
重新定义ELT:通过云器Lakehouse实现ELT新方式
问题与挑战
在很多数据项目中,特别是与ML、AI关系比较紧密的数据项目中,往往需要通过Python、SQL混合的方式进行开发实现,比如通过Jupyter Notebook进行Python代码的开发,用DBeaver、VS Code等数据管理和开发工具进行SQL代码的开发。在这种方案中,经常容易发生版本管理缺失、缺少统一的调度服务等问题,从而使开发和运维变得复杂且困难。
随着现代化数据栈的发展,Metabase、MindsDB等新一代BI、AI分析产品也得到飞速发展。数据平台如何紧密融入现代化数据栈,提供完整的解决方案,也变得至关重要。
对于日趋增多的半结构化数据以及向量数据(如CSV、JSON),如果依赖客户端解析会严重影响整体处理速度,这就要求数据平台能够同时高性能地处理表格中的结构化数据以及JSON数据、向量数据。比如GH Archive提供的GitHub每小时的事件归档数据集,就是以JSON格式提供的。
在数据清洗和转换的数据工程工作中,往往需要开发很多中间表才能得到最终的目标表。如何提高这一环节的效率,也成为提升数据工程师生产力的一个重要课题。
通过云器Lakehouse实现ELT的新方式
今天笔者尝试使用云器Lakehouse,从以下三个方面寻找以上问题的新解法。

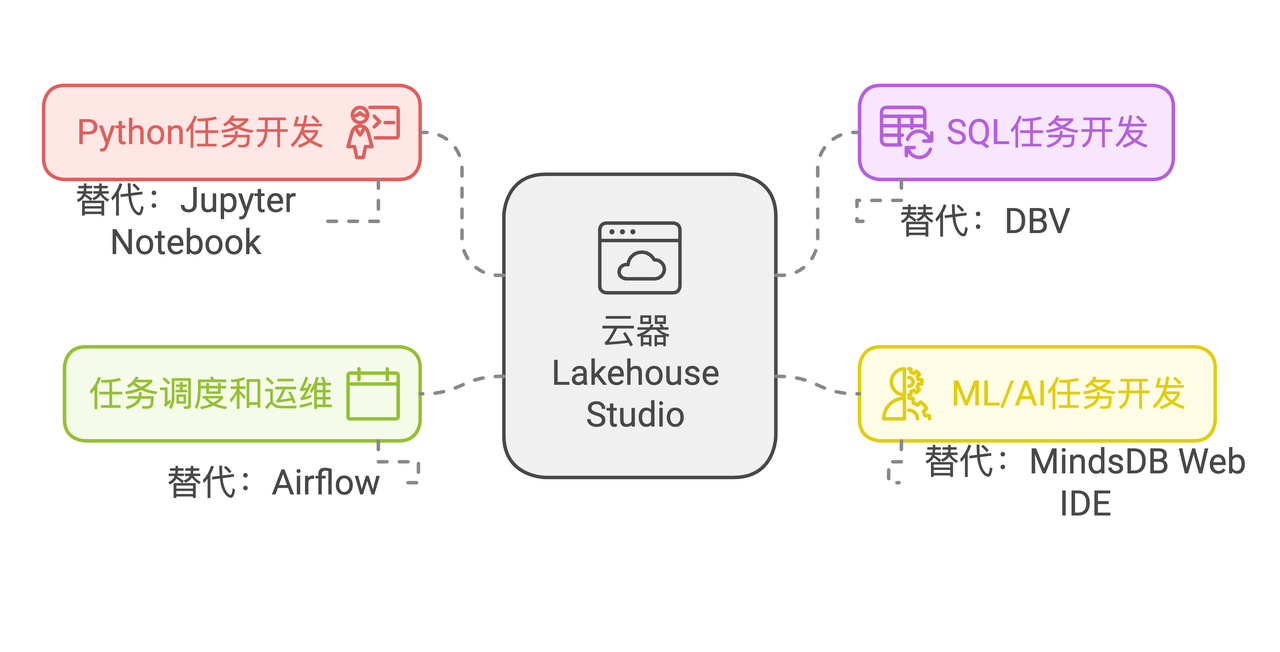
统一数据任务开发和调度
通过云器Lakehouse简化数据任务开发和运维环境,实现统一的任务版本管理:
-
Python任务开发:从Jupyter Notebook开发到云器Lakehouse Studio的Python任务开发。
-
SQL任务开发:从DBV SQL任务开发到云器Lakehouse Studio的SQL任务开发。
-
ML/AI任务开发:从MindsDB Web IDE到云器Lakehouse Studio的JDBC任务开发。
-
任务调度和运维:从Airflow到云器Lakehouse Studio任务调度和运维。
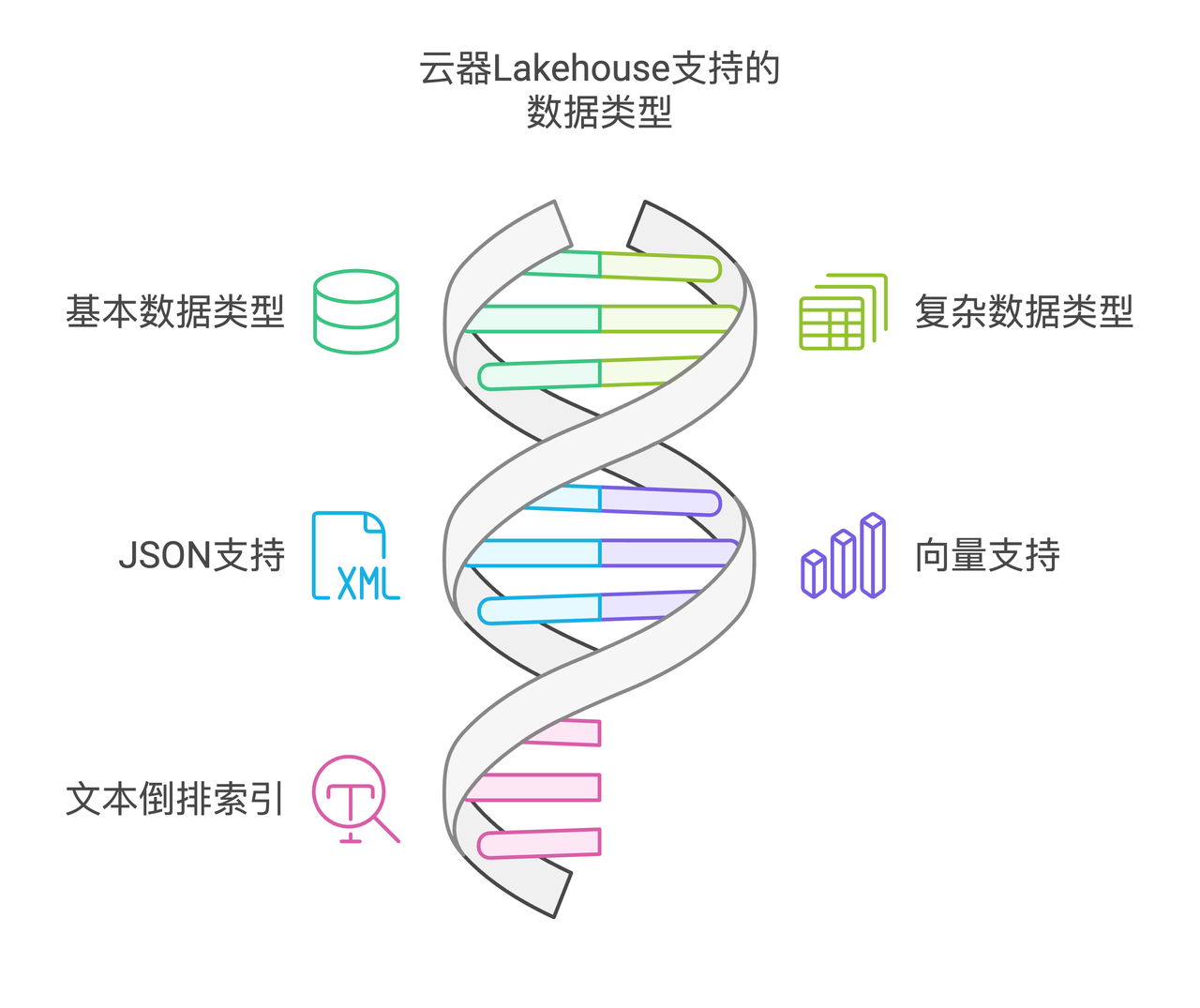
多数据类型支持
云器Lakehouse支持以下数据类型的高效存储和访问:
-
Table里常见的基本数据类型
-
Table里常见的复杂数据类型
-
JSON
-
Vector
-
文本倒排索引
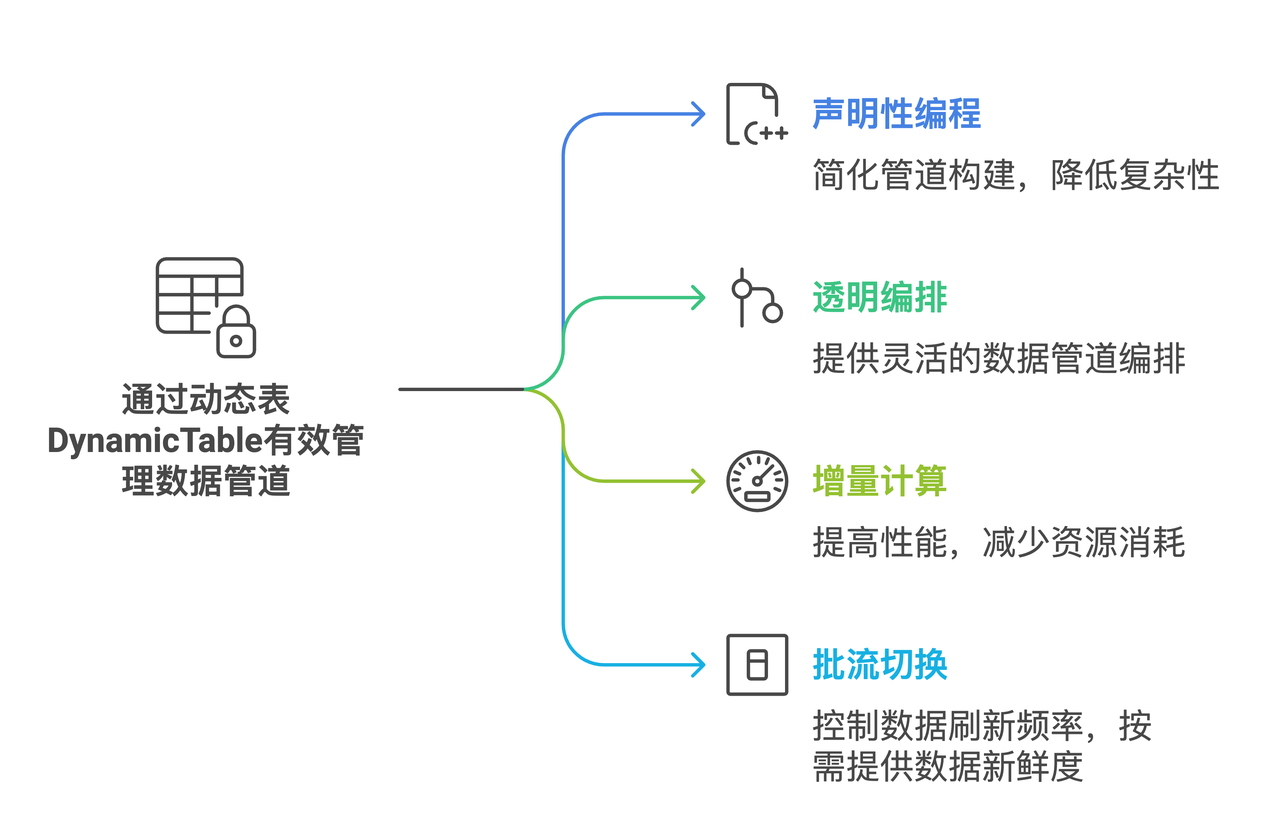
动态表Dynamic Table
云器提供的动态表(Dynamic Table),具备以下典型特性:
-
声明性编程:用声明性 SQL 定义管道结果,不用再考虑中间表逻辑,降低复杂度。
-
透明编排:通过将动态表、普通表链接在一起,管理刷新编排调度。
-
增量处理:适合增量工作负载,动态表性能优。
-
轻松切换:单命令实现批处理到流式处理过渡,平衡成本与新鲜度。
-
可观测:动态表可通过云器Lakehouse Web控制台Studio管理,提高可观测性。
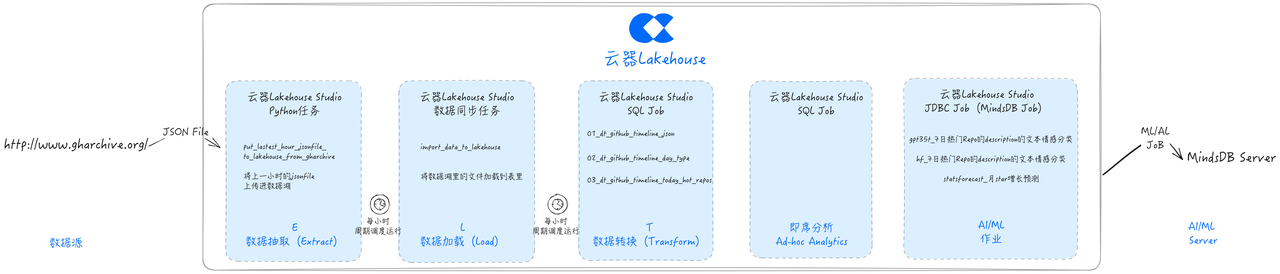
应用案例:GHArchive数据ELT流程实现
数据源介绍:GHArchive
全球范围内的开源开发者正在从事数以百万计的项目,涵盖诸如编写代码和文档、修复错误以及提交等工作。GH Archive 这一项目会对公共GitHub的事件数据予以记录,该项目提供了自2011年2月12日起始,长达13年多的GitHub事件数据存档,并使数据更易于访问,为进一步分析创造便利条件。
GitHub有15种以上事件类型,例如新提交(Push)、分叉仓库(Fork)、新建Issue、评论以及为项目添加成员等。这些事件会汇总到每小时的归档文件里,用任何HTTP客户端都能访问这些归档文件,每个归档文件里都以JSON编码GitHub API报告的事件。用户可以下载原始数据自行处理,例如编写自定义聚合脚本、将其导入数据库等。
GitHub 的事件数据示例如下:
开发任务:数据抽取(Extract)
接下来我们通过云器Lakehouse Studio开发一个Python任务,将数据从GH Archive网站抽取到数据湖存储(本方案采用阿里云OSS)中。
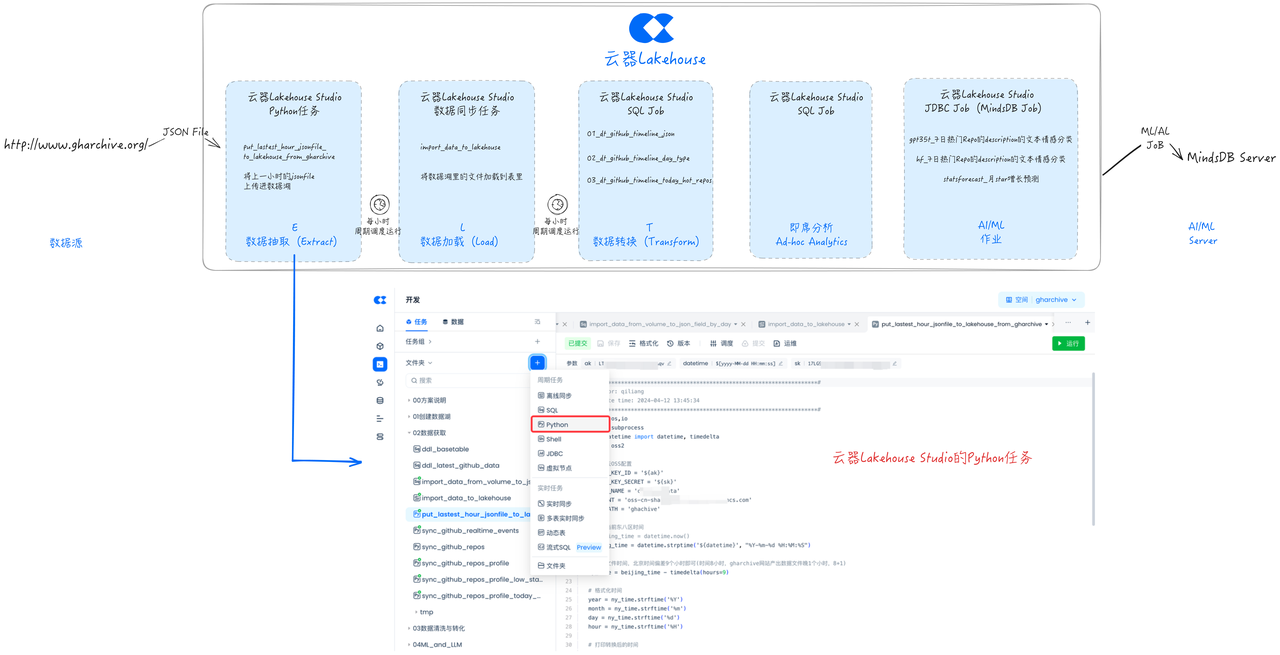
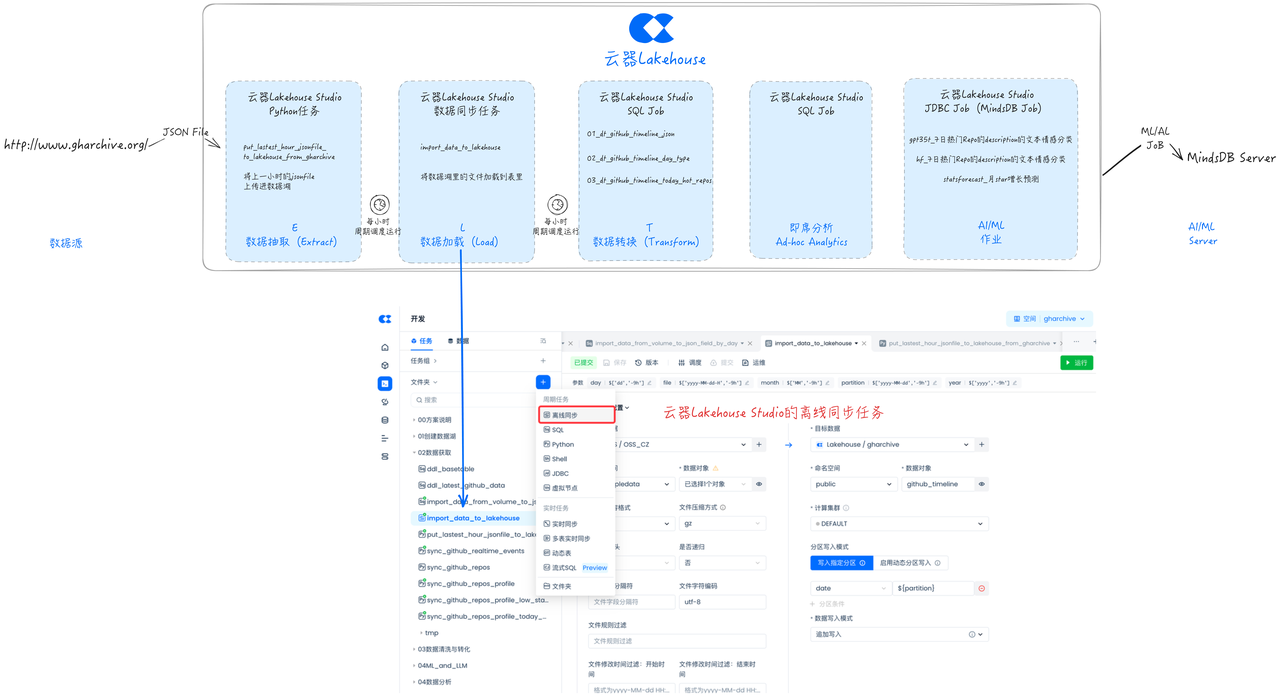
开发任务:数据加载任务(Load)
云器Lakehouse Studio支持通过离线同步任务,将数据从数据湖加载到Lakehouse的Table里,以优化的格式进行存储,并且便于细粒度的权限管理。
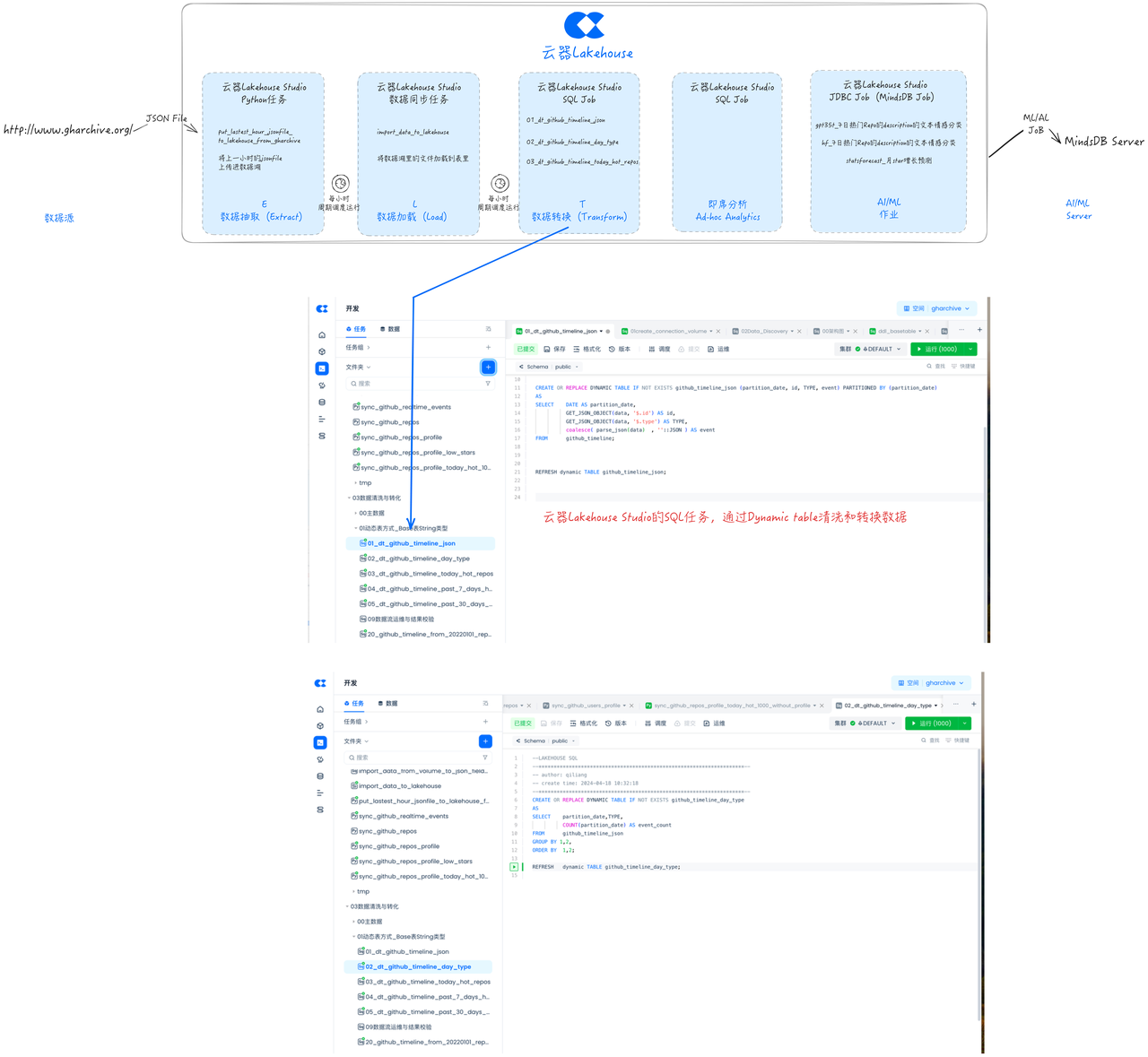
开发任务:数据清洗与转换(Transform)
云器Lakehouse动态表(Dynamic Table)是一种支持仅处理增量变化数据的表,具备增量刷新优化能力。与传统的ETL任务相比,动态表无需进行全量数据计算,也无需指定增量逻辑(如按分区对齐或使用max(system/event_time))。用户只需直接声明定义业务逻辑,动态表即可自动进行增量计算优化。
本文使用动态表进行数据清洗和转化。
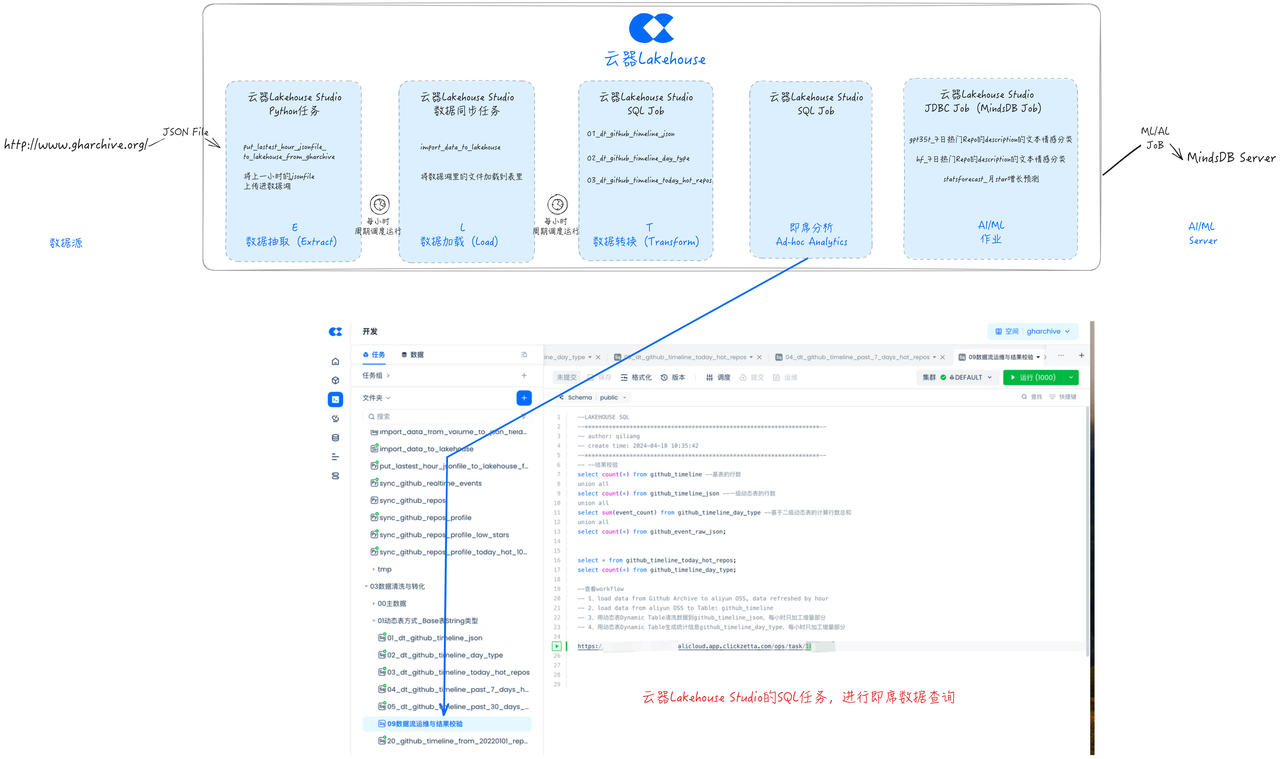
即席数据分析(Ad Hoc)
云器Lakehouse 内置了便捷的SQL查询界面,可以自由编写SQL代码、使用变量、选择集群,进行灵活的即席数据分析(Ad Hoc)。也便于进行调试运行。
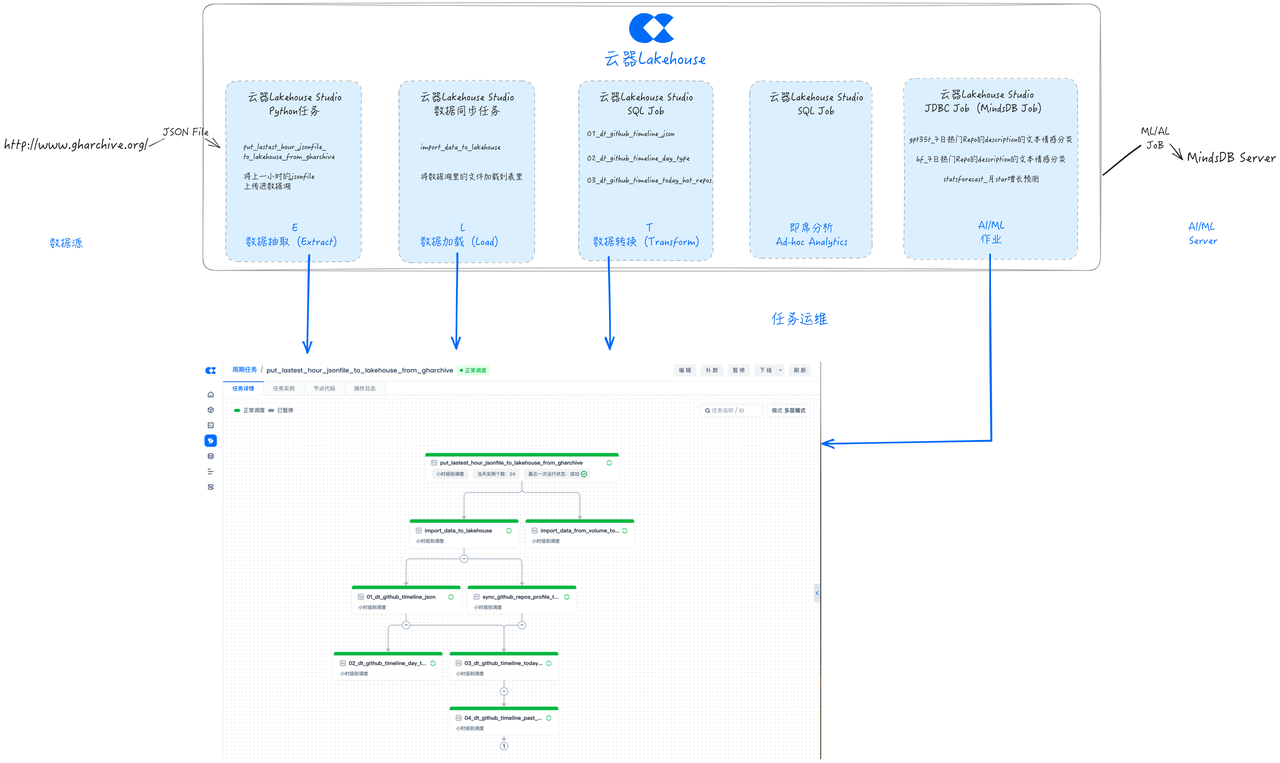
开发任务:AI/ML增强分析
基于Lakehouse Studio提供的JDBC任务节点,可以便捷地连接到MindsDB,进行增强的数据分析。
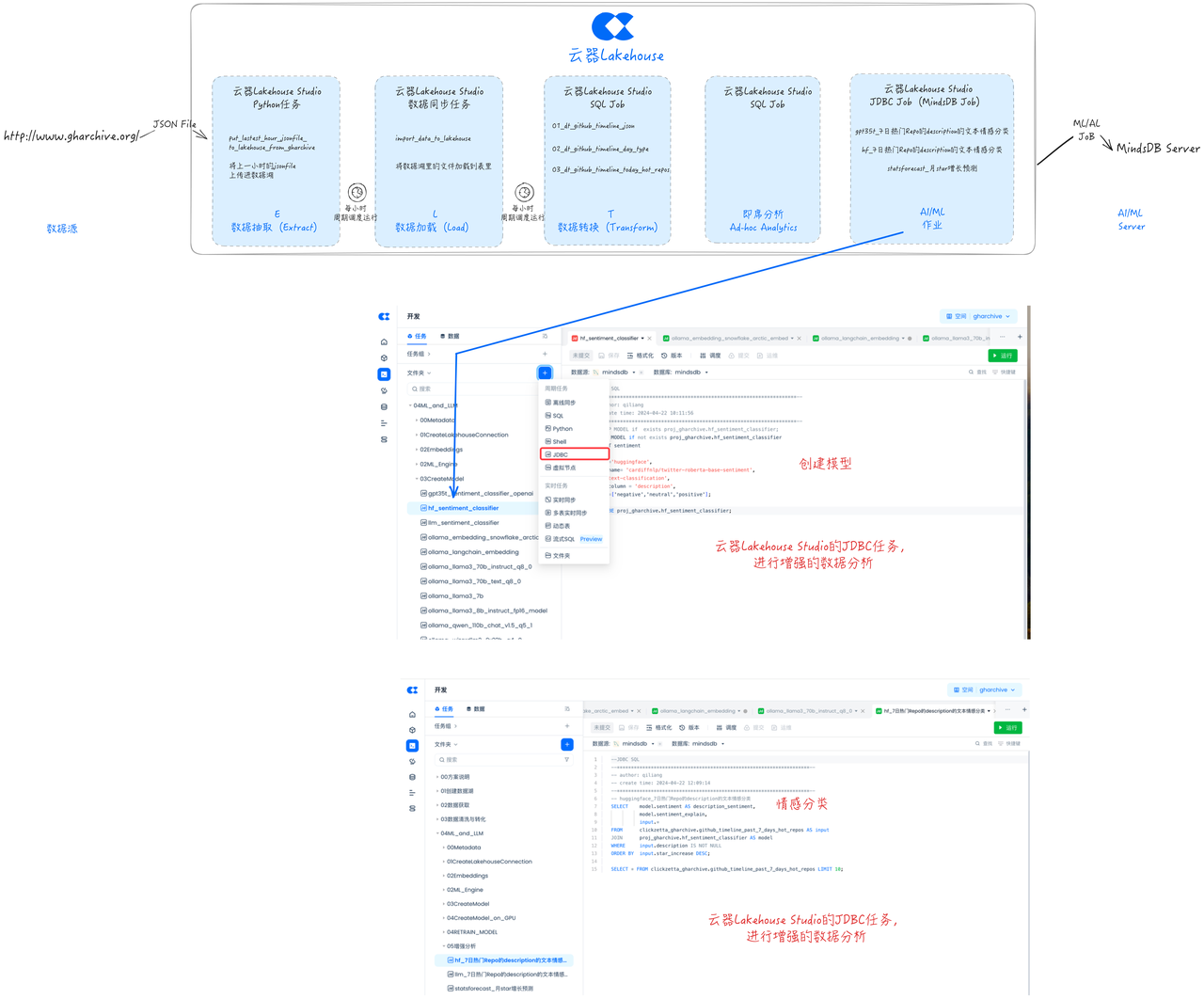
增量同步任务调度
对刚才开发好的ELT任务进行调度定时和依赖关系配置,确保任务按小时周期运行,提交并发布任务,这样就可以从GHArchive按小时同步到一小时前的GitHub事件数据,并进行清洗和转换。
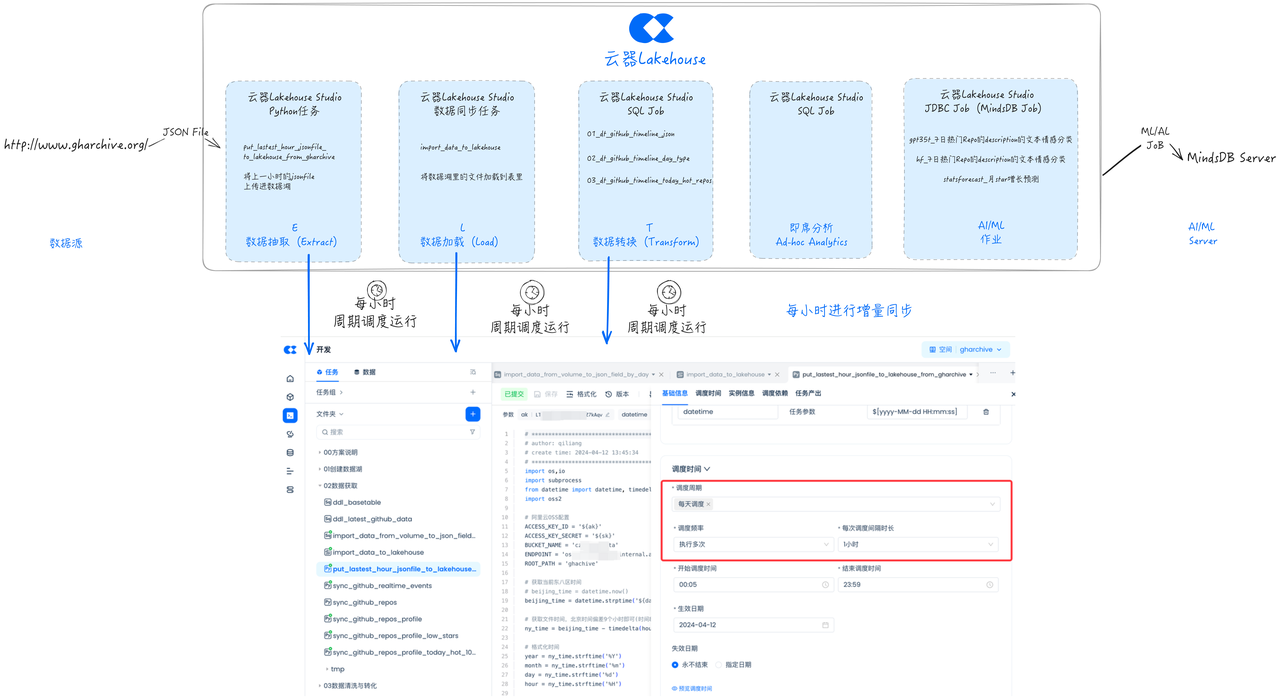
补全量数据
对于补数据任务,在云器Lakehouse Studio里,可以与增量任务完全复用,只需要按照全量数据的开始和结束日期配置并执行补数任务即可,来回刷写历史存量数据。
以GHArchive的数据为例,其网站(http://www.gharchive.org/)的数据开始日期为2011年2月12日,则按下图配置补数任务并运行即可实现全量数据的同步,补全量任务可以与增量数据同步任务同时进行,也无需开发新的全量同步任务。
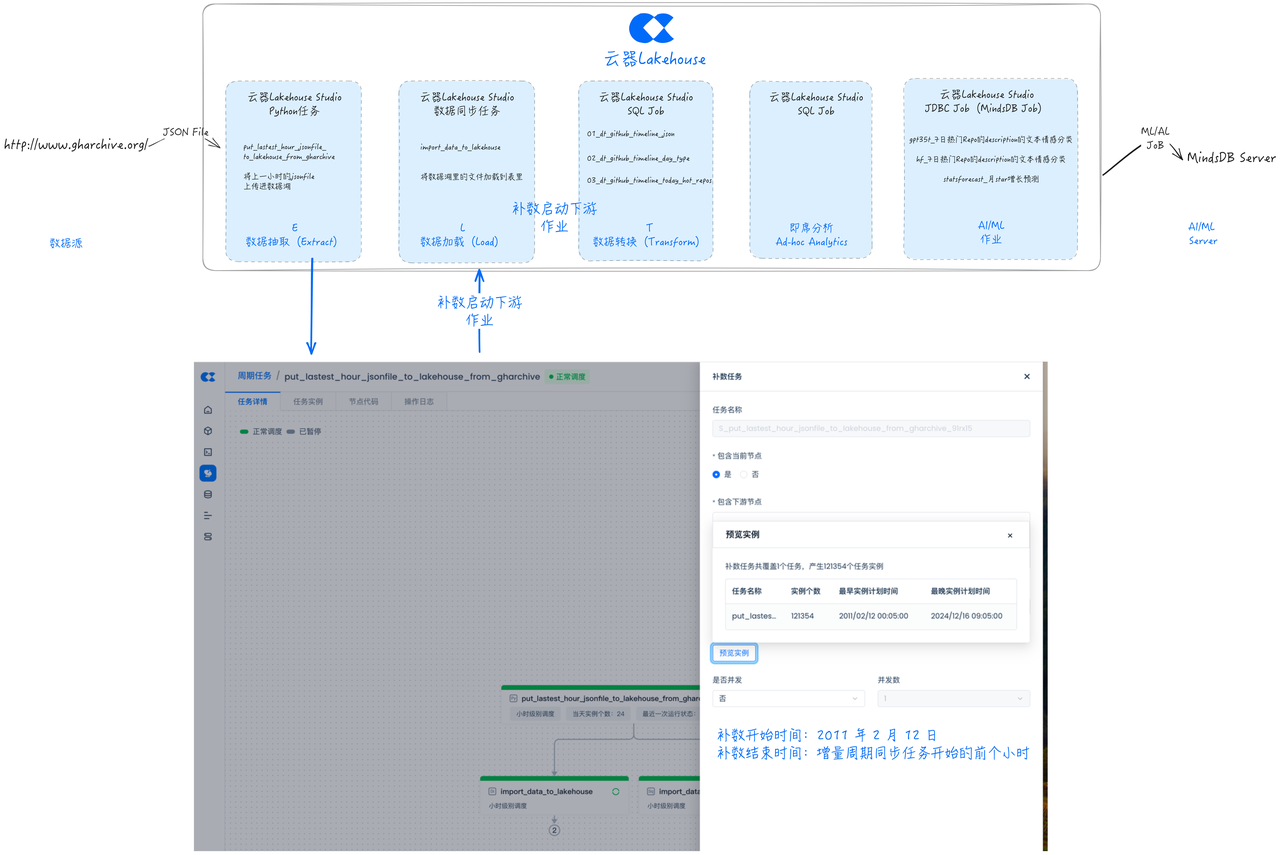
任务运维
云器Lakehouse Studio也提供了完善的运维操作界面,比如展示任务的上下游DAG关系,运行状态,进行重跑等运维操作。
总结
本文讨论了在数据项目中,特别是与ML、AI关系紧密的数据项目中,传统开发方式存在的问题与挑战,以及如何通过云器Lakehouse实现GHArchive ELT的新方式,进行统一的开发、调度和运维,显著精简方案中的产品组件,有助于大幅提升效率并节约管理成本。关键要点包括:
- 统一数据任务开发和调度:简化开发和运维环境,实现一致的任务版本管理,涵盖 Python、SQL、ML/AI 任务开发,以及统一的任务调度编排和运维管控。
- 多数据类型支持:高效存储和访问常见基本数据类型、复杂数据类型、JSON、Vector、文本倒排索引等。
- 动态表 Dynamic Table:具有声明性编程、透明编排、增量处理、轻松切换、可观测等特性。
- 应用案例:以 GHArchive 数据为例,展示了数据抽取、加载、清洗与转换、即席数据分析、AI/ML 增强分析、增量同步任务调度、补全量数据和任务运维等环节。