现有数据平台原地加速,不迁移
无需迁移数据、元数据和任务,以插件化方式嵌入现有 Hadoop / 湖仓架构——Spark 离线作业降本 50%+,即席查询提速 3 倍以上,业务全程零停机。
中大型企业的 Hadoop/湖仓架构在业务高速增长下,面临三重困境

现有平台支撑核心生产业务,大规模数据迁移意味着停机风险、元数据断裂、上下游任务全面改写——每一项都是高代价决策。

随着数据量飙升,Spark 计算成本直线上涨,Presto/Trino 查询延迟加剧,ClickHouse 并发瓶颈显现——性能已成增长阻力。

Spark + Presto + Flink + ClickHouse 各自为政,格式、元数据、调度无法统一,运维团队疲于奔命,一个故障牵连全链路。
云器 Lakehouse 以嵌入式方式接入现有平台,实现四大核心价值
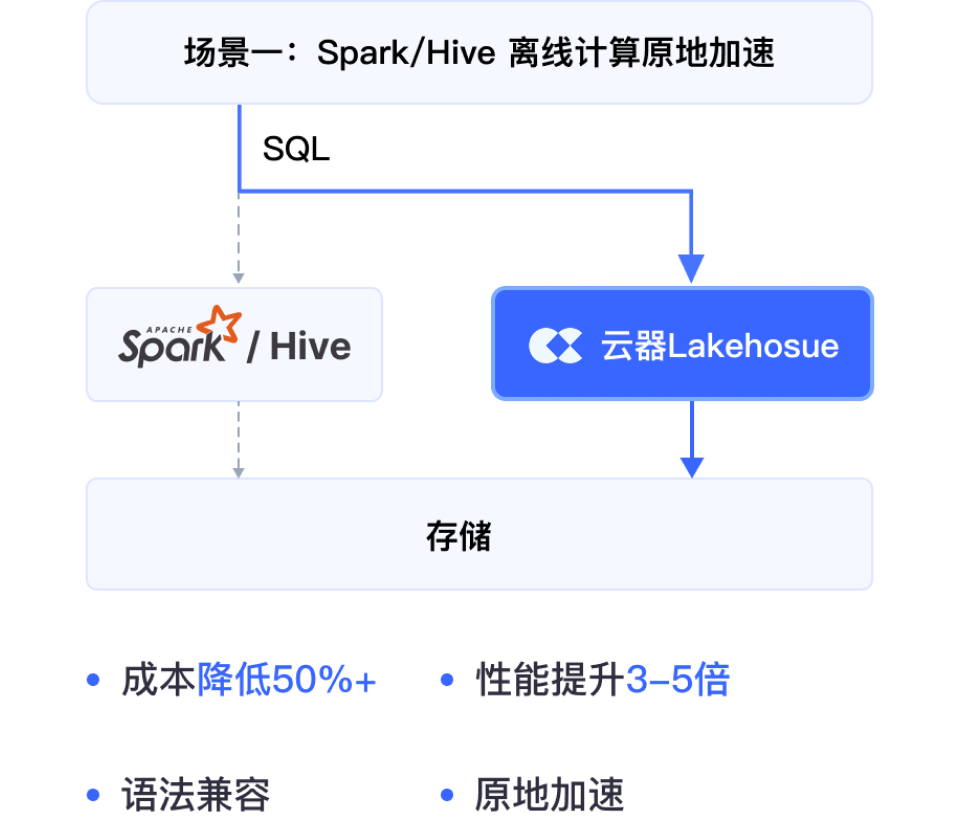
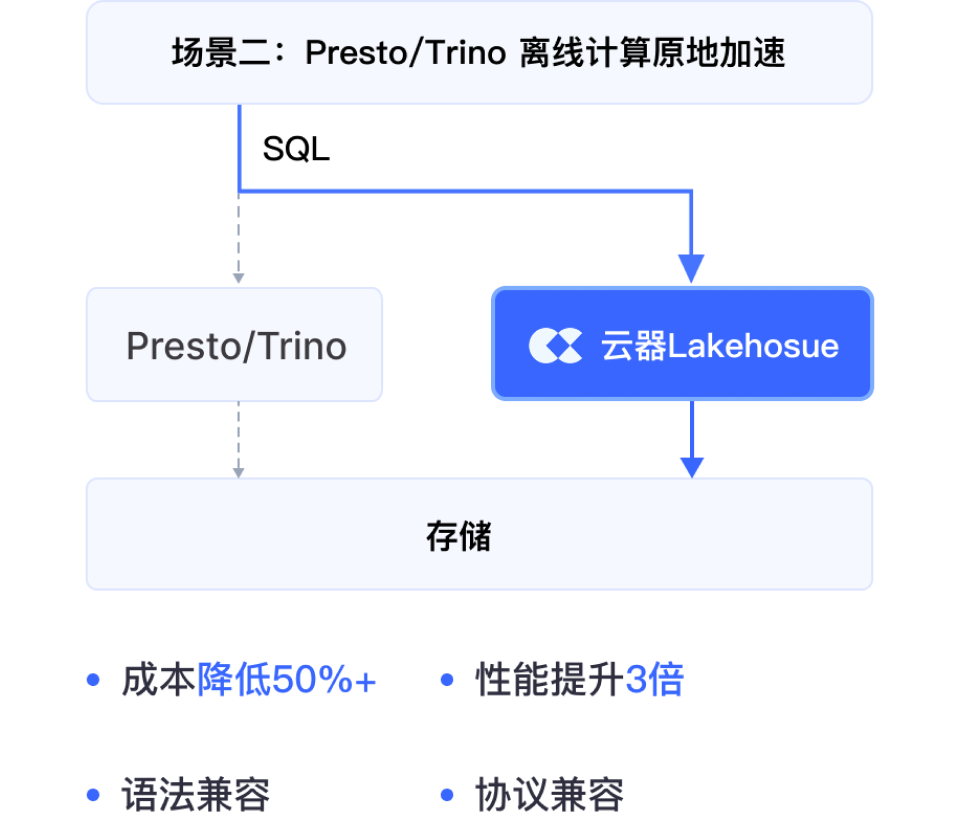
Spark 离线场景作业直接降本 50% 以上;Presto/Trino 外表查询加速 3 倍,导入内表后通过向量化引擎提速 6–10 倍。
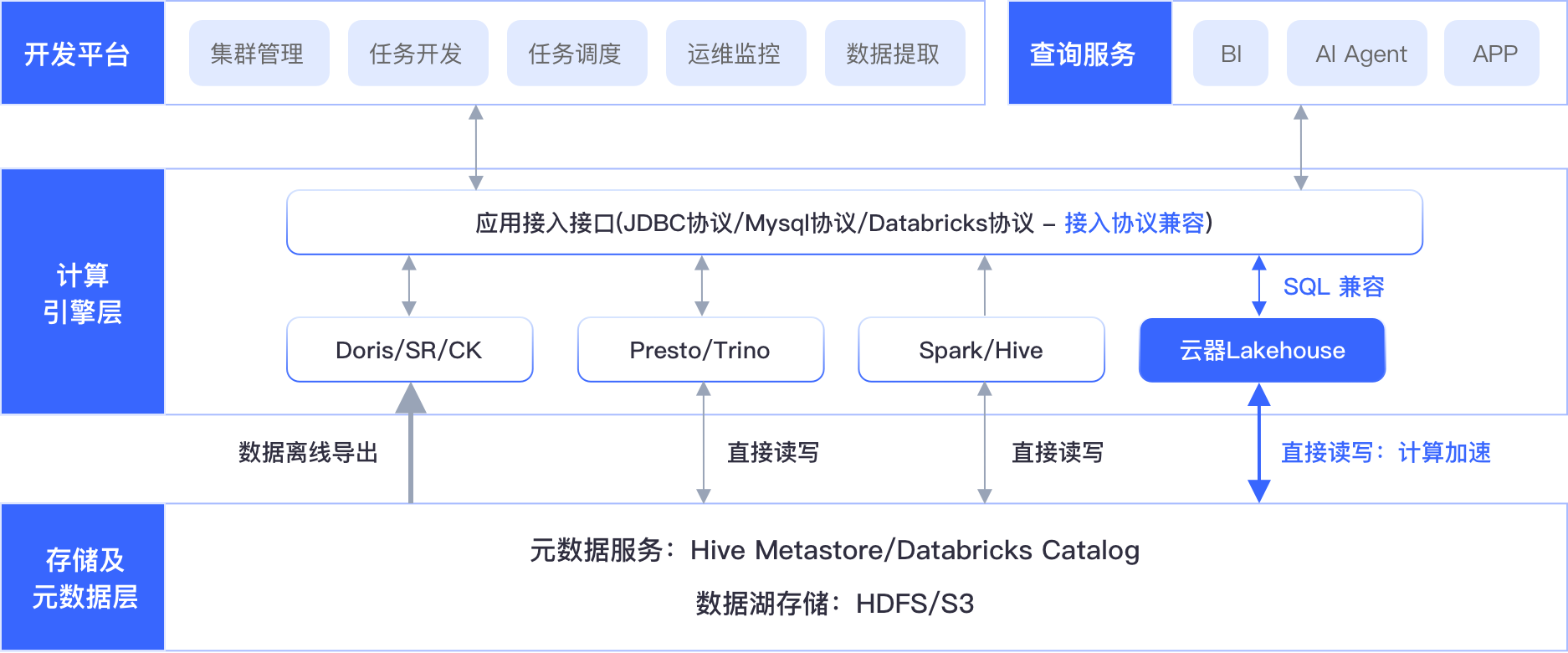
完整支持 HDFS/S3/OSS/COS/GCS;兼容 Hive、Iceberg、Delta、Hudi、Paimon 全部主流表格式;无缝对接 HMS/Catalog 及 JDBC/MySQL 协议。
一套云器 Lakehouse 架构同时支持离线 ETL、近实时加工、实时分析、Ad-hoc 查询、高并发检索——彻底消除"烟囱式"架构复杂性。
对现有系统"零入侵",无需推倒重来。数据不搬、元数据不动、任务不搬,快速 POC 验证效果,最大化保护既有 IT 投资。
不再为数据迁移付出沉重代价——直接在原地加速
历史数据搬迁涉及 PB 级规模,任何错误都是灾难性的
Hive/Iceberg 表结构需要重新梳理,血缘关系从零恢复
数百乃至数千条 SQL 任务逐条适配,不确定性极大
过渡期两套系统同时维护,成本高、风险多
需要大量资源才能证明价值,ROI 周期漫长
直接挂载现有 HDFS/S3 存储,数据一行不搬
HMS/Databricks Catalog 全兼容,历史血缘完整保留
Spark SQL、Hive-SQL、GP-SQL 兼容度 95%+
通过 SDK/OpenAPI 接入,存量任务可逐步切换
最小化风险,最大化信心,ROI 从第一个任务就可计算
嵌入式架构的核心承诺——每一项都经过生产验证


根据你的现有架构选择起步场景,按需逐步扩展
SQL 完整兼容,Spark SQL / Hive-SQL 无需改写
上下游零改动,调度系统、开发平台照常运行
向量化引擎加速,计算成本直接降低 50%+
存储兼容,支持 HDFS/S3/COS,Hive/Iceberg 表格式直接读写
协议兼容,JDBC / MySQL 协议兼容,无需改动查询工具
性能提升,外表直接查询,性能提升 3 倍以上,或降本 50%
数据零迁移,数据无需挪动,Hive/Iceberg 外表直接查询
内表加速,导入内表后向量化加速 6–10 倍(一条 SQL 完成)
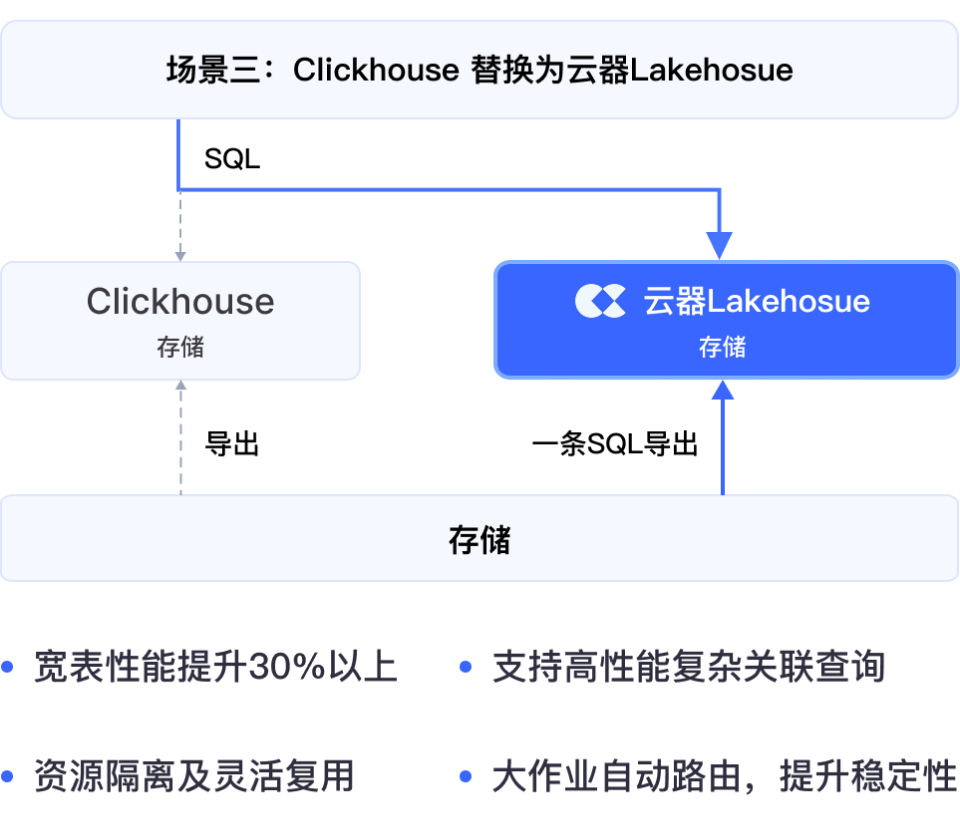
资源管理,更好的资源管理,资源隔离及灵活复用,大作业自动路由
性能超越,宽表查询 + 多表关联查询性能全面超越 ClickHouse
SQL 兼容,SQL 完整兼容,BI 工具无需改造
单引擎覆盖,单引擎同时处理 BI + ETL + 实时,彻底告别烟囱架构
三个真实客户从接入到上线的完整历程

火花思维的数据平台基于腾讯云 Spark + HMS + COS 对象存储构建。通过 Python SDK 将开发平台对接至云器 Lakehouse,利用外表读写实现 ETL 原地加速。Spark SQL 全程兼容,上下游任务无需任何改动,最终实现生产任务性能 3–10 倍提升,计算资源降本 60% 以上。

高途教育基于云器Lakehouse的湖上原地加速方案,通过Presto/Spark湖上计算加速实现P90查询性能提升5倍,同时借助增量计算以一半的成本将数据新鲜度从1小时提升至5分钟。

NinjaVan 从谷歌云(Spark + Presto + GCS)迁移至华为云,通过云器 Zettapark + sql-glot 工具实现 Spark SQL 兼容,代码改动不足 1%。开发调度系统从 Airflow 迁移至云器 Studio,BI 工具直连云器,最终实现 ETL 性能 6 倍提升,BI 报表性能 2–10 倍提升,SLA 达到 99.9%。
