导读
近期,云器 Lakehouse 带来了一系列令人兴奋的更新。从 SQL 性能的大幅提升,到 AI 能力的全面增强,再到生态集成的重大突破——每一项更新都期望让您的数据工作变得更轻松、更高效。
更新亮点速览
性能与成本优化
- Dynamic Table 按分区刷新功能全面开放,支持存量离线ETL任务快速切换为近实时增量计算,低成本提升数据时效性;
- 全面支持 BITMAP 数据类型,UV 统计和用户画像性能显著提升。
AI 能力增强
- 原生支持 VECTOR 数据类型,实现毫秒级向量检索,为 RAG 应用提供基础设施;
- 多模态混合检索,文本、向量数据统一处理,无需维护多套系统;
- 倒排索引支持 multi-match 查询和 BM25 算法参数调优;
- MCP Server 工具扩充至 63 个。
生态开放
- 提供标准 Iceberg REST Catalog 服务,外部引擎可直接访问 Lakehouse 数据;
- 支持访问 Snowflake OpenCatalog,实现跨云数据联邦查询;
- 打通 Databricks Unity Catalog,无需迁移即可读写数据。
体验优化
- 长时作业自动路由,保障核心业务 SLA;
- PIPE 导入任务可视化管理;
- BYOS 自助配置流程上线。
详细功能介绍
本文选取了近期更新的部分内容进行介绍。如果期望查阅完整更新内容和更多细节,请前往云器官网yunqi.tech了解更多或者在产品内直接体验使用!
SQL 相关更新
增量计算能力增强:
1、Dynamic Table(动态表)支持按分区刷新正式开放 ,您可以按数据分区(例如,某个特定区域、某一天或某个业务线的数据)为对象进行独立的增量计算刷新,更好地实现大规模数据处理场景下的任务运维(包括计算逻辑调整、补数、异常修正等)效率。同时,借助动态表的按分区刷新能力,存量的基于分区调度的周期性离线任务可以最小化改造切换为增量计算任务。这意味着计算资源消耗大幅降低,为您节省可观的成本,同时数据更新速度得到数倍乃至数十倍的提升。
参考链接:https://yunqi.tech/documents/dynamicTable-parmaters
**2、**现已全面支持 BITMAP 数据类型。这使得在进行大规模数据集的精确去重计算(如 UV 统计)和用户画像分析(如人群圈选)时,能够获得显著的性能提升和存储优化。 参考链接:https://www.yunqi.tech/documents/bitmap-type
3、新增内置函数
-
trans_array: 用于高效处理嵌套数组,可替代 split + explode 的复杂操作,简化数据处理逻辑。
参考链接:https://www.yunqi.tech/documents/sql_functions/scalar_functions/nested_functions/trans_array
-
regexp_instr: 新增正则表达式匹配函数,用于查找模式在字符串中出现的位置,与 Spark 兼容。
参考链接:https://www.yunqi.tech/documents/sql_functions/scalar_functions/string_functions/regexp_instr
-
regexp_count: 新增正则表达式计数函数,用于计算模式在字符串中出现的次数。
参考链接:https://www.yunqi.tech/documents/sql_functions/scalar_functions/string_functions/regexp_count
4、语法及 DDL/DML 增强
-
QUALIFY : 用于在 SELECT 语句中对窗口函数的结果进行过滤。
-
函数扩展: EXTRACT 函数现已支持 QUARTER(季度)时间部分,可以更方便地按季度进行日期和时间分析。
AI 功能更新
1、【邀测】Semantic View : 正式推出了“语义视图(Semantic View)”的创建功能。Semantic View 旨在将底层复杂的物理数据模型,通过业务人员易于理解的维度、指标等语义化概念进行封装。该功能目前属于邀测阶段,如需体验请通过云器官网(yunqi.tech)联系我们 。
2、Lakehouse MCP Server 增强 : 为了提升 AI 相关功能的开发与调试效率,我们对本地 MCP Server 工具数量扩充至 63 个。让用户在使用 MCP 客户端连接 Lakehouse 时,更高效、全面地与 Lakehouse 进行交互和管理。
参考链接:https://yunqi.tech/documents/LakehouseMCPServer_intro
3、Lakehouse 向量检索能力实现飞跃:原生支持 VECTOR 类型,赋能 AI 应用 : Lakehouse 原生支持 VECTOR 数据类型,基于此原生支持,您可以在 Lakehouse 的海量数据中实现毫秒级响应的相似性搜索。这为构建下一代 AI 应用,如基于 RAG(检索增强生成)的增强知识库、企业智能问答系统、以及更懂用户意图的语义搜索引擎,提供了坚实、高性能且统一的基础设施支持。
参考链接:https://www.yunqi.tech/documents/vector_search_ai
4、倒排索引:
-
multi-match 查询,允许您跨越多个字段进行搜索,并提供丰富的匹配策略控制(如 cross-fields, minimum_should_match)
参考链接:https://www.yunqi.tech/documents/inverted_idx_multi-match
例如:
- 您可以配置 cross-fields 策略,将多个字段(如姓和名,或国家和城市)视为一个整体来理解用户的查询;
- 通过 minimum_should_match 参数,您可以精确定义匹配的“门槛”。例如,在用户搜索“轻薄长续航笔记本”时,您可以设定“至少匹配3个词”,以确保返回的结果高度相关
- 支持配置 BM25 相似度算法的核心参数 k1 和 b 。
参考链接:https://www.yunqi.tech/documents/inverted_idx_bm25_param
-
调整 k1: 您可以控制“关键词在文档中重复出现”对相关性得分的影响程度。例如,在新闻标题搜索中,关键词重复可能意义不大;但在商品型号搜索中,重复出现则可能是强相关信号。
-
调整 b: 您可以控制“文档篇幅长度”对相关性的影响。例如,在问答社区,篇幅较短的精炼回答可能更受欢迎;而在法律文书或技术文档检索中,内容详尽的长文档可能更有价值。通过调整 b,您可以消除篇幅带来的“偏见”。
5、多模态数据的混合检索:利用云器 Lakehouse 实现多模态数据的混合检索的最大亮点是架构得到了的极大简化。通过在云器 Lakehouse 内部统一处理文本数据、向量数据及其索引,用户不再需要维护和同步三套独立的系统(传统数据仓库、文本检索引擎如 Elasticsearch、以及专门的向量数据库如 Weaviate 等)。 这不仅避免了数据在多系统间的冗余存储和复杂同步,还显著降低了整体的运维成本和技术复杂度,为构建 RAG(检索增强生成)、智能问答和语义搜索等 AI 应用提供了一个高性能且极具性价比的统一解决方案。
参考链接:https://www.yunqi.tech/documents/PerformingVectorandScalarRetrievalinheSameTableinLakehouse_$cp1$
6、AI 生态:
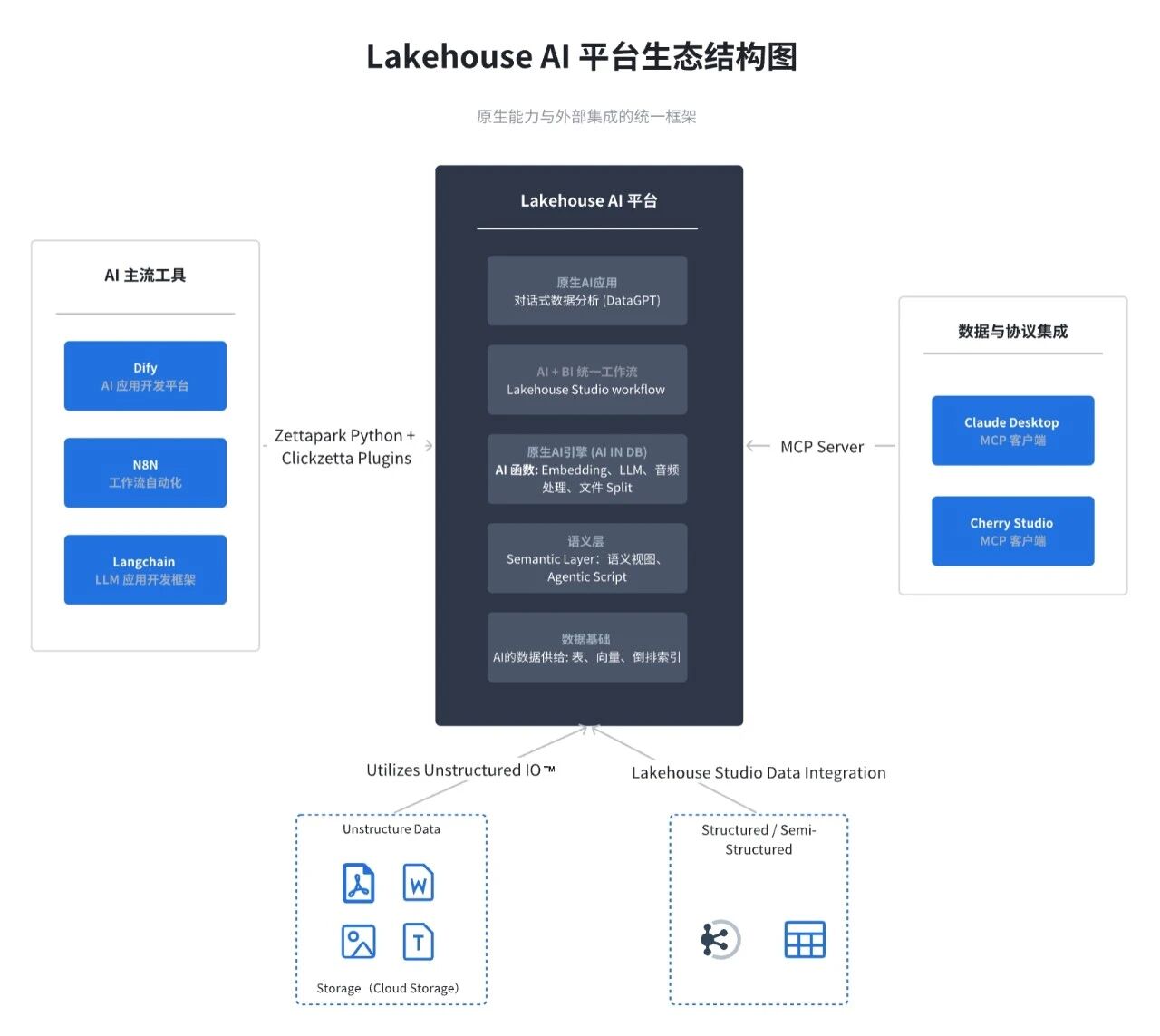
-
集成 Dify
参考链接:https://www.yunqi.tech/documents/dify_yunqilakehouse_integration_overview
-
集成 N8N
参考链接:https://www.yunqi.tech/documents/n8n_Integreated_with_lakehouse_mcp_server
-
集成 Langchain
参考链接:https://www.yunqi.tech/documents/Langchain_plugins_overview
集成与开放性
全面增强 Iceberg 生态双向集成能力 :本次更新全面打通了与外部 Iceberg 生态的连接,极大地提升了平台的开放性和数据联邦能力。
1、对外开放数据,提供标准 Iceberg REST Catalog 服务 :Lakehouse 现已提供标准的 Apache Iceberg Catalog REST API 接口。这意味着外部计算引擎(如 Apache Spark等)可以通过这一行业标准协议,直接访问和查询存储在 Lakehouse 中的 Iceberg 表。用户可以在保持数据统一存储的同时,灵活选择不同的计算引擎进行数据分析。
参考链接:https://www.yunqi.tech/documents/Spark_Lakehouse_iceberg_REST
2、访问外部数据,支持通过 Iceberg REST 方式访问外部 Catalog :通过外部 Catalog 集成功能,Lakehouse 现在可以连接并访问如 Snowflake OpenCatalog 中的 Iceberg 数据表。用户可以在Lakehouse ,无缝查询和分析存储在 Snowflake 生态中的数据,实现了跨云、跨平台的数据联邦查询。
参考链接:https://www.yunqi.tech/documents/Query_SnowflakeOpenCatalog_Icebergtable
3、现已支持使用 External Catalog 连通 Databricks Unity Catalog :您现在可以无需迁移数据,便能读取 Databricks Delta Table 并读写 Managed Iceberg Table,从而对 Databricks 平台已有的 ETL 和 BI 负载进行卸载与加速,实现显著的成本优化。
参考链接:https://yunqi.tech/documents/databricks_yunqi_integration_guide_v2
功能改进
1、数据导入:命令功能增强
COPY OVERWRITE 命令现已支持将查询结果直接输出到单个文件中。这简化了数据导出的流程,特别适用于需要将分析结果打包归档或交付的场景。
参考链接:https://yunqi.tech/documents/COPY-INTO-Location
2、支持 BYOS (Bring Your Own Storage)自助配置 : 针对 BYOS场景,上线了自助化配置流程,简化了用户的接入和管理成本。
参考链接:https://www.yunqi.tech/documents/byos_general
3、计算集群工作负载管理 :新增「长时作业自动路由」功能,精细化保障SLA:针对计算集群中因大作业导致资源争抢、小作业SLA下降的问题,现支持设置“作业运行时长阈值”。超过该阈值的作业将被自动路由到指定的其他计算集群执行。此功能可自动隔离长时运行的负载,避免其对高优先级作业(如BI分析)的性能冲击,有效保障核心业务的SLA。
4、持续数据导入(PIPE)现已集成至 Studio Web 界面 : 针对 PIPE 导入任务,我们新增了基于 Studio Web 的可视化管理功能。现在您可以在界面上直接进行任务运行监控、启停管理以及异常告警处理,享受更友好、更高效的任务观测与运维体验。
未来规划
本次更新覆盖了云器 Lakehouse 在计算性能、AI 能力和生态集成三个方面的重要进展。未来几个月,我们将持续在以下方向发力:
- 性能优化 :在性能提升和资源调度上持续投入,进一步降低使用成本。
- AI 能力深化 :Semantic View 将从邀测走向全面开放,同时会引入更多 AI 原生功能,降低企业构建智能应用的门槛。
- 生态拓展 :继续扩大与主流数据平台的互联互通,让数据流动更顺畅。
云器产品团队会持续听取用户反馈,如有任何问题或建议,欢迎通过云器官网(yunqi.tech)与我们联系。
🎁 新用户专享福利
✅ 1 TB 存储 · 1 CRU时/天计算 · 1 年全托管体验
➤ 即刻访问云器官网领取:https://www.yunqi.tech/product/one-year-package
