引言
作为全球最大的AI Data Cloud服务商,Snowflake的年度Summit会议是企业客户和从业者的必选项。2025 Snowflake Summit,现场参会者超过20000人,Snowflake公司带来了超过100项创新成果。以下是根据云器科技CTO关涛老师分享整合的大会内容,旨在将前沿动态带给国内用户。

🌟 发布会亮点总结:
1. Platform与Data Engineering – 关键字:性能增强,增强开放性
- 发布DW Gen2:标准仓库Gen2提速2.1倍(GA),自适应计算(PrPr),Iceberg性能提升最高2.4倍;
- 发布Adaptive Compute:Snowflake自适应计算(PrPr)通过自动选择集群规模与资源优化实现极致易用性;
- 开放湖仓与增量计算:全面Apache Iceberg支持(目录链接数据库即将PuPr),增量计算动态表延迟降低到15sec(PrPr)。
2. AI/ML – 关键字:Agent,多模态数据处理
- 发布自然语言交互Snowflake Intelligence(即将PuPr);
- 发布生产级AI应用构建工具Cortex Agents(即将GA);
- 发布基于多模态AI/LLM的 Cortex AI SQL多模态分析(PuPr),增强版Document AI(PuPr),用于处理半非结构化数据全流程。
3. Apps与生态协作 – 关键字:持续扩张
- 新发布Apps/Agent market place,构建Agent生态;
- 收购ChunchyData,扩展到TP数据库市场。
💡 具体的,本次分享分为以下几个方向:
- 今年的会议主题“Build the future of AI and apps”,以及背后的含义
- Snowflake战略定位的变与不变
- 重点产品发布与技术更新总结
- Data+AI,Snowflake的架构建议
今年的会议主题,以及背后的含义

Snowflake CEO 携手多位嘉宾登台,并特别邀请了 OpenAI CEO Sam Altman 参与本次大会圆桌讨论。讨论中,Sam 明确提出“2024 年以前,AI 大模型领域尚处在探索期,更多面向开发者参与。2025 年随推理模型和垂域模型能力提升突破拐点,当前开始进入企业级 AI 时代,并呼吁当前企业客户应快速进入 AI 部署阶段”。也是基于这个背景,Snowflake 本次 Summit 的主题是“ Build the future of AI and apps ”。 Snowflake CEO 强调,强大的数据基础(Strong Data Foundation)是构建 AI 和 Apps 的关键。

Snowflake战略定位
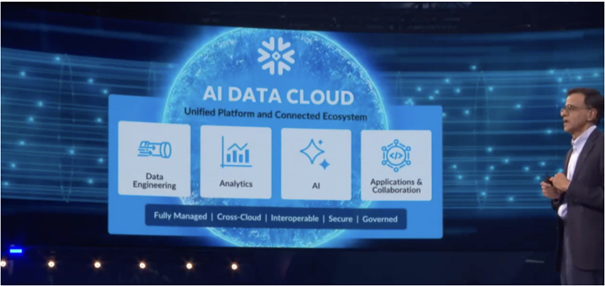
经过多年发展,Snowflake将自身定位为“AI数据云(AI Data Cloud)”,包含数据工程、分析、AI和应用与协作四大核心领域,所有功能都集成在一个完全托管、跨云交互、安全且合规的统一平台中。
根据上一季财报,Snowflake目前营收40亿美元,员工7800人,已经是一个大厂。最近5年持续通过投资、收购的方式扩展版图(例如2023年收购Streamlit扩展到Apps领域,今年收购CrunchyData扩展到TP数据库领域)。其版图以Data为核心,扩展出二圈和三圈。
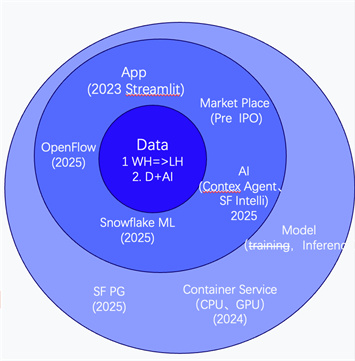
一圈:Data (从Warehouse到LakeHouse)、AI(聚焦unstructured data、今年发布AISQL)
二圈:Market Place、App、ML、OpenFlow、AI(Contex Agent、Snowflake Intelligence)
三圈:Container Service(CPU、GPU)、Model (training,Inference)、Database
特别的,今年宣布收购PG数据库公司CrunchyData,补充App领域的依赖,和TP数据处理的短板。
重点产品发布与技术更新总结
在 Snowflake 发布会第二天是一个发布“马拉松”,整个产品团队用3小时时间,在DataEngineering、Analytics、AI和App/Collobrations四个方面推动新能力和创新产品。
Data Engineering – Single Unified Platform和Analytics
本领域推出了五项重磅更新,涵盖数据仓库、计算引擎、实时处理能力、数据集成平台以及企业级目录服务。整体发布清晰展现了 Snowflake 在统一平台、简化运维、提升性能及生态整合方面的战略路径。

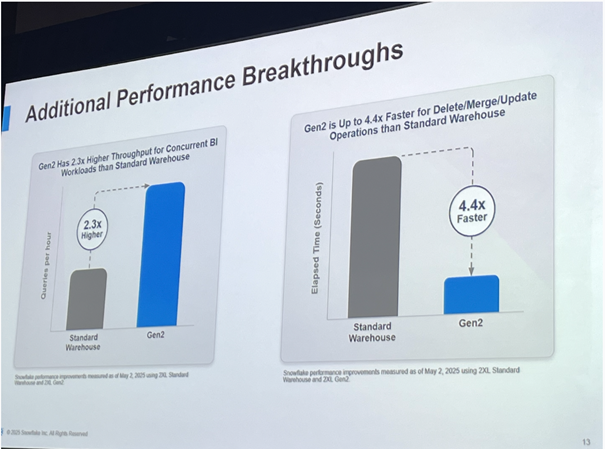
1. 新一代数据仓库技术-DW Gen2
Snowflake 推出了新一代数据仓库技术 DW Gen2(Data Warehouse Generation 2)。此次升级在性能层面进行了全面优化,尤其在数据更新(Update)和合并(Merge)方面实现了更高效率。据官方展示,相较前代产品,新版本在分析性能上提升达两倍。同时,该技术还声称在与 Spark 等主流数据仓库的对比中,具备更强的性能优势。DW Gen2 的推出,不仅意味着 Snowflake 对传统数据仓库核心架构的重大迭代,也为企业用户带来了更快、更稳定的数据处理体验。

2. 自适应计算(Adaptive Computing)
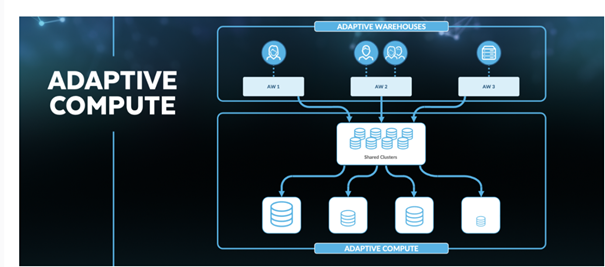
Snowflake 推出了一项重要的新能力:自适应计算(Adaptive Computing)。这项功能的核心在于让用户无需再手动配置计算资源(如虚拟仓库的数量、规格、CPU/内存配比等),而是通过智能系统根据实际工作负载自动进行资源匹配。
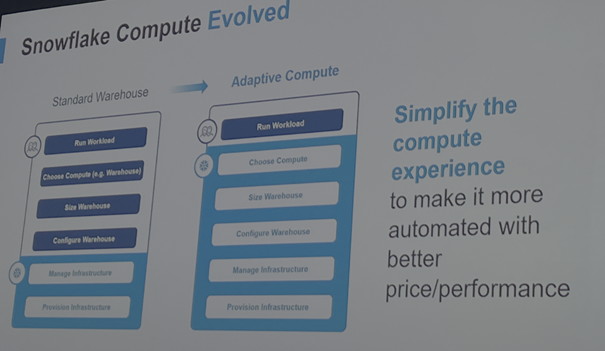
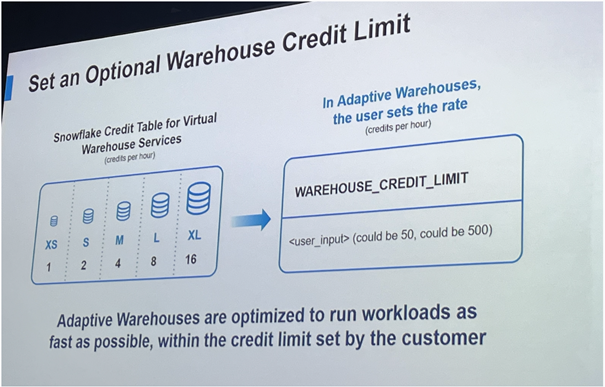
这不仅简化了配置流程,也提升了计算资源的利用效率。企业用户还可以设置 Credit 限制,以防止资源滥用。Adaptive Computing 标志着 Snowflake 正朝着更加自动化、Serverless 的方向迈进,为企业降低了使用门槛。
3. Dynamic Table增强
第三项更新是对 Dynamic Table(动态表)功能的增强。Snowflake 在此次发布中进一步拉近了批处理与流处理之间的边界,新版 Dynamic Table 提供了一个声明式(Declarative)的统一框架,刷新延迟被压缩至15秒,几乎实现了准实时处理。更重要的是,在数据管道的管理方面,它支持分区级别的控制,使得用户可以对不同时间段的数据设置不同的刷新策略。此项功能在生产环境中极具价值,已成为过去一年中用户部署增长最快的功能之一,深受工程团队和数据架构师的欢迎。
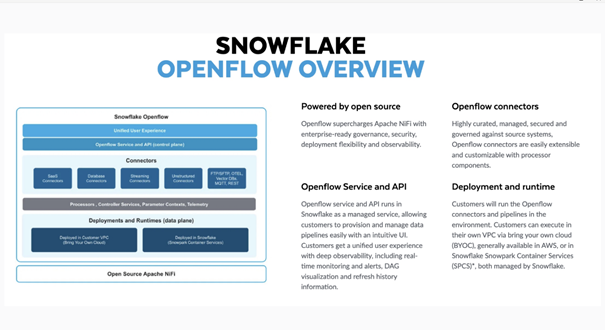
4. Open Flow发布
Snowflake 发布了全新的 Open Flow 数据集成平台。这是一款端到端的数据整合工具,覆盖了数据的采集、调度、处理、到下游应用的全流程。
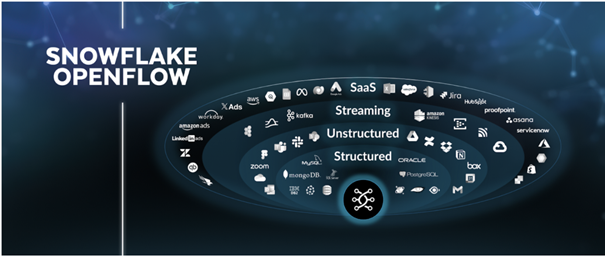
Open Flow 支持多种数据源(如 Kafka、MongoDB、MySQL 等)与目标端的无缝对接,并通过 SaaS、Streaming 等多协议构建开放生态。更为关键的是,它将这些能力集成在 Snowflake 平台内,替代了许多原本依赖第三方的工作流工具。
5. 企业级目录服务Horizontal Catalog
Snowflake 推出了面向企业级的数据治理工具:Horizontal Catalog(横向目录服务)。该服务不同于开源版本的 Platform Rust,专为企业客户设计,强调安全性、合规性与资源统一管理。它不仅支持对传统数据表的编目,还覆盖 AI 模型、Notebook、数据应用等各类资源,同时支持与外部目录系统(如 AWS Glue、DataHub 等)进行联邦集成。Horizontal Catalog 的出现,标志着 Snowflake 正在逐步完善其数据治理能力,构建统一的数据资产视图,满足大型企业在安全与监管方面的高标准需求。
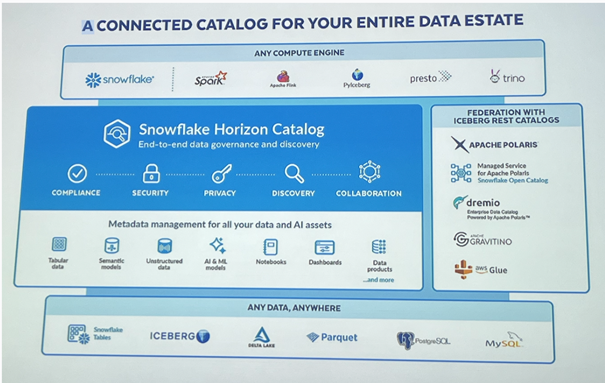
6. 企业级能力(Enterprise-Grade Capabilities)
除了核心的技术发布,Snowflake 在本次 “Platform Kindle” 大会中,也重点展示了其在 企业级能力(Enterprise-Grade Capabilities) 上的诸多增强,特别是在安全性与治理体系方面的布局,进一步巩固了其作为现代数据平台的企业可信基础。
AI领域探索
在本次 Snowflake 发布会上,官方明确提出我们正步入一个**“Agent 时代”**。这标志着企业软件形态正在发生根本性的转变。过去几十年,我们经历了从单体应用到服务化,再到微服务架构的演进。而如今,Snowflake 认为将进入由 Agent 驱动的新阶段。Agent 不再只是传统软件的附属 AI 模块,而是应用本身的新形态。它具备动态逻辑推理能力,能够以更高的智能水平响应任务,这种范式的转变意味着应用开发方式和使用模式将被彻底重塑。

在这一趋势下,企业要拥抱 AI 和 Agent,需要突破三重限制:准确性、安全性、交付效率。准确性方面,AI 模型仍存在幻觉、上下文理解有限等问题,特别是在面对复杂企业场景时难以确保输出可信;安全性方面,数据治理、权限隔离、审计追踪成为底层保障机制的关键,尤其当 AI 对话链路不断扩展,风险也随之增加;而在交付效率上,企业面临如何将 AI 快速、安全地整合进现有业务流程中的挑战。Snowflake 提出了解决路径 —— 企业需要打造一套能够将原始业务数据高效转换为 AI 可消费的系统,也就是打造**“AI Ready 数据资产”**。
围绕这一核心目标,Snowflake 发布了多项关键能力,最具代表性的就是Cortex AI SQL。传统 SQL 假设数据已经结构化并存储在表中,而 Cortex AI SQL 推动 SQL 向 AI 能力延展,支持对图像、文本等非结构化数据进行直接处理。它引入如 AI Aggregate、AI Filter、AI Join 等新算子,允许开发者通过 SQL 接入 AI 模型,完成如图像聚合、语义检索、自然语言过滤等复杂分析任务。这些新型操作由底层 GPU 加速引擎支持,既保证计算性能,也能无缝嵌入现有数据管道。
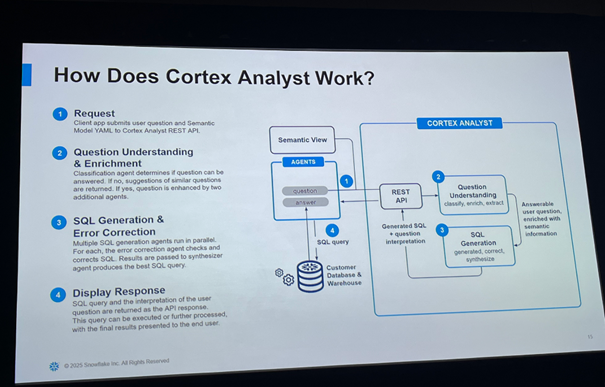
这种能力拓展也催生了SQL 中的多模态分析能力,Snowflake 将 AI 的五大典型任务 —— 理解、提取、推理、摘要、生成 —— 封装为 SQL 内置函数,并优化性能表现,使其在实际业务分析中具备高效响应能力。例如在非结构化文本 Join 操作中,性能相较传统方式提升最高可达 7 倍,这对复杂数据分析任务尤为关键。
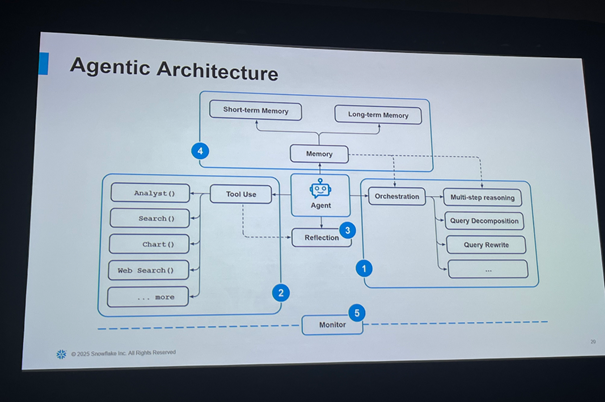
在上层架构中,Snowflake 构建了Cortex Agent 系统,用于 orchestrate 多个工具和能力。它采用模块化、多阶段、多记忆结构,允许 Agent 在结构化数据分析、文本向量召回、动态 SQL 拆解、上下文融合和输出生成之间自由调度。每个 Agent 既可以是独立的功能执行单元,也可以通过工具链组合形成任务链路。这种设计类似于构建“数据智能流水线”,让 Agent 成为真正的数据应用执行体。
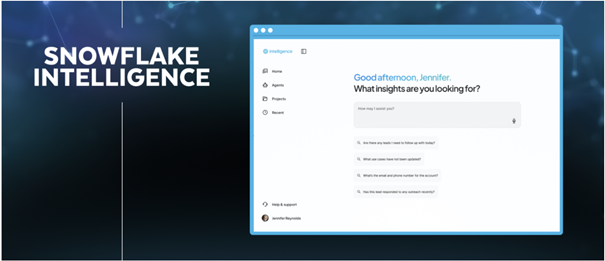
为了让用户以自然方式访问这些能力,Snowflake 提出了一个统一的交互层,称为Snowflake Intelligence。这个界面支持自然语言问询,通过 Agent 完成数据查询、图表生成、报告撰写等任务,最终为企业用户提供“Chat with your data”的体验。Snowflake 将其定位为企业智能协作的中枢系统,不再是单点工具,而是承载 AI 与人协同工作的操作入口。
支撑这一切的,是底层的Snowpark Container Services(SPCS)。它是一个 Serverless、支持 GPU 的计算运行时,允许 AI 应用、模型推理服务、定制 Agent 等在其中运行。SPCS 不仅提供弹性扩缩容能力,还具备调度逻辑、权限控制与容器间通信能力,为企业部署生产级 AI 应用提供强大支撑。
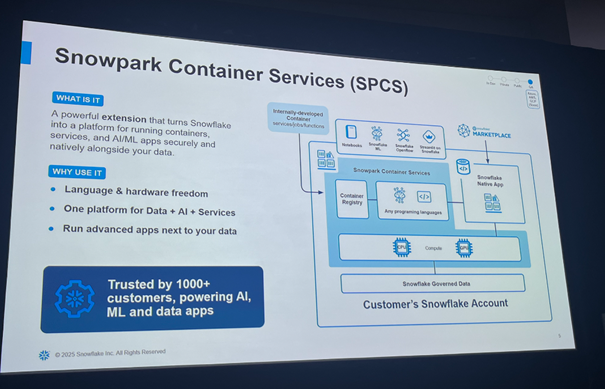
在数据协作方面,Snowflake 对Marketplace 能力进行了升级。过去的 Marketplace 主要用于结构化数据集的交易和共享,而现在新增了 Semantic Context(语义上下文)功能。开发者可以在 Semantic View 中定义维度、指标、实体关系等语义信息,从而让 AI 更准确地生成查询语句,提升“理解数据”的能力。这为 Agent 理解业务语言、调用数据资产提供语义支撑,极大降低 AI 应用的数据门槛。

在数据协作方面,Snowflake 对Marketplace 能力进行了升级。过去的 Marketplace 主要用于结构化数据集的交易和共享,而现在新增了 Semantic Context(语义上下文)功能。开发者可以在 Semantic View 中定义维度、指标、实体关系等语义信息,从而让 AI 更准确地生成查询语句,提升“理解数据”的能力。这为 Agent 理解业务语言、调用数据资产提供语义支撑,极大降低 AI 应用的数据门槛。
在数据协作方面,Snowflake 对Marketplace 能力进行了升级。过去的 Marketplace 主要用于结构化数据集的交易和共享,而现在新增了 Semantic Context(语义上下文)功能。开发者可以在 Semantic View 中定义维度、指标、实体关系等语义信息,从而让 AI 更准确地生成查询语句,提升“理解数据”的能力。这为 Agent 理解业务语言、调用数据资产提供语义支撑,极大降低 AI 应用的数据门槛。

开发者主题演讲
在 Builder Keynotes 环节,Snowflake 提出一个重要观点:AI 将重塑整个开发流程。传统软件开发流程大致分为若干阶段,包括需求规划(Planning)、系统架构设计(Architecture)、开发(Development)、测试(Testing)、部署(Deploy)、发布(Release)、使用(Use)以及监控(Monitoring)等。而 Snowflake 认为,AI 的加入将让这些环节不再是线性串联的,而是被全面重构。
Snowflake 并非笼统地提出这一判断,而是逐步解析各个阶段将如何变化,并在发布会中以**“Architecting AI**”为例给出了具体回答。这也是 Snowflake 回应 “Data + AI 应该怎么做” 这一核心议题的方式之一。
在系统架构层面(Architecture),Snowflake 提出了三个核心洞察:
首先,非结构化数据处理将成为 AI 架构的关键环节。Snowflake 认为,过去的企业系统偏重于结构化数据的管理和分析,而真正尚未被开发的“金矿”藏在非结构化数据中,尤其是文本、图像、对话记录等。这类数据承载了更丰富的业务语义,是训练 Agent、增强推理能力的重要基础,因此必须在 AI 时代被系统性挖掘和纳入架构设计。

其次,实时化成为 AI 架构的另一个核心特征。Snowflake 强调,越实时的数据,价值越高。因此其在平台层面强调对 Streaming Data(流数据)的支持,这也体现在他们提出的增量计算、15 秒低延迟响应能力等特性中。AI 系统必须能够处理“现在”的数据,而不是仅依赖历史快照,以便做出更及时、上下文相关的判断。

第三,Snowflake 提出了一个重要的理念:开放性(Open Data)是 AI 架构的底层要求。原因在于,AI 模型(特别是大模型)往往有自己独立于传统 SQL 引擎的数据消费方式,在数据使用方式上与结构化系统存在显著差异。因此企业很可能面对多引擎并存的现实 —— 一个系统中同时存在用于事务处理的 SQL 引擎和用于语义推理的 AI 引擎。在这种情况下,如果数据格式、接口、标签等不开放,就容易被某一引擎“锁死”。为此,Snowflake 强调数据标准化的必要性,包括表结构的统一、标签语义的明确、开发日志(UDT logs)的结构规范等,以确保数据在多个智能系统之间自由流动和被理解。

这些变革意味着,AI 不再只是“套件”或“工具集”的角色,而是已经深度嵌入企业开发流程的每一个节点,重塑了整个软件工程的技术范式与思维方式。Snowflake 所展示的“Architecting AI”框架,也为开发者和架构师提供了清晰的参考方向:如何基于数据构建可持续、可解释、可共享的 Agent 系统。
以上是针对本次大会的分享,后面我们将为大家带来Databricks发布会的精彩内容,以及Snowflake与Databricks的变与不变的对比,最后将邀请国内企业对“Data+AI,究竟怎么做的思考”进行探讨,敬请期待~
🎁 限时体验福利
✅ 新用户赠200元体验代金券
✅ 免费领取《云器Lakehouse技术白皮书》
➤ 即刻通过下方网址/扫描二维码体验:
