👨🏻💻 作者背景: 吴刚,Apache Parquet/Arrow/ORC PMC member,Iceberg committer,iceberg-cpp项目发起人和核心维护者
2026 年 4 月,Iceberg Summit 在旧金山马奎斯万豪酒店举行,现场氛围比去年更加热烈。如果说 2025 年的焦点是消化 v3 的新能力(如 Variant 类型、删除向量、行级血缘),那么今年则是 Iceberg 真正的爆发之年。作为 Iceberg 历史上首次连续两天的线下盛会,本次峰会展现了硬核的议程和肉眼可见的生态繁荣:
- 规模破纪录:参会人数从去年的 500 人激增至 700+。在垂直技术峰会中,这种规模增长非常罕见。
- 赞助商结构变化:除了 Google、Microsoft、Snowflake 等传统巨头,赞助商墙上出现了 Vakamo、Tower 等专注于 Iceberg 管理与 AI 接入的新兴公司。这表明 Iceberg 的商业闭环已从“基础组件”迈向“精细化运营”。
- 议程聚焦 V4:会议议程几乎被技术细节填满。v4 版本核心的自适应元数据树、列级更新,以及针对 GPU 算力优化的存储结构等,是现场最热门的讨论话题。
今年,我的身份也有了新的变化。作为新晋 Iceberg Committer 以及 iceberg-cpp 项目的发起人,我不再是台下的观众,而是站到了社区讨论的最前沿,与社区伙伴面对面推敲 Spec 细节。在会上,我分享了关于 C++ 原生实现路径的演讲(题为 Unleashing Native Performance: The Architecture and Roadmap of Apache Iceberg-cpp),展示了云器科技在开放存储领域的深耕与对极致性能的追求。Talk 的详细技术复盘,我会在后续文章中展开。
现在,让我们回到那个火热的会场,重点看看在 v4 时代,Iceberg 是如何通过自我革新,在 AI 浪潮中站稳脚跟的。
大会亮点
去年的 Summit 仍在关注 v3 的新能力,而今年 Keynote 则告别了 Iceberg 发起人 Ryan Blue 的“独角戏”。大会采用了双 Keynote 形式,由 Russell Spitzer 和 Julien Le Dem 这两位社区核心人物主讲,他们分别从表格式协议和物理存储格式两个维度,深入分析了在流式处理和 AI 负载重压下,数据湖底座如何演进。
Day One:Russell Spitzer — 拥抱 Streaming 与 AI 的 v4 蓝图
Russell Spitzer (Snowflake Principal Software Engineer,同时也是 Iceberg PMC 的核心成员之一) 在 Keynote 中直指 Iceberg 在高频流式场景下的核心痛点,并明确了 v4 的目标:为 Streaming 和 AI 提供原生的支撑与增强。
围绕 Streaming Commit 的架构重写
在 Russell 看来,高频流式提交的痛点在于元数据膨胀和提交延迟。Iceberg v4 彻底重构了元数据架构,引入支持单文件提交(Single File Commit)的自适应元数据树(Adaptive Metadata Tree)。V4 用 Root Manifest 取代 Manifest List,允许直接在根节点引用数据文件,并利用 Manifest Delete Vector 实现“软删除”。这种设计将小型写入的元数据开销压缩至单次文件提交,解决了流式场景下元数据写入放大的问题,使 Iceberg 具备实时数据摄入能力。
从 Row Update 到 Column Update 的范式转移
这是 v4 针对 AI 和大宽表场景的重大优化。
- 范式演进:Iceberg v3 基于删除向量(Delete Vector)实现了行级更新(Row-level Updates),但本质上仍是“整行缝合”。
- 列级精度:在 AI 特征工程中,宽表常有数千个特征,但更新操作可能仅涉及其中几个。v4 的 Column Update 实现了从“更新行”到“更新列”的转变——它仅重写受影响的列文件,并在读时进行列级合并。这种细粒度的操作显著降低了写入放大,是 PB 级 AI 数据治理的关键步骤。
V4 蓝图下的其他关键增强
除了上述的 Streaming Commit 和 Column Update,V4 蓝图还涵盖了多项重要的底层能力建设,它们共同构成了 Iceberg 在企业级应用和 AI 场景下的基石:
- 二级索引框架:Iceberg 正在构建一套通用的二级索引框架,旨在支持更多高级索引类型(如向量数据的 IVF 索引、DiskANN 索引)。其中,核心的主键索引提案将通过建立 Key 到物理位置的映射,加速点查、消除 Flink CDC 的等值删除,并优化 Spark 的 MERGE INTO 操作。
- SQL UDF 规范 :为了解决跨引擎互操作性和数据治理问题,社区正在标准化 SQL UDF/UDTF 的元数据格式。这确保了用户自定义函数,尤其是在细粒度访问控制(如列掩码)策略中,能够在不同计算引擎中保持一致性。
- 物化视图规范 :MV 规范定义了物化视图的元数据格式,将其视为一个逻辑视图和底层 Iceberg 存储表的组合。这项工作使得 MV 能够跨引擎管理,并能进行精确的新鲜度评估。
- 相对路径支持:Iceberg V4 正在实现对元数据和数据文件相对路径的支持。这一功能消除了在表移动(如灾难恢复、跨云迁移)时必须重写所有绝对 URI 的运营负担,实现了“零重写搬迁”。
值得一提的是,Russell 着重强调了 Iceberg 生态的重要性。他指出,随着 Iceberg 迈入 V4 时代,跨语言支持成为核心竞争力,而 iceberg-cpp 作为原生 C++ 实现的新成员,正是构建这一繁荣生态的关键组成部分。

Day Two:Julien Le Dem — 软硬协同下的存储“硬核”博弈
第二天的 Keynote 由 Julien Le Dem 接棒。他是 Parquet 和 Arrow 的联合创始人、Iceberg PMC 成员,现任 Datadog Principal Engineer。作为物理存储格式的奠基人,他的核心逻辑非常直接:当计算环境向 GPU、100G 网络以及 NVMe 等新硬件迁移时,存储层必须通过“硬核重构”来释放这些硬件的全部红利。

AI 负载倒逼格式进化
AI 场景带来了数千列的“超宽表”、极高并发的点查、对向量数据的极致检索需求,以及爆炸增长的多模态数据的存储和读写需求。Julien 坦言,面对 Vortex、Lance 等新兴格式在局部场景下的冲击,传统格式必须主动求变。
存储层的“武器库”更新
- 编码革命:通过引入 FSST(字符串编码) 和 ALP(浮点数编码),在保持高压缩比的同时,支持在不解压的情况下直接进行谓词下推,显著提升了扫描吞吐。
- 元数据瘦身:为了解决 Parquet Footer 过大导致的加载延迟,社区正在尝试将元数据从 Thrift 迁移到 Flatbuffers,以实现更快的随机访问。
- 向量原生化:引入 Vector 类型 并与 Iceberg 的 Index 框架深度集成,确保在 RAG(检索增强生成)等场景下,底层存储能提供原生的列式支持。
对开放生态底座的信心

在 Keynote 的最后,Julien Le Dem 总结了他对整个开放数据生态底座的信心。他认为,虽然新的挑战者(如 Vortex、Lance)不断涌现,且 Parquet 需要持续进化以应对 AI 时代的超宽表和高并发点查,但 Parquet、Arrow 和 Iceberg 这三者的根基是极其稳固。这种稳固性不仅体现在它们作为行业标准被广泛采用,更体现在社区致力于跨引擎、跨语言的兼容性与互操作性。Julien 的观点是,这些底层协议和格式已经奠定了开放湖仓的基础,未来的工作将是利用这些坚实的基础,通过协议的微调和存储的“硬核”优化,来持续释放新硬件和新场景的全部性能潜力。
有趣的 Session
尽管 Keynote 已经描绘了 v4 版本的宏大蓝图,但许多 v4 核心功能(如索引框架、UDF、物化视图、相对路径等)在社区中已经有了详细的设计文档和 PR 讨论。因此,我选择跳过这些规范层面的 Session,转而参加那些探讨有意思的真实场景和新鲜讨论的分论坛。以下将重点介绍三场令人印象深刻的讨论:
Firebolt:当“Big Metadata”哲学撞上万亿行挑战
- 演讲标题: What Breaks at Trillion Rows: Eliminating Iceberg Bottlenecks in Firebolt
- 作者简介: Mosha Pasumansky(Firebolt CTO),Google BigQuery 奠基人之一,亦是经典论文 《Big Metadata: When Metadata is Big Data》 的核心作者
Mosha 的这场分享以 Clickstream 这一真实超大表场景为例,直接把讨论带到了“万亿行”这一极限规模。他指出,当数据规模从 PB 级向 EB 级跨越时,Iceberg 原有的元数据管理机制会由于 Manifest List 的线性膨胀而产生严重的 Planning 瓶颈。
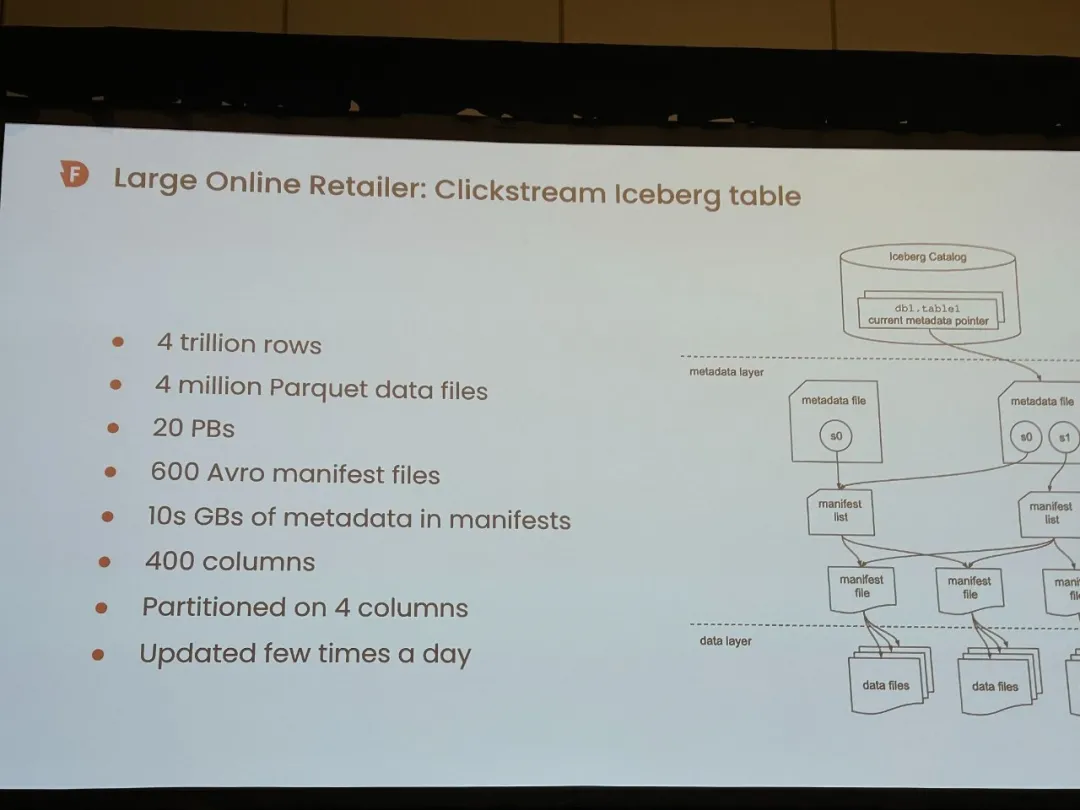
Mosha 的核心思路是将元数据视为“分布式查询”的对象。Firebolt 通过并行化读取 Manifest 并利用预聚合的统计信息(如 Row Count 和 Min/Max),在 Planning 阶段就消灭了不必要的 IO 往返。此外,他分享了 Firebolt 如何利用 Cache Snapshot 机制,在允许秒级 Staleness 的前提下,实现了万亿行表的亚秒级响应。这实际上为 Iceberg v4 正在推进的自适应元数据树(Adaptive Metadata Tree)提供了一个成熟的工程样板。
DuckDB:兼容性测试里的“血泪史”
- 演讲标题: Building DuckDB-Iceberg: Exploring the Iceberg Ecosystem
- 作者简介: Tom Ebergen(DuckDB Labs 核心工程师),专注于 DuckDB 与外部数据生态的无缝连接
这场演讲的名字听起来温和,内容却是实打实的“排雷指南”。Tom 展示了 DuckDB-Iceberg 插件在适配各大云厂商和计算引擎(Spark, Trino, Snowflake)时,撞上的大量 Spec 定义与实际实现“不对齐”的荒诞 Case:
- 元数据语义漂移:在处理 Avro 元数据时,字段的 nullable 定义在不同引擎中实现各异,导致跨引擎读写时频繁崩溃。
- 协议实现的小动作:REST Catalog 的 config endpoint 存在实现不一致性,部分实现对命名空间前缀(prefix)进行了 URL Encode,而另一些则没有,导致行为不一致。
- “大家一起错”的悖论:Spec 明确规定 Transform Date 应返回 Integer,但不少实现直接“参考”了 Iceberg Java 的实现返回了 Date 对象。这种“群体性违规”导致单个环境下跑得通,一旦 DuckDB 这种追求严格兼容的第三方接入,成本就会指数级上升。
- 报错行为不一致:不同引擎对于不支持的功能的报错行为不一致。例如,有的引擎在 Iceberg V2 版本中使用 V3 数据类型时居然不报错,而 Snowflake 在这种情况下会返回一个完全不知所云的错误码。
尽管 Iceberg 协议在设计上雄心勃勃,意图构建一个开放、兼容的生态,但 Tom 的分享揭示了将规范落地为可互操作的实现并非坦途。这些实战经验警示我们,协议的开放性带来了生态的繁荣,但也对像 iceberg-cpp 这样的原生实现提出了更高的挑战:必须以最严谨的态度,确保每一个细节都与 Spec 严格对齐,以避免重蹈覆辙,成为社区互操作性测试中的新痛点。
Vortex:从“被动存储”到“主动驱动”
- 演讲标题: From Drift to Drive: Slicing Through Data with Iceberg and Vortex
- 作者简介: Will Manning(Vortex TSC Chair & SpiralDB CEO),其创立的 Vortex 项目已正式加入 Linux 基金会,主打高性能 AI 存储

在这个演讲中,Vortex 的作者 Will Manning 带来的不仅是性能数据,还有对 Parquet 十年未曾进化的“宣战”。作为一款基于 Rust 原生实现、被设计为“文件格式领域的 LLVM”的新型格式,Vortex 的核心目标是成为在性能上全面超越 Parquet 和 Lance 的 SOTA 格式。
Vortex 利用 Rust 的极致性能与安全性,结合 GPU SIMT 和 CPU SIMD 释放现代硬件红利。这种设计在 AI 负载所需的随机访问场景中带来了颠覆性提升,声称比 Parquet 快 100-200 倍。此外,Vortex 采用 FlatBuffers 序列化元数据,实现了对超宽表的 O(1) 零拷贝访问,并最大限度减少了在 S3 等对象存储上的高延迟 I/O 往返。其轻量级、向量化的级联编码架构(如 FastLanes、ALP)允许计算引擎直接在压缩数据上执行计算,改变了 Parquet “读取 -> 解压 -> 计算”的传统范式。为了解决开源生态系统停滞问题,Vortex 还创新性地提出了嵌入式 WASM 解码器,确保格式能持续吸收最新技术而不破坏向后兼容性。
在会后的线下交流中,Will 向我透露了他更大的“野心”:他希望将 Vortex 推入 Iceberg 标准,甚至在未来逐步淘汰并替代现有的其他格式。他打趣道,由于 Vortex 极具攻击性的进化姿态,他觉得自己每次参加 Parquet 社区会议时都像是个“不受欢迎的贼”,试图从传统堡垒中夺取阵地。此外,我们也深入讨论了未来的合作空间,特别是在 C++/Rust 原生实现路径上的协同可能性。
行业洞察
最后,在深入探讨了代码与规范的微观世界之后,让我们跳出技术细节,聊聊我在旧金山这几天的所见所闻。通过会场茶歇、私下交流以及最后的“巨头对谈”,可以观察到一些正在重塑行业格局的深刻洞察。
巨头转身:从“防守”到“全速入场”

在峰会的一场圆桌会议上,美国三大云厂商的高管——AWS、Google Cloud和 Microsoft——罕见地齐聚一堂,和和气气地共同鼓吹 Iceberg Spec 和 REST Catalog Spec 的开放性。这种“其乐融融”的背后,本质上是利益的高度一致。
在私下交流中,我得到了一些更具冲击力的信息:Snowflake 和 BigQuery 上的 Iceberg Table 用户增长速度远超预期。 甚至在 Databricks 内部,其 Table Format 层的很多最新创新也开始显现出“Iceberg 优先”的迹象。这标志着 Iceberg 已经彻底跨越了“好用的工具”阶段,成为了云厂商公认的、能一起赚大钱的底层底座。当巨头们不再试图用私有格式锁死用户,而是竞相在 REST Catalog 上比拼服务能力时,用户真正的“数据自由”才算真正开启。
生态的毛细血管:繁荣且多元的商业闭环
今年赞助商阵营的豪华程度令人印象深刻。除了 AWS、Google Cloud、Microsoft、Snowflake、Databricks 和 Dremio 等主要云厂商悉数到场外,大量专注于垂直领域的初创公司也通过 Iceberg 找到了自己的商业生态位。这种“巨头引领、群雄并起”的局面,证明了 Iceberg 生态不仅在基础设施层面足够稳固,更在应用层展现出极强的盈利潜力和生命力。其中,有几家初创公司赞助商让人眼前一亮。
- Vakamo:依托于其幕后的 Lakekeeper(Rust 开发的原生 Catalog),它们正在定义一种“Catalog 驱动治理”的新模式,将复杂的元数据维护收敛到 Catalog 层。
- Etleap:在写入路径上玩出了花样。他们利用 双 Branch + Equality Delete 的 WAP(Write-Audit-Publish)模式,精准解决了实时摄入时的读放大与可见性矛盾。
- Ryft:把“冷板凳”坐穿,专注于超宽表在 AI 负载下的 Compaction 效率,这种精细化手术式的维护是目前大厂最缺乏的。
- Tower:由 Snowflake 前员工创立,极其敏锐地抓住了 Python 生态,通过底层集成 Polars 和 DuckDB,让 AI 开发者能用最熟悉的 API 享受到极致的 Iceberg 访问速度。
这些公司的共同繁荣传递了一个信号:在 Iceberg 的大树下,大家都能找到属于自己的垂直金矿。这种“共赢”的氛围,才是 Iceberg 能够持续碾压竞争对手的杀手锏。
与先行者的私房话:克制下的求变

在会场,我与 Parquet 和 Iceberg PMC 成员的 Ryan Blue、Daniel Weeks 和 Julien Le Dem 等社区资深人士进行了多场深度对谈。大家一致认为:面对层出不穷的挑战者,Iceberg 和 Parquet 必须主动求变,以格式标准扩圈和实现深度优化双线并行的战略与时俱进。我们深入讨论了 Parquet 格式在某些方面暂时落后于挑战者的现象,并一致认为这并非不可逆转。Parquet 和 Iceberg 拥有海量的客户和历史数据,在推进标准时必须平衡多方利益,因此步伐相对克制。但我们都坚信,一旦格式标准跟上并完成对应的实现优化,它与当前火热的挑战者将不会有任何本质差异。Ryan 强调了 Iceberg 进化的克制哲学,即不会为短期性能而急功近利地破坏标准的优雅与稳定性。Daniel 则对 Iceberg 在中国和亚洲的市场表现表示极大的兴趣,并对 iceberg-cpp 等原生实现路径寄予厚望,认为它是 Iceberg 进军高性能计算和亚洲市场的关键钥匙。最终,我们的结论高度一致:Iceberg 和 Parquet 凭借深厚的社区根基、严谨的取舍哲学和主动求变的创新文化,最终仍将保持行业先进性。
AI 时代的“生化”探索:共建未知
站在 2026 年这个节点,弥漫在会场中的最强烈的感受,是大家对 AI 带来的“未知机会”所表现出的兴奋。尽管当前的 AI 技术仍有不足和挑战,但参会者普遍认为它已经实实在在地改变了自己的工作方式,且极度期待 AI 能加持他们做出更多有开创性的工作成果。
我们已经走出了“存储数据”的时代,正在进入“存储智能”的时代。无论是向量检索的集成,还是列级更新对特征工程的优化,这些都是前所未有的挑战。作为一个社区的领导者,我深感这个领域的发展需要我们与用户、与其他开源社区一起去探索。
云器科技也将在这场 AI 与 Data 的“生化反应”中,继续扮演核心贡献者的角色。我们不仅在写代码,更是在与全球最顶尖的头脑一起,探索定义下一个十年的数据基础设施。
结语
旧金山的阳光依然耀眼,而开放湖仓的下半场,才刚刚开启。正如我们在会场反复讨论的那样:协议和实现必须两条腿走路。Iceberg Summit 2026 让我们看到了一个充满生命力的生态。而对于开发者来说,最幸福的事莫过于:你不仅见证了历史,你还在亲自书写它。
🎁 新用户专享福利
✅ 1 TB 存储 · 1 CRU时/天计算 · 1 年全托管体验
➤ 即刻访问云器官网领取:https://www.yunqi.tech/product/one-year-package

