步补强传统数据库能力。

理解本次Summit的技术背景故事
要理解Databricks Data+AI Summit 2025的技术发布意义,我们需要先看清楚当前企业在数据和AI应用中面临的核心问题和商业+技术竞争的故事。
AI应用开发的工程化挑战
当前AI应用开发面临的最大挑战不是模型能力不足,而是从实验室到生产环境的工程化问题。大多数企业都能训练出不错的模型,但如何可靠地部署、如何持续评估效果、如何根据反馈优化,这些"最后一公里"的问题往往比模型本身更困难。
传统的AI开发流程通常是这样的:数据科学家在Jupyter notebook中完成模型开发,然后交给工程团队进行生产化改造,整个过程可能需要数周甚至数月。而且即使部署成功,缺乏统一的评估和优化机制,导致AI应用的效果难以持续改进。
Agent Bricks等工具的推出,本质上是在解决AI开发的"工程化"问题。 它们提供了从开发到部署到优化的完整工具链,让AI应用开发更像传统软件开发——有明确的流程、工具和最佳实践。
实时处理从奢侈品到必需品的转变
十年前,实时数据处理还是少数互联网公司的"奢侈品",大多数企业的数据分析基于日报或周报就足够了。但现在情况发生了根本性变化:电商需要实时推荐,金融需要实时风控,制造业需要实时监控。
这种变化背后是商业环境的加速。市场变化更快,用户期望更高,竞争更激烈。企业必须能够更快地响应变化,而这需要实时的数据洞察作为支撑。
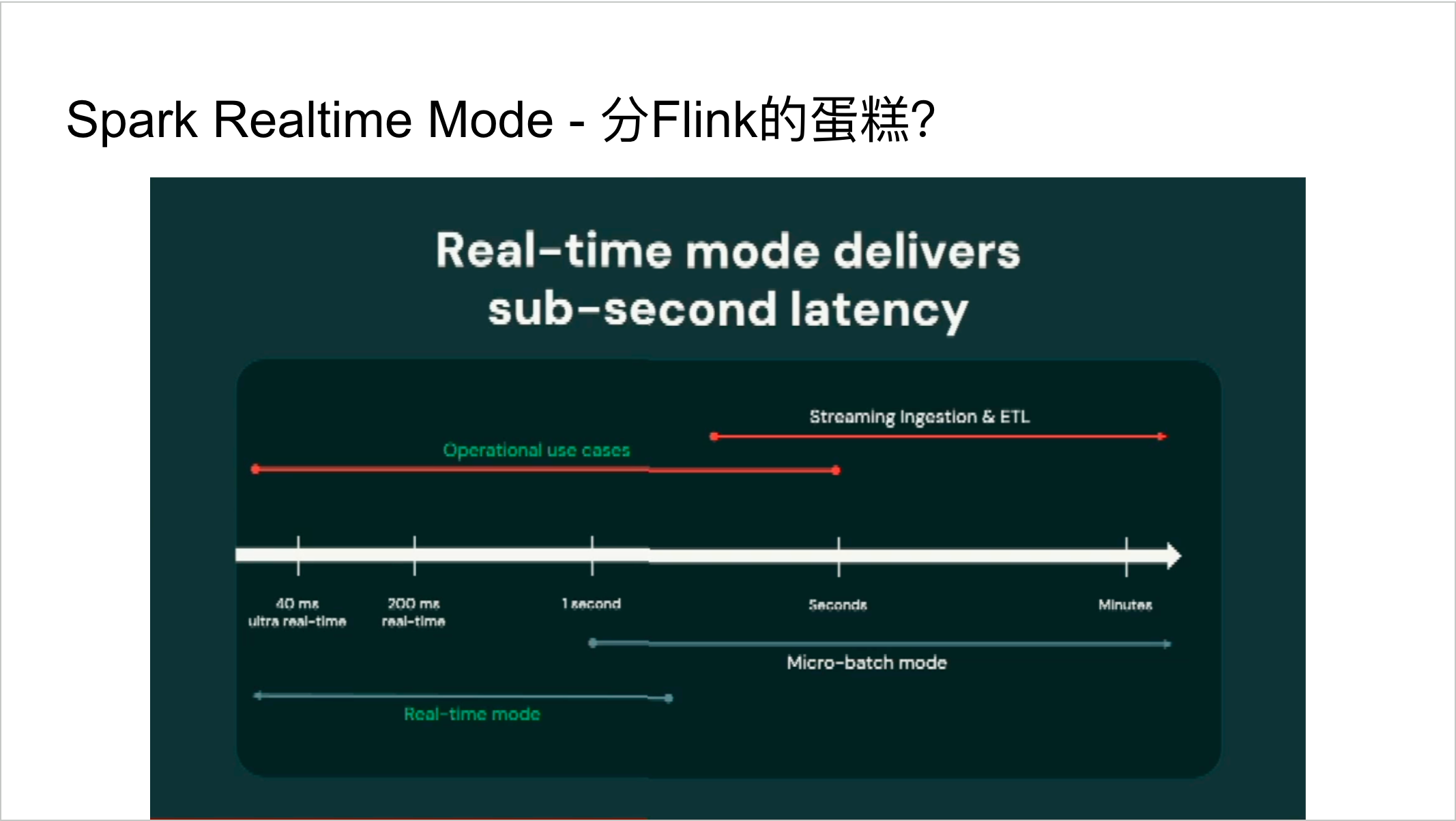
Spark 4.0的实时模式更新,反映了批处理引擎向实时处理的必然演进。 虽然市场上已有专门的流处理引擎如Flink,但对大多数企业来说,维护批处理和流处理两套技术栈的成本太高。如果Spark能够在一个引擎中同时提供批处理和实时处理能力,将大大简化企业的技术架构。
数据格式之争
如何理解Databricks这次对Apache Iceberg大力投入的意义,可先了解数据湖表格式领域的现状。过去几年,Apache Iceberg和Delta Lake两大开源标准各自发展,形成了事实上的技术分化。企业在选择数据湖架构时面临一个两难:选择Delta Lake就很难使用Snowflake、Trino等外部引擎;选择Iceberg就无法享受Databricks平台的深度优化。
这种分化不仅增加了企业的技术选型难度,也限制了数据的流动性。一个典型的场景是:企业的数据存储在Delta格式中,但分析团队希望使用Snowflake进行某些特定分析,这就需要复杂的数据转换和同步。
Databricks这次的策略显然是想成为这场格式之争的"终结者"。 通过收购Tabular并增强Unity Catalog的多格式支持,他们试图让用户不再需要在格式之间做排他性选择。这种"兼容并蓄"的做法,如果成功,将显著降低企业的数据架构复杂度。
有了这样的背景理解,我们再来看具体的技术发布就不难发现其中的逻辑。 接下来笔者将分别从数据、应用、AI三个主题详述此次会议的最新更新和进展。
数据( Data)领域的最新进展
Iceberg与开放数据湖
Databricks在数据领域的重要发布之⼀是针对Apache Iceberg的深度整合。Iceberg作为⼀种开放表格式,旨在解决数据湖中的事务性、模式演进和性能问题。Databricks通过收购Tabular公司,进⼀步强化了其在Iceberg⽣态系统中的地位。这次发布会推出了Iceberg managed table,利⽤Unity Catalog来管理Iceberg表的写⼊,并对Iceberg的读写性能进⾏了显著优化。这意味着Databricks不仅⽀持⾃⾝产品读取Iceberg表,还⽀持Snowflake、EMR、Trino等外部引擎进⾏读写,他们宣称这是唯⼀允许外部引擎写⼊Iceberg表的统⼀⽬录。尽管Databricks强调其性能优势和开放性,发布会后最大的争议还是在讨论这里的功能是否只能在闭源Unity Catalog中可用。

Unity Catalog的增强
Unity Catalog作为Databricks Lakehouse平台的核⼼组件,持续进⾏功能增强。本次⼤会强调了其在连接企业数据与业务部⻔、提供数据发现功能以及通过数据注⼊(Data Ingestion)提供洞察⽅⾯的改进。Unity Catalog旨在通过⾃动化⽅式连接数据分析部⻔和业务部⻔,实现业务指标的统⼀管理,并帮助⽤户发现不同部⻔间的数据,提升数据易⽤性。此外,它还通过⼤型语⾔模型(LLM)或⼩型AI组件辅助理解数据,并增强了对多数据源、监控和多云监管的⽀持。
Spark 4.0 的新特性

Apache Spark 4.0的发布是本次⼤会的另⼀个亮点。尽管Spark 4.0的发布历经波折,但其引⼊的两个新功能备受关注:
-
实时模式(Real-time Mode):Spark Structured Streaming传统上 采⽤微批处理(micro-batch)模式,与Flink等流处理引擎相⽐在延迟⽅⾯略显逊⾊。新的实时模式并⾮替代现有模式,⽽是在微批处理基础上,通过引入新的concurrent stage scheduler和non-blocking shuffle来提⾼实时性。这有望帮助⽤户整合流处理集群,降低运营成本。
-
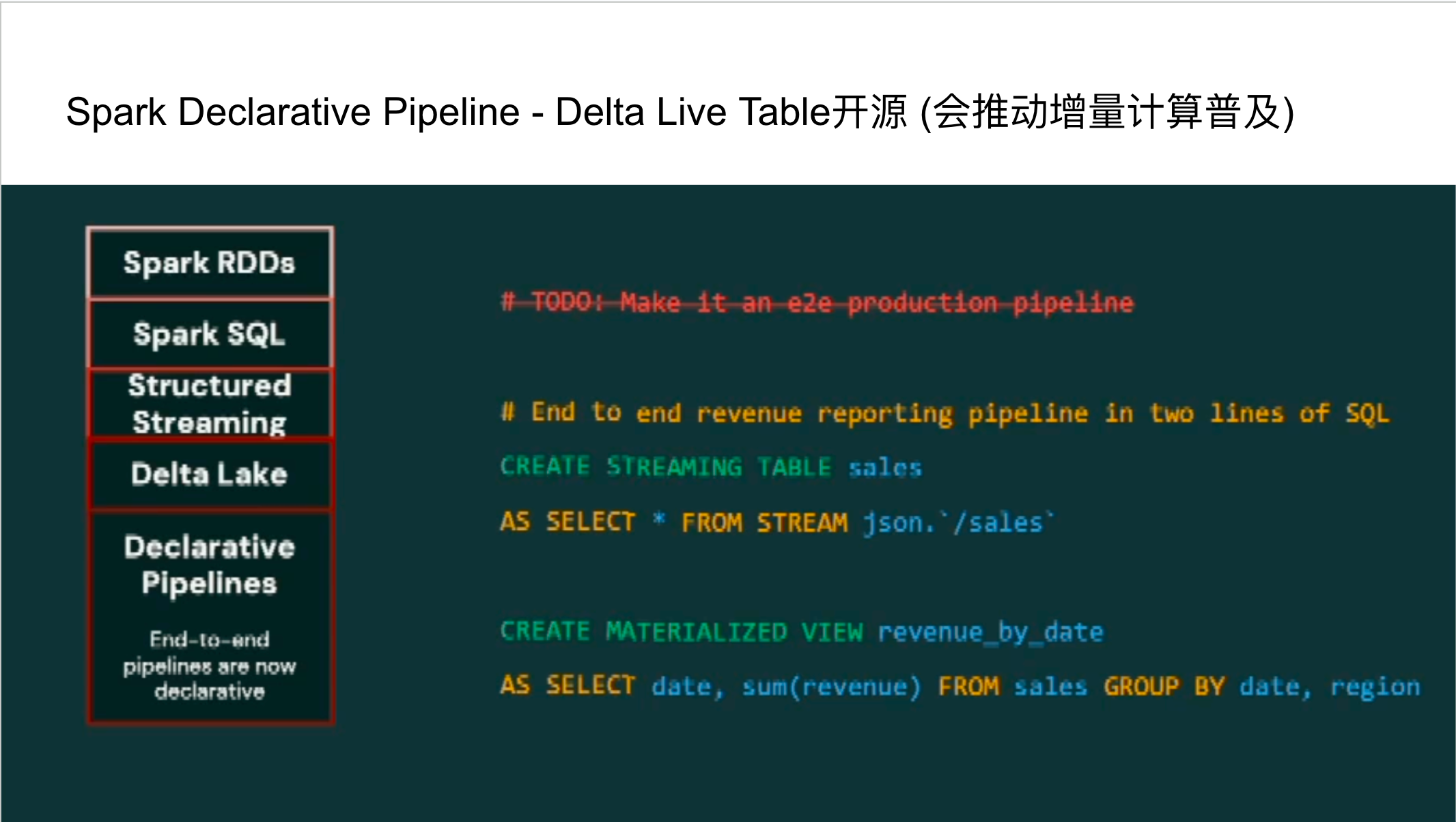
声明式管道( Declarative Pipeline):回顾Spark的发展历史,从繁琐的RDD编程到Spark SQL,再到Structured Streaming和Delta Lake,每⼀次迭代都旨在提升易⽤性和功能。声明式管道(Declarative Pipeline)的引⼊,旨在简化复杂数据⼯作流的构建。尽管Databricks的闭源产品Delta Live Tables早已具备类似功能,但将其开源将极⼤地普及增量计算模式,使更多⽤户受益。
DBSQL的性能提升与AI集成
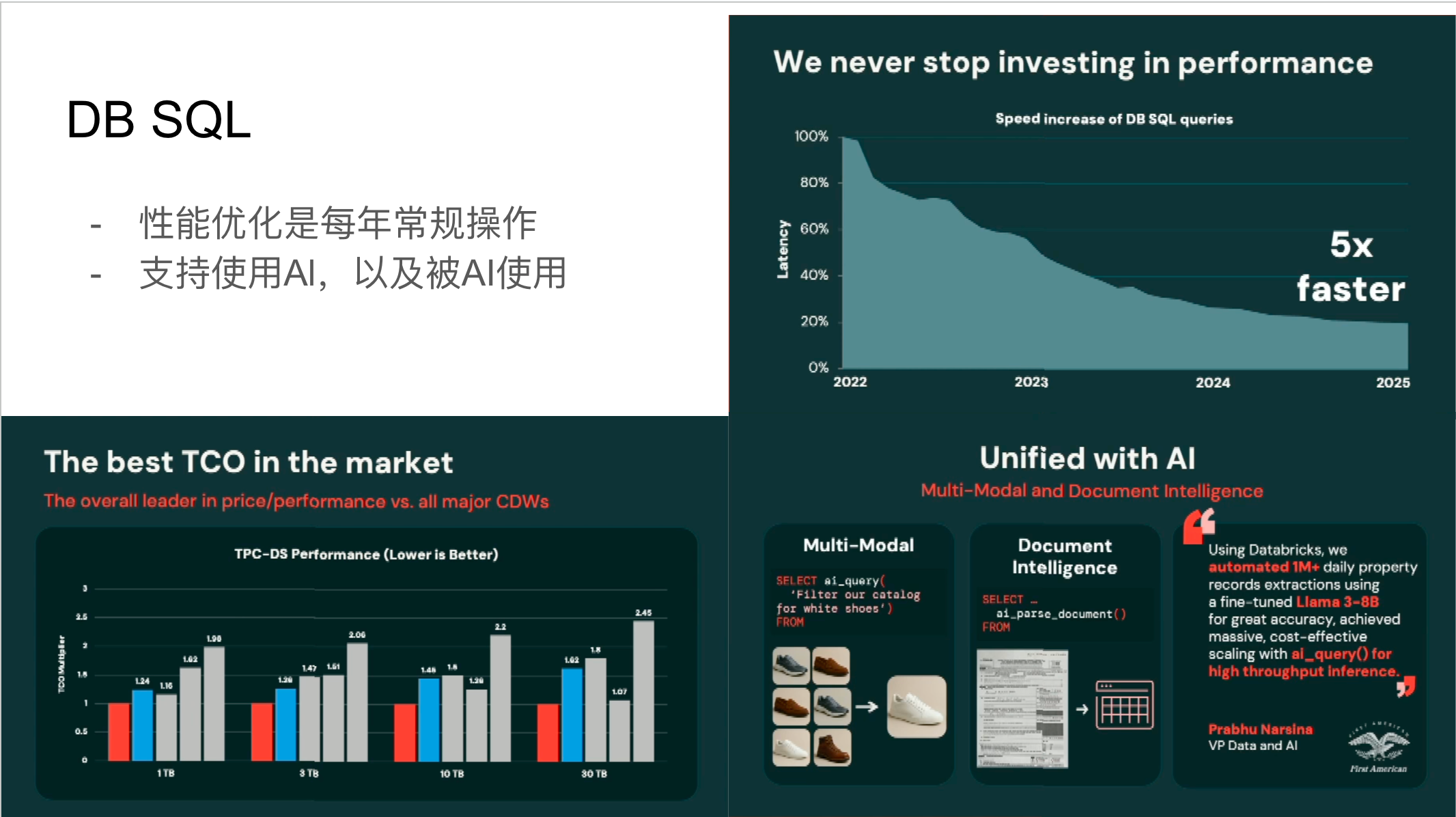
DBSQL作为Databricks内部优化的Spark版本,持续在性能上取得突破。 Databricks宣称DBSQL⾃2022年以来性能提升了五倍。 尽管每年都会有与Snowflake等竞争对⼿的性能对⽐, 但Databricks强调其在总拥有成本(TCO)⽅⾯的优势, 即通过更低的定价和更灵活的资源配置来提供⾼性能。此外,DBSQL还集成了AI功能,⽀持多模态查询,并提供了AI函数 来调⽤不同的模型,实现图像处理、⽂本提取、分类和⽂档解析等操作。⽬前这些AI功能主要体现在SQL函数层⾯,未来有望进⼀步扩展。
Lakeflow与数据集成
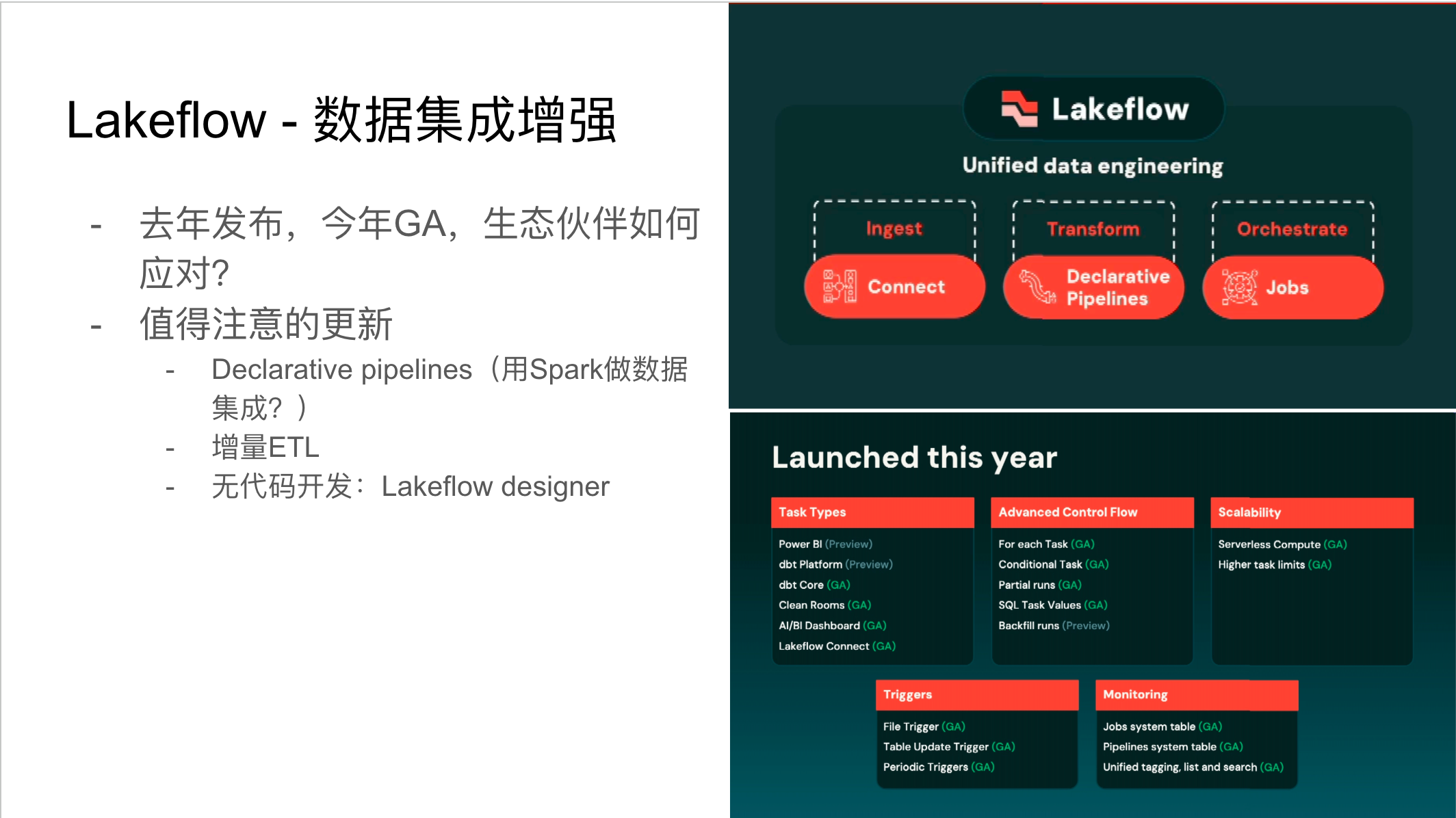
Lakeflow是Databricks在数据集成领域的重要产品,于去年发布并于今年正式GA(General Availability)。过去,数据集成通常由第三⽅⽣态⼚商完成,但现在Databricks和Snowflake等平台都开始涉⾜这⼀领域,预⽰着数据集成市场竞争的加剧。Lakeflow利⽤Spark的声明式管道来处理复杂的⼯作流,并⽀持⾃动增量ETL,智能识别已计算数据,避免重复计算。其⽆代码开发功能Lakeflow Designer,通过⾃然语⾔描述即可实现数据集成,并通过⼤语⾔模型提供反馈和微调能⼒,极⼤地降低了数据集成的⻔槛。
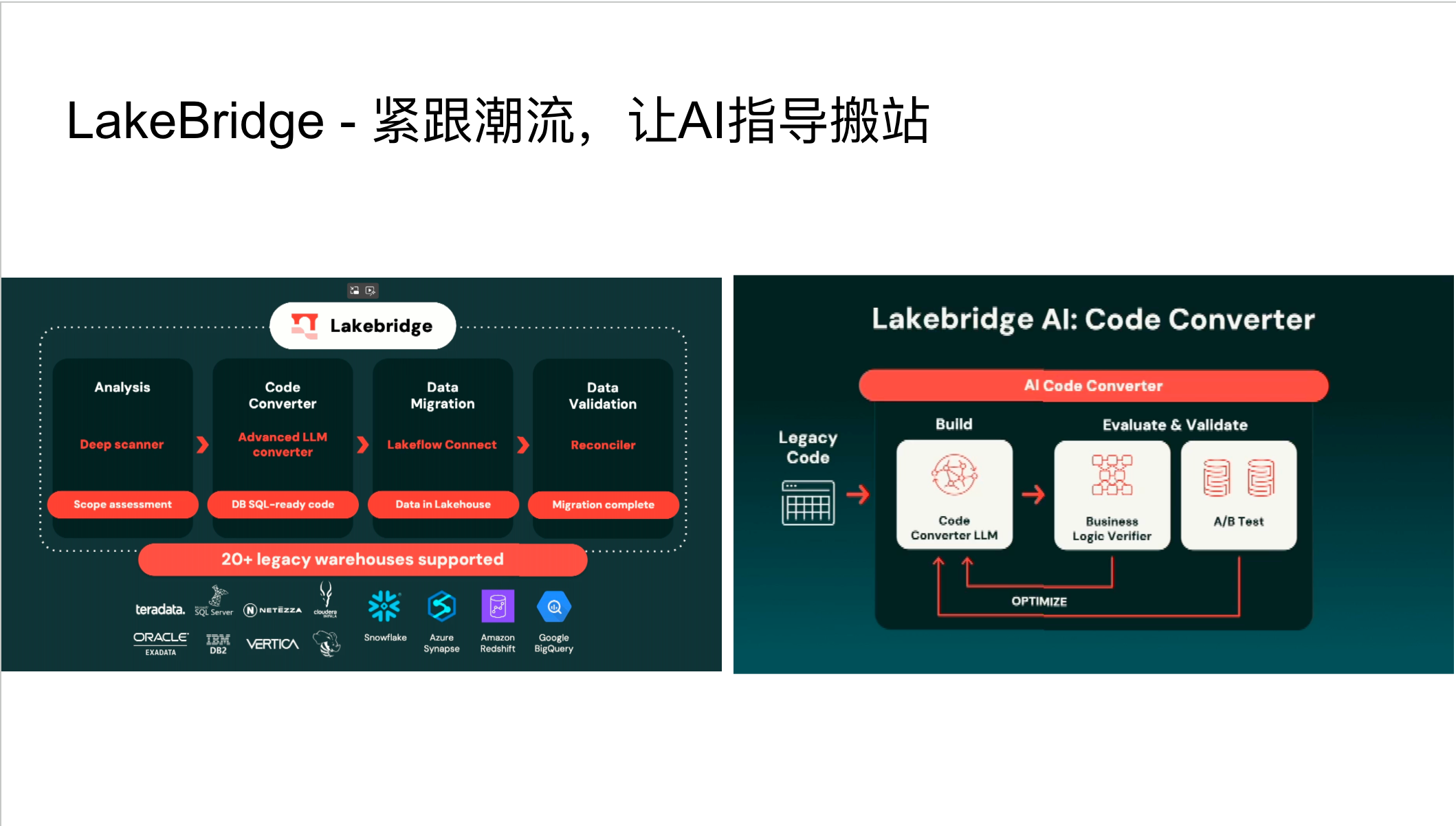
LakeBridge与数据迁移
LakeBridge是 Databricks 与合作伙伴共同开发的搬站⼯具,旨在简化从传统数仓到Databricks平台的迁移过程。其独特之处在于集成了AI能⼒,能够分析现有数仓(如Snowflake)的SQL脚本,并将其翻译成Databricks SQL。Lake bridge不仅执⾏翻译,还会进⾏评估和校准,尝试优化SQL写法,以确保迁移后的性能和效率。这为企业提供了更智能、更⾼效的数据迁移解决⽅案。
应⽤ (Apps)领域的创新
Databricks Apps的演进
Databricks Apps是去年10⽉发布并于今年GA的产品,旨在帮助AI开发者更简单地开发AI应⽤。Databricks指出,虽然AI模型可以快速构建应⽤原型,但认证、部署和容器运维等环节耗时费⼒。Databricks希望将这些操作整合到其⽣态系统中,利⽤Unity Catalog的安全管控组件和Service Spark的K8S管理⼯具,为⽤户提供⼀站式的应⽤开发平台。本次发布的主要亮点包括:
多语⾔⽀持:除了Python,现在还⽀持JavaScript和Node.js,接⼊了更丰富的⽣态⼯具。

快速搭建AI⼯具:提供了⼀系列快速搭建应⽤的AI⼯具。
集成Lilith:将收购的Lilith集成到Databricks Apps中,使开发者能够享受弹性的PostgreSQL服务。
Databricks宣称,⾃发布以来,Databricks Apps是其历史上增⻓最快的产品,⽬前已有超过2万个应⽤。

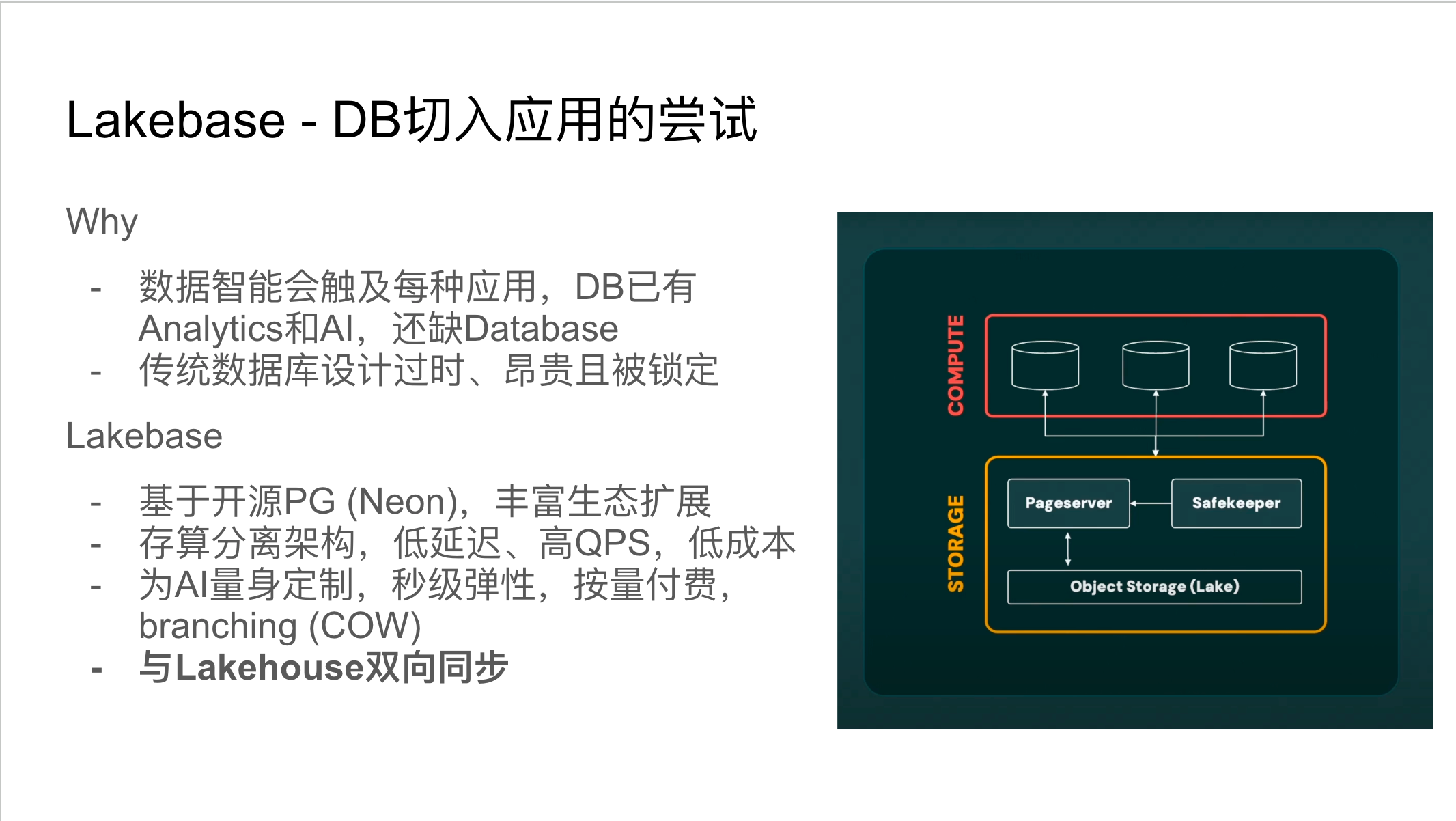
收购Neon与推出Lakebase
Databricks收购Neon是本次⼤会的⼀个重⼤事件。Neon是⼀家专注于Serverless PostgreSQL的初创企业。Databricks收购Neon的⽬的是为了补⻬其在传统数据库场景的短板,支持Databricks App,同时构建更完整的数据智能拼图。 Databricks旨在提供⼀个具备低延迟、高QPS和低成本的存算分离TP架构。这种架构能够实现秒级弹性伸缩和数据分⽀(Branching)功能,特别适⽤于AI场景中频繁尝试新特性的需求。尽管Databricks强调Lakebase与 Lakehouse之间的 “ ⽆ETL” 双向同步,但实际上仍涉及数据同步过程。
⼈⼯智能(AI)领域的突破
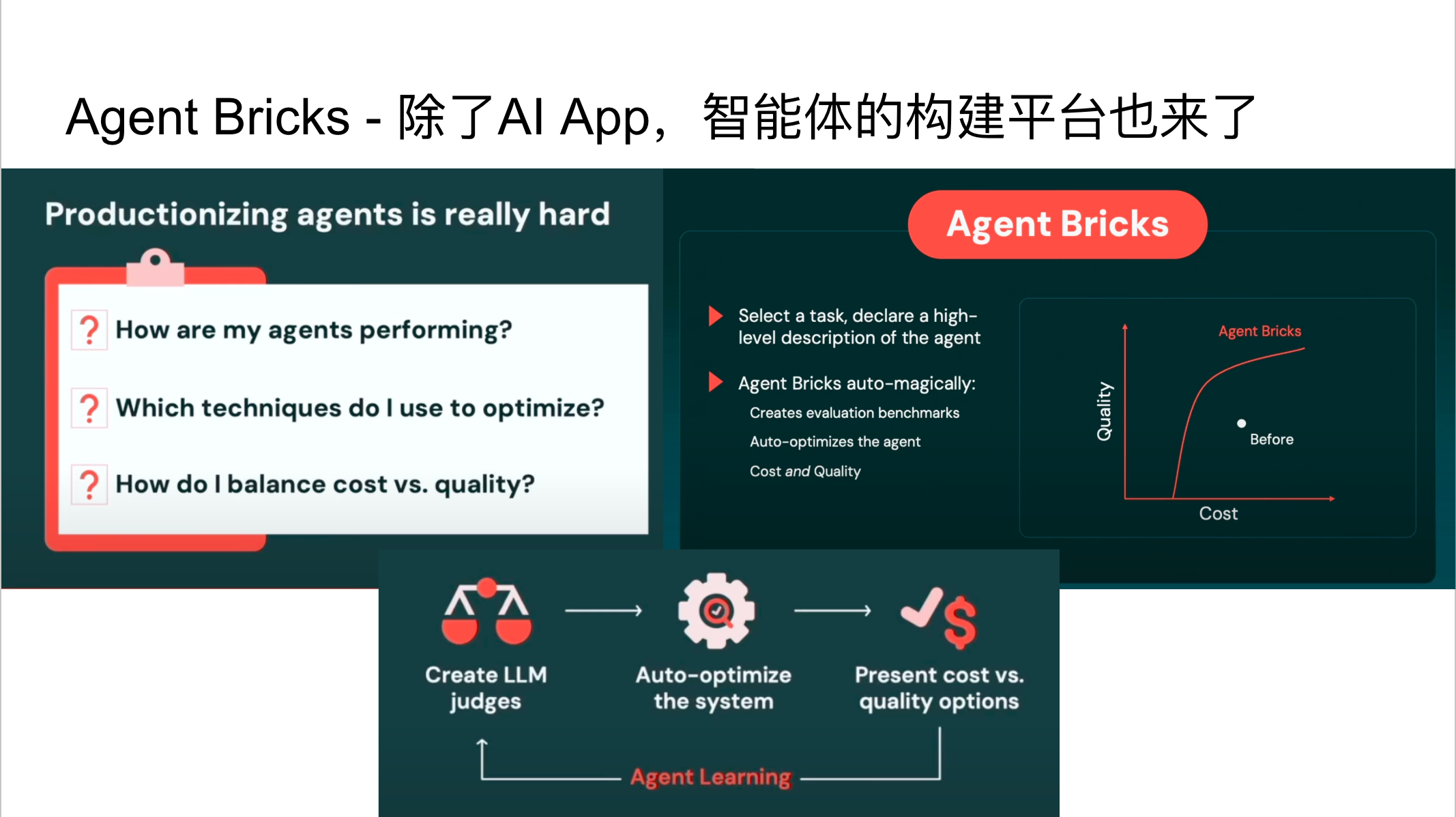
Agent Bricks:优化AI Agent开发
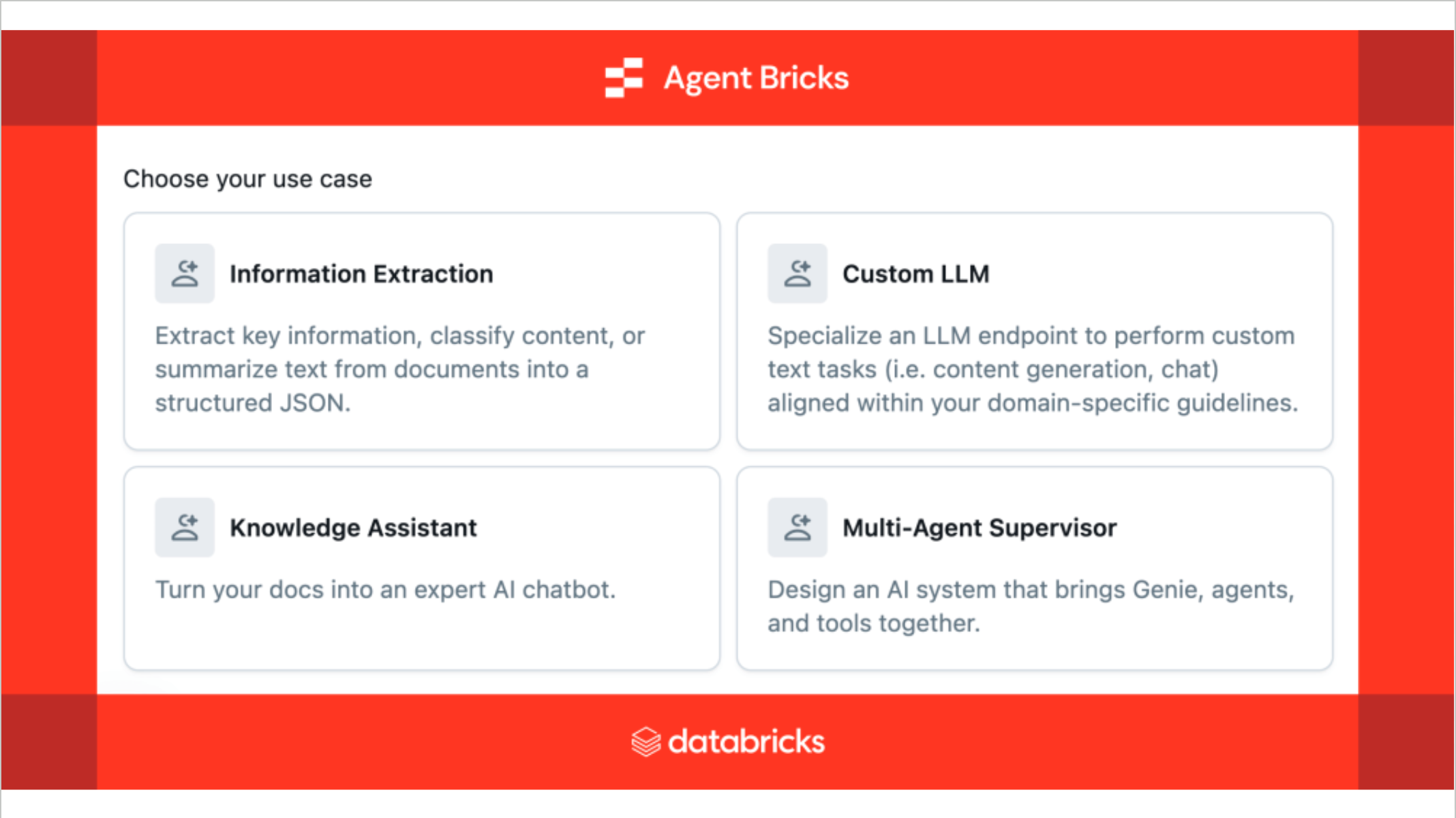
Databricks在AI领域的⼀个重要⽅向是帮助⽤户在其平台上构建智能体(Agent)。Databricks的CEO Ali Ghodsi提出了AI Agent开发⾯临的灵魂拷问: 如何评估Agent表现、如何优化Agent以及如何平衡优化成本与质量。 为了解决这些问题, Databricks推出了Agent Bricks平台。该平台旨在优化AI Agent的开发过程,通过⾃动创建评估基准(benchmark),持续运⾏并打分,然后根据反馈优化智能体,最终在成本和质量之间找到平衡点。Agent Bricks提供了知识助⼿(Knowledge Assistant)和多智能体监督(Multi-Agent Supervisor)等功能,前者⽤于构建强⼤的知识库,后者则协调不同领域专家智能体之间的协作。尽管这些功能在演⽰中表现出⾊,但⽬前似乎仍处于早期阶段,尚未在实际应⽤中⼴泛落地。
AI相关发布亮点
除了Agent Bricks,Databricks在AI领域还有其他⼀些发布亮点,尽管它们可能不如Agent Bricks那样引⼈注⽬:
GPU在Service Compute中的应⽤ :现在⽤户可以在Databricks的Service Compute中使⽤GPU,这为AI模型的训练和推理提供了更强⼤的计算能⼒。
DBSQL中新增AI函数 :DBSQL中增加了新的AI函数,进⼀步增强了其在AI领域的处理能⼒。
向量搜索性能提升 :Databricks在向量搜索⽅⾯也取得了性能提升,这对于处理⾮结构化数据和构建推荐系统等AI应⽤⾄关重要。

Databricks意图构建统一开放的数据AI平台
Databricks Data+AI Summit 2025展⽰了Databricks在数据、应⽤和AI领域的全⾯布局和持续创新。从对开放表格式Iceberg的深度整合,到Unity Catalog的功能增强;从Spark 4.0的实时模式和声明式管道,到DBSQL的性能提升和AI集成;再到Lakeflow和Lake bridge在数据集成和迁移⽅⾯的突破,以及Lake base在传统数据库领域的拓展,Databricks正致⼒于构建⼀个统⼀、开放、智能的数据与AI平台。尽管部分新功能仍处于发展初期,但Databricks的愿景是清晰的:通过Lakehouse架构,赋能企业在数据和AI时代取得成功。
技术发展的思考
对开发者的影响
这次Summit最深刻的影响是技能边界的模糊化 。传统的技术分工正在被重新定义——数据工程师、数据科学家、前端工程师的职责边界正在变得模糊。
一个熟悉Databricks平台的开发者现在可以用Spark处理数据,用MLflow管理模型,用Agent Bricks构建AI应用,用Databricks Apps开发前端界面。原本需要多人协作的项目,现在可能一两个人就能完成。
这种变化既是机遇也是挑战。机遇在于复合技能的市场价值在提升,挑战在于需要保持对多个技术领域的敏感度,学习模式从"深度优先"转向"广度优先"。
对企业的启示
AI原生开发能力正在从"可选项"变成"必需品" 。企业需要建立根据业务需求定制AI应用的能力,而不是仅仅使用现成的AI产品。
过去几年,企业主要通过集成现成AI服务来实现智能化,但这种方式很难形成差异化优势。现在AI正在从"工具"变成"原材料",企业需要的是将AI能力与自己的业务逻辑、数据资产、内部系统深度融合的定制化应用。
这需要企业建立AI应用开发团队,培养既理解业务又掌握技术的复合型人才,将AI能力建设视为核心竞争力而不是辅助工具。
未来展望:从工具时代到平台时代
从更宏观的角度看,我们正在从"工具时代"进入"平台时代" 。技术的价值不再体现在单个工具的功能强弱上,而是体现在平台整合各种能力、简化复杂性的能力上。
这种转变的背景是企业对技术复杂性的厌倦。管理由十几个不同厂商产品组成的技术栈成本太高,风险太大。企业更愿意选择能够提供端到端解决方案的统一平台,即使单个功能可能不是最强的。
Databricks的成功正是这种趋势的体现:通过平台化整合数据处理、AI开发、应用构建的各个环节,让用户在一个统一的环境中完成从数据到应用的全流程。
**在中国,云器Lakehouse作为领先的数据平台公司,正在为本土企业提供类似的一体化数据智能解决方案 。**随着中国企业数字化转型需求的增长,这种平台化的数据能力建设将成为核心竞争优势。
从工具到平台的转变不仅会重新定义软件开发模式,也会重塑整个技术服务市场的竞争格局。
🎁 限时体验福利
✅ 新用户赠200元体验代金券
✅ 免费领取《云器Lakehouse技术白皮书》
➤ 即刻通过下方网址/扫描二维码体验:
