
导读
杭州客攀(Apollo)作为跨境电商广告优化领域的创新企业,在业务快速增长的同时,面临着技术栈复杂、性能瓶颈突出等挑战。原有基于阿里云EMR+Flink+ADB的三套系统架构,不仅运维负担重,核心查询性能也难以满足业务需求。2025年7月,Apollo选择云器Lakehouse作为新一代数据平台,将技术栈从三套系统简化为两套,SQL方言从三种减少到两种。迁移后,核心业务查询性能提升3.5倍,ETL任务时间缩短90%以上,规则引擎自9月上线以来零故障运行。更重要的是,1人数据团队即可高效支撑500家客户的业务需求。本文将详细分享Apollo从技术选型到落地实践的完整历程,展示云器Lakehouse如何帮助初创团队实现技术架构的跃升。
一、现状与痛点
1.1 背景
杭州客攀网络科技有限公司成立于 2021 年,总部坐落于杭州未来科技城。专注于亚马逊广告投放的培训与咨询服务、广告代投服务以及 AI 效率工具。Apollo 以利用 AI 技术为跨境电商卖家破解流量难题、助力实现业务增长为使命。自创立起,Apollo 已累计为 3000 余家不同规模的电商卖家提供广告投放服务,培训了近 10000 名跨境广告运营人才。
Apollo 也是亚马逊官方的广告合作伙伴,同时荣获杭州市跨境电商培训基地认证,为国内跨境电商企业的发展贡献力量。截至目前,已与官方联合举办线上、线下广告培训活动 100 余场,活动参与人次超 100000。
Apollo 团队自主研发广告优化算法和 AI 智能系统。陆小凌飞积极推动 AI 大模型在广告技术中的应用与开发,成功推出业内首个 AI 大模型智能服务系统 Hanna,并于2024年 11 月 5 日发布上线。
1.2 核心问题
作为初创团队,Apollo在技术架构和数据处理方面面临诸多挑战,原有基于阿里云的技术栈存在明显瓶颈:
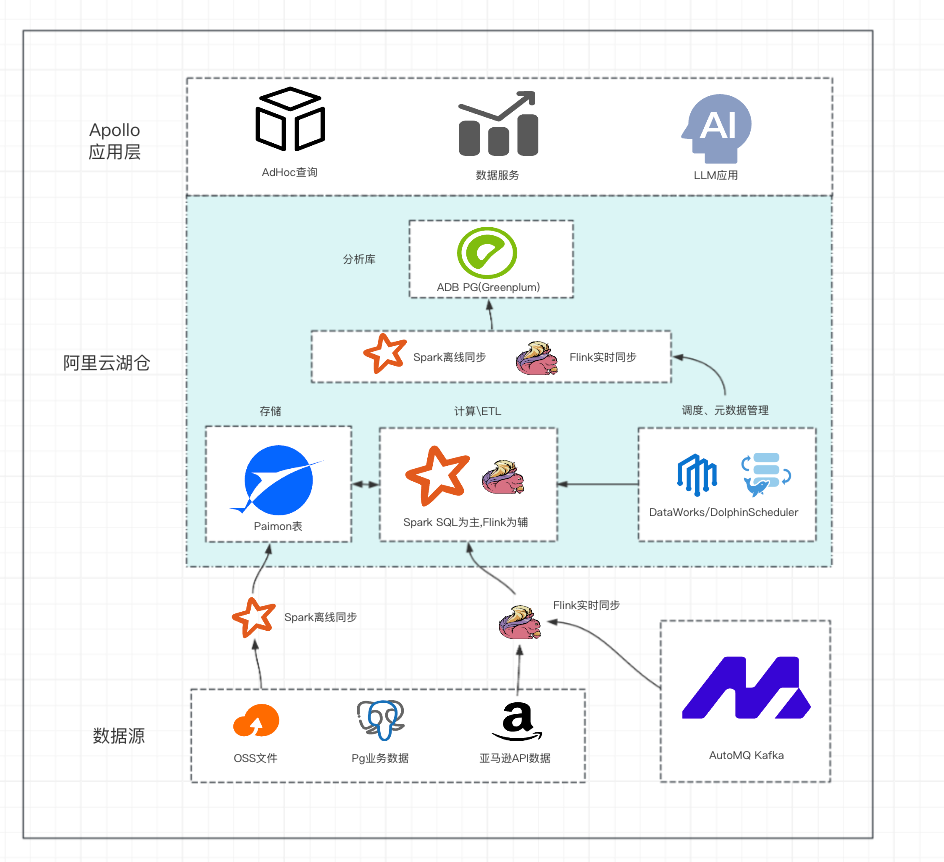
原有架构图——Apollo阿里云湖仓三套系统架构
问题一:技术栈过于复杂
- 需要同时维护EMR + Flink + ADB PG三套系统,存在Spark SQL、Flink SQL、PostgreSQL三种SQL方言,开发心智负担大,团队仅有1名数据工程师,难以维护如此复杂的技术栈
问题二:开发工具体验差
- DataWorks数据集成不支持RDS PostgreSQL的upsert操作,需要额外步骤处理,并且运维中心性能差,几千个工作实例筛选会导致浏览器卡顿
- EMR集群组件配置受限,部分可用区组件售罄无法自定义
问题三:性能瓶颈突出
- 核心查询(ASIN反查)在ADB For PG中平均需要50秒,大数据量时甚至达到200秒或直接OOM
- Spark ETL任务单个SQL执行时间超过10分钟,数据处理效率低下,影响用户体验
问题四:AI能力集成困难
- 需要自行搭建向量数据库(Vector Store)和Embedding功能
- 数据分散在多个系统,AI应用开发复杂度高
- 初创团队不会在多个云服务(如PostgreSQL、OpenSearch等)上花太多钱
二、升级选型逻辑(为什么选云器Lakehouse)
2.1 需求清单
经过多方产品的调研,以及内部讨论,明确了未来平台升级几个关键考虑的方向:
| 关键能力分类 | NO. | 关键项 | 说明 |
|---|---|---|---|
| 性能提升 | 1 | 具备增量计算的能力 | 大量业务涉及到了增量同步和离线处理,需要新引擎技能在支持离线计算的同时,能够支持增量计算 |
| 性能提升 | 2 | 查询性能优于ADB PG | 核心查询(ASIN反查)在ADB For PG中平均需要50秒,大数据量时甚至达到200秒或直接OOM |
| 使用体验提升 | 3 | 减少SQL方言 | 目前涉及到的组件包括Spark、Flink、ADB PG,涉及到Spark SQL、Flink SQL、PostgreSQL这3个方言,开发难度大 |
| 使用体验提升 | 4 | 开发调度工具不卡顿 | DataWorks运维中心性能差,几千个工作实例筛选会导致浏览器卡顿 |
| 使用体验提升 | 5 | 免运维或极简运维 | 创业公司人员有限,要将工程师从集群管理、参数调优等事务中解放出来,专注于业务价值创造 |
| 使用体验提升 | 6 | Serverless自动弹性扩缩容 | 业务每天不同时刻都有波动,资源需要能灵活弹缩,避免资源的浪费 |
| 成本降低 | 7 | 总体成本降低 | 希望通过本次技术选型带来的技术红利能够带来一定程度的成本降低 |
| AI能力建设 | 8 | 面向未来,支持Data+AI的应用 | 具备Data+AI底座的能力,包括但不限于:多模数据的存储、管理、计算,到向量化存储及检索,到构建知识库,支持MCP Server 接口,并基于这些能力实现自然语言问答,AutoETL等能力 |
2.3 方案选择:云器Lakehouse
为满足上述能力,apollo团队在深入评估多种方案后(包括完全开源自建方案等),还是决定引入云器Lakehouse作为核心平台,来支撑新一代一体化湖仓平台及Data+AI大数据基础设施平台的建设。

三、云器Lakehouse在Apollo生产环境的落地实践
apollo这次架构升级,可以概括为从”组件堆砌”到”平台一体化”的一步。下图直观展示了迁移前后的架构变化。
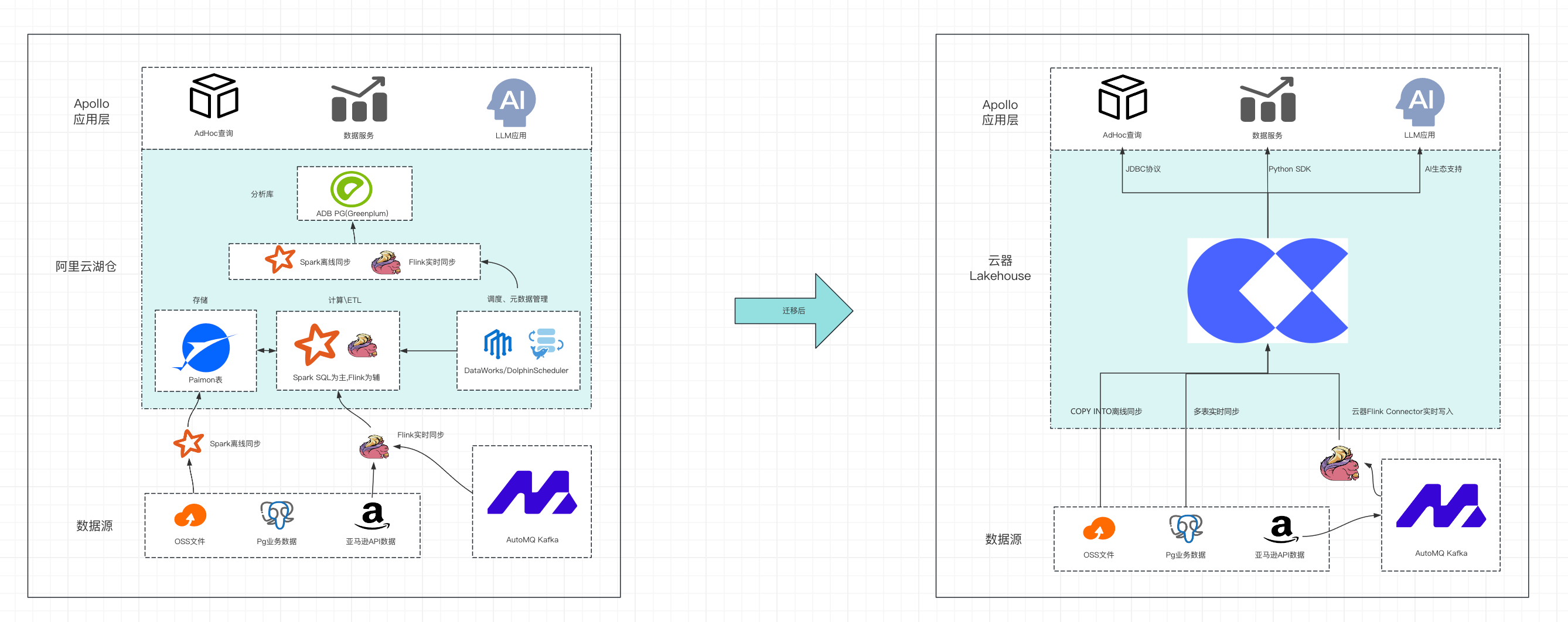
相比原有架构,最直观的变化是组件数量的大幅精简和数据链路的显著缩短。
3.1 外部数据快速入湖
云器Lakehouse提供多种数据写入能力,Apollo主要使用以下三种方式实现数据快速入湖:
- Volume Copy Into离线写入:通过批量导入方式将历史数据高效加载到云器中,适合首次迁移时的全量数据导入
- PG多表实时数据集成:利用云器内置的数据集成能力实现从PostgreSQL到湖仓的实时同步,原生支持upsert操作,大幅简化数据同步流程
- Flink Connector实时写入:对于需要复杂转换或实时性要求极高的场景,Flink仅负责数据入湖这一单一职责
通过这三种方式的组合使用,Apollo实现了灵活高效的数据接入能力。
3.2 增量计算能力
云器Lakehouse的增量计算能力是其核心优势之一,Apollo主要使用了Table Stream和Dynamic Table两大特性。
Table Stream(表流):Apollo在3个底层表上创建了近30个Table Stream,用于支持不同的增量消费场景。Table Stream能够自动跟踪表的变更,无需手动管理快照版本号,完美替代了原有Paimon的incremental query方案。
Dynamic Table(动态表):通过动态表实现物化视图能力,支持增量刷新。Apollo采用低基数列(按月/按周/按市场)作为分区键,配合Session Config参数,对于15分钟调度一次的任务,每周仅需1次全量刷新,其余都是增量更新,大幅降低计算开销。
这些高级SQL能力使得Apollo无需依赖Flink等外部组件进行增量计算,在云器内部即可完成所有增量数据处理逻辑。
3.3 极致的查询性能
云器Lakehouse在查询性能上的表现超出了Apollo团队的预期:
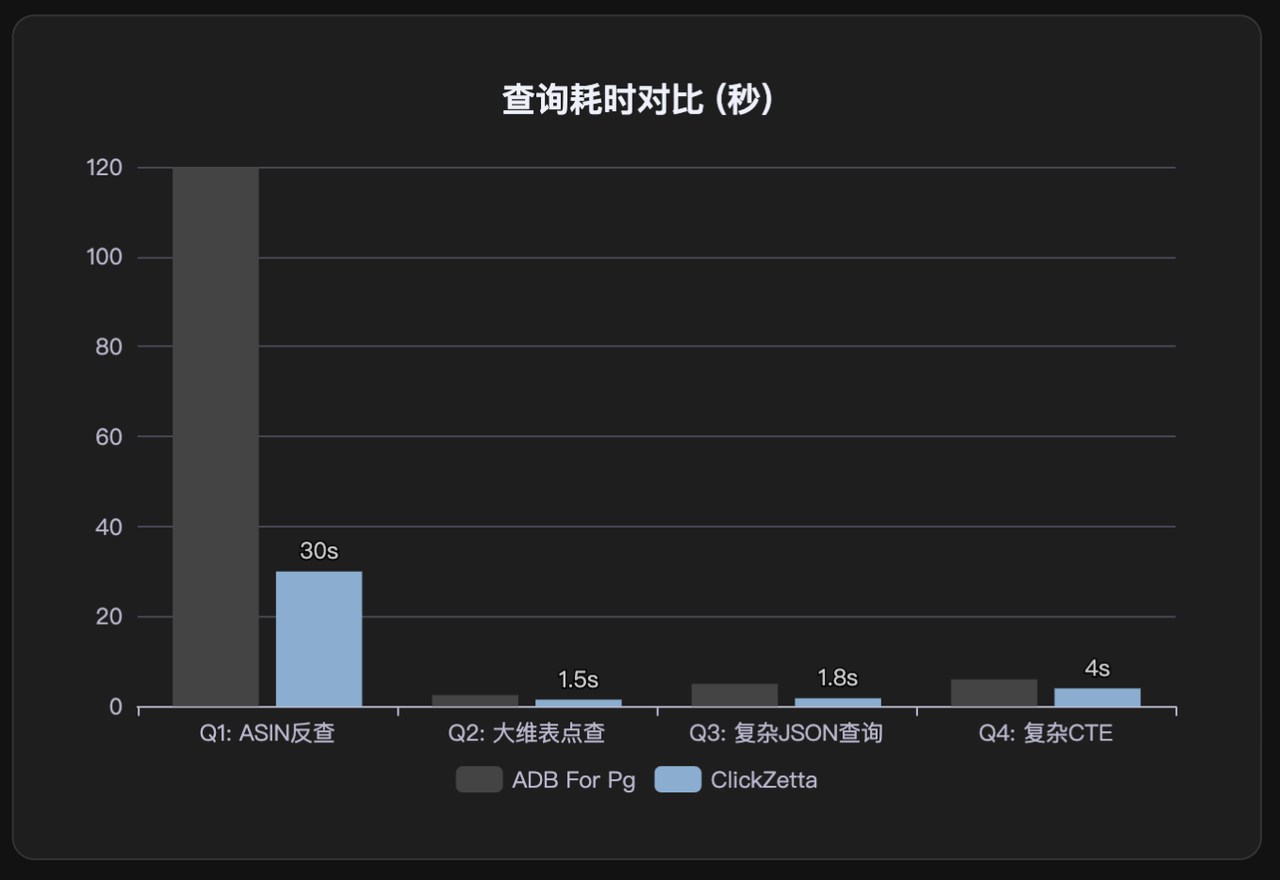
- 核心查询性能提升3.5倍+:ASIN反查在原有ADB PG架构下平均需要50秒,大数据量时甚至达到200秒或直接OOM。迁移到云器后,平均查询时间降至7秒,性能提升7倍以上。即使数据量特别大的查询,响应时间也控制在30-40秒。
- ETL任务提速10倍以上:原有基于Spark的ETL任务,单个SQL执行时间常常超过10-15分钟。迁移到云器后,几乎所有ETL任务都能在1分钟内完成,部分任务甚至只需几十秒。
这得益于云器高性能的向量化执行引擎和智能的查询优化器。Apollo团队表示,当前性能是在尚未针对云器进行深度优化的情况下取得的,通过合理运用布隆过滤器、分区裁剪等技术,性能还有进一步提升空间。
3.4 向量存储和检索
云器Lakehouse内置的向量存储和检索能力是Apollo未来架构演进的重要方向。
- 当前状态:Apollo的AI产品Hanna Agent目前主要数据还存储在ADB PG中,向量存储(Vector Store)和Embedding功能使用的是PG Vector方案,这导致需要在多个系统间同步数据。
- 未来规划:2026年,Apollo计划将云器作为统一的Vector Store,实现Embedding、全文搜索和结构化数据查询的一体化。云器支持在单个表中同时存储向量数据和结构化数据,这意味着Apollo可以在一个平台内完成从数据存储、向量检索到SQL分析的全流程操作。
- 业务价值:统一的向量存储能力将为Apollo的AI应用开发带来巨大便利,开发人员可以使用标准SQL接口完成向量相似度搜索、混合查询等操作,大幅降低AI应用的开发门槛和运维成本。
四、实际收益
4.1 性能提升:3.5X
- 对比ADB For PG,查询性能有3.5X的提升
- ETL任务延迟降低90%,ETL 任务从 10-15 分钟缩短至 1 分钟以内,性能提升超过 10 倍,彻底解决了业务等待数据的问题
4.2 成本下降:40%
-
计算资源降低:得益于云器Lakehouse的高性能向量化引擎以及高级SQL能力(Time Travel、动态表、Table Stream)极大简化复杂数据处理逻辑,从而实现计算资源的降本
动态表代码示例:
CREATE DYNAMIC TABLE apollo.sl.sponsored_ordered_flat_v2_dyn ( ... ) -- [省略20+个具体字段定义,仅保留核心业务字段] PARTITIONED BY(aba_date) REFRESH ON DEMAND AS WITH base_with_stats AS ( -- 步骤1:预计算页面级特征(如:是否包含SBH广告位) SELECT *, count(IF(page_area LIKE 'Ad%', 1, NULL)) OVER(PARTITION BY search_term, na_page) AS ad_area_count, max(IF(page_area = 'SBH', 1, 0)) OVER(PARTITION BY search_term, na_page) AS has_sbh FROM sl.sl_hanna_amz_aba_st_sr_flat_all_dyn WHERE aba_date = '${target_date}' ) SELECT t.search_term, t.asin, t.product_title, -- 步骤3:计算最终的广告位混合排名(核心算法) row_number() OVER( PARTITION BY t.search_term, t.na_page ORDER BY t.sponsored_priority_bucket ASC, t.idx_within_area ) AS final_sponsored_rank, t.final_sponsored_type, t.updated_at FROM ( -- 步骤2:过滤非广告项,并计算优先级桶(Bucket) SELECT *, /* 业务逻辑:根据页面区域映射权重,此处省略具体的CASE WHEN代码 */ CASE WHEN ... THEN 1.0 ELSE 2.0 END AS sponsored_priority_bucket FROM base_with_stats WHERE final_sponsored_type != 'Na' -- 仅保留广告数据 ) t;一张ods写入表可以创建数十个Tablestream对象,供下游消费,无需重复建表。
-
开发运维成本降低:将原有三套系统(EMR + Flink + ADB PG)简化为Flink + 云器两套,SQL方言从三种减少至两种(Flink SQL + 云器SQL),且Flink仅用于数据入湖,不做复杂转换,开发人员可将90%的时间聚焦于云器SQL开发,大幅降低维护成本
4.3 业务价值提升:30%
(1) 规则引擎重构
-
基于云器SQL重构了广告优化规则引擎,替代原有的Spark SQL方案,自9月上线以来零故障运行,日均执行2,500个作业
(2) AI数据分析平台优化
- Apollo的核心产品Hanna Agent是一个AI驱动的广告数据分析平台,集成了全维度的亚马逊广告数据。当前,Hanna Agent的部分数据已迁移至云器。随着对AI大模型应用的深入探索,Apollo团队发现纯AI决策存在幻觉问题,因此正在从纯AI决策向工作流Agent转型,确保数据准确性。未来Apollo计划将云器作为Hanna Agent的统一数据底座和Vector Store,实现Embedding、全文搜索和结构化数据的一体化管理。
(3) 实时广告结构变更捕捉
- 接入亚马逊SQS流式数据,通过Vector工具采集后,结合Flink任务和云器调度,处理百万级Campaign、千万级广告组、近百亿Targeting的实时变更,保障全球数据链路的实时性和稳定性
五、总结与展望
5.1 总结
Apollo的案例充分展示了云器Lakehouse在初创企业数字化转型中的价值。通过引入云器,Apollo不仅解决了技术栈复杂、性能瓶颈等痛点,更重要的是大幅提升了开发效率,让小团队能够高效支撑快速增长的业务需求。
云器的一体化能力、卓越性能、丰富的高级SQL特性,以及优秀的开发者体验,使其成为初创企业理想的数据平台选择。对于资源有限但追求技术卓越的团队,云器提供了一条高效、可靠的发展路径。
随着Apollo业务的持续发展和与云器合作的不断深化,我们期待看到更多创新应用场景的落地,为跨境电商行业创造更大价值。
5.2 展望
Apollo计划在2026年进一步深化与云器的合作,主要方向包括:
- 完成数据迁移:将剩余30-40%的业务数据从ADB PG迁移至云器,实现数据统一管理
- 接入更多数据源:将卖家端的订单、库存等Amazon Feed数据接入云器,扩展业务场景
- 优化数据链路:探索AutoMQ与云器的集成,实现更低延迟的数据入湖
- 持续性能优化:利用布隆过滤器等索引技术,进一步提升查询性能
六、客户评价
“作为一个初创团队,我们只有1名数据工程师。云器帮助我们将原本复杂的技术栈大幅简化,从EMR+Flink+ADB三套系统整合为Flink+云器两套,SQL方言也从三种减少到两种。最重要的是,云器的性能表现超出了我们的预期。我们的核心查询从平均50秒优化到7秒,这让我们能够为客户提供更好的产品体验。”
“Data Studio的使用体验完爆DataWorks,这不是夸张。从数据集成到任务调度,从运维监控到开发调试,每个环节都能感受到产品的用心。对于我们这样的小团队来说,一个好用的工具能节省大量时间,让我们把精力聚焦在业务创新上。”
“Table Stream、动态表这些高级SQL能力让我们可以用更少的代码实现复杂的数据处理逻辑。我们在3个底层表上建了近30个Table Stream来支持不同的增量消费场景,这在以前的技术栈中是难以想象的。云器让数据开发变得更加优雅和高效。”
——Apollo数据工程负责人
🎁 新用户专享福利
✅ 1 TB 存储 · 1 CRU时/天计算 · 1 年全托管体验
➤ 即刻访问云器官网领取:https://www.yunqi.tech/product/one-year-package

