大厂的数据压力,正在推动引擎能力的门槛上移
数据规模还在持续增长,AI对数据的需求也在同步加剧——模型训练要更大规模的数据,业务决策要更高时效的数据。这两股压力叠在一起,让数据处理引擎面临的挑战比以前难了不止一个量级。
这个背景下,头部互联网公司对引擎能力的要求也在同步提高。数据规模处于行业极值,业务对时效、成本、查询性能的要求同样苛刻——秒级响应、PB级数据查询、高并发下的稳定性,缺一不可。能在这样的环境里稳定跑通,对任何一套技术来说都是真实的门槛。
小红书、快手、美团陆续在核心业务场景里引入了云器Lakehouse。小红书基于云器Lakehouse搭建了千亿级流量日志的近实时实验数仓;快手与云器深度合作,在EB级规模下验证新一代增量计算架构;美团在BI指标平台的分析引擎选型中对云器Lakehouse做了深度评测,并在灰度场景持续推进。
云器Lakehouse的切入点,都落在同一项技术上:通用增量计算(GIC)。这套技术在实际生产环境里已经有具体数字可以验证——资源消耗降到全量计算的1/20,数据新鲜度从天级压到分钟级,实时与离线数据误差收窄至1%以内。
本文将详细拆解云器在三家大厂的实践,提炼关键的技术突破点,供有类似场景的数据平台团队参考。
实战场景下的云器答卷
小红书:千亿级日志的近实时实验数仓,数据新鲜度从天级压到5分钟
小红书日均流量日志数千亿条,算法团队每30分钟调参一次,需要在实验窗口内拿到准确的分组指标数据。原有架构是典型的Lambda双链路:离线链路准确但只有T+1;实时链路延迟低但成本高,只能采样处理,指标精度打了折扣,实时和离线数据差异超过5%,两套代码体系各自维护,开发成本居高不下。
小红书与云器组成联合项目组,基于通用增量计算(GIC)搭建近实时实验数仓,用一套统一的Single-Engine架构替代原有双链路——数据以分钟级调度驱动动态表刷新,每次只处理新增的增量部分,底层存储基于Iceberg开放格式,标准SQL开发,离线ETL逻辑可直接复用。
落地结果:数据新鲜度从天级压缩至5分钟;100%不采样,实时与离线指标差异收窄至1%以内;资源消耗降至原实时链路的36%。按照小红书团队的规划,后续会将更多核心观测指标迁移到近实时链路,逐步构建全域近实时数仓体系。
快手:增量计算跑通EB级数据规模任务,资源消耗仅1/20
快手数据总量EB级,计算资源数百万核。传统离线全量计算的结构性问题在这个规模下被放大:哪怕只有1%的数据变化,仍要对全量历史数据重新计算;时效性是T+1,关键任务一旦超出产出窗口就是"破线";要提升时效又得另起一套Flink链路,双轨维护成本持续叠加。
快手数据平台团队与云器深度合作,在真实生产环境里验证离线改增量的可行性。测试覆盖简单、中等、复杂三类场景,其中复杂场景涉及10多张大表、十几个join和window算子,直接从线上业务抽取,没有简化处理。
测试结果:简单场景增量资源开销不到离线的1/20,中等场景不到1/3,复杂场景最快达到30分钟时效;增量模式下单次计算耗时短、重跑成本低,关键任务"破线"风险相应降低;时效与成本之间可以灵活调配,大促期间提升频率换时效,平日降低频率节成本。
美团:百万级查询场景下,云器Lakehouse性能翻倍,高并发压测稳定通过
美团BI指标平台支撑百余条业务线,日查询量百万级。引擎面临的挑战来自两个方向:运营看数要求秒级响应,灵活探索要求支撑PB级明细数据的复杂查询——两种性能需求完全相反。传统双引擎方案(BSP+MPP)数据链路长、资源缺乏弹性,且美团的查询SQL由语义服务自动生成,复杂度高,对引擎算力要求更严苛。
美团技术团队经过多轮调研,将云器LH作为增强计算引擎在灰度场景下进行评测。云器Lakehouse的核心特点是Single-Engine架构同时支持BSP和MPP两种执行模式,通过向量化执行、弹性伸缩、三级缓存等能力应对两类场景。接入方式上通过外表直读现有HDFS数据,无需迁移,Spark UDF天然兼容。
评测结果:灵活探索场景线上双跑对比同配置Trino集群,性能提升2倍,涉及84张表、1000+TB数据;运营看数场景压测QPS递增至80(线上实际低于10),性能指标全程平稳。按照美团技术团队的规划,后续将持续扩大灰度范围,并将部分查询优化能力逐步下沉到引擎层。
三个案例背后,云器做对了什么
三个案例场景各异,但回头看,有几个共同点贯穿始终——正是这些地方,决定了云器Lakehouse能在这些场景里跑通。
通用增量计算(GIC):重新定义计算模式
快手简单场景资源降到离线的1/20,小红书数据新鲜度从天级压到5分钟——这些结果背后,是同一套技术逻辑:通用增量计算(GIC)。
通用增量计算(GIC)的原理并不复杂:上游数据发生变化时,只计算变动的部分,把结果合并到已有状态,而不是全量重算一遍。难的是工程实现——真实业务的SQL包含各种复杂算子,left join、window function、UDF……每种算子的增量化处理逻辑都不一样,有的能完全局限在增量数据内,有的需要与历史存量数据交互,有的在特定情况下甚至会退化为全量计算。
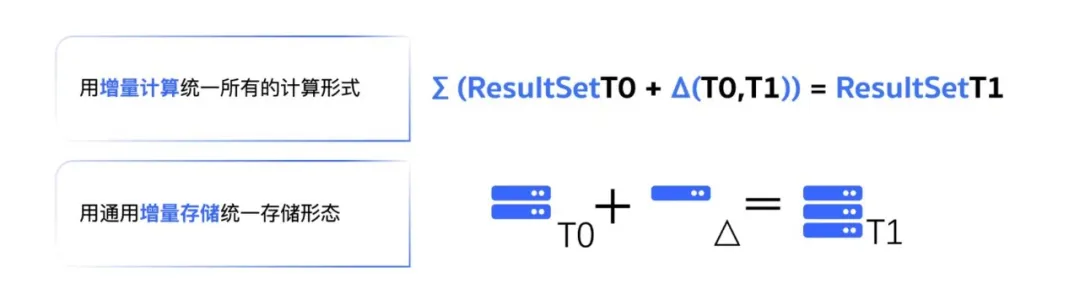
云器的通用增量计算(GIC)采用了基于代价(Cost-based)的动态执行引擎:每次动态表刷新时,系统综合评估查询复杂度、数据变化模式、数据变化量级、调度频率四个维度,从多种可行执行计划中实时选择最优方案。数据只有1%发生变化,就只算那1%;数据发生大规模变动,系统自动识别并切换策略。用户只需要关注业务逻辑,引擎在底层自动完成最优路径的选择。
这套动态选择的机制,让GIC在快手最复杂的场景下——十几个join和window算子、多张10TB级大表——也能稳定跑通,没有退化成全量重算。
Single-Engine:一个引擎跑通全场景
小红书、快手的案例里有一个共同细节:离线ETL逻辑几乎可以直接复用到增量链路,改造成本极低。这背后是云器Single-Engine架构的基础支撑——流、批、交互查询、增量计算,统一在同一套引擎里完成,底层基于Iceberg开放格式,统一用标准SQL开发。
大数据架构的历史,本质上是一部"堆引擎"的历史。批处理用Spark,流处理用Flink,实时查询用ClickHouse,历史数据用Hive……每引入一个新引擎,就引入一批新的数据同步、运维、一致性保障问题。架构越来越复杂,工程师越来越忙,但问题并没有越来越少。
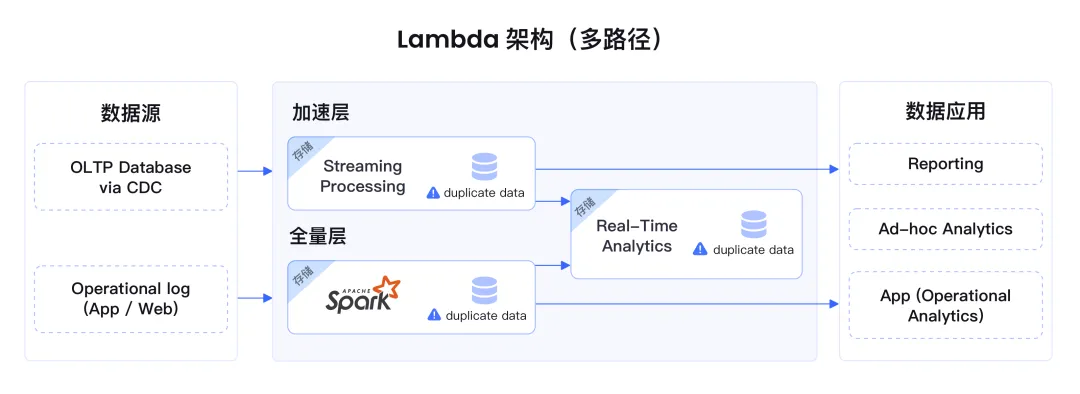
云器的Single-Engine选择了一条不同的路:不再堆叠各种组件,一个引擎支持全场景。批处理、流处理、交互查询,统一到一套引擎里,统一的存储格式(Iceberg开放格式),统一的开发语言(标准SQL),统一的运维体系。
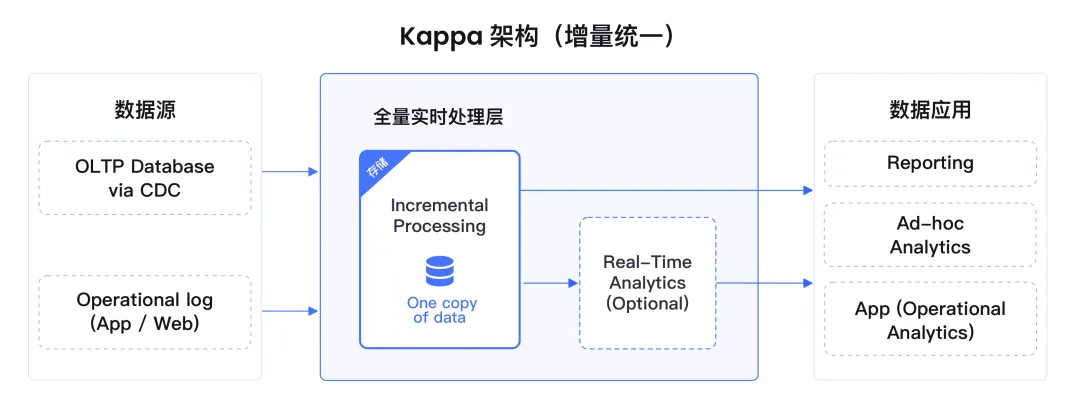
这不只是工程上的"省事",带来的是整条链路的一致性。在小红书的案例里,离线ETL逻辑可以直接复用到增量链路;在快手的案例里,离线SQL几乎可以"copy-paste"成增量SQL;在美团的案例里,现有HDFS数据无需迁移,引擎原生读写。这种"无损接入",让先进技术能以最低的切换成本转化为真实生产力。
统一引擎之外,云器Lakehouse在查询性能上也做了针对性的设计:向量化执行(C++/SIMD)提升计算吞吐,三级缓存体系(内存、SSD、对象存储)将缓存命中率做到95%以上,存算分离设计支持0到100+实例的秒级弹性伸缩。美团的评测里,同等配置下云器LH比Trino快2倍,在QPS递增至线上实际值8倍的压测下性能仍然平稳。
开放且深度的生态兼容
技术能跑通是一回事,能在大厂生产环境里落地是另一回事。原生支持Iceberg等开放数据湖格式,大厂现有数据资产无需迁移即可直接读写;完整兼容标准SQL语法和Hive UDF,现有代码几乎不需要改造;对接Kerberos等企业级安全认证体系,合规要求不会成为接入的阻碍。
每一个兼容点单独看都不起眼,但在大厂引入一套新引擎时,每一处不兼容都是真实的工程成本和推进阻力。三个案例里,小红书、快手、美团的现有技术栈都得到了不同程度的复用,没有出现为了用云器而大规模改造存量系统的情况。
从大厂到更多场景
三个案例,规模从千亿到EB级,场景从实验数仓到BI指标平台,结果都指向同一个方向:通用增量计算(GIC)和Single-Engine在真实生产压力下是跑得通的。
头部互联网公司的技术环境足够复杂、要求足够严苛,能在这里拿到结果,意味着这套技术路线具备了在更大范围落地的基础。
云器正在推进的方向之一,是Data+AI的结合。近实时数据与AI模型的结合正在成为大厂的实际需求——快手的规划里,增量计算要直接服务于广告AI模型的训练,数据新鲜度越高,模型效果越好;美团BI平台上孵化的自然语言数据助手,背后依赖的也是指标平台沉淀的准确语义层。云器的Single-Engine架构和通用增量计算(GIC),为这类Data+AI场景提供了数据侧的基础支撑。
数据的时效性和AI的智能化,正在越来越紧密地绑在一起。这个趋势下,增量计算能扮演什么角色,后续还有更多场景会给出答案。
🎁 新用户专享福利
✅ 1 TB 存储 · 1 CRU时/天计算 · 1 年全托管体验
➤ 即刻访问云器官网领取:https://www.yunqi.tech/product/one-year-package

