作者:吴刚 云器科技Lakehouse技术专家、Apache ORC PMC、Apache Parquet Commiter、 Apache Arrow Committer
📌 导语:
随着Data+AI技术的快速演进迭代,湖仓一体架构(Lakehouse)已经成为当前数据平台的事实标准。本文将简要概述数据平台的发展史,阐述湖仓架构产生的必然性。再从开放性的角度出发,探讨Lakehouse架构的选型,以及为什么开放式湖仓设计(Open Lakehouse)会是湖仓一体架构的最终归宿。
湖仓一体的诞生
我们先来看下湖仓一体架构出现之前,数据平台经过了怎样的发展。根据CCSA TC601 大数据技术标准推进委员会发布的《湖仓一体技术与产业研究报告(2023年)》显示,数据平台架构持续演进主要经历了数据库、数据仓库、数据湖三个阶段,它们各自都有明显的优缺点:
-
数据库(Database):数据库诞生于20世纪60年代,它能够对结构化数据进行集中式的存储和计算,主要作为数据存储和计算的基础设施。数据库支持事务处理,可以确保数据的一致性和完整性。例如,企业可能使用MySQL或Oracle等关系型数据库管理系统来存储和查询结构化数据,如客户信息、订单记录等。传统数据库主要适用于结构化数据,对于半结构化和非结构化数据的存储和处理能力有限。另外,数据库在处理大规模数据时可能面临性能瓶颈和扩展困难,无法满足快速增长的数据需求。
-
数据仓库(Data Warehouse):随着数据量的增长和多样化数据类型的出现,在上世纪90年代数据仓库成为数据平台的主流架构。数据仓库具备规范性,能够集中存储和计算结构化数据。数据仓库通常采用星型或雪花型模型来组织数据,以支持复杂的分析查询。数据仓库可以帮助企业实现数据整合,进行在线分析处理(OLAP)和数据挖掘(Data Mining),从而辅助决策。例如,企业可能使用Teradata、Amazon Redshift和Google BigQuery等数据仓库解决方案来集中存储和分析销售数据、市场趋势等。然而,随着大数据技术的发展,数据仓库在处理非结构化数据、半结构化数据以及具有高多样性、高速度和高容量的数据方面表现出局限性。在数据仓库中,数据的加载和转换过程可能较为复杂,导致数据加载速度较慢。由于数据仓库的数据模型和索引设计,某些查询可能需要较长的时间才能返回结果。此外,数据仓库在处理来自不同数据源的数据时,需要进行数据集成和转换,这可能涉及到复杂的ETL(抽取、转换和加载)过程。
-
数据湖(Data Lake):为了满足多种数据类型存储和多场景分析的需求,数据湖成为数据平台的另一种主流架构。它采用分布式存储来存储各种类型的数据,包括结构化、半结构化和非结构化数据,例如,企业可以Amazon S3等存储系统来存储各种数据源的原始数据,如日志文件、传感器数据、社交媒体数据等。数据湖提供了更大的灵活性和扩展性,使企业能够在需要时进行数据探索和分析。数据湖具有更好的扩展能力,能够灵活支持多种类型数据的高效取用,但不支持事务处理,数据质量难以保障。数据湖通常以原始数据的形式存储,缺乏严格的数据模式和约束,可能导致数据一致性和隔离性的问题。
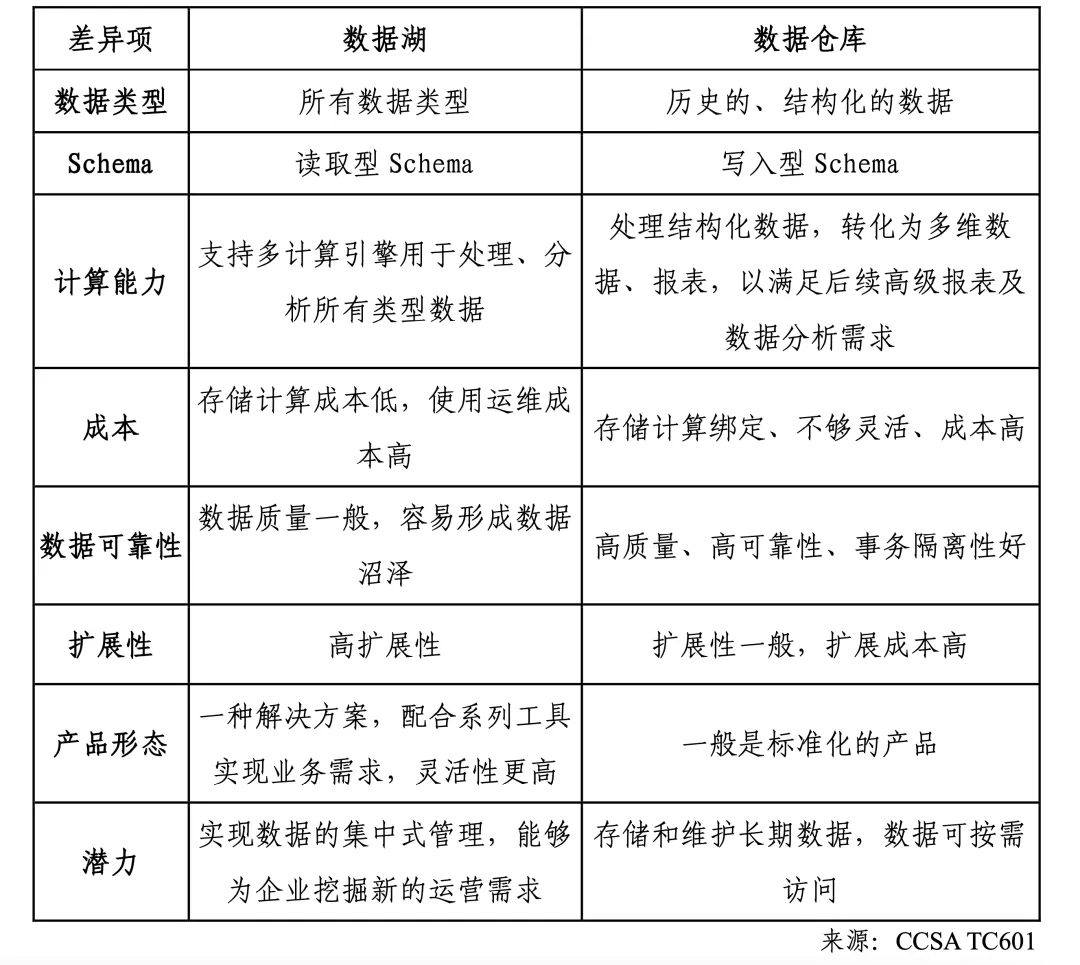
既然数据仓库和数据湖有着非常明显的优缺点(见上表),就短暂地诞生过一种“湖仓混合”架构(见下图),企业将数据湖和数据仓库结合起来,以充分发挥它们各自的优势。例如,企业可以使用数据湖作为数据的原始存储和数据探索的平台,而将数据仓库用于数据集成、数据清洗和高性能的分析查询。但是,"数据湖+数据仓库"混合架构也有着明显的缺点:
- 架构复杂:混合架构需要同时管理数据湖和数据仓库,涉及到不同的数据存储和计算引擎,增加了架构的复杂性。
- 开发运维难度大:混合架构需要维护和管理多个组件和系统,对开发人员和运维团队提出了更高的要求。
- 成本高:混合架构的建设和维护成本较高,包括硬件设备、软件许可和人力资源等方面的投入。
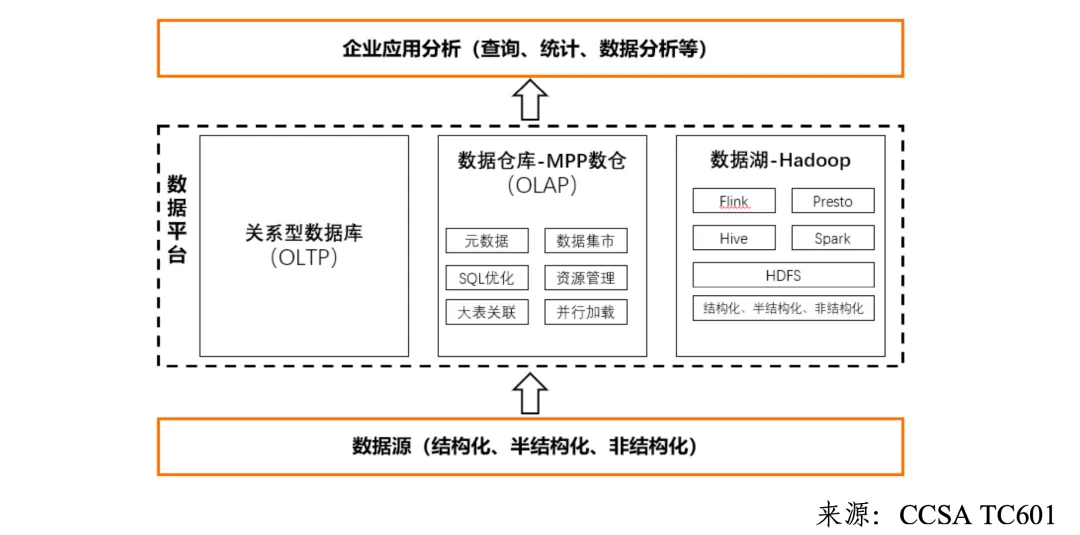
由于现有架构中的数据仓库和数据湖有着各种各样的问题,湖仓一体架构就应运而生了,接下来我们来看看什么是湖仓一体。
湖仓一体是什么
Databricks公司在CIDR 2021发表论文首次正式提出了Lakehouse的概念 ,但实际上湖仓一体的概念并非由单一个体提出,而是随着技术的发展和需求的变化逐渐形成的,下图分别列举了国外主流厂商对Lakehouse的理解。

与"湖+仓"混合架构简单地把数据湖和数据仓库进行简单的堆积不同,湖仓一体架构(Lakehouse)是一种新兴的数据架构,将数据湖和数据仓库的特点融合在一起。它旨在解决传统数据湖和数据仓库各自的局限性,并提供更强大的数据管理和分析能力。湖仓一体架构的特点如下:
-
统一数据存储:湖仓一体架构将结构化、半结构化和非结构化数据以原生格式存储在数据湖中。这种统一的数据存储方式消除了数据复制和转换的需求,简化了数据管理过程。
-
事务支持:与传统的数据湖相比,湖仓一体架构提供了事务支持。它允许在数据湖中执行事务操作,如插入、更新和删除,确保数据的一致性和可靠性。
-
数据质量和治理:湖仓一体架构注重数据质量和治理。它提供了数据血缘追踪、数据质量监控和数据访问控制等功能,确保数据的准确性、完整性和安全性。
-
实时和批处理:湖仓一体架构支持实时和批处理数据处理。它可以处理实时数据流和大规模批量数据,并提供实时分析和即席查询的能力。
-
弹性和可扩展性:湖仓一体架构具有弹性和可扩展性。它可以根据需求自动扩展计算和存储资源,以适应不断增长的数据量和变化的工作负载。
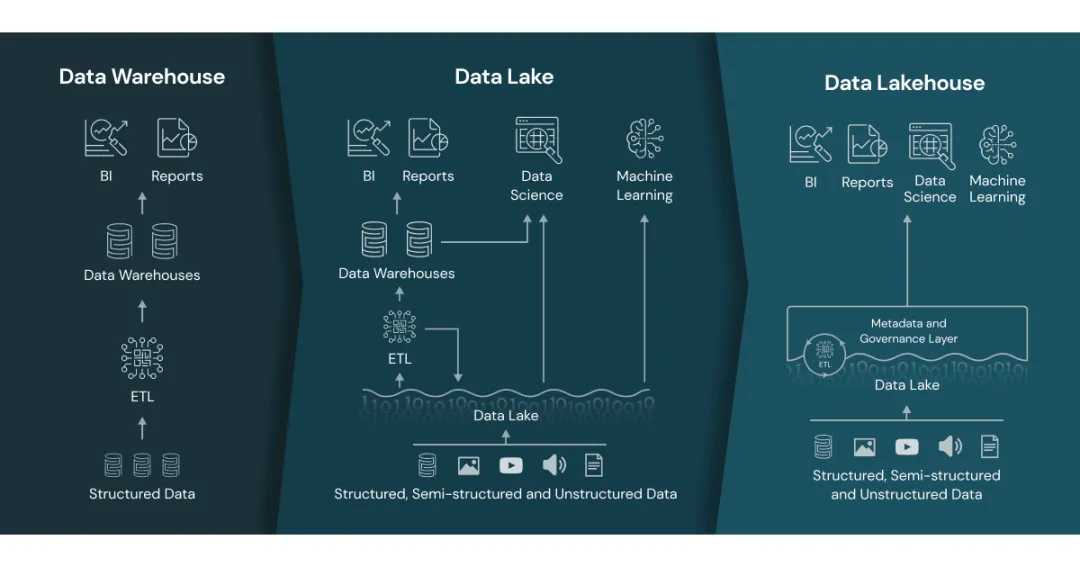
湖仓一体架构通过将数据湖和数据仓库的优势结合起来,提供了更灵活、可扩展和强大的数据管理和分析能力。它适用于各种数据场景,包括实时分析、机器学习、数据探索和报表等。
传统数据仓库和数据湖的老玩家,演进到湖仓一体架构有两个主要方向:一是“湖上建仓”,即在数据湖的基础上构建数据仓库,保留数据湖的灵活性和可扩展性,同时引入数据仓库的治理和分析能力,典型的例子是Databricks和开源Hadoop体系;二是“仓外挂湖”,即在数据仓库外部挂载数据湖,让数据湖成为数据仓库的一个数据源,以便企业更好地利用数据湖中的数据,典型的例子是Amazon Redshift、Google BigQuery、阿里云MaxCompute。由此可见,湖仓一体技术的发展,旨在融合数据湖和数据仓库的优势,形成一种更强大、灵活且易于管理的数据管理架构。通过湖仓一体,企业可以更好地处理和分析各种数据类型,实现数据价值的释放,因此湖仓一体架构已经成为当代大数据平台的事实标准。
湖仓一体发展趋势
随着用户场景和业务需求的不断变化,湖仓一体架构在发展过程中也出现了新的趋势。Dremio在2023年发表的论文《The Data Lakehouse: Data Warehousing and More》中,提出Lakehouse是一个与具体实现无关的模块化湖仓一体架构:
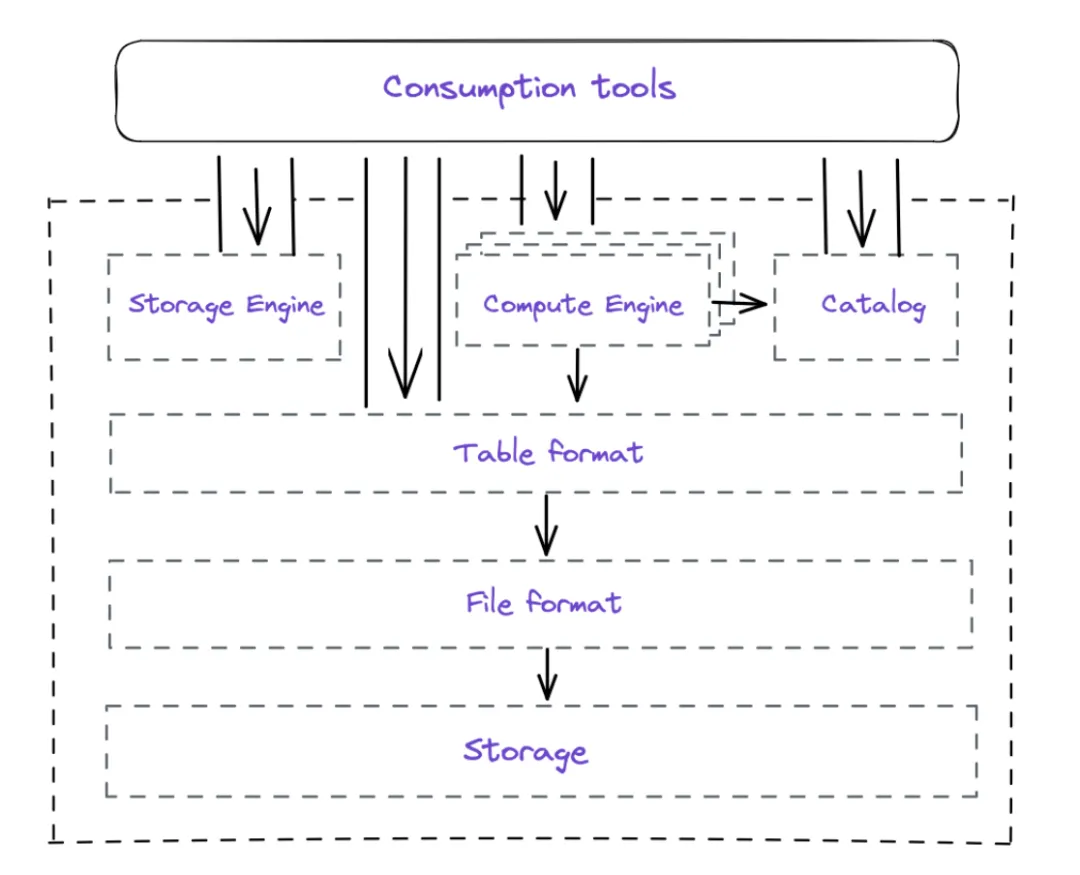
模块化的湖仓一体架构,核心模块包括以下几个方面:
-
数据存储(Data Storage):使用云对象存储来保存原始数据文件,需要能够高效地存储大量来自不同来源的数据。
-
存储引擎(Storage Engine):负责处理数据管理任务,如数据压缩、重分区和索引等。存储引擎通过优化数据的组织方式,提高查询性能,并确保数据在云对象存储中的高效存储。
-
文件格式(File Format):它将原始数据以特定的格式存储在对象存储中。数据湖仓使用开放的文件格式(如Apache Parquet、ORC等),这些格式具有高效的压缩和查询性能,并且可以被不同的分析引擎使用。
-
表格格式(Table Format):表格格式是数据湖仓的一个重要组件,它在数据湖上添加了逻辑模型和可靠的数据治理。表格格式简化了数据文件的组织和管理,并提供了元数据管理和数据版本控制的功能。常见的表格格式包括Apache Iceberg、Apache Hudi和Delta Lake等。
-
计算引擎(Compute Engine):计算引擎负责处理数据操作和计算任务,它与表格格式进行交互,实现数据的查询、转换和分析等功能。Lakehouse可以支持多种计算引擎,如Apache Spark、Presto等。
-
元数据服务(Catalog):用于管理数据湖中的表格信息和元数据,它跟踪每个表格的名称、模式和其他相关信息,提供了数据发现和搜索的功能。
模块化的设计让湖仓一体架构更加清晰和可解释,这个观点与Voltron Data(开源项目Apache Arrow背后的商业公司)提出的Composable Codex不谋而合。

Voltron Data联合Meta和Databricks发表在VLDB 23上的论文《The Composable Data Management System Manifesto》指出,不仅模块化是数据系统的正确发展方向,基于开放标准和开源模块构建的数据系统才是未来,可以带来很多好处:
-
提高灵活性和可扩展性:模块化的设计可以将数据计算引擎拆分为多个组件,使得每个组件可以独立开发、维护和优化。这样可以提高系统的灵活性和可扩展性,使得引擎可以适应不同的工作负载和需求。
-
促进互操作性:开放标准可以使不同的数据计算引擎之间实现互操作性,使得它们可以无缝地集成和协同工作。这样可以避免数据孤岛的问题,提高数据生态系统的整体效率和一致性。
-
降低开发和维护成本:模块化的设计和开放标准可以促进组件的重用和共享,减少重复开发的工作量。同时,开放标准可以吸引更多的开发者和厂商参与,形成一个庞大的社区,共同推动引擎的发展和优化,从而降低开发和维护的成本。
-
促进创新和进步:模块化的设计和开放标准可以为不同的开发者和厂商提供一个共同的平台,使他们可以自由地创新和实验新的功能和技术。这样可以推动数据计算引擎的不断进步,满足不断变化的需求和挑战。
开放式湖仓才是未来
传统数据仓库对用户最大的困扰是很容易被运营商锁定(Vendor Lock-in),通常有以下几个原因:
-
专有技术和格式:传统数据仓库通常使用特定厂商的专有技术和格式。这些技术和格式是特定厂商的商业机密,不公开或不兼容其他厂商的系统。因此,一旦选择了特定厂商的数据仓库解决方案,就会受到其技术和格式的限制,难以无缝地迁移到其他厂商的解决方案。另外,有一些开源项目使用了自有文件格式来存储数据,虽然源代码开源的,但其文件格式没办法被其他主流计算引擎理解,仍然不属于开放式的架构设计。
-
闭源软件:传统数据仓库通常使用闭源的商业软件,用户无法查看或修改其内部实现细节。这意味着用户对软件的定制和扩展能力受到限制,只能依赖于特定厂商提供的功能和更新。
-
依赖特定硬件和操作系统:传统数据仓库可能依赖于特定的硬件和操作系统。这意味着用户需要购买和维护特定的硬件设备,并且只能在特定的操作系统上运行数据仓库。这增加了用户的成本和依赖性,限制了他们在硬件和操作系统选择上的灵活性。
-
高度集成的架构:传统数据仓库通常采用高度集成的架构,将数据存储、计算和查询等功能紧密耦合在一起。这使得用户难以将数据仓库的不同组件替换为其他厂商的解决方案,因为这些组件之间存在复杂的依赖关系。
-
供应商锁定策略:一些数据仓库供应商可能采用锁定策略,通过限制用户的选择和迁移选项来维持其市场份额。这可能包括限制数据迁移工具、封闭的API接口、高昂的许可费用等。这使得用户难以切换到其他供应商的解决方案,从而导致供应商锁定。

湖仓一体架构发展到今天,其最吸引人的一个特点就是就是数据开放性,这是因为其独特的模块化设计带来的:
-
数据格式的灵活性:Lakehouse架构使用开放的数据格式,例如Parquet、Avro或ORC,这些格式是通用的、开放的标准。这意味着数据可以以一种独立于特定供应商的方式存储和处理,而不会受到特定供应商的限制。这样,即使更换或切换供应商,数据仍然可以保持可访问和可用。
-
开放的数据处理工具和技术:Lakehouse架构支持使用各种开放的数据处理工具和技术,例如Apache Spark、Apache Hive、Presto等。这些工具和技术是开源的,可以在不同的供应商之间进行迁移和切换。这样,即使更换供应商,组织可以继续使用相同的数据处理工具和技术,而不需要重新学习或更换整个技术栈。
-
数据所有权和控制:在Lakehouse架构中,数据湖是组织自己拥有和控制的。这意味着组织可以自由地管理和操作数据,而不受运营商的限制。即使切换供应商,组织仍然可以保持对数据的完全控制,并且可以根据需要进行数据迁移或复制。
-
多云和混合云支持:Lakehouse架构可以在多个云提供商之间进行部署,或者与本地数据中心进行混合部署。这种灵活性使得组织可以根据需求选择最适合的云提供商,而不会受到单一供应商的限制。这样,即使更换或切换云提供商,数据仍然可以保持可访问和可用。
值得一提的是,有些厂商声称自己是“开放式”湖仓一体架构,但所谓的“开放”实际是存算分离架构的“开放”,其实是与开放式湖仓一体混为一谈。存算分离是一种大数据处理架构,它将存储和计算节点分开,数据节点负责数据的存储和管理,而计算任务则由单独的计算节点来负责执行。相对于传统的存算一体架构,存算分离架构设计使得系统能够扩展到更大规模的并发能力和数据容量。相较于湖仓一体架构的开放数据设计,存算一体架构只是把数据放在了存储节点上,并没有保证数据的开放性(如使用开源表格式Apache Iceberg,或者开源文件格式Apache Parquet等),因此并不能认为存算分离架构也是开放的。
随着人工智能(AI)和大语言模型(LLM)的热潮,AI给数据平台带来新的挑战:AI需要更丰富的数据,数据需要更多样的BI+AI应用。Data与AI的关系不再是Data+AI,而是Data*AI ——数据平台不再是一对一的计算和存储架构,而是 m 对 n 关系的架构。这样的架构改变变化下,数据平台的架构更应有兼具一体化与开放性的设计。开放式湖仓一体架构,是面向Data+AI融合场景的新趋势。
云器开放式湖仓的设计理念
我们(云器科技)是一家新兴的数据平台服务提供商,主打多云及一体化的数据平台服务。我们依照Open Lakehouse的设计理念,实现了一套完整的系统,并服务多家头部客户。存储层设计兼容各种主流的开放存储格式,确保与广泛的数据环境的无缝集成:
-
开放元数据服务:采用Catalog形式开放,增强数据管理的灵活性和可访问性。
-
安全的数据访问:保障数据安全的同时,通过身份认证和鉴权机制,允许外部引擎访问云器Lakehouse中的数据文件。
-
统一安全策略与开放性结合:结合统一的安全策略与开放性,借助丰富的开源生态系统,最大化地释放企业数据的潜在价值。
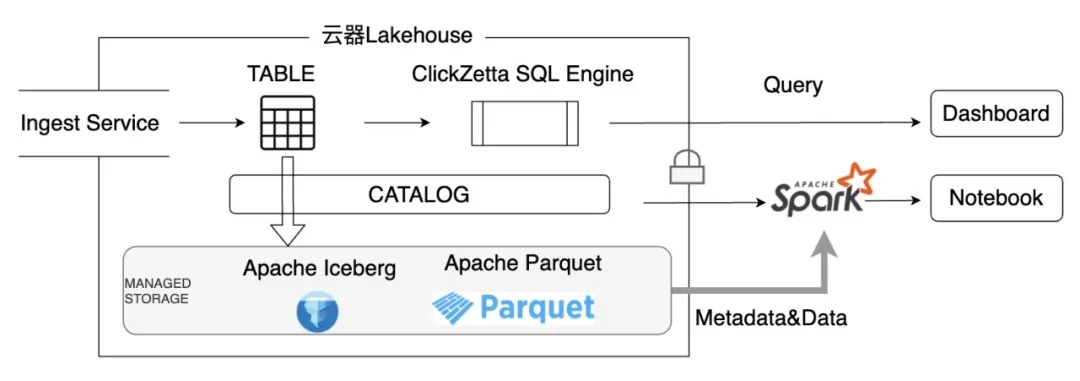
文章前半部分讲述了Open Lakehouse的架构优势、设计目标和原则。文章后半部分,重点介绍我们在实现过程中的设计、取舍和经验总结。
云器开放式湖仓的设计实践
拥抱 Apache Iceberg 打造开放生态

Apache Iceberg、Apache Hudi和Delta Lake是当前数据湖领域中的三种主要表格式,它们都在努力成为数据湖的标准表格式,这种竞争有时被形象地称为"Table Format War"。这三种表格式都是开源的,拥有非常好的生态,背后都有一个商业公司在支持。云器认为重复再造一个新的表格式的轮子并不能让Lakehouse更加地开放,因此选择一个最合适的表格式,围绕它构建Lakehouse的内置表格式,打造一个开放的生态是对用户最负责任的方案。
为什么是Apache Iceberg
来自Tabular(Apache Iceberg背后的商业公司)的Brian Olsen在2023年7月发表了一篇文章 Iceberg won the table format war,他认为Apache Iceberg已经在这场表格式的竞争中取得了胜利。其观点基本符合我们的看法,也是云器科技选择使用Apache Iceberg作为开放存储底座的原因:
-
从技术角度来说,Apache Iceberg是第一个跳出了Hive标准(比如Hive分区)限制的表格式,相对于Apache Hudi来说没有主键约束,通过Hidden Partition的设计支持Partition Evolution这种高级功能。这种设计使得使用方有更大的定制空间,支持更丰富的场景。
-
从标准角度来说,Apache Iceberg首先就制定了一套简单、清晰的标准,然后才提供各种引擎下的实现。Apache Hudi实现太过复杂,并且非常依赖JVM生态。Delta Lake开源版本相比Databricks内部版本有很多滞后性,与Apache Spark框架绑定也比较深。有了一个简洁的标准,用户和厂商既可以选择使用官方开源实现,也可以根据自己的需求开发一套完全兼容的实现,这正是一个开放的标准所带来的好处。
-
从生态角度来说,Dremio很早就选择了Apache Iceberg作为其完全开源的Open Lakehouse底座。像Snowflake这种起初期望用其私有格式抢占市场的大玩家,也支持了Apache Iceberg作为可选的内置存储格式,并且性能与内置格式相差无几。甚至像Databricks和Onehouse(Apache Hudi背后的商业公司)这样的直接竞争对手,也分别通过Delta Uniserval Format和Hudi OneTable的机制,输出Apache Iceberg兼容格式。选择Apache Iceberg能更好地避免被运营商绑定的风险,保护用户的数据。
如何基于Apache Iceberg构建通用的增量存储
云器Lakehouse使用Apache Iceberg表格式,以及Apache Parquet文件格式,打造了一个能够实时兼容Apache Iceberg标准的存储文件布局,其元数据通过完全兼容Iceberg的catalog进行输出,天然兼容所有支持消费Apache Iceberg的开源框架,如Apache Spark和Trino等。由于所有云器Lakehouse内表输出的数据文件都是以Apache Parquet格式存放在云对象存储上,元数据完全兼容Apache Iceberg,用户真正拥有自己的数据资产,无需担心Lock-in的风险。
前面提到过增量计算模式依赖增量存储,这也是通过Apache Iceberg实现的。具体来说,基于Snapshot Isolation使用Apache Iceberg V2标准引入的Position Delete File来表示增量数据。由于Position Delete File只能表示数据的删除,我们需要把Update拆分成经典的Delete+Insert模式,这样的设计对数据有三个挑战:
-
Freshness:代表数据进入Lakehouse的新鲜度,即数据写入湖仓之后多久可见。为了让数据尽快可见,我们设计了单独的Ingestion Service服务,根据不同的表类型,兼顾性能和成本使用最优的方式把数据灌入湖仓。
-
Latency:代表数据的查询性能,也就是查询湖仓中的数据要多久才能出结果。由于数据文件都保存在云对象存储上,我们设计了Shared-Everything的分层Cache服务,根据数据的冷热以及访问模式,自动将文件中的数据放到最合适的Cache中,加快查询速度。
-
Performance:增量计算的间隔越短,就会以增量存储的方式引入越多的小文件,这对后续查询的性能会带来影响。同时,用户的数据和访问模式后续都可能会动态变化,我们需要能够识别并给出存储文件排布的最佳方案。因此,写入增量存储的时候,我们可以根据需要,自动选择以Copy-on-Write或者Merge-on-Read的方式产生数据文件。同时,在后台使用单独的Compaction服务,根据Lakehouse搜集到的信息进行文件的重排布,以节省成本,优化查询性能。
围绕Apache Parquet锤炼极致性能
对于Lakehouse的引擎来说,一个SQL查询始于读(TableScan)终于写(TableSink)。如果说开放的表格式决定了Lakehouse的能力下限,那合适的文件格式则可以决定Lakehouse的性能上限。在大数据领域,Apache Parquet和Apache Orc基本就是列存格式的实施标准。两者曾一度各占半壁江山,但现在就像DuckDB作者Hannes回答社区问题时说的,似乎Apache Orc已经被用得越来越少了。那在Apache Parquet越来越独领风骚的今天,是不是无脑选择它就能高枕无忧了?
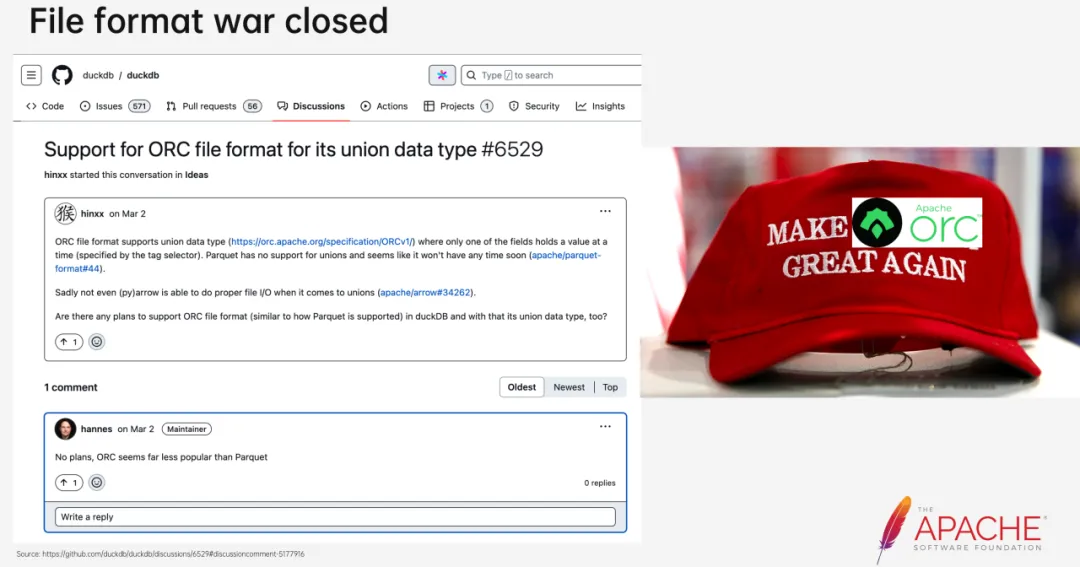
事实并非如此,Parquet标准其实是一个基于Thrift协议定义的文件格式,其中包含很多可选的字段,这为后面的问题埋下了伏笔:
-
由于早期Parquet开源代码的糟糕实现,各个引擎和框架都开始从头写自己的Parquet Reader/Writer,它们都根据自己的需要,只使用了Parquet标准中一部分字段,这对不同引擎之间Parquet文件的互操作性带来了问题,系统A因为用了某个更高级的字段,系统B没有实现它,导致B无法直接消费A产生的文件。
-
不同的Parquet实现有不同的bug,而用户持久化的文件无法重写,这进一步导致不同引擎需要打上各种补丁,从有问题的历史Parquet文件中读出正确的数据。
-
再就是臭名昭著的Parquet V2争论。Apache Parquet社区先是引入了一个Data Page V2的概念,用来支持对某一列的某个Page进行更细粒度的压缩和编码控制,这没有问题。但后续又引入了一个Feature V2的概念,把所有新加入的功能如Page Index、Bloom Filter、Delta Encoding、Byte Stream Split Encoding等,都称做V2功能。这样一来,有的实现认为Data Page V2才是V2,其他则认为只要用了某个V2功能也叫V2,导致对如何判断一个Parquet文件是不是V2版本没有一个共识。所以很多企业为了规避这个问题,直接禁用V2的任何功能。

尽管Parquet有各种各样的问题,它仍然是当前大数据文件格式的事实标准,在开放存储这个大前提下,也没有什么好纠结的。既然Parquet是开源的,是不是挑一个开源实现拿来用就好了?很多引擎和框架都实现了自己的Parquet读写模块,但由于前面提到的问题,要么功能不全,要么性能不佳,基本没有能直接拿来用。早在云器Lakehouse选型文件格式的时候(2022年初),C++的开源Parquet实现只有Apache Arrow、Apache Impala和DuckDB三家,其中后两者都只实现了V1的功能;而Apache Arrow中的Parquet C++代码是Parquet社区捐赠的,V2的功能也实现了一部分,但仍然缺少Predicate Pushdown、Page Index和Bloom Filter等重要功能,并且内部测评的性能也不及预期,无法直接使用。
Community Over Code
纵观国外的一些友商,Velox和Databricks开发了自己的Native C++ Parquet实现,而Snowflake、BigQuery和ClickHouse则都是基于Apache Arrow中的Parquet C++实现来完成Parquet的拼图。虽然从头开发一套Parquet实现的确能够获得最佳的定制和性能,但也需要付出大量重复劳动,也可能会掉进一些前人踩过的坑。既然Apache Parquet是一个开源的标准,没有任何秘密,而Apache Arrow已经被友商广泛使用,那直接基于Apache Arrow中的Parquet代码来实现云器Lakehouse的文件格式,也符合云器Lakehouse追求最佳开放性的设计理念。与此同时,云器科技也决定投入到社区当中,补全Parquet缺失的功能,并且深度优化性能,从而真正成为社区的一部分。
主要贡献
云器科技对Parquet社区的贡献,主要涉及了Apache软件基金会旗下两个顶级项目Apache Parquet和Apache Arrow的三个GitHub仓库:
-
apache/parquet-format:Parquet格式规范,所有的实现必须遵循此规范。参与该项目可以影响格式标准的后续发展,把对云器有益的格式演进推回社区,从而让更多用户受益。
-
apache/parquet-mr:Parquet的Java语言实现,是以Java生态为主的大数据开源生态圈依赖最广泛的Parquet实现。它也被认为是Parquet最权威的实现,其他语言的实现在拿不准的时候,都会参照它来统一行为。参与该社区,可以让云器Lakehouse写出的Parquet文件,能被所有Java生态的开源框架(如Apache Spark、Apache Hive、Trino)直接消费,达到最大的开放性。
-
apache/arrow:Apache Arrow项目的核心是一种基于内存的列式数据结构,这是一种与语言无关的标准化规范,使得数据可以在不同的编程语言和计算引擎之间以零复制(zero-copy)的方式进行共享和交换,同时提供了一套比较干净和功能最多的Parquet C++实现。云器Lakehouse的Parquet正是基于这套代码进行功能开发和性能优化,使其达到一个比较理想的状态。

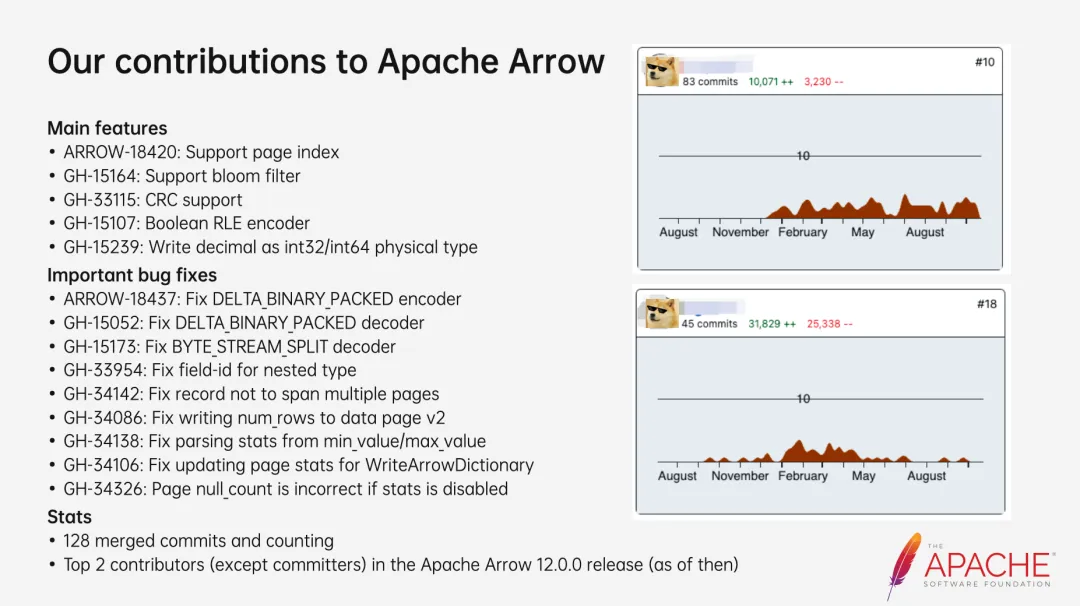
上面两张图基本涵盖了云器科技在Parquet社区中最主要的贡献,团队两名成员也因此被Apache Parquet和Apache Arrow社区提名为Committer。云器科技对开源社区的投入不会停止,团队成员在2023年8月北京举行的「Apache Software Foundation旗下大会 - Community Over Code Asia 2023」上分享了参与开源项目的心得,后续仍会深耕社区,把我们认为有价值的功能贡献回社区,让更多的用户受益。
总结
本文回顾和分析了数据湖仓的历史和大数据平台的演进趋势,提出了基于增量计算的一体化趋势,以及该架构必然需要一个开放式的增量存储支撑。基于Single Engine · All Data理念云器发布了一体化数据平台——云器Lakehouse,并分享了如何围绕Apache Iceberg和Apache Parquet,来构建开放湖仓之上的增量存储,获得最佳开放性和极致性能。同时云器科技也大力投入开源社区,以合作共赢的姿态践行构建Open Lakehouse的设计理念。

