📌 导读:
本文整理自云器科技解决方案负责人石静猛在技术分享会上的演讲。面对大数据平台负责人同时背负的“降本增效”与“AI探索”双重KPI(近期几十家客户交流实际面临的问题),传统Hadoop/Lambda架构暴露出组件冗余、成本高企、无法支撑AI所需的多模数据与实时性等瓶颈。
云器科技提出“湖上原地加速”方案,通过“数据不动、元数据不动、任务不搬、SQL不改”的插件式嵌入,在零停机前提下实现离线ETL计算成本降低50%以上(每个月真实钱的花费降低)、即席查询性能提升3-10倍,并平滑演进至面向AI的新一代Lakehouse架构。本文结合火花思维、高途教育、美团等真实生产案例,详解方案原理、落地路径与量化ROI。

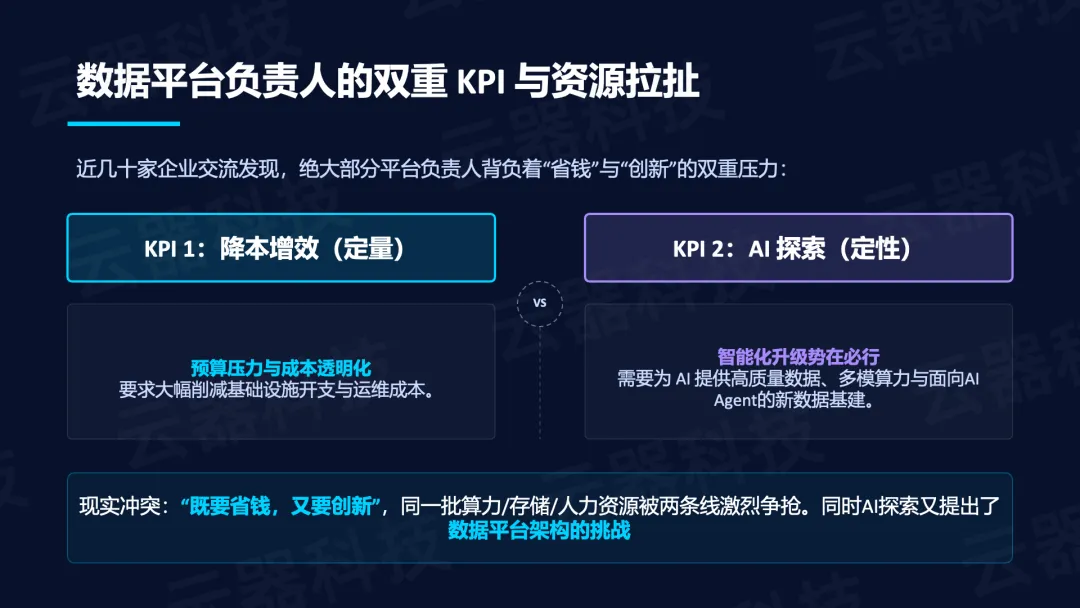
双重困境:降本增效的极大压力与AI探索的不可或缺
当前绝大多数数据平台负责人背负着两个相互冲突的KPI: 一是定量降本增效,要求大幅削减基础设施开支与运维成本;二是AI探索,需要为AI提供高质量数据、多模算力以及面向AI Agent的新型数据基建。现实冲突在于,同一批算力、存储和人力资源被两条线激烈争抢,而AI探索本身又对数据平台架构提出了更高要求。
解决方案:湖上加速方案,降本增效的同时满足AI探索需求
为了解决上述的矛盾问题,云器推出了湖上原地加速方案,在快速降本增效的同时,也能更好的满足AI探索的需求,以下是湖上原地加速方案效果的说明,后续会展开细节。


方案介绍:痛点分析及破局之道
痛点分析:降本增效依然是普遍的关切
“降本增效”依然是当前用户最普遍的关切。需要澄清的是,数据平台的总拥有成本(TCO)远不止硬件成本——它包含硬件、软件、开发人员、维护人力以及治理优化等多方面支出。真实客户案例显示,TCO通常是硬件成本的3倍以上。

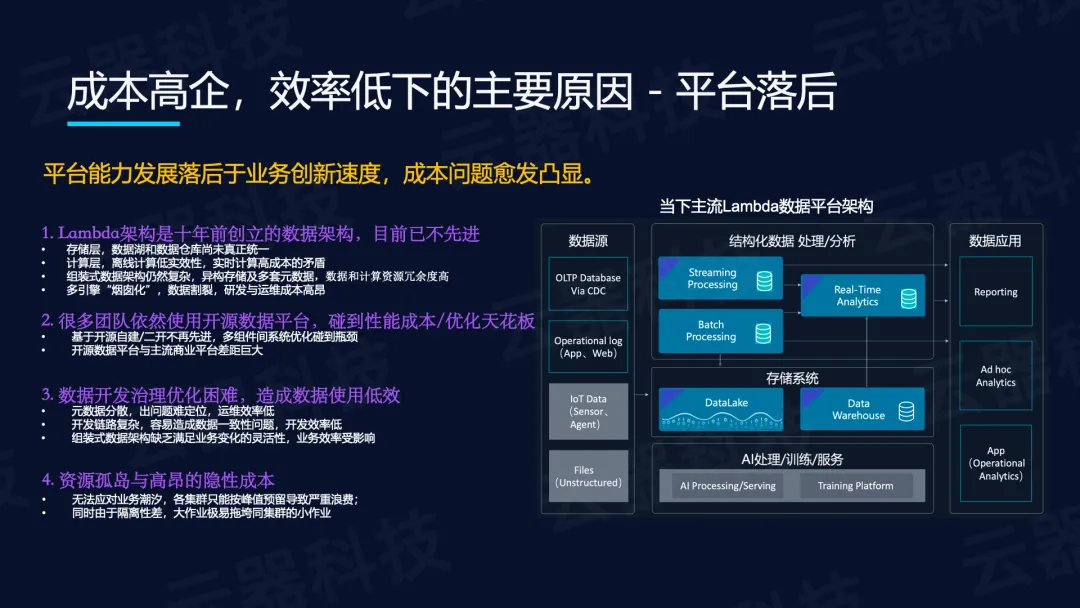
而成本高企、效率低下的核心原因之一在于平台落后,当前主流的Lambda数据平台架构(创立于十五年前)已不先进:
- 存储层中数据湖与数据仓库尚未真正统一;
- 计算层存在离线计算低时效性与实时计算高成本的矛盾;
- 组装式架构导致异构存储、多套元数据、数据和计算资源高度冗余;
- 多引擎“烟囱化”使得数据割裂,研发与运维成本高昂;
- 很多团队依然使用开源自建平台,在多组件间遭遇系统优化瓶颈,与主流商业平台差距巨大;
- 元数据分散导致问题难定位,开发链路复杂易造成数据不一致,资源孤岛与高昂隐性成本(各集群按峰值预留导致严重浪费,大作业拖垮小作业)进一步加剧了效率问题。
外部环境也在加剧降本压力: 云与硬件采购成本大幅攀升,一块大容量硬盘价格可能翻倍;自建IDC越来越少,电力与空间成为致命约束,建设成本与周期失控。单纯依赖“增加机器”解决性能问题的路径已被封死,必须用“软件执行效率”对冲硬件成本的翻倍上涨。

痛点分析:AI探索对数据平台提出了新的要求
AI探索倒逼底层数据平台重构。
企业共识已形成:AI不再是试水的单点工具,而是必须建立的系统级生产力。
关键约束在于:没有高质量的数据,就没有高质量的AI。AI应用的质量上限被数据的可用性、新鲜度与治理水平死死限制。冰冷现实是,绝大多数企业的核心数据依然跑在旧一代Hadoop或多引擎拼装平台上,根本无法为AI提供所需的高质量多模数据支撑。AI时代,每个企业都要重做数据底座,但面临降本压力,不能停机、不能推倒重来。

面向AI时代的数据基础设施演进呈现出 6大关键特征(这是老一代Lambda架构不具备的):
1)Lakehouse成为默认选择;
2)Kappa架构一体化引擎;
3)多模计算的融合是未来;
4)基于增量计算的奖牌模型;
5)面向模型/Agent的设计;
6)治理与可观测性贯穿始终。

架构瓶颈:存量平台为什么“升不动”也无法满足AI?
存量平台难以演化到AI时代的数据平台,根本原因在于迁移风险极高,代价难以承受:
- PB级数据搬迁导致迁移周期长,停机窗口极难协调,数据核对与容错成本高昂;
- 元数据/血缘断裂,历史数据链路丢失,Hive/Iceberg表结构需梳理,治理体系几近从零重建;
- 上下游任务改写,数百乃至数千SQL逐条适配,全量代码修改不确定性大,研发资源投入成为巨大黑洞。

破局之道:“湖上原地加速”为何是最低风险跳板?
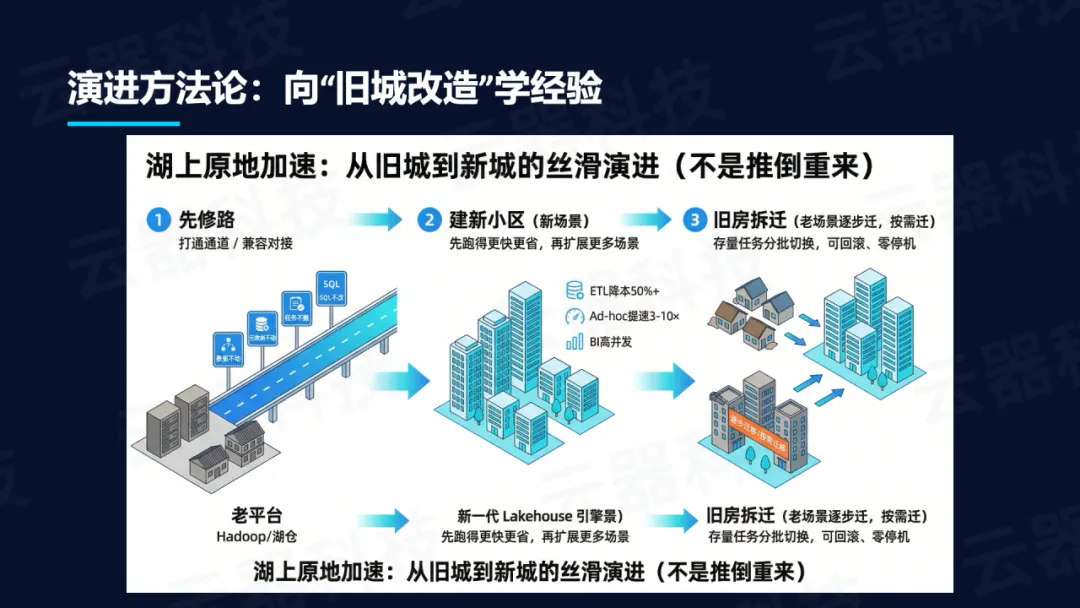
演进方法论应向“旧城改造”学习:
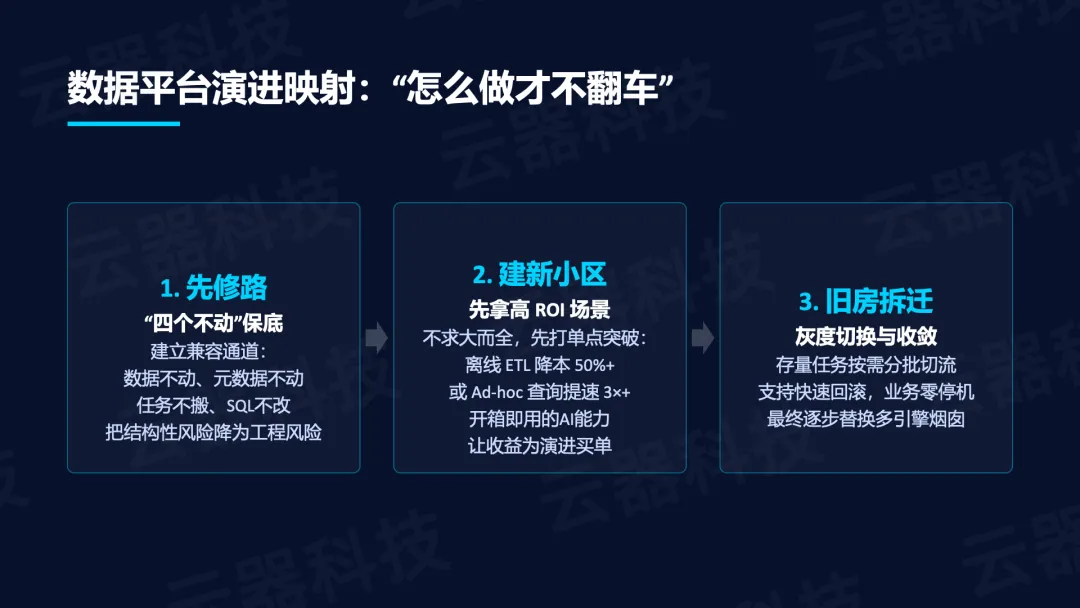
- 第一步“先修路”——建立兼容通道,做到数据不动、元数据不动、任务不搬、SQL不改,把结构性风险降为工程风险;
- 第二步“建新小区”——先拿高ROI场景,不求大而全,先打单点突破(离线ETL降本50%+或Ad-hoc查询提速3×+),开箱即用的AI能力让收益为演进买单;
- 第三步“旧房拆迁”——灰度切换与收敛,存量任务按需分批切流,支持快速回滚,业务零停机,最终逐步替换多引擎烟囱。
传统升级方式与湖上原地加速方案的对比鲜明:
- 全量迁移 vs 原地读写(业务零停机);
- 元数据完全重建 vs 直接复用HMS/Catalog(血缘保留);
- SQL代码全量改写 vs 完整兼容(上下游工具无需改动);
- 架构长期并行运维翻倍 vs 单引擎替代多系统、插件式接入;
- 重资产投入后见效 vs 轻量POC数天验证50%降本效果。

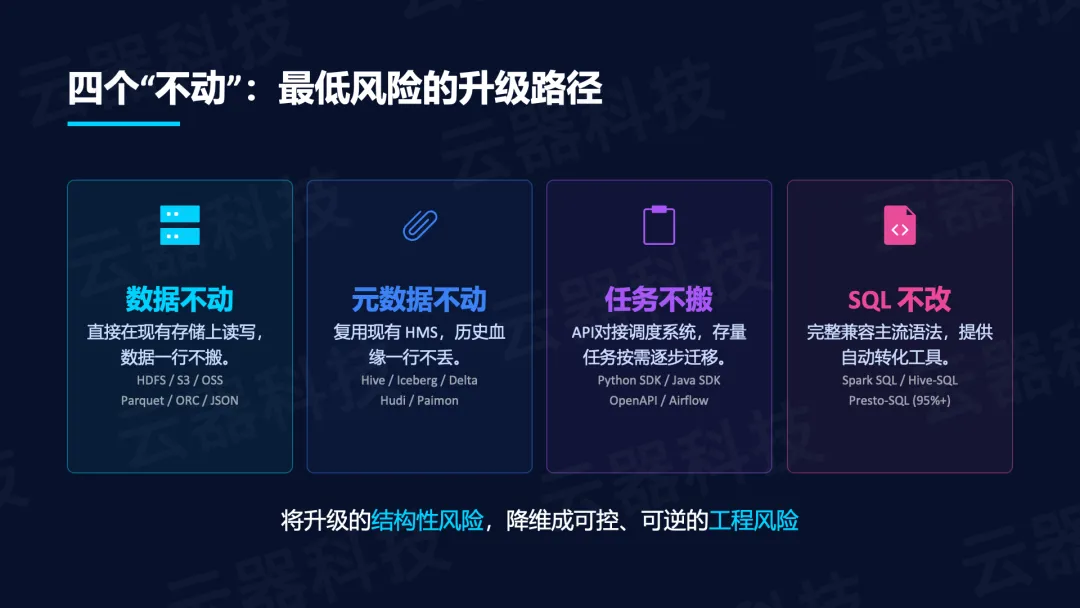
最低风险的升级路径“四个不动”:
- 数据不动: 直接在现有存储(HDFS/S3/OSS,Parquet/ORC/JSON)上读写;
- 元数据不动: 复用现有HMS(Hive/Iceberg/Delta/Hudi/Paimon),历史血缘一行不丢;
- 任务不搬: 通过Python SDK/Java SDK/OpenAPI对接调度系统(如Airflow),存量任务按需逐步迁移;
- SQL不改: 完整兼容Spark SQL/Hive-SQL/Presto-SQL(95%+),提供自动转化工具。
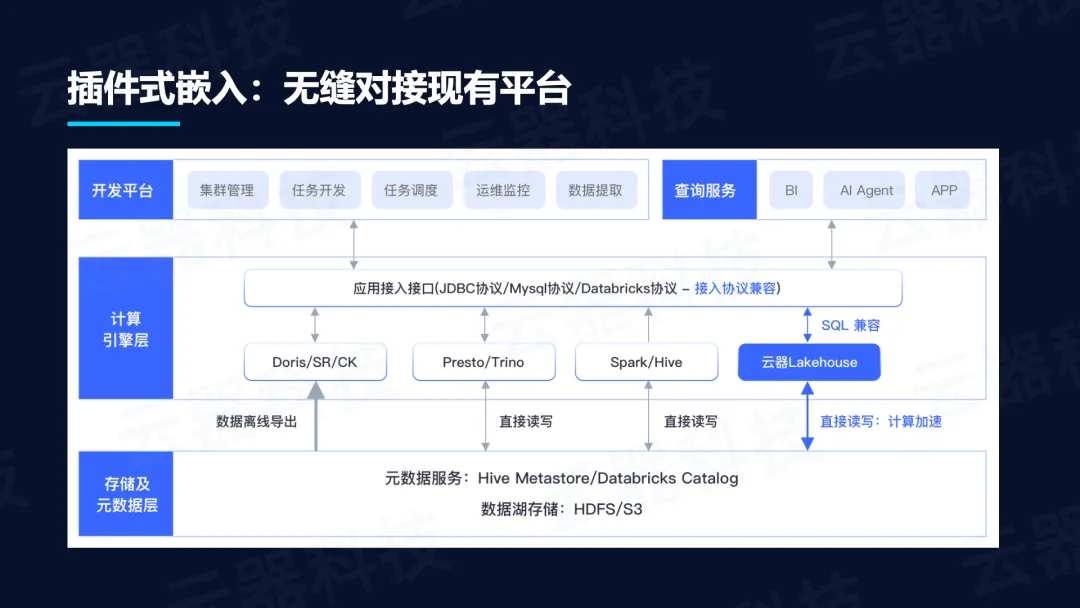
嵌入式架构,无缝对接现有平台:
单一引擎支持多场景:
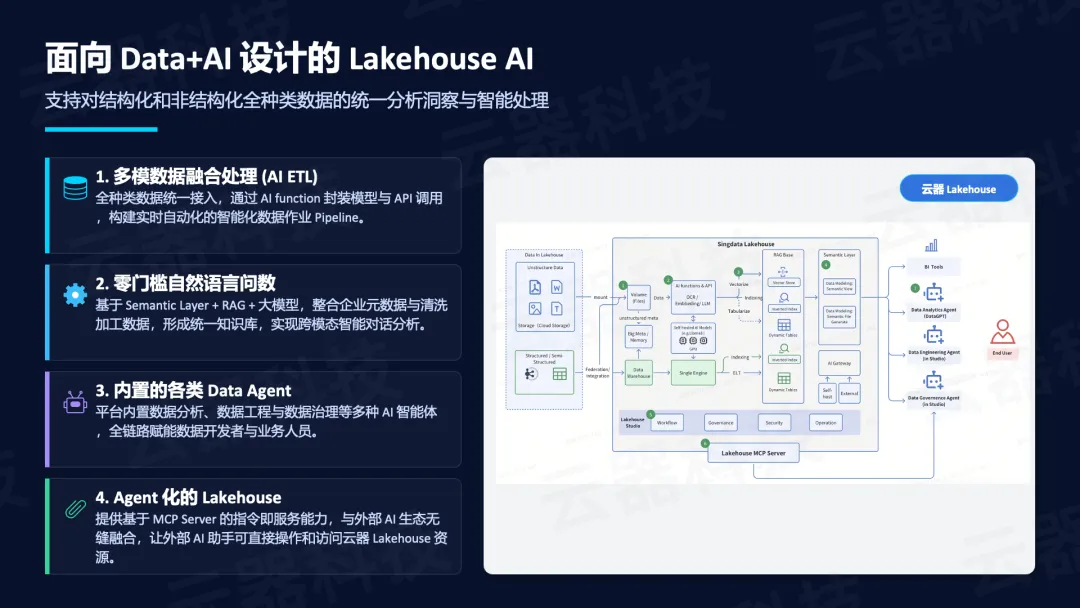
面向Data+AI设计的Lakehouse AI支持:
- 多模数据融合处理(AI ETL)——全种类数据统一接入,通过AI function封装模型与API调用,构建实时自动化的智能化数据作业Pipeline;
- 零门槛自然语言问数——基于Semantic Layer + RAG + 大模型,整合企业元数据与清洗加工数据,形成统一知识库;
- 内置的各类Data Agent——数据分析、数据工程与数据治理等多种AI智能体;
- Agent化的Lakehouse——提供基于MCP Server的指令即服务能力,与外部AI生态无缝融合。
业务落地:三大核心场景
三大核心场景之一: 离线ETL计算加速。SQL完整兼容Spark SQL/Hive-SQL无需改写,上下游调度系统、开发平台照常运行,向量化引擎加速使计算成本直接降低50%+,存储兼容HDFS/S3/COS及Hive/Iceberg表格式直接读写。
三大核心场景之二: Ad-hoc查询。Ad-hoc即席查询通过JDBC/MySQL协议兼容、外表直接查询,相比Presto/Trino,外表性能提升3倍以上或降本60%以上;导入内表后向量化加速6-10倍。
三大核心场景之三: BI交互式查询。BI高并发低延迟查询具备更好的资源管理与隔离,大作业自动路由,宽表查询+多表关联全面超越ClickHouse,彻底告别BI+ETL烟囱架构。


生产环境验证:火花思维、高途教育、美团真实案例
火花思维案例: 点击查看
架构集成:
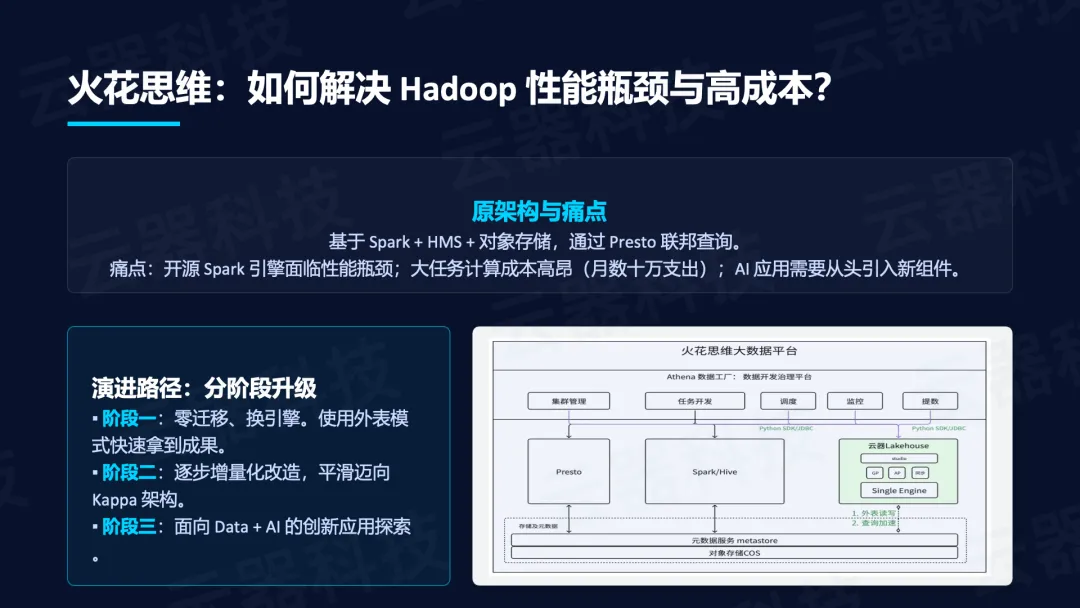
- 火花思维原架构基于Spark + HMS + 对象存储,通过Presto做Adhoc查询,痛点在于开源Spark引擎性能瓶颈、大任务计算成本高昂(月数十万支出)、AI应用需要从头引入新组件。
- 云器Lakehouse插件式站在旁边进行计算加速
演进分三阶段:
- 阶段一零迁移换引擎,使用外表模式快速拿成果;
- 阶段二逐步增量化改造平滑迈向Kappa架构;
- 阶段三面向Data+AI的创新应用探索。
落地成果:
- 整体性能提升3-10倍(大任务平均10倍)
- 综合计算降本60%+(Serverless消除闲置+执行效率提升)
- 业务中断为零,Spark SQL 100%跑通
- 开箱即用的AI Agent

高途教育案例
架构集成:
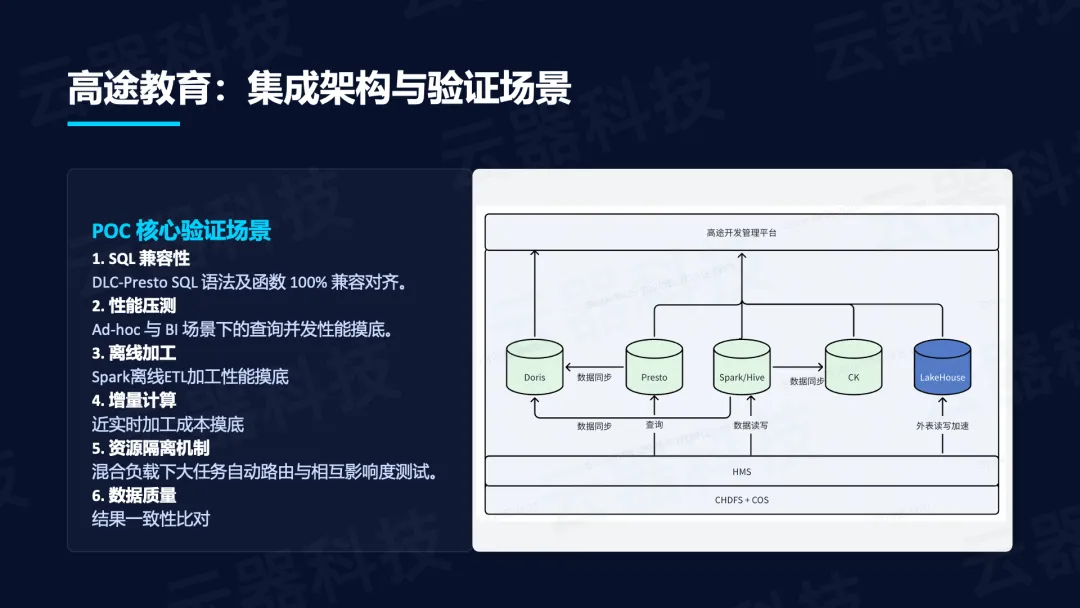
- 高途教育原架构基于Spark/hive + HMS + chdfs+对象存储,通过Presto做Adhoc 查询,CK做实时分析;架构割裂,成本高昂
- 云器Lakehouse先以插件方式站旁边进行计算加速,实现降本增效的效果,再阶段式演进,逐渐替换已有组件
高途教育验证了六大场景:
- SQL兼容性
- 性能压测
- 离线加工
- 增量计算
- 资源隔离机制
- 数据质量比对。
落地成果:
- Presto查询场景无缝迁移,外表查询保持2-4倍性能优势,QPS是原架构的2.3-3.7倍,90%查询效率领先5倍以上;
- 大任务自动路由大幅简化架构;
- 增量计算将数据新鲜度从1小时提升到5分钟,成本降低50%;
- 离线大任务资源消耗降低85%,性能提升3倍。

美团案例: 点击查看
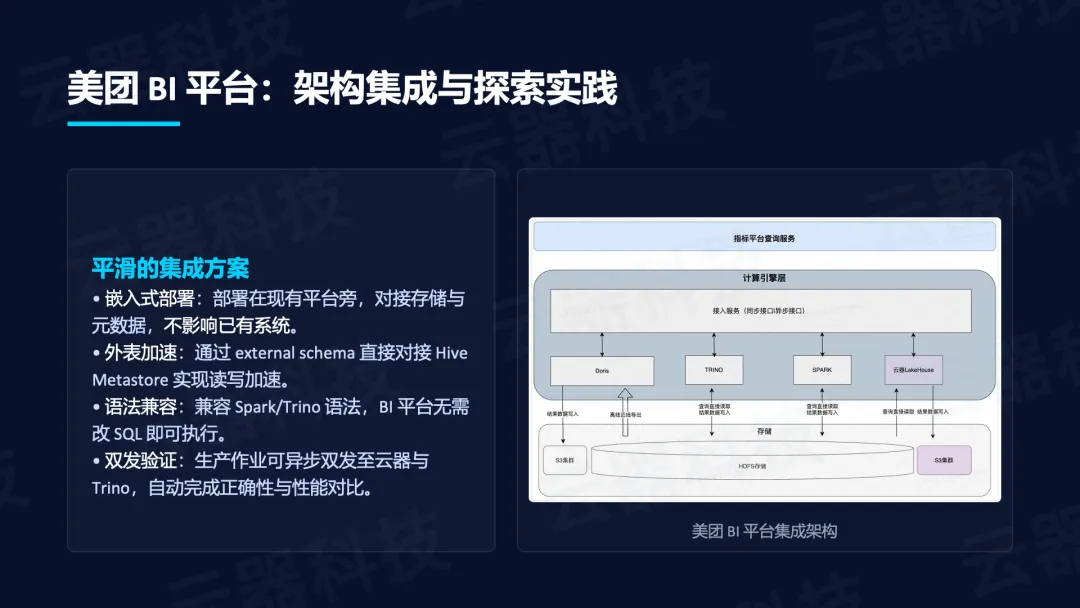
架构集成:
- 美团BI平台采用嵌入式部署,通过external schema对接Hive Metastore,兼容Spark/Trino语法。
- 实现和已有BI平台打通,双发验证,自动完成真实生产任务的正确性与性能对比。
落地成果:
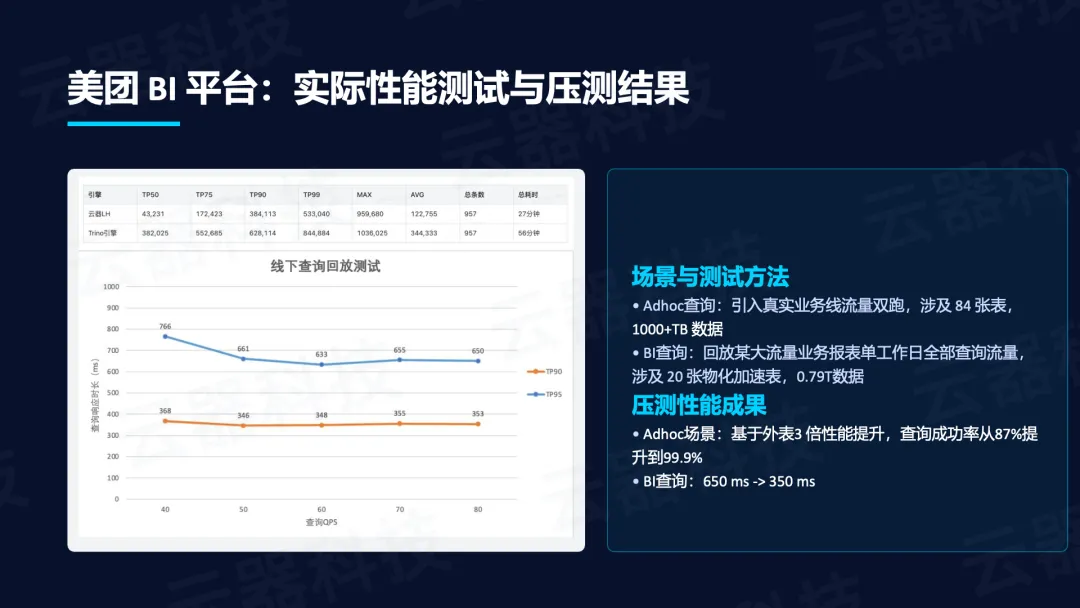
- Ad-hoc场景引入真实业务流量双跑(84张表,1000+TB数据),基于外表实现3倍性能提升,查询成功率从87%提升到99.9%。
- BI查询回放某大流量业务报表单工作日全部查询流量(20张物化加速表,0.79T数据),平均延迟从650ms降至350ms。
总结与展望
业务挑战: 降本增效与AI探索的双重压力。外部环境巨变导致云与硬件采购成本大幅攀升,单纯“堆机器”对冲性能的模式已不可持续;AI探索倒逼企业重构数据底座,走向多模处理与流批一体的现代化架构,并实现数据平台Agent化。
架构瓶颈: 存量老平台“想升升不动”。传统架构组件繁多,数据孤岛严重,推倒重来的风险与高昂的迁移成本让企业望而却步。
破局之道: “湖上原地加速”凭借“四个不动”(数据、元数据、代码、习惯均不改变),成为阻力最小、风险最低的最佳跳板。既能通过极致的计算提效对冲硬件成本,又能平滑演进到新一代AI数据平台架构。

欢迎交流:灰度切流、兼容性评估、POC任务选择与ROI核算
🎁 新用户专享福利
✅ 1 TB 存储 · 1 CRU时/天计算 · 1 年全托管体验
➤ 即刻访问云器官网领取:https://www.yunqi.tech/product/one-year-package

